
En este artículo, construiremos un modelo básico de una red neuronal convolucional que sea capaz de realizar el
reconocimiento de las emociones en las imágenes. El reconocimiento de las emociones en nuestro caso es una tarea de clasificación binaria, cuyo propósito es dividir las imágenes en positivas y negativas.
Aquí puede encontrar todo el código, los documentos del cuaderno y otros materiales, incluido el Dockerfile.
Datos
El primer paso en prácticamente todas las tareas de aprendizaje automático es comprender los datos. Hagámoslo
Estructura del conjunto de datos
Los datos sin procesar se pueden descargar
aquí (en el documento
Baseline.ipynb , todas las acciones en esta sección se realizan automáticamente). Inicialmente, los datos están en el archivo del formato Zip *. Desempaquete y familiarícese con la estructura de los archivos recibidos.
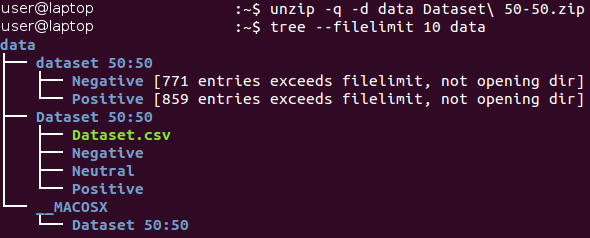
Todas las imágenes se almacenan dentro del catálogo del "conjunto de datos 50:50" y se distribuyen entre sus dos subdirectorios, cuyo nombre corresponde a su clase: Negativo y Positivo. Tenga en cuenta que la tarea está un poco
desequilibrada : el 53 por ciento de las imágenes son positivas y solo el 47 por ciento son negativas. Típicamente, los datos en problemas de clasificación se consideran desequilibrados si el número de ejemplos en diferentes clases varía de manera muy significativa. Hay
varias formas de trabajar con datos desequilibrados, por ejemplo, sobremuestreo, sobremuestreo, cambio del peso de los datos, etc. En nuestro caso, el desequilibrio es insignificante y no debería afectar drásticamente el proceso de aprendizaje. Solo es necesario recordar que el clasificador ingenuo, siempre produciendo el valor "positivo", proporcionará un valor de precisión de aproximadamente el 53 por ciento para este conjunto de datos.
Veamos algunas imágenes de cada clase.
Negativo

 Positivo
Positivo


A primera vista, las imágenes de diferentes clases son realmente diferentes entre sí. Sin embargo, hagamos un estudio más profundo e intentemos encontrar malos ejemplos: imágenes similares pertenecientes a diferentes clases.
Por ejemplo, tenemos alrededor de 90 imágenes de serpientes etiquetadas como negativas y alrededor de 40 imágenes muy similares de serpientes etiquetadas como positivas.
Imagen positiva de una serpiente. Imagen negativa de una serpiente
Imagen negativa de una serpiente
La misma dualidad ocurre con las arañas (130 imágenes negativas y 20 positivas), la desnudez (15 imágenes negativas y 45 positivas) y algunas otras clases. Uno tiene la sensación de que el marcado de las imágenes fue realizado por diferentes personas, y su percepción de la misma imagen puede diferir. Por lo tanto, el etiquetado contiene su inconsistencia inherente. Estas dos imágenes de serpientes son casi idénticas, mientras que diferentes expertos las atribuyen a diferentes clases. Por lo tanto, podemos concluir que es casi imposible garantizar una precisión del 100% cuando se trabaja con esta tarea debido a su naturaleza. Creemos que una estimación más realista de la precisión sería un valor del 80 por ciento; este valor se basa en la proporción de imágenes similares encontradas en diferentes clases durante una verificación visual preliminar.
Separación del proceso de capacitación / verificación.
