
Comenzamos a actualizar el monitoreo de PgBouncer en nuestro servicio y decidimos combinar todo un poco. Para que todo encajara, utilizamos las metodologías de monitoreo de rendimiento más famosas: USE (Utilización, Saturación, Errores) de Brendan Gregg y RED (Solicitudes, Errores, Duraciones) de Tom Wilkie.
Debajo de la escena hay una historia con gráficos sobre cómo funciona pgbouncer, qué configuración maneja y cómo, usando USE / RED, elegir las métricas correctas para monitorearlo.
Primero sobre los métodos mismos
Aunque estos métodos son bastante conocidos (sobre ellos ya estaban en Habré, aunque no con gran detalle ), no es que estén muy extendidos en la práctica.
USO
Para cada recurso, realice un seguimiento de la eliminación, la saturación y los errores.
Brendan Gregg
Aquí, un recurso es cualquier componente físico separado: una CPU, disco, bus, etc. Pero no solo: el rendimiento de algunos recursos de software también puede considerarse mediante este método, en particular los recursos virtuales, como los contenedores / grupos c con límites, también es conveniente considerar esto.
U - Eliminación : ya sea un porcentaje del tiempo (desde el intervalo de observación) cuando el recurso estaba ocupado con un trabajo útil. Como, por ejemplo, cargar la CPU o la utilización del disco en un 90% significa que el 90% del tiempo lo tomó algo útil) o, para recursos como la memoria, este es el porcentaje de memoria utilizada.
En cualquier caso, el 100% de reciclaje significa que el recurso no se puede usar más que ahora. Y o bien el trabajo se atascará esperando la liberación / ir a la cola, o habrá errores. Estos dos escenarios están cubiertos por las dos métricas de USO restantes correspondientes:
S - Saturación , también es saturación: una medida de la cantidad de trabajo "diferido" / en cola.
E - Errores : simplemente contamos el número de fallas. Los errores / fallas afectan el rendimiento, pero es posible que no se noten de inmediato debido a la recuperación de operaciones invertidas o mecanismos de tolerancia a fallas con dispositivos de respaldo, etc.
Rojo
Tom Wilkie (ahora trabajando en Grafana Labs) se sintió frustrado por la metodología USE, o más bien, su poca aplicabilidad en algunos casos y la inconsistencia con la práctica. ¿Cómo, por ejemplo, medir la saturación de la memoria? ¿O cómo medir los errores del bus del sistema en la práctica?
Resulta que Linux realmente informa los recuentos de errores.
T. Wilkie
En resumen, para monitorear el desempeño y el comportamiento de los microservicios, propuso otro método adecuado: medir, nuevamente, tres indicadores:
R - Rate : el número de solicitudes por segundo.
E - Errores : cuántas solicitudes devolvieron un error.
D - Duración : tiempo necesario para procesar la solicitud. Es latencia, "latencia" (© Sveta Smirnova :), tiempo de respuesta, etc.
En general, USE es más adecuado para monitorear recursos y RED para servicios y su carga de trabajo / carga útil.
Pgbouncer
Al ser un servicio, al mismo tiempo tiene todo tipo de límites y recursos internos. Lo mismo puede decirse de Postgres, a los que los clientes acceden a través de este PgBouncer. Por lo tanto, para un monitoreo completo en esta situación, se necesitan ambos métodos.
Para comprender cómo aplicar estos métodos a un portero, debe comprender los detalles de su dispositivo. No es suficiente monitorearlo como una caja negra: "está vivo el proceso pgbouncer" o "está abierto el puerto", porque En caso de problemas, esto no dará una idea de qué es exactamente y cómo se rompió y qué hacer.
