El éxito en los proyectos de aprendizaje automático generalmente se asocia no solo con la capacidad de usar diferentes bibliotecas, sino también con la comprensión del área de donde provienen los datos. Una excelente ilustración de esta tesis fue la solución propuesta por el equipo de Alexei Kayuchenko, Sergey Belov, Alexander Drobotov y Alexey Smirnov en la competencia PIK Digital Day. Tomaron el segundo lugar, y después de un par de semanas hablaron sobre su participación y los modelos construidos en la próxima
capacitación de Yandex ML .
Alexey Kayuchenko:
- Buenas tardes! Hablaremos sobre el concurso PIK Digital Day en el que participamos. Un poco sobre el equipo. Éramos cuatro de nosotros. Todo con un fondo completamente diferente, desde diferentes áreas. De hecho, nos encontramos en la final. El equipo se formó justo un día antes de la final. Hablaré sobre el curso de la competencia, la organización del trabajo. Luego, Seryozha saldrá, él contará sobre los datos, y Sasha contará sobre la presentación, el curso final de trabajo y cómo nos movimos a lo largo de la tabla de clasificación.

Brevemente sobre la competencia. La tarea fue muy aplicada. PIC organizó esta competencia proporcionando datos sobre ventas de apartamentos. Como conjunto de datos de entrenamiento, hubo una historia con atributos durante 2 años y medio en Moscú y la región de Moscú. La competencia consistió en dos etapas. Fue una etapa en línea, donde cada uno de los participantes intentó individualmente hacer su propio modelo, y la etapa fuera de línea, no tanto tiempo, fue solo un día desde la mañana hasta la tarde. Golpeó a los líderes de la etapa en línea.
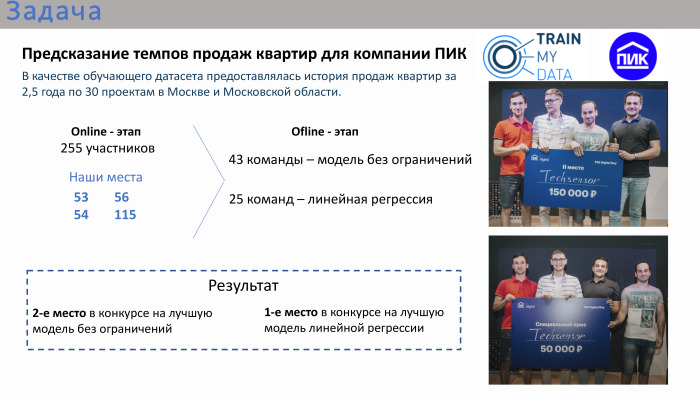
Según los resultados de la competencia en línea, nuestros lugares ni siquiera estaban en el top 10, ni siquiera en el top 20. Estuvimos allí en lugares de 50+. Al final, es decir, la etapa fuera de línea, había 43 equipos. Había muchos equipos formados por una sola persona, aunque era posible unirse. Alrededor de un tercio de los equipos tenían más de una persona. Hubo dos competiciones en la final. La primera competencia es un modelo sin restricciones. Fue posible utilizar cualquier algoritmo: aprendizaje profundo, aprendizaje automático. Paralelamente, se realizó un concurso para la mejor solución de regresión lineal. El organizador consideró que la regresión lineal también se aplicaba bastante, ya que la competencia en sí se aplicaba en su conjunto. Es decir, se planteó la tarea: era necesario predecir el volumen de ventas de apartamentos, teniendo datos históricos de los últimos 2.5 años con atributos.
Nuestro equipo ocupó el segundo lugar en la competencia por el mejor modelo sin restricciones y el primer lugar en la competencia por la mejor regresión. Premio doble

Puedo decir sobre el curso general de la organización que la final fue muy estresante, bastante estresante. Por ejemplo, nuestra decisión ganadora se cargó solo dos minutos antes del final del juego. La decisión anterior nos puso, en mi opinión, en cuarto o quinto lugar. Es decir, trabajamos hasta el final, sin relajarnos. PIC organizó todo muy bien. Había tales mesas, incluso había una terraza para que te pudieras sentar en la calle y respirar aire fresco. Comida, café, todo fue proporcionado. La imagen muestra que todos estaban sentados en sus grupos, trabajando.
Sergey contará más sobre los datos.
Sergey Belov:
Gracias. PIC nos proporcionó varios archivos de datos. Los dos principales son train.csv y test.csv, en los que el PIC generaba alrededor de 50 características. El tren consistió en aproximadamente 10 mil líneas, prueba - de 2 mil.
