
Mi nombre es Yuri Nevinitsin y estoy involucrado en el sistema de estadísticas internas en OK. Quiero hablar sobre cómo transferimos un sistema analítico de 50 terabytes en tiempo real, en el que miles de millones de eventos se registran diariamente, desde Microsoft SQL a una base de columnas llamada Druid. Y al mismo tiempo, aprenderá algunas recetas para usar
Druid .
¿Por qué necesitamos estadísticas?
Queremos saber todo acerca de nuestro sitio, por lo que registramos no solo el comportamiento de los discos, procesadores, etc., sino también cada acción del usuario, cada interacción entre subsistemas y todos los procesos internos de casi todos nuestros sistemas. El sistema de estadísticas está estrechamente integrado en el proceso de desarrollo.
Con base en los datos del sistema de estadísticas, nuestros gerentes establecen metas para los equipos, realizan un seguimiento de sus logros e indicadores clave. Los administradores y desarrolladores supervisan el funcionamiento de todos los sistemas, investigan incidentes y anomalías. El monitoreo automático monitorea constantemente y en una etapa temprana identifica problemas, hace pronósticos de exceder los límites. Además, las características y los experimentos se lanzan constantemente, se realizan actualizaciones y cambios. Y monitoreamos el efecto de todas estas acciones a través del sistema de estadísticas. Si ella se niega, no podremos realizar cambios en el sitio.
Nuestras estadísticas se presentan principalmente en forma de gráficos. Por lo general, el gráfico muestra varios días a la vez, para que la dinámica sea clara. Aquí hay un ejemplo de mis experimentos con Druid. Aquí hay un gráfico de carga de datos (líneas / 5 min).
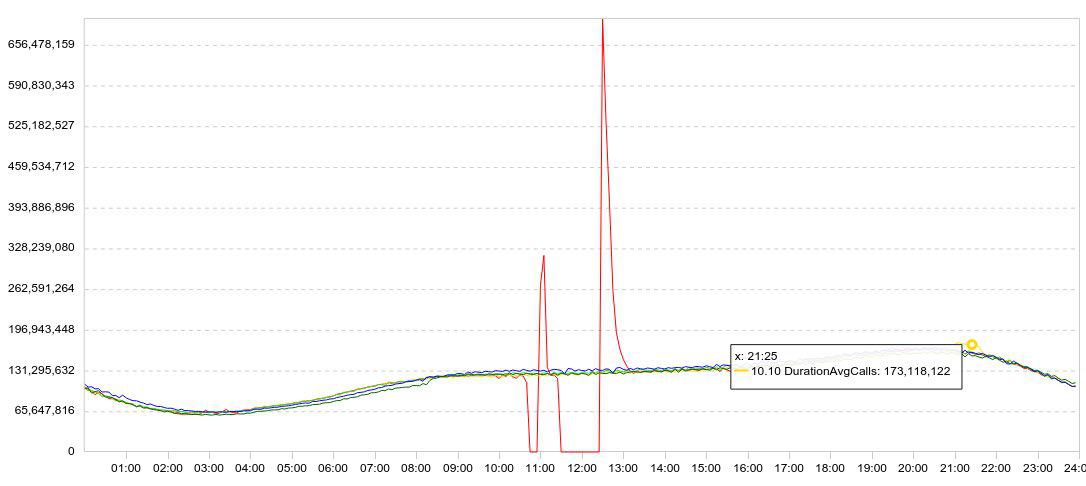
Disminuí la velocidad de la descarga (el gráfico rojo se bloquea a cero), esperé un tiempo, reinicié la descarga y observé qué tan rápido Druid podía cargar los datos acumulados (picos después de fallas).
Cualquier programación puede ampliarse mediante cualquier parámetro, por ejemplo, por host, tabla, operación, etc. También tenemos gráficos a largo plazo con dinámicas anuales. Por ejemplo, a continuación se muestra un gráfico del aumento diario en el número de entradas en Druid.