Siempre nos esforzamos por crear el mejor modelo posible. Sin embargo, ¿cuál es el significado de este concepto? Hay muchos criterios diferentes para esto, como: calidad, tiempo de entrega (aprendizaje + obtención de resultados) y consumo de memoria. Algunos de ellos se pueden medir de manera fácil y objetiva (por ejemplo, el tiempo y el tamaño de la memoria), mientras que otros (calidad) son mucho más difíciles de determinar. Por ejemplo, su modelo puede demostrar una precisión del 100 por ciento al aprender de ejemplos que se han utilizado muchas veces, pero no funcionan con ejemplos nuevos. Este problema se llama
sobreajuste y es uno de los más importantes en el aprendizaje automático. También existe el problema de la
falta de
ajuste : en este caso, el modelo no puede aprender de los datos presentados y muestra malas predicciones incluso cuando se utiliza un conjunto de datos de entrenamiento fijo.
Para resolver el problema del sobreajuste, se utiliza la llamada técnica de
mantener parte de las muestras . Su idea principal es dividir los datos de origen en dos partes:
- Un conjunto de entrenamiento , que generalmente constituye la mayor parte del conjunto de datos y se utiliza para entrenar el modelo.
- El conjunto de pruebas suele ser una pequeña parte de los datos de origen, que se divide en dos partes antes de realizar todos los procedimientos de capacitación. Este conjunto no se utiliza en absoluto en el entrenamiento y se considera como nuevos ejemplos para probar el modelo después de completar el entrenamiento.
Con este método, podemos observar qué tan bien
generaliza nuestro modelo (es decir, funciona con ejemplos previamente desconocidos).
Este artículo utilizará una proporción de 4/1 para los conjuntos de entrenamiento y prueba. Otra técnica que utilizamos es la llamada
estratificación . Este término se refiere a la partición de cada clase independientemente de todas las demás clases. Este enfoque permite mantener el mismo equilibrio entre el tamaño de las clases en los conjuntos de entrenamiento y prueba. La estratificación utiliza implícitamente la suposición de que la distribución de ejemplos no cambia cuando los datos de origen cambian y permanece igual cuando se usan nuevos ejemplos.
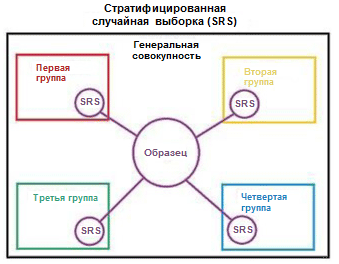
Ilustramos el concepto de estratificación con un ejemplo simple. Supongamos que tenemos cuatro grupos de datos / clases con un número apropiado de objetos: niños (5), adolescentes (10), adultos (80) y personas mayores (5); ver foto a la derecha (de
Wikipedia ). Ahora necesitamos dividir estos datos en dos conjuntos de muestras en una proporción de 3/2. Al utilizar la estratificación de ejemplos, la selección de objetos se realizará independientemente de cada grupo: 2 objetos del grupo de niños, 4 objetos del grupo de adolescentes, 32 objetos del grupo de adultos y 2 objetos del grupo de personas mayores. El nuevo conjunto de datos contiene 40 objetos, que son exactamente 2/5 de los datos originales. Al mismo tiempo, el equilibrio entre las clases en el nuevo conjunto de datos corresponde a su equilibrio en los datos de origen.
Todas las acciones anteriores se implementan en una función, que se llama
prepare_data ; Esta función se puede encontrar en el archivo Python
utils.py . Esta función carga los datos, los divide en conjuntos de entrenamiento y prueba usando un número aleatorio fijo (para reproducción posterior), y luego distribuye los datos en consecuencia entre los directorios en el disco duro para su uso posterior.
Pretratamiento y aumento
En uno de los artículos anteriores, se describieron las acciones de preprocesamiento y las posibles razones para su uso en forma de aumento de datos. Las redes neuronales convolucionales son modelos bastante complejos, y se requieren grandes cantidades de datos para entrenarlos. En nuestro caso, solo hay 1600 ejemplos; esto, por supuesto, no es suficiente.
