Una demostración del uso de herramientas de código abierto como Packer y Terraform para entregar continuamente cambios de infraestructura a los entornos de nube favoritos de los usuarios.
El material se basó en una presentación de Paul Stack en nuestra conferencia
DevOops 2017 de otoño
. Paul es un desarrollador de infraestructura que solía trabajar en HashiCorp y participó en el desarrollo de herramientas utilizadas por millones de personas (por ejemplo, Terraform). A menudo habla en conferencias y transmite la práctica desde la vanguardia de las implementaciones de CI / CD, los principios de la organización adecuada de la parte de operaciones, y puede explicar claramente por qué los administradores hacen esto. El resto del artículo está narrado en primera persona.
Entonces, comencemos de inmediato con algunos hallazgos clave.
El servidor de larga ejecución apesta

Anteriormente trabajé en una organización donde implementamos Windows Server 2003 en 2008, y hoy todavía están en producción. Y esa compañía no está sola. Utilizando el escritorio remoto en estos servidores, instalan el software manualmente, descargando archivos binarios de Internet. Esta es una muy mala idea, porque los servidores no son típicos. No puede garantizar que ocurra lo mismo en la producción que en su entorno de desarrollo, en el entorno intermedio, en el entorno de control de calidad.
Infraestructura inmutable
En 2013, apareció un artículo en el blog de Chad Foiler titulado "Lanza tus servidores y graba tu código: infraestructura inmutable y componentes desechables" (Chad Foiler
"Basura tus servidores y graba
tu código: infraestructura inmutable y componentes desechables" ). Esto es principalmente una conversación de que la infraestructura inmutable es el camino a seguir. Hemos creado la infraestructura, y si necesitamos cambiarla, estamos creando una nueva infraestructura. Este enfoque es muy común en la nube, porque aquí es rápido y barato. Si tiene centros de datos físicos, esto es un poco más complicado. Obviamente, si ejecuta la virtualización del centro de datos, las cosas se vuelven más fáciles. Sin embargo, si todavía inicia servidores físicos cada vez, se tarda un poco más en ingresar uno nuevo que en modificar uno existente.
Infraestructura desechable
Según los programadores funcionales, "inmutable" es en realidad el término incorrecto para este fenómeno. Porque para ser realmente inmutable, su infraestructura necesita un sistema de archivos de solo lectura: no se escribirán archivos localmente, nadie podrá usar SSH o RDP, etc. Por lo tanto, parece que, de hecho, la infraestructura no es inmutable.
La terminología fue discutida en Twitter durante seis o incluso ocho días por varias personas. Al final, acordaron que una "infraestructura única" es una formulación más apropiada. Cuando finaliza el ciclo de vida de "infraestructura única", puede destruirse fácilmente. No necesita aferrarse a él.
Daré una analogía. Las vacas de granja generalmente no se consideran mascotas.

Cuando tienes ganado en la granja, no les das nombres individuales. Cada individuo tiene un número y una etiqueta. Así es con los servidores. Si aún ha creado servidores manualmente en producción en 2006, tienen nombres significativos, por ejemplo, "Base de datos SQL en producción 01". Y tienen un significado muy específico. Y si uno de los servidores falla, comienza el infierno.
Si uno de los animales del rebaño muere, el granjero simplemente compra uno nuevo. Esta es la "infraestructura de una sola vez".
Entrega continua
Entonces, ¿cómo se combina esto con la entrega continua?
Todo lo que estoy hablando ahora ha existido por bastante tiempo. Solo estoy tratando de combinar las ideas de desarrollo de infraestructura y desarrollo de software.
Los desarrolladores de software llevan mucho tiempo comprometidos con la entrega continua y la integración continua. Por ejemplo, Martin Fowler escribió sobre la integración continua en su blog a principios de la década de 2000. Jez Humble ha promovido durante mucho tiempo la entrega continua.
Si observa más de cerca, no hay nada creado específicamente para el código fuente del software. Existe una definición estándar de Wikipedia:
la entrega continua es un conjunto de prácticas y principios destinados a crear, probar y lanzar software lo más rápido posible .
La definición no significa aplicaciones web o API, se trata de software en general. Crear un software de rompecabezas requiere muchas piezas de rompecabezas. De esta manera, puede practicar la entrega continua de código de infraestructura de la misma manera.
El desarrollo de infraestructura y aplicaciones son direcciones bastante cercanas. Y las personas que escriben código de aplicación también escriben código de infraestructura (y viceversa). Estos mundos comienzan a unirse. Ya no existe tal separación y las trampas específicas de cada uno de los mundos.
Principios y prácticas de entrega continua
La entrega continua tiene una serie de principios:
- El proceso de lanzamiento / implementación de software debe ser repetible y confiable.
- ¡Automatiza todo!
- Si un procedimiento es difícil o doloroso, hágalo con más frecuencia.
- Mantenga todo bajo control de la fuente.
- Hecho: significa "inédito".
- ¡Integre el trabajo con calidad!
- Todos son responsables del proceso de lanzamiento.
- Aumenta la continuidad.
Pero lo más importante, la entrega continua tiene cuatro prácticas. Tómelos y transfiéralos directamente a la infraestructura:
- Cree archivos binarios solo una vez. Construye tu servidor una vez. Aquí estamos hablando de "disposición" desde el principio.
- Use el mismo mecanismo de implementación en cada entorno. No practique diferentes implementaciones en desarrollo y producción. Debe usar la misma ruta en cada entorno. Esto es muy importante
- Pon a prueba tu despliegue. He creado muchas aplicaciones. Creé muchos problemas porque no seguí el mecanismo de implementación. Siempre debes verificar lo que sucede. Y no digo que debas pasar cinco o seis horas en una prueba a gran escala. Suficiente "prueba de humo". Usted tiene una parte clave del sistema que, como sabe, le permite a usted y a su empresa ganar dinero. No seas demasiado vago para comenzar las pruebas. Si no lo hace, puede haber interrupciones que le costarán dinero a su empresa.
- Y finalmente, lo más importante. Si algo se rompe, ¡deténgase y arréglelo de inmediato! No puede permitir que el problema crezca y empeore cada vez más. Tienes que arreglarlo. Esto es realmente importante
¿Alguien ha leído el libro
Entrega continua ?