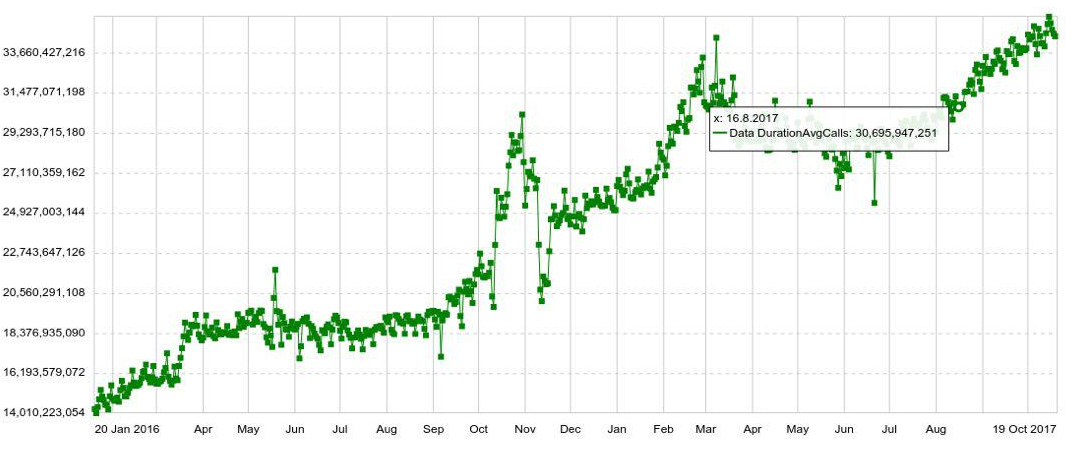
También podemos combinar varios gráficos en paneles separados (paneles), lo que resultó ser muy conveniente. E incluso si el usuario necesita ver solo un par de gráficos de cientos, todavía los abre no individualmente, sino en el panel, lo que aumenta la carga en el sistema.
El problema
Si bien el volumen de datos era pequeño, lidiamos con SQL bastante bien. Pero a medida que crecía el volumen de datos, la producción de gráficos disminuyó. Y al final, las estadísticas en la hora pico comenzaron a retrasarse media hora, y el tiempo de respuesta promedio de un gráfico alcanzó los 6 segundos. Es decir, alguien recibió el cronograma en 2 segundos, alguien en 10-20 y alguien en un minuto. (Puede leer sobre el desarrollo del sistema en SQL
aquí )
Cuando investiga una anomalía o incidente, generalmente necesita abrir y ver una docena de gráficos, cada uno de los cuales se deduce del anterior, no se pueden abrir al mismo tiempo. Tuve que esperar 10 veces durante 10-20 segundos. Fue muy molesto.
La migracion
Todavía podría extraer algo del sistema, agregar servidores ... Pero aproximadamente al mismo tiempo, Microsoft cambió su política de licencias. Si continuamos usando SQL Server, tendríamos que regalar millones de dólares. Por lo tanto, decidieron migrar.
Los requisitos fueron los siguientes:
- Las estadísticas no deben retrasarse (más de 2 minutos).
- El cuadro debe abrirse en no más de 2 segundos.
- Todo el panel debería abrirse en no más de 10 segundos.
- El sistema debe ser tolerante a fallas, capaz de sobrevivir a la pérdida de un centro de datos.
- El sistema debe ser fácilmente escalable.
- El sistema debería ser fácil de modificar, por lo que queríamos que estuviera en Java.
Todo esto nos lo ofreció solo Druida. También tiene agregación preliminar, que le permite ahorrar un poco más de volumen e indexación durante la inserción de datos. Druid admite todos los tipos de consultas que se necesitan para nuestras estadísticas. Por lo tanto, parecía que podíamos sustituir fácilmente Druid por SQL Server.
Por supuesto, consideramos no solo a Druid para el papel de candidato para la mudanza. Mi primer pensamiento fue reemplazar Microsoft SQL Server con PostgreSQL. Sin embargo, esto solo resolvería el problema de los costos financieros, pero no ayudaría con la accesibilidad y la ampliación.
También analizamos Influx, pero resultó que la parte responsable de la alta disponibilidad y escalabilidad está cerrada. Prometheus, con el debido respeto a su rendimiento, está más ajustado para el monitoreo y no puede presumir de alta disponibilidad o escalabilidad simple. OpenTSDB también es más adecuado para la supervisión, no tiene índices para todos los campos. No consideramos Click House, ya que en ese momento no estaba allí.
