Hoy en día, las fibras ópticas se han convertido en una parte integral de las esferas más diversas de la vida humana: desde Internet en el hogar hasta la endoscopia. El uso de fibras ópticas se debe a una serie de ventajas: velocidad de transmisión, resistencia física, ancho de banda, seguridad de la información, etc.
Para aumentar el rendimiento, se creó una fibra óptica multimodo (MMF) cuando la información se transmite a través de varios canales paralelos. A pesar de todas sus ventajas, el MMF también tiene una serie de inconvenientes, uno de los cuales los investigadores decidieron eliminar para mejorar el proceso de transferencia de imágenes. La conclusión es esta: cuando se proyecta una muestra en el lado proximal del MMF, la imagen que obtenemos en el lado distal está manchada, porque sus datos entrantes se distribuyen en muchos modos con diferentes grados de propagación a lo largo de la longitud de la fibra. Los científicos proponen usar una combinación de fibra multimodo y aprendizaje profundo para redes neuronales artificiales para obtener imágenes precisas, incluso cuando se usa endoscopia. Analicemos el informe de los investigadores e intentemos entender cómo funciona y qué da los resultados. Vamos
Base de estudioLas técnicas para utilizar redes neuronales artificiales para descifrar imágenes transmitidas a través de MMF se han desarrollado durante mucho tiempo. Entonces, en los primeros trabajos se describió una red de dos capas, capaz de reconocer aproximadamente 10 imágenes que pasaron por 10 metros de una fibra cosida.
En este estudio, el sistema es mucho más complejo, pero, según los científicos, mucho más eficiente. El paso inicial fue recolectar una gran cantidad de muestras moteadas obtenidas pasando una imagen a través de un MMF. Se han convertido en la base de conocimiento para la formación de DNN (red neuronal artificial basada en
el aprendizaje profundo * ).
 Ejemplo de imagen moteada
Ejemplo de imagen moteadaAprendizaje profundo * : una combinación de métodos de aprendizaje automático basados en la presentación, en lugar de un algoritmo especializado para una tarea específica.
La arquitectura DNN es muy compleja y tiene aproximadamente 14
capas ocultas * .
Capa oculta * : una red neuronal artificial consta de unidades computacionales (neuronas), que se dividen en 3 categorías: entrada, oculta y salida. Las entradas reciben información, las ocultas realizan varios cálculos y los fines de semana transmiten más información.
Para realizar experimentos en DNN, se creó una base de datos de 20,000 números escritos manualmente. A continuación, la base se divide aleatoriamente en grupos:
- 16,000 dígitos - entrenamiento;
- 2,000 dígitos - verificación;
- 2,000 dígitos - prueba.
Preparándose para el experimentoLa imagen a continuación muestra un diagrama de un sistema óptico que se utilizó para recopilar datos.
 Imagen No. 1: diagrama de instalación:
Imagen No. 1: diagrama de instalación:
Fuente láser: una fuente de radiación láser (haz);
HWP - placa de media onda;
M1 es un espejo;
SLM - modulador de luz espacial;
P es un polarizador lineal;
L es la lente;
BS - divisor de haz;
OBJ - objetivo del microscopio;
OF - fibra óptica;
CCD - Cámara CCD.Y ahora en orden. Un rayo láser con una longitud de onda de 560 nm dirige la luz a través de una
fibra óptica gradiente * con un diámetro central de 62.5 μm y una
apertura numérica * 0.275.
Gradient MMF * es una fibra óptica con un perfil de refracción no uniforme, cuando el índice de refracción disminuye gradualmente desde el borde hasta el eje de la fibra.
 Comparación de tipos de fibra: paso multimodo, gradiente multimodo y modo único (de arriba a abajo).
Comparación de tipos de fibra: paso multimodo, gradiente multimodo y modo único (de arriba a abajo).
La apertura numérica * es el seno del ángulo máximo entre la viga y el eje. En este caso, hay una reflexión interna total en la distribución de radiación sobre la fibra.