Estoy seguro de que sus compañías le pagarán una copia que puede transferir dentro del equipo. No estoy diciendo que debas sentarte y pasar un día libre leyéndolo. Si lo hace, probablemente querrá dejarlo. Pero recomiendo dominar periódicamente pequeñas piezas del libro, digerirlas y pensar en cómo transferir esto a su entorno, a su cultura y a su proceso. Una pieza pequeña a la vez. Porque el suministro continuo es una conversación sobre la mejora continua. No es solo sentarse en la oficina con colegas y el jefe y comenzar una conversación con la pregunta: "¿Cómo implementaremos la entrega continua?", Luego escriba 10 cosas en la pizarra y después de 10 días entienda que lo ha implementado. Lleva mucho tiempo, provoca muchas protestas, porque a medida que la implementación cambia la cultura.
Hoy usaremos dos herramientas: Terraform y Packer (ambos son desarrollos de Hashicorp). Una discusión adicional será sobre por qué deberíamos usar Terraform y cómo integrarlo en nuestro entorno. No es casualidad que hable sobre estas dos herramientas. Hasta hace poco, también trabajaba en Hashicorp. Pero incluso después de dejar Hashicorp, sigo contribuyendo al código de estas herramientas, porque en realidad las encuentro muy útiles.
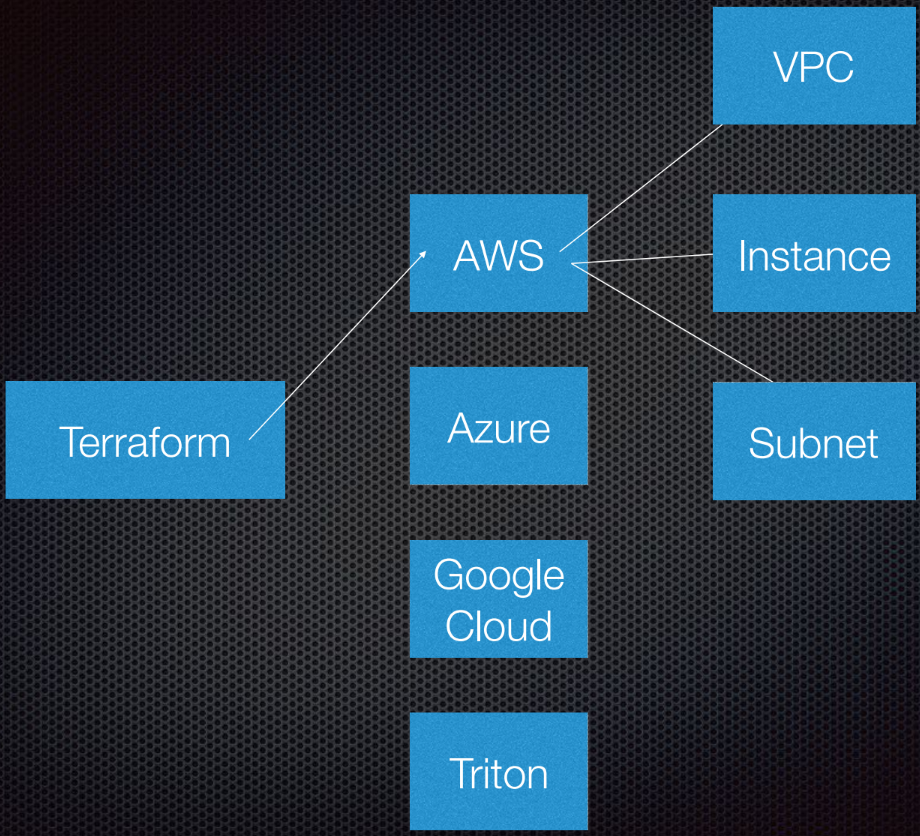
Terraform admite la interacción con proveedores. Los proveedores son nubes, servicios Saas, etc.
Dentro de cada proveedor de servicios en la nube, hay varios recursos, como una subred, VPC, equilibrador de carga, etc. Al usar DSL (lenguaje específico de dominio), le dice a Terraform cómo se verá su infraestructura.
Terraform usa la teoría de grafos.

Probablemente conozcas la teoría de grafos. Los nodos son parte de nuestra infraestructura, como un equilibrador de carga, subred o VPC. Las costillas son las relaciones entre estos sistemas. Esto es todo lo que personalmente considero necesario saber sobre la teoría de grafos para usar Terraform. Dejamos el resto a los expertos.

Terraform en realidad usa un gráfico dirigido porque conoce no solo las relaciones, sino también su orden: que A (supongamos que A es una VPC) debe establecerse en B, que es una subred. Y B debe crearse antes que C (instancia), porque existe un procedimiento prescrito para crear abstracciones en Amazon o cualquier otra nube.
Paul Hinze, que todavía es Director de Infraestructura en Hashicorp, ofrece más información sobre este tema en
YouTube . Por referencia: una gran conversación sobre infraestructura y teoría de grafos.
Practica
Escribir un código es mucho mejor que discutir una teoría.
Previamente creé AMI (Amazon Machine Images). Utilizo Packer para crearlos y les mostraré cómo hacerlo.
AMI es una instancia de un servidor virtual en Amazon, está predefinido (en términos de configuración, aplicaciones, etc.) y se crea a partir de una imagen. Me encanta poder crear nuevas AMI. Esencialmente, los AMI son mis contenedores Docker.
Entonces, tengo AMI, tienen identificación. Al ir a la interfaz de Amazon, vemos que solo tenemos un AMI y nada más:

Puedo mostrarte lo que hay en este AMI. Todo es muy sencillo.
Tengo una plantilla de archivo JSON:
{ "variables": { "source_ami": "", "region": "", "version": "" }, "builders": [{ "type": "amazon-ebs", "region": "{{user 'region'}}", "source_ami": "{{user 'source_ami'}}", "ssh_pty": true, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ssh_timeout": "5m", "associate_public_ip_address": true, "ami_virtualization_type": "hvm", "ami_name": "application_instance-{{isotime \"2006-01-02-1504\"}}", "tags": { "Version": "{{user 'version'}}" } }], "provisioners": [ { "type": "shell", "start_retry_timeout": "10m", "inline": [ "sudo apt-get update -y", "sudo apt-get install -y ntp nginx" ] }, { "type": "file", "source": "application-files/nginx.conf", "destination": "/tmp/nginx.conf" }, { "type": "file", "source": "application-files/index.html", "destination": "/tmp/index.html" }, { "type": "shell", "start_retry_timeout": "5m", "inline": [ "sudo mkdir -p /usr/share/nginx/html", "sudo mv /tmp/index.html /usr/share/nginx/html/index.html", "sudo mv /tmp/nginx.conf /etc/nginx/nginx.conf", "sudo systemctl enable nginx.service" ] } ] }
Tenemos variables que pasamos, y Packer tiene una lista de los llamados Constructores para diferentes áreas; Hay muchos de ellos. Builder utiliza una fuente especial de AMI, que paso en un identificador de AMI. Le doy el nombre de usuario y contraseña de SSH, y también le indico si necesita una dirección IP pública para que las personas puedan acceder a ella desde el exterior. En nuestro caso, esto realmente no importa, porque es una instancia de AWS para Packer.
También configuramos el nombre y las etiquetas de AMI.
No tiene que analizar este código. Él está aquí solo para mostrarte cómo trabaja. La parte más importante aquí es la versión. Será relevante más adelante cuando ingresemos a Terraform.
Después de que el constructor invoca la instancia, los agentes de aprovisionamiento se inician en ella. De hecho, instalo NCP y nginx para mostrarle lo que puedo hacer aquí. Copio algunos archivos y simplemente configuro la configuración de nginx. Todo es muy sencillo. Luego activo nginx para que comience cuando comience la instancia.
Entonces, tengo un servidor de aplicaciones y funciona. Puedo usarlo en el futuro. Sin embargo, siempre reviso mis plantillas de Packer. Porque es una configuración JSON donde puede encontrar algunos problemas.
Para hacer esto, ejecuto el comando:
make validate
Recibo la respuesta de que la plantilla de Packer se verificó correctamente:
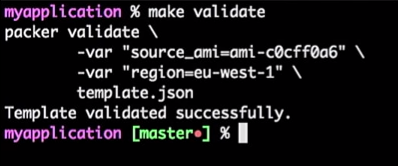
Esto es solo un comando, por lo que puedo conectarlo a la herramienta CI (cualquiera). De hecho, será un proceso: si el desarrollador cambia la plantilla, se genera la solicitud de extracción, la herramienta CI verificará la solicitud, ejecutará el equivalente de la verificación de la plantilla y publicará la plantilla si la verificación es exitosa. Todo esto se puede combinar en el "Maestro".
Obtenemos una transmisión de plantillas AMI: solo necesita elevar la versión.
Supongamos que el desarrollador ha creado una nueva versión de AMI.
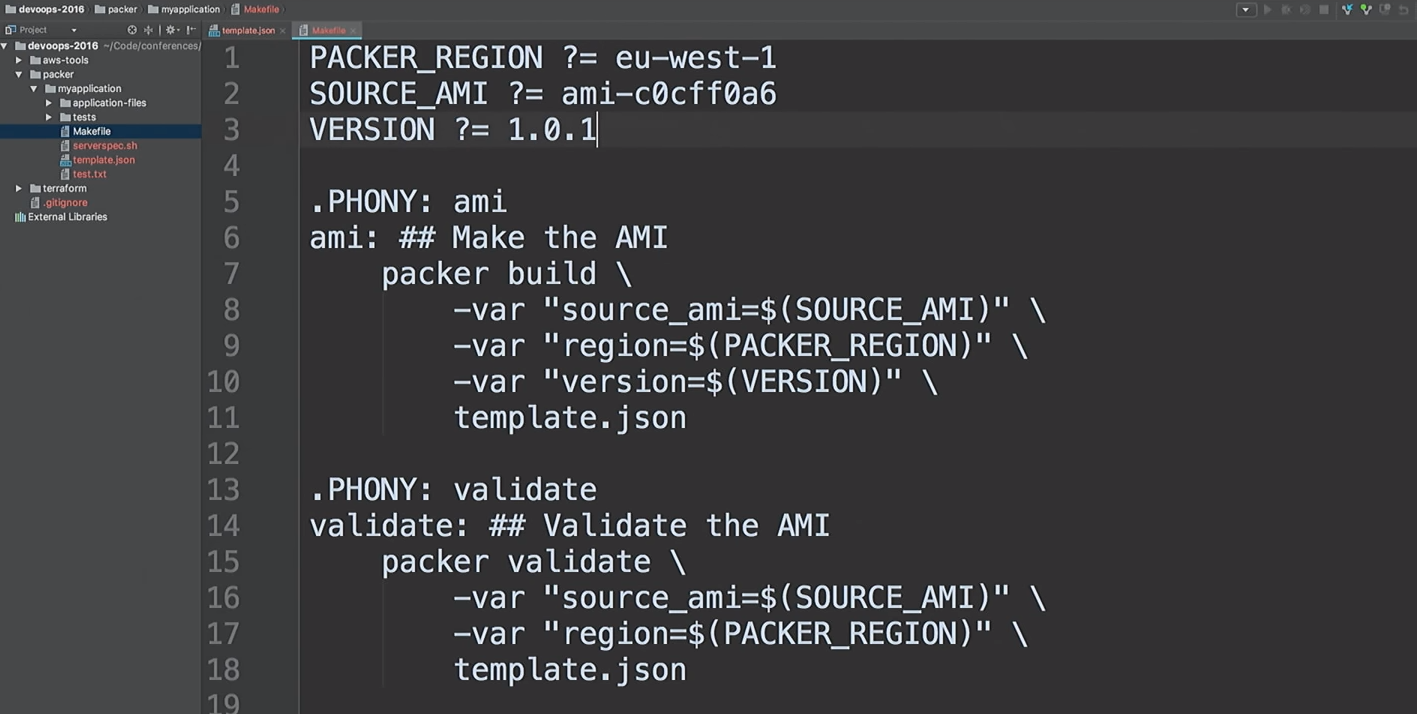
Solo corregiré la versión en los archivos de 1.0.0 a 1.0.1 para mostrarle la diferencia:
<html> <head> <tittle>Welcome to DevOops!</tittle> </head> <body> <h1>Welcome!</h1> <p>Welcome to DevOops!</p> <p>Version: 1.0.1</p> </body> </html>
Volveré a la línea de comando e iniciaré la creación de AMI.
No me gusta correr los mismos equipos. Me gusta crear AMI rápidamente, así que uso archivos MAKE. Echemos un vistazo con
cat en mi archivo MAKE:
cat Makefile