Pon Druida. Terabytes de datos migrados. E inmediatamente después de cambiar de SQL Server a Druid, el número de vistas de gráficos aumentó 5 veces. Luego comenzaron a ejecutar estadísticas "pesadas", que tenían miedo de ejecutar antes, porque SQL difícilmente lo manejaría.
Ahora Druid de 12 nodos (40 núcleos, 196 GB de RAM) toma 500 mil eventos por segundo por hora punta, mientras que hay un gran margen de seguridad (columna MAX: casi cinco veces el margen de la CPU).
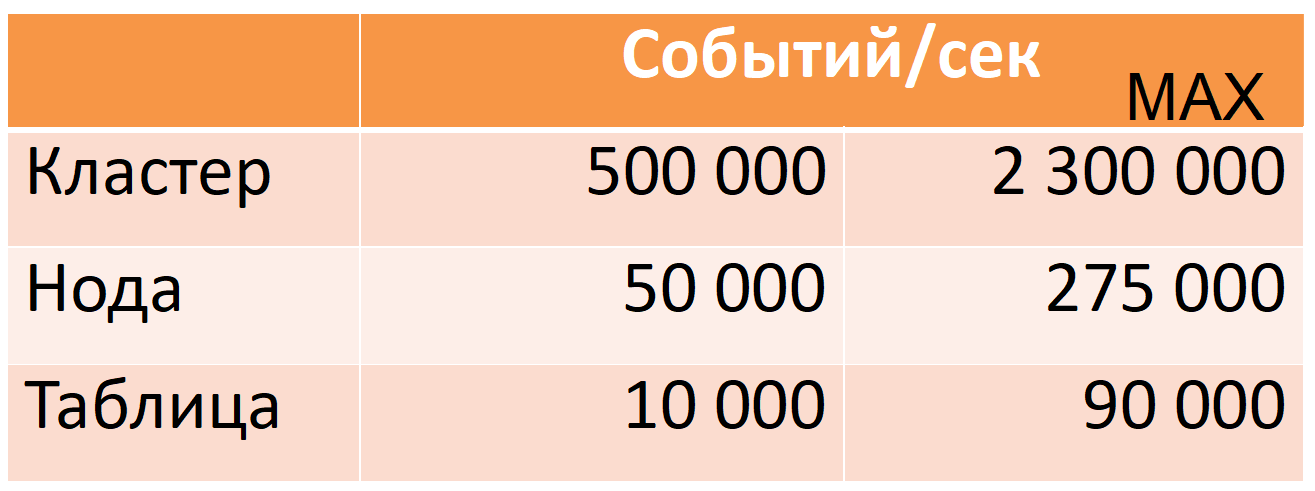
Estas cifras se basan en datos de producción. Te diré cómo logramos esto, pero primero describiré a Druid con más detalle.
Druida
Este es un sistema OLAP de series de tiempo de columna distribuida. Su documentación no contiene los conceptos usuales del mundo SQL para una tabla (fuente de datos en su lugar) o una cadena (evento en su lugar), pero los usaré para facilitar la descripción.
Druid se basa en varios supuestos de datos (limitaciones):
- cada línea de datos tiene una marca de tiempo que crece de manera monótona (dentro de una ventana de 10 minutos por defecto).
- los datos no cambian, solo insertar (la operación de actualización no).
Esto le permite cortar datos en los llamados segmentos de tiempo. Un segmento es una "partición" indivisible e invariable mínima de una tabla durante un cierto período de tiempo. Todas las operaciones de datos, todas las consultas se realizan segmento por segmento.
Cada segmento es autosuficiente: además de la tabla principal, escrita en forma de columnas, también contiene directorios e índices necesarios para la ejecución de consultas. Podemos decir que un segmento es una pequeña columna de base de datos de solo lectura (a continuación se ofrece una descripción más detallada del dispositivo del segmento).
A su vez, esto da como resultado una "distribución": la capacidad de dividir una gran cantidad de datos en pequeños segmentos para realizar cálculos en paralelo (tanto en una máquina como en varias a la vez).