A una longitud de onda específica, la fibra es capaz de soportar aproximadamente 4.500 modos espaciales. Las muestras de entrada (imágenes) se muestran en un modulador de luz espacial, después de lo cual se redirigen utilizando el sistema 4f a la cara proximal (cercana al centro) del MMF. En el extremo más alejado de la fibra, otro sistema 4f visualiza la mancha que emana de la cara distal (lejos del centro) de la fibra a la cámara CCD.
CCD * es un dispositivo acoplado a carga que implementa la tecnología de transferencia de carga controlada en el volumen de un semiconductor.
Para verificar los modelos de fase y amplitud como señales de entrada para el gradiente MMF, se instaló una placa de media onda antes de SLM y un polarizador lineal después de SLM.
Como se mencionó anteriormente, los números escritos manualmente actuaban como muestras. Fueron tomados de la
base de datos MNIST .
Antes de ser procesados por DNN, cada una de las imágenes grabadas en CCD1 o CCD2 se recortó a 1024 × 1024 píxeles. Además, las imágenes moteadas obtenidas se redujeron a 32 × 32 píxeles y se utilizaron como entrada para DNN.
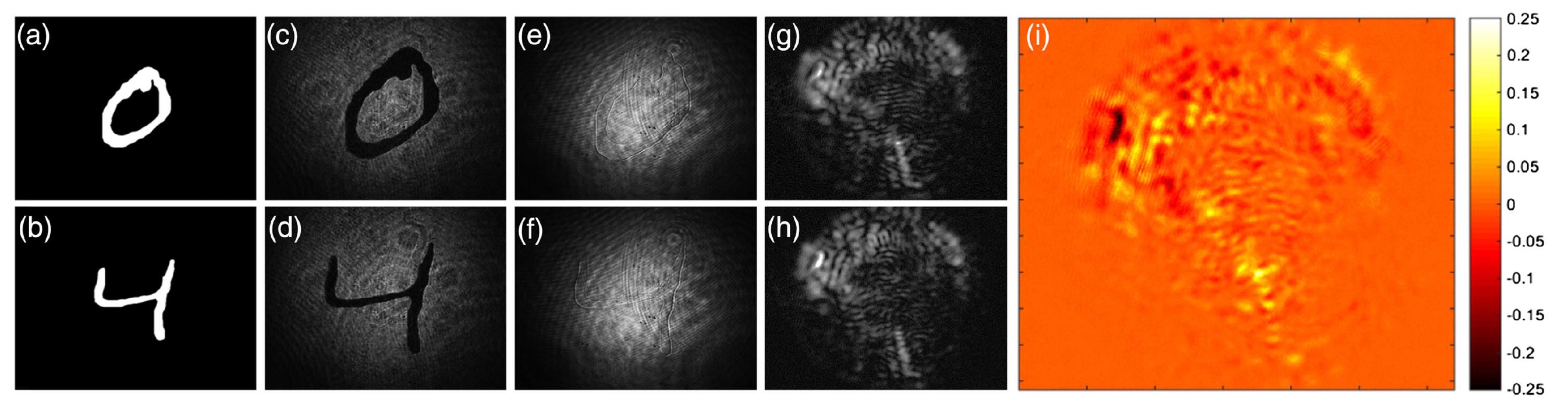
Imagen No. 2En las imágenes
2a y
2b vemos patrones de números (0 y 4).
2c y
2d son los mismos números, pero después de la modulación de amplitud, cuando la amplitud de la señal transmitida estaba sujeta a cambios.
2e y
2f son dígitos de muestra después de la modulación de fase, cuando la fase de la oscilación de la portadora cambió en proporción directa a la señal. También vemos manchas en sí mismas, que se fijaron en la cara distal de la fibra después de pasar una distancia de 2 cm.
Es bastante difícil distinguir motas (
2g y
2h ). Sin embargo, si comparamos las imágenes
2d y
2h (por ejemplo, considere la muestra "4"), entonces podemos aislar la diferencia que DNN puede determinar (
2i ). Por lo tanto, estas características distintivas permitirán al sistema distinguir "0" de "4", "2" de "9", etc.
Procesamiento de datosUna
red neuronal convolucional * del tipo de Grupo de Geometría Visual (VGG) (3a) se convirtió en la base del sistema para determinar motas e imágenes de entrada reconstruidas.
