SDSM-15. Sobre QoS Ahora con posibilidad de
solicitudes de
extracción .
Y así llegamos al tema de QoS.
¿Sabes por qué solo ahora y por qué será el artículo de cierre de todo el curso SDSM? Porque QoS es inusualmente complejo. Lo más difícil que había antes en el ciclo.
Este no es un tipo de archivador mágico que comprime inteligentemente el tráfico sobre la marcha y empuja su gigabit a un enlace ascendente de cien megabits. QoS se trata de cómo sacrificar algo innecesario, empujando lo no comestible al marco de lo permisible.
QoS está tan enredado con el aura del chamanismo y la inaccesibilidad que todos los ingenieros jóvenes (y no solo) intentan ignorar cuidadosamente su existencia, creyendo que es suficiente para generar problemas con el dinero y expandir los vínculos sin fin. Es cierto, hasta que se den cuenta de que con este enfoque, el fracaso inevitablemente les esperará. O el negocio comenzará a hacer preguntas incómodas, o habrá muchos problemas que casi no están relacionados con el ancho del canal, sino que dependen directamente de la eficiencia de su uso. Sí, VoIP agita activamente un bolígrafo detrás de escena, y el tráfico de multidifusión te acaricia maliciosamente en la espalda.
Por lo tanto, vamos a darnos cuenta de que QoS es obligatorio, tendrá que saberlo de una forma u otra, y por alguna razón, no comience ahora, en un ambiente relajado.

Contenido
1.
¿Qué determina la QoS?- Pérdida
- Retrasos
- Nerviosismo
2.
Tres modelos de QoS- Mejores efectos
- Servicios integrados
- Servicios diferenciados
3.
Mecanismos DiffServ4.
Clasificación y etiquetado.- Agregación de comportamiento
- Campo múltiple
- Basado en la interfaz
5.
Colas6.
Evitar la congestión- Tail Drop y Head Drop
- Rojo
- Wred
7.
Manejo de la congestión- Primero adentro, primero afuera
- Cola prioritaria
- Colas justas
- Round robin
8.
Límite de velocidad- Dar forma
- Vigilancia
- Cubo con fugas y cubo de fichas
9.
Implementación de hardware de QoS
Antes de que el lector se sumerja en este agujero, estableceré tres configuraciones en él:
- No todos los problemas se pueden resolver expandiendo la banda.
- QoS no expande la banda.
- QoS sobre la gestión de recursos limitados.
1. ¿Qué determina la QoS?
El negocio espera que la pila de red realice su función simple bien: entregar un flujo de bits de un host a otro: sin pérdidas y en un tiempo predecible.
De esta breve oración, se pueden derivar todas las métricas de calidad de red:
- Pérdida
- Retrasos
- Nerviosismo
Estas tres características determinan la
calidad de la red independientemente de su naturaleza: paquete, canal, IP, MPLS, radio,
palomas .
Pérdida
Esta métrica le indica cuántos paquetes enviados por la fuente llegaron al destino.
La causa de la pérdida puede ser un problema en la interfaz / cable, congestión de red, errores de bit que bloquean las reglas de ACL.
La aplicación decide qué hacer en caso de pérdida. Puede ignorarlos, como en el caso de una conversación telefónica, donde ya no se necesita un paquete tardío, o reenviarlo; esto es lo que hace TCP para garantizar la entrega precisa de los datos de origen.

Cómo gestionar las pérdidas, si son inevitables, en el capítulo Gestión de la congestión.
Cómo aprovechar las pérdidas en el capítulo Prevención de la congestión.
Retrasos
Este es el tiempo que necesitan los datos para llegar desde el origen al destino.

El retraso acumulativo consta de los siguientes componentes.
- Retardo de serialización : el tiempo que tarda un nodo en descomponer un paquete en bits y poner un enlace al siguiente nodo. Está determinado por la velocidad de la interfaz. Entonces, por ejemplo, transferir un paquete de 1500 bytes de tamaño a través de una interfaz de 100 Mb / s tomará 0.0001 s, y para 56 Kb / s - 0.2 s.
- El retraso de propagación es el resultado de la infame limitación de la velocidad de propagación de las ondas electromagnéticas. La física no le permite llegar de Nueva York a Tomsk en la superficie del planeta más rápido que en 30 ms (de hecho, unos 70 ms).
- Los retrasos introducidos por QoS son la languidez de los paquetes en las colas ( Retardo de cola ) y las consecuencias de la configuración ( Retraso de modelado ). Hablaremos mucho de esto hoy en el capítulo Control de velocidad.
- Retraso en los paquetes de procesamiento ( Retraso de procesamiento ): el tiempo para decidir qué hacer con el paquete: búsqueda, ACL, NAT, DPI, y entregarlo desde la interfaz de entrada a la salida. Pero el día en que Juniper separó el control y el plano de datos en su M40, los retrasos en el procesamiento podrían descuidarse.
Los retrasos no son tan malos para las aplicaciones donde no hay necesidad de apresurarse: compartir archivos, navegar, VoD, estaciones de radio por Internet, etc. Por el contrario, son críticos para los interactivos: 200ms ya es desagradable para los oídos durante una conversación telefónica.
Un término relacionado con la demora que no es sinónimo de
RTT (
Tiempo de ida y vuelta) es el viaje de ida y vuelta. Al hacer ping y rastrear, verá exactamente RTT, y no un retraso unidireccional, aunque los valores tienen una correlación.
Nerviosismo
La diferencia en los retrasos entre la entrega de paquetes consecutivos se llama jitter.
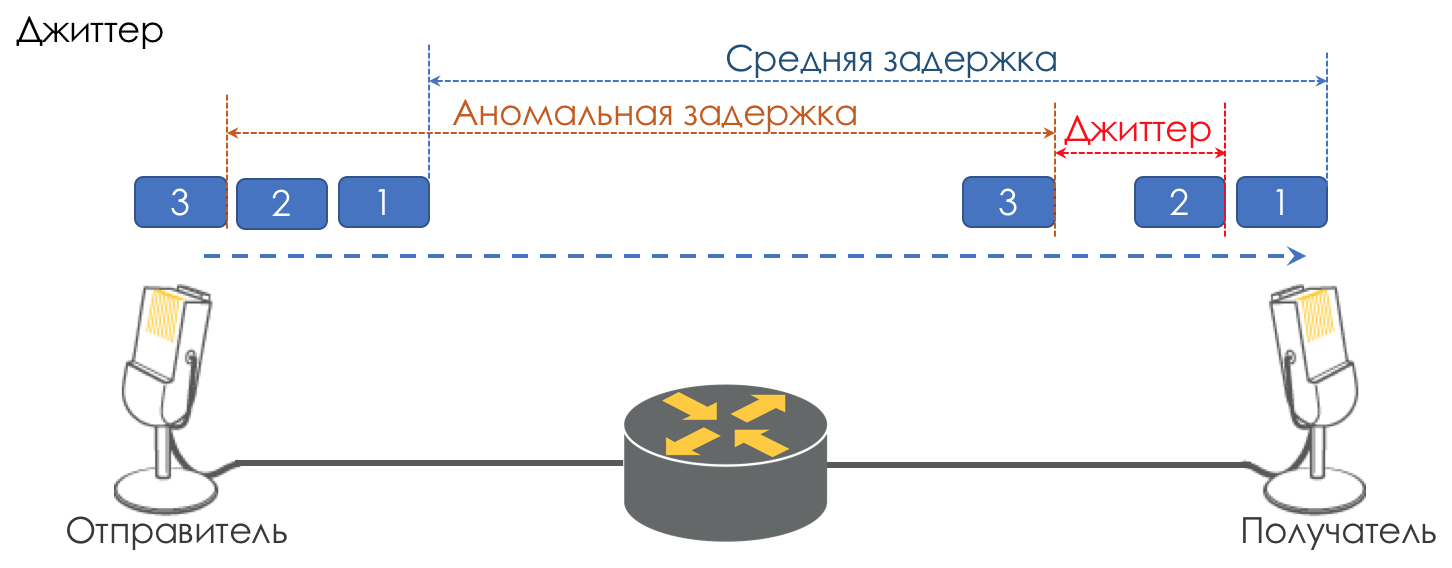
Al igual que la latencia, el jitter no importa para muchas aplicaciones. E incluso, parece, cuál es la diferencia: el paquete se ha entregado, ¿y qué más?
Sin embargo, para los servicios interactivos es importante.
Tome la misma telefonía como ejemplo. De hecho, es una digitalización de señales analógicas con una división en fragmentos de datos separados. La salida es un flujo bastante uniforme de paquetes. En el lado de recepción hay un pequeño búfer de tamaño fijo en el que los paquetes que llegan se ajustan secuencialmente. Para restaurar la señal analógica, es necesario un cierto número de ellas. En condiciones de demoras flotantes, el siguiente fragmento de datos puede no llegar a tiempo, lo que equivale a una pérdida, y la señal no se puede restaurar.
La mayor contribución para retrasar la variabilidad se realiza solo con QoS. Esto también es mucho y tedioso en los mismos capítulos Speed Limit.
Estas son las tres características principales de la calidad de la red, pero hay otras dos que también juegan un papel importante.
Entrega al azar
Varias aplicaciones, como la telefonía,
NAS ,
CES, son extremadamente sensibles a la entrega aleatoria de paquetes cuando llegan al destinatario en el orden incorrecto en el que fueron enviados. Esto puede conducir a la pérdida de conectividad, errores, daños al sistema de archivos.
Aunque la entrega aleatoria no es una característica formal de QoS, definitivamente se refiere a la calidad de la red.
Incluso con TCP tolerante a este tipo de problema, se producen ACK duplicados y retransmisiones.

Ancho de banda
No se distingue como una métrica de la calidad de la red, ya que de hecho su desventaja resulta en las tres anteriores. Sin embargo, en nuestras realidades, cuando debe garantizarse para algunas aplicaciones o, por el contrario, debe estar limitado por contrato, por ejemplo, MPLS TE lo reserva en todo el LSP, vale la pena mencionarlo, al menos como una métrica débil.
Los mecanismos de control de velocidad se analizarán en los capítulos Límite de velocidad.
¿Por qué pueden ir mal las especificaciones?
Entonces, comenzamos con una idea muy primitiva de que un dispositivo de red (ya sea un conmutador, enrutador, firewall, lo que sea) es solo otra pieza de tubería llamada canal de comunicación, lo mismo que un cable de cobre o un cable óptico.

Luego, todos los paquetes vuelan en el mismo orden en que llegaron y no experimentan demoras adicionales: no hay ningún lugar para quedarse.
Pero, de hecho, cada enrutador restaura bits y paquetes de la señal, hace algo con ellos (todavía no lo pensamos) y luego convierte los paquetes nuevamente en una señal.
Aparece un retraso de serialización. Pero en general, esto no da miedo porque es constante. No da miedo, siempre que el ancho de la interfaz de salida sea mayor que la entrada.
Por ejemplo, en la entrada del dispositivo hay un puerto gigabit, y en la salida hay una línea de retransmisión de radio de 620 Mb / s conectada al mismo puerto gigabit.
Nadie prohibirá la viñeta a través del enlace gigabit formalmente tráfico gigabit.
No hay nada que hacer: 380 Mb / s se derramarán en el piso.
Aquí están: pérdidas.
Pero al mismo tiempo, me gustaría mucho que la peor parte se perdiera: un video de youtube, y la conversación telefónica del director ejecutivo con el director de la planta no interrumpió ni llegó a croar.
Me gustaría que la voz tenga una línea dedicada.
O hay cinco interfaces de entrada, pero una salida, y al mismo tiempo, cinco nodos comenzaron a intentar inyectar tráfico a un destinatario.
Agregue una pizca de teoría de VoIP (un artículo sobre el que nadie escribió): es muy sensible a los retrasos y sus variaciones.
Si para una transmisión de video TCP de YouTube (en el momento de escribir el artículo
QUIC , sigue siendo un experimento), los retrasos, incluso en segundos, son completamente inútiles debido al almacenamiento en búfer, entonces el director después de la primera conversación con Kamchatka llamará al jefe del departamento técnico.
En los viejos tiempos, cuando el autor del ciclo todavía hacía su tarea por las tardes, el problema era especialmente grave. Las conexiones de módem tenían una
velocidad de 56k .
Y cuando un paquete de 1.5K entró en dicha conexión, ocupó toda la línea durante 200 ms. Nadie más podría pasar en este momento. Una voz? No, no he escuchado.
Por lo tanto, la pregunta MTU es tan importante: el paquete no debe ocupar la interfaz por mucho tiempo. A menor velocidad, menor MTU es necesaria.
Aquí están, retrasos.
Ahora el canal es gratuito y la demora es baja, después de un segundo alguien comenzó a descargar un archivo grande y las demoras aumentaron. Aquí está, nervioso.
Por lo tanto, es necesario que los paquetes de voz vuelen a través de la tubería con retrasos mínimos, y YouTube esperará.
Los 620 Mb / s disponibles se deben usar para voz y video, y para clientes B2B que compren VPN. Me gustaría que un tráfico no oprima al otro, por lo que necesitamos una garantía de banda.
Todas las características anteriores son universales con respecto a la naturaleza de la red. Sin embargo, hay tres enfoques diferentes para su provisión.
2. Tres modelos de QoS
- El mejor esfuerzo: sin garantía de calidad. Todos son iguales
- IntServ es una garantía de calidad para cada transmisión. Reserva de recursos desde el origen hasta el destino.
- DiffServ - No hay reserva. Cada nodo en sí mismo determina cómo garantizar la calidad adecuada.
Mejor esfuerzo (BE)
Sin garantíasEl enfoque más simple para implementar QoS, a partir del cual las redes IP comenzaron y todavía se practican hasta el día de hoy, a veces porque es suficiente, pero más a menudo porque nadie pensó en QoS.
Por cierto, cuando envía tráfico a Internet, se procesará allí como BestEffort. Por lo tanto, a través de una VPN lanzada por Internet (a diferencia de una VPN proporcionada por el proveedor), el tráfico importante, como una conversación telefónica, puede no ser muy confiable.
En el caso de BE, todas las categorías de tráfico son iguales; no se da preferencia a ninguna. En consecuencia, no hay garantía de retraso / fluctuación o banda.
Este enfoque tiene un nombre algo contradictorio: mejor esfuerzo, que el recién llegado confunde con la palabra "mejor".
Sin embargo, la frase "haré lo mejor que pueda" significa que el orador intentará hacer todo lo que pueda, pero no garantiza nada.
No se requiere nada para implementar BE; este es el comportamiento predeterminado. Es barato de fabricar, el personal no necesita un conocimiento específico profundo, QoS en este caso no se puede personalizar.
Sin embargo, esta simplicidad y estática no conducen al hecho de que el enfoque de Mejor Esfuerzo no se usa en ninguna parte. Encuentra aplicaciones en redes con gran ancho de banda y ausencia de congestión y ráfagas.
Por ejemplo, en líneas transcontinentales o en las redes de algunos centros de datos donde no hay una suscripción excesiva.
En otras palabras, en redes sin congestión y donde no hay necesidad de relacionarse con ningún tráfico (por ejemplo, telefonía) de una manera especial, BE es bastante apropiado.
Interv
Reserva anticipada de recursos para el flujo desde el origen hasta el destino.Los padres de las redes MIT, Xerox e ISI decidieron agregar el elemento de previsibilidad a la creciente Internet fortuita, manteniendo su operatividad y flexibilidad.
Entonces, en 1994, la idea de IntServ nació en respuesta al rápido crecimiento del tráfico en tiempo real y al desarrollo de multidifusión. Luego se redujo a IS.
El nombre refleja el deseo en la misma red de proporcionar servicios simultáneamente para tipos de tráfico en tiempo real y no en tiempo real, proporcionando el derecho de primera prioridad para usar los recursos a través de la reserva de la banda. La capacidad de reutilizar la banda en la que todos ganan dinero, y gracias a la cual se conservó el disparo IP.
La misión de respaldo fue asignada al protocolo RSVP, que para
cada flujo reserva una banda en
cada dispositivo de red.
En términos generales, antes de configurar una sesión Single Rate Three Color MarkerP o comenzar el intercambio de datos, los hosts finales envían la ruta RSVP con el ancho de banda requerido. Y si ambos respondieron RSVP Resv, pueden comenzar a comunicarse. Al mismo tiempo, si no hay recursos disponibles, entonces RSVP devuelve un error y los hosts no pueden comunicarse o seguir BE.
Supongamos ahora que los lectores más valientes imaginen que un canal será señalizado de antemano para
cualquier transmisión en Internet hoy. Teniendo en cuenta que esto requiere costos de CPU y memoria distintos de cero en
cada nodo de tránsito, pospone la interacción real durante algún tiempo, queda claro por qué IntServ resultó ser una idea prácticamente innata: escalabilidad cero.
En cierto sentido, la encarnación moderna de IntServ es MPLS TE con una versión de etiquetado adaptada de RSVP - RSVP TE. Aunque aquí, por supuesto, no es de extremo a extremo y no por flujo.
IntServ se describe en
RFC 1633 .
El documento es, en principio, curioso por evaluar cuán ingenuo puede ser en los pronósticos.
Diffserv
DiffServ es complicado.Cuando se hizo evidente a fines de los años 90 que el enfoque de IP IntServ de extremo a extremo falló, el IETF convocó al grupo de trabajo de Servicios diferenciados en 1997, que desarrolló los siguientes requisitos para el nuevo modelo de QoS:
- Sin señalización (Adjos, RSVP!).
- Basado en clasificación de tráfico agregada, en lugar de centrarse en flujos, clientes, etc.
- Tiene un conjunto de acciones limitado y determinista para procesar el tráfico de datos de clases.
Como resultado, el hito
RFC 2474 (
Definición del campo de servicios diferenciados (campo DS) en los encabezados IPv4 e IPv6 ) y
RFC 2475 (
Una arquitectura para servicios diferenciados ) nacieron en 1998.
Y más adelante solo hablaremos de DiffServ.
Vale la pena señalar que el nombre DiffServ no es la antítesis de IntServ. Refleja que diferenciamos los servicios proporcionados por varias aplicaciones, o más bien su tráfico, en otras palabras, compartimos / diferenciamos estos tipos de tráfico.
IntServ hace lo mismo: distingue entre los tipos de tráfico BE y Real-Time, transmitidos en la misma red. Ambos: e IntServ y DiffServ: se refieren a formas de diferenciar los servicios.
3. Mecanismos DiffServ
¿Qué es DiffServ y por qué supera a IntServ?
Si es muy simple, el tráfico se divide en clases. Se clasifica un paquete en la entrada de cada nodo y se le aplica un conjunto de herramientas, que procesa paquetes de diferentes clases de diferentes maneras, proporcionándoles un nivel de servicio diferente.
Pero simplemente
no lo será .
En el corazón de DiffServ está el concepto de IP IP
PHB idealmente experimentado
: comportamiento por salto . Cada nodo en la ruta de tráfico de forma independiente toma una decisión sobre cómo comportarse en relación con el paquete entrante, en función de sus encabezados.
Las acciones del enrutador de paquetes se denominarán modelo de comportamiento. El número de tales modelos es determinista y limitado. En diferentes dispositivos, los modelos de comportamiento con respecto al mismo tráfico
pueden diferir, por lo tanto, son por salto.
Los conceptos de comportamiento y PHB que usaré en el artículo como sinónimos.Hay una ligera confusión. PHB es, por un lado, el concepto general de comportamiento independiente de cada nodo, y por otro, un modelo específico en un nodo particular. Con esto lo resolveremos.

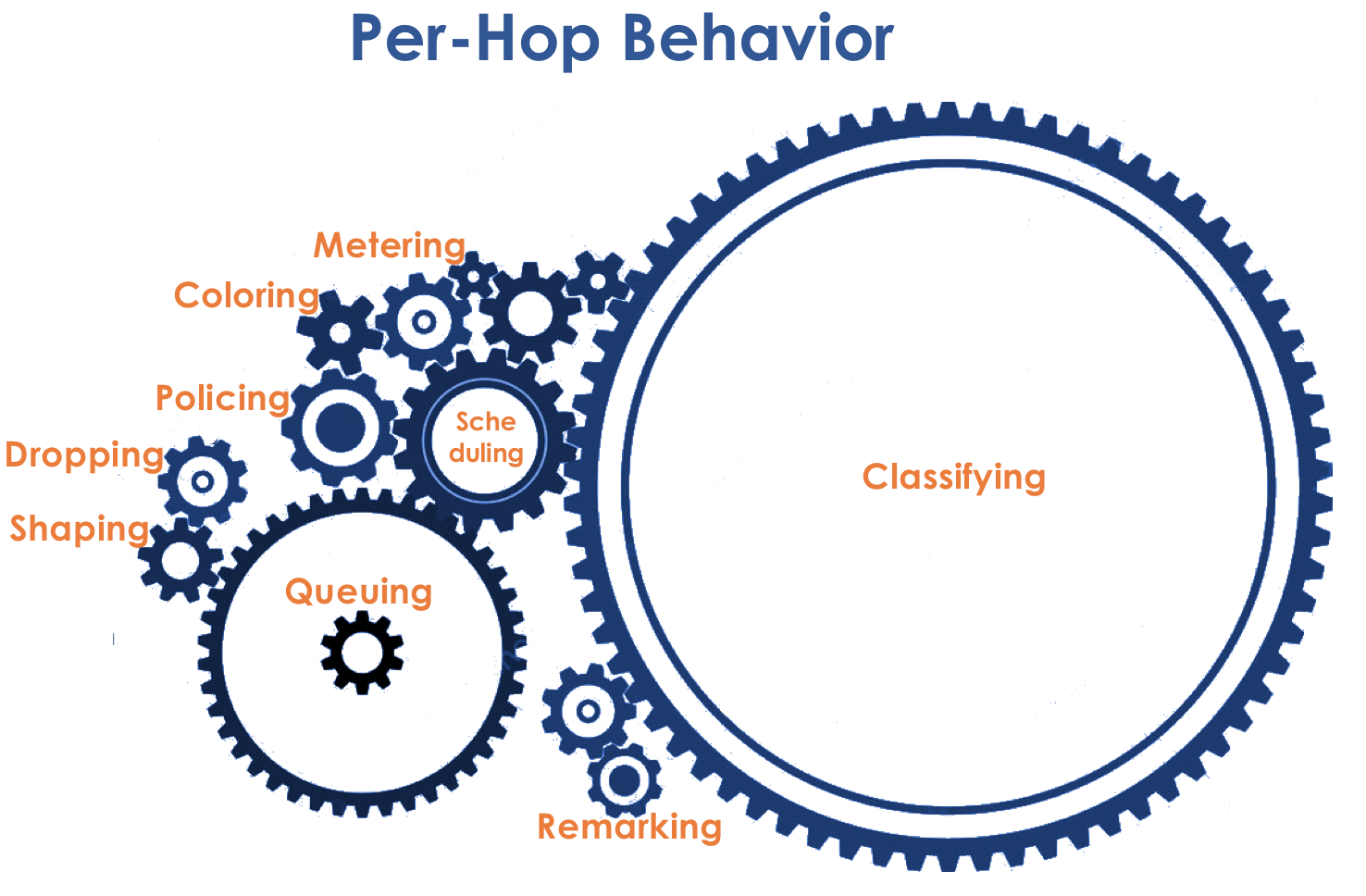
El modelo de comportamiento está determinado por un conjunto de herramientas y sus parámetros: Vigilancia, caída, puesta en cola, programación, conformación.
Usando los modelos de comportamiento disponibles, la red puede proporcionar varias clases de servicio (
Clase de servicio ).
Es decir, diferentes categorías de tráfico pueden recibir diferentes niveles de servicio en la red al aplicarles diferentes PHB.
En consecuencia, en primer lugar, debe determinar a qué clase de tráfico de servicio se refiere:
Clasificación .
Cada nodo clasifica independientemente los paquetes entrantes.

Después de la clasificación, se produce una medición (
Medición ): cuántos bits / bytes de tráfico de esta clase han llegado al enrutador.
Según los resultados, los paquetes se pueden pintar (
colorear ): verde (dentro del límite establecido), amarillo (fuera del límite), rojo (completamente engañado por la costa).
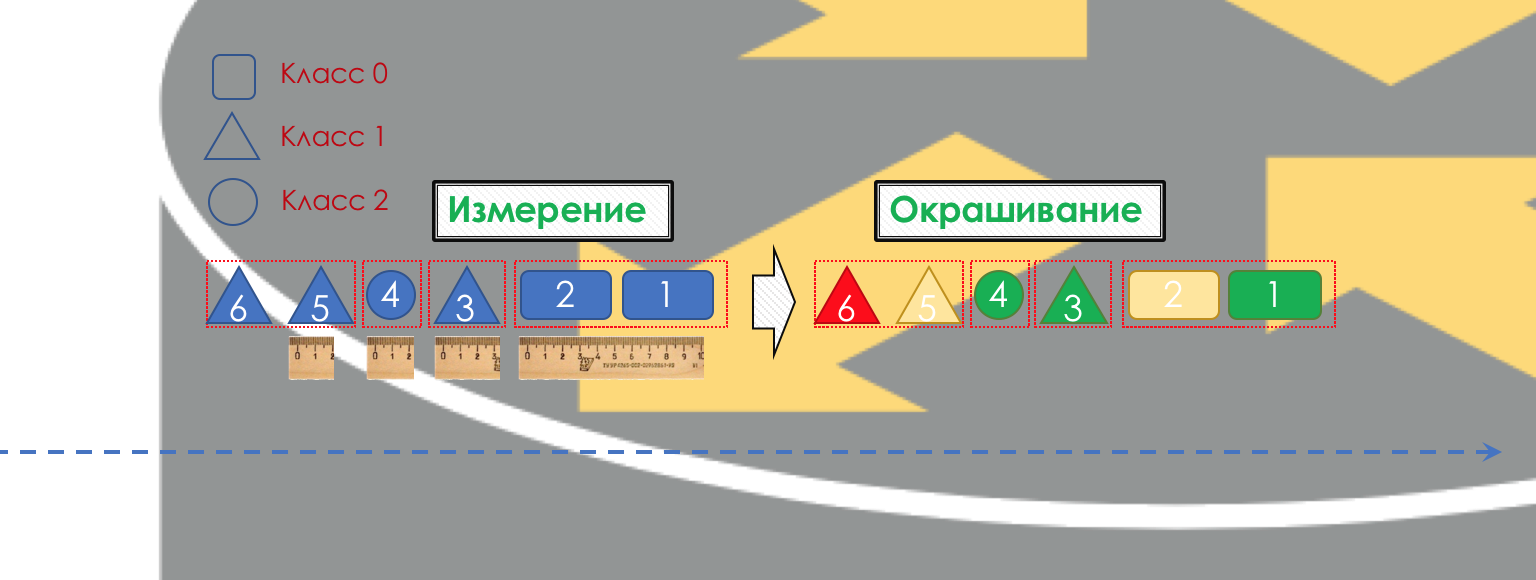
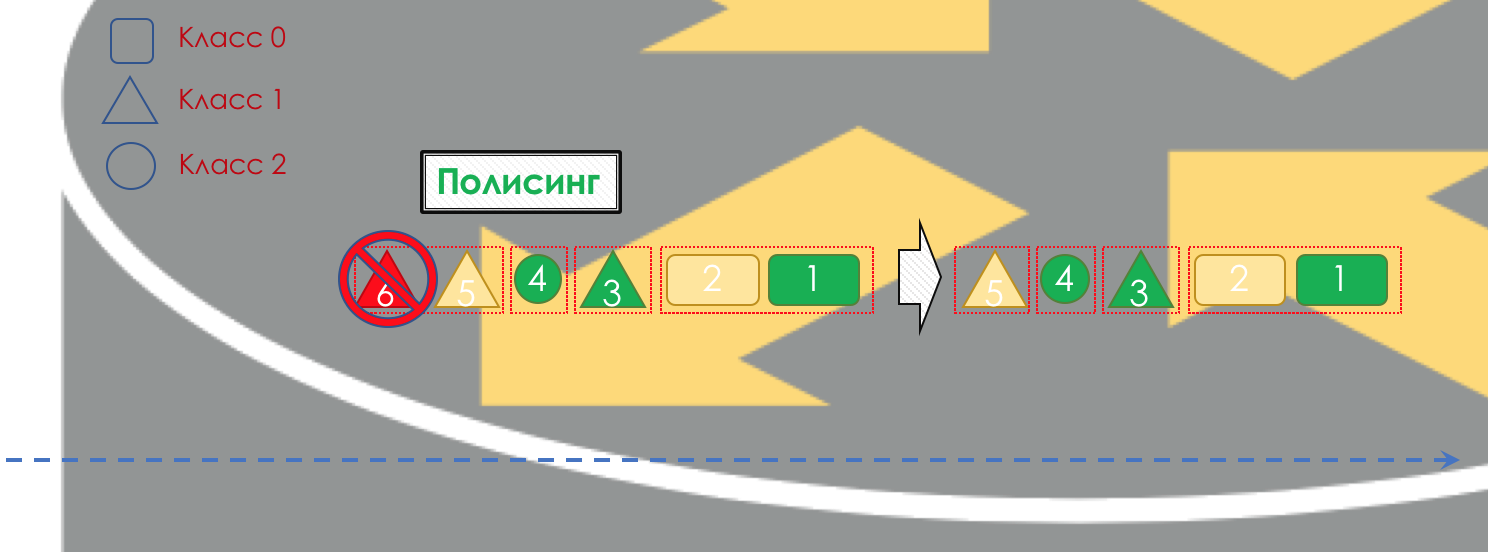
Si es necesario, se lleva a cabo la
Política (lo siento por un papel de calco, hay una mejor opción: escribir, cambiaré). Un pulidor basado en el color de un paquete asigna una acción al paquete: transmitir, descartar o volver a marcar.
Después de eso, el paquete debe caer en una de las colas (En
cola ). Se asigna una cola separada para cada clase de servicio, lo que les permite diferenciarse utilizando diferentes PHB.
Pero incluso antes de que el paquete entre en la cola, se puede descartar (
cuentagotas ) si la cola está llena.
Si es verde, pasará, si es amarillo, lo más probable es que se descarte si la línea está llena y si el rojo es un suicida seguro. Condicionalmente, la probabilidad de caída depende del color del paquete y de la plenitud de la cola a la que va a llegar.
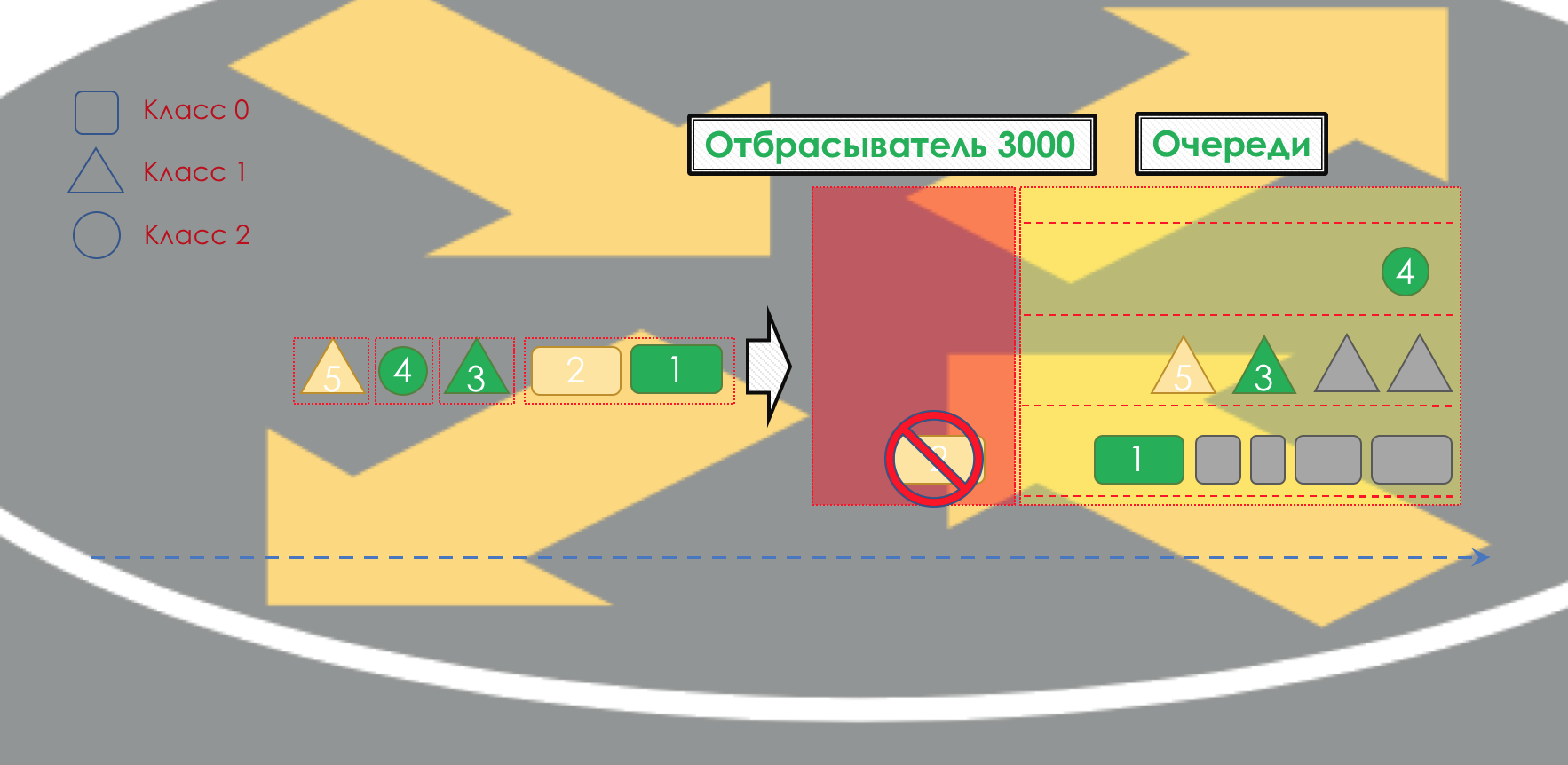
A la salida de la cola, funciona un
Shaper , cuya tarea es muy similar a la tarea del polisador: limitar el tráfico a un valor dado.
Puede configurar moldeadores arbitrarios para colas individuales, o incluso dentro de las colas.
Sobre la diferencia entre un moldeador y un polisador en el capítulo Límite de velocidad.
Todas las colas eventualmente deberían fusionarse en una única interfaz de salida.
Recuerde la situación cuando en el camino se unen 8 carriles en 3. Sin un controlador de tráfico, esto se convierte en un caos. La separación por turnos no tendría sentido si tuviéramos la misma salida que la entrada.
Por lo tanto, hay un despachador especial (
Programador ), que extrae cíclicamente paquetes de diferentes colas y los envía a la interfaz (
Programación ).
De hecho, una combinación de un conjunto de colas y un despachador es el mecanismo de QoS más importante que le permite aplicar diferentes reglas a diferentes clases de tráfico, una que proporciona un ancho de banda amplio, la otra de baja latencia y la tercera falta de caídas.
Luego, los paquetes ya van a la interfaz, donde los paquetes se convierten en un flujo de bits: serialización (
serialización ) y luego la señal del entorno.
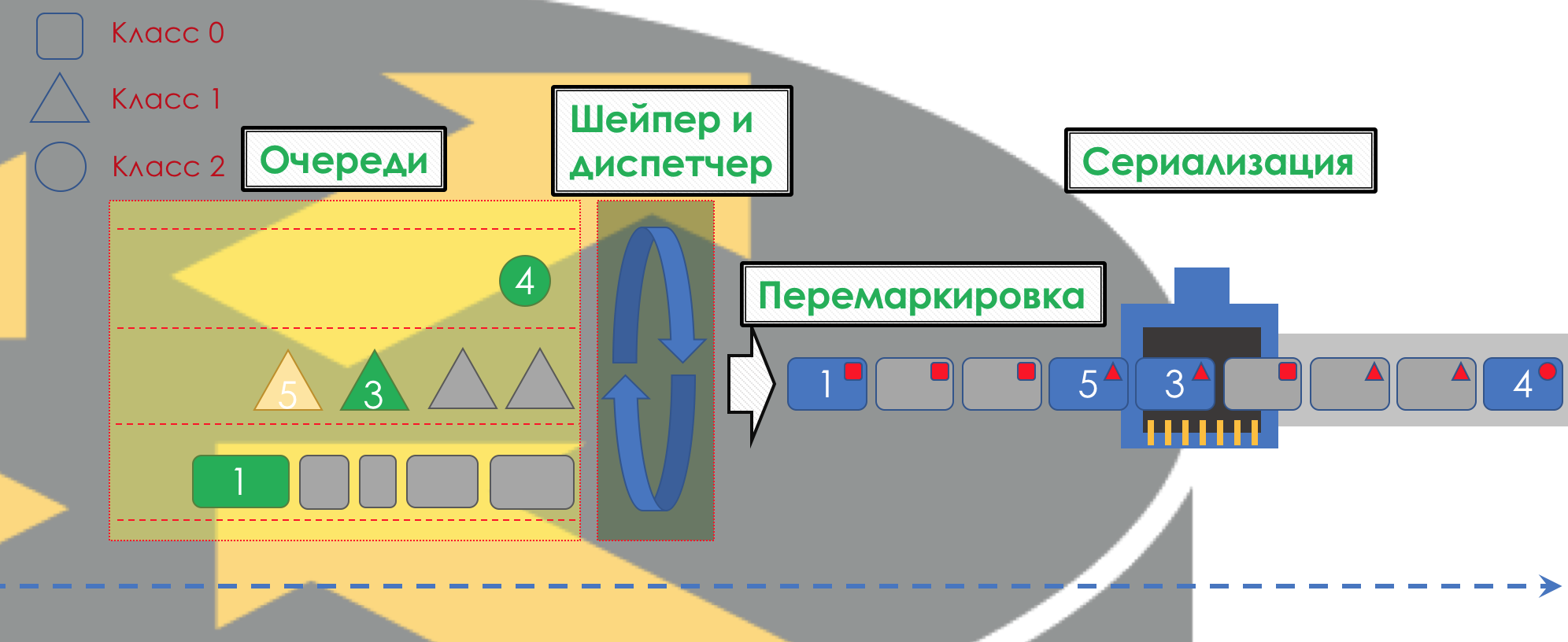
En DiffServ, el comportamiento de cada nodo es independiente de los demás; no hay protocolos de señalización que indiquen qué política de QoS está en la red. Al mismo tiempo, dentro de la red, me gustaría que el tráfico se maneje de la misma manera. Si solo un nodo se comporta de manera diferente, toda la política de QoS se está agotando.
Para esto, en primer lugar, en todos los enrutadores, se configuran las mismas clases y PHB para ellos, y en segundo lugar, se utiliza el
Marcado del paquete: su pertenencia a una clase particular se registra en el encabezado (IP, MPLS, 802.1q).
Y la belleza de DiffServ es que el siguiente nodo puede confiar en esta etiqueta para su clasificación.
Dicha zona de confianza, en la que se aplican las mismas reglas de clasificación de tráfico y los mismos comportamientos, se denomina dominio
DiffServ (
DiffServ-Domain ).