Lo que generalmente hace el aspecto de PgBouncer desde el punto de vista del cliente:
- el cliente se conecta
- [el cliente hace una solicitud - recibe una respuesta] x cuántas veces necesita
Aquí he dibujado un diagrama de los estados de cliente correspondientes desde el punto de vista de PgBoucer:

En el proceso de inicio de sesión, la autorización puede ocurrir tanto localmente (archivos, certificados e incluso PAM y hba de nuevas versiones) como remotamente, es decir, en la base de datos a la que se intenta la conexión. Por lo tanto, el estado de inicio de sesión tiene un subestado adicional. Llamémoslo Executing para indicar que auth_query está auth_query en la base de datos en este momento:
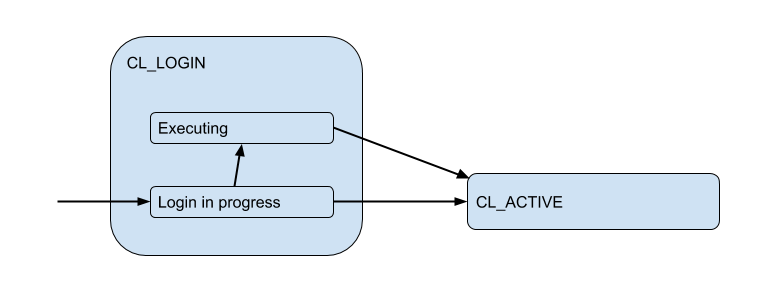
Pero estas conexiones de cliente en realidad coinciden con las conexiones de backend / upstream que PgBouncer abre dentro del grupo y tiene un número limitado. Y brindan dicha conexión al cliente solo por el tiempo, por la duración de la sesión, transacción o solicitud, dependiendo del tipo de agrupación (determinada por la configuración pool_mode ). Muy a menudo, se usa la agrupación de transacciones (lo discutiremos principalmente más adelante), cuando la conexión se emite al cliente para una transacción, y el resto del tiempo el cliente no está conectado al servidor. Por lo tanto, el estado "activo" del cliente nos dice poco y lo dividiremos en sustratos:
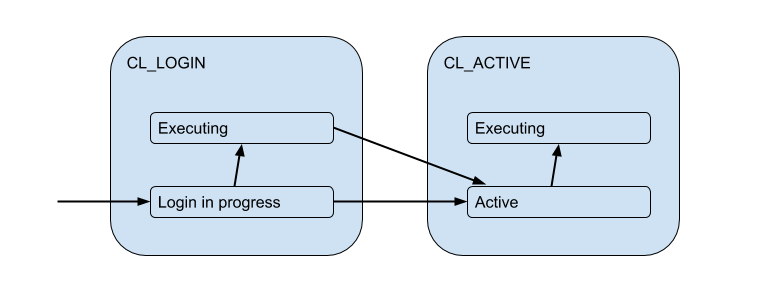
Cada uno de estos clientes se incluye en su propio grupo de conexiones, que se emitirá para su uso por la conexión real a Postgres. Esta es la tarea principal de PgBouncer: limitar el número de conexiones a Postgres.
Debido a las conexiones limitadas del servidor, puede surgir una situación en la que el cliente necesita cumplir con la solicitud directamente, pero ahora no hay conexión gratuita. Luego, el cliente se pone en cola y su conexión pasa al estado CL_WAITING . Por lo tanto, el diagrama de estado debe complementarse:
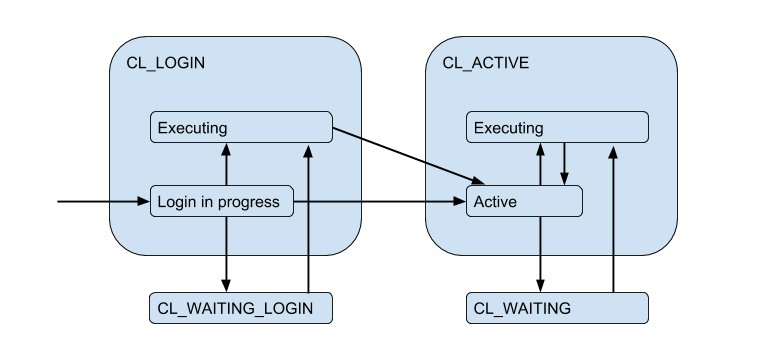
Como esto puede suceder en el caso de que el cliente solo CL_WAITING_LOGIN sesión y necesite ejecutar una solicitud de autorización, también CL_WAITING_LOGIN estado CL_WAITING_LOGIN .
Si ahora mira desde el reverso, desde el lado de las conexiones del servidor, entonces, en consecuencia, están en tales estados: cuando la autorización se produce inmediatamente después de la conexión - SV_LOGIN , emitida y (posiblemente) utilizada por el cliente - SV_ACTIVE , o libremente - SV_IDLE .
