Hola Habr Me gustaría hablar sobre uno de los enfoques para resolver el problema de la diarización del hablante y mostrar cómo se puede implementar este método en Python. Para no asustar al lector, no daré fórmulas matemáticas complejas (en parte porque yo mismo "no soy un verdadero soldador"), pero intentaré explicar todo en un lenguaje simple y contarlo todo de tal manera que un desarrollador que nunca antes haya encontrado el aprendizaje automático lo haya entendido.
Al prepararme para escribir este artículo, elegí entre dos opciones: para aquellos que ya están familiarizados con Data Science y para aquellos que simplemente programan bien. Al final, elegí la segunda opción, decidiendo que sería una buena demostración de las capacidades de DS.
Declaración del problema.
Como nos
dice Wikipedia, la diarización es el proceso de dividir una secuencia de audio entrante en segmentos homogéneos de acuerdo con si la secuencia de audio pertenece a uno u otro altavoz. En otras palabras, el registro debe dividirse en partes y numerarse: una persona habla en estos lugares y otra en estos lugares. Desde el punto de vista del aprendizaje automático, las tareas de este tipo pertenecen a la clase de aprendizaje sin un maestro y se denominan agrupaciones. Puede leer acerca de qué métodos de agrupación existen
aquí o
aquí , por ejemplo, pero solo hablaré de los que nos son útiles: este es un modelo de mezcla gaussiana y agrupación espectral. Pero sobre ellos un poco más tarde.
Comencemos desde el principio.
Preparación del medio ambiente
SpoilerNo estaba seguro de si abandonar esta sección; no quería convertir el artículo en un tutorial. Pero al final lo dejé. Quien no lo necesite saltará, y para aquellos que harán todo desde cero, este paso facilitará el inicio.
En términos generales, además de R, python es el lenguaje principal para resolver problemas de Data Science, y si aún no ha intentado programarlo, le recomiendo hacerlo porque python le permite hacer muchas cosas con elegancia, literalmente en unas pocas líneas (por cierto, hay incluso ese meme).
Hay dos ramas de python en desarrollo por separado: las versiones 2 y 3. En mis ejemplos, utilicé la versión 3.6, pero si lo deseaba, se pueden portar fácilmente a la versión 2.7. Es conveniente implementar cualquiera de estas ramas junto con el instalador de
Anaconda , instalando el cual recibirá de inmediato un shell interactivo para el desarrollo: IPython.
Además del entorno de desarrollo en sí, se necesitarán bibliotecas adicionales: librosa (para trabajar con audio y extraer atributos), webrtcvad (para segmentación) y pickle (para escribir modelos entrenados en un archivo). Todos ellos se instalan mediante un comando simple en Anaconda Prompt.
pip install [library]
Extracción de características
Comencemos con la extracción de características: datos con los que trabajarán los modelos de aprendizaje automático. En principio, la señal de sonido en sí misma ya son datos, es decir, una matriz ordenada de valores de amplitud de sonido, a la que se agrega un encabezado que contiene el número de canales, frecuencia de muestreo y otra información. Pero no podremos analizar estos datos directamente, ya que no contienen esas cosas, observando qué, nuestro modelo puede decir: sí, estas piezas pertenecen a la misma persona.
En las tareas de procesamiento de voz, hay varios enfoques para extraer funciones. Una de ellas es obtener coeficientes cepstrales de frecuencia de mel. Ya se
han escrito aquí, así que solo te recordaré un poco.
La señal original se corta en cuadros con una longitud de 16-40 ms. Luego, aplicando una ventana de
Hamming al marco, realizan una rápida transformación de Fourier y obtienen la densidad espectral de potencia. Luego, con un "peine" especial de filtros dispuestos uniformemente en la escala de tiza, se crea un espectrograma de tiza, al que se aplica una transformada discreta de coseno (DCT), un algoritmo de compresión de datos ampliamente utilizado. Los coeficientes así obtenidos son una especie de característica comprimida del marco, y dado que los filtros que utilizamos estaban ubicados en la escala de
tiza , los coeficientes transportan más información en el rango de percepción del oído humano. Típicamente, se utilizan de 13 a 25 MFCC por cuadro. Como además del espectro en sí, la personalidad de la voz está formada por la velocidad y la aceleración, MFCC se combina con la primera y la segunda derivada.
En general, MFCC es la opción más común para trabajar con el habla, pero hay otros signos además de ellos: LPC (Codificación predictiva lineal) y PLP (Predicción lineal perceptual), y a veces también puede encontrar LFCC, donde en lugar de la escala de tiza, se usa lineal.
