Hola a todos!
Una vez, los clientes me preguntaron si tenía FFT entera en mis proyectos, a lo que siempre respondí que esto
ya lo habían hecho otros en forma de núcleos IP listos para usar, aunque curvos, pero libres (Altera / Xilinx): tómalo y úsalo. Sin embargo, estos núcleos
no son
óptimos , tienen un conjunto de "características" y requieren un mayor refinamiento. En este sentido, después de haber ido a otras vacaciones planificadas, que no quería pasar mediocres, comencé a implementar el kernel configurable del entero FFT.
 KDPV (proceso de depuración de errores de desbordamiento de datos)
KDPV (proceso de depuración de errores de desbordamiento de datos)En el artículo quiero decirle por qué métodos y medios se realizan las operaciones matemáticas al calcular la transformada rápida de Fourier en un formato entero en cristales modernos de FPGA. La base de cualquier FFT es un nodo llamado "mariposa". La mariposa implementa operaciones matemáticas: suma, multiplicación y sustracción. Se trata de la implementación de la "mariposa" y sus nodos terminados que la historia irá primero. Basado en las modernas familias Xilinx FPGA: esta es la serie Ultrascale y Ultrascale +, así como las series más antiguas 6- (Virtex) y 7- (Artix, Kintex, Virtex) se ven afectadas. Las series más antiguas en proyectos modernos no son de interés en 2018. El propósito del artículo es revelar las características de la implementación de núcleos personalizados de procesamiento de señales digitales utilizando el ejemplo de una FFT.
Introduccion
Para nadie es un secreto que los algoritmos para tomar FFT están firmemente arraigados en la vida de los ingenieros de procesamiento de señales digitales y, por lo tanto, esta herramienta se necesita constantemente. Los principales fabricantes de FPGA como Altera / Xilinx ya tienen núcleos FFT / IFFT configurables flexibles, pero tienen una serie de limitaciones y características, y por lo tanto he tenido que usar mi propia experiencia más de una vez. Así que esta vez tuve que implementar una FFT en un formato entero de acuerdo con el esquema Radix-2 en el FPGA. En
mi último artículo, ya hice FFT en formato de coma flotante, y desde allí sabes que el algoritmo con doble paralelismo se usa para implementar el FFT, es decir, el
núcleo puede procesar dos muestras complejas con la misma frecuencia . Esta es una característica clave de FFT que no está disponible en los núcleos preparados de Xilinx FFT.
Ejemplo: se requiere desarrollar un nodo FFT que realice una operación continua del flujo de entrada de números complejos a una frecuencia de 800 MHz. El núcleo de Xilinx no extraerá esto (las frecuencias de reloj de procesamiento alcanzables en los FPGA modernos son del orden de 300-400 MHz), o requerirá diezmar el flujo de entrada de alguna manera. El núcleo personalizado le permite registrar dos muestras de entrada a una frecuencia de 400 MHz sin intervención previa, en lugar de una sola muestra a 800 MHz. Otra
desventaja del núcleo Xilinx FFT es la incapacidad de aceptar el flujo de entrada en orden de inversión de bits . En este sentido, se gasta un enorme recurso de memoria de chip FPGA para reorganizar los datos en un orden normal. Para tareas de convolución rápida de señales, cuando dos nodos FFT se encuentran uno detrás del otro, esto puede convertirse en un momento crítico, es decir, la tarea simplemente no estará en el chip FPGA seleccionado. El núcleo FFT personalizado le permite recibir datos en el orden normal en la entrada y emitirlos en modo bit-reverse, mientras que el núcleo del FFT inverso, por el contrario, recibe datos en orden bit-reverse y los emite en modo normal. ¡Se guardan dos memorias intermedias para la permutación de datos a la vez!
Como la mayor parte del material de este artículo podría
superponerse con el anterior , decidí centrarme en el tema de las operaciones matemáticas en formato entero en FPGA para la implementación de FFT.