Por lo tanto, queremos expandir el conjunto de datos utilizados por el
aumento de datos. De acuerdo con la información contenida en el artículo sobre preprocesamiento de datos, la biblioteca Keras * brinda la capacidad de aumentar los datos sobre la marcha al leerlos desde el disco duro. Esto se puede hacer a través de la clase
ImageDataGenerator .
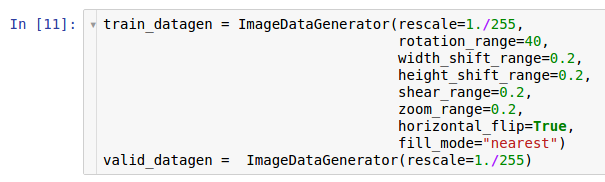
Aquí se crean dos instancias de los generadores. La primera instancia es para entrenamiento y usa muchas transformaciones aleatorias, como rotación, cambio, convolución, escala y rotación horizontal, mientras lee datos del disco y los transfiere al modelo. Como resultado, el modelo recibe los ejemplos convertidos, y cada ejemplo recibido por el modelo es único debido a la naturaleza aleatoria de esta conversión. La segunda copia es para verificación, y solo amplía las imágenes. Los generadores de aprendizaje y prueba solo tienen una transformación común: el zoom. Para asegurar la estabilidad computacional del modelo, es necesario usar el rango [0; 1] en lugar de [0; 255].
Arquitectura modelo
Después de estudiar y preparar los datos iniciales, sigue la etapa de creación del modelo. Dado que tenemos disponible una pequeña cantidad de datos, vamos a construir un modelo relativamente simple para poder entrenarlo adecuadamente y eliminar la situación de sobreajuste. Probemos con la
arquitectura de estilo
VGG , pero usemos menos capas y filtros.
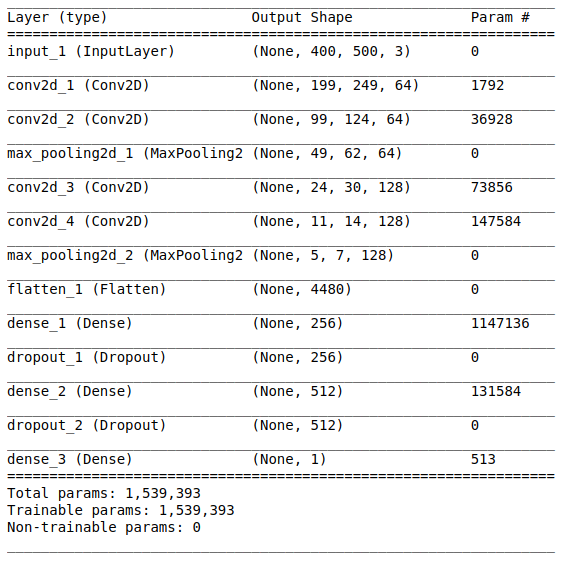

La arquitectura de red consta de las siguientes partes:
[Capa de convolución + capa de convolución + selección de valor máximo] × 2La primera parte contiene dos capas convolucionales superpuestas con 64 filtros (con tamaño 3 y paso 2) y una capa para seleccionar el valor máximo (con tamaño 2 y paso 2) ubicado después de ellos. Esta parte también se conoce comúnmente como
una unidad de extracción de características , ya que los filtros extraen eficientemente características significativas de los datos de entrada (consulte el artículo
Descripción general de redes neuronales convolucionales para la clasificación de imágenes para obtener más información).
AlineaciónEsta parte es obligatoria, ya que los tensores de cuatro dimensiones se obtienen a la salida de la parte convolucional (ejemplos, altura, ancho y canales). Sin embargo, para una capa ordinaria totalmente conectada, necesitamos un tensor bidimensional (ejemplos, características) como entrada. Por lo tanto, es necesario
alinear el tensor alrededor de los últimos tres ejes para combinarlos en un eje. De hecho, esto significa que consideramos cada punto en cada mapa de entidades como una propiedad separada y los alineamos en un vector. La siguiente figura muestra un ejemplo de una imagen 4 × 4 con 128 canales, que se alinea en un vector extendido con una longitud de 1024 elementos.
