Si ha sido aficionado a las tecnologías de redes neuronales durante mucho tiempo, entonces probablemente haya encontrado una opinión brevemente concluida en la pregunta retórica: "¿Cómo le explica a una persona cuando una red neuronal considera que tiene cáncer?" Y si en el mejor de los casos, tales pensamientos le hacen dudar del uso de redes neuronales en áreas suficientemente
responsables , entonces, en el peor de los casos, puede perder todo su interés.
Encontré la mejor opción: acepté con calma esta limitación y, sin pensarlo mucho, seguí usando tecnologías de redes neuronales en el campo de la visión por computadora.
Desafío
Recientemente, me tocó una tarea: crear rápidamente un detector de emociones viable. Las condiciones se establecieron con bastante claridad: una persona ubicada frontalmente con una resolución de 100x100. En busca de un conjunto de datos terminado, pasé un par de horas y me di cuenta de que prácticamente nada me convenía. O incluso para "fines de investigación" era demasiado difícil acceder al conjunto de datos. La salida se encontró rápidamente: tomar una docena de largometrajes y simplemente pasar por la cascada de Haar para descargar todas las caras. Durante la noche, se recibieron más de (!) 30k imágenes. Además, las imágenes recibidas se ordenaron por 5 emociones principales (feliz, triste, neutral, enojado, sorprendido). Por supuesto, lejos de encajar todas las imágenes, y como resultado, 400-500 imágenes de caras cayeron en cada categoría.
Entonces todo comenzó con el tema de explicar los resultados de las redes neuronales. Incluso con un aumento de datos personalizado de calidad suficientemente alta, dicho conjunto de datos parecía obviamente insuficiente. Al entrenar una red basada en bloques de Resnet, se obtuvieron los siguientes números para las métricas:
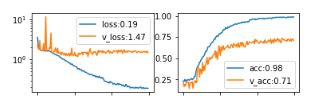
La reentrenamiento es evidente en el contexto de un número insuficiente de ejemplos, pero debido a la falta de tiempo fue urgente asegurarse de que la red funciona al menos de manera satisfactoria y no se basa, por ejemplo, en la determinación de las emociones.
Solía tener que trabajar con herramientas como Lime y Keras-Vis, pero fue aquí donde pudieron convertirse en una piedra filosófica que convierte una caja negra en algo más transparente. La esencia de ambas herramientas es aproximadamente la misma: determinar las áreas de la imagen de origen que hacen la mayor contribución a la solución de red final. Para la prueba, grabé un video que imitaba varias emociones. Habiendo descargado expresiones faciales correspondientes a varias emociones, ejecuté las herramientas anteriores en ellas
Los siguientes resultados se obtuvieron de Lime:

Desafortunadamente, incluso cambiando varios parámetros de funciones, Lime no pudo obtener suficiente visualización legible por humanos. Por alguna razón, la mitad derecha de la cara afecta la pertenencia a la clase "enojada". Lo único para "feliz" es el área lógica de la boca y los hoyuelos típicos de una sonrisa.
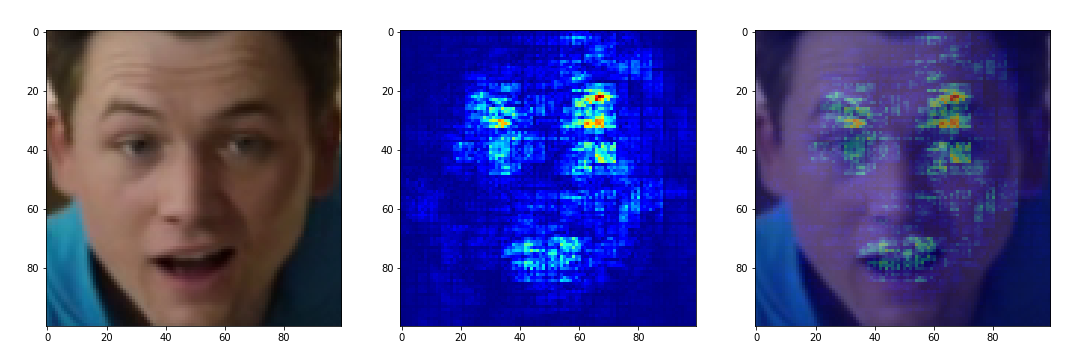
Además, todas las mismas imágenes se ejecutaron a través de Keras-Vis y bingo:
Happy busca la ubicación de los ojos y la forma de la boca. Triste se centra en las cejas caídas y los párpados. Neutral intenta mirar todo el rostro como un todo y las inocentes esquinas inferiores de la imagen. "Enojado" se enfoca lógicamente en las cejas desplazadas, PERO se olvida de la forma de la boca y, por alguna razón, busca características en la esquina inferior derecha. Y "Sorprendido" mira la forma de la boca y el párpado izquierdo (!) Elevado: es hora de comenzar a reconocer también el correcto.