Si necesita "actualizar" al menos una línea, deberá volver a cargar todo el segmento nuevamente. Es posible y todo está listo para esto. Cada segmento tiene una versión, y un segmento con una versión más nueva reemplazará automáticamente al segmento con la versión anterior (sin embargo, si se requiere una actualización regular, entonces vale la pena reevaluar si Druid es adecuado para este caso de uso).
Para describir el segmento del dispositivo, consideramos un ejemplo simple en la forma tabular habitual:
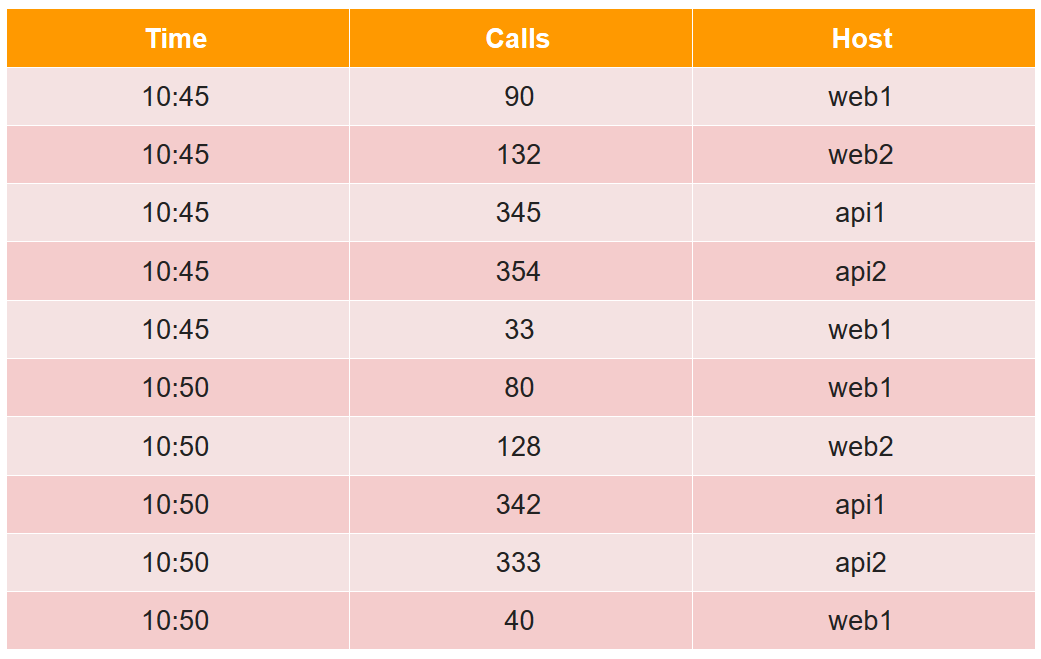
En esta tabla, el número de llamadas en dos cinco minutos de cuatro hosts (tenga en cuenta que para el host web1 hay dos líneas en cada período de cinco minutos).
Todas las celdas de datos desde el punto de vista del druida se dividen en tres tipos:
- marca de tiempo: marca de tiempo UTC en ms (en el ejemplo, es hora).
- métricas es lo que necesita calcular (suma, mínimo, máximo, conteo, ...), y necesita conocerlas de antemano para cada tabla (en el ejemplo, esto es Llamadas, y calcularemos la suma).
- dimensiones: esto es lo que puede agrupar y filtrar (no necesita conocerlas de antemano y se puede cambiar sobre la marcha) (en el ejemplo, esto es Host).
Al insertar, todas las filas se agrupan por el conjunto completo de dimensiones + marca de tiempo, y si coinciden con cada una de las métricas, se aplica "su" función de agregación (como resultado, no hay filas con el mismo conjunto de dimensiones + marca de tiempo). Por lo tanto, nuestro ejemplo después de la inserción en el druida se verá así:

La marca de tiempo y todas las métricas (en nuestro caso, es Tiempo y llamadas) se escribirán como matrices de números de tipo largo (también se admiten flotantes y dobles). Para cada una de las dimensiones (en nuestro caso es Host), se creará un diccionario, un conjunto ordenado de cadenas (con nombres de host). La columna del host se escribirá como una matriz int, indicando los números en el diccionario.