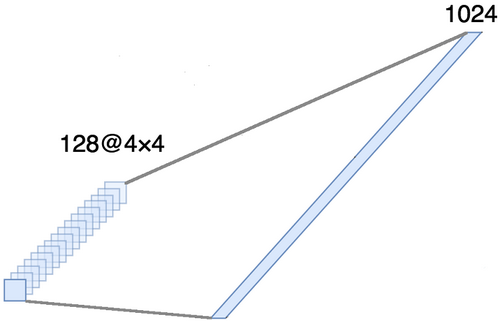 [Capa completa + método de exclusión] × 2
[Capa completa + método de exclusión] × 2Aquí está la
parte de clasificación de la red. Ella toma una vista alineada de las características de las imágenes e intenta clasificarlas de la mejor manera posible. Esta parte de la red consta de dos bloques superpuestos que consisten en una capa totalmente conectada y
un método de exclusión . Ya nos hemos familiarizado con las capas totalmente conectadas, por lo general, son capas con una conexión totalmente conectada. Pero, ¿qué es el "método de exclusión"? El método de exclusión es una
técnica de regularización que ayuda a prevenir el sobreajuste. Uno de los posibles signos de sobreajuste son los valores extremadamente diferentes de los coeficientes de peso (órdenes de magnitud). Hay muchas formas de resolver este problema, incluida la reducción de peso y el método de eliminación. La idea del método de eliminación es desconectar neuronas aleatorias durante el entrenamiento (la lista de neuronas desconectadas debe actualizarse después de cada paquete / era de entrenamiento). Esto evita fuertemente obtener valores completamente diferentes para los coeficientes de ponderación, de esta manera la red se regulariza.
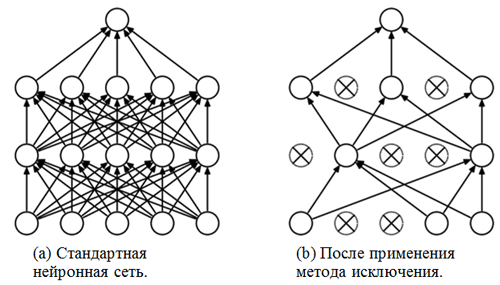
Un ejemplo de la aplicación del método de exclusión (la figura está tomada del artículo
Método de exclusión: una forma fácil de evitar el sobreajuste en redes neuronales ):
Módulo sigmoideLa capa de salida debe corresponder a la declaración del problema. En este caso, estamos lidiando con el problema de clasificación binaria, por lo que necesitamos una neurona de salida con una función de activación
sigmoidea , que estima la probabilidad P de pertenecer a la clase con el número 1 (en nuestro caso, serán imágenes positivas). Entonces, la probabilidad de pertenecer a la clase con el número 0 (imágenes negativas) se puede calcular fácilmente como 1 - P.
Configuraciones y opciones de entrenamiento
Elegimos la arquitectura del modelo y la especificamos utilizando la biblioteca Keras para el lenguaje Python. Además, antes de comenzar el entrenamiento modelo, es necesario
compilarlo .

En la etapa de compilación, el modelo está ajustado para el entrenamiento. En este caso, se deben especificar tres parámetros principales:
- El optimizador En este caso, utilizamos el optimizador predeterminado Adam *, que es un tipo de algoritmo estocástico de descenso de gradiente con un momento y velocidad de aprendizaje adaptativa (para obtener más información, consulte la entrada del blog de S. Ruder Descripción general de los algoritmos de optimización de descenso de gradiente ).
- Función de pérdida . Nuestra tarea es un problema de clasificación binaria, por lo que sería apropiado utilizar la entropía cruzada binaria como una función de pérdida.
- Métricas Este es un argumento opcional con el que puede especificar métricas adicionales para realizar un seguimiento durante el proceso de capacitación. En este caso, necesitamos rastrear la precisión junto con la función objetivo.
Ahora estamos listos para entrenar al modelo. Tenga en cuenta que el procedimiento de capacitación se realiza utilizando los generadores inicializados en la sección anterior.