Veamos cómo extraer MFCC en python.
import numpy as np import librosa mfcc=librosa.feature.mfcc(y=y, sr=sr, hop_length=int(hop_seconds*sr), n_fft=int(window_seconds*sr), n_mfcc=n_mfcc) mfcc_delta=librosa.feature.delta(mfcc) mfcc_delta2=librosa.feature.delta(mfcc, order=2) stacked=np.vstack((mfcc, mfcc_delta, mfcc_delta2)) features=stacked.T
Como puede ver, esto realmente se hace en unas pocas líneas. Ahora pasemos al primer algoritmo de agrupamiento.
Modelo de mezcla gaussiana
Un modelo de una mezcla de distribuciones gaussianas sugiere que nuestros datos son una mezcla de distribuciones gaussianas multidimensionales con ciertos parámetros.
Si lo desea, puede encontrar fácilmente una descripción detallada del modelo y cómo funciona el
algoritmo EM que entrena este modelo, pero prometí no molestar con fórmulas complejas y, por lo tanto, mostraré hermosos ejemplos de
este artículo.
Generaremos cuatro grupos y los dibujaremos.
from sklearn.datasets.samples_generator import make_blobs X, y_true=make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) plt.scatter(X[:, 0], X[:, 1]);
Crearemos un modelo, entrenaremos sobre nuestros datos y nuevamente dibujaremos los puntos, pero teniendo en cuenta el modelo predicho de membresía de clúster.
from sklearn.mixture import GaussianMixture gmm = GaussianMixture(n_components=4) gmm.fit(X) labels=gmm.predict(X) plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis');
El modelo se las arregló bien con datos artificiales. En principio, al regular el número de componentes de la mezcla y el tipo de matriz de covarianza (el número de grados de libertad de los gaussianos), se pueden describir datos bastante complicados.

Entonces, sabemos cómo parametrizar los datos y podemos entrenar un modelo de una mezcla de distribuciones gaussianas. Ahora se podría tratar de agrupar en la frente: entrenar GMM en el MFCC extraído del diálogo. Y, probablemente, en algún diálogo ideal de vacío esférico, en el que cada hablante se ajuste a su gaussiano, obtendremos un buen resultado. Está claro que en realidad esto nunca sucederá. De hecho, con la ayuda de GMM, no modelan un diálogo, pero cada persona en un diálogo, es decir, imaginan que la voz de cada hablante en los signos extraídos es descrita por su propio conjunto de gaussianos.
Para resumir, estamos llegando lentamente al tema principal.
Segmentación
Tradicionalmente, el proceso de diarización consta de tres bloques consecutivos: detección de voz (detección de actividad de voz), segmentación y agrupamiento (existen modelos en los que se combinan los dos últimos pasos, ver
LIA E-HMM ).
En el primer paso, el habla se separa de varios tipos de ruido. El algoritmo VAD determina si la parte del archivo de audio que se le envía es un discurso o, por ejemplo, si suena una sirena o alguien estornudó. Está claro que para que dicho algoritmo sea de alta calidad, es necesario capacitarse con un maestro. Y esto a su vez significa que necesita marcar los datos; en otras palabras, crear una base de datos con grabaciones de voz y todo tipo de ruido. Lo haremos perezosamente: tome un
VAD ya hecho, que no funciona perfectamente, pero para empezar tenemos suficiente.
El segundo bloque corta los datos de voz en segmentos con un altavoz activo. El enfoque clásico a este respecto es el algoritmo para determinar el cambio del hablante basado en el criterio de información bayesiano -
BIC . La esencia de este método es la siguiente: una ventana deslizante pasa a través de las grabaciones de audio y en cada punto del pasaje responden la pregunta: "¿Cómo se describen mejor los datos en este lugar? ¿Una distribución o dos?" Para responder a esta pregunta, se calcula el parámetro
, según el signo de que se toma la decisión de cambiar el hablante. El problema es que este método no funcionará muy bien en caso de cambios frecuentes de los altavoces, e incluso en presencia de ruido (que son muy característicos para grabar una conversación telefónica).
Una pequeña explicacionEn el original, trabajé con grabaciones telefónicas de un centro de llamadas con una duración promedio de aproximadamente 4 minutos. Por razones obvias, no puedo publicar estas notas, así que para la demostración tomé
una entrevista de una estación de radio. En el caso de una entrevista larga, este método probablemente daría un resultado aceptable, pero no funcionó en mis datos.
En las condiciones en que los locutores no se interrumpen entre sí y sus voces no se superponen, el VAD que utilizaremos más o menos hace frente a la tarea de segmentación, por lo tanto, los dos primeros pasos se verán así.