Tenga en cuenta que después de insertar en el druida, se agregaron pares de líneas para el host web1 con la misma marca de tiempo, y la cantidad total se registró en las llamadas (es imposible extraer los datos iniciales del druida).
Se requieren índices para el filtrado rápido de datos, porque puede haber millones de filas y miles de hosts. Los índices son mapas de bits, uno para cada línea en el diccionario.

Las unidades indican los números de línea en los que participa este host. Para filtrar dos hosts, debe tomar dos mapas de bits, combinarlos a través de OR y seleccionar los números de línea en unidades del mapa de bits resultante.
Un druida se compone de muchos componentes.
En primer lugar, tiene varias dependencias externas.

- Almacenamiento Allí, Druid simplemente almacena los segmentos en forma comprimida. Puede ser un directorio local, HDFS, Amazon S3. Aquí solo se usa el espacio, no se realizan cálculos.
- Meta: una base de datos para la información Meta. Esta base de datos almacena el mapa de datos completo: qué segmentos son relevantes, cuáles están desactualizados, qué ruta está almacenada.
- Usando ZooKeeper, el sistema realiza el descubrimiento y anuncia en qué nodos de druida qué segmentos están disponibles para consulta.
- Caché de solicitudes ejecutadas, puede ser memcached o caché local en java heap.
En segundo lugar, el propio druida consta de varios tipos de componentes.
- Los nodos en tiempo real cargan el flujo de datos nuevos en el orden en que se reciben y atienden las solicitudes.
- Los nodos históricos contienen toda la masa de datos y sirven solicitudes para ello. Cuando decimos que tenemos un clúster de 300 TB, nos referimos a nodos históricos.
- Broker es responsable de distribuir los cálculos entre nodos históricos y en tiempo real.
- El Coordinador es responsable de asignar segmentos entre los nodos históricos y de la replicación.
- Servicio de indexación, que le permite (re) cargar datos en lotes, por ejemplo, para "actualizar" parte de los datos.
Flujo de datos
 Las flechas en negrita indican una secuencia de datos, las flechas delgadas indican una secuencia de metadatos.
Las flechas en negrita indican una secuencia de datos, las flechas delgadas indican una secuencia de metadatos.Un nodo en tiempo real toma datos, índices y cortes en segmentos por tiempo, por ejemplo, por día.
Cada nuevo segmento de un nodo en tiempo real escribe en el almacenamiento y deja una copia para atender las solicitudes. Luego registra metadatos de que un nuevo segmento ha aparecido en el repositorio a lo largo de tal y tal camino.
El coordinador recibe esta información, releyendo periódicamente la base de metadatos. Cuando encuentra un nuevo segmento, (a través de ZooKeeper) ordena varios nodos históricos para descargar este segmento. Se descargan y (a través de ZooKeeper) anuncian que tienen un nuevo segmento. Cuando un nodo en tiempo real recibe este mensaje (a través de ZooKeeper), elimina su copia para dejar espacio para nuevos datos.
Procesamiento de solicitudes

Tres tipos de nodos participan en el procesamiento de solicitudes: intermediario, en tiempo real e histórico. La solicitud llega al agente, que sabe en qué nodos qué segmentos se encuentran. Distribuye la solicitud por nodos históricos (y en tiempo real) que almacenan los segmentos deseados. Los nodos históricos también paralelizan los cálculos tanto como sea posible, envían los resultados al intermediario y él se los entrega al cliente. Al combinar este esquema con el almacenamiento de datos en columna, Druid puede procesar grandes cantidades de información muy rápidamente.
Alta disponibilidad
Como recordará, Druid en la lista de dependencias tiene una base para los metadatos, que pueden ser MySQL o PostgreSQL. También se menciona Apache Derby, pero este producto no se puede usar para la producción, solo para el desarrollo (según tengo entendido, el derby se usa en una forma incrustada, para no generar mysql / pgsql en un entorno virgen).
