
Una de las principales conferencias de Data Science del año comenzó hoy en Londres. Trataré de hablar rápidamente sobre lo que fue interesante escuchar.
El comienzo resultó ser nervioso: en la misma mañana, se organizó una reunión masiva de los testigos de Jehová en el mismo centro, por lo que no fue fácil encontrar el mostrador de registro para la policía de tránsito, y cuando finalmente lo encontré, la línea tenía una longitud de 150-200 metros. Sin embargo, después de ~ 20 minutos de espera, recibió una codiciada insignia y fue a una clase magistral.
Privacidad en el análisis de datos.
El primer taller se dedicó a mantener la privacidad en el análisis de datos. Al principio, llegaba tarde, pero, aparentemente, no perdí mucho: hablaron sobre la importancia de la privacidad y sobre cómo los atacantes pueden hacer un mal uso de la información privada que se divulga. Por cierto, dicen personas bastante respetables de Google, LinkedIn y Apple. Como resultado de que la clase magistral dejó una impresión muy positiva, las diapositivas están disponibles
aquí .
Resulta que el concepto de
privacidad diferencial ha existido durante mucho tiempo, cuya idea es agregar ruido que dificulta el establecimiento de valores individuales verdaderos, pero conserva la capacidad de restaurar distribuciones comunes. En realidad, hay dos parámetros:
e : cuán difícil es revelar los datos,
d : cuán distorsionadas son las respuestas.
El concepto original sugiere que hay algún tipo de vínculo intermedio entre el analista y los datos: el "Curador", es él quien procesa todas las solicitudes y genera respuestas para que el ruido oscurezca los datos privados. En realidad, a menudo se usa el modelo de Privacidad diferencial local, en el que los datos del usuario permanecen en el dispositivo del usuario (por ejemplo, un teléfono móvil o PC), sin embargo, al responder a las solicitudes de los desarrolladores, la aplicación envía un paquete de datos desde el dispositivo personal que no permite averiguar exactamente qué Este usuario en particular respondió. Sin embargo, al combinar respuestas de un gran número de usuarios, puede restaurar la imagen general con alta precisión.
Un buen ejemplo es la encuesta "¿Ha tenido un aborto"? Si realiza una encuesta "en la frente", nadie dirá la verdad. Pero si organiza la encuesta de la siguiente manera: "arroje una moneda, si hay un águila, luego tírela nuevamente y diga" sí "al águila, pero" no "a las colas, de lo contrario responda la verdad", es fácil restaurar la verdadera distribución mientras se mantiene la privacidad individual. El desarrollo de esta idea fue la mecánica de recopilar estadísticas confidenciales de
Google RAPPOR (Informe ordinario de preservación de privacidad aleatorio), que se utilizó para recopilar datos sobre el uso de Chrome y sus tenedores.
Inmediatamente después del lanzamiento de Chrome en código abierto, apareció un número bastante grande de personas que querían hacer su propio navegador con una página de inicio anulada, un motor de búsqueda, sus propios dados publicitarios, etc. Naturalmente, los usuarios y Google no estaban entusiasmados con esto. Las acciones adicionales son generalmente comprensibles: para encontrar las sustituciones más comunes y aplastar administrativamente, pero surgió lo inesperado ... La política de privacidad de Chrome no permitió a Google tomar y recopilar información sobre la configuración de la página de inicio y el motor de búsqueda del usuario :(
Para superar esta limitación y creó RAPPOR, que funciona de la siguiente manera:
- Los datos en la página de inicio se registran en un pequeño filtro de floración de aproximadamente 128 bits.
- Se agrega ruido blanco permanente a este filtro de floración. Permanente = lo mismo para este usuario, sin ahorrar ruido, múltiples solicitudes podrían revelar datos del usuario.
- Además del ruido constante, el ruido individual generado para cada solicitud se superpone.
- El vector de bits resultante se envía a Google, donde comienza el descifrado de la imagen general.
- Primero, por métodos estadísticos, restamos el efecto del ruido de la imagen general.
- A continuación, creamos vectores de bits candidatos (los sitios / motores de búsqueda más populares en principio).
- Usando los vectores obtenidos como base, construimos una regresión lineal para reconstruir la imagen.
- Combine la regresión lineal con LASSO para suprimir candidatos irrelevantes.
Esquemáticamente, la construcción del filtro se ve así:

La experiencia de implementar RAPPOR resultó ser muy positiva, y el número de estadísticas privadas recopiladas con su ayuda está creciendo rápidamente. Entre los principales factores de éxito, los autores identificaron:
- Simplicidad y claridad del modelo.
- Apertura y documentación del código.
- La presencia en los gráficos finales de los límites de los errores.