Este es mi archivo MAKE. Incluso proporcioné ayuda: escribo
make y
make clic en la pestaña, y me muestra todo el objetivo.

Entonces, vamos a crear una nueva versión 1.0.1 de AMI.
make ami

De vuelta a Terraform.
Destaco que este no es un código de producción. Esta es una demostración. Hay maneras de hacer lo mismo mejor.
Yo uso módulos de Terraform en todas partes. Como ya no trabajo en Hashicorp, puedo expresar mi opinión sobre los módulos. Para mí, los módulos están en el nivel de encapsulación. Por ejemplo, me gusta encapsular todo lo relacionado con VPC: redes, subredes, tablas de enrutamiento, etc.
¿Qué está pasando adentro? Es posible que a los desarrolladores que trabajan con esto no les importe. Necesitan tener una comprensión básica de cómo funciona la nube, qué es VPC. Pero no es necesario profundizar en los detalles. Solo las personas que realmente necesitan cambiar un módulo deben entenderlo.
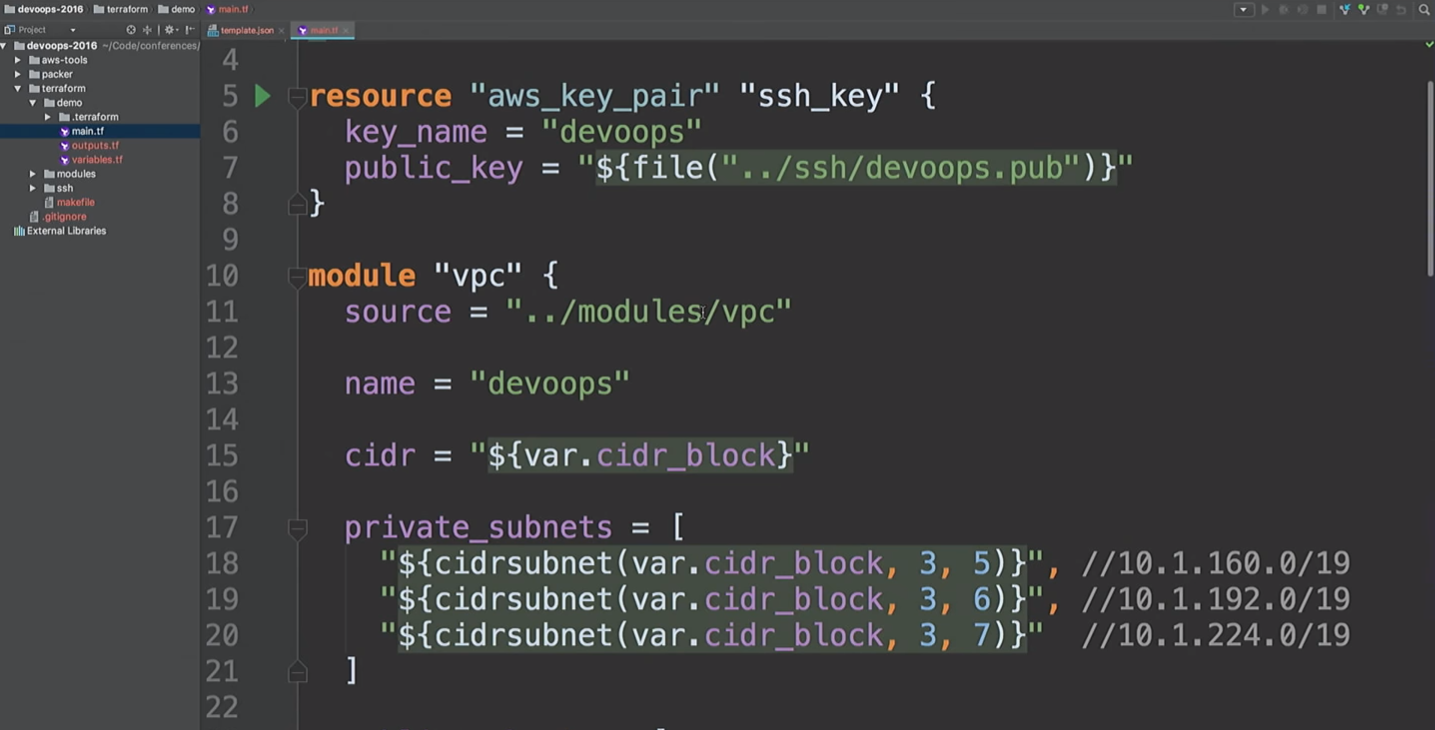

Aquí voy a crear un recurso de AWS y un módulo VPC. ¿Qué está pasando aquí? Tome
cidr_block nivel
cidr_block y cree tres subredes privadas y tres subredes públicas. La siguiente es una lista de zonas de disponibilidad. Pero no sabemos cuáles son estas zonas de accesibilidad.