Parámetros del kernel FFT
- NFFT - número de mariposas (longitud FFT),
- DATA_WIDTH : profundidad de bits de los datos de entrada (4-32),
- TWDL_WIDTH : profundidad de bits de los factores de giro (8-27).
- SERIE : define la familia FPGA en la que se implementa el FFT ("NUEVO" - Ultrascale, "OLD" - 6/7 Xilinx FPGA series).
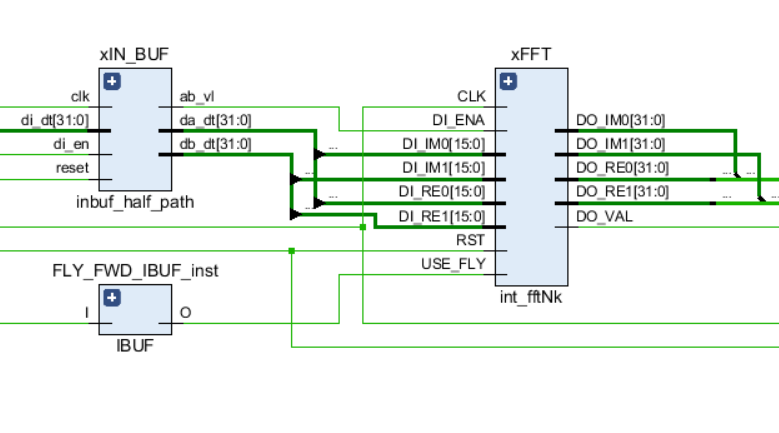
Al igual que cualquier otro enlace en el circuito, el FFT tiene puertos de control de entrada: una señal de reloj y un reinicio, así como puertos de datos de entrada y salida. Además, la señal USE_FLY se usa en el núcleo, lo que le permite desactivar dinámicamente las mariposas FFT para los procesos de depuración o para ver la secuencia de entrada original.
La siguiente tabla muestra la cantidad de recursos FPGA utilizados, dependiendo de la longitud de la NFFT FFT para DATA_WIDTH = 16 y dos bits TWDL_WIDTH = 16 y 24 bits.

El núcleo en NFFT = 64K es estable a la frecuencia de procesamiento
FREQ = 375 MHz en un cristal Kintex-7 (410T).
Estructura del proyecto
El gráfico esquemático del nodo FFT se muestra en la siguiente figura:

Para la conveniencia de comprender las características de ciertos componentes, daré una lista de archivos de proyecto y su breve descripción en un orden jerárquico:
- Granos FFT:
- int_fftNk - nodo FFT, circuito Radix-2, decimación de frecuencia (DIF), el flujo de entrada es normal, el flujo de salida es bit-reverse.
- int_ifftNk : nodo OBPF , circuito Radix-2, decimación de tiempo (DIT), el flujo de entrada es de inversión de bits, el flujo de salida es normal.