Sin embargo, este enfoque tiene una limitación significativa: es necesario tener listas de respuestas candidatas para el descifrado (razón por la cual O - Ordinal). Cuando Apple comenzó a recopilar estadísticas sobre las palabras y los emoji utilizados en los mensajes de texto, quedó claro que este enfoque no era bueno. Como resultado, en la conferencia WDC-2016, una de las principales características nuevas anunciadas en iOS fue la adición de privacidad diferencial. La combinación de una estructura de croquis con ruido adicional también se utilizó como base, sin embargo, muchos problemas técnicos tuvieron que resolverse:
- El cliente (teléfono) debe poder construir y almacenar esta respuesta en un tiempo razonable.
- Además, esta respuesta debe empaquetarse en un mensaje de red de tamaño limitado.
- Del lado de Apple, todo esto debería ser acumulable en un período de tiempo razonable.
Como resultado, se nos ocurrió un esquema usando
count-min-sketch para codificar palabras, luego seleccionamos aleatoriamente la respuesta de solo una de las funciones hash (pero al fijar la elección del par usuario / palabra), el vector se convirtió usando la
transformación Hadamard y se envió al servidor solamente un "bit" significativo para la función hash seleccionada.
Para restaurar el resultado en el servidor, también fue necesario revisar las hipótesis candidatas. Pero resultó que con un tamaño de diccionario grande es demasiado complicado incluso para un clúster. Era necesario seleccionar de manera heurística las áreas de búsqueda más prometedoras. El experimento con el uso de bigrams como puntos de partida, desde el cual luego se puede ensamblar el mosaico, no tuvo éxito: todos los bigrams fueron igualmente populares. El enfoque bigram + word hash resolvió el problema, pero condujo a una violación de la privacidad. Como resultado, nos decidimos por árboles de prefijos: se recopilaron estadísticas sobre las partes iniciales de la palabra y luego sobre la palabra completa.
Sin embargo, un análisis del algoritmo de privacidad utilizado por Apple por la comunidad de investigación ha demostrado que la privacidad aún puede
verse comprometida con estadísticas a largo plazo.
LinkedIn estaba en una situación más difícil con su estudio de la distribución de los salarios de los usuarios. El hecho es que la privacidad diferencial funciona bien cuando tenemos un gran número de mediciones, de lo contrario no es posible restar ruido de manera confiable. En la encuesta salarial, el número de informes es limitado, y LinkedIn decidió tomar un camino diferente: combinar criptografía técnica y herramientas de ciberseguridad con el concepto de
k-anonimato : los datos del usuario se consideran suficientemente disfrazados si los envía en un paquete donde hay k respuestas con los mismos atributos de entrada (por ejemplo, ubicación y profesión) que difieren solo en la variable objetivo (salario).
Como resultado, se construyó un transportador complejo en el que diferentes servicios transmiten datos entre sí, encriptando constantemente para que una sola máquina no pueda abrirlos por completo. Como resultado, los usuarios se dividen por atributos en cohortes, y cuando la cohorte alcanza el tamaño mínimo, sus estadísticas van a HDFS para su análisis.