Vamos a crear una VPN. Simplemente no use este módulo VPN. Esto es openVPN, que crea una instancia de AWS que no tiene un certificado. Utiliza solo la dirección IP pública y se menciona aquí solo para mostrarle que podemos conectarnos a la VPN. Hay herramientas más convenientes para crear una VPN. Me tomó unos 20 minutos y dos cervezas para escribir la mía.
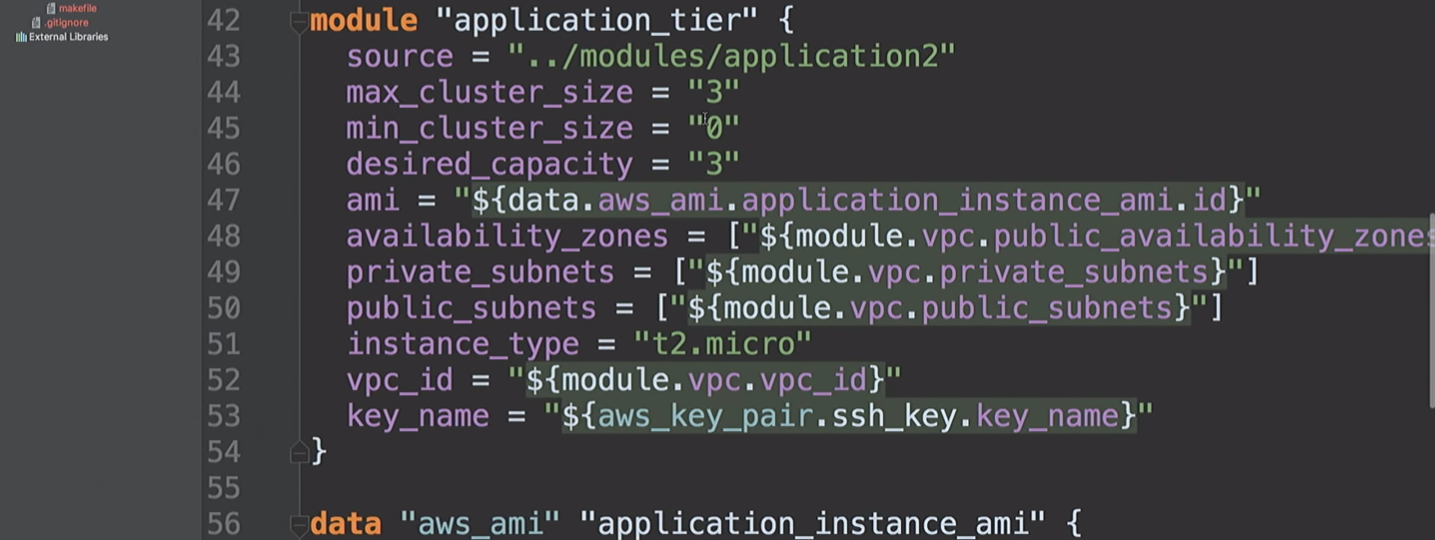


Luego creamos un
application_tier , que es un grupo de escalado automático, un equilibrador de carga. Parte de la configuración de inicio se basa en AMI-ID, y combina varias subredes y zonas de disponibilidad, y también utiliza una clave SSH.
Volvamos a esto en un segundo.
Ya mencioné las zonas de disponibilidad. Difieren para diferentes cuentas de AWS. Mi cuenta en los Estados Unidos en el Este puede tener acceso a las zonas A, B y D. Su cuenta de AWS puede tener acceso a B, C y E. Por lo tanto, al corregir estos valores en el código, encontraremos problemas. En Hashicorp sugerimos que podríamos crear tales fuentes de datos para poder preguntarle a Amazon qué estaba disponible para nosotros. Debajo del capó, solicitamos una descripción de las zonas de disponibilidad y luego devolvemos una lista de todas las zonas para su cuenta. Gracias a esto, podemos usar fuentes de datos para AMI.
Ahora llegamos al fondo de mi demostración. Creé un grupo de escalado automático en el que se ejecutan tres instancias. Por defecto, todos tienen la versión 1.0.0.
Cuando implementemos la nueva versión de AMI, volveré a iniciar la configuración de Terraform, esto cambiará la configuración de inicio y el nuevo servicio recibirá la próxima versión del código, etc. Y podemos controlarlo.

Vemos que Packer ha terminado y tenemos un nuevo AMI.
Regreso a Amazon, actualizo la página y veo un segundo AMI.

De vuelta a Terraform.
A partir de la versión 0.10, Terraform ha dividido a los proveedores en repositorios separados. Y el comando
init terraform obtiene una copia del proveedor que se necesita para ejecutarse.