En realidad, la gente ciertamente hablará simultáneamente. Además, el VAD en algunos lugares se ha equivocado debido al hecho de que el registro no está vivo, sino que es un encolado en el que se cortan las pausas. Puede intentar repetir el corte en segmentos, aumentando la agresividad del VAD de 2 a 3.
GMM-UBM
Ahora tenemos segmentos separados, y decidimos que modelaríamos cada altavoz usando GMM. Extraemos los signos del segmento y sobre estos datos entrenamos el modelo. Hagámoslo en cada segmento y comparemos los modelos resultantes entre sí. Es justificable esperar que los modelos entrenados en segmentos pertenecientes a la misma persona sean algo similares. Pero aquí nos enfrentamos con el siguiente problema, extrayendo signos de un archivo de audio de 1 segundo de largo con una frecuencia de muestreo de 8000 Hz con un tamaño de ventana de 10 ms, obtenemos un conjunto de 800 vectores MFCC. Nuestro modelo no podrá aprender de tales datos, porque es insignificante. Incluso si no es un segundo, sino diez, los datos aún no serán suficientes. Y aquí el Universal Background Model (UBM) viene al rescate, también se llama independiente del hablante. La idea es la siguiente. Entrenaremos GMM en una muestra de datos de gran tamaño (en nuestro caso, esta es una grabación completa de la entrevista) y obtendremos un modelo acústico de un orador generalizado (esta será nuestra UBM). Y luego, utilizando un algoritmo de adaptación especial (sobre esto más adelante), "ajustaremos" este modelo a las características extraídas de cada segmento. Este enfoque es ampliamente utilizado no solo para la diarización, sino también en los sistemas de reconocimiento de voz. Para reconocer a una persona por voz, primero debe entrenar a un modelo y, sin UBM, debería tener varias horas de grabación del discurso de esta persona.
De cada GMM adaptado, extraemos el vector de coeficientes de corte
(también es una expectativa de mediana o mat., si lo desea) y, según los datos de estos vectores de todos los segmentos, haremos un agrupamiento (a continuación, quedará claro por qué es el vector de desplazamiento).
Adaptación del mapa
El método mediante el cual personalizaremos UBM para cada segmento se llama Adaptación máxima A-posteriori. En general, el algoritmo es el siguiente. Primero, la probabilidad posterior se calcula sobre los datos de adaptación y
las estadísticas suficientes para el peso, la mediana y la varianza de cada gaussiano. Luego, las estadísticas obtenidas se combinan con los parámetros UBM y se obtienen los parámetros del modelo adaptado. En nuestro caso, adaptaremos solo las medianas, sin afectar el resto de los parámetros. A pesar del hecho de que prometí no profundizar en las matemáticas, citaré tres fórmulas después de todo, porque la adaptación MAP es el punto clave en este artículo.
Aqui
- probabilidad posterior,
- estadísticas suficientes para
,
- mediana del modelo adaptado,
- coeficiente de adaptación,
- factor de cumplimiento.
Si todo esto parece absurdo y causa desánimo, no se desespere. De hecho, para comprender el funcionamiento del algoritmo, no es necesario profundizar en estas fórmulas; su funcionamiento se puede demostrar fácilmente con el siguiente ejemplo:
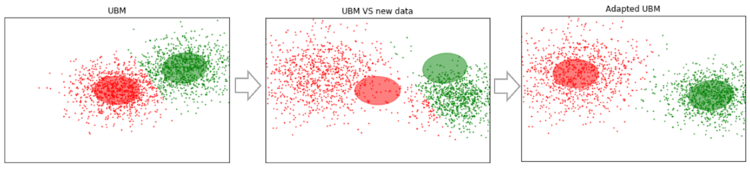
Supongamos que tenemos algunos datos lo suficientemente grandes y capacitamos a UBM en ellos (imagen de la izquierda, UBM es una mezcla de dos componentes de distribuciones gaussianas). Aparecen nuevos datos que no se ajustan a nuestro modelo (figura en el medio). Usando este algoritmo, desplazaremos los centros de los gaussianos para que se encuentren en los nuevos datos (figura a la derecha). Aplicando este algoritmo a los datos experimentales, esperaremos que en segmentos con el mismo altavoz los gaussianos se desplacen en una dirección, formando así grupos. Es por eso que usaremos datos de corte para agrupar segmentos
.
Entonces, hagamos la adaptación MAP para cada segmento. (Como referencia: además de la adaptación MAP, el método MLLR - Regresión lineal de máxima verosimilitud y algunas de sus modificaciones son ampliamente utilizadas. También intentan combinar estos dos métodos).
SV = []
Ahora que para cada segmento tenemos datos sobre
, finalmente pasamos al paso final.