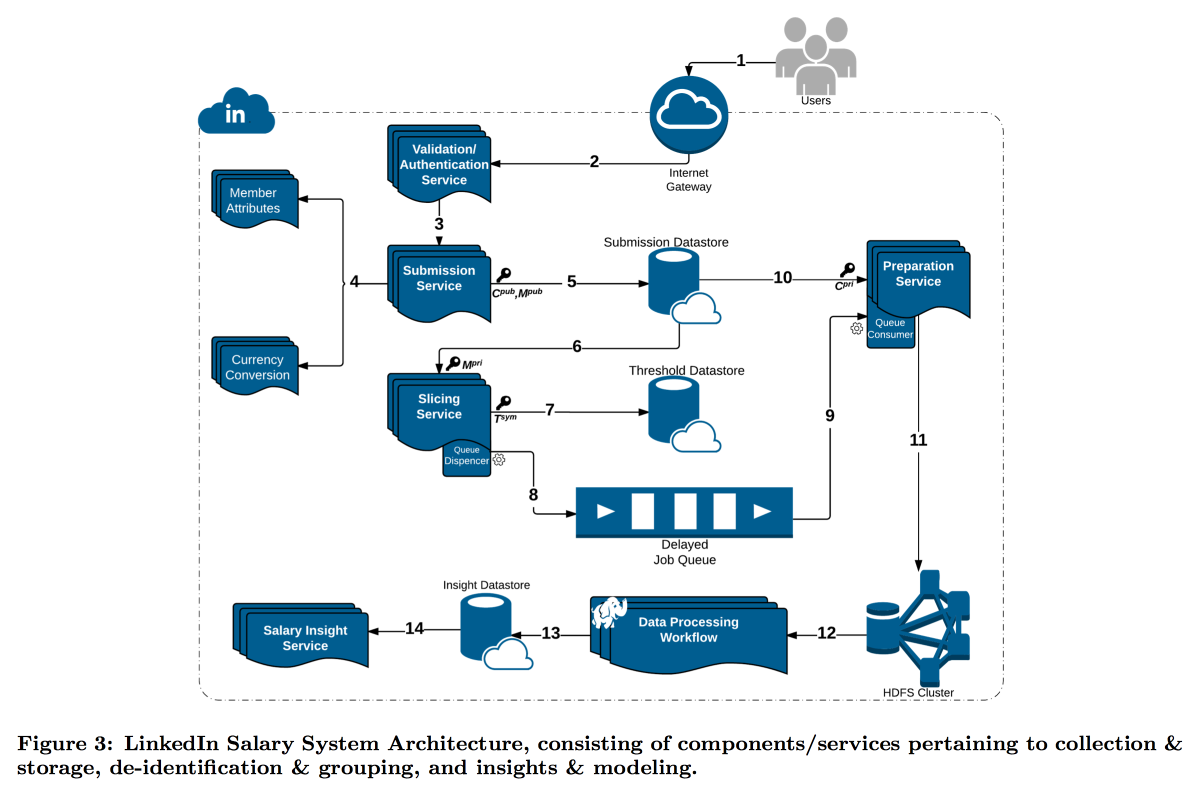
La marca de tiempo merece una atención especial: también debe ser anonimizada, de lo contrario puede averiguar de quién es la respuesta en el registro de llamadas. Pero no quiero quitarme el tiempo por completo, porque es interesante seguir la dinámica. Como resultado, decidimos agregar una marca de tiempo a los atributos por los cuales se construye la cohorte y promediar su valor.
El resultado es una característica premium interesante y algunas preguntas abiertas interesantes:
El RGPD sugiere que, previa solicitud, deberíamos poder eliminar todos los datos del usuario, pero tratamos de ocultarlos para que ahora no podamos encontrar de quién son los datos. Al tener datos sobre una gran cantidad de diferentes sectores / cohortes, puede aislar coincidencias y expandir la lista de atributos abiertos
Este enfoque funciona para datos grandes, pero no funciona con datos continuos. La práctica muestra que simplemente muestrear datos no es una buena idea, pero Microsoft en NIPS2017
propuso una solución sobre cómo trabajar con ellos. Desafortunadamente, los detalles no tuvieron tiempo de revelar.
Análisis de gráfico grande
El segundo taller sobre el análisis de gráficos grandes comenzó por la tarde. A pesar del hecho de que también fue dirigido por los chicos de Google, y había más expectativas de él, le caía muy mal: hablaron sobre sus tecnologías cerradas, luego cayeron en el banalismo y la filosofía general, luego se sumergieron en detalles salvajes, sin siquiera tener tiempo para formular la tarea. Sin embargo, pude captar algunos aspectos interesantes. Las diapositivas se pueden encontrar
aquí .
En primer lugar, me gustó el esquema llamado
agrupamiento del ego-red , creo que es posible construir soluciones interesantes sobre la base. La idea es muy simple:
- Consideramos el gráfico local desde el punto de vista de un usuario específico, PERO menos él mismo.
- Agrupamos este gráfico.
- A continuación, "clonamos" la parte superior de nuestro usuario, agregando una instancia a cada clúster y no conectándolos entre sí por bordes.
En un gráfico transformado similar, muchos problemas se resuelven más fácilmente y los algoritmos de clasificación funcionan mejor. Por ejemplo, es mucho más fácil dividir dicho gráfico de manera equilibrada, y cuando se clasifica en la recomendación de amigos, los nodos del puente son mucho menos ruidosos. Fue para esta tarea que se consideraron / promovieron las recomendaciones de amigos de ENC.
Pero, en general, ENC fue solo un ejemplo, en Google todo un departamento se dedica a desarrollar algoritmos en gráficos y a suministrarlos a otros departamentos como una biblioteca. La funcionalidad declarada de la biblioteca es impresionante: una biblioteca de ensueño para SNA, pero todo está cerrado. En el mejor de los casos, los artículos pueden intentar reproducir bloques individuales. Se afirma que la biblioteca tiene cientos de implementaciones dentro de Google, incluso en gráficos con más de un billón de bordes.