- Mariposas
- int_dif2_fly - mariposa Radix-2, diezmado en frecuencia,
- int_dit2_fly - mariposa Radix-2, diezmado en el tiempo,
- Multiplicadores complejos:
- int_cmult_dsp48 - multiplicador configurable general, incluye:
- int_cmult18x25_dsp48 : multiplicador para pequeñas profundidades de bits de los datos y factores de rotación,
- int_cmult_dbl18_dsp48 - multiplicador duplicado, ancho de bit de los factores de giro hasta 18 bits,
- int_cmult_dbl35_dsp48 - multiplicador duplicado, ancho de bits de los factores de rotación de hasta 25 * bits,
- int_cmult_trpl18_dsp48 - multiplicador triple, la capacidad de los factores de giro de hasta 18 bits,
- int_cmult_trpl52_dsp48 - multiplicador triple, la capacidad de los factores de rotación de hasta 25 * bits,
- Multiplicadores
- mlt42x18_dsp48e1 : un multiplicador con bits de operandos de hasta 42 y 18 bits basado en DSP48E1,
- mlt59x18_dsp48e1 : multiplicador con bits de operando de hasta 59 y 18 bits basados en DSP48E1,
- mlt35x25_dsp48e1 : un multiplicador con bits de operandos de hasta 35 y 25 bits basado en DSP48E1,
- mlt52x25_dsp48e1 : un multiplicador con bits de operandos de hasta 52 y 25 bits basado en DSP48E1,
- mlt44x18_dsp48e2 : multiplicador con bits de operandos de hasta 44 y 18 bits basados en DSP48E2,
- mlt61x18_dsp48e2 : multiplicador con bits de operando de hasta 61 y 18 bits basados en DSP48E2,
- mlt35x27_dsp48e2 : multiplicador con bits de operando de hasta 35 y 27 bits basados en DSP48E2,
- mlt52x27_dsp48e2 es un multiplicador con bits de operando de hasta 52 y 27 bits basado en DSP48E2.
- Totalizador:
- int_addsub_dsp48 - sumador universal, bits de operando de hasta 96 bits.
- Líneas de retraso:
- int_delay_line : la línea de base de la demora, proporciona una permutación de datos entre mariposas,
- int_align_fft : alineación de los datos de entrada y los factores de giro en la entrada de la mariposa FFT,
- int_align_fft : alineación de los datos de entrada y los factores de giro en la entrada de la mariposa OBPF ,
- Factores rotativos:
- rom_twiddle_int : un generador de factores rotativos, a partir de una cierta longitud, la FFT considera coeficientes basados en celdas FPGA DSP,
- row_twiddle_tay - generador de factores rotativos usando una serie Taylor (NFFT> 2K) **.
- Búfer de datos:
- inbuf_half_path - buffer de entrada, recibe el flujo en el modo normal y produce dos secuencias de muestras desplazadas a la mitad de la longitud del FFT ***,
- outbuf_half_path : el búfer de salida, recopila dos secuencias y produce una continua igual a la longitud de la FFT,
- iobuf_flow_int2 : el búfer funciona en dos modos: recibe un flujo en modo Intercalación-2 y produce dos secuencias de FFT desplazadas a la mitad de la longitud. O viceversa, dependiendo de la opción BITREV.
- int_bitrev_ord es un simple convertidor de datos de orden natural a bit-reverse.
* - para DSP48E1: 25 bits, para DSP48E2 - 27 bits.** - a partir de una determinada etapa de la FFT, se puede usar una cantidad fija de memoria de bloque para almacenar coeficientes de rotación, y se pueden calcular coeficientes intermedios utilizando nodos DSP48 usando la fórmula de Taylor para la primera derivada. Debido al hecho de que el recurso de memoria es más importante para la FFT, puede sacrificar de forma segura las unidades informáticas por el bien de la memoria.
*** - buffer de entrada y líneas de retardo - hacen una contribución significativa a la cantidad de recursos de memoria FPGA ocupadosMariposaTodos los que han encontrado al menos una vez el algoritmo de transformación rápida de Fourier saben que este algoritmo se basa en una operación elemental: una "mariposa". Convierte el flujo de entrada multiplicando la entrada por el factor twiddle. Existen dos esquemas de conversión clásicos para FFT: diezmado en frecuencia (DIF, diezmado en frecuencia) y diezmado en tiempo (DIT, diezmado en tiempo). El algoritmo DIT se caracteriza por dividir la secuencia de entrada en dos secuencias de media duración, y el algoritmo DIF en dos secuencias de muestras pares e impares de duración NFFT. Además, estos algoritmos difieren en operaciones matemáticas para la operación de mariposa.