Por lo tanto, a la entrada del dominio DiffServ, podemos clasificar un paquete basado en 5-Tuple o una interfaz, marcarlo (
Observar / Reescribir ) de acuerdo con las reglas del dominio, y otros nodos confiarán en este marcado y no harán una clasificación compleja.
Es decir, no hay señalización explícita en DiffServ, pero el nodo puede decir a todos los siguientes en qué clase se debe proporcionar este paquete, esperando que sea confiable.
En los cruces entre los dominios DiffServ, debe negociar las políticas de QoS (o no).
Toda la imagen se verá así:
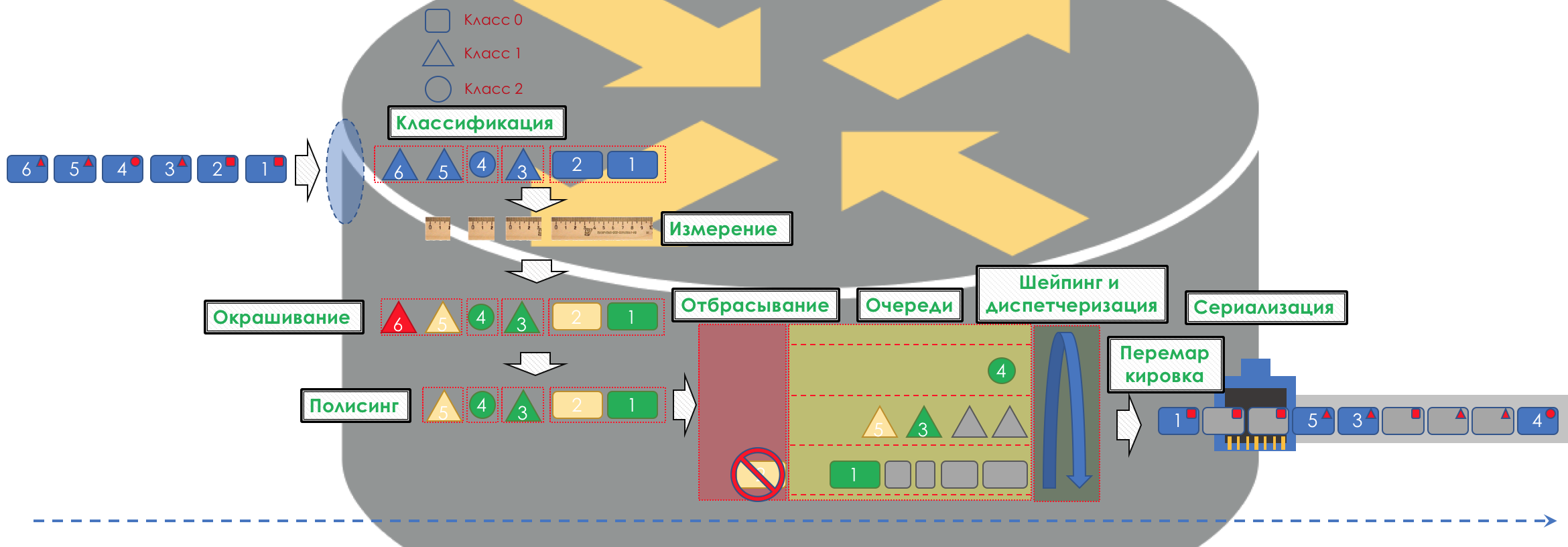
Para que quede claro, daré un análogo de la vida real.
Vuelo en avión (no Victoria).
Hay tres clases de servicio (CoS): Economía, Negocios, Primero.
Al comprar un boleto, se realiza la Clasificación: el pasajero recibe una cierta clase de servicio según el precio.
En el aeropuerto hay una marca (Observación): se emite un boleto que indica la clase.
Hay dos comportamientos (PHB): Mejor esfuerzo y Premium.
Existen mecanismos que implementan comportamientos: una sala de espera común o VIP Lounge, un minibús o un autobús compartido, cómodos asientos grandes o filas estrechas, el número de pasajeros por asistente de vuelo, la capacidad de pedir alcohol.
Dependiendo de la clase, los modelos de comportamiento se asignan, a la economía del mejor esfuerzo, a la empresa, a la prima básica y a la primera: SUPER-POWER-NINJA-TURBO-NEO-ULTRA-HYTRA-HYPER-MEGA-MULTI-ALPHA-META-EXTRA-UBER-PREFIX premium.
Al mismo tiempo, dos Premium difieren en eso, en una dan una copa de semidulce y en la otra tienen Bacardi ilimitado.
Luego, al llegar al aeropuerto, todos entran por una puerta. Aquellos que intentaron traer armas con ellos o no tienen un boleto no están permitidos (Drop). Los negocios y la economía entran en diferentes salas de espera y diferentes transportes (colas). Primero dejaron a bordo la Primera Clase, luego los negocios, luego la Economía (Programación), pero luego todos vuelan a su destino con un avión (interfaz).
En el mismo ejemplo, un vuelo en un avión es un retraso de propagación, el aterrizaje es un retraso de serialización, la espera de un avión en los pasillos está en cola y el control de pasaportes está en proceso. Tenga en cuenta que aquí el Retraso en el procesamiento suele ser insignificante en términos de tiempo total.
El próximo aeropuerto puede tratar a los pasajeros de una manera completamente diferente: su PHB es diferente. Pero al mismo tiempo, si el pasajero no cambia la aerolínea, lo más probable es que la actitud hacia él no cambie, porque una compañía es un dominio DiffServ.
Como habrás notado, DiffServ es extremadamente (o infinitamente) complejo. Pero analizaremos todo lo descrito anteriormente. Al mismo tiempo, en el artículo no abordaré los matices de la implementación física (pueden diferir incluso en dos placas del mismo enrutador), no hablaré sobre HQoS y MPLS DS-TE.
El umbral para ingresar al círculo de ingenieros que entienden la tecnología para QoS es mucho más alto que para los protocolos de enrutamiento, MPLS o, perdóneme, Radya, STP.
A pesar de esto, DiffServ se ha ganado el reconocimiento y la implementación en redes de todo el mundo porque, como dicen, es altamente escalable.
En el resto de este artículo, analizaré solo DiffServ.
A continuación analizaremos todas las herramientas y procesos indicados en la ilustración.
En el curso de la expansión del tema, mostraré algunas cosas en la práctica.
Trabajaremos con dicha red:
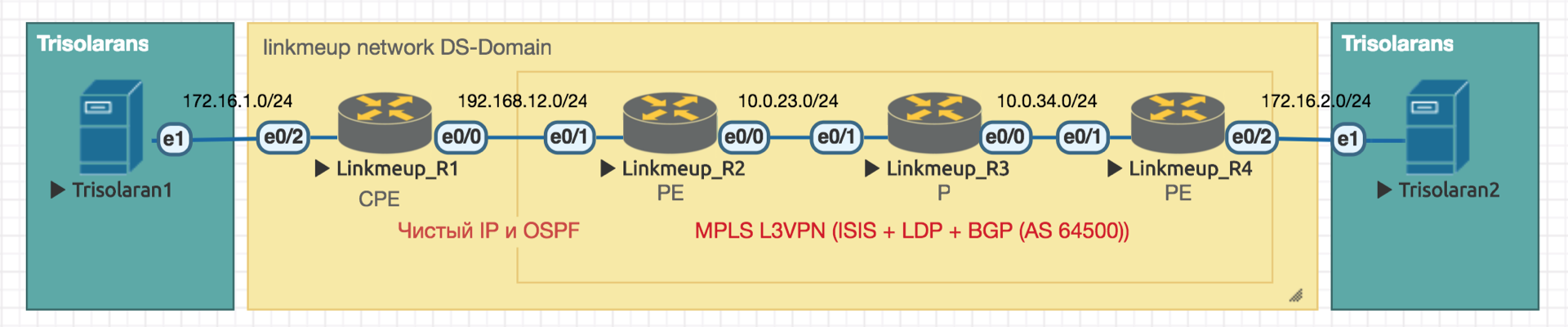
Trisolarans es un cliente proveedor de linkmeup con dos puntos de conexión.
El área amarilla es el dominio DiffServ de la red linkmeup, donde está vigente una única política de QoS.
Linkmeup_R1 es un dispositivo CPE administrado por el proveedor y, por lo tanto, en una zona de confianza. OSPF se plantea con él y la interacción se lleva a cabo a través de una IP limpia.
Dentro del núcleo de la red se encuentran MPLS + LDP + MP-BGP con L3VPN, que se extiende desde Linkmeup_R2 a Linkmeup_R4.
Daré todos los demás comentarios según sea necesario.
El archivo de configuración inicial .
4. Clasificación y etiquetado.
Dentro de su red, el administrador define las clases de servicio que puede proporcionar tráfico.
Por lo tanto, lo primero que hace cada nodo cuando recibe un paquete es clasificarlo.
Hay tres formas:
- Comportamiento agregado ( BA )
Solo confíe en la etiqueta del paquete existente en su encabezado. Por ejemplo, el campo IP DSCP.
Se llama así porque bajo la misma etiqueta en el campo DSCP se agregan varias categorías de tráfico que esperan el mismo comportamiento con respecto a ellos mismos. Por ejemplo, todas las sesiones SIP se agregarán en una clase.
El número de posibles clases de servicio y, por lo tanto, patrones de comportamiento, es limitado. En consecuencia, es imposible que cada categoría (o incluso más para la secuencia) asigne una clase separada; es necesario agregarla. - Basado en la interfaz
Todo lo que viene a una interfaz particular debe colocarse en una clase de tráfico. Por ejemplo, sabemos con certeza que el servidor de la base de datos está conectado a este puerto y nada más. Y en otra estación de trabajo para empleados. - Multicampo ( MF )
Analice los campos del encabezado del paquete: direcciones IP, puertos, direcciones MAC. En términos generales, campos arbitrarios.
Por ejemplo, todo el tráfico que va a la subred 10.127.721.0/24 en el puerto 5000 debe marcarse como tráfico, lo que requiere condicionalmente la quinta clase de servicio.
El administrador determina el conjunto de clases de servicio que la red puede proporcionar y les asigna un valor digital.
En la entrada al dominio DS, no confiamos en nadie, por lo que la clasificación se realiza de la segunda o tercera forma: en función de las direcciones, protocolos o interfaces, se determina la clase de servicio y el valor digital correspondiente.
A la salida del primer nodo, este dígito se codifica en el campo DSCP del encabezado IP (u otro campo de la Clase de tráfico: Clase de tráfico MPLS, Clase de tráfico IPv6, Ethernet 802.1p): se produce una observación.
Es habitual confiar en este etiquetado dentro del dominio DS, por lo tanto, los nodos de tránsito usan el primer método de clasificación (BA), el más simple. Sin análisis de rumbo complicado, solo mire el número registrado.
En la unión de dos dominios, puede clasificar según una interfaz o MF, como describí anteriormente, o puede confiar en el marcado BA con reservas.
Por ejemplo, confíe en todos los valores excepto 6 y 7, y reasigne 6 y 7 a 5.
Esta situación es posible cuando el proveedor conecta una entidad legal que tiene su propia política de etiquetado. Al proveedor no le importa guardarlo, pero no quiere que el tráfico caiga en la clase en la que recibe los paquetes de protocolo de red.
Agregación de comportamiento
BA usa una clasificación muy simple, veo un número, entiendo la clase.
Entonces, ¿cuál es la figura? ¿Y en qué campo se registra?
- Clase de tráfico IPv6
- Clase de tráfico MPLS
- Ethernet 802.1p
La clasificación se basa principalmente en el encabezado de conmutación.
Llamo un encabezado de conmutación en función del cual el dispositivo determina dónde enviar el paquete para que se acerque al destinatario.Es decir, si un paquete IP llega al enrutador, se analizan el encabezado IP y el campo DSCP. Si llega MPLS, se analiza: clase de tráfico MPLS.
Si un paquete Ethernet + VLAN + MPLS + IP llegó a un conmutador L2 normal, entonces se analizará 802.1p (aunque esto se puede cambiar).
IPv4 TOS
El campo QoS nos acompaña exactamente tanto como la IP. Se suponía que el campo TOS de ocho bits, Tipo de servicio, tenía la prioridad del paquete.
Incluso antes de la llegada de DiffServ,
RFC 791 (
PROTOCOLO DE INTERNET ) describió el campo de esta manera:
Precedencia de IP (IPP) + DTR + 00.
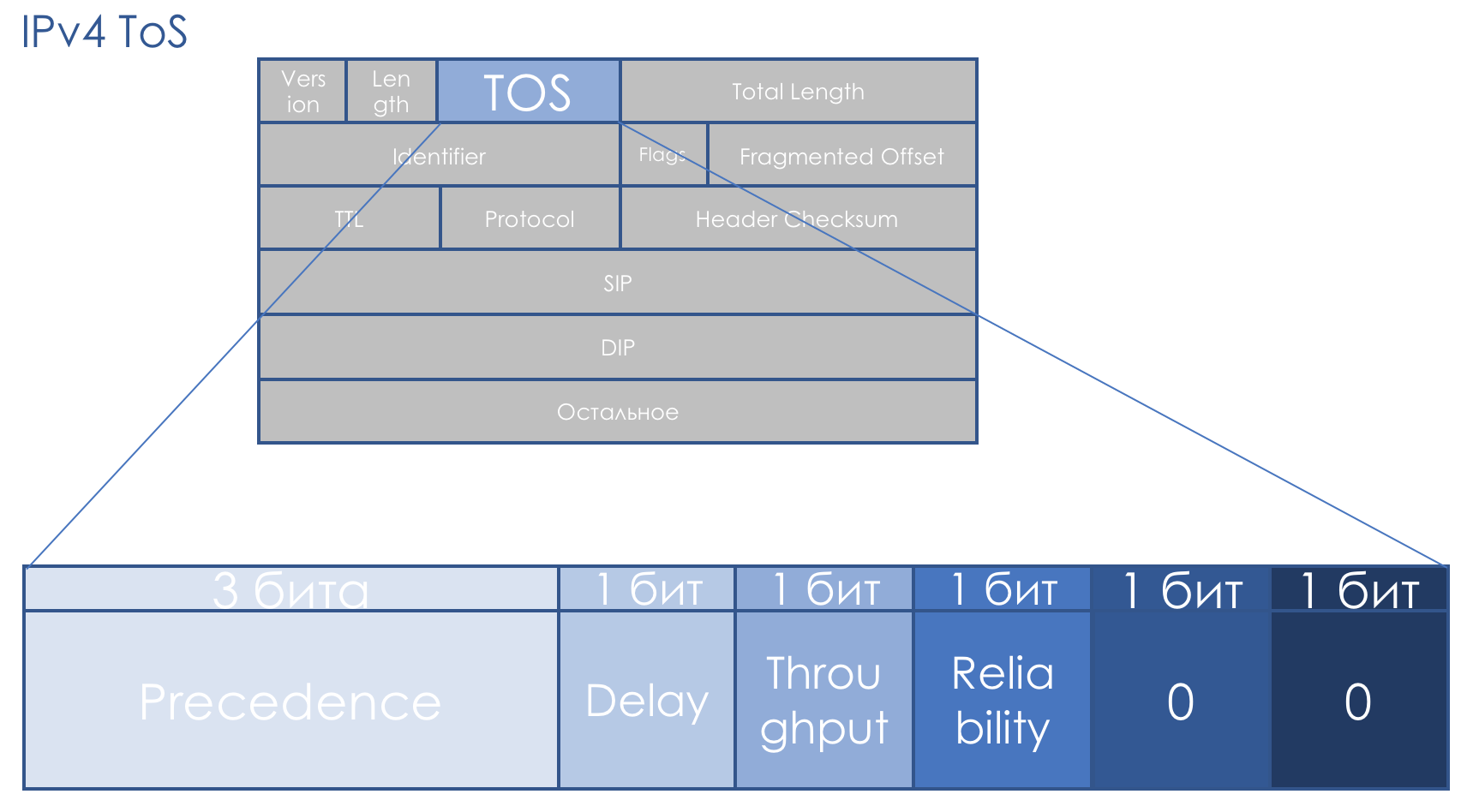
Es decir, la prioridad del paquete va, luego los bits de exigencia para el retraso, el rendimiento y la confiabilidad (0 - sin requisitos, 1 - con requisitos).
Los dos últimos bits deben ser cero.
La prioridad determinó los siguientes valores ...111 - Control de red
110 - Control entre redes
101 - CRÍTICO / ECP
100 - Anulación de flash
011 - Flash
010 - Inmediato
001 - Prioridad
000 - Rutina
Más adelante en
RFC 1349 (
Tipo de servicio en la suite de protocolos de Internet ), el campo TOS se redefinió ligeramente:
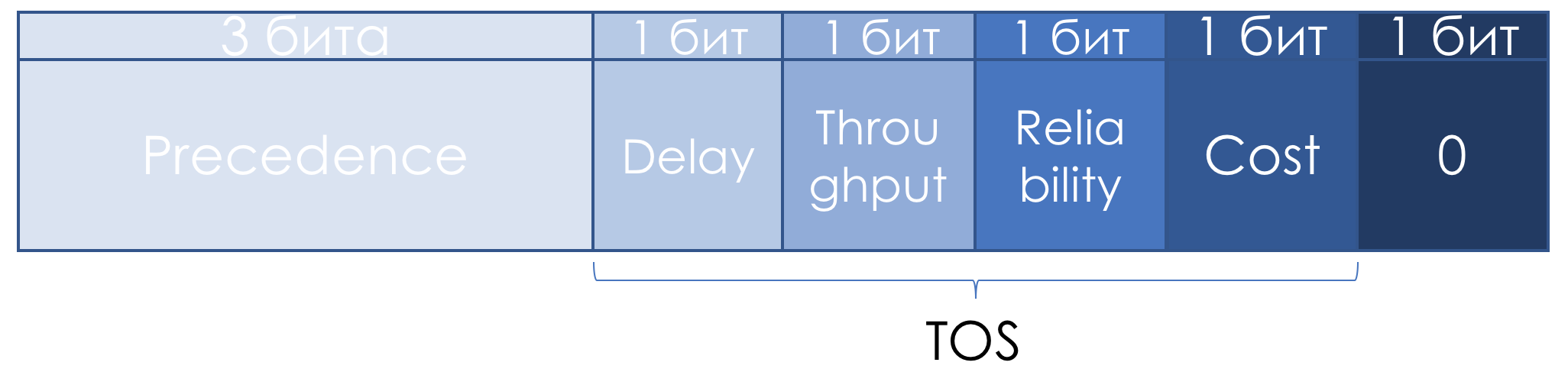
Los tres bits restantes permanecieron con precedencia IP, los siguientes cuatro se convirtieron en TOS después de agregar el bit de costo.
Aquí le mostramos cómo leer las unidades en estos bits TOS:
- D - "minimizar d elay",
- T - "maximizar el rendimiento de t ",
- R - "maximizar la confiabilidad",
- C - "minimizar el costo".
Las descripciones confusas no contribuyeron a la popularidad de este enfoque.
No hubo un enfoque sistemático para la QoS a lo largo de todo el camino, no hubo recomendaciones claras sobre cómo usar el campo de prioridad, la descripción de los bits de Retardo, Rendimiento y Fiabilidad fue extremadamente vaga.
Por lo tanto, en el contexto de DiffServ, el campo TOS se redefinió una vez más en
RFC 2474 (
Definición del campo de servicios diferenciados (campo DS) en los encabezados IPv4 e IPv6 ):

En lugar de los bits IPP y DTRC,
se introdujo el DSCP de campo de seis bits -
Punto de código de servicios diferenciados , no se utilizaron los dos bits correctos.
A partir de ese momento, fue el campo DSCP el que debería haberse convertido en la marca principal de DiffServ: un cierto valor (código) está escrito en él, que dentro del dominio DS caracteriza la clase específica de servicio requerida por el paquete y su prioridad de descarte. Esta es la misma figura.
El administrador puede usar los 6 bits de DSCP como lo considere conveniente, compartiendo hasta un máximo de 64 clases de servicio.
Sin embargo, en aras de la compatibilidad con la precedencia de IP, conservaron el papel de selector de clase durante los primeros tres bits.
Es decir, como en IPP, 3 bits de Selector de clase le permiten definir 8 clases.

Sin embargo, esto no es más que un acuerdo que, dentro de los límites de su dominio DS, el administrador puede ignorar y usar fácilmente los 6 bits a su discreción.
Además, también observo que, según las recomendaciones de IETF, cuanto mayor sea el valor registrado en el CS, más exigente es este tráfico al servicio.
Pero esto no debe tomarse como una verdad innegable.
Si los primeros tres bits definen la clase de tráfico, los tres siguientes se utilizan para indicar la prioridad de descarte de paquetes (Prioridad de descarte o
Prioridad de pérdida de paquetes - PLP ).
Ocho clases: ¿es mucho o poco? A primera vista, no es suficiente, después de todo, hay tanto tráfico diferente en la red que uno quiere distinguir cada protocolo por clase. Sin embargo, resulta que ocho es suficiente para todos los escenarios posibles.
Para cada clase, debe definir un PHB que lo maneje de alguna manera diferente de otras clases.
Y con un aumento en el divisor, el dividendo (recurso) no aumenta.
Deliberadamente, no estoy hablando de los valores exactos de la clase de tráfico que describen, ya que no hay estándares y puede usarlos formalmente a su propio criterio. A continuación le diré qué clases y sus valores correspondientes se recomiendan.
Bits ECN ...El campo ECN de dos bits apareció solo en
RFC 3168 (
Notificación explícita de congestión ). El campo se definió con el buen propósito de informar explícitamente a los hosts finales que alguien estaba experimentando congestión en el camino.
Por ejemplo, cuando los paquetes se retrasan en las colas del enrutador durante mucho tiempo y los llenan, por ejemplo, en un 85%, cambia el valor de ECN y le dice al host final qué debe ser más lento, algo como Pause Frames en Ethernet.
En este caso, el emisor debe reducir la velocidad de transmisión y reducir la carga en el nodo que sufre.
Al mismo tiempo, teóricamente, no se requiere el soporte de este campo por parte de todos los nodos de tránsito. Es decir, el uso de ECN no interrumpe la red que no lo admite.
El objetivo es bueno, pero antes de la aplicación en la vida no se encuentra ECN particularmente. Hoy en día, las mega e hiperescalas miran estos dos bits con
nuevo interés .
La ECN es uno de los mecanismos para evitar la congestión que se describen a continuación.
Práctica de clasificación DSCP
No hace daño un poco de práctica.
El esquema es el mismo.
Para comenzar, solo envíe una solicitud ICMP:
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds: Packet sent with a source address of 172.16.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
Linkmeup_R1. E0 / 0. pcapng
pcapngY ahora con el valor DSCP establecido.
Linkmeup_R1#ping ip 172.16.2.2 source 172.16.1.1 tos 184 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 172.16.2.2, timeout is 2 seconds: Packet sent with a source address of 172.16.1.1 !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 1/1/1 ms
El valor 184 es la representación decimal del binario 10111000. De estos, los primeros 6 bits son 101110, es decir, el decimal 46, y esta es la clase EF.
Tabla de valores de TOS estándar para popingushki conveniente ...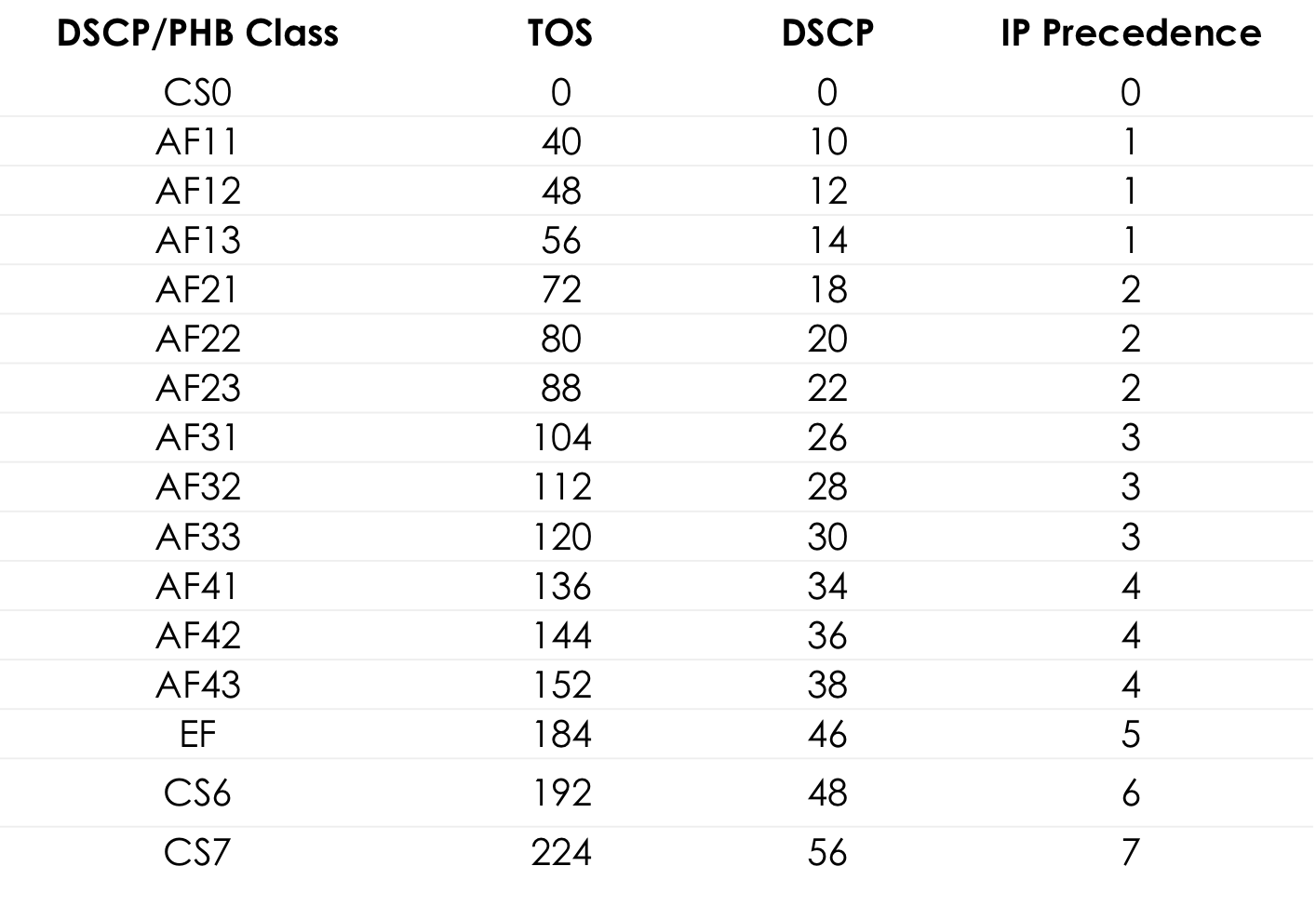 Más detalles
Más detallesA continuación, en el texto del capítulo de la
Recomendación IETF, le diré de dónde provienen estos números y nombres.
Linkmeup_R2. E0 / 0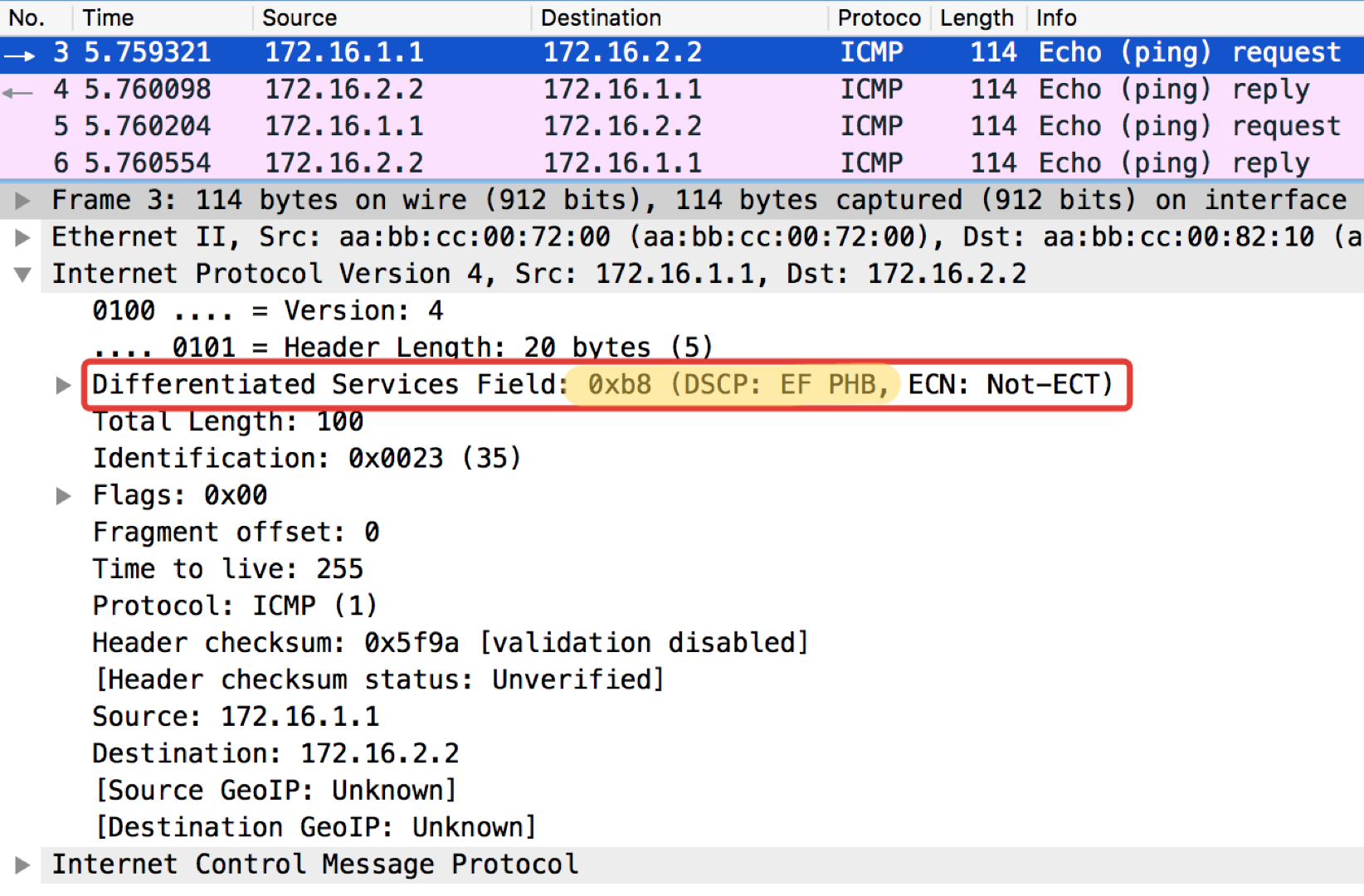 pcapng
pcapngUna nota curiosa: el destino de pingushka en ICMP Echo reply establece el mismo valor de clase que en Echo Request. Esto es lógico: si el remitente envió un paquete con un cierto nivel de importancia, entonces obviamente quiere recibir la garantía de devolución.
Linkmeup_R2. E0 / 0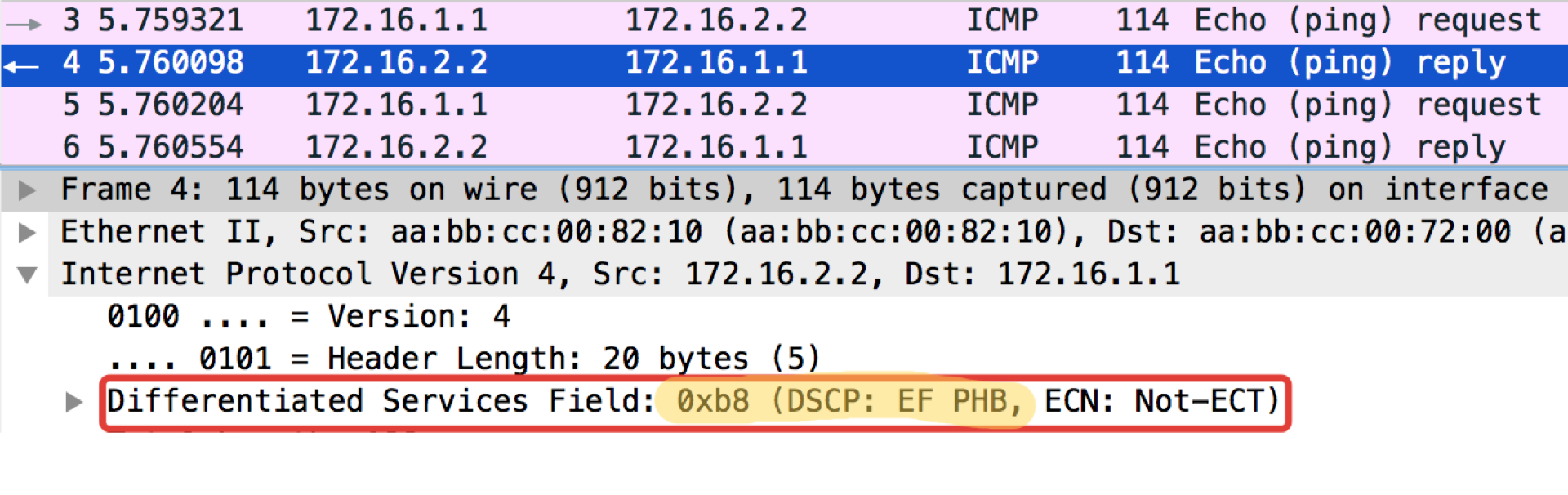 Archivo de configuración de clasificación DSCP.
Archivo de configuración de clasificación DSCP.Clase de tráfico IPv6
IPv6 no es muy diferente en términos de QoS que IPv4. El campo de ocho bits, llamado Clase de tráfico, también se divide en dos partes. Los primeros 6 bits, DSCP, juegan exactamente el mismo papel.

Sí, ha aparecido Flow Label. Dicen que podría usarse para la diferenciación adicional de clases. Pero esta idea aún no se ha aplicado en la vida.
Clase de tráfico MPLS
El concepto de DiffServ se centró en redes IP con enrutamiento de encabezado IP. Eso es solo mala suerte: después de 3 años, publicaron
RFC 3031 (
Multiprotocol Label Switching Architecture ). Y MPLS comenzó a hacerse cargo de los proveedores de la red.
DiffServ no pudo extenderse a él.
Por una coincidencia afortunada, se puso un campo EXP de tres bits en MPLS para cualquier caso experimental. Y a pesar del hecho de que hace mucho tiempo en
RFC 5462 (campo
"EXP" renombrado como campo "clase de tráfico" ) se convirtió oficialmente en el campo de clase de tráfico, por inercia se llama IExPi.
Hay un problema con él: su longitud es de tres bits, lo que limita el número de valores posibles a 9. No es solo pequeño, es 3 órdenes binarias menos que DSCP.