USE para PgBouncer
Así llegamos a la (versión ingenua) Utilización de un grupo específico:
Pool utiliz = /
PgBouncer tiene una base de datos de utilidad pgbouncer especial en la que hay un SHOW POOLS que muestra el estado actual de las conexiones de cada grupo:

Hay 4 conexiones de cliente abiertas y todas ellas son cl_active . De 5 conexiones de servidor: 4 sv_active y una en el nuevo estado sv_used .
¿Qué es realmente sv_used sobre las diferentes configuraciones de pgbouncer no relacionadas con el monitoreo?Por sv_used tanto, sv_used no significa "se está utilizando la conexión", como podría pensar, pero "la conexión se usó una vez y no se ha utilizado durante mucho tiempo". El hecho es que PgBouncer usa conexiones de servidor en modo LIFO por defecto, es decir Primero, se usan conexiones recién lanzadas, luego las usadas recientemente, etc. moviéndose gradualmente a compuestos de uso prolongado. En consecuencia, las conexiones del servidor desde la parte inferior de dicha pila pueden "ir mal". Y deben verificarse su vivacidad antes de su uso, lo que se hace usando server_check_query , mientras se están verificando, el estado será sv_tested .
La documentación dice que LIFO está habilitado de forma predeterminada, como luego "un pequeño número de conexiones obtiene la mayor carga de trabajo. Y esto brinda el mejor rendimiento cuando hay un servidor que sirve la base de datos detrás de pgbouncer", es decir como en el caso más típico Creo que el potencial aumento del rendimiento se debe al ahorro en el cambio de rendimiento entre múltiples procesos de back-end. Pero no funcionó de manera confiable, porque Este detalle de implementación ha existido durante> 12 años y va más allá del historial de compromisos en github y la profundidad de mi interés =)
Entonces, parecía extraño e server_check_delay con las realidades actuales que el valor predeterminado de la configuración server_check_delay , que determina que el servidor no se ha utilizado durante demasiado tiempo y debe verificarse antes de dárselo al cliente, es de 30 segundos. Esto es a pesar del hecho de que, de forma predeterminada, tcp_keepalive se habilita simultáneamente con la configuración predeterminada: comience a verificar la conexión de mantener vivo con las muestras 2 horas después de su inactividad.
Resulta que en una situación de ráfaga / sobretensión de conexiones de clientes que desean hacer algo en el servidor, se introduce un retraso adicional en server_check_query , que, aunque " SELECT 1; aún puede tomar ~ 100 microsegundos, y si server_check_query = ';' entonces puedes guardar ~ 30 microsegundos =)
Pero la suposición de que trabajar en solo unas pocas conexiones = en varios procesos de postgres de back-end "principales" será más eficiente, me parece dudoso. El proceso de trabajo de postgres almacena en caché (meta) información sobre cada tabla a la que se accedió en esta conexión. Si tiene una gran cantidad de tablas, entonces este relanzamiento puede crecer mucho y ocupar mucha memoria, hasta el intercambio de las páginas del proceso 0_o. Para evitar esto, use la configuración server_lifetime (el valor predeterminado es 1 hora), por el cual la conexión del servidor se cerrará por rotación. Pero, por otro lado, hay una configuración server_round_robin que cambiará el modo de usar conexiones de LIFO a FIFO, extendiendo las solicitudes de los clientes en las conexiones del servidor de manera más uniforme.
SHOW POOLS tomar métricas SHOW POOLS de SHOW POOLS (por algún exportador de prometheus) podemos trazar estos estados:
Pero para llegar a la disposición necesita responder algunas preguntas:
- ¿Cuál es el tamaño de la piscina?
- ¿Cómo contar cuántos compuestos se usan? ¿En bromas o en el tiempo, en promedio o en el pico?