Red neuronal convolucional * : arquitectura ANN, caracterizada por el funcionamiento de la convolución, cuando cada fragmento de imagen se multiplica por la matriz de convolución por elementos, después de lo cual el resultado se suma y se escribe en la misma posición en la imagen de salida.

Un ejemplo de arquitectura de red neuronal convolucional.
La introducción de dicho sistema permitió descifrar imágenes con mayor precisión. Para la reconstrucción de imágenes, se utilizó el tipo de red neuronal convolucional "U-net" con 14 capas ocultas (
3b ).
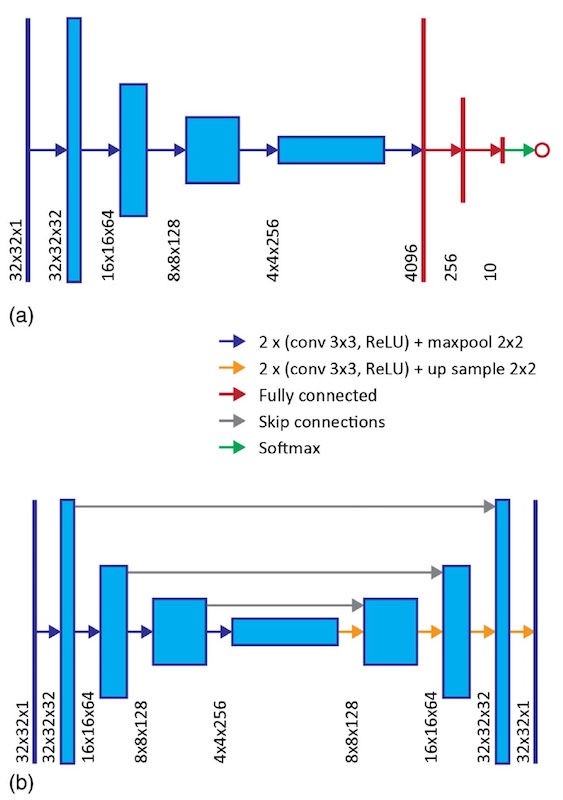 Imagen No. 3
Imagen No. 3Recuerde que la base de 20,000 números se dividió en tres grupos (16,000 para entrenamiento, 2,000 para pruebas y 2,000 para pruebas).
El grupo de capacitación se procesó en lotes de 50 para la red de reconstrucción y 500 para la red de determinación. Al mismo tiempo, las partes cambiaron para evitar la
recapacitación * .
Reentrenamiento * : el caso en que el sistema maneja bien los ejemplos del conjunto de entrenamiento, pero no se adapta bien a los ejemplos de la prueba.
Para minimizar el error de raíz cuadrática media,
se utilizó un algoritmo de optimización con una velocidad de aprendizaje de 1 x 10
-4 .
Las redes pasaron por la fase de entrenamiento no más de 50 épocas (ciclos de propagación hacia atrás). Para cada caso, el entrenamiento se repitió 10 veces para recopilar datos estadísticos sobre la precisión del sistema de entrenamiento.
Todos los DNN se implementaron sobre la base de una sola GPU NVIDIA GeForce GTX 1080Ti utilizando la biblioteca Python TensorFlow 1.5.
Resultados de la investigaciónReconstrucciónEl primer parámetro que los científicos decidieron examinar con más detalle fue la capacidad del sistema para reconstruir los datos de entrada.

La imagen de arriba muestra los resultados de la reconstrucción de los números (0 ... 9), después de pasar los datos a través de una fibra de 0.1 m, 10 my 1000 m de largo.
Como podemos ver, el resultado del procedimiento es muy preciso, lo que confirma la capacidad del sistema U-net para aislar las características distintivas extremas de la imagen futura.
También se verificó el grado de precisión de la reconstrucción. Este indicador disminuye al aumentar la longitud de la fibra de 96.9% (0.1 m) a 90.0% (1000 m).