Dado que la clase de tráfico MPLS a menudo se hereda del paquete IP DSCP, tenemos el archivo con pérdida. O ... No, no quieres saber eso ...
L-LSP . Utiliza una combinación de Clase de tráfico + valor de etiqueta.
En general, la situación es extraña: MPLS se diseñó como una ayuda IP para la toma de decisiones rápida: la etiqueta MPLS se detecta instantáneamente en CAM mediante Full Match, en lugar de la tradicional coincidencia de prefijo más largo. Es decir, sabían sobre IP y participaron en el cambio, pero no proporcionaron un campo de prioridad normal.
De hecho, ya vimos anteriormente que solo los primeros tres bits de DSCP se utilizan para determinar la clase de tráfico, y los otros tres bits son Precedencia de caída (o PLP - Prioridad de pérdida de paquetes).
Por lo tanto, en términos de clases de servicio, todavía tenemos una correspondencia 1: 1, perdiendo solo información sobre la Precedencia de caída.
En el caso de MPLS, la clasificación como en IP puede basarse en la interfaz, MF, IP DSCP o Traffic Class MPLS.
Etiquetar significa escribir un valor en el campo Clase de tráfico del encabezado MPLS.
Un paquete puede contener múltiples encabezados MPLS. Para fines de DiffServ, solo se usa la parte superior.
Existen tres escenarios diferentes de remarcado cuando se mueve un paquete de un segmento IP puro a otro a través del dominio MPLS: (esto es solo un extracto del
artículo ).
- Modo uniforme
- Modo de tubería
- Modo de tubo corto
Modos de operación ...Modo uniforme
Este es un modelo plano de extremo a extremo.
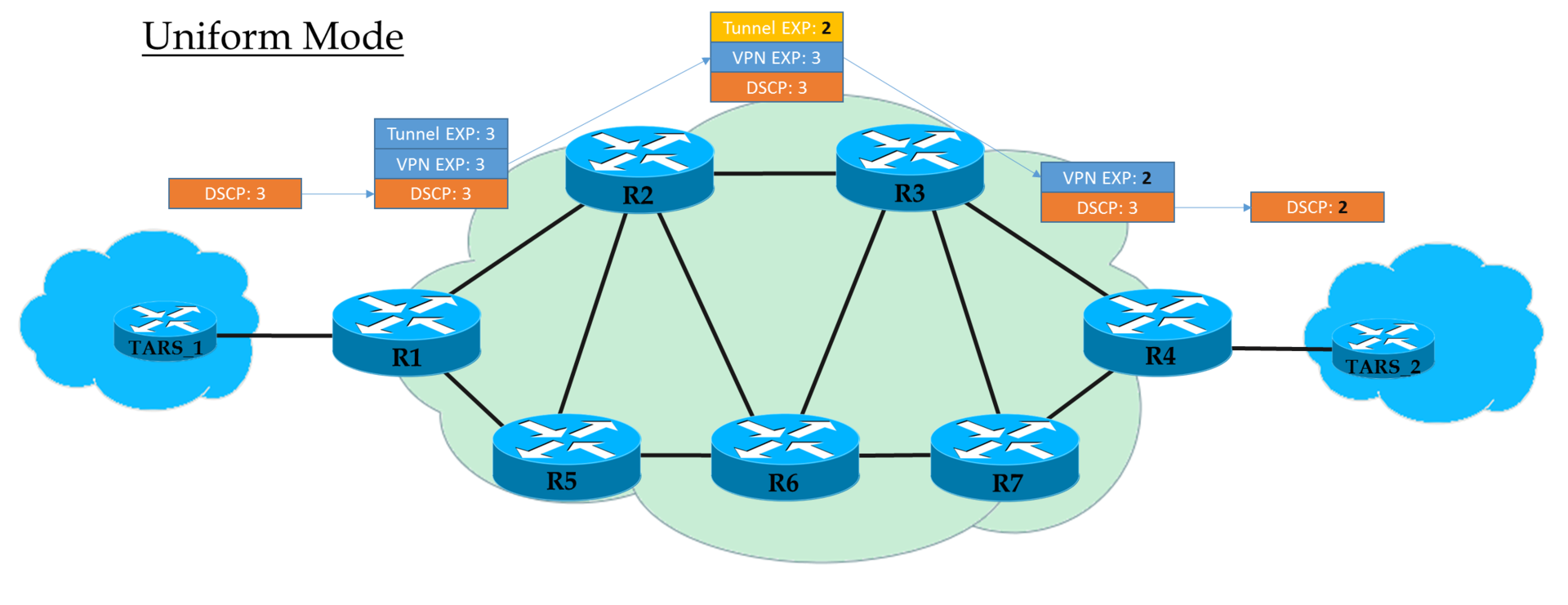
En Ingress PE, confiamos en IP DSCP y copiamos (
estrictamente hablando, visualización, pero por simplicidad diremos "copiar" ) su valor en MPLS EXP (tanto encabezados de túnel como VPN). En la salida de Ingress PE, el paquete ya se procesa de acuerdo con el valor del campo EXP del encabezado MPLS superior.
Cada tránsito P también procesa paquetes basados en el EXP superior. Pero al mismo tiempo, puede cambiarlo si el operador lo quiere.
El penúltimo nodo elimina la etiqueta de transporte (PHP) y copia el valor EXP en el encabezado VPN. No importa lo que haya allí: en el modo Uniforme, se produce la copia.
Egress PE, al eliminar la etiqueta VPN, también copia el valor EXP a IP DSCP, incluso si hay algo más escrito allí.
Es decir, si en algún lugar en el medio el valor de la etiqueta EXP en el encabezado del túnel ha cambiado, el paquete IP heredará este cambio.
Modo de tubería
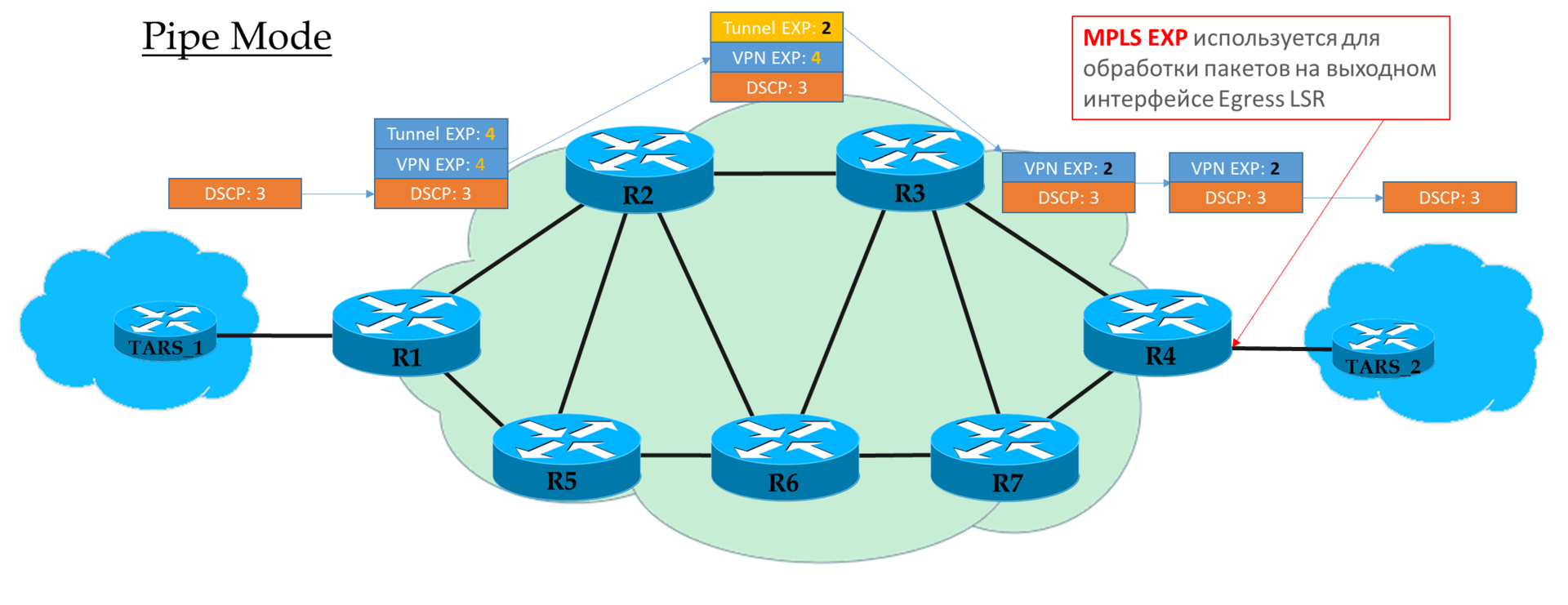
Si en Ingress PE decidimos no confiar en el valor DSCP, entonces el valor EXP que el operador desea se inserta en los encabezados MPLS.
Pero es aceptable copiar los que estaban en DSCP. Por ejemplo, puede redefinir valores: copie todo hasta EF y asigne CS6 y CS7 a EF.
Cada tránsito P solo mira la EXP del encabezado MPLS superior.
El penúltimo nodo elimina la etiqueta de transporte (PHP) y
copia el valor EXP en el encabezado VPN.
Egress PE primero procesa el paquete basado en el campo EXP en el encabezado MPLS, y solo luego lo elimina,
sin copiar el valor en DSCP.
Es decir, independientemente de lo que sucedió con el campo EXP en los encabezados MPLS, el IP DSCP permanece sin cambios.
Tal escenario se puede usar cuando el operador tiene su propio dominio Diff-Serv, y no quiere que el tráfico del cliente lo influya de alguna manera.
Modo de tubo corto
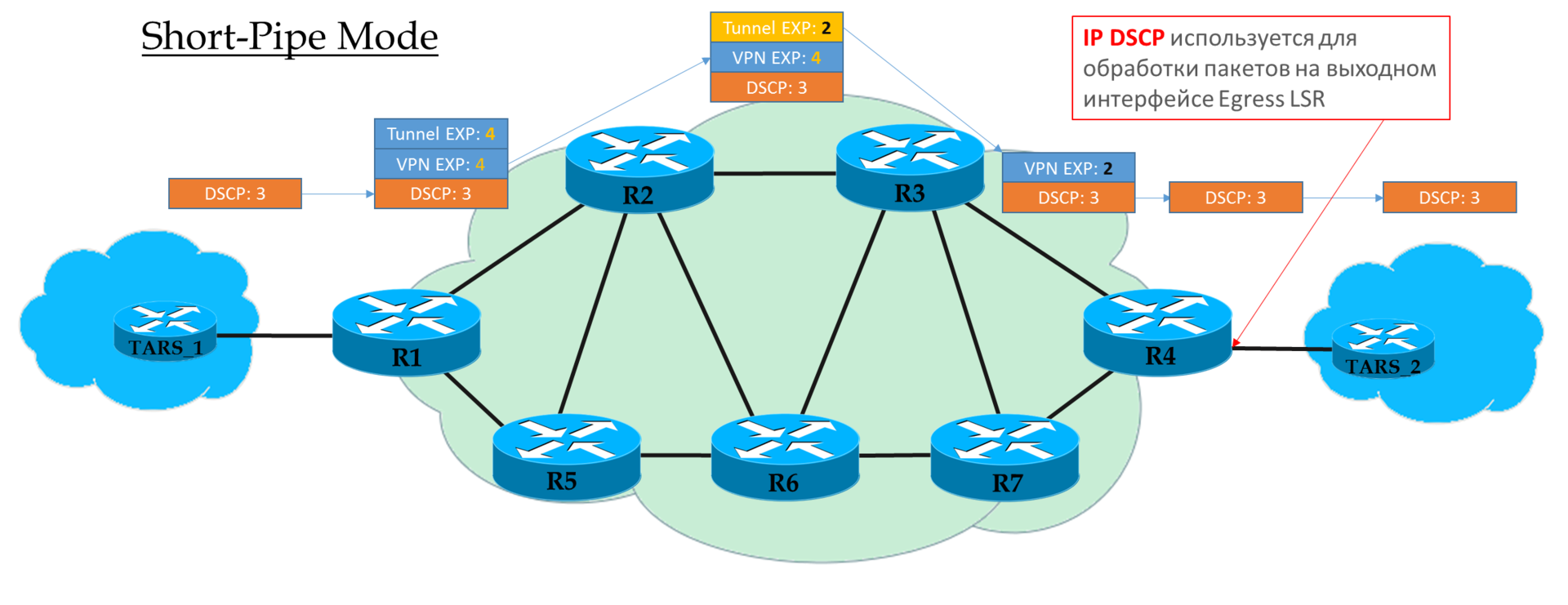
Puede considerar este modo como una variación del modo Pipe. La única diferencia es que a la salida de la red MPLS, el paquete se procesa de acuerdo con su campo IP DSCP, no MPLS EXP.
Esto significa que la prioridad del paquete en la salida la determina el cliente, no el operador.
Ingress PE no confía en los paquetes entrantes IP DSCP
Transit Ps busca en el campo EXP del encabezado superior.
El penúltimo P elimina la etiqueta de transporte y copia el valor en la etiqueta VPN.
Egress PE primero elimina la etiqueta MPLS, luego procesa el paquete en las colas.
Explicación de
cisco .
Práctica de clasificación MPLS Traffic Class
El esquema es el mismo:
El archivo de configuración es el mismo.En el diagrama de red linkmeup, hay una transición de IP a MPLS a Linkmeup_R2.
Veamos qué sucede con el marcado cuando ping
ping ip 172.16.2.2 fuente 172.16.1.1 tos 184 .
Linkmeup_R2. E0 / 0. pcapng
pcapngEntonces, vemos que la etiqueta EF original en IP DSCP se transformó en el valor 5 del campo EXP MPLS (también es la clase de tráfico, recuerde esto) tanto del encabezado VPN como del encabezado de transporte.
Aquí estamos presenciando el modo uniforme de operación.
Ethernet 802.1p
La falta de un campo de prioridad en 802.3 (Ethernet) se explica por el hecho de que Ethernet se planificó originalmente exclusivamente como una solución para el segmento LAN. Por dinero modesto, puede obtener un ancho de banda excesivo, y el enlace ascendente siempre será un cuello de botella: no hay nada de qué preocuparse por priorizar.
Sin embargo, pronto se hizo evidente que el atractivo financiero de Ethernet + IP lleva este paquete a los niveles de red troncal y WAN. Y la cohabitación en un segmento LAN de torrentes y telefonía debe resolverse.
Afortunadamente, 802.1q (VLAN) llegó a tiempo para esto, en el que se asignó un campo de 3 bits (nuevamente) para las prioridades.
En el plan DiffServ, este campo le permite definir las mismas 8 clases de tráfico.
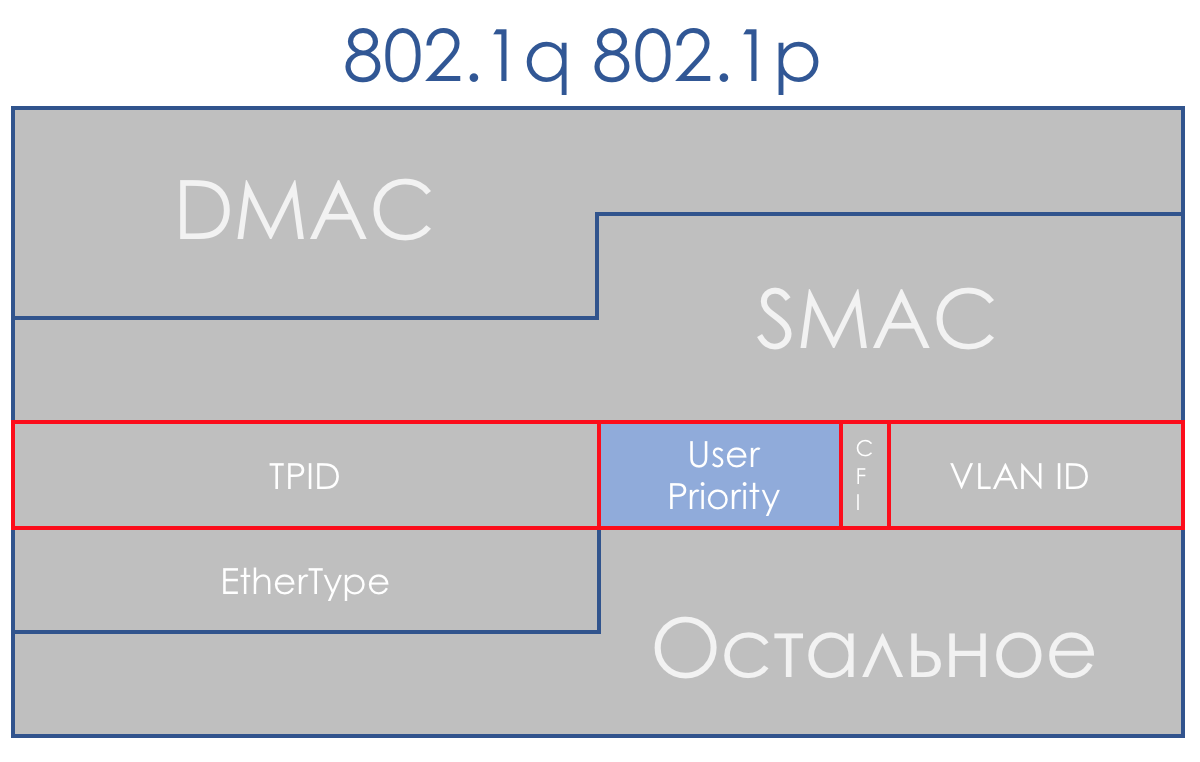
Al recibir un paquete, el dispositivo de red del dominio DS en la mayoría de los casos tiene en cuenta el encabezado que utiliza para cambiar:
- Conmutador Ethernet - 802.1p
- Nodo MPLS - Clase de tráfico MPLS
- Enrutador IP - IP DSCP
Aunque este comportamiento se puede cambiar: clasificación basada en interfaz y multicampo. Y a veces incluso puedes decir explícitamente en el campo CoS qué encabezado mirar.
Basado en la interfaz
Esta es la forma más fácil de clasificar paquetes en la frente. Todo lo que se vierte en la interfaz especificada se marca con una determinada clase.
En algunos casos, esta granularidad es suficiente, por lo que la interfaz se utiliza en la vida.
Práctica de clasificación basada en interfaz
El esquema es el mismo:
La configuración de políticas de QoS en el equipo de la mayoría de los proveedores se divide en etapas.
- Primero, se define un clasificador:
class-map match-all TRISOLARANS_INTERFACE_CM
match input-interface Ethernet0/2
Todo lo que viene a la interfaz Ethernet0 / 2.
- A continuación, se crea una política donde se asocian el clasificador y la acción necesaria.
policy-map TRISOLARANS_REMARK class TRISOLARANS_INTERFACE_CM set ip dscp cs7
Si el paquete cumple con el clasificador TRISOLARANS_INTERFACE_CM, escriba CS7 en el campo DSCP.
Aquí me adelanto usando CS7 oscuro, y luego EF, AF. A continuación puede leer sobre estas abreviaturas y acuerdos aceptados. Mientras tanto, es suficiente saber que se trata de diferentes clases con diferentes niveles de servicio.
- Y el último paso es aplicar la política a la interfaz:
interface Ethernet0/2 service-policy input TRISOLARANS_REMARK
Aquí, el clasificador es un poco redundante, lo que verificará que el paquete llegó a la interfaz e0 / 2, donde luego aplicamos la política. Se podría escribir coincide con cualquiera:
class-map match-all TRISOLARANS_INTERFACE_CM match any
Sin embargo, la política se puede aplicar realmente en vlanif o en la interfaz de salida, por lo que es posible.
Ejecute el ping habitual en 172.16.2.2 (Trisolaran2) con Trisolaran1:
Y en el volcado entre Linkmeup_R1 y Linkmeup_R2 veremos lo siguiente:
 pcapngArchivo de configuración de clasificación basada en la interfaz.
pcapngArchivo de configuración de clasificación basada en la interfaz.Campo múltiple
El tipo de clasificación más común en la entrada al dominio DS. No confiamos en el etiquetado existente y, sobre la base de los encabezados de los paquetes, asignamos una clase.
A menudo, esta es una forma de "habilitar" QoS, en el caso de que los remitentes no marquen.
Una herramienta bastante flexible, pero al mismo tiempo engorrosa: debe crear reglas difíciles para cada clase. Por lo tanto, dentro del dominio DS, BA es más relevante.
Práctica de clasificación de MF
El esquema es el mismo:
De los ejemplos prácticos anteriores, se puede ver que los dispositivos de red por defecto confían en el etiquetado de los paquetes entrantes.
Esto está bien dentro del dominio DS, pero no es aceptable en el punto de entrada.
¿Y ahora no confiemos ciegamente? En
Linkmeup_R2, ICMP se etiquetará como EF (solo por ejemplo), TCP como AF12 y todo lo demás es CS0.
Esta será la clasificación MF (Multi-Field).
- El procedimiento es el mismo, pero ahora haremos coincidir las ACL que desenganchan las categorías de tráfico necesarias, así que primero las creamos.
En Linkmeup_R2:
ip access-list extended TRISOLARANS_ICMP_ACL permit icmp any any ip access-list extended TRISOLARANS_TCP_ACL permit tcp any any ip access-list extended TRISOLARANS_OTHER_ACL permit ip any any
- A continuación, definimos los clasificadores:
class-map match-all TRISOLARANS_TCP_CM match access-group name TRISOLARANS_TCP_ACL class-map match-all TRISOLARANS_OTHER_CM match access-group name TRISOLARANS_OTHER_ACL class-map match-all TRISOLARANS_ICMP_CM match access-group name TRISOLARANS_ICMP_ACL
- Y ahora definimos las reglas de observación en política:
policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_ICMP_CM set ip dscp ef class TRISOLARANS_TCP_CM set ip dscp af11 class TRISOLARANS_OTHER_CM set ip dscp default
- Y colgamos la política en la interfaz. En la entrada, respectivamente, porque la decisión debe tomarse en la entrada a la red.
interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
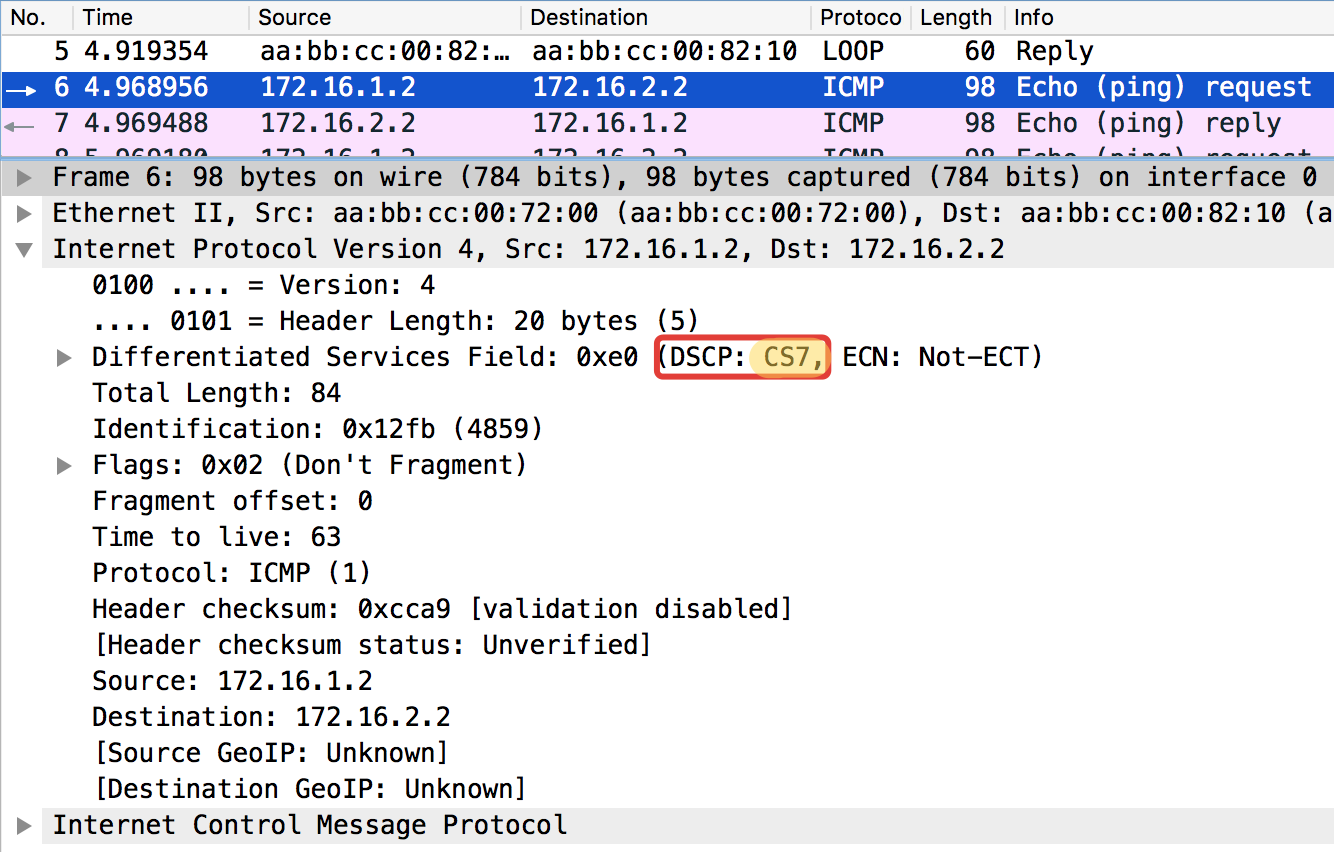
Prueba ICMP del anfitrión final Trisolaran1. No especificamos a sabiendas la clase: el valor predeterminado es 0.
Ya eliminé la política con Linkmeup_R1, por lo que el tráfico viene con la marca CS0, no CS7.
Aquí hay dos vertederos cercanos, con Linkmeup_R1 y Linkmeup_R2:
Linkmeup_R1. E0 / 0.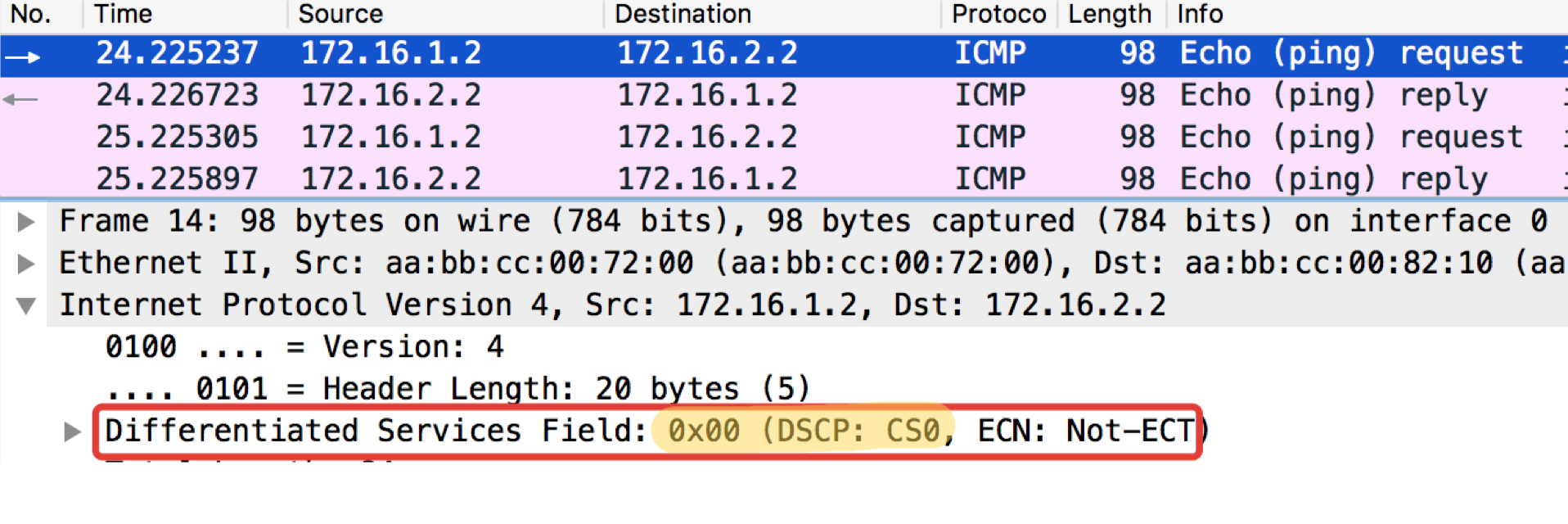 pcapngLinkmeup_R2. E0 / 0.
pcapngLinkmeup_R2. E0 / 0.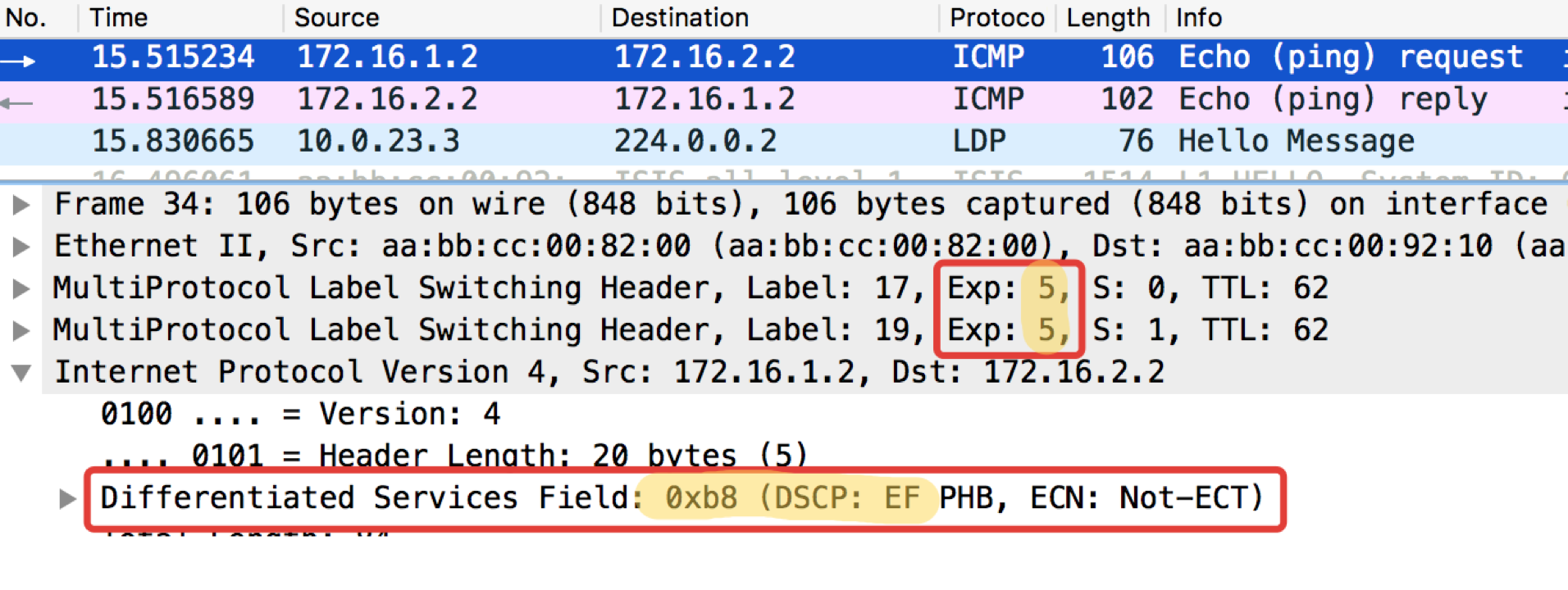 pcapng
pcapngSe puede ver que después de los clasificadores y el reetiquetado en Linkmeup_R2 en los paquetes ICMP, no solo DSCP cambió a EF, sino que la clase de tráfico MPLS se volvió igual a 5.
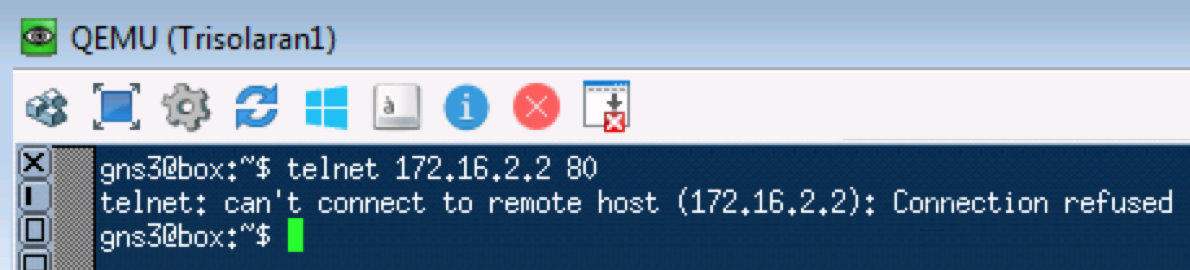
Una prueba similar con telnet 172.16.2.2. 80 - entonces verifique TCP:
 Linkmeup_R1. E0 / 0.
Linkmeup_R1. E0 / 0. pcapngLinkmeup_R2. E0 / 0.
pcapngLinkmeup_R2. E0 / 0.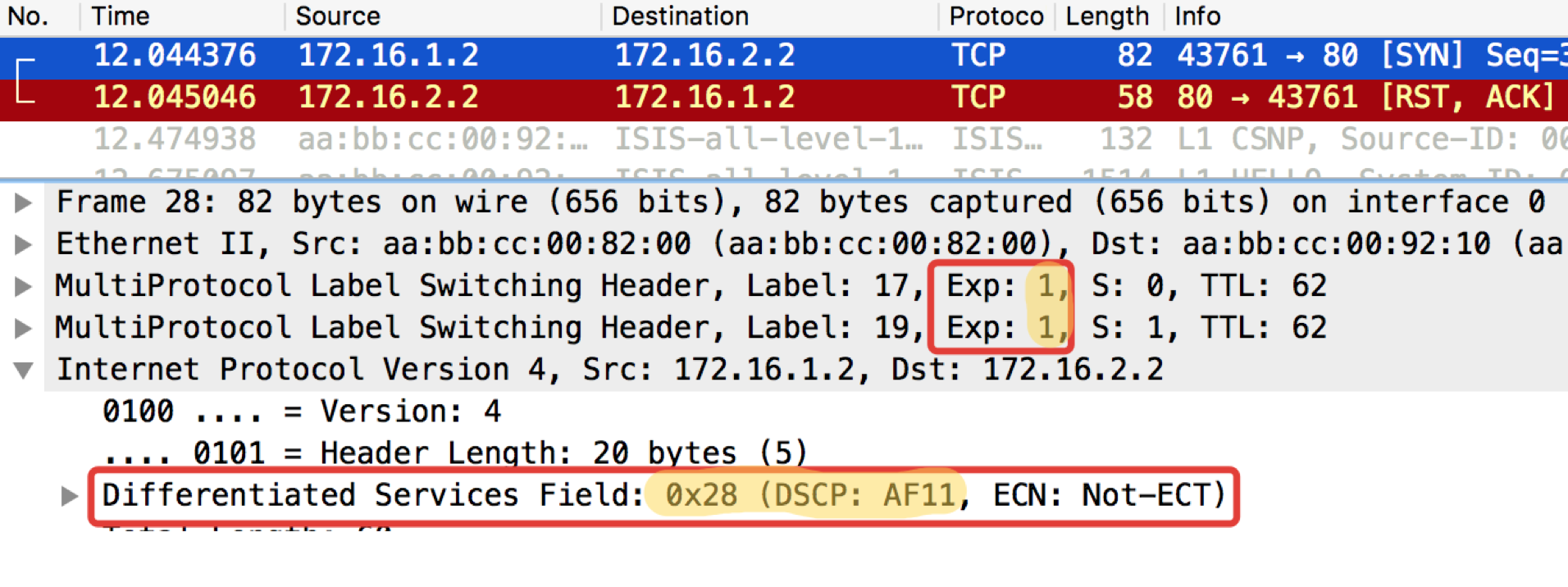 pcapng
pcapngLEA - Lo que se requiere para esperar. TCP se transmite como AF11.
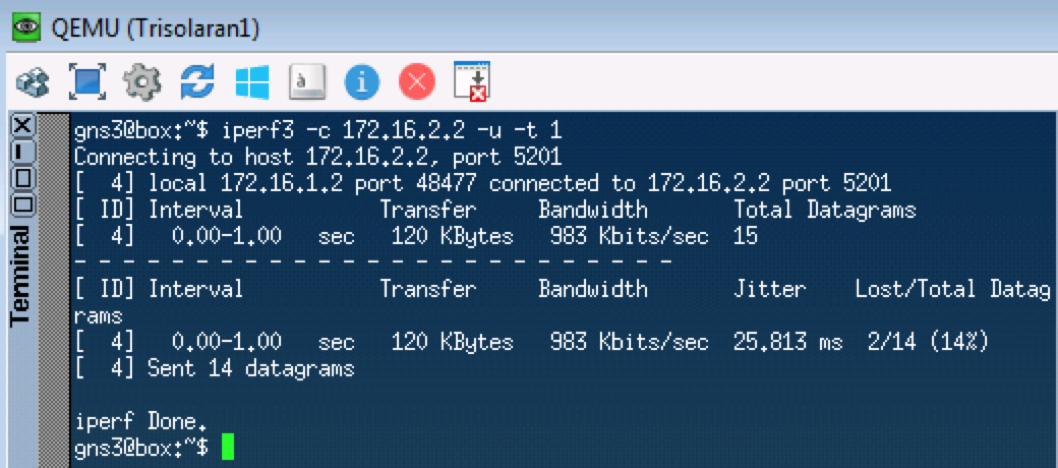
La próxima prueba probará UDP, que debería ir a CS0 de acuerdo con nuestros clasificadores. Usaremos iperf para esto (tráigalo a Linux Tiny Core a través de aplicaciones). En el lado remoto
iperf3 -s : inicie el servidor, en el
iperf3 local
-c -u -t1 - cliente (
-c ), protocolo UDP (
-u ), pruebe durante 1 segundo (
-t1 ).
 Linkmeup_R1. E0 / 0.
Linkmeup_R1. E0 / 0.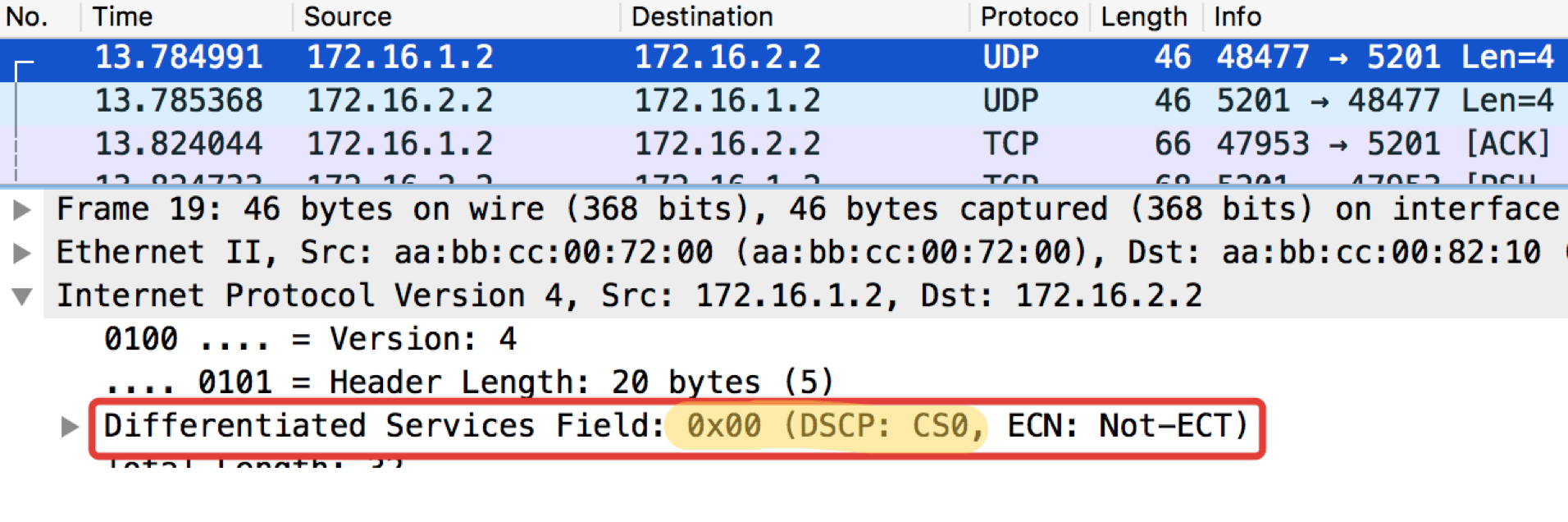 pcapngLinkmeup_R2. E0 / 0
pcapngLinkmeup_R2. E0 / 0 pcapng
pcapngDe ahora en adelante, todo lo que venga a esta interfaz se clasificará de acuerdo con las reglas configuradas.
Marcado dentro del dispositivo
Una vez más: en la entrada a la clasificación de dominio DS puede ocurrir MF, basado en interfaz o BA.
Entre los nodos del dominio DS, el paquete en el encabezado lleva un signo sobre la clase de servicio requerida y está clasificado por BA.
Independientemente del método de clasificación, después de esto, al paquete se le asigna una clase interna dentro del dispositivo, según la cual se procesa. El encabezado se elimina y el paquete desnudo (no) viaja a la salida.
Y en la salida, la clase interna se convierte en el campo CoS del nuevo encabezado.
Es decir, Título 1 ⇒ Clasificación ⇒ Clase interna de servicio ⇒ Título 2.
En algunos casos, debe mostrar el campo de encabezado de un protocolo en el campo de encabezado de otro, por ejemplo, DSCP en la clase de tráfico.
Esto sucede solo a través de la marca interna intermedia.
Por ejemplo, Encabezado de DSCP ⇒ Clasificación ⇒ Clase de servicio interno ⇒ Encabezado de clase de tráfico.
Formalmente, las clases internas se pueden llamar a su gusto, o simplemente numerarlas, y solo se les asigna una determinada cola.
En la profundidad a la que nos sumergimos en este artículo, no importa cómo se llamen, es importante que un modelo de comportamiento específico esté asociado con valores específicos de los campos de QoS.
Si estamos hablando de implementaciones específicas de QoS, entonces el número de clases de servicio que el dispositivo puede proporcionar no es más que el número de colas disponibles. A menudo hay ocho de ellos (ya sea bajo la influencia del IPP o, a veces, por acuerdo no escrito). Sin embargo, dependiendo del proveedor, dispositivo, placa, pueden ser más o menos.
Es decir, si hay 4 colas, entonces las clases de servicio simplemente no tienen sentido hacer más de cuatro.
Hablemos de esto con más detalle en el capítulo de hardware.
Si todavía quieres un poco de especificidad ...Las tablas a continuación pueden parecer convenientes a primera vista de la relación entre los campos de QoS y las clases internas, pero son algo engañosas al llamar a los nombres de las clases PHB. Aún así, PHB es qué tipo de modelo de comportamiento se asigna al tráfico de una determinada clase, cuyo nombre, en términos generales, es arbitrario.
Por lo tanto, consulte las tablas a continuación con una parte de escepticismo (por lo tanto, debajo del spoiler).
En el ejemplo de Huawei . Aquí, Service-Class es la clase muy interna del paquete.
Es decir, si BA se clasifica en la entrada, los valores de DSCP se traducirán a los valores de clase de servicio y color correspondientes.