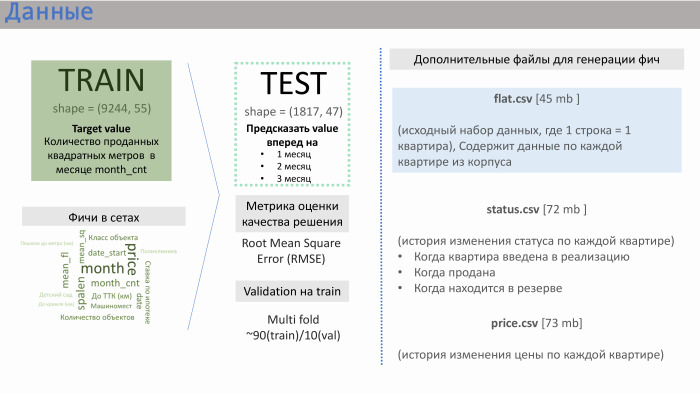
¿Qué proporcionó la cuerda? Contenía datos de ventas. Es decir, como valor (en este caso, objetivo), tuvimos ventas por metros cuadrados para apartamentos promediados sobre un edificio en particular. Había aproximadamente 10 mil de esas líneas. Las características en los conjuntos que generó el PIK en sí se muestran en la diapositiva con el significado aproximado que obtuvimos.
Aquí me ayudó la experiencia en empresas de desarrollo. Las características como la distancia del apartamento al Kremlin o al anillo de transporte, la cantidad de espacios de estacionamiento, no afectan en gran medida las ventas. La influencia es ejercida por la clase del objeto, la latencia y, lo más importante, el número de apartamentos en la implementación en este momento. PIC no generó esta función, pero nos proporcionaron tres archivos adicionales: flat.csv, status.csv y price.csv. Y decidimos echar un vistazo a flat.csv, porque solo había datos sobre la cantidad de apartamentos, su estado.
Y si uno se pregunta qué sirvió como el éxito de nuestra decisión, entonces este es un trabajo de equipo definitivo. Desde el comienzo de esta competencia, trabajamos muy armoniosamente. Inmediatamente discutimos en algún lugar en unos 20 minutos lo que haremos. Llegamos a la conclusión general de que lo primero que necesita para trabajar con datos es porque cualquier científico de datos comprende que hay muchos datos en los datos y, a menudo, la victoria se debe a alguna característica que generó el equipo. Después de trabajar con los datos, utilizamos principalmente varios modelos. Decidimos ver qué resultado dan nuestras características en cada uno de estos modelos, y luego nos enfocamos en el modelo ilimitado y el modelo de regresión lineal.
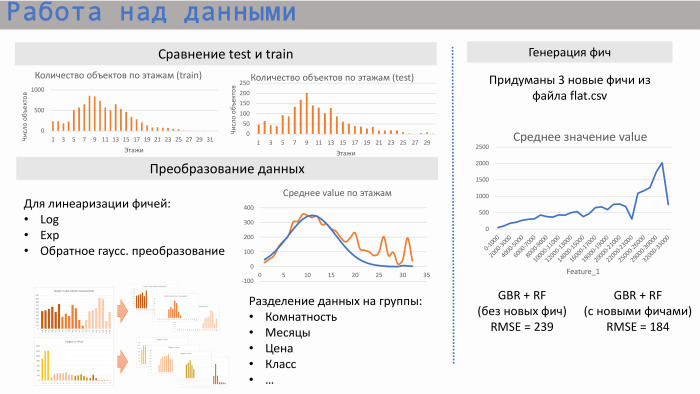
Comenzamos a trabajar con datos. En primer lugar, observamos cómo se relacionan las pruebas del conjunto de trenes, es decir, si las áreas de estos datos se cruzan. Sí, se cruzan: en el número de apartamentos, y en la latencia, y en un cierto número promedio de pisos.
Además para la regresión lineal, comenzamos a realizar ciertas transformaciones. Es como los logaritmos estándar de un exponente. Por ejemplo, en el caso del piso medio, esta fue la transformación gaussiana inversa para la linealización. También notamos que a veces es mejor separar los datos en grupos. Si tomamos, por ejemplo, la distancia desde el apartamento hasta el metro o su habitación, entonces hay mercados ligeramente diferentes, y es mejor dividir, hacer diferentes modelos para cada grupo.
Generamos tres características del archivo flat.csv. Uno de ellos se presenta aquí. Se puede ver que tiene una relación lineal bastante buena, además de este hundimiento. ¿Cuál fue esta característica? Corresponde a la cantidad de apartamentos que se encuentran actualmente en ejecución. Y esta característica funciona muy bien en valores bajos. Es decir, no puede haber más apartamentos vendidos que la cantidad que está en la venta. Pero en estos archivos, de hecho, se estableció un cierto factor humano, porque a menudo son compilados por humanos. Vimos directamente los puntos que quedan fuera de esta área, porque estaban obstruidos un poco incorrectamente.
Ejemplo de scikit-learn. Un modelo de GBR y Random Forest sin características le dio a RMSE 239, y con estas tres características, 184.
Sasha hablará sobre los modelos que usamos.
Alexander Drobotov:
- Algunas palabras sobre nuestro enfoque. Como dijeron los muchachos, todos somos diferentes, venimos de diferentes áreas, de diferente educación. Y teníamos diferentes enfoques. En la etapa final, Lesha usó más XGBoost de Yandex (muy probablemente, me refiero a CatBoost - ed.), Seryozha - la biblioteca de aprendizaje de scikit, I - LightGBM y regresión lineal.