La disminución en la precisión se debe al hecho de que con una longitud de fibra de 1 km, surgen inhomogeneidades de temperatura (expansión del material debido al calor y / o un cambio en el índice de refracción), que cambian la trayectoria óptica de la señal. Estos procesos conducen al hecho de que el patrón de manchas en el extremo distal se vuelve inestable, lo que dificulta la reconstrucción en la imagen deseada.
Los investigadores señalan que la exposición externa a la fibra también reduce el grado de precisión de la reconstrucción de la imagen. Por lo tanto, con una mejora adicional del sistema, la fibra óptica debería estar provista de aislamiento térmico y un medio isotérmico para lograr el nivel máximo de precisión de reconstrucción.
El procedimiento de reconstrucción también nivela perfectamente los artefactos en la imagen procesada.

Por ejemplo, el sistema aísla la imagen (
2a ) de la moteada distal (
2g ), al tiempo que elimina los defectos proyectados en el borde proximal de la fibra (
2c y
2e ). Además, el sistema intenta eliminar los artefactos que han surgido debido a la contaminación o defectos en la muestra o imprecisiones estructurales de la fibra misma.
Clasificación de muestras de cirf.El sistema puede recrear la imagen, y la precisión de este proceso es muy impresionante. Ahora pasamos al análisis de la precisión con que el sistema puede determinar dónde está la imagen (número), es decir, clasificar los datos después de su reconstrucción.
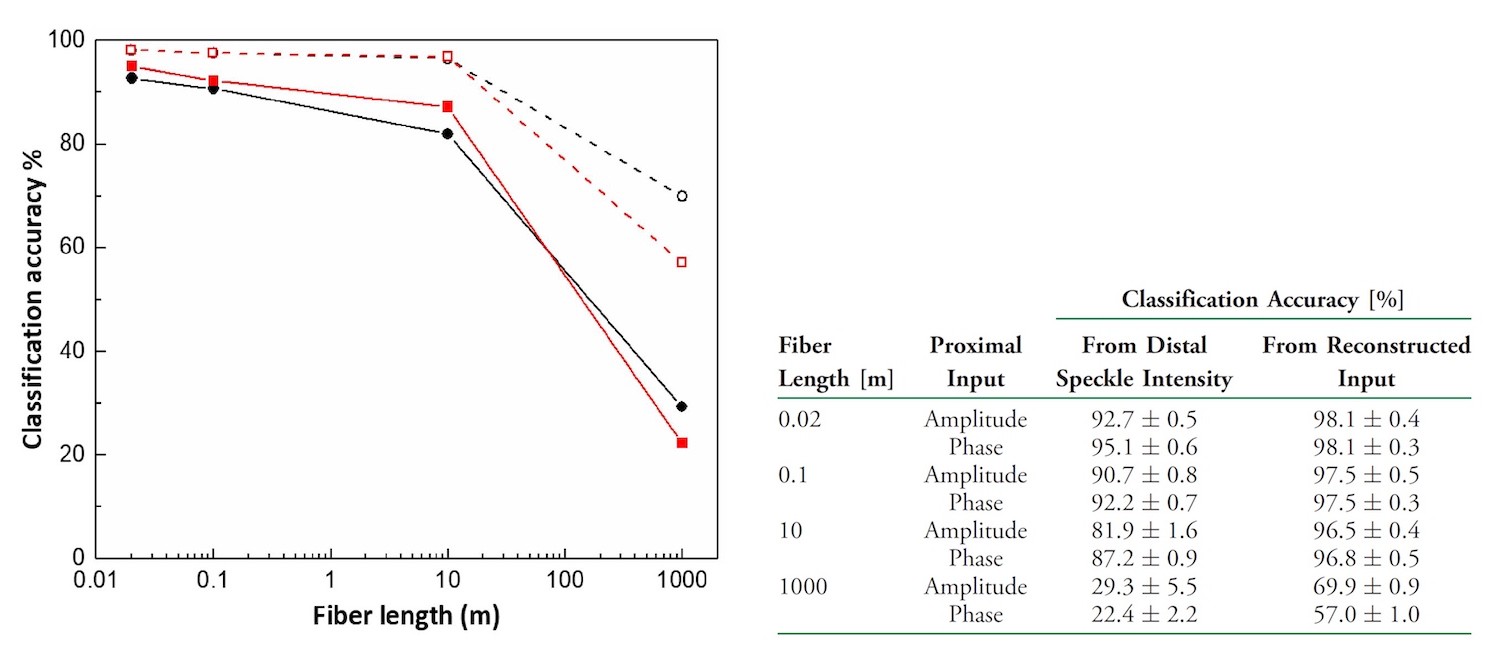
Del gráfico y la tabla de arriba se puede ver que la precisión de la clasificación disminuye al aumentar la longitud de la fibra involucrada en la transmisión. Una tendencia similar fue con la precisión de la reconstrucción. Independientemente de si el modelo de amplitud o la fase, la precisión disminuye. A 2 cm de fibra - 90% de precisión. Este es un buen indicador, pero la fibra es demasiado corta. Pero con una longitud de 1 km, la precisión cae al 30%. Los investigadores atribuyen esto al aumento de las pérdidas por dispersión, el acoplamiento de modo y la deriva de manchas distales. Todas estas "interferencias" son causadas por el aumento en la longitud de la fibra.