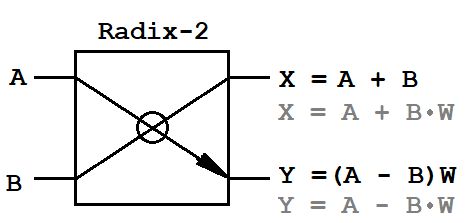 A, B
A, B - pares de entrada de muestras complejas,
X, Y - pares de salida de muestras complejas,
W - factores de giro complejos.
Dado que los datos de entrada son cantidades complejas, la mariposa requiere un multiplicador complejo (4 operaciones de multiplicación y 2 operaciones de suma) y dos sumadores complejos (4 operaciones de suma). Esta es toda la base matemática que debe implementarse en el FPGA.
Multiplicador
Cabe señalar que todas las operaciones matemáticas en FPGA a menudo se realizan en código adicional (complemento de 2). El multiplicador de FPGA se puede implementar de dos maneras: en la lógica usando disparadores y tablas LUT, o en unidades especiales de cálculo DSP48, que se han incluido larga y firmemente en todos los FPGA modernos. En los bloques lógicos, la multiplicación se implementa utilizando el algoritmo Booth o sus modificaciones, ocupa una cantidad decente de recursos lógicos y no siempre satisface las limitaciones de tiempo a altas frecuencias de procesamiento de datos. En este sentido, los multiplicadores de FPGA en proyectos modernos casi siempre se diseñan en base a nodos DSP48 y solo ocasionalmente en lógica. Un nodo DSP48 es una celda terminada compleja que implementa funciones matemáticas y lógicas. Operaciones básicas: multiplicación, suma, resta, acumulación, contador, operaciones lógicas (XOR, NAND, AND, OR, NOR), cuadratura, comparación de números, desplazamiento, etc. La siguiente figura muestra la celda DSP48E2 para la familia Xilinx Ultrascale + FPGA.

Mediante una configuración simple de los puertos de entrada, operaciones de cálculo en los nodos y la configuración de retrasos dentro del nodo, puede hacer una trilladora de datos matemáticos de alta velocidad.
Tenga en cuenta que todos los principales proveedores de FPGA en el entorno de desarrollo tienen núcleos IP estándar y gratuitos para calcular funciones matemáticas basadas en el nodo DSP48. Le permiten calcular funciones matemáticas primitivas y establecer varios retrasos en la entrada y salida del nodo. Para Xilinx, este es el "multiplicador" IP-Core (ver. 12.0, 2018), que le permite configurar el multiplicador a cualquier profundidad de bits de datos de entrada de 2 a 64 bits. Además, puede especificar cómo se implementa el multiplicador: en recursos lógicos o en primitivas DSP48 incorporadas.
Calcule cuánta lógica "come" el multiplicador con la profundidad de bits de los datos de entrada en los puertos A y B = 64 bits. Si usa los nodos DSP48, necesitarán solo 16.

La principal limitación en las celdas DSP48 es la profundidad de bits de los datos de entrada. El nodo DSP48E1, que es la celda base de las series FPGA Xilinx 6 y 7, el ancho de los puertos de entrada para la multiplicación: "A" - 25 bits, "B" - 18 bits, por lo tanto, el resultado de la multiplicación es un número de 43 bits. Para la familia Xilinx Ultrascale y Ultrascale + FPGA, el nodo ha sufrido varios cambios, en particular, la capacidad del primer puerto aumentó en dos bits: "A" - 27 bits, "B" - 18 - bits. Además, el nodo en sí se llama DSP48E2.