Vale la pena prestar atención al hecho de que muchos valores DSCP no se utilizan, y los paquetes con tales marcas se procesan realmente como BE.
Aquí hay una tabla de correspondencia hacia atrás que muestra qué valores DSCP se establecerán para el tráfico cuando se vuelva a marcar la salida.

Tenga en cuenta que solo AF tiene una gradación de color. BE, EF, CS6, CS7: todo solo verde.
Esta es una tabla para convertir los campos IPP, MPLS Traffic Class y 802.1p Ethernet en clases de servicio interno.

Y de regreso.

Tenga en cuenta que cualquier información sobre la prioridad de caída generalmente se pierde aquí.
Debe repetirse: este es solo un ejemplo específico de coincidencias predeterminadas de proveedores seleccionados
al azar . Para otros, esto puede ser diferente. Los administradores pueden configurar clases de servicios y PHB completamente diferentes en su red.
En términos de PHB, no hay absolutamente ninguna diferencia en lo que se usa para la clasificación: DSCP, Traffic Class, 802.1p.
Dentro del dispositivo, se convierten en clases de tráfico definidas por el administrador de la red.
Es decir, todas estas marcas son una forma de decirle a los vecinos qué clase de servicio deberían asignar a este paquete. Se trata como BGP Community, que no significa nada por sí solo, hasta que la política para interpretarlos esté definida en la red.
Recomendaciones de IETF (categorías de tráfico, clases de servicio y comportamientos)
Las normas no estandarizan en absoluto qué clases de servicios particulares deberían existir, cómo clasificarlas y etiquetarlas, y qué PHB aplicarles.
Esto está a merced de los vendedores y administradores de red.
Tenemos solo 3 bits, los usamos como queremos.
Esto es bueno:
- Cada pieza de hierro (proveedor) elige independientemente qué mecanismos usar para PHB: sin señalización, sin problemas de compatibilidad.
- El administrador de cada red puede distribuir de manera flexible el tráfico entre diferentes clases, elegir las clases mismas y el PHB correspondiente.
Esto es malo
- En los límites de los dominios de DS, surgen problemas de conversión.
- En condiciones de completa libertad de acción, algunos están en el bosque, otros son demonios.
Por lo tanto, el IETF emitió en 2006 un manual de capacitación sobre cómo abordar la diferenciación de servicios:
RFC 4594 (
Pautas de configuración para las clases de servicio DiffServ ).
El siguiente es un breve resumen de este RFC.
Modelos de comportamiento (PHB)
DF - Reenvío predeterminadoEnvío estándarSi a un modelo de tráfico no se le asigna específicamente un modelo de comportamiento, se procesará utilizando el reenvío predeterminado.
Este es el mejor esfuerzo: el dispositivo hará todo lo posible, pero no garantiza nada. Son posibles caídas, desorden, retrasos impredecibles y fluctuación de fase flotante, pero esto no es exacto.
Este modelo es adecuado para aplicaciones poco exigentes, como el correo o la descarga de archivos.
Por cierto, hay PHB e incluso menos definido:
un esfuerzo más bajo .
AF: reenvío aseguradoEnvio garantizado.Este es un BE mejorado. Aquí aparecen algunas garantías, por ejemplo, bandas. Todavía son posibles caídas y retrasos flotantes, pero en un grado mucho menor.
El modelo es adecuado para multimedia: transmisión, videoconferencia, juegos en línea.
RFC 2597 (
Grupo PHB de reenvío asegurado ).
EF - Reenvío aceleradoEnvío de emergencia.Todos los recursos y prioridades se apresuran aquí. Este es un modelo para aplicaciones que no necesitan pérdidas, demoras cortas, fluctuaciones estables, pero no son codiciosos para la banda. Como, por ejemplo, telefonía o un servicio de emulación de cable (CES - Servicio de emulación de circuito).
Pérdidas, desordenes y retrasos flotantes en EF son extremadamente improbables.
RFC 3246 (
Un reenvío acelerado PHB ).
CS - Selector de claseEstos son comportamientos diseñados para mantener la compatibilidad con versiones anteriores de precedencia IP en redes capaces de DS.
Las siguientes clases existen en IPP: CS0, CS1, CS2, CS3, CS4, CS5, CS6, CS7.
No siempre para todos ellos hay un PHB separado, generalmente hay dos o tres, y el resto simplemente se traducen a la clase DSCP más cercana y obtienen el PHB correspondiente.
Entonces, por ejemplo, un paquete etiquetado CS 011000 puede clasificarse como 011010.
De los CS, seguramente solo CS6, CS7, que se recomiendan para NCP - Protocolo de control de red y requieren un PHB separado, se conservan en el equipo.
Al igual que EF, PHB CS6.7 está diseñado para clases que tienen requisitos de latencia y pérdida muy altos, pero que son algo tolerantes con la discriminación de banda.
La tarea de PHB para CS6.7 es proporcionar un nivel de servicio que elimine caídas y demoras incluso en caso de sobrecarga extrema de la interfaz, el chip y las colas.
Es importante entender que PHB es un concepto abstracto, y de hecho, se implementan a través de mecanismos disponibles en equipos reales.
Por lo tanto, el mismo PHB definido en el dominio DS puede diferir en Juniper y Huawei.
Además, un solo PHB no es un conjunto estático de acciones; por ejemplo, un AF PHB puede constar de varias opciones que difieren en el nivel de garantías (banda, retrasos aceptables).
Clases de servicio
El IETF se hizo cargo de los administradores e identificó las principales categorías de aplicaciones y sus clases de servicio.
No seré detallado aquí, solo inserte un par de placas de esta Guía RFC.Categorías de aplicación: Requisitos para las características de la red:
Requisitos para las características de la red: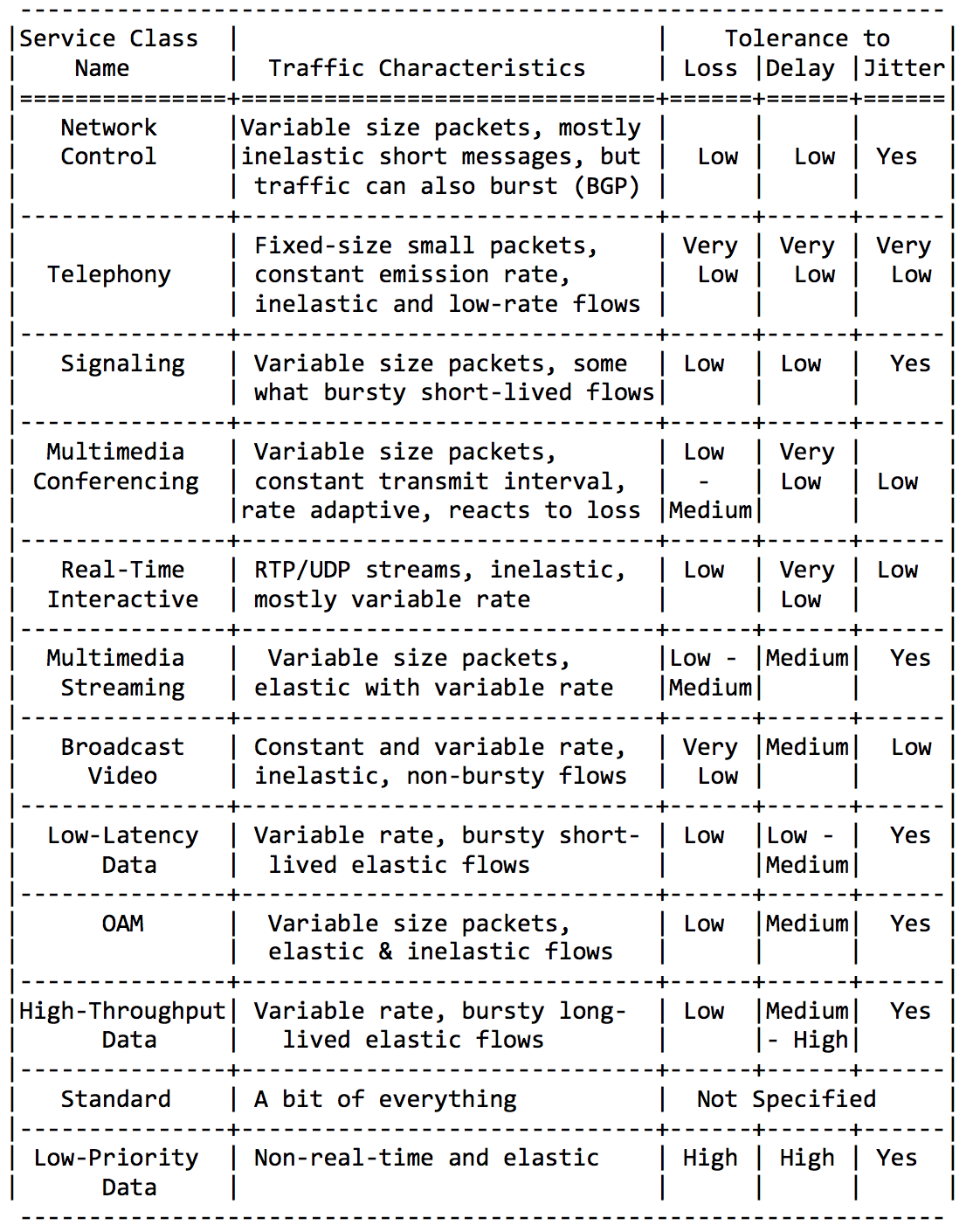 Y, por último, los nombres de clase recomendados y los valores DSCP correspondientes:
Y, por último, los nombres de clase recomendados y los valores DSCP correspondientes: Al combinar las clases anteriores de diferentes maneras (para adaptarse a los 8 disponibles), puede obtener soluciones de QoS para diferentes redes.Quizás lo más común es esto: la
Al combinar las clases anteriores de diferentes maneras (para adaptarse a los 8 disponibles), puede obtener soluciones de QoS para diferentes redes.Quizás lo más común es esto: la clase DF (o BE) marca un tráfico absolutamente poco exigente: recibe atención de forma residual.PHB AF sirve clases AF1, AF2, AF3, AF4. Todos deben proporcionar un carril, en detrimento de los retrasos y las pérdidas. Las pérdidas son controladas por los bits de Precedencia de caída, por lo que se llaman AFxy, donde x es la clase de servicio e y es Precedencia de caída.EF necesita algún tipo de garantía de banda mínima, pero lo más importante: una garantía de demoras, fluctuaciones y sin pérdidas.CS6, CS7 requieren incluso menos ancho de banda, ya que este es un conjunto de paquetes de servicio en los que todavía son posibles las ráfagas (actualización BGP, por ejemplo), pero las pérdidas y los retrasos son inaceptables: ¿cuál es el uso de BFD con un temporizador de 10 ms si Hello se bloquea? 100 ms colas?Es decir, 4 clases de 8 disponibles se dieron bajo AF.Y a pesar del hecho de que generalmente hacen exactamente eso, repito que estas son solo recomendaciones, y nada impide que tres clases en su dominio DS asignen EF y solo dos a AF.
clase DF (o BE) marca un tráfico absolutamente poco exigente: recibe atención de forma residual.PHB AF sirve clases AF1, AF2, AF3, AF4. Todos deben proporcionar un carril, en detrimento de los retrasos y las pérdidas. Las pérdidas son controladas por los bits de Precedencia de caída, por lo que se llaman AFxy, donde x es la clase de servicio e y es Precedencia de caída.EF necesita algún tipo de garantía de banda mínima, pero lo más importante: una garantía de demoras, fluctuaciones y sin pérdidas.CS6, CS7 requieren incluso menos ancho de banda, ya que este es un conjunto de paquetes de servicio en los que todavía son posibles las ráfagas (actualización BGP, por ejemplo), pero las pérdidas y los retrasos son inaceptables: ¿cuál es el uso de BFD con un temporizador de 10 ms si Hello se bloquea? 100 ms colas?Es decir, 4 clases de 8 disponibles se dieron bajo AF.Y a pesar del hecho de que generalmente hacen exactamente eso, repito que estas son solo recomendaciones, y nada impide que tres clases en su dominio DS asignen EF y solo dos a AF.
Resumen de clasificación
En la entrada a un nodo, un paquete se clasifica en función de una interfaz, MF o su etiquetado (BA).El etiquetado es el valor de los campos DSCP en IPv4, la clase de tráfico en IPv6 y en MPLS o 802.1p en 802.1q.Hay 8 clases de servicio que agregan varias categorías de tráfico. A cada clase se le asigna su propio PHB, satisfaciendo los requisitos de la clase.De acuerdo con las recomendaciones del IETF, se distinguen las siguientes clases de servicio: CS1, CS0, AF11, AF12, AF13, AF21, CS2, AF22, AF23, CS3, AF31, AF32, AF33, CS4, AF41, AF42, AF43, CS5, EF, CS6, CS7 en importancia creciente del tráfico.De ellos puede elegir una combinación de 8, que en realidad puede codificarse en campos CoS.La combinación más común: CS0, AF1, AF2, AF3, AF4, EF, CS6, CS7 con 3 gradaciones de color para la FA.A cada clase se le asigna un PHB, de los cuales hay 3: reenvío predeterminado, reenvío asegurado, reenvío acelerado en orden creciente de gravedad. Un poco aparte es el selector de clase PHB. Cada PHB puede variar según los parámetros de la herramienta, pero más sobre eso más adelante.
En una red descargada, QoS no es necesaria, dijeron. Dijeron que cualquier problema de QoS se resuelve expandiendo los enlaces. Con Ethernet y DWDM, nunca enfrentamos congestión de línea, dijeron.Son aquellos que no entienden qué es QoS.Pero la realidad golpea VPN en ILV.- No en todas partes hay ópticas. RRL es nuestra realidad. A veces, en el momento del accidente (y no solo) en el enlace de radio estrecho, desea rastrear todo el tráfico de la red.
- Las ráfagas de tráfico son nuestra realidad. Las ráfagas de tráfico a corto plazo se ponen en cola fácilmente, lo que obliga a descartar los paquetes muy necesarios.
- Telefonía, videoconferencia, juegos en línea son nuestra realidad. Si la cola está al menos algo ocupada, los retrasos comienzan a bailar.
En mi práctica, hubo ejemplos cuando la telefonía se convirtió en código Morse en una red cargada en no más del 40%. Solo volver a marcarlo en EF resolvió el problema momentáneamente.
Es hora de lidiar con herramientas que le permiten proporcionar diferentes servicios a diferentes clases.
Herramientas de PHB
En realidad, solo hay tres grupos de herramientas de QoS que manipulan activamente los paquetes:- Evitar la congestión: qué hacer para no ser malo.
- Gestión de la congestión: qué hacer cuando ya está mal.
- Limitación de velocidad: cómo no poner más en la red de lo que debería, y no liberar tanto como no pueden aceptar.
, .
5.
- , , .
.
, , .
.
( ) , , ( ), , - .
— — .
. , , . VoIP , 200. TCP , , RTT ( sysctl). — .
, .
, / , . , .
Si hay más tráfico del que puede manejar el chip de conmutación o la interfaz de salida, las colas comienzan a llenarse. Y la utilización crónica por encima del 20-30% ya es una situación que debe abordarse.
6. Evitar la congestión
En la vida de cualquier enrutador, llega un momento en que la cola está llena. Dónde colocar el paquete, si definitivamente no hay dónde colocarlo, eso es todo, el búfer ha terminado, no estará allí, incluso si es bueno para mirar, incluso si paga más.Hay dos formas: descartar este paquete o aquellos que ya han marcado el turno.Si ya están en la cola, considere lo que falta.Y si este, entonces considera que él no vino.Estos dos enfoques se llaman caída de cola y caída de cabeza .Tail Drop y Head Drop
Tail Drop , el mecanismo de gestión de colas más simple, descarta todos los paquetes recién llegados que no caben en el búfer. Head Drop descarta paquetes que han estado en cola durante mucho tiempo. Es mejor tirarlos a la basura que guardarlos, porque lo más probable es que sean inútiles. Pero los paquetes más relevantes que llegaron al final de la cola tendrán más posibilidades de llegar a tiempo. Además, Head Drop le permite no cargar la red con paquetes innecesarios. Naturalmente, los paquetes más antiguos son aquellos que están en la cabeza de la cola, de ahí el nombre del enfoque.
Head Drop descarta paquetes que han estado en cola durante mucho tiempo. Es mejor tirarlos a la basura que guardarlos, porque lo más probable es que sean inútiles. Pero los paquetes más relevantes que llegaron al final de la cola tendrán más posibilidades de llegar a tiempo. Además, Head Drop le permite no cargar la red con paquetes innecesarios. Naturalmente, los paquetes más antiguos son aquellos que están en la cabeza de la cola, de ahí el nombre del enfoque. Head Drop tiene otra ventaja no obvia: si deja caer el paquete al comienzo de la cola, el destinatario se enterará rápidamente de la congestión en la red e informará al remitente. En el caso de Tail Drop, la información sobre el paquete descartado alcanzará, posiblemente, cientos de milisegundos más tarde, hasta que llegue desde la cola de la línea hasta su cabeza.Ambos mecanismos funcionan con diferenciación a su vez. Es decir, de hecho, no es necesario que todo el búfer esté lleno. Si la segunda cola está vacía, y la cero a los globos oculares, solo se descartarán los paquetes del cero.
Head Drop tiene otra ventaja no obvia: si deja caer el paquete al comienzo de la cola, el destinatario se enterará rápidamente de la congestión en la red e informará al remitente. En el caso de Tail Drop, la información sobre el paquete descartado alcanzará, posiblemente, cientos de milisegundos más tarde, hasta que llegue desde la cola de la línea hasta su cabeza.Ambos mecanismos funcionan con diferenciación a su vez. Es decir, de hecho, no es necesario que todo el búfer esté lleno. Si la segunda cola está vacía, y la cero a los globos oculares, solo se descartarán los paquetes del cero. Tail Drop y Head Drop pueden funcionar simultáneamente.
Tail Drop y Head Drop pueden funcionar simultáneamente.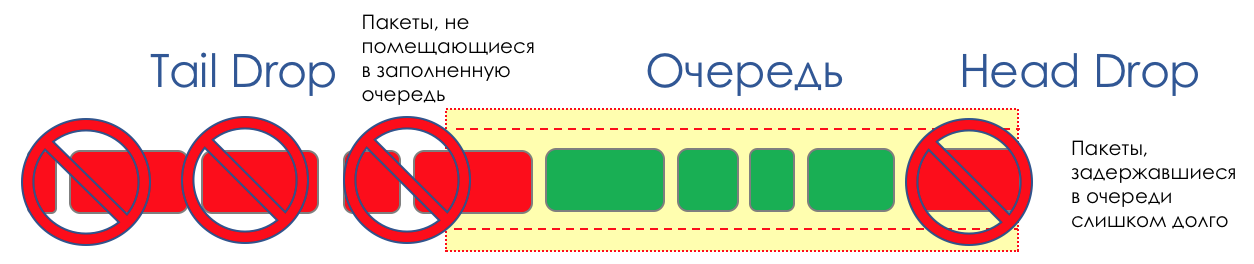
La cola y la caída de la cabeza son la "frente" para evitar la congestión. Incluso puedes decir: esta es su ausencia.No hacemos nada hasta que la cola esté 100% llena. Y después de eso, comenzamos a descartar todos los paquetes recién llegados (o retrasados por mucho tiempo).Si no necesita hacer nada para lograr el objetivo, en algún lugar hay un matiz.Y este matiz es TCP.Recordemos ( más profundo y extremadamente profundo ) cómo funciona TCP: estamos hablando de implementaciones modernas.Hay una Ventana deslizante (Ventana deslizante o rwnd - Ventana anunciada del receptor), que controla el destinatario, que le dice al remitente cuánto se puede enviar.Y hay una ventana de sobrecarga ( CWND - Ventana de congestión), que responde a problemas de red y es controlado por el remitente.El proceso de transferencia de datos comienza con un inicio lento ( Inicio lento ) con un aumento exponencial en CWND. Con cada segmento confirmado, se agrega 1 tamaño de MSS al CWND, es decir, se duplica en un tiempo igual a RTT (datos allí, ACK de regreso) (Discurso sobre Reno / NewReno).Por ejemplo
 El crecimiento exponencial continúa hasta un valor llamado ssthreshold (Umbral de inicio lento), que se especifica en la configuración de TCP en el host.A continuación, comienza un crecimiento lineal de 1 / CWND para cada segmento confirmado hasta que descanse contra RWND o comiencen las pérdidas (la pérdida se confirma mediante una nueva confirmación (ACK duplicado) o ninguna confirmación).Tan pronto como se detecta una pérdida de segmento, se produce un retroceso de TCP (TCP reduce drásticamente la ventana, en realidad reduce la velocidad de envío) y se inicia el mecanismo de recuperación rápida :
El crecimiento exponencial continúa hasta un valor llamado ssthreshold (Umbral de inicio lento), que se especifica en la configuración de TCP en el host.A continuación, comienza un crecimiento lineal de 1 / CWND para cada segmento confirmado hasta que descanse contra RWND o comiencen las pérdidas (la pérdida se confirma mediante una nueva confirmación (ACK duplicado) o ninguna confirmación).Tan pronto como se detecta una pérdida de segmento, se produce un retroceso de TCP (TCP reduce drásticamente la ventana, en realidad reduce la velocidad de envío) y se inicia el mecanismo de recuperación rápida :- enviar segmentos perdidos (retransmisión rápida),
- la ventana está doblada
- El valor umbral también se vuelve igual a la mitad de la ventana alcanzada,
- el crecimiento lineal comienza nuevamente hasta la primera pérdida,
- Repetir
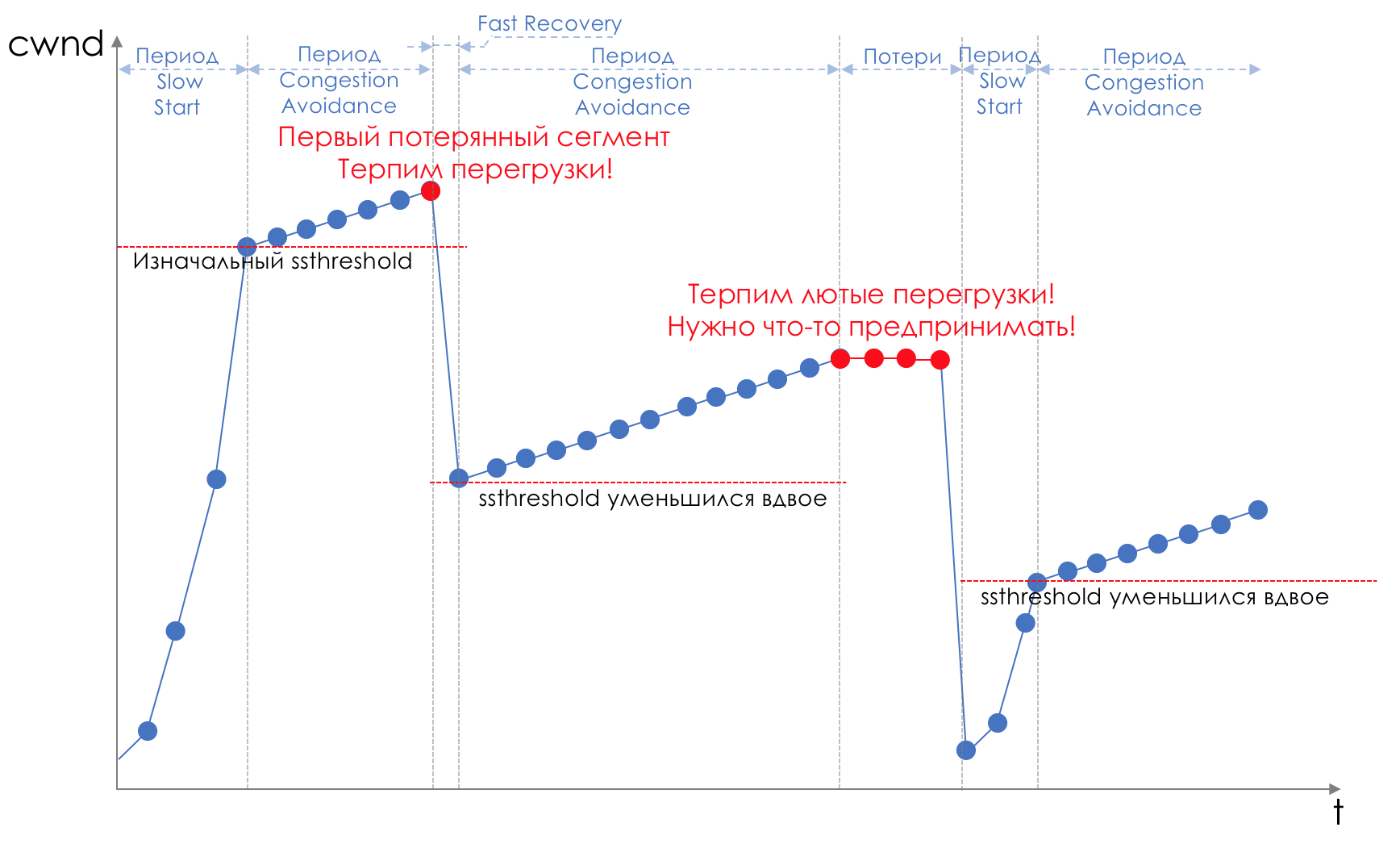 La pérdida puede significar el colapso completo de un segmento de red y luego considerar que está perdido, o la congestión en la línea (leer el desbordamiento del búfer y descartar un segmento de esta sesión).Este es el método de TCP para maximizar la utilización del ancho de banda disponible y tratar la congestión. Y es bastante efectivo.Sin embargo, ¿a qué conduce Tail Drop?
La pérdida puede significar el colapso completo de un segmento de red y luego considerar que está perdido, o la congestión en la línea (leer el desbordamiento del búfer y descartar un segmento de esta sesión).Este es el método de TCP para maximizar la utilización del ancho de banda disponible y tratar la congestión. Y es bastante efectivo.Sin embargo, ¿a qué conduce Tail Drop?- Digamos que a través de un enrutador se encuentra el camino de miles de sesiones TCP. En algún momento, el tráfico de sesión alcanzó 1.1 Gb / s, velocidad de interfaz de salida - 1 Gb / s.
- Tráfico viene más rápido que las hojas, las memorias intermedias están llenas vsklyan .
- Tail Drop se activa hasta que el despachador extraiga algunos paquetes de la cola.
- Fast Recovery ( Slow Start).
- , , Tail Drop .
- TCP- , .
- .
- Fast Recovery/Slow Start.
- .
Obtenga más información sobre los cambios en los mecanismos TCP en RFC 2001 ( inicio lento TCP, prevención de congestión, retransmisión rápida y algoritmos de recuperación rápida ).Esta es una ilustración típica de una situación llamada Sincronización global de TCP : Global porque muchas sesiones establecidas a través de este nodo sufren.Sincronización , porque sufren al mismo tiempo. Y la situación se repetirá hasta que haya una sobrecarga.TCP : porque UDP, que no tiene mecanismos de control de congestión, no se ve afectado por él.Nada malo habría sucedido en esta situación si no hubiera causado el uso subóptimo de la tira, los espacios entre los dientes de la sierra, el dinero desperdiciado.El segundo problema es el hambre TCP - agotamiento de TCP. Mientras que TCP se ralentiza para reducir la carga (no disimulemos, en primer lugar, para transmitir con seguridad nuestros datos), UDP, todo este sufrimiento moral en general por el datagrama, envía todo lo que puede.Entonces, la cantidad de tráfico TCP se reduce y UDP está creciendo (posiblemente), el próximo ciclo de Pérdida: la recuperación rápida ocurre en un umbral más bajo. UDP ocupa espacio. La cantidad total de tráfico TCP cae.Cómo resolver el problema, es mejor evitarlo. Intentemos reducir la carga antes de que se llene la cola usando la Recuperación rápida / Inicio lento, que acaba de estar en nuestra contra.
Global porque muchas sesiones establecidas a través de este nodo sufren.Sincronización , porque sufren al mismo tiempo. Y la situación se repetirá hasta que haya una sobrecarga.TCP : porque UDP, que no tiene mecanismos de control de congestión, no se ve afectado por él.Nada malo habría sucedido en esta situación si no hubiera causado el uso subóptimo de la tira, los espacios entre los dientes de la sierra, el dinero desperdiciado.El segundo problema es el hambre TCP - agotamiento de TCP. Mientras que TCP se ralentiza para reducir la carga (no disimulemos, en primer lugar, para transmitir con seguridad nuestros datos), UDP, todo este sufrimiento moral en general por el datagrama, envía todo lo que puede.Entonces, la cantidad de tráfico TCP se reduce y UDP está creciendo (posiblemente), el próximo ciclo de Pérdida: la recuperación rápida ocurre en un umbral más bajo. UDP ocupa espacio. La cantidad total de tráfico TCP cae.Cómo resolver el problema, es mejor evitarlo. Intentemos reducir la carga antes de que se llene la cola usando la Recuperación rápida / Inicio lento, que acaba de estar en nuestra contra.ROJO - Detección temprana aleatoria
Pero, ¿qué pasa si tomamos y untamos gotas en alguna parte del tampón?En términos relativos, comience a descartar paquetes aleatorios cuando la cola esté llena al 80%, lo que obligará a algunas sesiones TCP a reducir la ventana y, en consecuencia, la velocidad.Y si la cola está llena al 90%, comenzamos a descartar aleatoriamente el 50% de los paquetes.90%: la probabilidad aumenta hasta Tail Drop (se descarta el 100% de los paquetes nuevos).Los mecanismos que implementan dicha gestión de colas se denominan AQM - Gestión de colas adaptativa (o activa).Así es como funciona RED .Detección temprana : corrija la sobrecarga potencial;Aleatorio : descarta los paquetes al azar.A veces decodifican ROJO (en mi opinión, semánticamente más correctamente), como Aleatorio temprano descarte.Gráficamente, se ve así: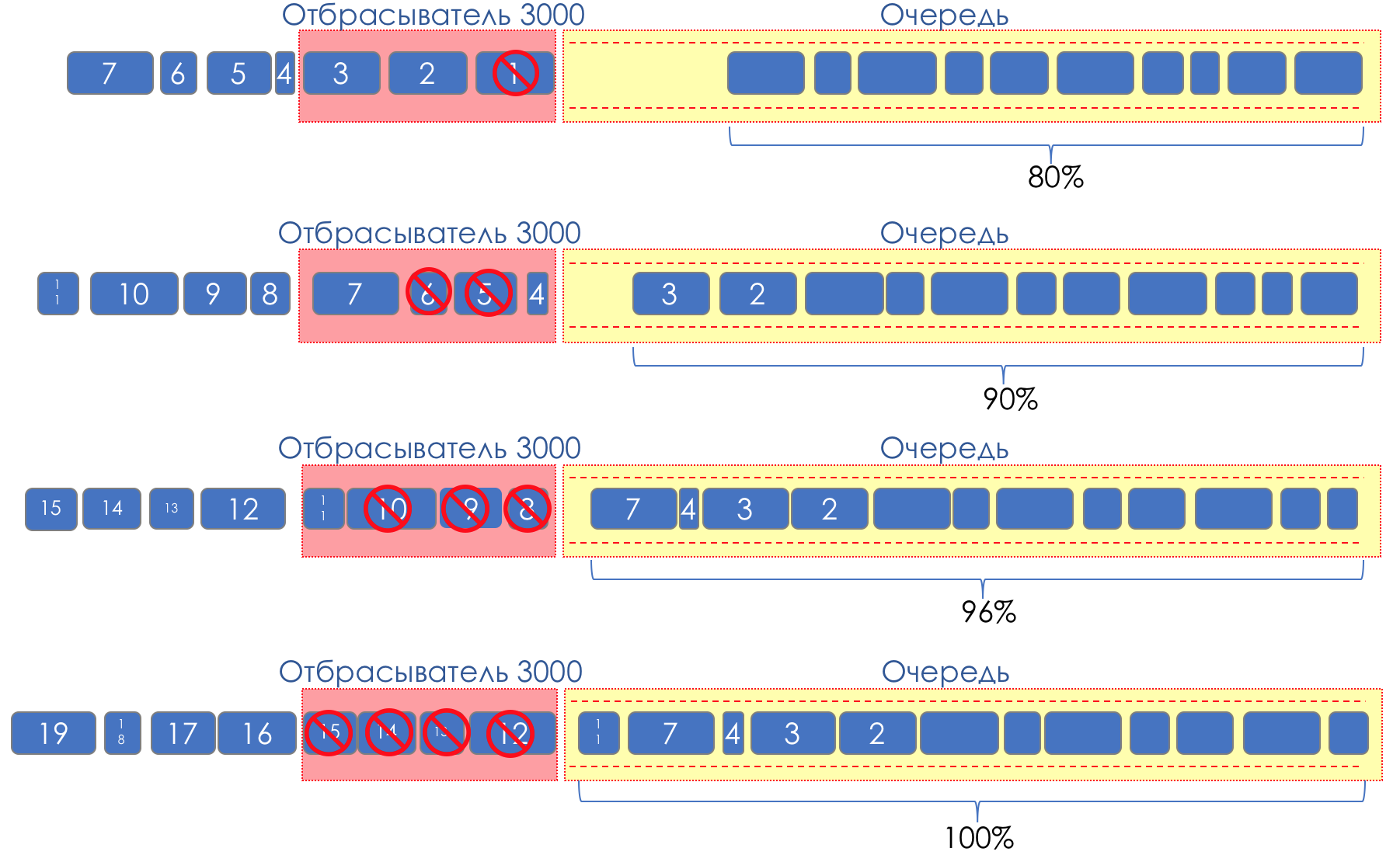
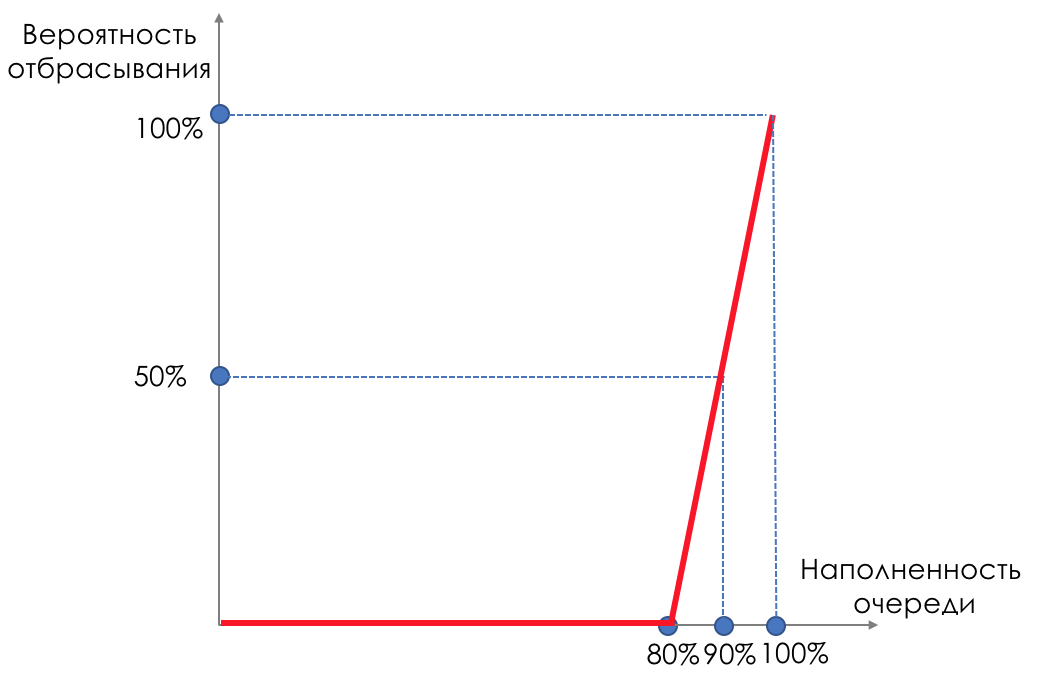 hasta que el búfer esté lleno al 80%, los paquetes no se descartan en absoluto; la probabilidad es 0%.De 80 a 100 paquetes comienzan a descartarse, y cuanto más, mayor es el llenado de la cola.Por lo tanto, el porcentaje crece de 0 a 30.Un efecto secundario de RED es que las sesiones TCP agresivas tienen más probabilidades de disminuir, simplemente porque hay muchos paquetes y es más probable que se descarten.La ineficiencia del uso de la tira ROJA se resuelve opacando una parte mucho más pequeña de las sesiones sin causar una reducción tan grave entre los dientes.Exactamente por la misma razón UDP no puede ocupar todo.
hasta que el búfer esté lleno al 80%, los paquetes no se descartan en absoluto; la probabilidad es 0%.De 80 a 100 paquetes comienzan a descartarse, y cuanto más, mayor es el llenado de la cola.Por lo tanto, el porcentaje crece de 0 a 30.Un efecto secundario de RED es que las sesiones TCP agresivas tienen más probabilidades de disminuir, simplemente porque hay muchos paquetes y es más probable que se descarten.La ineficiencia del uso de la tira ROJA se resuelve opacando una parte mucho más pequeña de las sesiones sin causar una reducción tan grave entre los dientes.Exactamente por la misma razón UDP no puede ocupar todo.WRED - Detección temprana aleatoria ponderada
Pero a la vista de todos, probablemente, todavía ESCRITO . El lector astuto de linkmeup ya ha sugerido que este es el mismo ROJO, pero ponderado por turnos. Y no tenía toda la razón.RED opera dentro de la misma cola. No tiene sentido mirar hacia atrás a EF si el BE está lleno. En consecuencia, pesar por turnos no traerá nada.Aquí Drop Precedence simplemente funciona.Y dentro de la misma cola, los paquetes con diferente prioridad de descarte tendrán diferentes curvas. Cuanto menor sea la prioridad, más probabilidades hay de que sea criticado. Aquí hay tres curvas:rojo: menos tráfico prioritario (en términos de caída), amarillo: más, verde: máximo.El tráfico rojo comienza a descartarse cuando el búfer está lleno en un 20%, de 20 a 40 se reduce al 20%, y luego Tail Drop.El amarillo comienza más tarde: de 30 a 50, se descarta hasta un 10%, luego, Tail Drop.El verde es el menos susceptible: de 50 a 100 crece sin problemas hasta el 5%. El siguiente es Tail Drop.En el caso de DSCP, esto podría ser AF11, AF12 y AF13, respectivamente verde, amarillo y rojo.
Aquí hay tres curvas:rojo: menos tráfico prioritario (en términos de caída), amarillo: más, verde: máximo.El tráfico rojo comienza a descartarse cuando el búfer está lleno en un 20%, de 20 a 40 se reduce al 20%, y luego Tail Drop.El amarillo comienza más tarde: de 30 a 50, se descarta hasta un 10%, luego, Tail Drop.El verde es el menos susceptible: de 50 a 100 crece sin problemas hasta el 5%. El siguiente es Tail Drop.En el caso de DSCP, esto podría ser AF11, AF12 y AF13, respectivamente verde, amarillo y rojo. Aquí es muy importante que funcione con TCP y no sea aplicable en absoluto a UDP.O una aplicación que usa UDP ignora las pérdidas, como en el caso de la telefonía o la transmisión de video, y esto afecta negativamente lo que ve el usuario.O la aplicación controla la entrega y le pide que vuelva a enviar el mismo paquete. Sin embargo, no tiene que pedirle a la fuente que baje la velocidad de transmisión. Y en lugar de reducir la carga, un aumento se debe a las retransmisiones.Es por eso que solo se usa Tail Drop para EF.Para CS6, CS7, también se usa Tail Drop, ya que no se supone que haya altas velocidades y WRED no resolverá nada.Para AF, se aplica WRED. AFxy, donde x es la clase del servicio, es decir, la cola en la que cae, e y es la prioridad de caída: el mismo color.Para BE, la decisión se toma en función del tráfico predominante en esta cola.Dentro de un solo enrutador, se usa un etiquetado de paquete interno especial, diferente del que lleva los encabezados. Por lo tanto, MPLS y 802.1q, donde no es posible codificar la Precedencia de caída, se pueden procesar en colas con diferentes prioridades de caída.Por ejemplo, un paquete MPLS llegó a un nodo, no lleva el etiquetado Drop Precedence, sin embargo, de acuerdo con los resultados del pulido, resultó ser amarillo y se puede descartar antes de colocarlo en la cola (que puede determinarse mediante el campo Clase de tráfico).Vale la pena recordar que todo este arco iris existe solo dentro del nodo. No existe un concepto de color en la línea entre vecinos.Aunque es posible, por supuesto, codificar el color en la parte de Precedencia de caída de DSCP.
Aquí es muy importante que funcione con TCP y no sea aplicable en absoluto a UDP.O una aplicación que usa UDP ignora las pérdidas, como en el caso de la telefonía o la transmisión de video, y esto afecta negativamente lo que ve el usuario.O la aplicación controla la entrega y le pide que vuelva a enviar el mismo paquete. Sin embargo, no tiene que pedirle a la fuente que baje la velocidad de transmisión. Y en lugar de reducir la carga, un aumento se debe a las retransmisiones.Es por eso que solo se usa Tail Drop para EF.Para CS6, CS7, también se usa Tail Drop, ya que no se supone que haya altas velocidades y WRED no resolverá nada.Para AF, se aplica WRED. AFxy, donde x es la clase del servicio, es decir, la cola en la que cae, e y es la prioridad de caída: el mismo color.Para BE, la decisión se toma en función del tráfico predominante en esta cola.Dentro de un solo enrutador, se usa un etiquetado de paquete interno especial, diferente del que lleva los encabezados. Por lo tanto, MPLS y 802.1q, donde no es posible codificar la Precedencia de caída, se pueden procesar en colas con diferentes prioridades de caída.Por ejemplo, un paquete MPLS llegó a un nodo, no lleva el etiquetado Drop Precedence, sin embargo, de acuerdo con los resultados del pulido, resultó ser amarillo y se puede descartar antes de colocarlo en la cola (que puede determinarse mediante el campo Clase de tráfico).Vale la pena recordar que todo este arco iris existe solo dentro del nodo. No existe un concepto de color en la línea entre vecinos.Aunque es posible, por supuesto, codificar el color en la parte de Precedencia de caída de DSCP.Las gotas también pueden aparecer en una red descargada, donde parecería que no debería haber un desbordamiento de cola. Como?
La razón de esto puede ser ráfagas cortas - ráfagas - de tráfico. El ejemplo más simple: 5 aplicaciones al mismo tiempo decidieron transferir tráfico a un host final.
Un ejemplo es más complicado: el remitente está conectado a través de la interfaz de 10 Gb / s, y el receptor es de 1 Gb / s. El entorno en sí le permite crear paquetes más rápido en el remitente. El control de flujo Ethernet del receptor le pide al host más cercano que disminuya la velocidad, y los paquetes comienzan a acumularse en las memorias intermedias.
Bueno, ¿qué hacer cuando todo empeora?7. Manejo de la congestión
Cuando todo está mal, se debe dar prioridad de procesamiento al tráfico más importante. La importancia de cada paquete se determina en la etapa de clasificación.Pero que es malo?No todas las memorias intermedias deben estar obstruidas para que las aplicaciones comiencen a experimentar problemas.El ejemplo más simple son los paquetes de voz, que se agrupan en grandes paquetes de paquetes grandes de una aplicación que descarga un archivo.Esto aumentará el retraso, arruinará la inquietud y posiblemente provocará caídas.Es decir, tenemos problemas para proporcionar servicios de calidad en ausencia de congestión real.Este problema está diseñado para resolver el mecanismo de gestión de congestión.El tráfico de diferentes aplicaciones se divide en colas, como vimos anteriormente.Pero solo como resultado, todo debería fusionarse nuevamente en una interfaz. La serialización todavía ocurre secuencialmente.¿Cómo se las arreglan las diferentes colas para proporcionar diferentes niveles de servicios?Eliminar paquetes de diferentes colas de diferentes maneras.El despachador se dedica a esto.Consideraremos la mayoría de los despachadores hoy, comenzando con el más simple:- FIFO - solo una línea, todo en BE, C - injusticia.
- PQ: el camino hacia los oligarcas, los lacayos ceden.
- FQ: todos son iguales.
- DWRR: todos son iguales, pero algunos son más uniformes.
FIFO - Primero en entrar, primero en salir
El caso más simple, de hecho, la ausencia de QoS, es que todo el tráfico se maneja de la misma manera, en una cola.Los paquetes salen de la cola exactamente en el orden en que llegaron, de ahí el nombre: primero ingresado - primero y a la izquierda .FIFO no es un despachador en el sentido completo de la palabra, ni un mecanismo DiffServ en general, ya que en realidad no separa las clases.Si la cola comienza a llenarse, los retrasos y la inquietud comienzan a crecer, no puede manejarlos, porque no puede extraer un paquete importante del centro de la cola.Las sesiones TCP agresivas con un tamaño de paquete de 1,500 bytes pueden ocupar toda la cola, causando que los pequeños paquetes de voz se vean afectados.En FIFO, todas las clases se fusionan en CS0. Sin embargo, a pesar de todas estas deficiencias, así es como funciona ahora Internet.La mayoría de los proveedores FIFO son ahora el despachador predeterminado con una cola para todo el tráfico de tránsito y una más para los paquetes de servicios generados localmente.Es simple, es extremadamente barato. Si los canales son anchos y hay poco tráfico, todo está bien.La quintaesencia de la idea de que QoS, para los pobres, expande la banda, y los clientes estarán satisfechos, y su salario aumentará en múltiples.Solo así los equipos de red funcionaron una vez.Pero muy pronto el mundo se enfrentó al hecho de que simplemente no funcionaría.Con la tendencia hacia las redes convergentes, quedó claro que los diferentes tipos de tráfico (servicio, voz, multimedia, navegación por Internet, uso compartido de archivos) tienen requisitos de red fundamentalmente diferentes.FIFO no fue suficiente, por lo que crearon varias colas y comenzaron a producir esquemas de programación de tráfico.Sin embargo, FIFO nunca deja nuestras vidas: dentro de cada una de las colas, los paquetes siempre se procesan de acuerdo con el principio FIFO.
Sin embargo, a pesar de todas estas deficiencias, así es como funciona ahora Internet.La mayoría de los proveedores FIFO son ahora el despachador predeterminado con una cola para todo el tráfico de tránsito y una más para los paquetes de servicios generados localmente.Es simple, es extremadamente barato. Si los canales son anchos y hay poco tráfico, todo está bien.La quintaesencia de la idea de que QoS, para los pobres, expande la banda, y los clientes estarán satisfechos, y su salario aumentará en múltiples.Solo así los equipos de red funcionaron una vez.Pero muy pronto el mundo se enfrentó al hecho de que simplemente no funcionaría.Con la tendencia hacia las redes convergentes, quedó claro que los diferentes tipos de tráfico (servicio, voz, multimedia, navegación por Internet, uso compartido de archivos) tienen requisitos de red fundamentalmente diferentes.FIFO no fue suficiente, por lo que crearon varias colas y comenzaron a producir esquemas de programación de tráfico.Sin embargo, FIFO nunca deja nuestras vidas: dentro de cada una de las colas, los paquetes siempre se procesan de acuerdo con el principio FIFO.PQ - Colas de prioridad
El segundo mecanismo más complicado e intentar dividir el servicio en clases es una cola prioritaria .El tráfico ahora se presenta en varias colas según su prioridad de clase (por ejemplo, aunque no necesariamente, el mismo BE, AF1-4, EF, CS6-7). El despachador pasa por una cola tras otra.Primero, omite todos los paquetes de la cola de mayor prioridad, luego de menos, luego de menos. Y así en un círculo.
El despachador no comienza a recuperar paquetes de baja prioridad hasta que la cola de alta prioridad esté vacía. Si, en el momento de procesar paquetes de baja prioridad, un paquete llega a una cola de mayor prioridad, el despachador cambia a él y solo después de vaciarlo regresa a los demás.
Si, en el momento de procesar paquetes de baja prioridad, un paquete llega a una cola de mayor prioridad, el despachador cambia a él y solo después de vaciarlo regresa a los demás. PQ funciona casi tan bien como FIFO.Es ideal para tipos de tráfico como paquetes de protocolo y voz, donde los retrasos son críticos y el volumen total no es muy grande.Bueno, debes admitir que no deberías quedarte con BFD Hello debido al hecho de que han aparecido varios fragmentos grandes de video de YouTube.Pero aquí radica la falta de PQ: si la cola de prioridad está cargada de tráfico, el despachador nunca cambiará a otros.Y si algún Doctor Evil, en busca de métodos para conquistar el mundo, decide marcar todo su tráfico villano con la marca negra más alta, todos los demás esperarán obedientemente y luego serán descartados.Tampoco es necesario hablar de un carril garantizado para cada línea.Las colas de alta prioridad se pueden reducir por la velocidad del tráfico procesado en ellas. Entonces otros no morirán de hambre. Sin embargo, controlar esto no es fácil.
PQ funciona casi tan bien como FIFO.Es ideal para tipos de tráfico como paquetes de protocolo y voz, donde los retrasos son críticos y el volumen total no es muy grande.Bueno, debes admitir que no deberías quedarte con BFD Hello debido al hecho de que han aparecido varios fragmentos grandes de video de YouTube.Pero aquí radica la falta de PQ: si la cola de prioridad está cargada de tráfico, el despachador nunca cambiará a otros.Y si algún Doctor Evil, en busca de métodos para conquistar el mundo, decide marcar todo su tráfico villano con la marca negra más alta, todos los demás esperarán obedientemente y luego serán descartados.Tampoco es necesario hablar de un carril garantizado para cada línea.Las colas de alta prioridad se pueden reducir por la velocidad del tráfico procesado en ellas. Entonces otros no morirán de hambre. Sin embargo, controlar esto no es fácil.
Los siguientes mecanismos pasan por todas las colas a su vez, tomando de ellos una cierta cantidad de datos, proporcionando así condiciones más honestas. Pero lo hacen de manera diferente.FQ-Fair Queuing
El siguiente contendiente para el papel de un despachador ideal son los mecanismos de cola justos .FQ - Colas justas
Su historia comenzó en 1985, cuando John Nagle sugirió crear una cola para cada flujo de datos. En espíritu, esto está cerca del enfoque IntServ y se explica fácilmente por el hecho de que la idea de clases de servicio, como DiffServ, no existía entonces.FQ extrajo la misma cantidad de datos de cada cola en orden.La honestidad radica en el hecho de que el despachador no opera con la cantidad de paquetes, sino con la cantidad de bits que se pueden transmitir desde cada cola.Por lo tanto, una secuencia TCP agresiva no puede inundar la interfaz y todos tienen las mismas oportunidades.En teoría FQ nunca se implementó en la práctica como un mecanismo para despachar colas en equipos de red.Hay tres inconvenientes:— — — , .
— — . ?
— — FQ : , , .
, 256 , , 256-.
.
, - 3- , .
La descripción de los mecanismos bit a bit de Round Robin y GPS ya está fuera del alcance de este artículo, y remito al lector a un estudio independiente .WFQ - Colas justas ponderadas
Las fallas segunda y parcialmente tercera de la FQ intentaron cerrar la WFQ, publicada en 1989.Cada cola estaba dotada de peso y, en consecuencia, el derecho a dar tráfico en múltiplos de peso para un ciclo.El peso se calculó sobre la base de dos parámetros: sigue siendo relevante, luego la precedencia de IP y la longitud del paquete.En el contexto de WFQ, cuanto más peso, peor.Por lo tanto, cuanto mayor sea la precedencia de IP, menor será el peso del paquete.Cuanto más pequeño es el tamaño del paquete, más pequeño es su peso.Por lo tanto, los paquetes pequeños de alta prioridad obtienen la mayor cantidad de recursos, mientras que los gigantes de baja prioridad están esperando., , , . , , , .