El número de eras es otro hiperparámetro que se puede personalizar. Aquí simplemente le asignamos un valor de 10. También queremos guardar el modelo y el historial de aprendizaje para poder descargarlo más tarde.

Calificación
Ahora veamos qué tan bien funciona nuestro modelo. En primer lugar, consideramos el cambio en las métricas en el proceso de aprendizaje.
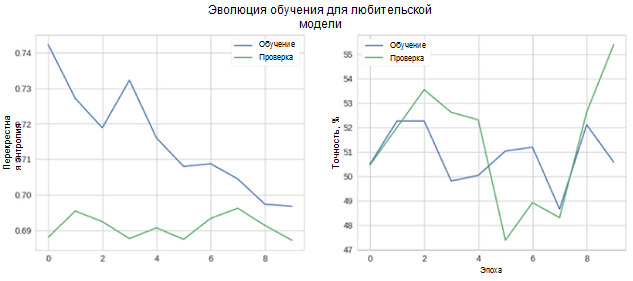
En la figura, puede ver que la entropía cruzada de verificación y precisión no disminuye con el tiempo. Además, la métrica de precisión para el conjunto de entrenamiento y prueba simplemente fluctúa alrededor del valor de un clasificador aleatorio. La precisión final para el conjunto de prueba es del 55 por ciento, que es solo un poco mejor que una estimación aleatoria.
Veamos cómo se distribuyen las predicciones del modelo entre clases. Para este propósito, es necesario crear y visualizar una
matriz de imprecisiones usando la función correspondiente del paquete Sklearn * para el lenguaje Python.
Cada celda en la matriz de imprecisiones tiene su propio nombre:
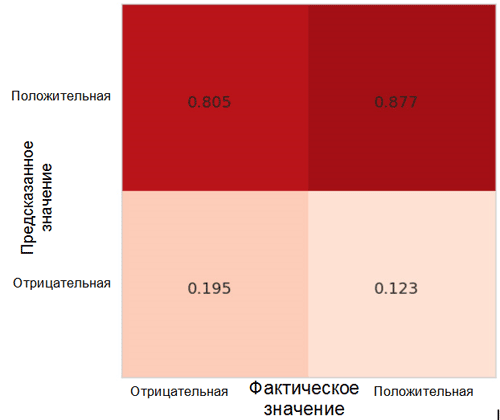
- La tasa positiva verdadera = TPR (celda superior derecha) representa la proporción de ejemplos positivos (clase 1, es decir, emociones positivas en nuestro caso), clasificados correctamente como positivos.
- La tasa de falsos positivos = FPR (celda inferior derecha) representa la proporción de ejemplos positivos que se clasifican incorrectamente como negativos (clase 0, es decir, emociones negativas).
- La tasa negativa verdadera = TNR (celda inferior izquierda) representa la proporción de ejemplos negativos que se clasifican correctamente como negativos.
- La tasa negativa falsa = FNR (celda superior izquierda) representa la proporción de ejemplos negativos que se clasifican incorrectamente como positivos.
En nuestro caso, tanto TPR como FPR están cerca de 1. Esto significa que casi todos los objetos se clasificaron como positivos. Por lo tanto, nuestro modelo no está muy alejado del modelo base ingenuo con predicciones constantes de una clase más grande (en nuestro caso, estas son imágenes positivas).
Otra métrica interesante que es interesante observar es la curva de rendimiento del receptor (curva ROC) y el área bajo esta curva (ROC AUC). Una definición formal de estos conceptos se puede encontrar
aquí . En pocas palabras, la curva ROC muestra qué tan bien funciona el clasificador binario.
El clasificador de nuestra red neuronal convolucional tiene un módulo sigmoide como salida, que asigna la probabilidad del ejemplo a la clase 1. Ahora suponga que nuestro clasificador muestra un buen trabajo y asigna valores de baja probabilidad para ejemplos de la clase 0 (el histograma verde en la figura a continuación) valores de alta probabilidad para ejemplos Clase 1 (histograma azul).