Agrupación espectral
La agrupación espectral se describe brevemente en el artículo, un enlace al que di al principio. El algoritmo construye un gráfico completo, donde los vértices son nuestros datos, y los bordes entre ellos son una medida de similitud. En las tareas de reconocimiento de voz, se utiliza una métrica del coseno como tal medida, ya que tiene en cuenta el ángulo entre los vectores, ignorando su magnitud (que no lleva información sobre el hablante). Al construir el gráfico, se calculan los vectores propios de la matriz de Kirchhoff (que es esencialmente una representación del gráfico resultante) y luego se utiliza algún método de agrupamiento estándar, por ejemplo, el método de k-medias. Todo cabe en dos líneas de código.
N_CLUSTERS = 2 sc = SpectralClustering(n_clusters=N_CLUSTERS, affinity='cosine') labels = sc.fit_predict(SV)
Conclusiones y planes futuros
El algoritmo descrito ha sido probado con varios parámetros:
- Número MFCC: 7, 13, 20
- MFCC en combinación con LPC
- Tipo y número de mezclas en GMM: completo [8, 16, 32], diag [8, 16, 32, 64, 256]
- Métodos de adaptación UBM: MAP (con covariance_type = 'full') y MLLR (con covariance_type = 'diag')
Como resultado, los parámetros permanecieron subjetivamente óptimos: MFCC 13, GMM covariance_type = 'full' n_components = 16.
Desafortunadamente, no tuve la paciencia (comencé a escribir este artículo hace más de un mes) para marcar los segmentos recibidos y calcular DER (tasa de error de diarrea). Subjetivamente, evalúo el funcionamiento del algoritmo como "en principio, no está mal, pero está lejos de ser ideal". Al agrupar en vectores obtenidos de los primeros cien segmentos (con un pase de MAP), y luego seleccionar aquellos donde el entrevistador dice (niña, ella habla mucho menos que el invitado allí), el agrupamiento da una lista
eso es 100% de éxito. Al mismo tiempo, los segmentos donde ambos altavoces están presentes (por ejemplo, 14) se desconectan, pero esto ya puede atribuirse al error VAD. Además, dichos segmentos comienzan a tenerse en cuenta con un aumento en el número de pases MAP. Un punto importante La entrevista con la que trabajamos es más o menos "limpia". Si se agregan varias inserciones musicales, ruidos y otras cosas no verbales, la agrupación comienza a cojear. Por lo tanto, hay planes para tratar de entrenar nuestro propio VAD (porque webrtcvad, por ejemplo, no separa la música del habla).
Debido al hecho de que inicialmente trabajé con una conversación telefónica, no necesitaba estimar la cantidad de hablantes. Pero el número de oradores no siempre está predeterminado, incluso si se trata de una entrevista. Por ejemplo, en
esta entrevista en el medio hay un anuncio superpuesto en la música y expresado por dos personas adicionales. Por lo tanto, sería interesante probar el método para estimar el número de hablantes especificado en el primer artículo en la sección de la lista de referencias (basado en un análisis de los valores propios de la matriz de Laplace normalizada).
Referencias
Además de los materiales ubicados en los enlaces en el texto y las computadoras portátiles Jupyter, se utilizaron las siguientes fuentes para preparar este artículo:
- Diarización de altavoces usando GMM Supervector y algoritmos de reducción avanzada. Nurit Spingarn
- Métodos de extracción de características LPC, PLP y MFCC en reconocimiento de voz. Namrata dave
- Evaluación de MAP para observaciones de mezcla gaussiana mulivariada de cadenas de markov. Jean-Luc Gauvain y Chin-Hui Lee
- Sobre análisis de agrupamiento espectral y un algoritmo. Andrew Y. Ng, Michael I. Jordan, Yair Weiss
- Reconocimiento de oradores utilizando el modelo de fondo universal en la base de datos YOHO Alexandre Majetniak
También agregaré algunos proyectos de diarización:
- Sidekit y extensión de diarización s4d . Una biblioteca de python para trabajar con el habla. Lamentablemente, la documentación es pobre.
- Bob y sus diversas partes, como bob.bio , bob.learn.em , una biblioteca de python para procesar señales y trabajar con datos biométricos. Windows no es compatible.
- LIUM es una solución llave en mano escrita en Java.
Todo el código se publica en el
github . Por conveniencia, hice varias computadoras portátiles Jupyter con una demostración de ciertas cosas: MFCC, GMM, MAP Adaptation and Diarization. Este último es el proceso principal. También en el repositorio hay archivos de pepinillos con algunos modelos previamente entrenados y la entrevista en sí.