WFQ, packet finish time,
.
. Flow Based , , , .
Sin embargo, esto no impidió que WFQ se usara en algunos dispositivos Cisco (en su mayoría viejos). Hubo hasta 256 colas en las que se colocaron hilos en función del hash de sus encabezados. Un compromiso entre el paradigma basado en el flujo y los recursos limitados.CBWFQ - WFQ basado en clase
CBWFQ hizo el enfoque del problema de complejidad con la llegada de DiffServ. Comportamiento agregado clasificó todas las categorías de tráfico en 8 clases y, en consecuencia, colas. Esto le dio un nombre y una cola muy simplificada.El peso en CBWFQ ha adquirido un significado diferente. El peso se asignó a clases (no hilos) manualmente en la configuración a solicitud del administrador, porque el campo DSCP ya se usaba para la clasificación.Es decir, DSCP determinó en qué cola colocar y el peso configurado: cuántas bandas hay disponibles para esta cola.Lo más importante, esto indirectamente hizo la vida un poco más fácil y los flujos de baja latencia, que ahora se agregaron en una (dos-tres- ...) colas y recibieron sus puntos más altos con mucha más frecuencia. La vida ha mejorado, pero aún no es buena, no hay garantías, en general, en WFQ todo sigue igual en términos de demoras.Y la necesidad de un monitoreo constante del tamaño de los paquetes, su fragmentación y desfragmentación, no ha desaparecido.CBWFQ + LLQ - Cola de baja latencia
El enfoque final, la culminación de un enfoque bit a bit, es la unión de CBWFQ con PQ.Una de las colas se convierte en la llamada LLQ (cola de baja latencia), y mientras que todas las otras colas son procesadas por el administrador CBWFQ, el administrador PQ se ejecuta entre las LLQ y el resto.Es decir, mientras hay paquetes en LLQ, las colas restantes están esperando, sus retrasos aumentan. Tan pronto como se agotaron los paquetes en LLQ, fuimos a procesar el resto. Los paquetes aparecieron en LLQ: se olvidaron del resto y volvieron a él.FIFO también funciona dentro de LLQ, por lo que no debe empujar todo sin llegar allí, aumentando la utilización del búfer y el retraso al mismo tiempo.Sin embargo, para que las colas no prioritarias no se mueran de hambre, vale la pena establecer un límite de ancho de banda en LLQ. Entonces las ovejas están llenas y los lobos están a salvo.
Entonces las ovejas están llenas y los lobos están a salvo.RR - Round-Robin
FQ
RR .
, . .

RR , . , FQ, . 1500 .
— , .
— Round-Robin .
WRR — Weighted Round Robin
WRR, IP Precedence. WRR , .
, .

DWRR — Deficit Weighted Round Robin
, 1995- M. Shreedhar and G. Varghese.
.
, .
, .
, , . , .
, , -, .
,
.
Para diferentes colas, el cuanto es diferente: cuanto mayor sea la banda que necesita dar, mayor será el cuanto.Por lo tanto, todas las colas reciben un ancho de banda garantizado, independientemente del tamaño de los paquetes que contiene.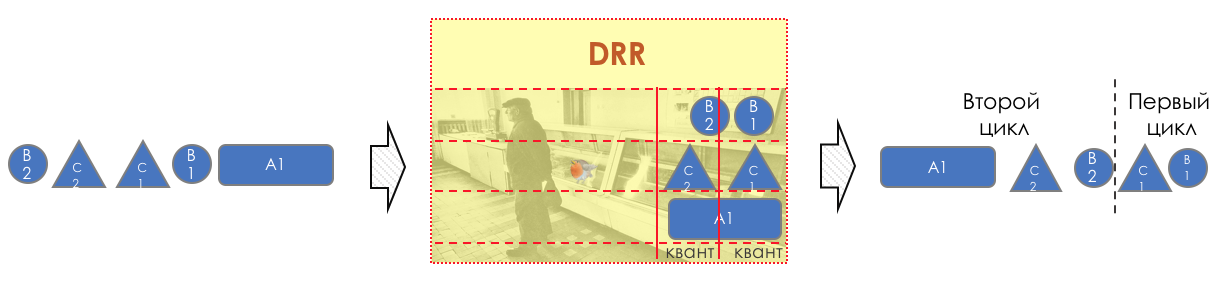 De la explicación anterior, no me quedaría claro cómo funciona esto.
De la explicación anterior, no me quedaría claro cómo funciona esto.Dibujemos los pasos ...:
- DRR ( W),
- 4 ,
- 0- 500 ,
- 1- — 1000,
- 2- 1500,
- 3- 4000,
- — 1600 .