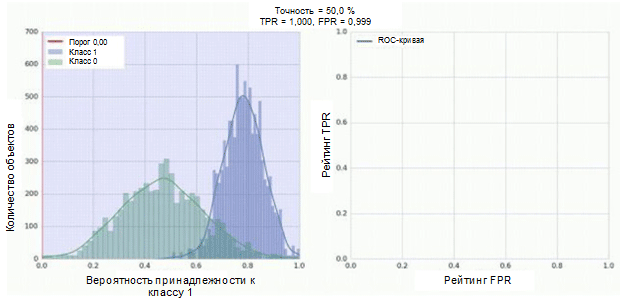
La curva ROC muestra cómo el indicador TPR depende del indicador FPR cuando se mueve el umbral de clasificación de 0 a 1 (figura derecha, parte superior). Para una mejor comprensión del concepto de umbral, recuerde que tenemos la probabilidad de pertenecer a la clase 1 para cada ejemplo. Sin embargo, la probabilidad aún no es una etiqueta de clase. Por lo tanto, debe compararse con un umbral para determinar a qué clase pertenece el ejemplo. Por ejemplo, si el valor umbral es 1, todos los ejemplos deben clasificarse como pertenecientes a la clase 0, ya que el valor de probabilidad no puede ser mayor que 1, mientras que los valores de los indicadores FPR y TPR serán iguales a 0 (dado que ninguna de las muestras se clasifica como positiva ) Esta situación corresponde al punto más a la izquierda en la curva ROC. En el otro lado de la curva hay un punto en el que el valor umbral es 0: esto significa que todas las muestras se clasifican como pertenecientes a la clase 1, y los valores de TPR y FPR son iguales a 1. Los puntos intermedios muestran el comportamiento de la dependencia TPR / FPR cuando el valor umbral cambia.
La línea diagonal en el gráfico corresponde a un clasificador aleatorio. Cuanto mejor funcione nuestro clasificador, más cerca estará su curva del punto superior izquierdo del gráfico. Por lo tanto, el indicador objetivo de la calidad del clasificador es el área bajo la curva ROC (indicador ROC AUC). El valor de este indicador debe ser lo más cercano posible a 1. El valor de AUC de 0.5 corresponde a un clasificador aleatorio.
El AUC en nuestro modelo (ver la figura anterior) es 0.57, lo cual está lejos de ser el mejor resultado.
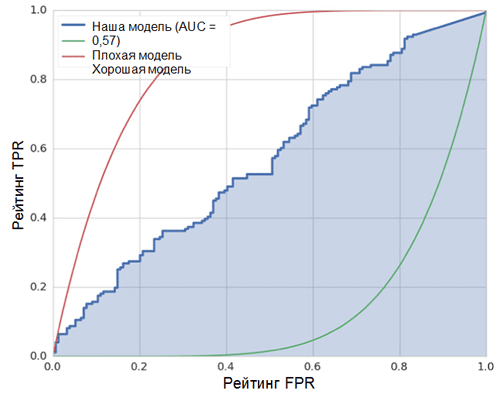
Todas estas métricas indican que el modelo resultante es solo un poco mejor que el clasificador aleatorio. Hay varias razones para esto, las principales se describen a continuación:
- Muy pequeña cantidad de datos para el entrenamiento, insuficiente para resaltar los rasgos característicos de las imágenes. Incluso el aumento de datos no podría ayudar en este caso.
- Un modelo de red neuronal convolucional relativamente complejo (en comparación con otros modelos de aprendizaje automático) con una gran cantidad de parámetros.
Conclusión
En este artículo, creamos un modelo simple de red neuronal convolucional para reconocer las emociones en las imágenes. Al mismo tiempo, en la etapa de entrenamiento, se utilizaron varios métodos para el aumento de datos, y el modelo también se evaluó utilizando un conjunto de métricas como precisión, curva ROC, AUC ROC y matriz de inexactitud. El modelo mostró resultados, solo algunos de los mejores al azar. .