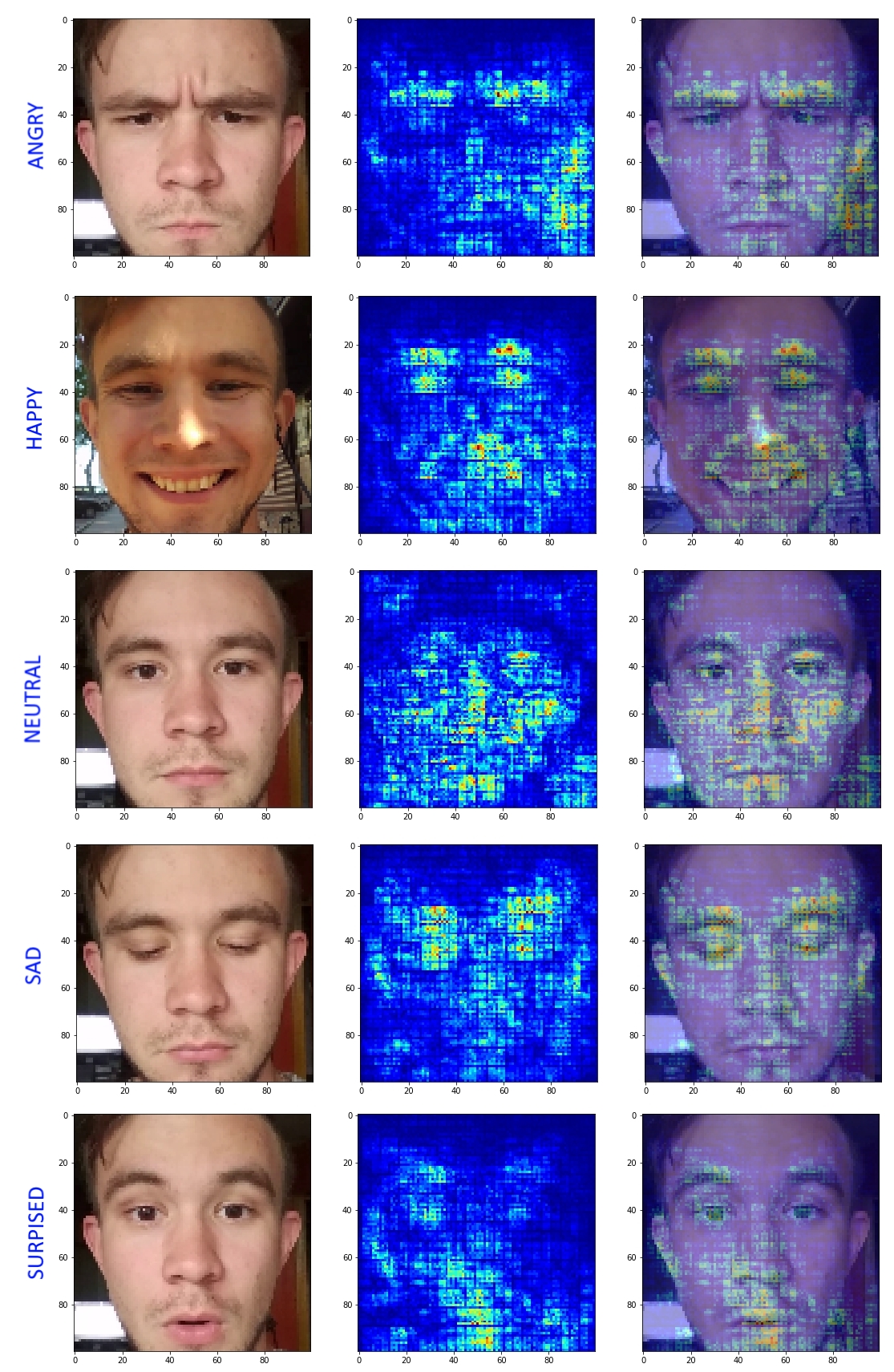
Los resultados complacieron e hicieron posible ver las fortalezas y debilidades de la red resultante. Habiendo sentido debilidades en la clasificación de las clases Sorprendido y Enojado, encontré la fuerza para aumentar ligeramente la muestra y agregué una caída más. En la siguiente iteración, se obtuvieron los siguientes resultados:

Se ve que las regiones de activación estaban más localizadas. La atención de la red al fondo en el caso de "Angry" ha desaparecido. Por supuesto, la red todavía tiene sus inconvenientes, olvidando la ceja de un lado y así sucesivamente. Pero este enfoque permitió comprender mejor qué y por qué lo hace el modelo resultante. Este enfoque es ideal en casos donde tenemos dudas sobre la convergencia correcta de la red.
Conclusiones
Las redes neuronales siguen siendo solo la solución al complejo problema de optimización. Pero incluso las tarjetas de atención de red más simples aportan algo de transparencia a esta jungla. Este enfoque se puede utilizar junto con la orientación habitual a la función de pérdida, lo que permitirá obtener redes aún más conscientes.
Si recordamos la pregunta retórica desde el comienzo del artículo, entonces podemos decir que el uso de tarjetas de atención junto con la respuesta final de la red ya conlleva cierta explicación clara que faltaba.
¡Visualiza, visualiza y visualiza de nuevo!