1
1. 0, 1600 ()
0- . :
— (1600 — 500 = 1100).
— — (1100 — 500 = 600).
— — (600 — 500 = 100).
— (100 — 500 = -400). .
— 100 .
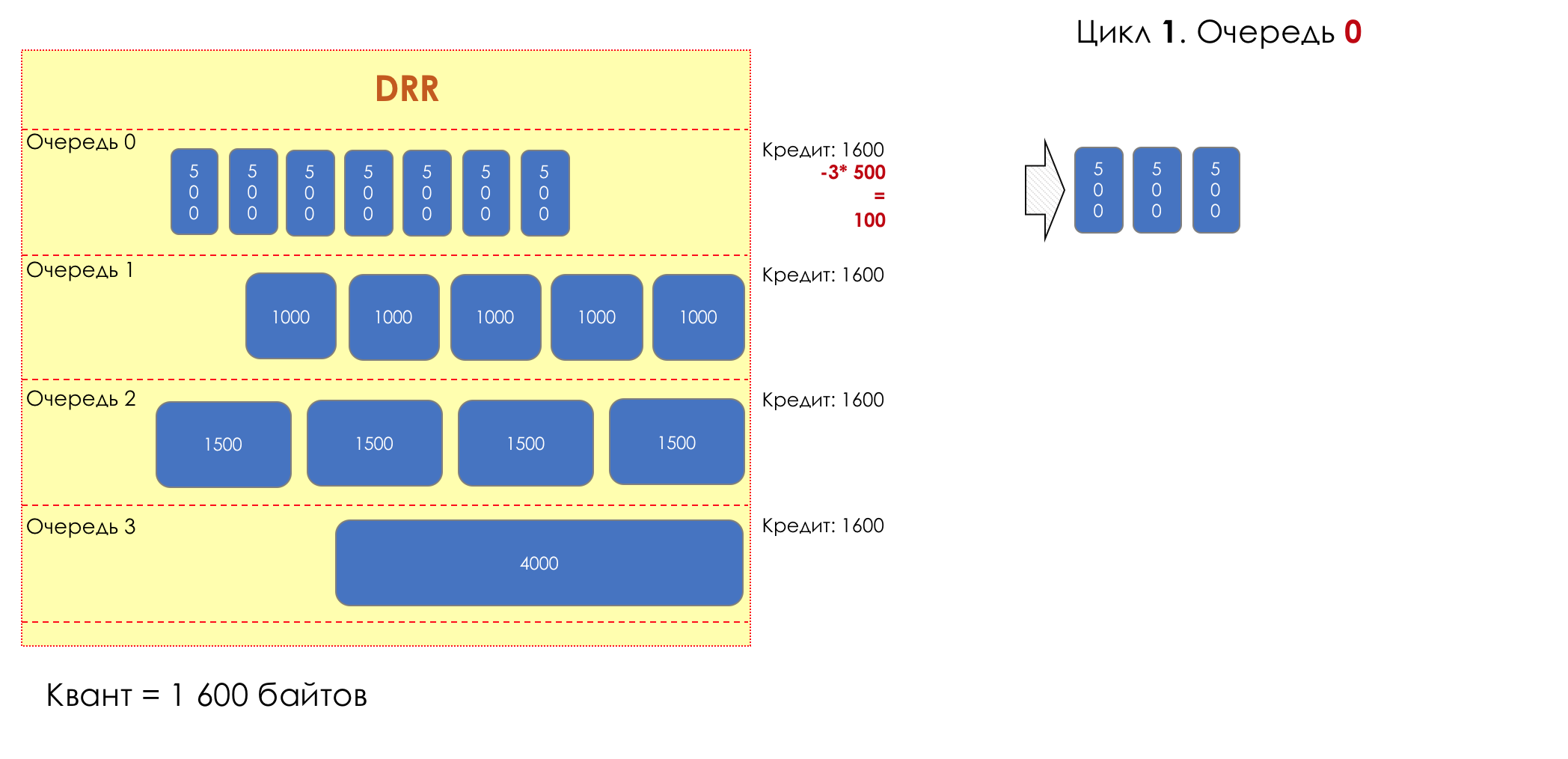 1. 1
1. 1— (1600 — 1000 = 600).
(600 — 1000 = -400). .
— 600 .
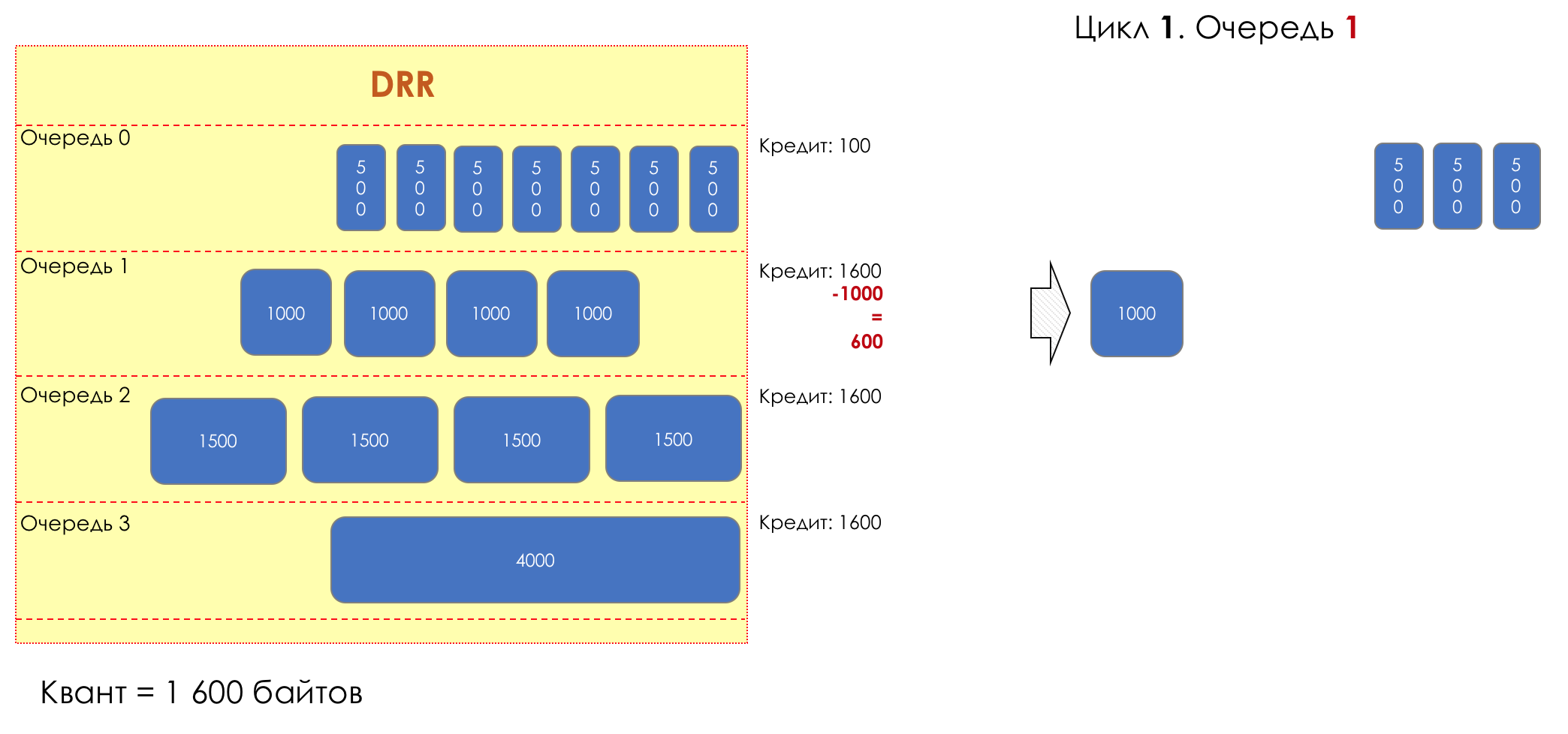 1. 2
1. 2— (1600 — 1500 = 100).
(100 — 1000 = -900). .
— 100 .
 1. 3
1. 3. (1600 — 4000 = -2400).
.
— 1600 .
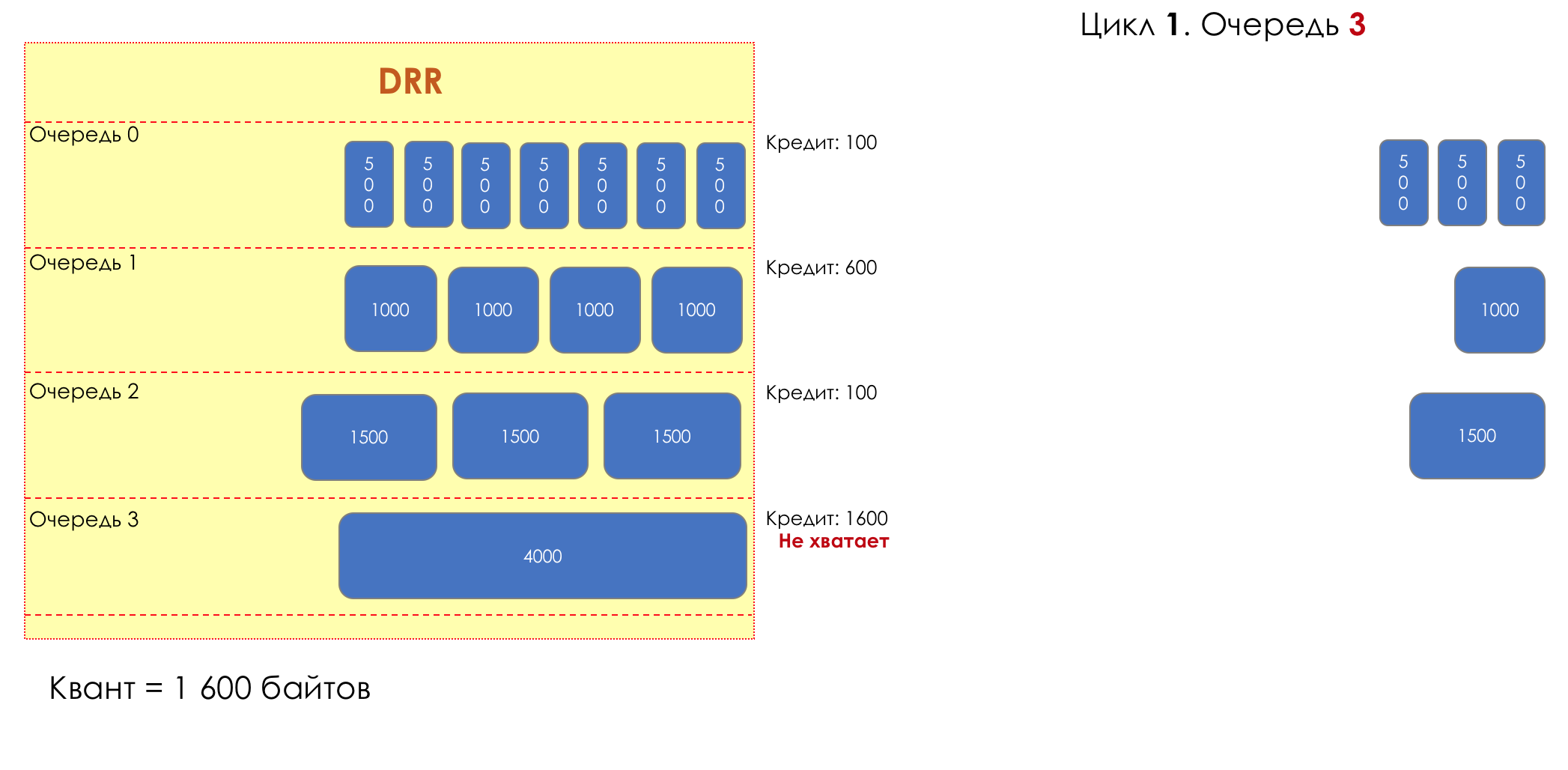
, :
- 0 — 1500
- 1 — 1000
- 2 — 1500
- 3 — 0
:
- 0 — 100
- 1 — 600
- 2 — 100
- 3 — 1600
2
— 1600 .
2. 01700 (100 + 1600).
— (1700 — 3*500 = 200).
.
— 200 .
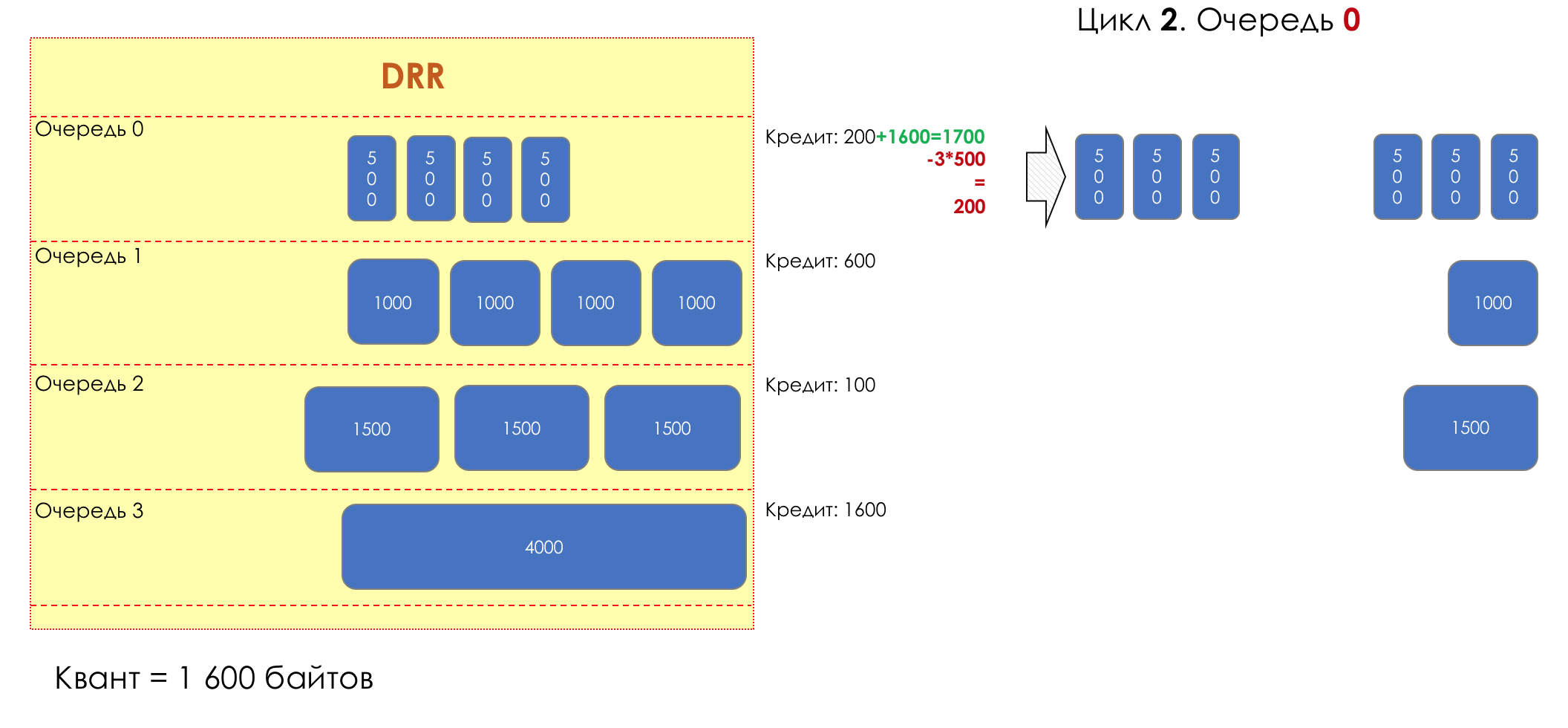 2. 1
2. 12200 (600 + 1600).
— (2200 — 2*1000 = 200).
.
— 200 .
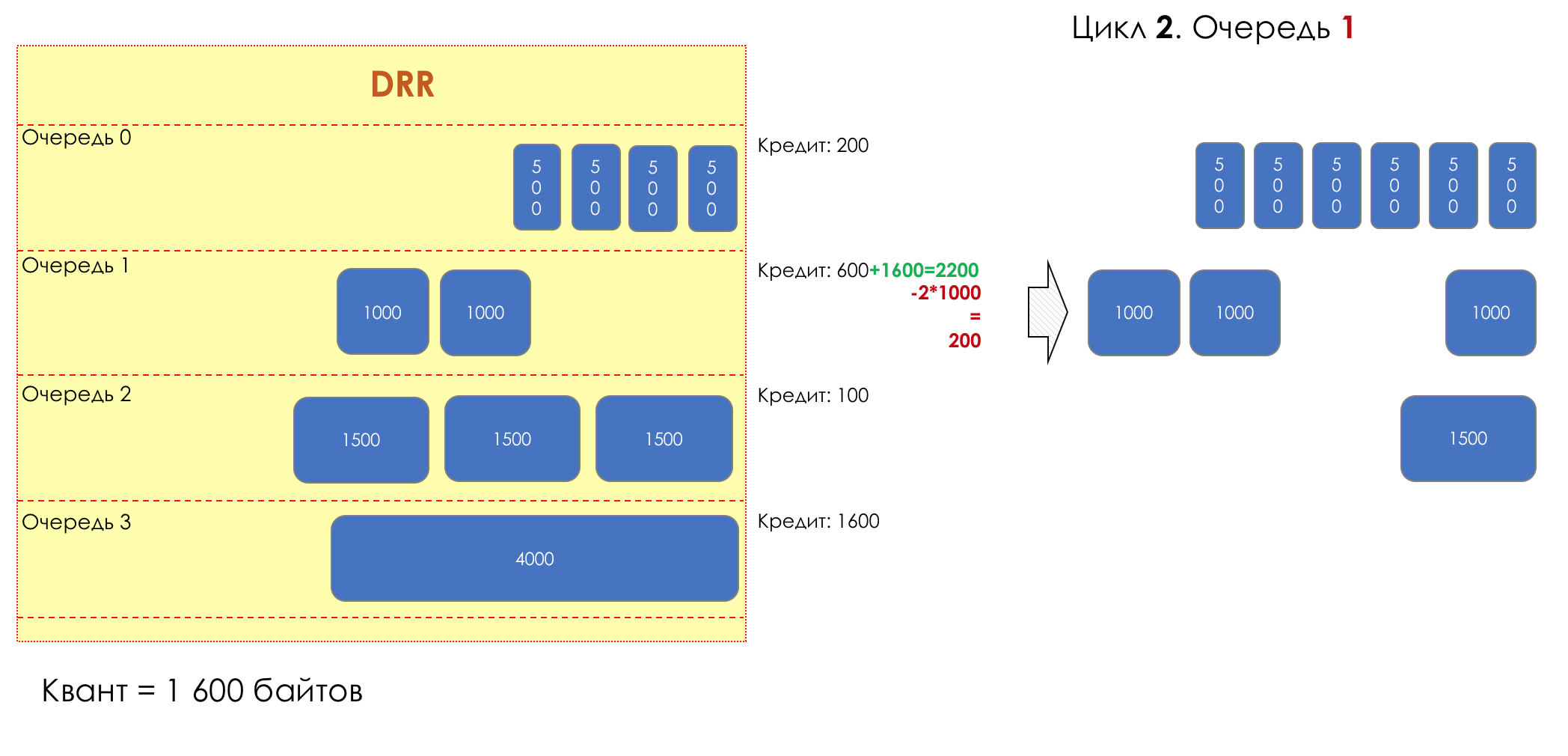 2. 2
2. 21700 (100 + 1600).
— (2200 — 1500 = 200).
— .
— 200 .
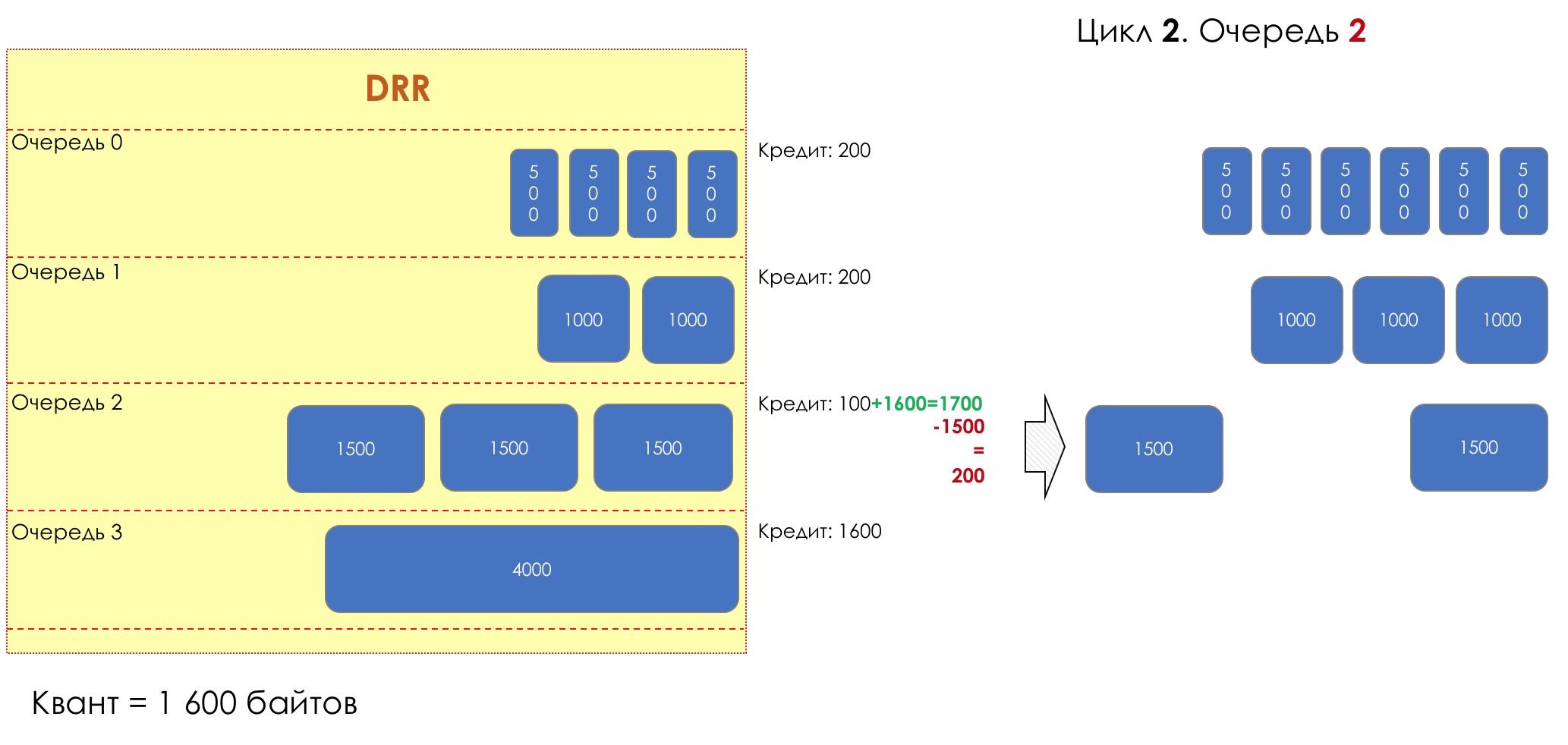 2. 3
2. 33200 (1600 + 1600).
(3200 — 4000 = -800)
— 3200 .
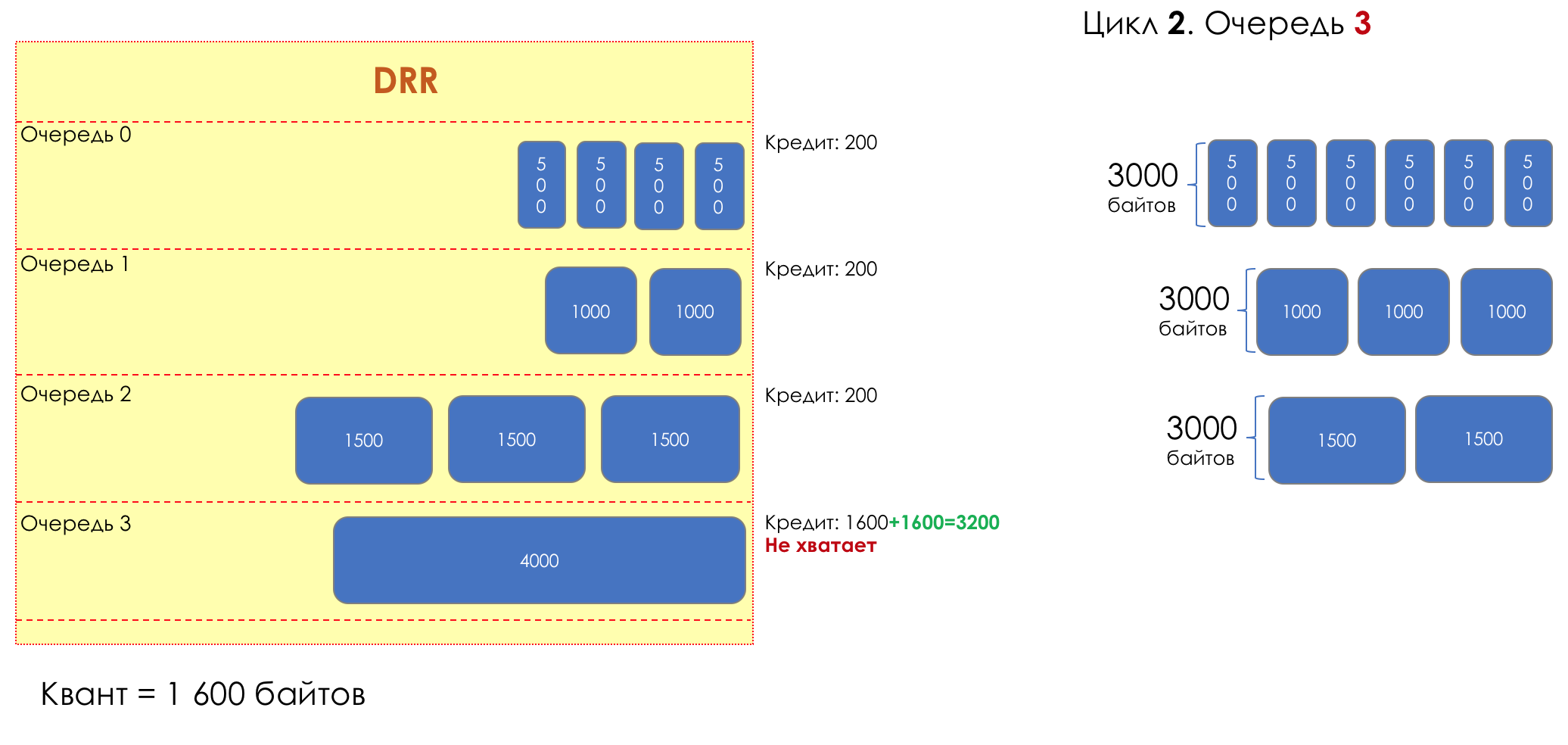
, :
- 0 — 3000
- 1 — 3000
- 2 — 3000
- 3 — 0
:
- 0 — 200
- 1 — 200
- 2 — 200
- 3 — 3200
3
— 1600 .
3. 01800 (200 + 1600).
— (1800 — 3*500 = 300).
.
— 300 .
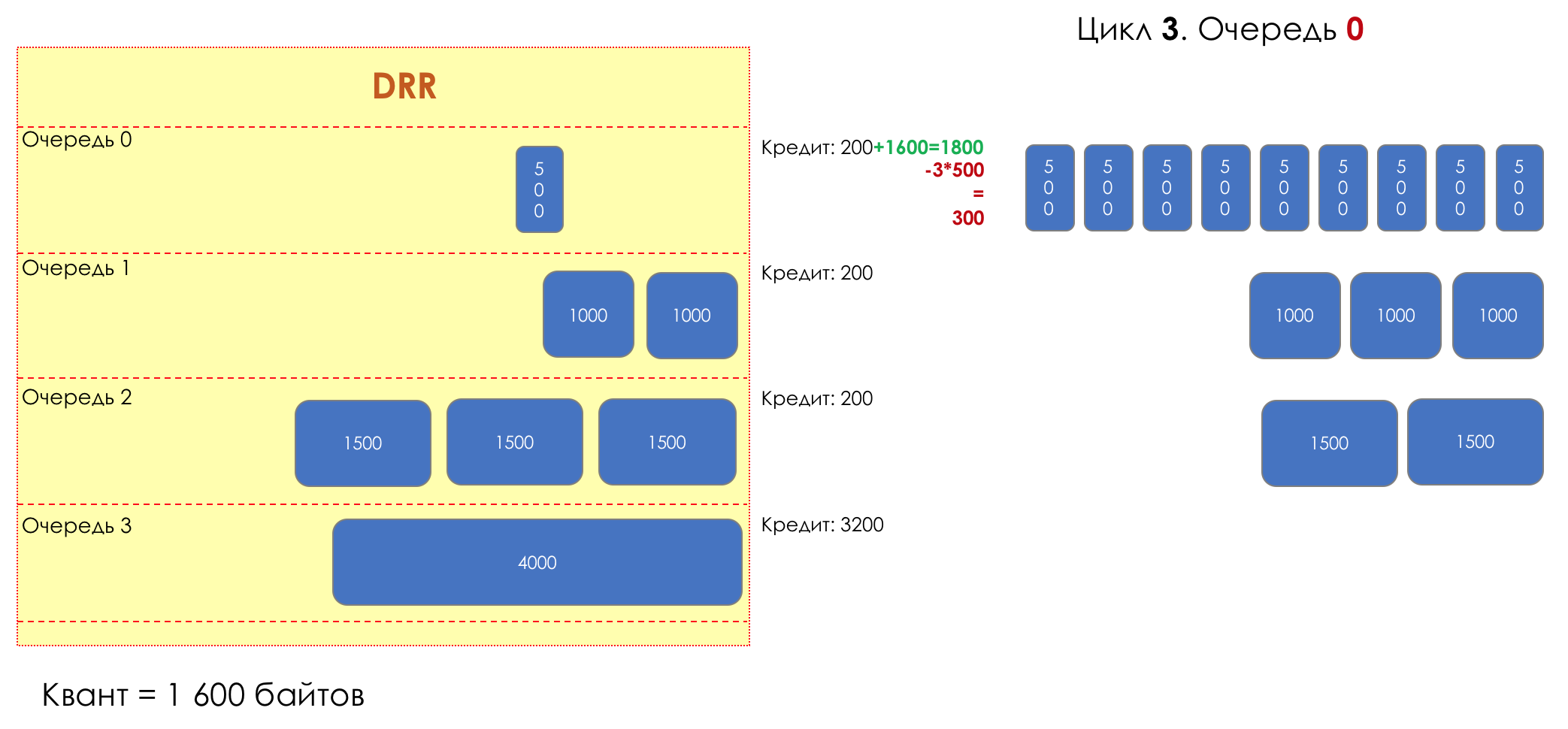 3. 1
3. 11800 (200 + 1600).
— (1800 — 1000 = 800).
— 800 .
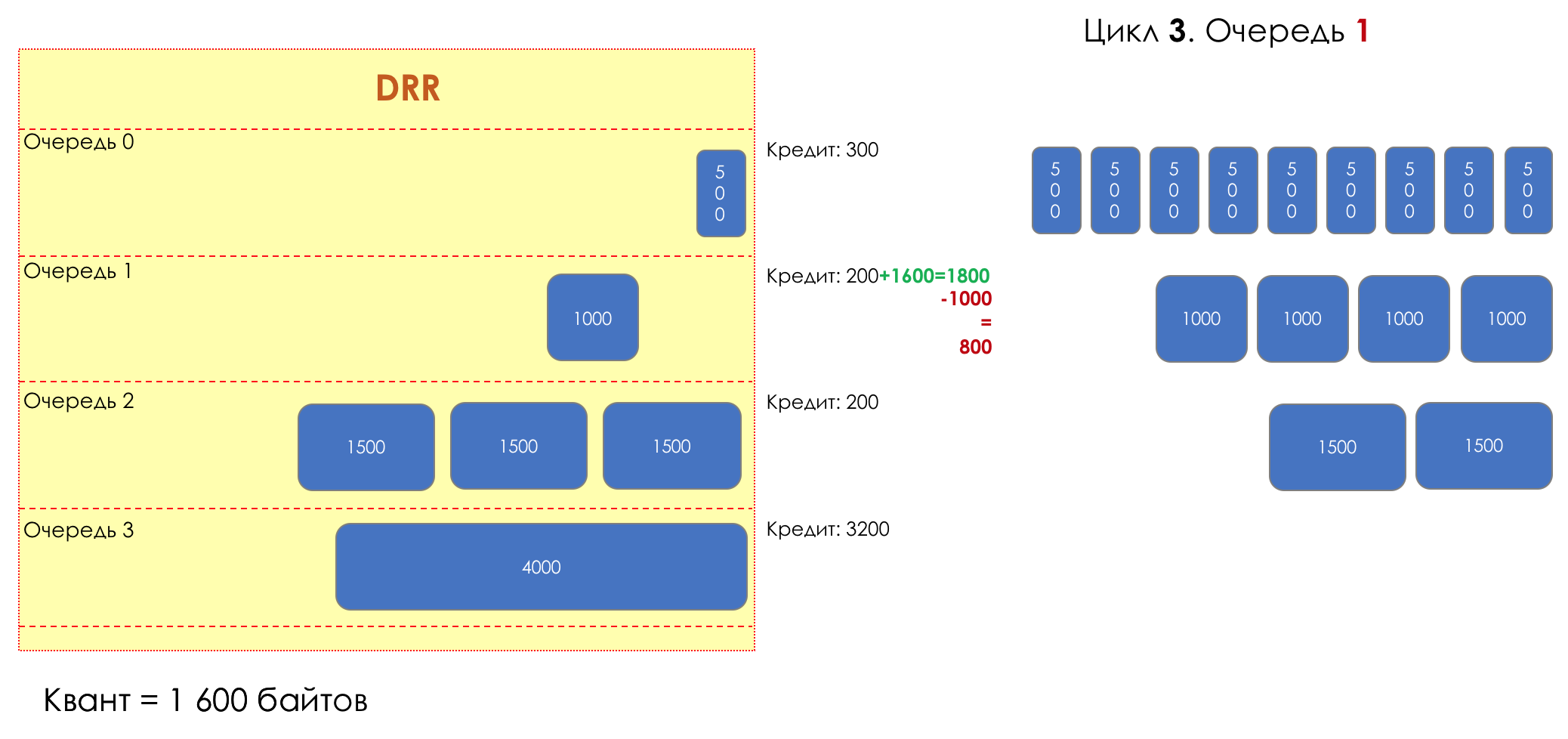 3. 2
3. 21800 (200 + 1600).
— (1800 — 1500 = 300).
— 300 .
 3. 3
3. 33- !
4800 (3200 + 1600).
— (4800 — 4000 = 800).
— 800 .
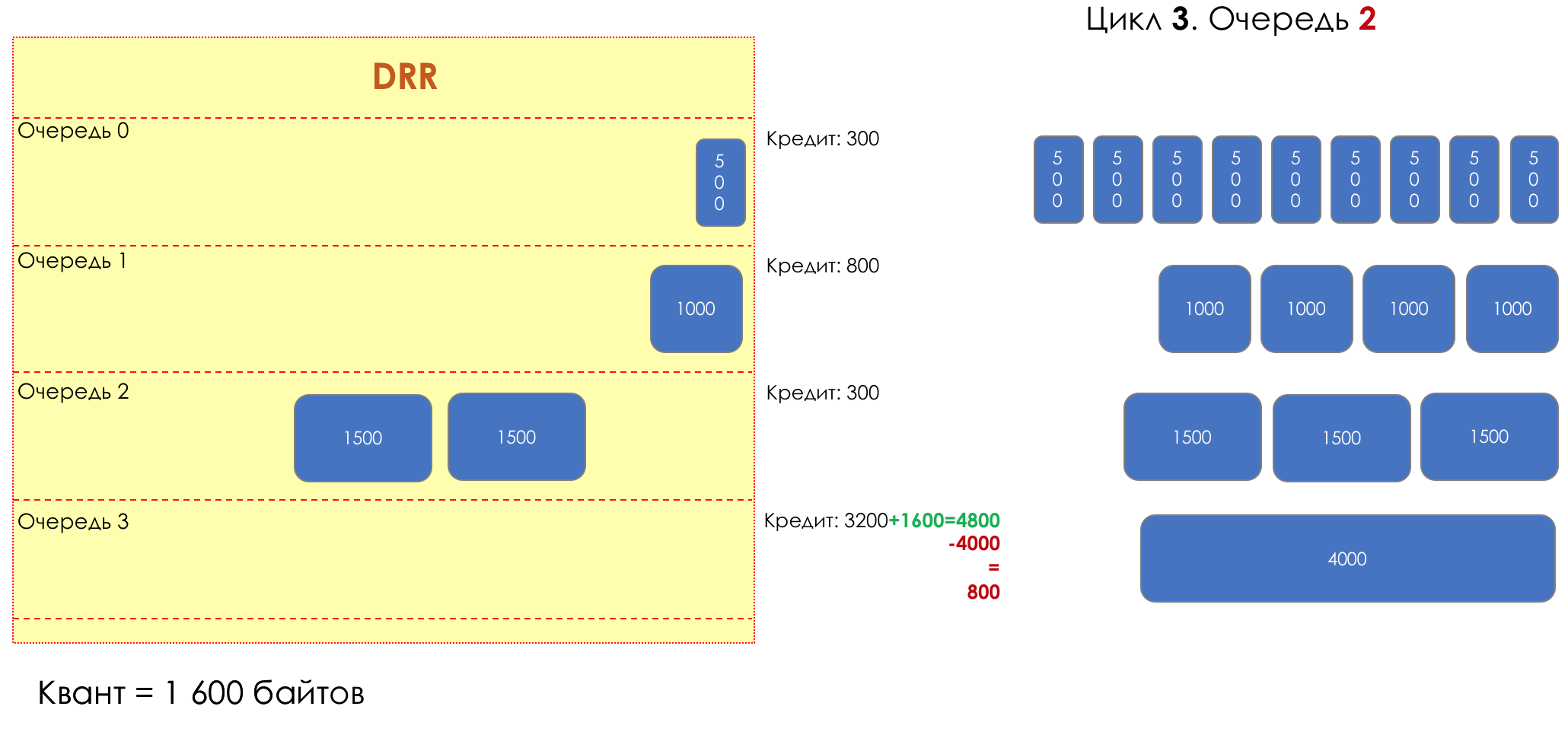
, :
- 0 — 4500
- 1 — 4000
- 2 — 4500
- 3 — 4000
:
- 0 — 300
- 1 — 800
- 2 — 300
- 3 — 800
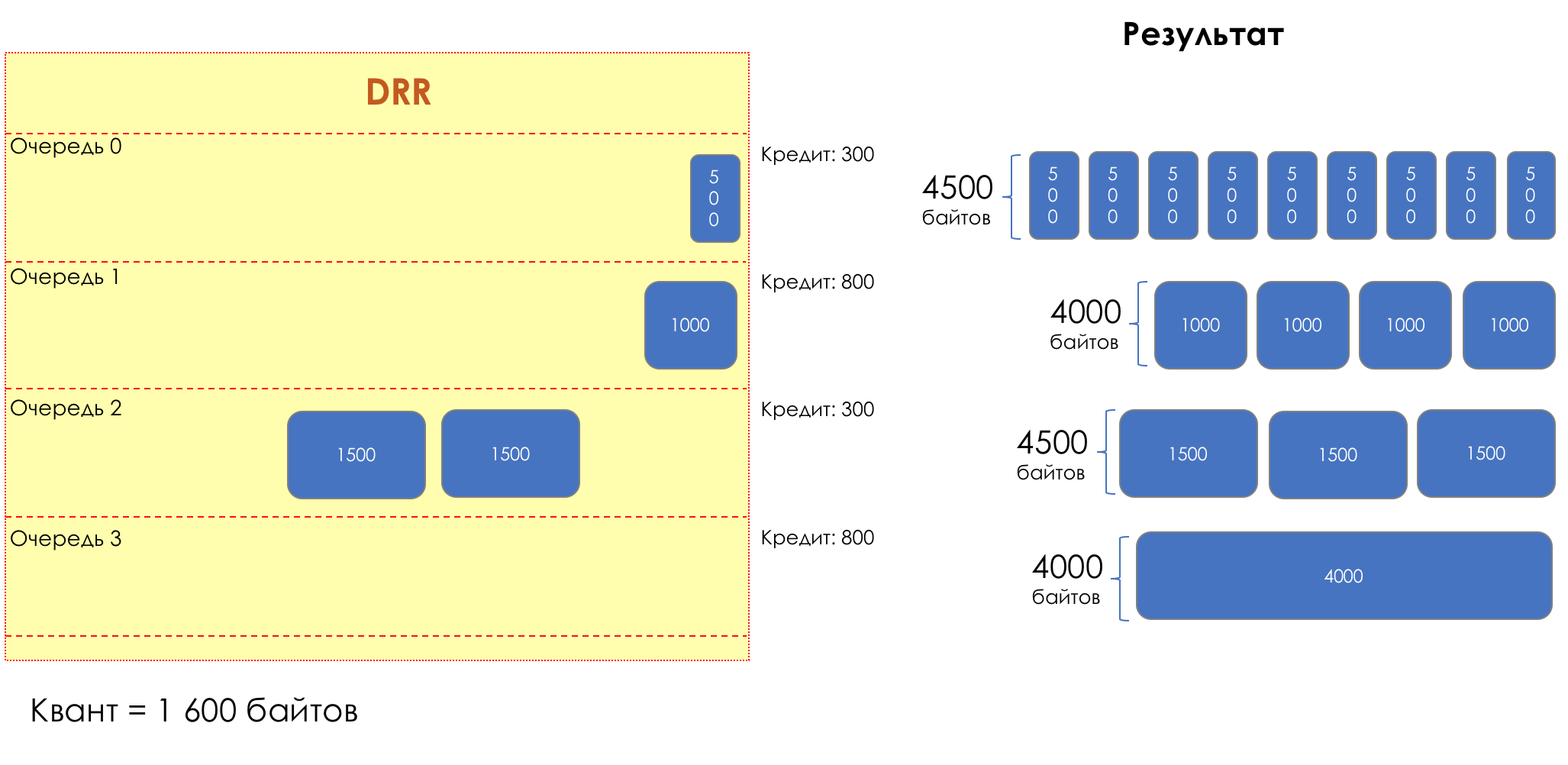
DRR. .
, .
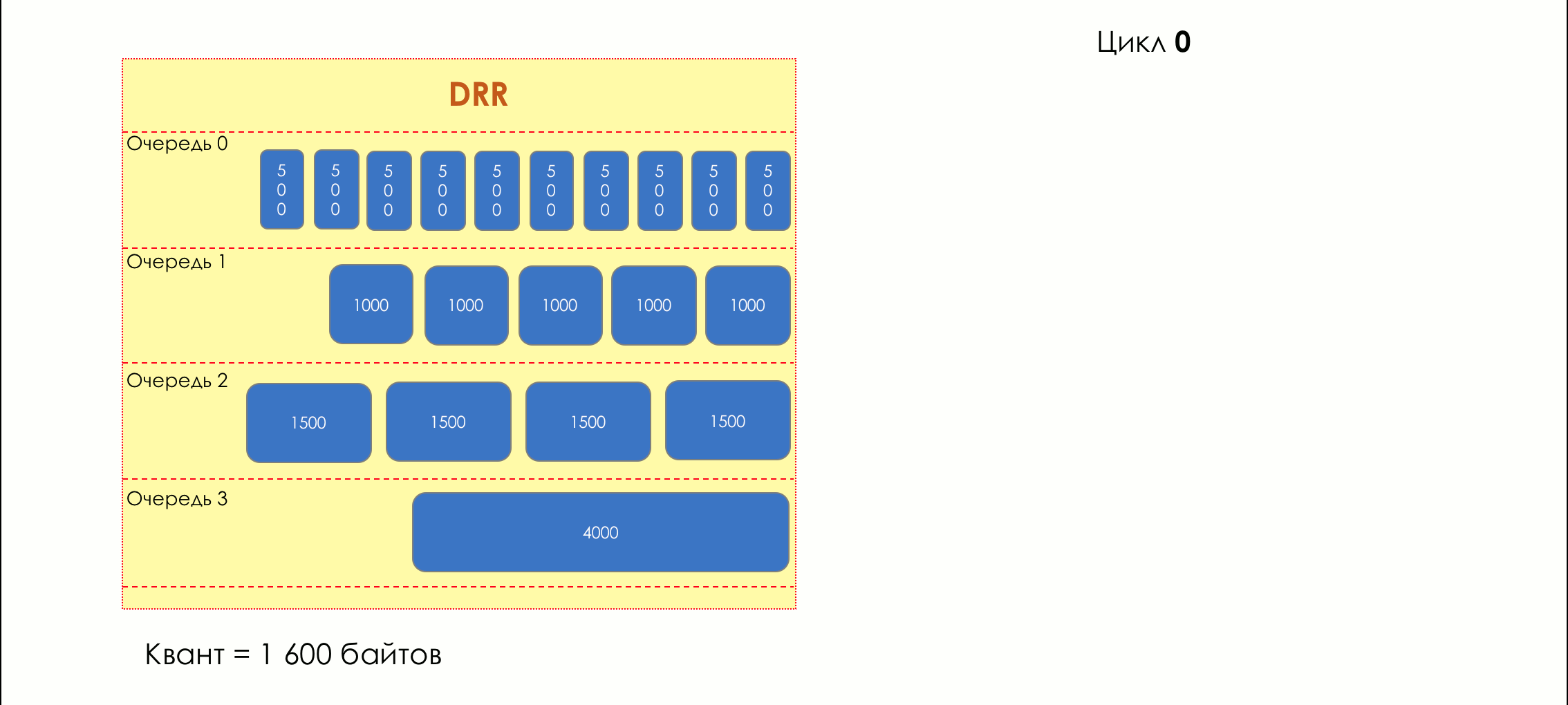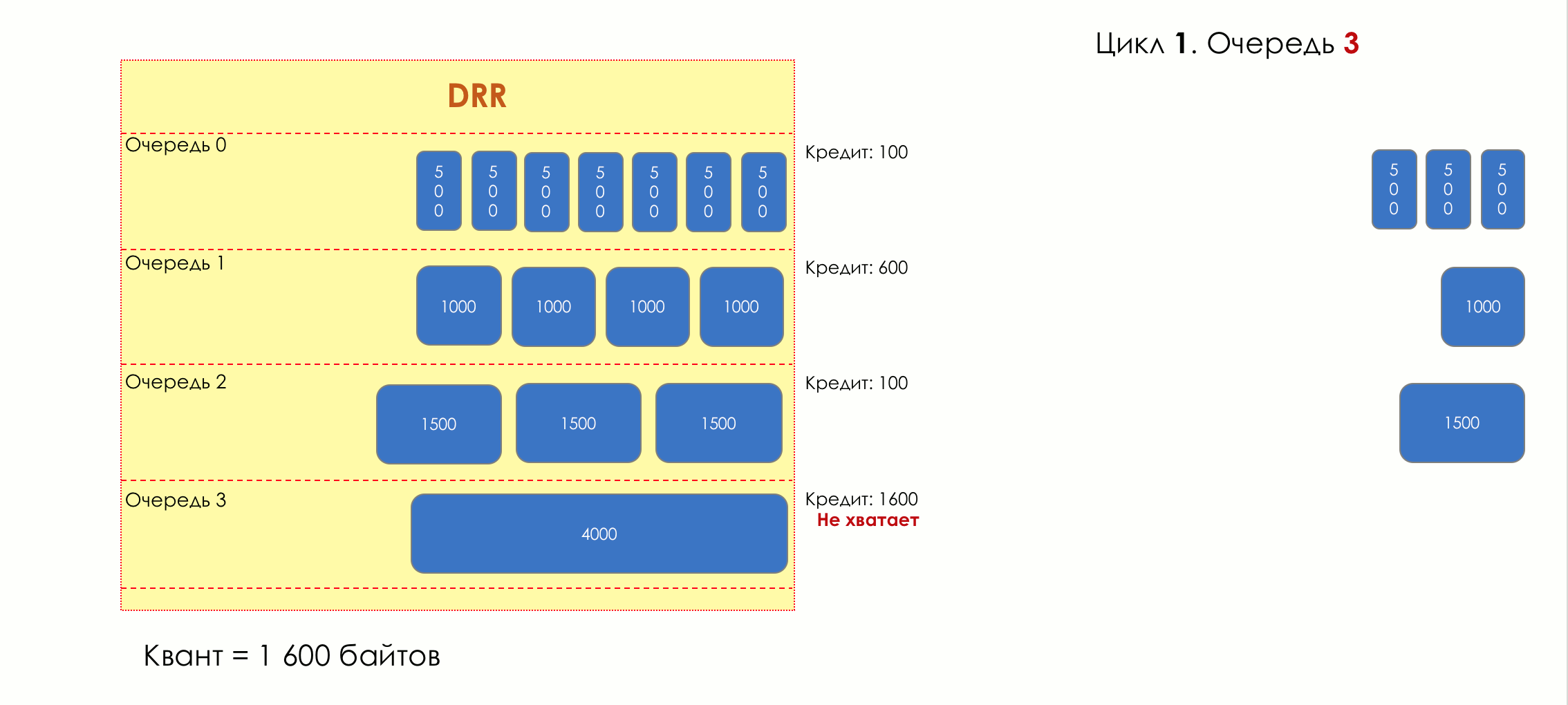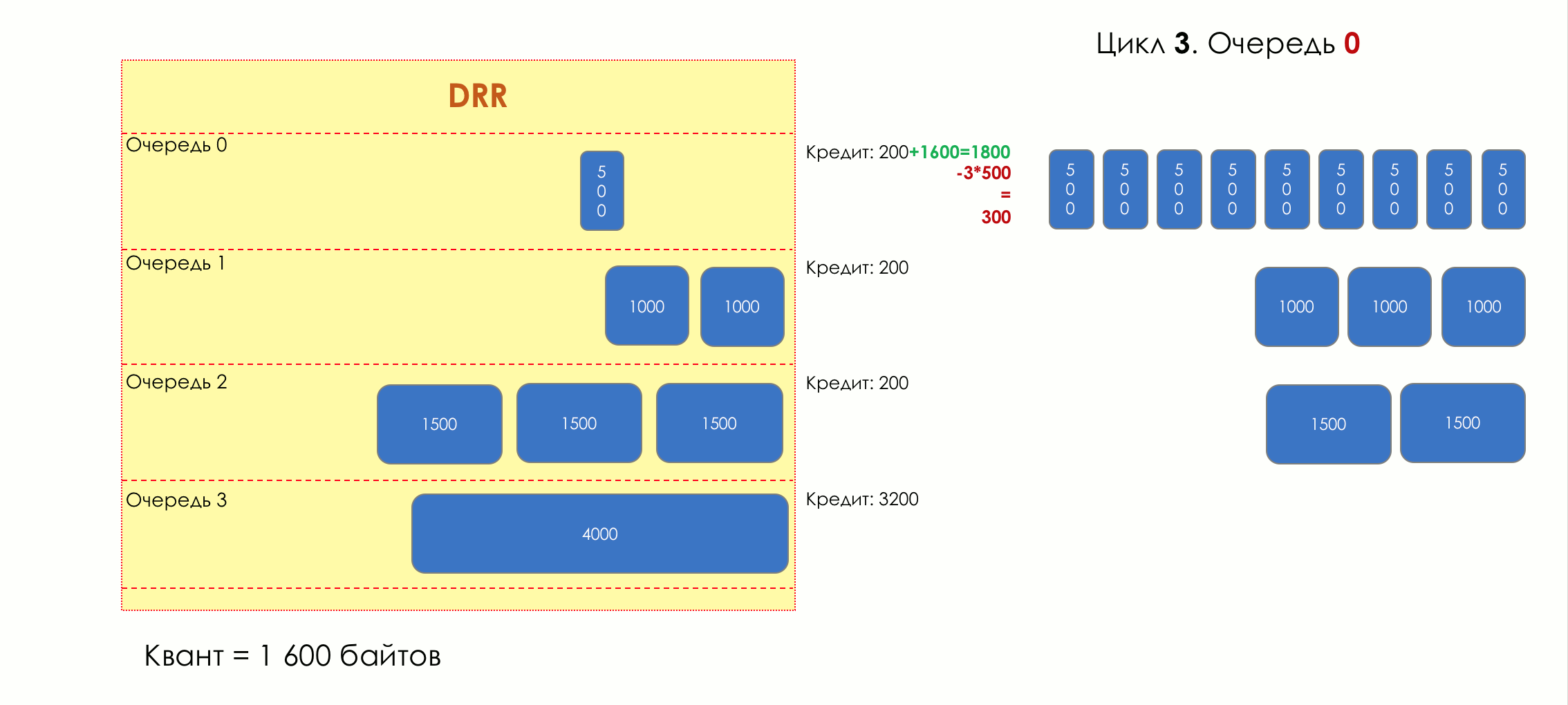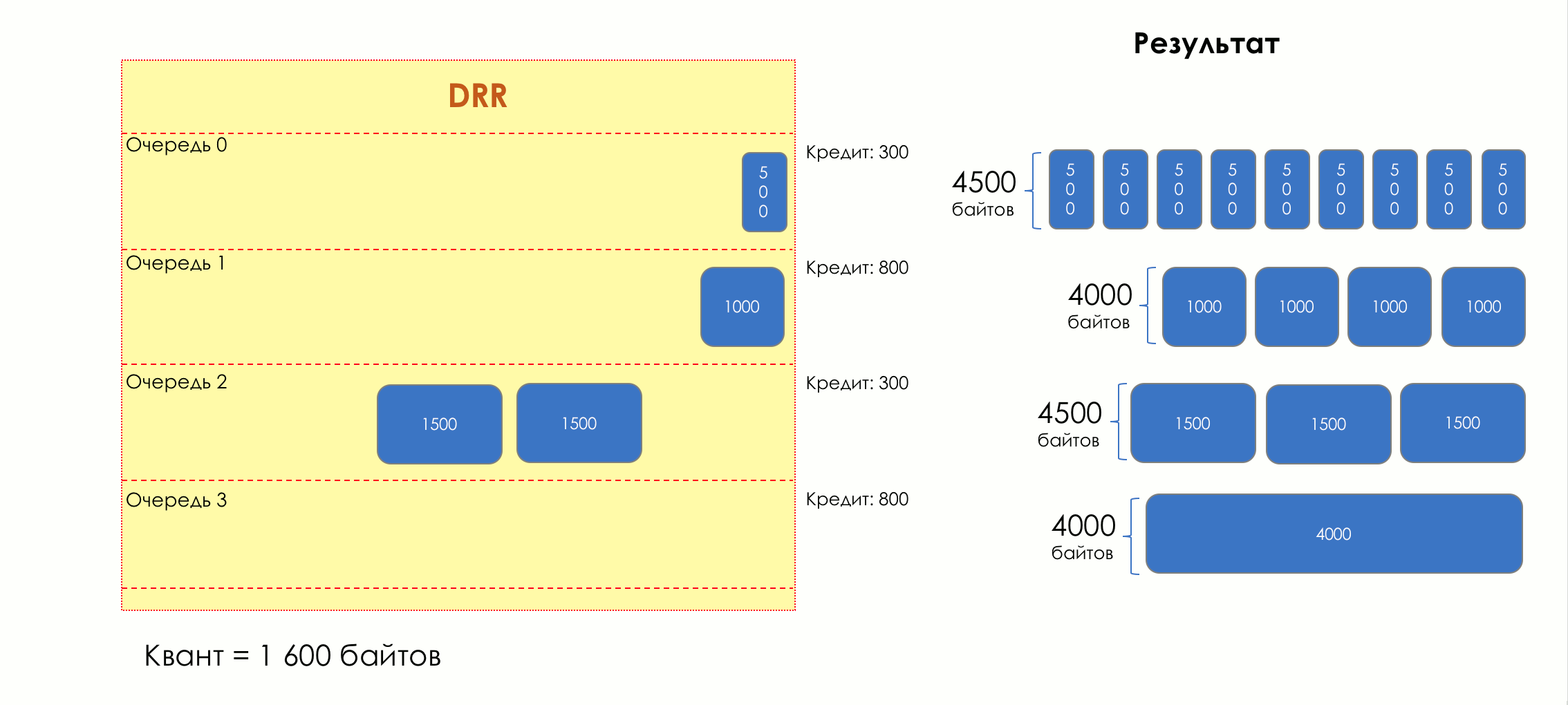
DWRR DRR , , , .
DRR, — , .
: , . .
Con DWRR, la cuestión permanece con la garantía de demoras y nerviosismo: el peso no lo resuelve de ninguna manera.Teóricamente, puede hacer lo mismo que con CB-WFQ, agregando LLQ.Sin embargo, este es solo uno de los posibles escenarios de la creciente popularidad actual.PB-DWRR - DWRR basado en prioridades
En realidad, la corriente principal de hoy se está convirtiendo en PB-DWRR - Round Robin de ponderación por déficit basada en prioridades.Este es el mismo viejo DWRR malvado, en el que se agrega otra cola: prioridad, en la que los paquetes se procesan con una prioridad más alta. Esto no significa que le den una tira más grande, sino que los paquetes se tomarán de allí con más frecuencia.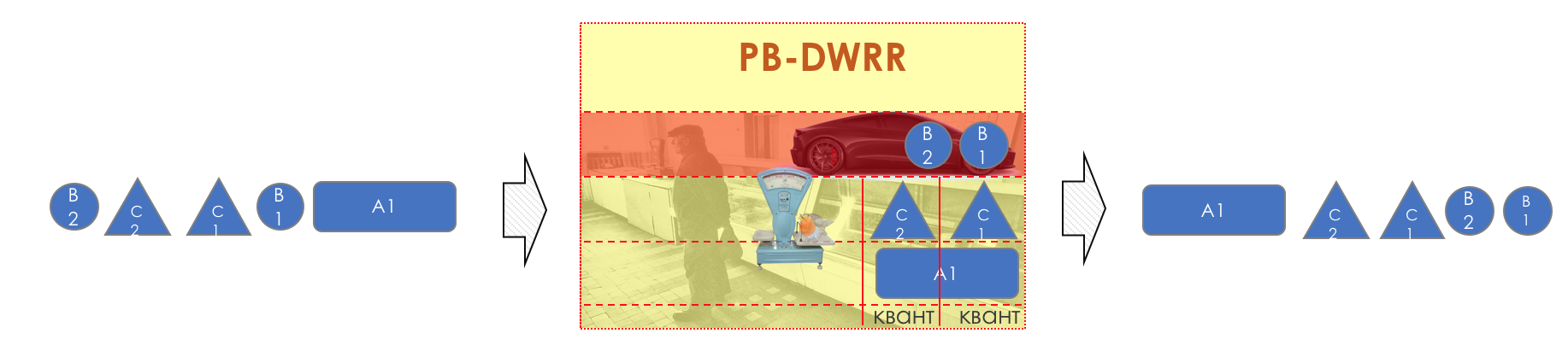 Existen varios enfoques para implementar PB-DWRR. En algunos de ellos, como en PQ, cualquier paquete que llegue a la cola de prioridad se elimina inmediatamente. En otros, se accede cada vez que el despachador se mueve entre colas. En tercer lugar, se introducen un crédito y un cuanto para que la cola de prioridad no pueda exprimir toda la tira.Por supuesto, no los analizaremos.
Existen varios enfoques para implementar PB-DWRR. En algunos de ellos, como en PQ, cualquier paquete que llegue a la cola de prioridad se elimina inmediatamente. En otros, se accede cada vez que el despachador se mueve entre colas. En tercer lugar, se introducen un crédito y un cuanto para que la cola de prioridad no pueda exprimir toda la tira.Por supuesto, no los analizaremos.Un breve resumen sobre los mecanismos de despacho
Durante décadas, la humanidad ha estado tratando de resolver el problema más difícil de garantizar el nivel correcto de servicio y la distribución justa de la banda. Las colas eran la herramienta principal; la única pregunta era cómo obtener paquetes de las colas, tratando de insertarlos en una interfaz.Comenzando con FIFO, inventó el PQ: la voz podía coexistir con el surf, pero no se trataba de garantizar la banda.Aparecieron varios monstruosos FQ, WFQ, que funcionaron, si no por flujo, casi así. CB-WFQ llegó a la sociedad de clases, pero no fue más fácil.Como alternativa, desarrolló RR. Se convirtió en un WRR, y luego en un DWRR.Y en las profundidades de cada uno de los despachadores vive FIFO.Sin embargo, como puede ver, no existe un despachador universal que maneje todas las clases según lo requieran. Siempre es una combinación de despachadores, uno de los cuales resuelve el problema de garantizar demoras, nerviosismo y falta de pérdidas, y el otro asigna una banda.CBWFQ + LLQ o PB-WDRR o WDRR + PQ.En equipos reales, puede especificar qué colas procesar con qué despachador.CBWFQ, WDRR y sus derivados son los favoritos de hoy.PQ, FQ, WFQ, RR, WRR: no nos afligimos y no recordamos (a menos que, por supuesto, nos estemos preparando para CCIE Clipper).
Entonces, los despachadores pueden garantizar la velocidad, pero ¿cómo limitarla desde arriba?8. Límite de velocidad
La necesidad de limitar la velocidad del tráfico a primera vista es obvia: no permita que el cliente salga de su banda de acuerdo con el acuerdo.Si Pero no solo eso. - 620 /, 1/. , - , , , QoS, , .
, 600 /, EF, CS6, CS7 , BE, AF . 600 / .
— (Admission Control). , , CS7 — - CS7 — . CS6 EF — .
, ? . , , .
. , — . — — BE, . .
: . , -.
:

Traffic Policing
La vigilancia limita la velocidad al dejar caer el exceso de tráfico.Todo lo que excede el valor establecido, el polyser corta y tira. Lo que se corta se olvida. La imagen muestra que el paquete rojo no está en el tráfico después del poliser.Y así es como se verá el perfil seleccionado después del polisador:
Lo que se corta se olvida. La imagen muestra que el paquete rojo no está en el tráfico después del poliser.Y así es como se verá el perfil seleccionado después del polisador: debido a la severidad de las medidas tomadas, esto se llama Hard Policing .Sin embargo, hay otras acciones posibles.El policía generalmente trabaja en conjunto con un medidor de tráfico. El medidor colorea las bolsas, como recordará, en verde, amarillo o rojo.Y sobre la base de este color ya, el polisador puede no descartar el paquete, sino colocarlo en otra clase. Estas son medidas suaves - Policia suave .Se puede aplicar tanto al tráfico entrante como al tráfico saliente.Una característica distintiva del polyser es la capacidad de absorber ráfagas de tráfico y determinar la velocidad máxima permitida gracias al mecanismo Token Bucket.Es decir, de hecho, todo lo que no está por encima del valor establecido no se corta, se le permite ir un poco más allá, se saltan ráfagas cortas o pequeños excesos de la banda asignada.El nombre "Vigilancia" está dictado por la relación bastante estricta de la herramienta al exceso de tráfico: descarte o degradación a una clase inferior.
debido a la severidad de las medidas tomadas, esto se llama Hard Policing .Sin embargo, hay otras acciones posibles.El policía generalmente trabaja en conjunto con un medidor de tráfico. El medidor colorea las bolsas, como recordará, en verde, amarillo o rojo.Y sobre la base de este color ya, el polisador puede no descartar el paquete, sino colocarlo en otra clase. Estas son medidas suaves - Policia suave .Se puede aplicar tanto al tráfico entrante como al tráfico saliente.Una característica distintiva del polyser es la capacidad de absorber ráfagas de tráfico y determinar la velocidad máxima permitida gracias al mecanismo Token Bucket.Es decir, de hecho, todo lo que no está por encima del valor establecido no se corta, se le permite ir un poco más allá, se saltan ráfagas cortas o pequeños excesos de la banda asignada.El nombre "Vigilancia" está dictado por la relación bastante estricta de la herramienta al exceso de tráfico: descarte o degradación a una clase inferior.Conformación del tráfico
El modelado limita la velocidad al amortiguar el exceso de tráfico.Todo el tráfico entrante pasa a través del búfer. Un modelador elimina los paquetes de este búfer a una velocidad constante.Si la velocidad de llegada de paquetes al búfer es inferior a la salida, no se retrasan en el búfer, sino que pasan volando.Y si la tasa de llegada es mayor que la salida, comienzan a acumularse.La velocidad de salida es siempre la misma.Por lo tanto, se agregan ráfagas de tráfico al búfer y se enviarán cuando lleguen a la cola.Por lo tanto, junto con la programación en colas, la configuración es la segunda herramienta que contribuye al retraso total .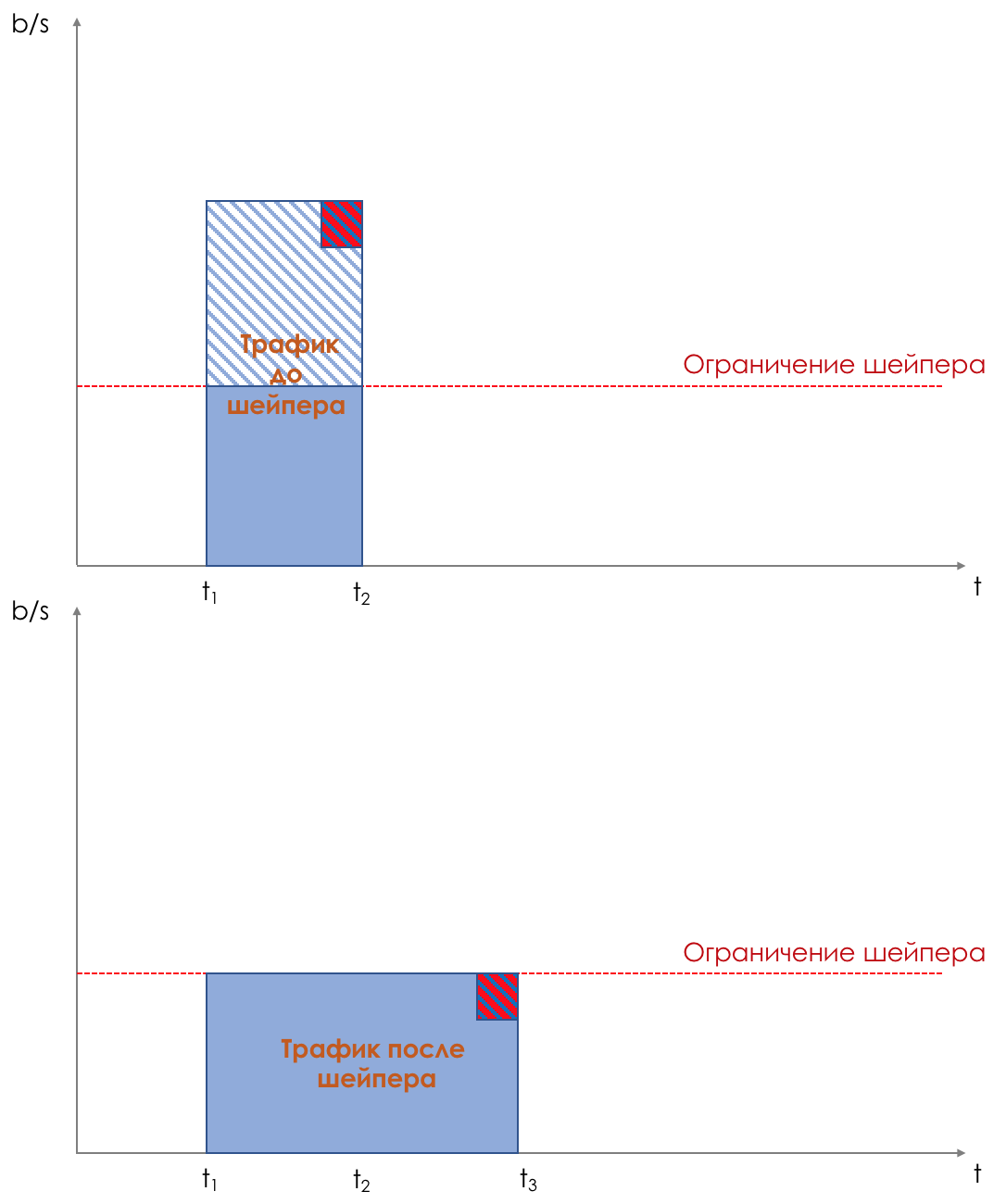
, , t2, t3. t3-t2 — , .
.
.
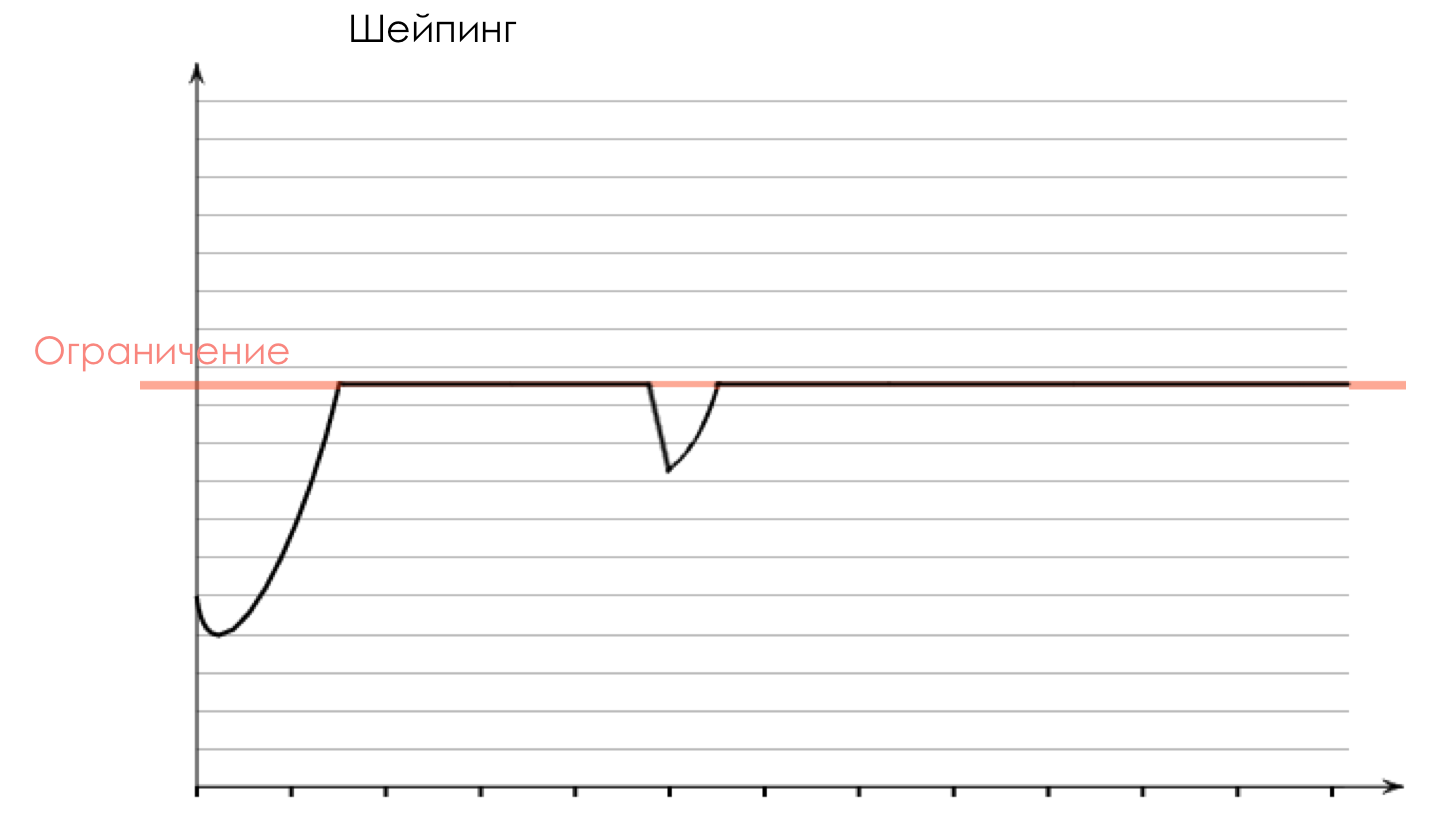
«Shaping» , , .
— — , .
— — , . .
Shaping Leaky Bucket.
El trabajo del poliser es similar a un cuchillo, que, moviéndose a lo largo de la superficie del aceite, corta el lado afilado del tubérculo.El trabajo de un moldeador es similar a un rodillo, que alisa los tubérculos, distribuyéndolos uniformemente sobre la superficie.Shaper intenta no soltar paquetes mientras están almacenados en el búfer a costa de un mayor retraso.El pulidor no introduce demoras, pero descarta más fácilmente los paquetes.Las aplicaciones que no son sensibles a los retrasos, pero cuya pérdida no es deseable, deben limitarse a un moldeador.Para aquellos para quienes un paquete tardío es igual a uno perdido, es mejor dejarlo de inmediato, luego pulir.Un modelador no afecta los encabezados de paquetes y su destino fuera del nodo, mientras que después de pulir el dispositivo puede volver a clasificar la clase en el encabezado. Por ejemplo, en la entrada, el paquete tenía la clase AF11, la medición lo pintó de amarillo dentro del dispositivo, en la salida volvió a marcar su clase en AF12: en el siguiente nodo tendrá una mayor probabilidad de caerse.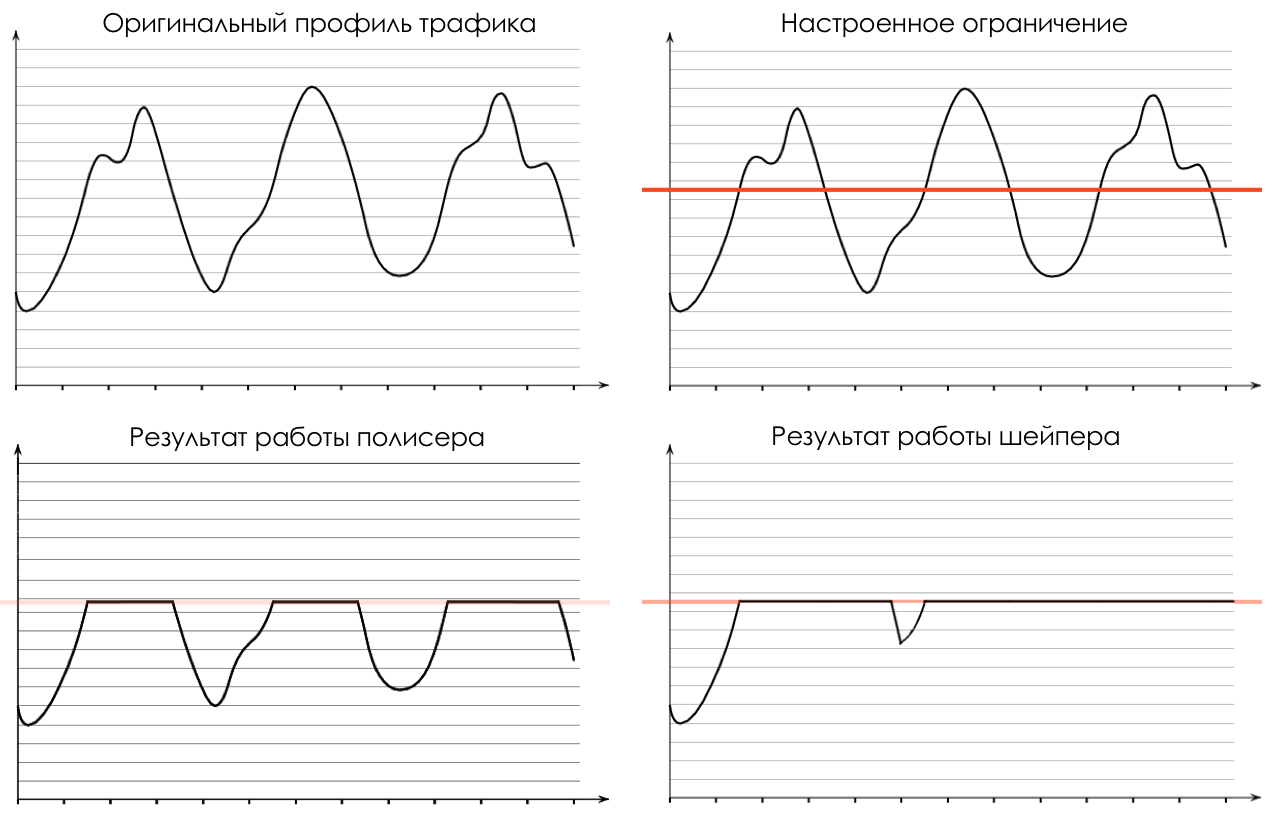
Practica pulido y modelado
El esquema es el mismo:archivo de configuración.Observamos esta imagen sin aplicar restricciones: procederemos de la siguiente manera:
procederemos de la siguiente manera:- En la interfaz de entrada Linkmeup_R2 (e0 / 1) configuraremos el pulido, este será el control de entrada. Según el acuerdo, otorgamos 10 Mb / s.
- En la interfaz de salida Linkmeup_R4 (e0 / 2), configure el modelado a 20 Mb / s.
Comencemos con el shaper en Linkmeup_R4 .Combina todo: class-map match-all TRISOLARANS_ALL_CM match any
Forma hasta 20Mb / s: policy-map TRISOLARANS_SHAPING class TRISOLARANS_ALL_CM shape average 20000000
Aplicar a la interfaz de salida: interface Ethernet0/2 service-policy output TRISOLARANS_SHAPING
Todo lo que debería salir (salida) de la interfaz Ethernet0 / 2, forma hasta 20 Mb / s.Archivo de configuración de modelador.Y aquí está el resultado: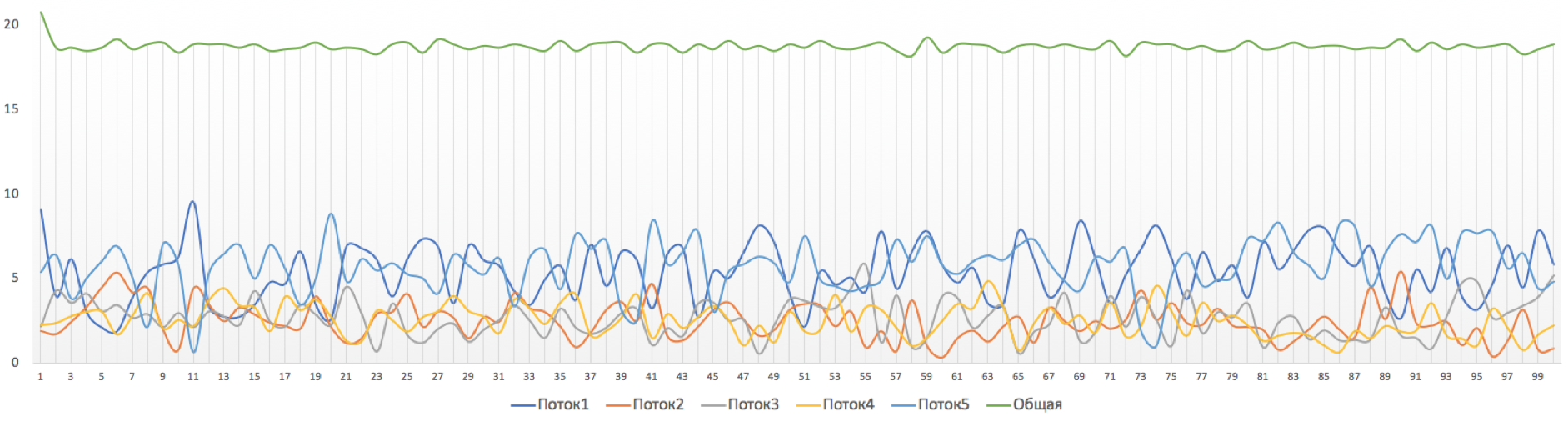 resulta una línea bastante plana de rendimiento total y gráficos desgarrados para cada flujo individual.El hecho es que restringimos el modelador a la banda general. Sin embargo, dependiendo de la plataforma, las transmisiones individuales también se pueden configurar individualmente, obteniendo así la igualdad de oportunidades.
resulta una línea bastante plana de rendimiento total y gráficos desgarrados para cada flujo individual.El hecho es que restringimos el modelador a la banda general. Sin embargo, dependiendo de la plataforma, las transmisiones individuales también se pueden configurar individualmente, obteniendo así la igualdad de oportunidades.
Ahora configure el pulido en Linkmeup_R2.Agregaremos un polisador a la política existente. policy-map TRISOLARANS_ADMISSION_CONTROL class TRISOLARANS_TCP_CM police cir 10000000 bc 1875000 conform-action transmit exceed-action drop
La política ya se ha aplicado a la interfaz: interface Ethernet0/1 service-policy input TRISOLARANS_ADMISSION_CONTROL
Aquí indicamos la velocidad media permitida CIR (10Mb / s) y la ráfaga permitida Bc (1,875,000 bytes aproximadamente 14.6 MB).Más adelante, explicando cómo funciona el poliser, le diré cuáles son el CIR y Bc y cómo determinar estos valores.Archivo de configuración de Polyser.Esta imagen se observa con polising. Los cambios repentinos en el nivel de velocidad son inmediatamente aparentes:
Pero se obtiene una imagen tan interesante si hacemos que el tamaño de ráfaga permitido sea demasiado pequeño, por ejemplo, 10,000 bytes. police cir 10000000 bc 10000 conform-action transmit exceed-action drop
 La velocidad general se redujo inmediatamente a aproximadamente 2Mb / s.Tenga cuidado con la configuración de ráfagas :)Tabla de prueba.
La velocidad general se redujo inmediatamente a aproximadamente 2Mb / s.Tenga cuidado con la configuración de ráfagas :)Tabla de prueba.
Cubo con fugas y cubo de fichas
Suena fácil y claro. Pero, ¿cómo funciona en la práctica y se implementa en hardware?Un ejemplo
¿El límite de 400 Mb / s es mucho (o poco)? En promedio, un cliente usa solo 320. Pero a veces aumenta a 410 durante 5 minutos. Y a veces hasta 460 por minuto. Y a veces hasta 500 por medio segundo.Como el proveedor contractual linkmeup puede decir: ¡400 y eso es todo! Si quieres más, conéctate a la tarifa de 1Gb / s + 27 canales de anime.Y podemos aumentar la lealtad del cliente si esto no interfiere con otros al permitir tales sobretensiones.¿Cómo permitir 460 Mb / s por solo un minuto, y no 30 o por siempre?¿Cómo permitir 500 Mb / s, si la banda es libre, y presionar hasta 400, si han aparecido otros consumidores?Ahora tome un descanso, vierta un balde de fuerte.Comencemos con el mecanismo más simple utilizado por el moldeador: un cubo con fugas.Algoritmo de cubo con fugas
Leaky Bucket — .

. / . .
, .
, Leaky Bucket .
, , .
.
Leaky Bucket — SD-RAM.
Incluso si la configuración no está configurada explícitamente, en presencia de ráfagas que no pasan a la interfaz, los paquetes se almacenan temporalmente y se transmiten a medida que se libera la interfaz. Esto también se está formando.Leaky Bucket se usa solo para dar forma y no es adecuado para pulir.Algoritmo Token Bucket
Muchas personas piensan que Token Bucket y Leaking Bucket son lo mismo. Solo Einstein estaba mucho más equivocado, agregando una constante cosmológica.Los chips de conmutación no entienden realmente qué hora es, empeoran aún más la cantidad de bits que transmiten por unidad de tiempo. Su trabajo es trillar.¿Se está acercando este bit a otros 400,000,000 bits por segundo, o ya a 400,000 001? Los desarrolladores de ASIC tuvieron un desafío de ingeniería no trivial.Se dividió en dos subtareas:
Los desarrolladores de ASIC tuvieron un desafío de ingeniería no trivial.Se dividió en dos subtareas:- . .
- , ( ) , .
, Token Bucket. ().
Token Bucket — , / , .
, .
Leaky Bucket , Token Bucket .
Single Rate — Two Color Marking
=)
, — 400 , .
— 600 . .
: , — .
, .
. — — .
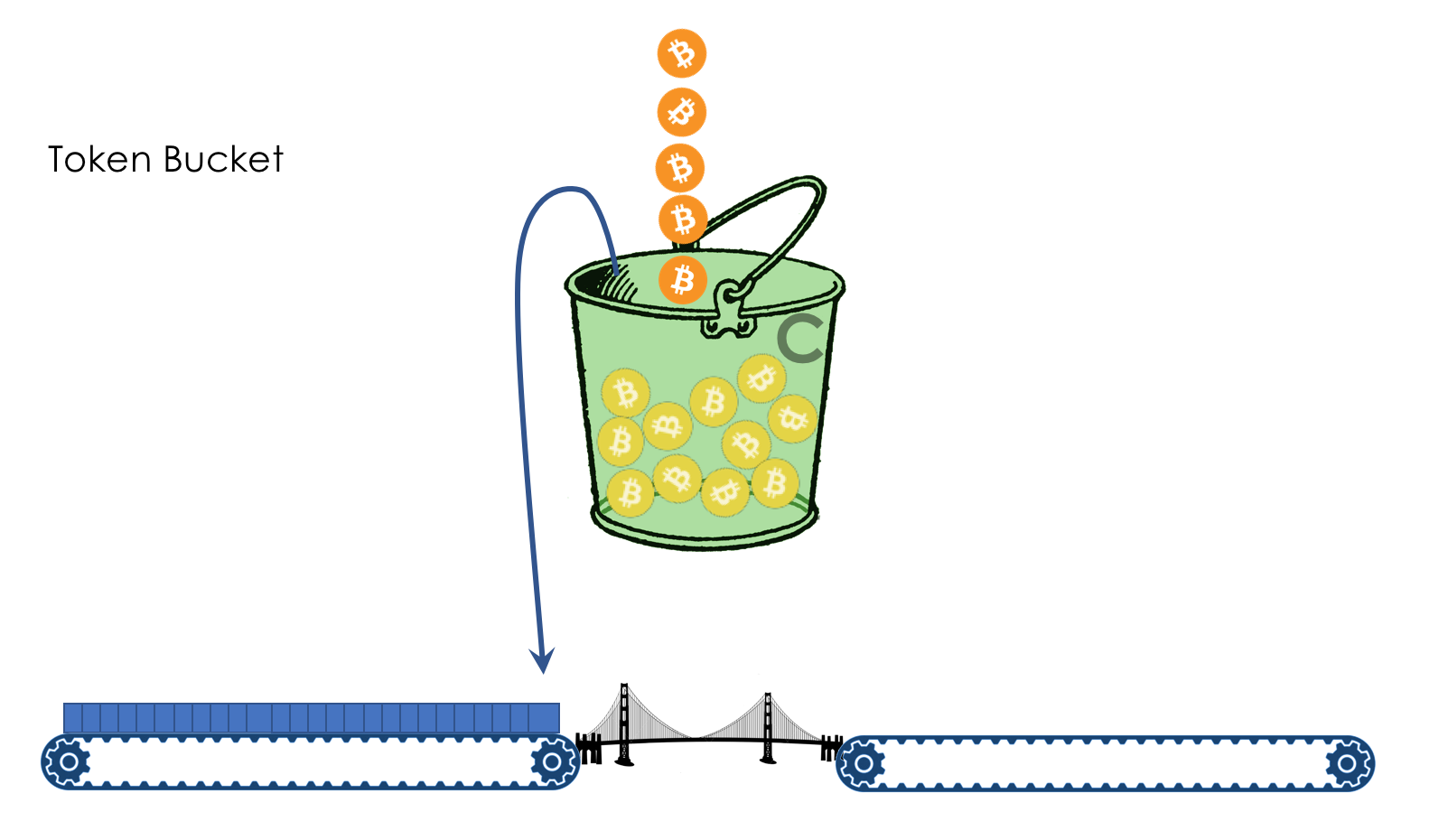