Proveedores cargados. Estamos listos para seguir adelante.
Luego tenemos que ejecutar
terraform get - cargar los módulos necesarios. Ahora están en mi máquina local. Entonces Terraform obtendrá todos los módulos localmente. En general, los módulos se pueden almacenar en sus propios repositorios en GitHub o en otro lugar. Por eso hablé sobre el módulo VPC. Puede dar acceso al equipo de red para realizar cambios. Y esta es la API para que el equipo de desarrollo trabaje con ellos. Realmente útil
El siguiente paso es construir un gráfico.
Comience con
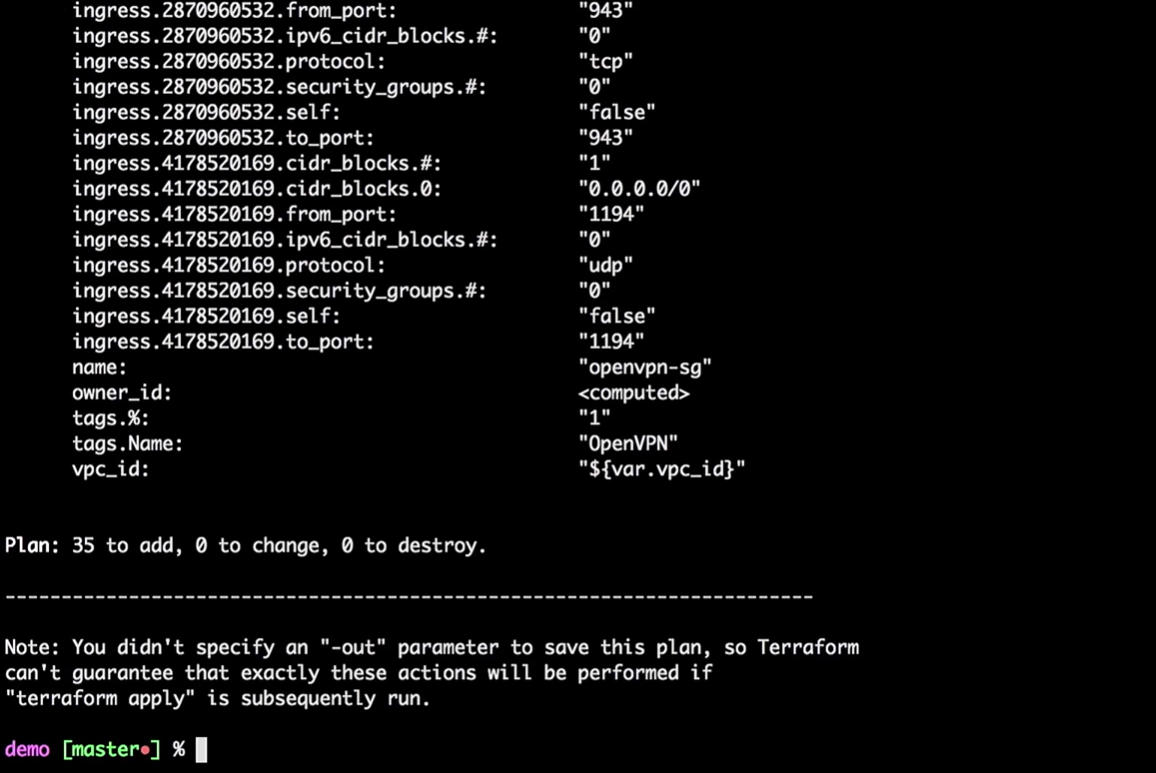
terraform plan

Terraform tomará el estado local actual y lo comparará con la cuenta de AWS, indicando las diferencias. En nuestro caso, creará 35 nuevos recursos.
Ahora aplicamos los cambios:
terraform apply
No tiene que hacer todo esto desde la máquina local. Estos son solo comandos, pasando variables a Terraform. Puede portar este proceso a las herramientas de CI.
Si desea mover esto a CI, debe usar el estado remoto. Me gustaría que todos los que usan Terraform trabajen con estado remoto. Por favor no use el estado local.
Uno de mis amigos señaló que incluso después de todos los años de trabajar con Terraform, todavía está descubriendo algo nuevo. Por ejemplo, si está creando una instancia de AWS, debe proporcionarle una contraseña y puede guardarla en su estado. Cuando trabajé en Hashicorp, asumimos que habría un proceso de colaboración que cambiaría esta contraseña. Por lo tanto, no intente almacenar todo localmente. Y luego puede poner todo esto en las herramientas de CI.
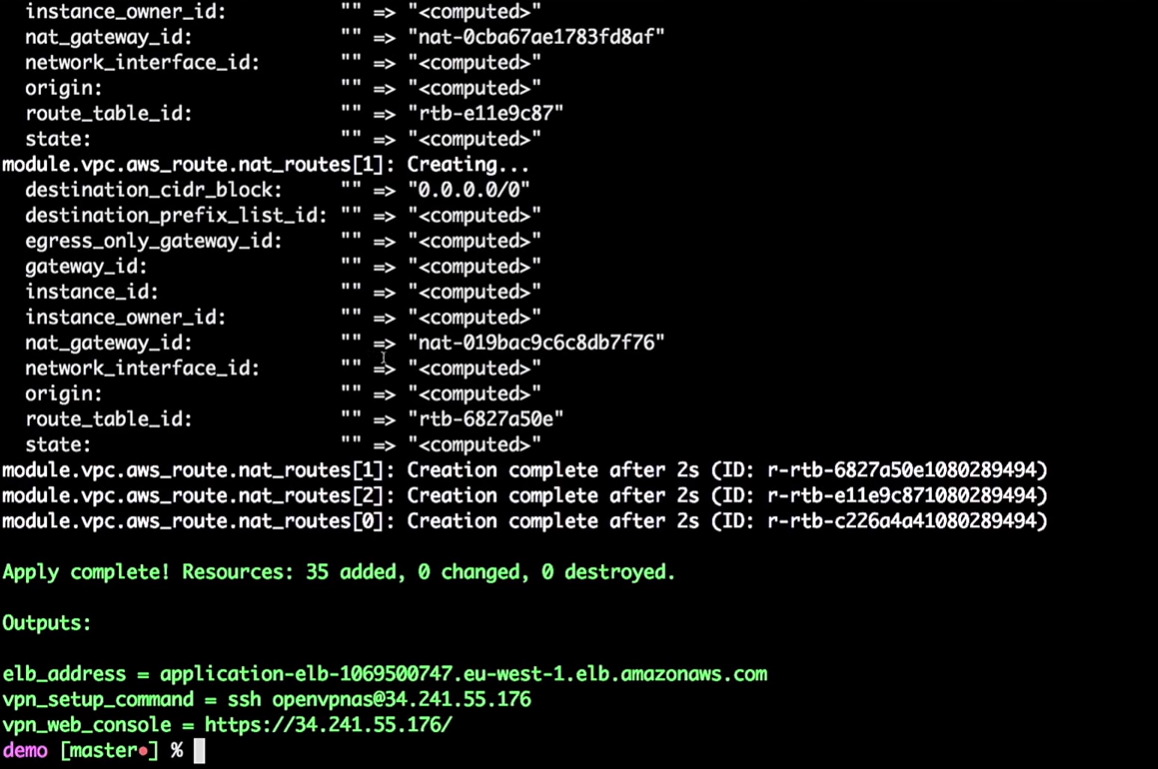
Entonces, la infraestructura está creada para mí.