¿Qué sucederá si esta base falla (y / o el almacenamiento y / o el coordinador)? Un nodo en tiempo real no puede escribir metadatos (y / o segmentos). Entonces el coordinador no podrá volver a leerlos y no encontrará un nuevo segmento. El nodo histórico no lo descargará y el nodo en tiempo real no eliminará su copia, pero continuará descargando los últimos datos. Como resultado, los datos comenzarán a acumularse en nodos en tiempo real. Esto no puede continuar indefinidamente. Sin embargo, se sabe qué recursos están disponibles en los nodos en tiempo real y qué tipo de flujo de datos tenemos. Por lo tanto, tenemos una cantidad de tiempo predecible por la cual podemos arreglar la base fallida (y / o almacenamiento y / o coordinador).
Dado que los mysql / pgsql compatibles no garantizan una alta disponibilidad inmediata, decidimos jugar de forma segura y utilizamos nuestra propia solución (ya hecha) basada en Cassandra, ya que ofrece una alta disponibilidad (puede leer más sobre esto
aquí ).
Además, finalizamos los nodos en tiempo real de tal manera que con una acumulación excesiva, los datos más antiguos se eliminan, liberando espacio para los nuevos. Esto es muy importante para nosotros, porque la situación en la que no podemos elevar la base fallida (y / o el almacenamiento y / o el coordinador) durante mucho tiempo y se acumulan muchos datos es muy probablemente una consecuencia de un gran accidente. Y en este momento, los últimos datos son los más importantes.
Druida y ZooKeeper
Con ZooKeeper, todo es mejor y peor. Mejor porque ZooKeeper es tolerante a fallas, tiene replicación lista para usar. Parece que eso podría pasar?
En términos generales, este capítulo ya no es relevante. Y esta no es una historia de éxito, es un dolor que (tanto nosotros como el druida reciente) decidimos eliminar radicalmente casi todos los datos de ZooKeeper, y ahora los nodos de druida los solicitan directamente entre sí a través de HTTP.
ZooKeeper tiene dos tipos de tiempos de espera. El tiempo de espera de conexión es un tiempo de espera de red simple, después del cual el cliente se vuelve a conectar a ZooKeeper e intenta restaurar su sesión. Y el tiempo de espera de la sesión, después del cual la sesión se elimina y todos los datos
efímeros creados dentro de esta sesión también se eliminan (por el propio ZooKeeper), que se notifica a todos los demás clientes de ZooKeeper.
En base a esto, el descubrimiento en el druida funciona: al inicio, cada nodo crea una nueva sesión en ZooKeeper y registra datos
efímeros sobre sí mismo: host: puerto, tipo de nodo (corredor / tiempo real / histórico / ...), marca de tiempo de conexión, etc. ... Otros nodos druidas reciben notificaciones de ZooKeeper y leen estos datos, para que sepan que un nuevo nodo druida ha aumentado y qué tipo de nodo es. Si algún nodo druida cae después del tiempo de espera de su sesión, ZooKeeper eliminará los datos al respecto, y los demás nodos druidas lo sabrán. Para que lo aprendan más rápido, preferimos poner un pequeño tiempo de espera de sesión.
Cuando se eleva un nodo en tiempo real o histórico, además de datos sobre sí mismo, también escribe en ZooKeeper una lista de segmentos que tiene (también son datos
efímeros ). Más adelante, se crean segmentos en nodos históricos y en tiempo real, se eliminan los nuevos y viejos, y cada nodo refleja esto en su lista en ZooKeeper. Esta lista puede ser grande, por lo que se divide en partes para que no se sobrescriba toda la lista, sino solo la parte modificada.
El agente, a su vez, cuando ve un nuevo nodo en tiempo real o histórico, también resta su lista de segmentos de ZooKeeper para distribuir las solicitudes a este nodo. Los nodos en tiempo real leen esta lista para eliminar su copia del segmento que apareció en el nodo histórico. Dado que la lista se divide en partes y se sobrescribe en partes, ZooKeeper le dirá qué parte ha cambiado, solo que se volverá a leer.
Como dije, esta lista puede ser larga. Cuando hay muchos datos en ZooKeeper, resulta que ya no es tan estable. En nuestro caso, los problemas obvios comenzaron cuando el número de segmentos alcanzó los 7 millones, la instantánea de ZooKeeper luego ocupó 6 GB.