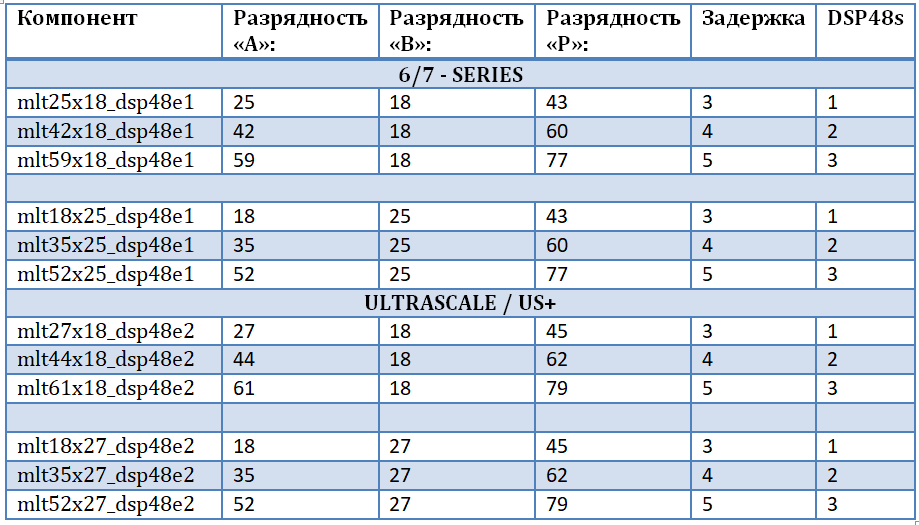
Para no estar vinculado a una familia específica y un chip FPGA, para garantizar la "pureza del código fuente", y para tener en cuenta todas las profundidades de bits posibles de los datos de entrada, se decidió diseñar nuestro propio conjunto de multiplicadores. Esto permitirá la implementación más eficiente de multiplicadores complejos para mariposas FFT, a saber, multiplicadores y un sumador-sustractor basado en bloques DSP48. La primera entrada del multiplicador son los datos de entrada, la segunda entrada del multiplicador son los factores de rotación (señal armónica de la memoria). Se implementa un conjunto de multiplicadores utilizando la biblioteca UNISIM incorporada, desde la cual es necesario conectar las primitivas DSP48E1 y DSP48E2 para su uso posterior en el proyecto. Un conjunto de multiplicadores se presenta en la tabla. Cabe señalar que:
- La operación de multiplicar números conduce a un aumento en la capacidad del producto como la suma de la capacidad de los operandos.
- De hecho, cada uno de los multiplicadores 25x18 y 27x18 está duplicado: este es un componente para diferentes familias.
- Cuanto mayor es la etapa de paralelismo de la operación, mayor es el retraso en la computación y mayor es la cantidad de recursos ocupados.
- Con una profundidad de bits más baja en la entrada "B", se pueden implementar multiplicadores con una profundidad de bits más alta en otra entrada.
- La principal limitación para aumentar la profundidad de bits se introduce por el puerto "B" (el puerto real de la primitiva DSP48) y el registro de desplazamiento interno por 17 bits.
Un aumento adicional en la profundidad de bits no es de interés en el marco de la tarea por las razones que se describen a continuación:
Profundidad de bits de los factores de giro
Se sabe que cuanto mayor es la resolución de la señal armónica, más exactamente aparece el número (más signos en la parte fraccional). Pero el tamaño del bit de puerto es B <25 bits debido al hecho de que para los factores de rotación en los nodos FFT, esta profundidad de bits es suficiente para garantizar una multiplicación de alta calidad de la secuencia de entrada con elementos de señal armónica en las "mariposas" (para cualquier longitud FFT realísticamente alcanzable en FPGA modernos). El valor típico de la profundidad de bits de los coeficientes de giro en las tareas que estoy implementando es 16 bits, 24, con menos frecuencia, 32, nunca.
Profundidad de bits de muestras de entrada
La capacidad de estos nodos de recepción y grabación típicos (ADC, DAC) no es grande, de 8 a 16 bits, y rara vez, de 24 o 32 bits. Además, en el último caso, es más eficiente usar el formato de datos de coma flotante de acuerdo con el estándar IEEE-754. Por otro lado, cada etapa de la "mariposa" en la FFT agrega un bit de datos a las muestras de salida debido a operaciones matemáticas. Por ejemplo, para una longitud de NFFT = 1024, se utiliza log2 (NFFT) = 10 mariposas.