Luego hubo unos 20 minutos de promoción del modelo MapReduce, como si no supiéramos lo genial que fue. Después de lo cual los chicos mostraron que muchos problemas complejos pueden resolverse (aproximadamente) utilizando el modelo de Conjuntos de núcleo componibles aleatorios. La idea principal es que los datos sobre los bordes se dispersan aleatoriamente en N nodos, allí se almacenan en la memoria y el problema se resuelve localmente, después de lo cual los resultados de la solución se transfieren a la máquina central y se agregan. Se argumenta que de esta manera puede obtener buenas aproximaciones a bajo costo para muchos problemas: componentes de conectividad, bosque de expansión mínima, coincidencia máxima, cobertura máxima, etc. En algunos casos, al mismo tiempo, tanto mapper como reduce resuelven el mismo problema, pero pueden ser ligeramente diferentes. Un buen ejemplo de cómo nombrar inteligentemente una solución simple para que la gente crea en ella.
Luego hubo una conversación sobre a qué me dirigía aquí: Particionamiento de gráficos equilibrados. Es decir cómo cortar un gráfico en N partes para que las partes tengan un tamaño aproximadamente igual, y el número de enlaces dentro de las partes sea significativamente mayor que el número de enlaces externos. Si puede resolver bien este problema, entonces muchos algoritmos se vuelven más fáciles, e incluso las pruebas A / B se pueden ejecutar de manera más eficiente, con una compensación por el efecto viral. Pero la historia un poco decepcionada, todo parecía un "plan gnómico": asignar números basados en agrupamientos jerárquicos afines, mover, agregar desequilibrio. Sin detalles Sobre esto en KDD habrá un informe separado de ellos más tarde, intentaré ir. Además hay una
publicación en el blog .
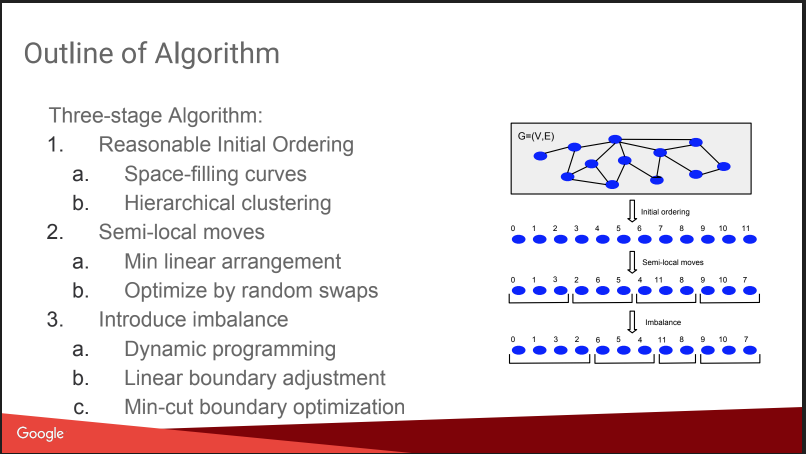
Sin embargo, dieron una comparación con algunos competidores, algunos de ellos abiertos:
Spinner ,
UB13 de FB,
Fennel de Microsoft,
Metis . Puedes mirarlos también.
Luego hablamos un poco sobre detalles técnicos. Utilizan varios paradigmas para trabajar con gráficos:
- MapReduce encima de Flume. No sabía que era posible: Flume no está escrito mucho en Internet para recopilar, pero no para analizar datos. Creo que esta es una perversión intra-google. UPD: descubrí que este es realmente un producto interno de Google, no tiene nada que ver con Apache Flume, hay algunos errores en la nube llamados flujo de datos
- MapReduce + Tabla Hash Distribuida. Dicen que ayuda a reducir significativamente el número de rondas de MP, pero en Internet no se escribe mucho sobre esta técnica, por ejemplo, aquí
- Pregel: dicen que morirá pronto.
- ASYnchronous Message Passing es el mejor, más rápido y más prometedor.
La idea de ASYMP es muy similar a Pregel:
- los nodos se distribuyen, mantienen su estado y pueden enviar un mensaje a los vecinos;
- se crea una cola en la máquina con prioridades, qué enviar (el orden puede diferir del orden de adición);
- habiendo recibido un mensaje, el nodo puede o no cambiar el estado; al cambiar, enviamos un mensaje a los vecinos;
- terminar cuando todas las colas estén vacías.
Por ejemplo, cuando buscamos componentes conectados, inicializamos todos los vértices con pesos aleatorios U [0,1], después de lo cual comenzamos a enviar al menos vecinos entre sí. En consecuencia, habiendo recibido sus mínimos de los vecinos, estamos buscando un mínimo para ellos, etc., hasta que el mínimo se estabilice. Señalan un punto importante para la optimización: colapsar mensajes de un nodo (este es el turno), dejando solo el último. También hablan sobre lo fácil que es recuperarse de fallas mientras se mantiene el estado de los nodos.
Dicen que construyen algoritmos muy rápidos sin problemas, parece ser cierto: el concepto es simple y racional. Hay
publicaciones .
Como resultado, la conclusión se sugiere a sí misma: es triste contar historias sobre tecnologías cerradas, pero se pueden obtener algunas partes útiles.