 Cambios de manchas distales
Cambios de manchas distalesLa grabación se realizó con una velocidad de fotogramas de 83 fps. Como experimento en una fibra de 1 km, se transmitió una imagen vacía.
 (a) y (b) - 2 cuadros tomados del registro anterior, (c) - su comparación.
(a) y (b) - 2 cuadros tomados del registro anterior, (c) - su comparación.Estos cuadros fueron grabados con una diferencia de 2 segundos. Y como vemos en la imagen (c), la diferencia entre ellos es muy significativa. Tales cambios bruscos en la mancha pueden estar asociados con fluctuaciones de temperatura del ambiente o flujos de aire sobre el dispositivo (imagen No. 1), que pueden causar pequeñas perturbaciones de la fibra. Pero cuando la longitud de la fibra aumenta, la fuerza de tales perturbaciones se vuelve notable.
Resulta que toda la operación del sistema será en vano debido a estas "interferencias". Sin embargo, los científicos no detienen tales dificultades, sino que los alientan a pensar.
Se decidió realizar un estudio sobre el desplazamiento de manchas y cómo afectan la precisión de la clasificación de imágenes. Para esto, la red VGG se capacitó sobre la base de 10,000 muestras (la mitad de las disponibles), luego se realizaron las pruebas, pero con la otra mitad de las muestras. El proceso se repitió, cambiando 2 grupos de muestras en lugares. Los resultados mostraron que no hay cambios significativos en la precisión de la clasificación, ya que el cambio de las motas no es accidental, lo que significa que el ANN puede estudiarlo, recordarlo y determinarlo en el proceso.
La diferencia entre la amplitud y la modulación de fase fue insignificante. Con una longitud de fibra de 10 my modulación de fase, la clasificación fue ligeramente mejor que con la modulación de amplitud. Esto se debe a una distribución más uniforme de la luz sobre los modos de la fibra óptica. Con la modulación de amplitud, el número de modos involucrados en la transmisión es limitado debido a la excitación espacial selectiva de las fibras.
Si consideramos la opción de una fibra de 1 km de largo, entonces la modulación de amplitud ya excede la fase. Cuando la luz pasa a través de una fibra larga, todos los modos están involucrados en la transmisión de información a la vez.
 Matrices de error (matrices de confusión)
Matrices de error (matrices de confusión)Para mejorar la precisión de la clasificación, el ANN también fue entrenado utilizando muestras ya reconstruidas. También se aplicaron matrices de error, lo que mejoró significativamente la precisión de la clasificación.
Por ejemplo, en el caso de una fibra de 1 km de largo, existe confusión entre los números 4 y 9, así como entre 3, 5, 6 y 8.
Para confirmar, solo mira los resultados de la reconstrucción.
 Números 4 y 9
Números 4 y 9 Números 3, 5, 6 y 8.