Por lo tanto, la profundidad de bits de salida será diez bits mayor que la entrada, WOUT = WIN + 10. En general, la fórmula se ve así:
WOUT = WIN + log2 (NFFT);
Un ejemplo:
Profundidad de bits del flujo de entrada WIN = 32 bits,
Profundidad de bits de los factores de giro TWD = 27,
La capacidad del puerto "A" de la lista de multiplicadores implementados en este artículo no supera los 52 bits. Esto significa que el número máximo de mariposas es FFT = 52-32 = 20. Es decir, es posible realizar FFT con una longitud de hasta 2 ^ 20 = 1M de muestras. (Sin embargo, en la práctica, esto no es posible por medios directos debido a los recursos limitados incluso para los cristales FPGA más potentes, pero esto se relaciona con otro tema y no será considerado en el artículo).
Como puede ver, esta es una de las razones principales por las que no implementé multiplicadores con mayor profundidad de bits de puertos de entrada.
Los multiplicadores utilizados cubren el rango completo de los tamaños de
bits de entrada
requeridos y los factores de rotación para la tarea de calcular el FFT entero. ¡En todos los demás casos, puede usar el cálculo
FFT en formato de punto flotante !
La implementación del multiplicador "ancho"
Basado en un ejemplo simple de multiplicar dos números que no encajan en la profundidad de bits de un nodo DSP48 estándar, mostraré cómo puede implementar un multiplicador de datos amplio. La siguiente figura muestra su diagrama de bloques. El multiplicador implementa la multiplicación de dos números con signo en el código adicional, el ancho del primer operando X es de 42 bits, el segundo Y es de 18 bits. Contiene dos nodos DSP48E2. Se utilizan dos registros para igualar los retrasos en el nodo superior. Esto se hace porque en el sumador superior necesita agregar correctamente los números de los nodos superior e inferior del DSP48. El sumador inferior no se usa realmente. En la salida del nodo inferior hay un retraso adicional del producto para alinear el número de salida con el tiempo. El retraso total es de 4 ciclos.

El trabajo consta de dos componentes:
- La parte más joven: P1 = '0' y X [16: 0] * Y [17: 0];
- La parte anterior: P2 = X [42:17] * Y [17: 0] + (P1 >> 17);
Totalizador
Al igual que un multiplicador, un sumador puede construirse sobre recursos lógicos utilizando una cadena de transferencia o en bloques DSP48. Para lograr el máximo rendimiento, es preferible un segundo método. Una primitiva DSP48 permite implementar la operación de adición hasta 48 bits, dos nodos hasta 96 bits. Para la tarea actual, tales profundidades de bits son suficientes. Además, la primitiva DSP48 tiene un modo especial "MODO SIMD", que paraleliza la ALU incorporada de 48 bits en varias operaciones con diferentes datos de pequeña capacidad. Es decir, en el modo "UNO" se utiliza una cuadrícula de bits completa de 48 bits y dos operandos, y en el modo "DOS" la cuadrícula de bits se divide en varios flujos paralelos de 24 bits cada uno (4 operandos). Este modo, que usa solo un sumador, ayuda a reducir la cantidad de recursos de chip FPGA ocupados a pequeñas profundidades de bits de muestras de entrada (en las primeras etapas de cálculo).
Incremento de profundidad de bits
La operación de
multiplicar dos números con los bits N y M en un código adicional binario conduce a un aumento en la capacidad del bit de salida a
P = N + M.Ejemplo: para multiplicar números de tres bits N = M = 3, el número positivo máximo es +3 =
(011) 2 , y el número negativo máximo es 4 =
(100) 2 . El bit más significativo es responsable del signo del número. Por lo tanto, el número máximo posible al multiplicar es +16 =
(010000) 2 , que se forma como resultado de multiplicar dos números negativos máximos -4. La profundidad de bits de la salida es igual a la suma de los bits de entrada P = N + M = 6 bits.