¿Qué sucede si un nodo druida pierde contacto con ZooKeeper?
Druid trabaja con ZooKeeper de tal manera que en el caso de un tiempo de espera de sesión, cada nodo crea una nueva sesión y escribe todos sus datos allí y vuelve a leer los datos de otros nodos. Como hay muchos datos, el tráfico despega en ZooKeeper. Esto puede llevar a un tiempo de espera en otros nodos del druida, luego ellos también comienzan a reescribir y volver a leer. Por lo tanto, el tráfico crece como una avalancha hasta el punto de que ZooKeeper pierde la sincronización entre sus instancias y comienza a generar instantáneas de un lado a otro.
¿Qué ve el usuario en este momento?
Cuando un corredor pierde contacto con ZooKeeper (y se produce un tiempo de espera de sesión), ya no sabe en qué segmentos se encuentran los nodos históricos. Y da respuestas vacías. Es decir, si ZooKeeper está inactivo, Druid no funciona. Es completamente imposible "curarlo", pero es posible esparcir popotes en algunos lugares.
En primer lugar, puede eliminar datos de ZooKeeper. Está bien si se pierden: Druid simplemente los sobrescribirá. Si el problema con ZooKeeper ya ha comenzado, para su solución más rápida, se recomienda desactivar ZooKeeper, eliminar los datos y dejarlos vacíos, y no esperar a que se resuelva por sí solo.
Ahora estamos aumentando el tiempo de espera de la sesión. ¿Qué pasa en este caso?
Supongamos que un nodo histórico se reinicia incorrectamente y no elimina la sesión anterior de ZooKeeper, mientras crea uno nuevo y escribe un montón de datos allí. Mientras la sesión anterior todavía está activa y el tiempo de espera no ha pasado, dos copias de los datos se almacenan en ZooKeeper. Si hay muchos de estos nodos reiniciados inmediatamente, se duplicarán muchos datos. Por lo tanto, debe mantener un suministro de memoria para ZooKeeper para que no se agote y ZooKeeper no deje de funcionar. ¿Por qué no se pudieron eliminar los datos de la sesión anterior?
Por la misma razón, es necesario completar correctamente la operación de los nodos históricos, ya que en ese momento eliminan sus datos de ZooKeeper y pueden hacerlo durante mucho tiempo. La finalización de los nodos históricos lleva aproximadamente media hora.
Los nodos históricos tienen una característica más. Cuando comienzan, observan qué segmentos están almacenados en ellos, y luego la información sobre esto se escribe en ZooKeeper. Y dado que los datos se distribuyen de manera más o menos uniforme en los nodos históricos, si los ejecuta al mismo tiempo, comenzarán a escribir en ZooKeeper aproximadamente al mismo tiempo. De nuevo, esto aumenta la probabilidad de un crecimiento del tráfico y tiempos de espera similares a las olas. Por lo tanto, debe ejecutar nodos históricos secuencialmente para difundir las sesiones de grabación en ZooKeeper a tiempo.
También hicimos dos optimizaciones más:
- Reprogramamos ligeramente el trabajo con ZooKeeper para que solo los nodos que los necesitan fueran leídos de Druid. realtime, , . , . , .
- , ZooKeeper, , . ZooKeeper 6 2 ( ).
8 ; .
Druid
realtime , . - ( , , ). , MMAP ( ). . .
-, realtime- , JVM , .

. : 1) 2) . , . , , . , , , . ( , , ).
, realtime- , , .. , , , ( ).
, . , , .
, Druid . , , , .
, . , (web%, api%).
- Druid — . .
- , .
- Druid , , : , , , .
- Druid , , calls.
, 5 % , 95 % — .
, , realtime- .