, . -. .
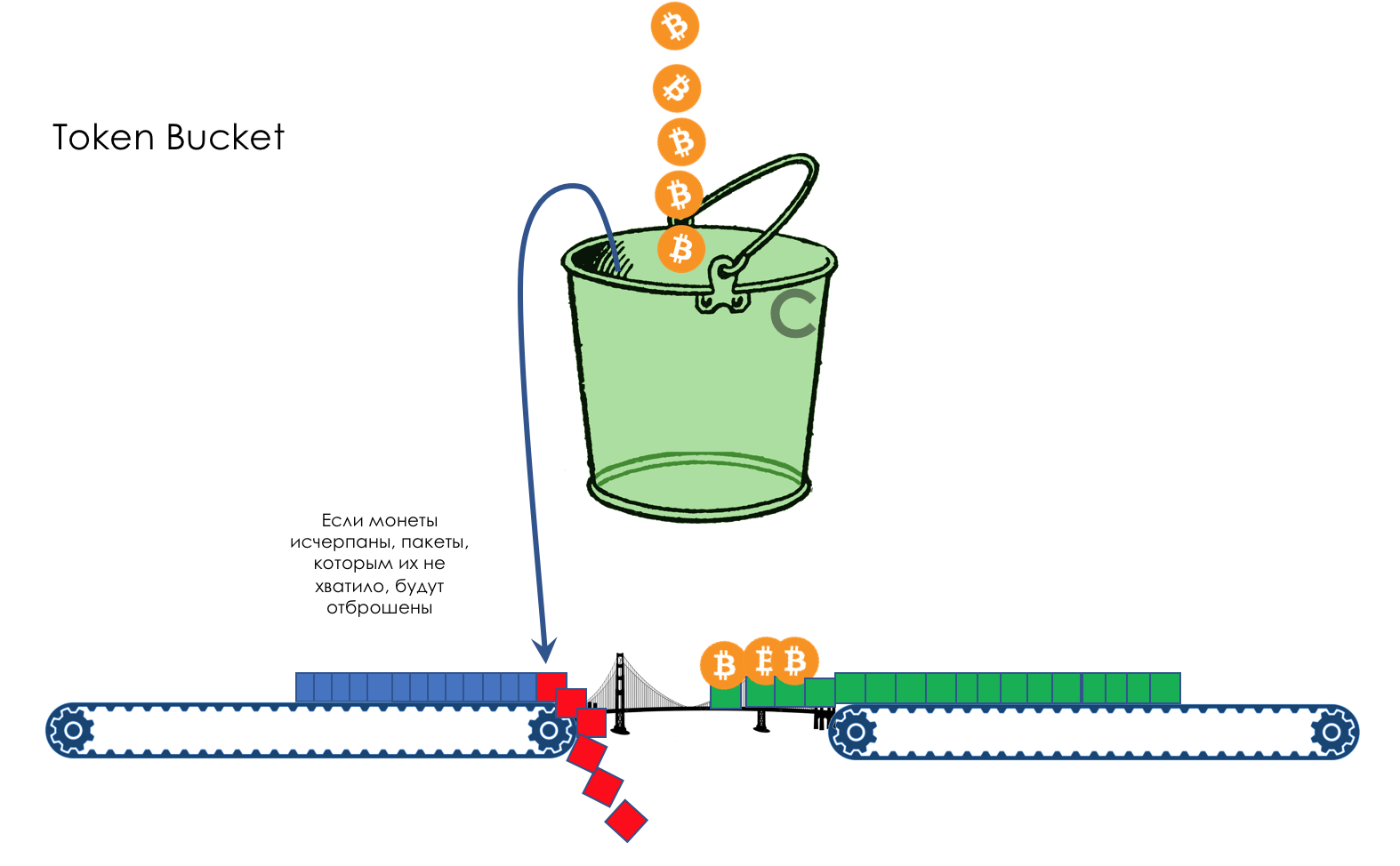 El siguiente paquete de monedas ya puede ser suficiente: en primer lugar, el paquete puede ser más pequeño y, en segundo lugar, ataca más monedas durante este tiempo.Si el cubo ya está lleno, se tirarán todas las monedas nuevas.
El siguiente paquete de monedas ya puede ser suficiente: en primer lugar, el paquete puede ser más pequeño y, en segundo lugar, ataca más monedas durante este tiempo.Si el cubo ya está lleno, se tirarán todas las monedas nuevas.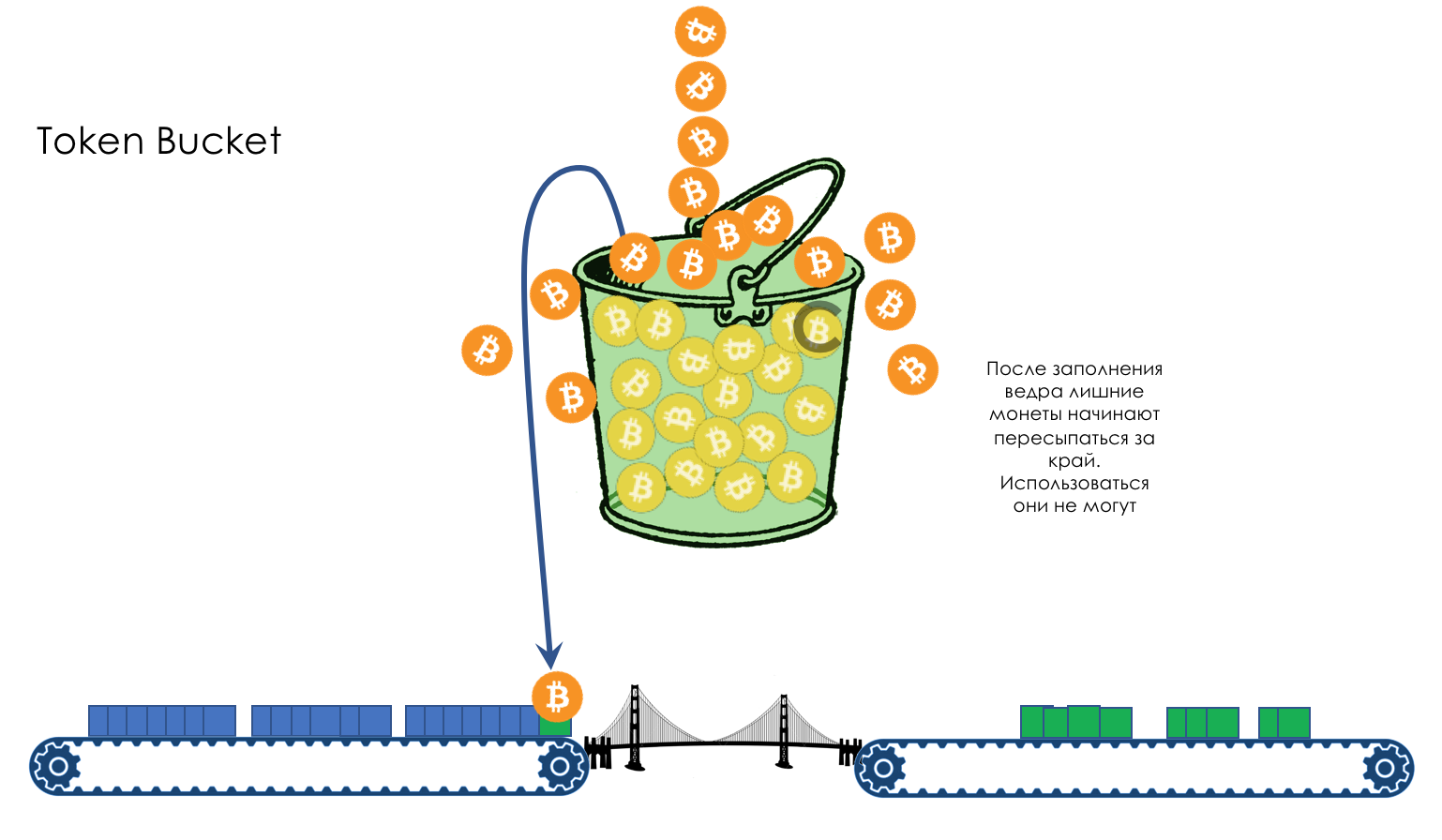 Todo depende de la velocidad de llegada del paquete y su tamaño.Si es establemente inferior o igual a 400 MB por segundo, siempre habrá suficientes monedas.Si es superior, se perderán algunos de los paquetes.
Todo depende de la velocidad de llegada del paquete y su tamaño.Si es establemente inferior o igual a 400 MB por segundo, siempre habrá suficientes monedas.Si es superior, se perderán algunos de los paquetes.Un ejemplo más específico con gifs, como todos amamos.
- Hay un depósito con una capacidad de 2500 bytes. En el momento inicial, contiene 550 tokens.
Hay tres paquetes de 1000 bytes en la tubería que desean enviarse a la interfaz.
En cada intervalo de tiempo, 500 bytes caen en el depósito (500 * 8 = 4,000 bits / intervalo de tiempo - límite de polyser). - 500 . . 1000 , 1050 — . . 1000 .
50 . - 500 — 550. — 1000 — .
, . - 500 — 1050. — 1000 — .
, .
2500 , 2500 — . MTU , , , 1,5-2 .
:
CBS = CIR ( )*1,5 ()/8 ( )
, (Bc), , (1 875 000 ) . (10 000 ), , MTU, .
¿Por qué el volumen del cubo? El flujo de bits no siempre es uniforme, esto es obvio. Un límite de 400 Mb / s no es una asíntota: el tráfico puede cruzarlo. El volumen de monedas almacenadas permite que pequeñas ráfagas vuelen sin ser descartadas, pero mantiene la velocidad promedio en 400Mb / s.Por ejemplo, un flujo estable de 399 Mb / s en 600 segundos permitirá que el cubo se llene hasta el borde.Además, el tráfico puede aumentar a 1000Mb / sy permanecer en este nivel durante 1 segundo: 600 Mm (Megamonet) de stock y una banda garantizada de 400 Mm / s.O bien, el tráfico puede subir hasta 410 Mb / sy permanecer así durante 60 segundos.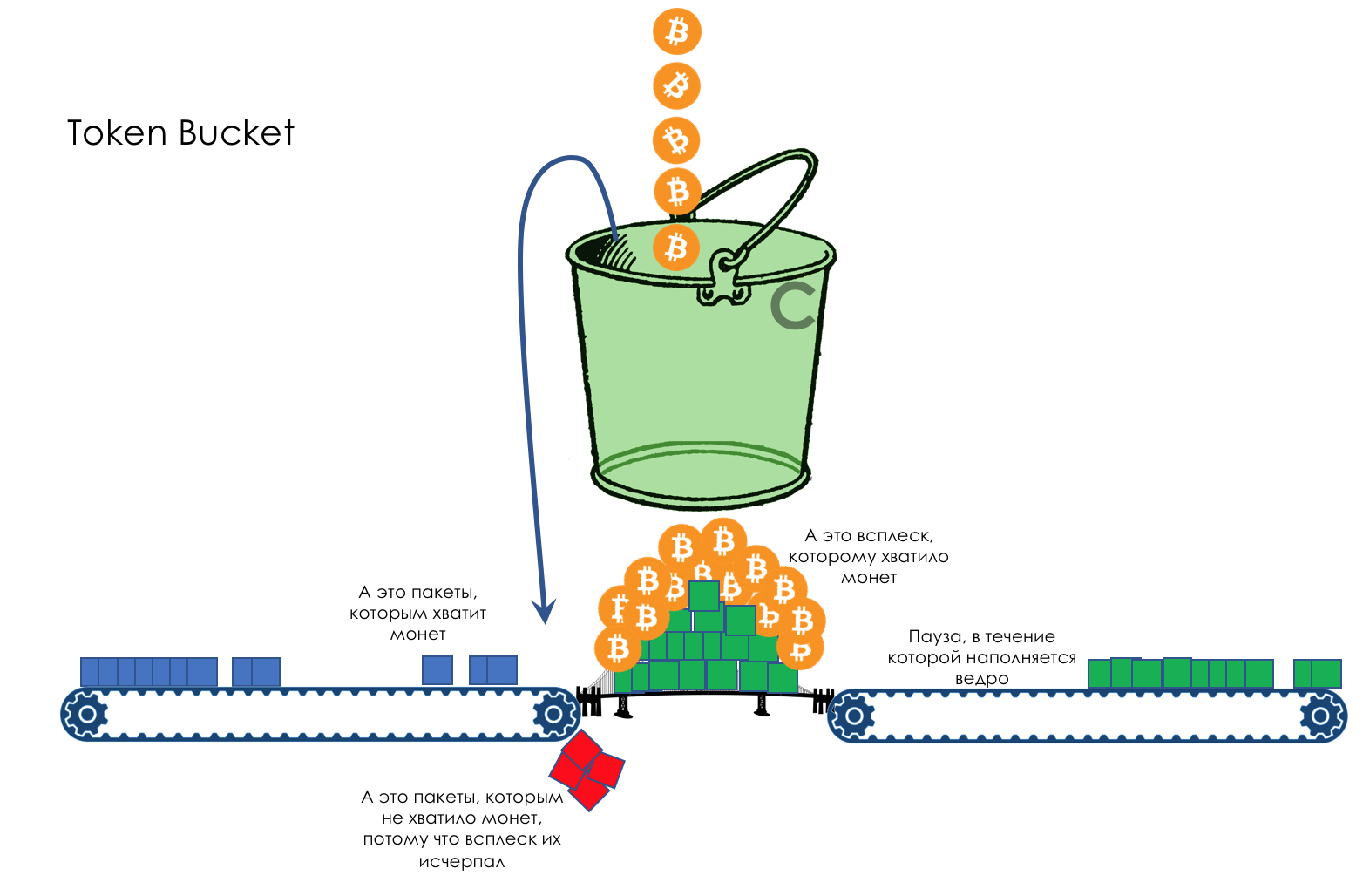 Es decir, el suministro de monedas le permite ir un poco más allá de la restricción durante mucho tiempo o lanzar una oleada corta pero alta.Ahora a la terminología.
Es decir, el suministro de monedas le permite ir un poco más allá de la restricción durante mucho tiempo o lanzar una oleada corta pero alta.Ahora a la terminología.—
CIR — Committed Information Rate ( ). .
, —
CBS — Committed Burst Size . . . , ,
Bc .
Tc — (Token)
C (CBS) .
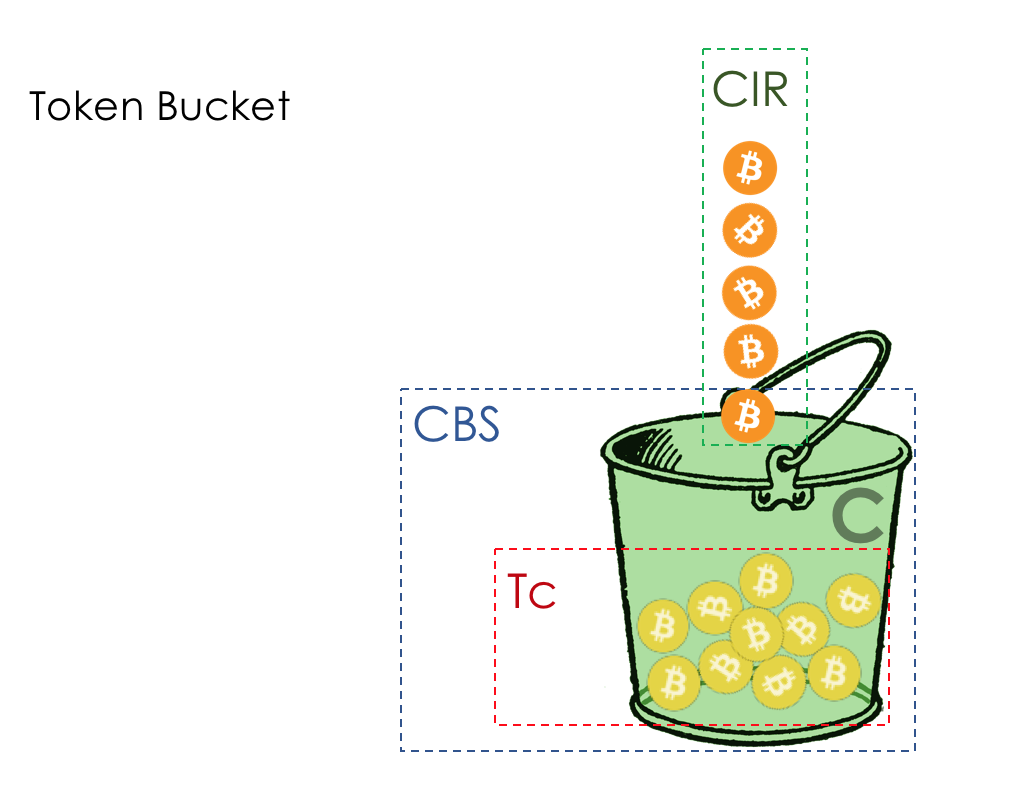
" Tc ", , RFC 2697 ( A Single Rate Three Color Marker ).
Tc, , .
.
, , Token Bucket, TDM (Time-Division Multiplexing) — .
— , , .
CIR . .
, — , — , — .
, .
( Cisco) Tc , — Bc . Bc = CIR*Tc .
Tc Bc .
Este es el escenario más simple. Se llama Single Rate - Two Color .Tarifa única significa que solo hay una velocidad promedio permitida y Dos colores : que puede colorear el tráfico en uno de dos colores: verde o rojo.- Si la cantidad de monedas (bits) disponibles en el depósito C es mayor que la cantidad de bits que se deben omitir en este momento, el paquete está coloreado en verde, una baja probabilidad de caer en el futuro. Las monedas se retiran del cubo.
- De lo contrario, el paquete está pintado en rojo: una alta probabilidad de una caída (o, más a menudo, una caída momentánea). Monedas de este modo cubos C se retira .
PHB CS EF, , , .
: Single Rate — Three Color.
Single Rate — Three Color Marking
, . , , ?
sr-TCM (
Single Rate — Three Color Marking ) —
E . ,
C ,
E .
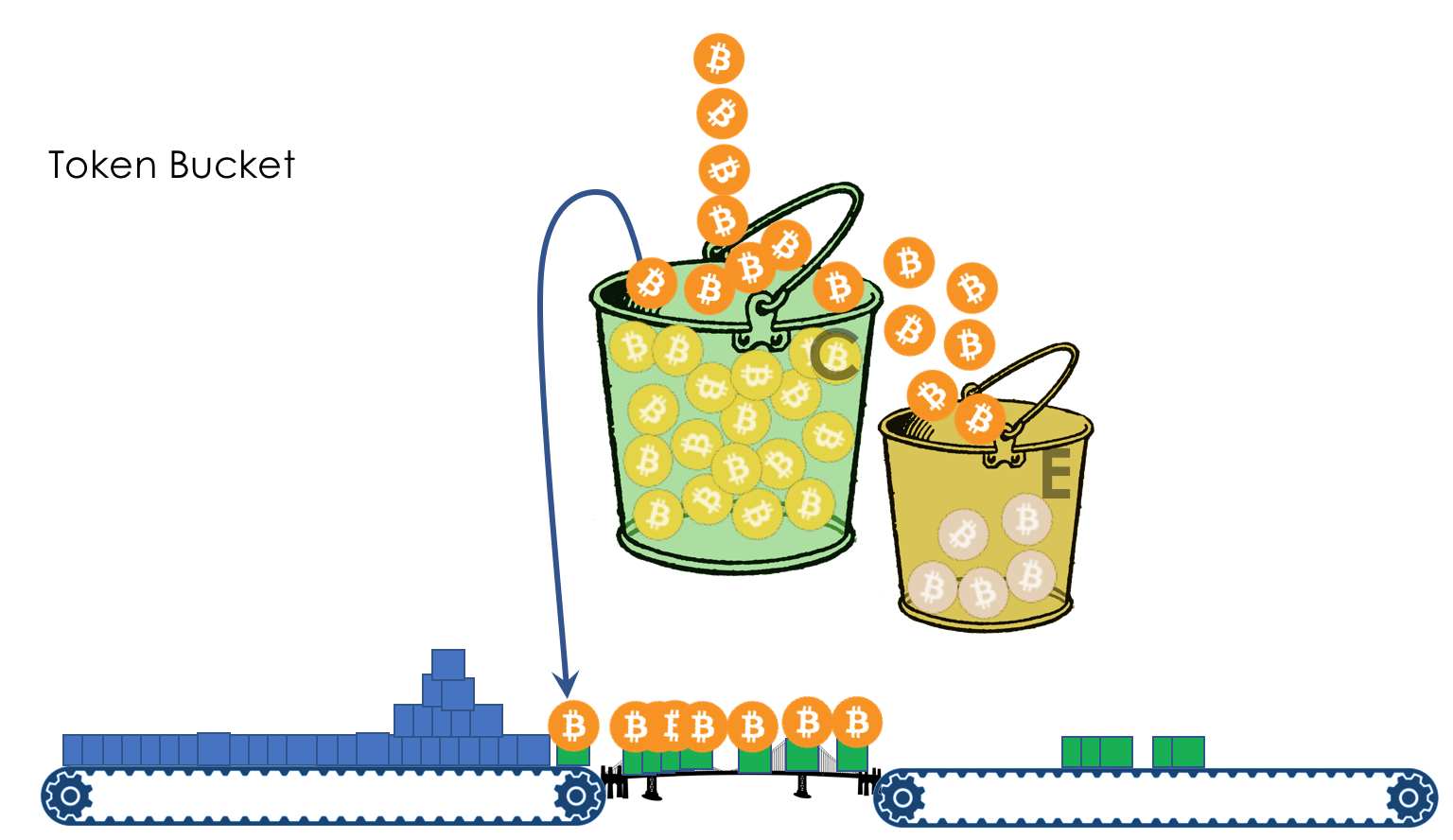
CIR CBS
EBS — Excess Burst Size — .
Te —
E .
 B
B . Entonces
- C , . C B (: Tc — B).
- C , E . , ( ), E B .

- E , , .

, Tc Te
.
8000 ,
C 3000 ,
E — 7000.
C ,
E — — .
. , CIR+CBS ( , / ) — . ,
C , Te
E .
Es decir, puede omitir un poco más, pero en el caso de congestión, es más probable que se descarten.sr-TCM se describe en RFC 2697 .Utilizado para pulir en PHB AF.Bueno, el último sistema es el más flexible y, por lo tanto, complejo: dos velocidades, tres colores.Dos tasas - Marcado tricolor
Tr-TCM , , , .
, 400 /, , 500. 30 ?
P .
:
CIR — .
CBS — (
C ).
PIR — Peak Information Rate — .
EBS — (
P ).
A diferencia de sr-TCM, en tr-TCM, las monedas ahora se entregan independientemente a ambos cubos. En C - con la velocidad de CIR, en P - PIR.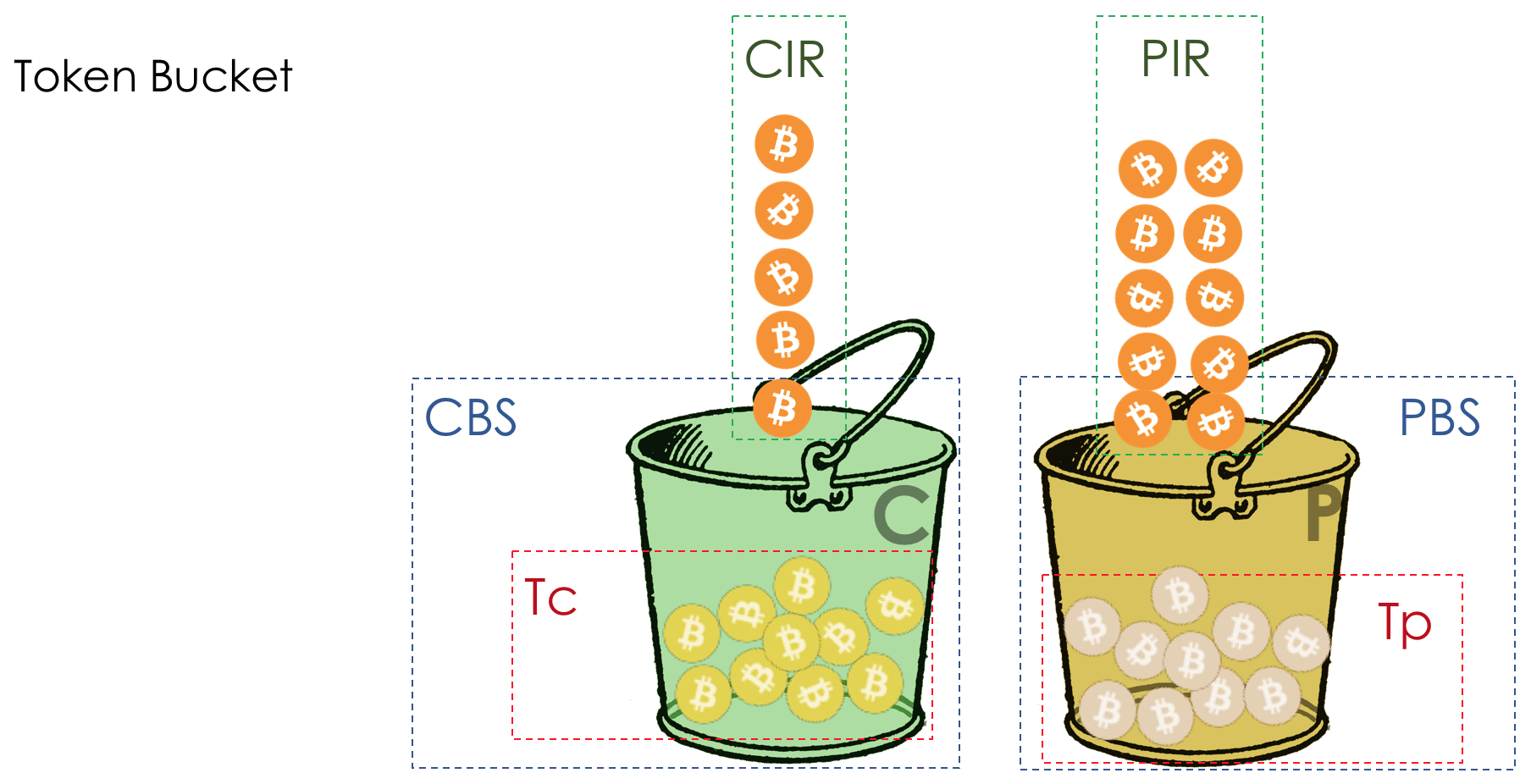 Cuales son las reglas?Llega un paquete de bytes de tamaño B.
Cuales son las reglas?Llega un paquete de bytes de tamaño B.- Si no hay suficientes monedas en el cubo P , el paquete se marca en rojo. Las monedas no se sacan . De lo contrario:
- Si no hay suficientes monedas en el cubo C , el paquete se marca en amarillo y las monedas B se sacan del cubo P. De lo contrario:
- El paquete está marcado en verde y las monedas B se extraen de ambos cubos .

tr-TCM .
, . ,
C ,
P , , PIR (
C ,
P ́ ).
, , ,
P ,
C .
tr-TCM , .
tr-TCM
RFC 2698 .
PHB AF.
Si bien la configuración difiere el tráfico cuando se excede, el pulido lo descarta.La configuración no es adecuada para aplicaciones sensibles a la latencia y la fluctuación de fase.Para implementar el pulido en hardware, se utiliza el algoritmo Token Bucket, para dar forma: Leaky Bucket.Token Bucket puede ser:- Con un cubo - Tasa única - Marcado de dos colores Permite explosiones válidas.
- Con dos cubos - Tasa única - Marcado tricolor (sr-TCM). El excedente del cubo C (CBS) se vierte en el cubo E. Permite sobretensiones permitidas y redundantes.
- Con dos cubos - Dos velocidades - Marcado de tres colores (tr-TCM). Los cucharones C y P (PBS) se reponen independientemente a diferentes velocidades. Permite la velocidad máxima y explosiones permitidas y excesivas.
sr-TCM se centra en la cantidad de tráfico por encima del límite. tr-TCM: a la velocidad con la que llega.El pulido se puede utilizar en la entrada y salida del dispositivo. La conformación es predominantemente a la salida.Para PHB CS y EF, se utiliza la marca de dos colores de tasa única.Para AF, sr-TCM o tr-TCM.Para una mejor comprensión, recomiendo consultar el RFC original o leer aquí .Token Bucket . , , , , .
, — , . , , , — .
, . — . .
Arriba, describí todos los mecanismos básicos de QoS, si no profundizo en la QoS jerárquica. Un sistema sofisticado con muchas partes móviles.Todo estaba bien (¿verdad?) Sonó hasta ahora, pero ¿qué está sucediendo debajo del panel externo de vainilla del enrutador?A lo largo de los años, los proveedores han agregado más y más contornos, desarrollado chips sofisticados, buffers expandidos, por un lado, para mantenerse al día con el creciente volumen de tráfico y sus nuevas categorías, y por otro, para resolver los crecientes problemas causados por el primer párrafo.La carrera en curso. Los paquetes no deben perderse si el competidor no los pierde. No puedes rechazar la funcionalidad si un oponente está con él debajo de las puertas del cliente.¡Ida a la guarida de la propiedad!9. Implementación de hardware de QoS
En este capítulo, asumo la tarea desagradecida. Si lo describe de la manera más simple posible, siempre habrá quienes digan que no todo es así en realidad.Si lo describe como es, el lector dejará caer el artículo porque se convertirá en un dibujo submarino, más precisamente, dibujos de tres barcos con lápices de diferentes colores en una hoja.En general, haré un descargo de responsabilidad de que, en realidad, no todo es igual que en la realidad, e iré de acuerdo con la versión de una presentación simple.Perdóname mi compañero perfeccionista.¿Qué controla el comportamiento del nodo y activa los mecanismos apropiados en relación con el paquete? ¿La prioridad que tiene en uno de los títulos? Si y no

, .

, , - .
(BA MF) .
.
— , , , (CoS) (Drop Precedence). — DSCP, .
En principio, dentro del cuadro puede establecer una longitud de marcado arbitraria sin estar atado a estándares y definir acciones muy flexibles con el paquete.En Cisco, el etiquetado interno se llama Grupo QoS, en Juniper - Forwarding Class, Huawei no ha decidido: en algún lugar llama prioridades internas, en algún lugar prioridades locales, en algún lugar Clase de servicio y en algún lugar solo CoS. Agregue nombres para otros proveedores en los comentarios, agregaré.Esta marca interna se asigna en función de la clasificación que realizó el nodo.Es importante que, a menos que se indique lo contrario, el etiquetado interno funciona solo dentro del nodo, pero luego no aparece en el etiquetado en los encabezados del paquete que se enviará desde el nodo; seguirá siendo el mismo.Sin embargo, en la entrada al dominio DS después de la clasificación, generalmente hay un cambio de marca en una determinada clase de servicio aceptada en esta red. Luego, el etiquetado interno se convierte al valor aceptado para esta clase en la red y se registra en el encabezado del paquete que se envía.El etiquetado interno CoS y Drop Precedence define el comportamiento solo dentro de un nodo dado y no se transmite explícitamente a los vecinos, excepto para el reetiquetado de encabezados.CoS y Drop Precedence definen el PHB, sus mecanismos y parámetros: prevención de congestión, gestión de congestión, programación y reetiquetado.
¿Qué círculos pasan los paquetes entre las interfaces de entrada y salida? Revisé en un artículo anterior . En realidad, resultó no programado, ya que en algún momento se hizo obvio que sin comprender la arquitectura era prematuro hablar de QoS.Sin embargo, repitamos.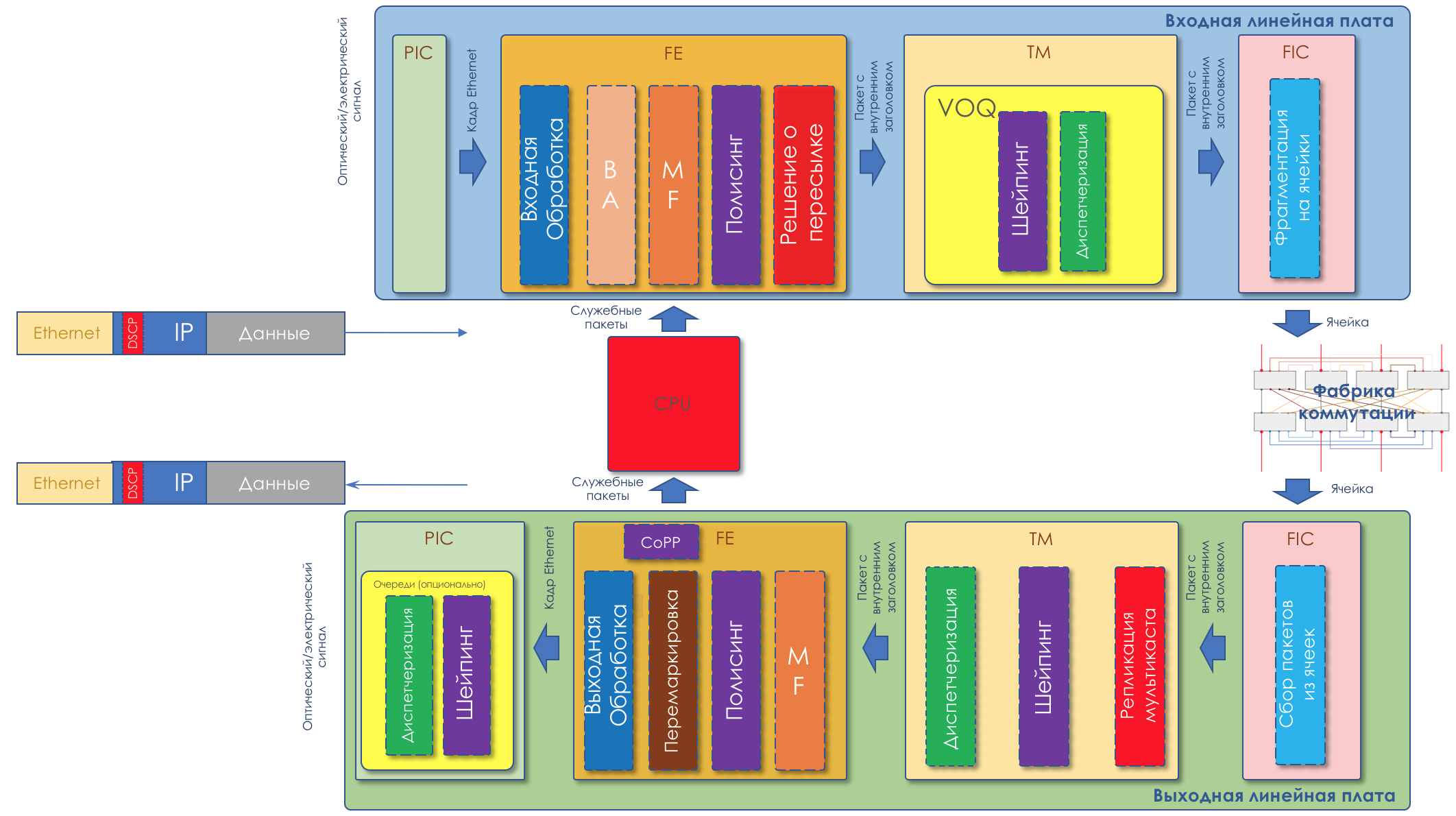
- La señal golpea la interfaz de entrada física y su chip (PIC). Un flujo de bits fluye de él y luego un paquete con todos los encabezados.
- Junto al chip de conmutación de entrada (FE), donde los encabezados se separan del cuerpo del paquete. La clasificación se produce y se determina a dónde debe enviarse el paquete.
- Junto a la cola de entrada (TM / VOQ). Ya aquí los paquetes se presentan en diferentes colas según su clase.
- Además de la fábrica de conmutación (si existe).
- Al lado de la cola de salida (TM).
- (FE), .
- (, ) (PIC).
En este caso, el enrutador debe resolver una ecuación compleja.Expanda todo en clases, proporcione a alguien una banda ancha, alguien de baja latencia, alguien que no garantice pérdidas.Y al mismo tiempo, tenga tiempo para omitir todo el tráfico si es posible.Además, debe realizar la conformación, posiblemente el pulido. Si se produce una sobrecarga repentina, entonces enfréntela.Y esto no cuenta las búsquedas, el procesamiento de ACL, el conteo de estadísticas.Cuota inviable. Pero los robots inyectan, no un hombre.De hecho, solo hay dos lugares donde funcionan los mecanismos de QoS: un chip de conmutación y un chip / cola de Traffic Management.Al mismo tiempo, se producen operaciones en el chip de conmutación que requieren análisis o acciones con encabezados.- Clasificación
- Pulido
- Reetiquetado
TM se encarga del resto. Básicamente, estas son operaciones de rutina con un algoritmo predefinido y parámetros personalizados:- Prevención de congestión
- Gestión de la congestión
- Dar forma
TM es un buffer inteligente, generalmente basado en SD-RAM.Es inteligente porque, a) programable, b) puede hacer todo tipo de cosas difíciles con las colas.A menudo se distribuye: los chips SD-RAM se encuentran en cada placa de interfaz, y juntos se combinan en VOQ (Cola de salida virtual), lo que resuelve el problema del bloqueo del cabezal de línea.El hecho es que si el chip de conmutación o la interfaz de salida están bloqueados, le piden al chip de entrada que disminuya la velocidad y no envíe tráfico por algún tiempo. Si solo hay una cola en todas las direcciones, es muy decepcionante que todas las demás sufran de una interfaz de salida. Este es el Jefe de Bloqueo de Línea.VOQ, en la placa de interfaz de entrada, crea varias colas de salida virtual para cada interfaz de salida existente.Además, estas líneas en equipos modernos tienen en cuenta el etiquetado del paquete.Acerca de VOQ se describe con suficiente detalle en una serie de notas aquí .Por cierto, realmente se colocan en la cola, se los promociona, no se les confiscan los paquetes, etc., sino solo los registros sobre ellos. No tiene sentido hacer tantos gestos con grandes conjuntos de bits. Mientras QoS se burla de los registros, los paquetes están perfectamente en su memoria y se recuperan desde allí en la dirección.VOQ es una cola de software (el término en inglés Software Queue es más preciso). Después de eso, inmediatamente antes de la interfaz también hay una cola de hardware, que siempre funciona estrictamente de acuerdo con FIFO. Es casi imposible controlar cualquiera de sus parámetros (por ejemplo, Cisco le permite configurar solo la profundidad con el comando tx-ring-limit).Solo entre las colas de software y hardware, puede ejecutar despachadores arbitrarios. Es en la cola del programa que Head / Tail-drop y AQM, trabajo de pulido y modelado.El tamaño de la cola de hardware es muy pequeño (unidades de paquetes), porque el despachador hace todo el trabajo de apilar la velocidad de línea.Desafortunadamente, aquí puede hacer muchas reservas y, de hecho, tachar todo con un bolígrafo rojo y decir "el vendedor X no es así".
Me gustaría hacer un comentario más sobre los paquetes de servicios. Se manejan de manera diferente a los paquetes de usuario de tránsito.Al generarse localmente, no se verifica el cumplimiento de las reglas de ACL y los límites de velocidad.Los paquetes desde el exterior destinados a la CPU desde el chip de conmutación de salida caen en otras colas, a la CPU, según el tipo de protocolo.Por ejemplo, BFD tiene la máxima prioridad, OSPF puede esperar más tiempo y, por lo general, ICMP no da miedo abandonar. Es decir, cuanto más importante es el paquete para que funcione la red, mayor es su clase de servicio cuando se envía a la CPU. Es por eso que es normal ver demoras variables en el salto de tránsito en el ping o el rastreo: ICMP no es un tráfico prioritario para la CPU.Además, se aplican paquetes de protocoloCoPP - Control Plane Protection (o Policing) - limitación de velocidad para evitar una alta utilización de CPU - nuevamente, mejores caídas predecibles en colas de baja prioridad antes de que comiencen los problemas.CoPP ayudará tanto del DoS dirigido como del comportamiento anormal de la red (por ejemplo, bucles) cuando una gran cantidad de tráfico de transmisión comienza a llegar al dispositivo.
Enlaces utiles
- El mejor libro sobre la teoría y filosofía de QoS: Redes habilitadas para QOS: herramientas y fundamentos .
Algunos extractos de él se pueden leer aquí , pero recomendaría leerlo desde y hacia, sin intercambiar. - QoS Huawei: Special Edition QoS(v6.0) . PHB .
- sr-TCM tr-TCM : Understanding Single-Rate and Dual-Rate Traffic Policing .
- VOQ: What is VOQ and why you should care?
- QoS MPLS: MPLS and Quality of Service .
- QoS Juniper: Juniper CoS notes .
- QoS TCP UDP. : The TCP/IP Guide
- , , : TCP .
- , FQ: Queuing and Scheduling .
, , An Introduction to Computer Networks , , Introduction, . .
- WFQ , , , , , : Weighted Fair Queueing: a packetized approximation for FFS/GP.
- LFI, , , : Link Fragmentation and Interleaving .
Conclusión
.
Gracias
Alexander Fatin ( LoxmatiyMamont ) por una palabra introductoria y valiosos consejos sobre la expresividad y claridad del texto.Alexander Clipper (@ metallicat20) por su revisión por pares.Alexander Klimenko (@ v00lk) por sus duras críticas y los cambios más masivos de los últimos días.Andrey Glazkov (@glazgoo) para comentarios sobre estructura, terminología y comas.Artyom Chernobay para KDPV.Anton Klochkov (@NAT_GTX) para contactos con Miran.Miran (miran.ru) para organizar un servidor con Eva y transmitir. Tradicionalmente, mi familia, que, sin embargo, esta vez sufrió menos por su ausencia cerca en los momentos más difíciles.