Los modelos XGBoost, la regresión lineal y Prophet son las tres opciones que nos mostraron la mejor puntuación. Para la regresión lineal, tuvimos una combinación de dos modelos, y para la competencia general, XGBoost, y agregamos una pequeña regresión lineal.

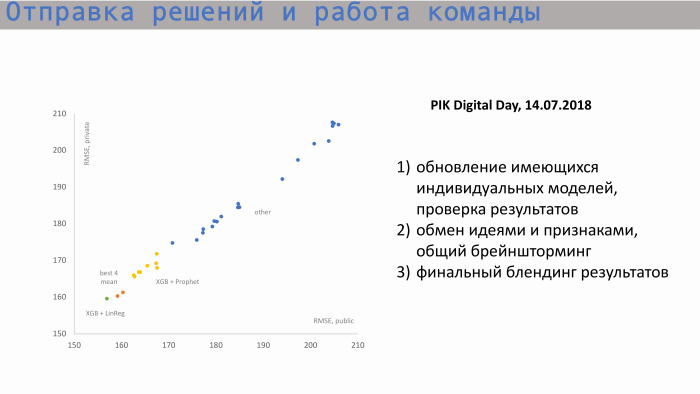
Aquí está el proceso de envío de decisiones y trabajo en equipo. En el gráfico de la izquierda, el eje X es RMSE público, el valor métrico, y el eje Y es el puntaje privado, RMSE. Partimos de estas posiciones. Aquí hay modelos individuales de cada uno de los participantes. Luego, después de intercambiar ideas y crear nuevas características, comenzamos a acercarnos a nuestro mejor puntaje. Nuestros valores para modelos individuales eran aproximadamente los mismos. El mejor modelo individual es XGBoost y Prophet. Prophet creó un pronóstico para las ventas acumuladas. Había un letrero como cuadrado de inicio. Es decir, sabíamos cuántos apartamentos tenemos en total, entendimos qué valor histórico, y el valor incremental buscaba el valor total. Prophet hizo un pronóstico para el futuro, emitió valores en los siguientes períodos y los envió a XGBoost.
La combinación de nuestro mejor puntaje individual está en algún lugar por aquí, estos dos puntos naranjas. Pero este puntaje no fue suficiente para llegar a la cima.
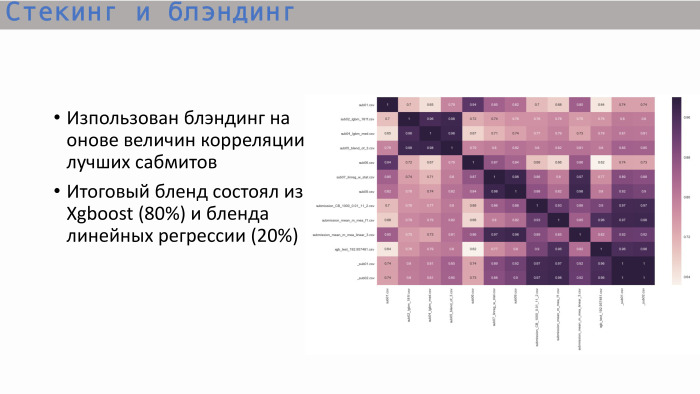
Después de estudiar la matriz de correlación habitual de las mejores presentaciones, vimos lo siguiente: los árboles, y esto es lógico, mostraron una correlación cercana a la unidad, y el mejor árbol dio XGBoost. Muestra una correlación no tan alta con la regresión lineal. Decidimos combinar estas dos opciones en una proporción de 8 a 2. Así es como obtuvimos la mejor solución final.
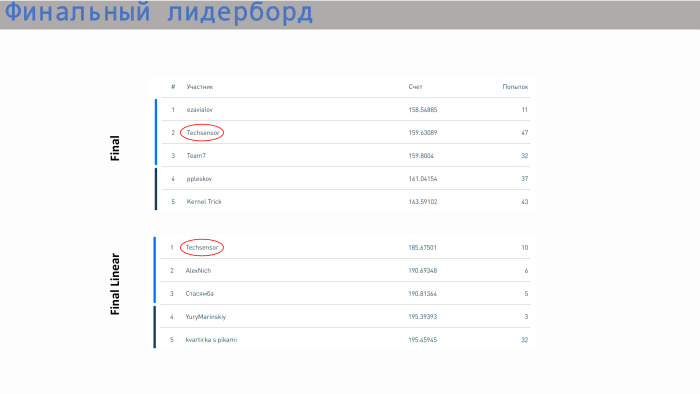
Esta es una tabla de clasificación con resultados. Nuestro equipo ocupó el segundo lugar en modelos ilimitados y el primer lugar en modelos lineales. En cuanto a la puntuación, aquí todos los valores están bastante cerca. La diferencia no es muy grande. Una regresión lineal ya está dando un paso en el área 5. Tenemos todo, ¡gracias!