Tamaño de la piscina
Aquí todo es complicado, como en la vida. ¡En total, ya hay cinco límites de configuración en pbbouncer!
pool_size se puede establecer para cada base de datos. Se crea un grupo separado para cada par DB / usuario, es decir desde cualquier usuario adicional , puede crear otros backends de pool_size / trabajadores de Postgres. Porque si pool_size no pool_size configurado, cae en default_pool_size , que por defecto es 20, entonces resulta que cada usuario que tiene derecho a conectarse a la base de datos (y trabaja a través de pgbouncer) puede potencialmente crear 20 procesos de Postgres, lo que parece no ser mucho. Pero si tiene muchos usuarios diferentes de las bases de datos o las propias bases de datos, y los grupos no están registrados con un usuario fijo, es decir, será creado sobre la marcha (y luego eliminado por autodb_idle_timeout ), entonces esto puede ser peligroso =)
Puede valer la pena dejar default_pool_size pequeño, solo para cada bombero.
max_db_connections : solo es necesario limitar el número total de conexiones a una base de datos, porque de lo contrario, los clientes que se comportan mal pueden crear muchos procesos backends / postgres. Y por defecto aquí - ilimitado ¯_ (ツ) _ / ¯
Tal vez debería cambiar las max_db_connections , por ejemplo, puede enfocarse en las max_connections sus Postgres (por defecto 100). Pero si tienes muchos PgBouncers ...
reserve_pool_size : en realidad, si pool_size utiliza pool_size, PgBouncer puede abrir varias conexiones más a la base. Según tengo entendido, esto se hace para hacer frente a un aumento de la carga. Volveremos a esto.max_user_connections : por el contrario, este es el límite de conexiones de un usuario a todas las bases de datos, es decir, relevante si tiene varias bases de datos y van bajo los mismos usuarios.max_client_conn : cuántas conexiones de cliente aceptará PgBouncer en total. El valor predeterminado, como de costumbre, tiene un significado muy extraño: 100. Es decir, se asume que si más de 100 clientes se bloquean repentinamente, entonces solo necesitan reset silenciosamente al nivel TCP y reset (bueno, en los registros, debo admitir, esto será "no se permitirán más conexiones (max_client_conn)").
Puede valer la pena hacer max_client_conn >> SUM ( pool_size' ) , por ejemplo, 10 veces más.
Además de SHOW POOLS servicio pseudo-base pgbouncer también proporciona el SHOW DATABASES , que muestra los límites realmente aplicados a un grupo particular:

Conexiones del servidor
Una vez más, ¿cómo medir cuántos compuestos se usan?
¿En bromas en promedio / en pico / a tiempo?
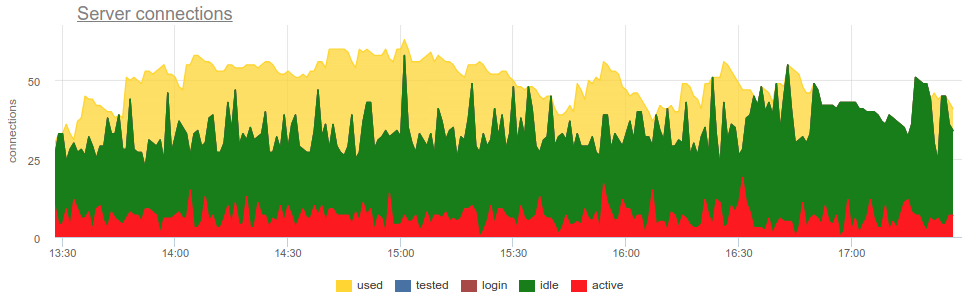
En la práctica, es bastante problemático monitorear el uso de piscinas por parte del portero con herramientas extendidas, como pgbouncer proporciona solo una imagen momentánea y, como a menudo no hace una encuesta, todavía existe la posibilidad de una imagen incorrecta debido al muestreo. Aquí hay un ejemplo real de cuándo, dependiendo de cuándo trabajó el exportador, al principio del minuto o al final, la imagen de los compuestos abiertos y usados cambia fundamentalmente:
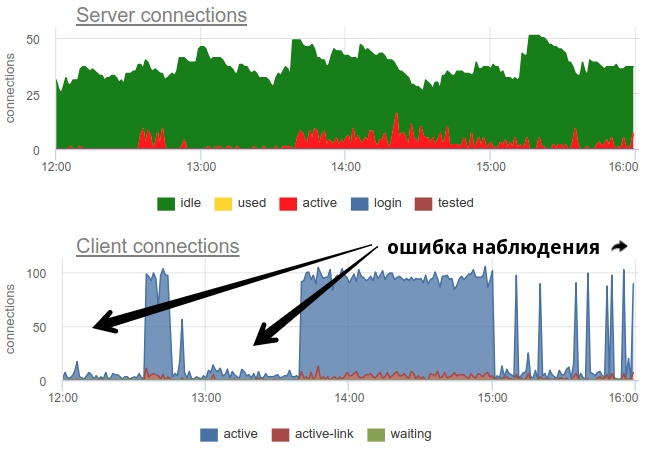
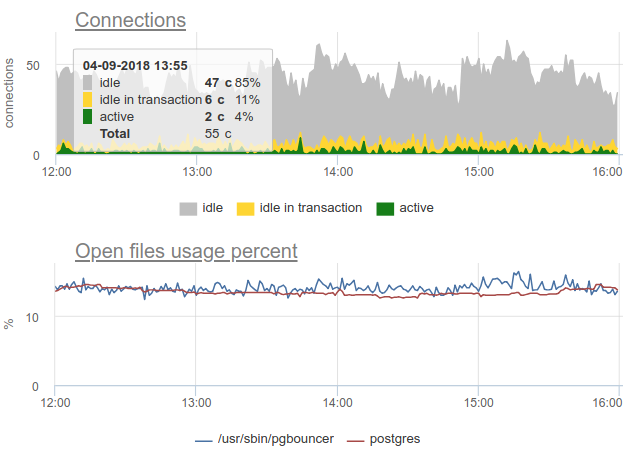
Aquí todos los cambios en la carga / uso de las conexiones son solo una ficción, un artefacto de los reinicios del recopilador de estadísticas. Aquí puede ver los gráficos de conexión en Postgres durante este tiempo y los descriptores de archivo del gorila y PG - sin cambios:
Volver a la cuestión de la eliminación. Decidimos utilizar un enfoque combinado en nuestro servicio: probamos SHOW POOLS una vez por segundo, y una vez por minuto mostramos el número promedio y máximo de conexiones en cada clase:
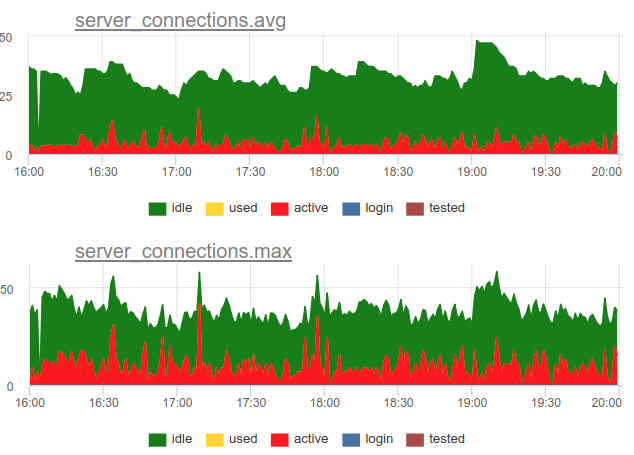
Y si dividimos el número de estas conexiones de estado activo por el tamaño del grupo, obtenemos la utilización promedio y máxima de este grupo y podemos alertar si está cerca del 100%.
Además, PgBouncer tiene un comando SHOW STATS que mostrará estadísticas de uso para cada base de datos proxy:

Estamos más interesados en la columna total_query_time : el tiempo empleado por todas las conexiones en el proceso de ejecución de consultas en postgres. Y a partir de la versión 1.8 también existe la métrica total_xact_time , el tiempo dedicado a las transacciones. En base a estas métricas, podemos construir la utilización del tiempo de conexión del servidor; este indicador no está sujeto, en contraste con el calculado a partir de los estados de conexión, a problemas de muestreo, porque Estos contadores de total_..._time son acumulativos y no pasan nada:

Comparar
Se puede ver que el muestreo no muestra todos los momentos de alta ~ 100% de utilización, y consulta query_time.
Saturación y PgBouncer
¿Por qué necesita monitorear la saturación, debido a la alta utilización ya está claro que todo está mal?