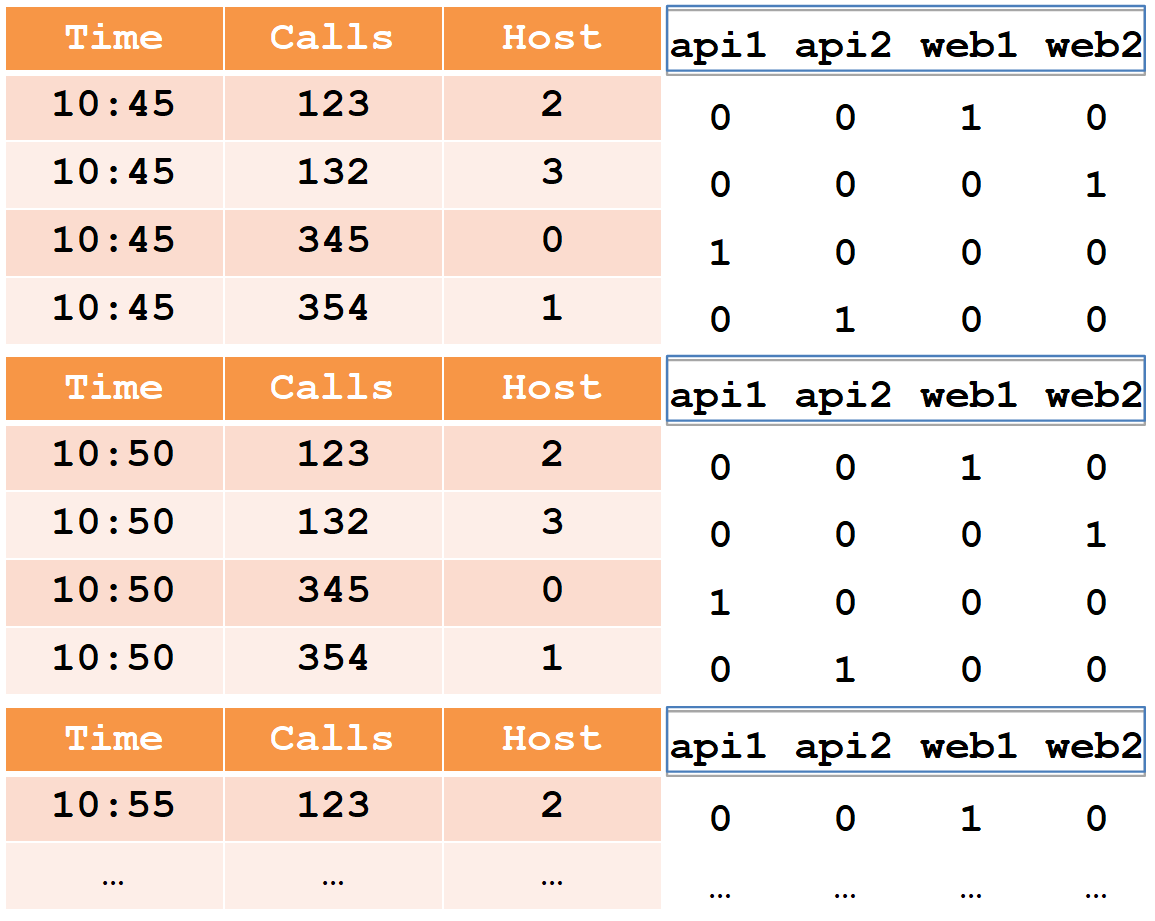
, ( 10:45) . - , -. , ( 10:50) , -. Y así sucesivamente. , , «calls», «time» «host» .
-. , «» . , , . ( 95% ) , : , . 100 , 1000.
? , . , realtime , . (.. historical realtime-), .
, : . , , . 100 . , . .
. 80% , , , . . . , selector, . , .
, , , . , . , 8 . Druid. , , Druid, . , . :

, , . . , , . . 27 . , 27 , 27 .
, . 27 , 9, 9 , .
.

— : , , . — : , , . — : , , . — , . , . , 27. 9, . ( 95% ) 9 . 27 .
14 . . , 14 . 14 . . , , 10 , . .
, 2 . 11 , 74 . , . 74 ? , .
Druid . , , , . , , . , , . , , .
, Druid . , ( ) , . 5 : , . . ( java), . Druid , .
Resumen
, , SQL Server, Microsoft.
, / .
, , .
20 , , 18 .
one-cloud (
https://habr.com/company/odnoklassniki/blog/346868/ ), .