Números 3, 5, 6 y 8.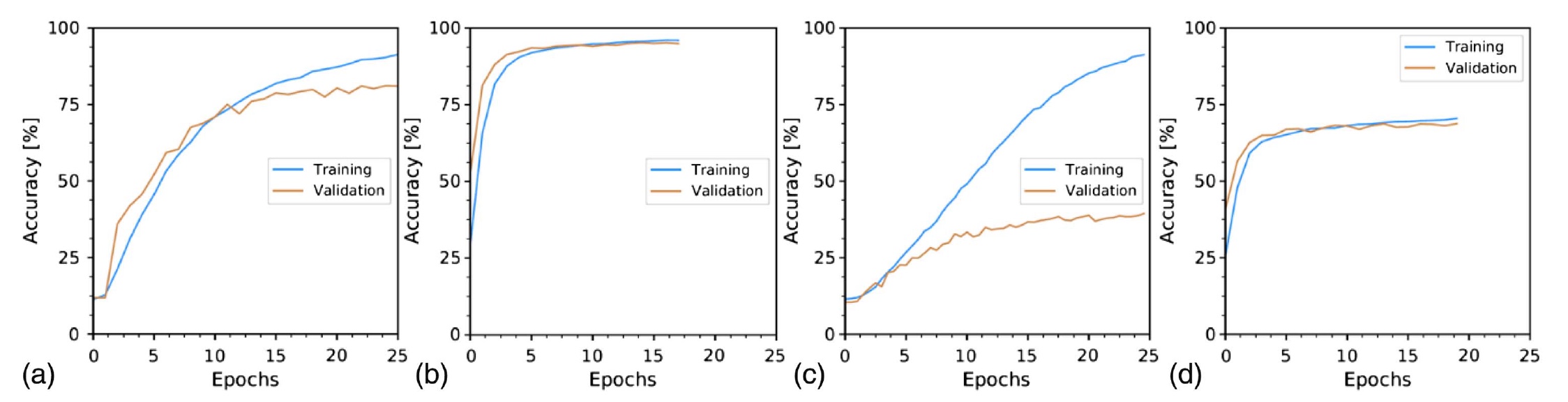
Los gráficos anteriores muestran cambios en la precisión de la clasificación de imágenes a lo largo del tiempo:
a - 10 m de fibra y motas distales;
b - 10 m de fibra e imágenes reconstruidas;
s - 1 km de fibra y motas distales;
d - 1 km de fibra e imágenes reconstruidas.
Para un conocimiento detallado de los matices del estudio, recomiendo mirar el informe de los científicos. Una versión en PDF también está disponible en la misma página (el botón "Obtener PDF").
EpílogoEste estudio mostró excelentes resultados, lo que indica su desarrollo futuro y su implementación práctica. Los métodos anteriores se pueden aplicar para telecomunicaciones (decodificación en multiplexación) e incluso en medicina (endoscopia).
Después de calcular los costos de tiempo, los científicos descubrieron que la mayoría de ellos van a la preparación del sistema, o más bien a su capacitación. Y esto sugiere que un sistema ya capacitado puede realizar sus funciones increíblemente rápido, hasta milisegundos. La única limitación será la potencia del hardware.
Por supuesto, habrá que estudiar mucho más en el campo de las redes neuronales artificiales basadas en el aprendizaje profundo. Pero su utilidad es visible ahora. Mejorar los sistemas existentes, sea cual sea su aplicación, es una actividad tan importante como crear otros nuevos. Después de todo, no siempre es necesario reinventar la rueda, si simplemente puede mejorarla. Lo principal, como lo ha demostrado la práctica, es pensar fuera de la caja, aprender de nuestros propios errores y los de los demás, establecer tareas a veces imposibles y creer en nosotros mismos. Si una idea puede beneficiar a la humanidad, debe realizarse.
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
3 meses gratis al pagar un nuevo Dell R630 por un período de seis meses -
2 x Intel Deca-Core Xeon E5-2630 v4 / 128GB DDR4 / 4x1TB HDD o 2x240GB SSD / 1Gbps 10 TB - desde $ 99.33 al mes , solo hasta el final de agosto, ordene puede estar
aquíDell R730xd 2 veces más barato? ¡Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los Estados Unidos! Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?