El problema es que no importa cómo mida la utilización, incluso los contadores acumulados no pueden mostrar una utilización local del 100% de los recursos si se produce solo a intervalos muy cortos. Por ejemplo, tiene coronas u otros procesos sincrónicos que pueden comenzar simultáneamente a realizar consultas a la base de datos con el comando. Si estas solicitudes son cortas, la utilización, medida en las escalas de minutos e incluso segundos, puede ser baja, pero al mismo tiempo, en algún momento, estas solicitudes se vieron obligadas a esperar en línea para su ejecución. Esto es similar con una situación en la que el uso de la CPU no es del 100% y un promedio de carga alto, como el tiempo de procesador todavía está allí, pero sin embargo, muchos procesos están esperando en línea para la ejecución.
¿Cómo se puede monitorear esta situación? Bueno, de nuevo, simplemente podemos contar el número de clientes en el estado cl_waiting acuerdo con SHOW POOLS . En una situación normal, hay cero, y más de cero significa desbordamiento de este grupo:
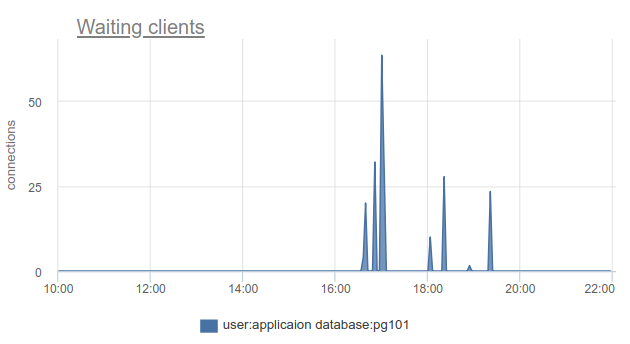
Sigue existiendo el problema de que SHOW POOLS solo se puede muestrear, y en una situación con coronas síncronas o algo así, simplemente podemos omitir y no ver a esos clientes en espera.
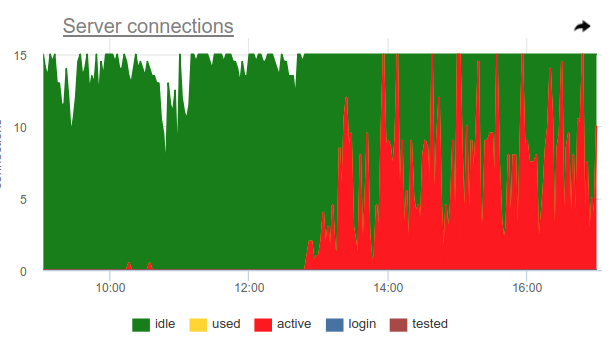
Puede usar este truco, pgbouncer en sí mismo puede detectar el uso del 100% del grupo y abrir el grupo de copia de seguridad. Dos configuraciones son responsables de esto: reserve_pool_size - por su tamaño, como dije, y reserve_pool_timeout - cuántos segundos debe waiting un cliente antes de usar el grupo de respaldo. Por lo tanto, si vemos en el gráfico de conexiones del servidor que el número de conexiones abiertas a Postgres es mayor que pool_size, entonces hubo una saturación del pool, así:

Obviamente, algo como coronas una vez por hora hace muchas solicitudes y ocupa completamente la piscina. Y aunque no vemos el momento en que active conexiones active exceden el límite de pool_size , pgbouncer se vio obligado a abrir conexiones adicionales.
También en este gráfico, el server_idle_timeout configuración server_idle_timeout es claramente visible, después de cuánto dejar de mantener y cerrar conexiones que no se utilizan. Por defecto, esto es 10 minutos, que vemos en el gráfico, después de los picos active exactamente a las 5:00, a las 6:00, etc. (según cron 0 * * * * ), las conexiones se cuelgan idle + used otros 10 minutos y se cierran.