La operación de
agregar dos números con los bits N y M en el código adicional binario conduce a un aumento en el bit de salida en un bit.
Ejemplo: agregue dos números positivos, N = M = 3, el número positivo máximo es 3 =
(011) 2 , y el número negativo máximo es 4 =
(100) 2 .
El bit más significativo es responsable del signo del número. Por lo tanto, el número positivo máximo es 6 = (0110) 2 , y el número negativo máximo es -8 = (1000) 2 . La resolución de la salida aumenta en un bit.Consideración de las características del algoritmo.
:. . , 16- -32768 = 0x8000, -32767 = 0x8001.
~0.003% .
, . : – 4 = (100)
2 , +3 = (011)
2. Resultado de multiplicación = -12 = (110100) 2 . El quinto bit se puede descartar porque duplica el vecino, el cuarto es un bit de signo.Truncamiento de bits desde abajo:, «» , , . M- , , . 0x8000 = -1, 0x7FFF = +1. , ( M ). , , 1 . , [N+M-1-1: M-1]. ( 1), – .
/ «»
.
Tenga en cuenta que en la primera etapa del algoritmo FFT DIT o en la última etapa del algoritmo FFT DIF, los datos deben multiplicarse por un factor de giro con un índice cero W0 = {Re, Im} = {1, 0}. Debido al hecho de que la multiplicación por unidad y cero son operaciones primitivas, se pueden omitir. En este caso, la operación de multiplicación compleja no es necesaria en absoluto: los componentes reales e imaginarios experimentan un "giro" sin cambios. En la segunda etapa, se utilizan dos coeficientes: W0 = {Re, Im} = {1, 0} y W1 = {Re, Im} = {0, -1}. Del mismo modo, las operaciones se pueden reducir a transformaciones elementales y utilizar un multiplexor para seleccionar la muestra de salida. Esto le permite guardar significativamente los bloques DSP48 en las dos primeras mariposas.– -, , .
- , . . — — .
INT_FFTK
- .
- NFFT = 8-512K .
- NFFT.
- , .
- , .
- .
- !
- .
- : – , -.
- : - , – .
- . Radix-2.
- NFFT *.
- .
- (Virtex-6, 7-Series, Ultrascale).
- ~375MHz Kintex-7
- – VHDL.
- bitreverse +.
- Proyecto de código abierto sin la inclusión de núcleos IP de terceros.
Código fuente
El código fuente para el núcleo FFT INTFFTK en VHDL (incluidas las operaciones básicas y un conjunto de multiplicadores) y los scripts m para Matlab / Octave están disponibles en mi perfil de github .Conclusión
Durante el desarrollo, se diseñó un nuevo núcleo FFT, que proporciona un mayor rendimiento en comparación con sus pares. La combinación de núcleos FFT y OBPF no requiere traducción al orden natural, y la longitud máxima de conversión está limitada solo por los recursos FPGA. La doble concurrencia le permite procesar flujos de entrada de doble frecuencia, lo que Xilinx de IP-CORE no puede hacer. La profundidad de bits en la salida del entero FFT aumenta linealmente según el número de etapas de conversión.: Radix-4, Radix-8, Ultra-Long FFT , FFT-FP32 ( IEEE-754). , , . FFT Radix-8, ( ).
dsmv2014 , . Gracias por su atencion!
UPDATE 2018/08/22
SCALED FFT / IFFT . 1 (truncate LSB). = .
, , : . , - .
: — 6 . — 128 . NFFT = 1024 , DATA_WIDTH = 16, TWDL_WIDTH = 16.
Fig. 1 - : Fig. 2 - :
Fig. 2 - :
- — UNSCALED FFT,
- — SCALED FFT.
, SCALED « » , UNSCALED .