Si vive a la vanguardia del progreso y ha actualizado PgBouncer en los últimos 9 meses, puede encontrar en la columna SHOW STATS total_wait_time , que mejor muestra la saturación, porque considera acumulativamente el tiempo que pasan los clientes en estado de waiting . Por ejemplo, aquí, el waiting apareció a las 16:30:
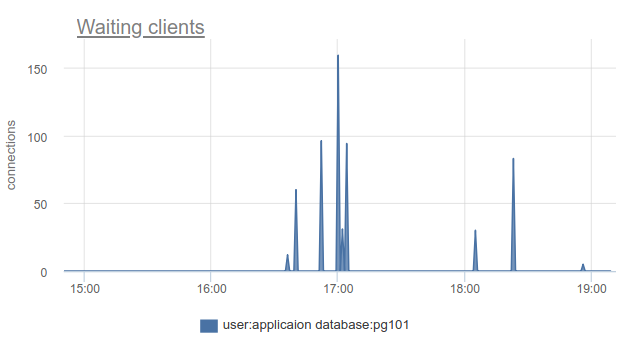
Y wait_time , que es comparable y claramente afecta el average query time , se puede ver desde las 15:15 hasta casi las 19:

Sin embargo, monitorear el estado de las conexiones del cliente sigue siendo muy útil, porque le permite descubrir no solo el hecho de que todas las conexiones a dicha base de datos se han gastado y los clientes tienen que esperar, sino también porque SHOW POOLS dividido en grupos separados por los usuarios, y SHOW STATS no, le permite averiguar qué clientes usaron todas las conexiones a la base especificada, de acuerdo con la columna sv_active del grupo correspondiente. O por métrica
sum_by(user, database, metric(name="pgbouncer.clients.count", state="active-link")):
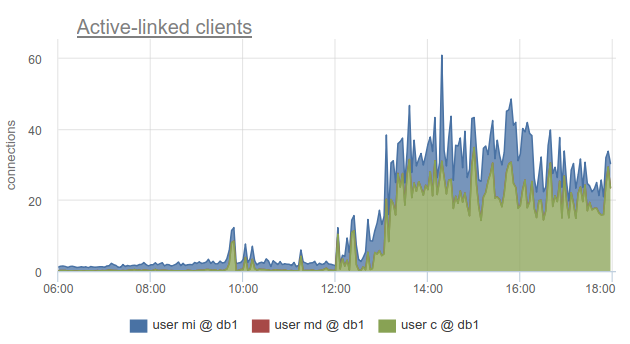
En okmeter fuimos aún más lejos y agregamos un desglose de las conexiones utilizadas por las direcciones IP de los clientes que las abrieron y utilizaron. Esto le permite comprender exactamente qué instancias de aplicación se comportan de manera diferente:

Aquí vemos IP de kubernetes específicos de hogares con los que tenemos que lidiar.
Errores
Aquí no hay nada particularmente complicado: pgbouncer escribe registros en los que informa errores si se alcanza el límite de conexiones del cliente, el tiempo de espera para conectarse al servidor, etc. Todavía no hemos llegado a los registros de pgbouncer :(
ROJO para PgBouncer
Si bien el USO se centra más en el rendimiento, en el sentido de los cuellos de botella, RED, en mi opinión, trata más sobre las características del tráfico entrante y saliente en general, y no sobre los cuellos de botella. Es decir, RED responde a la pregunta: ¿funciona todo bien y, de lo contrario, USE ayudará a comprender cuál es el problema?
Requisitos
Parece que todo es bastante simple para la base de datos SQL y para el extractor de proxy / conexión en dicha base de datos: los clientes ejecutan declaraciones SQL, que son solicitudes. De SHOW STATS tomamos total_requests y total_requests su derivada de tiempo
rate(metric(name="pgbouncer.total_requests", database: "*"))

Pero, de hecho, hay diferentes modos de extracción, y el más común son las transacciones. La unidad de trabajo para este modo es una transacción, no una consulta. En consecuencia, a partir de la versión 1.8, Pgbouner ya proporciona otras dos estadísticas: total_query_count , en lugar de total_requests y total_xact_count , el número de transacciones completadas.
Ahora, la carga de trabajo se puede caracterizar no solo en términos de la cantidad de solicitudes / transacciones completadas, sino que, por ejemplo, puede ver la cantidad promedio de solicitudes por transacción en diferentes bases de datos, dividiendo una en otra
rate(metric(name="total_requests", database="*")) / rate(metric(name="total_xact", database="*"))

Aquí vemos cambios obvios en el perfil de carga, que pueden ser la razón del cambio en el rendimiento. Y si observara solo la tasa de transacciones o solicitudes, es posible que no vea esto.
Errores rojos
Está claro que RED y USE se cruzan en el monitoreo de errores, pero me parece que los errores en el USE son principalmente errores de procesamiento de solicitudes debido al 100% de utilización, es decir. cuando el servicio se niega a aceptar más trabajo. Y los errores para RED serían mejores para medir los errores con precisión desde el punto de vista del cliente, las solicitudes del cliente. Es decir, no solo en una situación en la que el grupo en el PgBouncer está lleno o si otro límite ha funcionado, sino también cuando se solicitan tiempos de espera como "cancelación del estado de cuenta debido al tiempo de espera del estado de cuenta", cancelaciones y reversiones de transacciones por parte del cliente, etc. e. de nivel superior, más cercano a los tipos de errores de lógica de negocios.
Duraciones
Aquí nuevamente SHOW STATS con contadores acumulativos total_xact_time , total_query_time y total_wait_time nos ayudarán, dividiéndolos por el número de solicitudes y transacciones, respectivamente, obtenemos el tiempo promedio de solicitud, el tiempo promedio de transacción, el tiempo promedio de espera por transacción. Ya mostré un gráfico sobre el primero y el tercero:
¿Qué más puedes ponerte genial? El conocido antipatrón en el trabajo con la base de datos y Postgres, en particular, cuando la aplicación abre una transacción, realiza una solicitud, luego comienza (durante mucho tiempo) a procesar sus resultados, o peor aún, va a algún otro servicio / base de datos y realiza solicitudes allí. Todo este tiempo, la transacción "se cuelga" en la apertura de postgres, el servicio luego regresa y realiza algunas solicitudes más, actualizaciones en la base de datos, y solo luego cierra la transacción. Para los postgres esto es especialmente desagradable, porque Los trabajadores de PG son caros. Por lo tanto, podemos monitorear cuando dicha aplicación está idle in transaction en el propio postgres, de acuerdo con la columna de state en pg_stat_activity , pero todavía hay los mismos problemas descritos con el muestreo, porque pg_stat_activity proporciona solo la imagen actual. En PgBouncer, podemos restar el tiempo dedicado por los clientes en total_query_time solicitudes total_query_time del tiempo dedicado a las transacciones total_xact_time ; este será el momento de dicha inactividad. Si el resultado aún se divide por total_xact_time , entonces se normalizará: un valor de 1 corresponde a una situación en la que los clientes están idle in transaction 100% del tiempo. Y con tal normalización, hace que sea fácil entender lo malo que está todo:
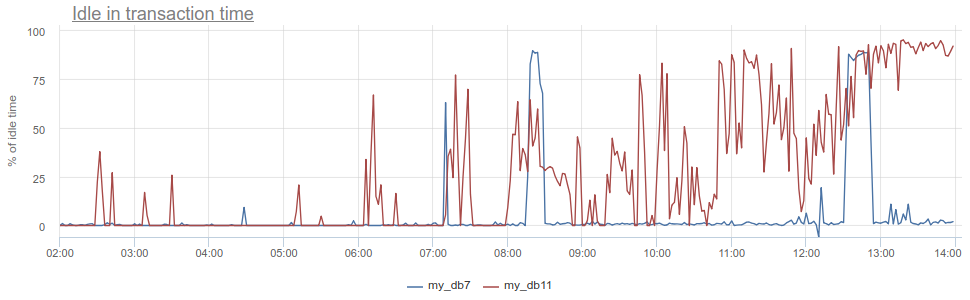
Además, volviendo a Duración, la métrica total_xact_time - total_query_time se puede dividir por el número de transacciones para ver cuánto es la aplicación inactiva promedio por transacción.
En mi opinión, los métodos USE / RED son más útiles para estructurar qué métricas disparas y por qué. Dado que estamos involucrados en el monitoreo a tiempo completo y tenemos que monitorear varios componentes de la infraestructura, estos métodos nos ayudan a tomar las métricas correctas, hacer los cronogramas y disparadores correctos para nuestros clientes.
Un buen monitoreo no se puede hacer de inmediato; es un proceso iterativo. En okmeter.io solo tenemos monitoreo continuo (hay muchas cosas, pero mañana será mejor y más detallado :)