Terraform puede construir un gráfico:
terraform graph
Como dije, él está construyendo un árbol. De hecho, le brinda la oportunidad de evaluar lo que sucede en su infraestructura. Él le mostrará la relación entre todas las diferentes partes, todos los nodos y bordes. Como las conexiones tienen direcciones, estamos hablando de un gráfico dirigido.
El gráfico será una lista JSON que se puede guardar en un archivo PNG o DOC.
De vuelta a Terraform. Realmente estamos creando un grupo de escalado automático.

El grupo de escalado automático tiene una capacidad de 3.

Una pregunta interesante: ¿podemos usar Vault para administrar secretos en Terraform? Por desgracia no. No hay una fuente de datos de Vault para leer secretos en Terraform. Hay otras formas, como las variables de entorno. Con su ayuda, no necesita ingresar secretos en el código; puede leerlos como variables de entorno.
Entonces, tenemos algunas instalaciones de infraestructura:
Entro en mi VPN muy secreta (no descifro mis VPN).
Lo más importante aquí es que tenemos tres instancias de la aplicación. Es cierto que debería haber notado qué versión de la aplicación se ejecuta en ellos. Esto es muy importante
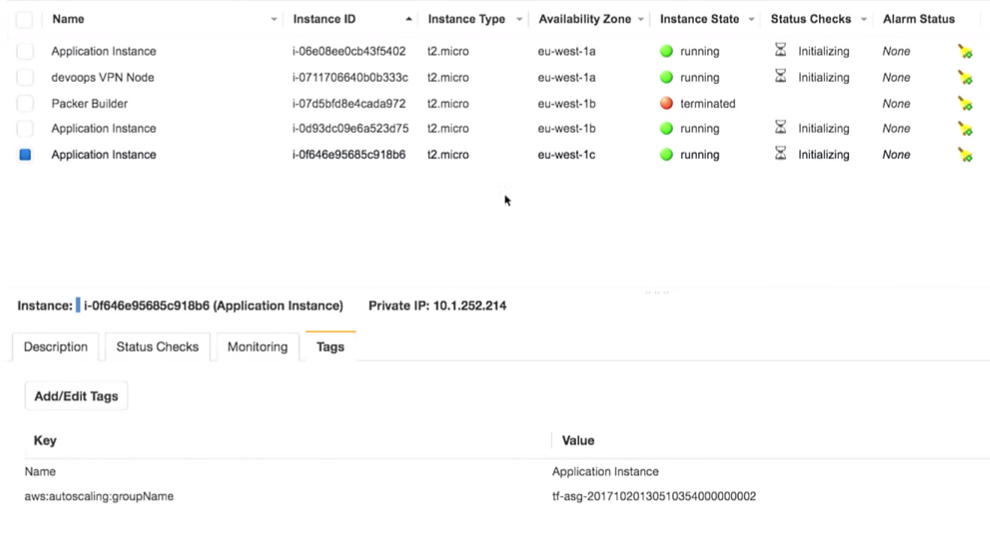
Todo realmente está detrás de la VPN:

Si tomo esto (
application-elb-1069500747.eu-west-1.elb.amazonaws.com ) y lo pego en la barra de direcciones del navegador, obtengo lo siguiente:

Déjame recordarte que estoy conectado a una VPN. Si me desconecto, la dirección especificada no estará disponible.
Vemos la versión 1.0.0. Y no importa cuánto refresquemos la página, obtenemos 1.0.0.
¿Qué sucede si cambio la versión de 1.0.0 a 1.0.1 en el código?
filter { name = "tag:Version" values = ["1.0.1"] }
Obviamente, las herramientas de CI asegurarán que cree la versión correcta.
¡Noto que no hay actualizaciones manuales! Somos imperfectos, cometemos errores y podemos poner la versión 1.0.6 en lugar de la 1.0.1 al actualizar manualmente.
filter { name = "tag:Version" values = ["1.0.6"] }
Pero pasemos a nuestra versión (1.0.1).
terraform plan
Estado de actualizaciones de Terraform:

Entonces, en este momento me dice que va a cambiar la versión en la configuración de lanzamiento. Debido al cambio en el identificador, forzará un reinicio de la configuración y el grupo de escalado automático cambiará (esto es necesario para habilitar la nueva configuración de inicio).
Esto no cambia las instancias en ejecución. Esto es realmente importante Puede seguir este proceso y probarlo sin cambiar las instancias en producción.
Nota: siempre debe crear una nueva configuración de inicio antes de destruir la anterior, de lo contrario habrá un error.
Apliquemos los cambios:
terraform apply
Ahora de vuelta a AWS. Cuando se aplican todos los cambios, vamos al grupo de escala automática.
Pasemos a la configuración de AWS. Vemos que hay tres instancias con una configuración de inicio. Son lo mismo.
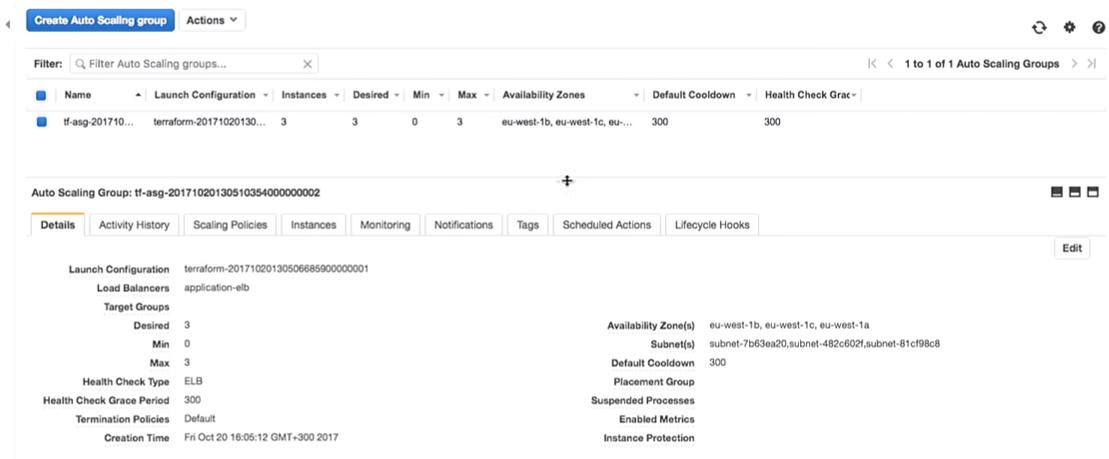
Amazon garantiza que si queremos ejecutar tres instancias del servicio, de hecho se lanzarán. Por eso les pagamos dinero.
Pasemos a los experimentos.
Se ha creado una nueva configuración de inicio. Por lo tanto, si elimino una de las instancias, el resto no se dañará. Esto es importante Sin embargo, si usa las instancias directamente, mientras cambia los datos del usuario, esto destruirá las instancias "en vivo". Por favor no hagas esto.
Entonces, elimine una de las instancias:

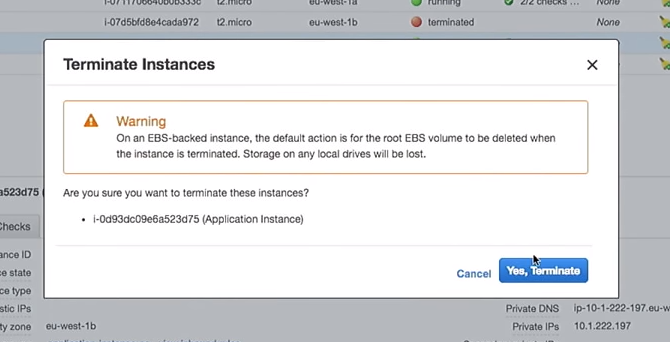
¿Qué sucederá en el grupo de escalado automático cuando se cierre? Una nueva instancia aparecerá en su lugar.
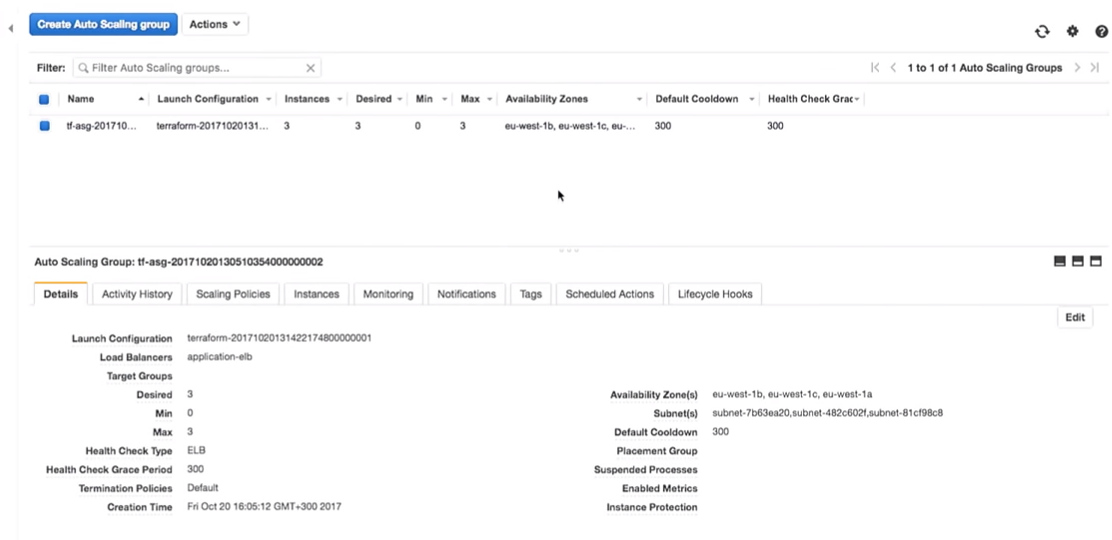
Aquí te encuentras en una situación interesante. La instancia se lanzará con la nueva configuración. Es decir, en el sistema puede tener varias imágenes diferentes (con diferentes configuraciones). A veces es mejor no eliminar inmediatamente la configuración de inicio anterior para conectarse según sea necesario.
Aquí todo se vuelve aún más interesante. ¿Por qué no hacerlo con scripts y herramientas de CI, y no manualmente, como lo muestro? Hay herramientas que pueden hacer esto, como las excelentes herramientas faltantes de AWS en GitHub.

¿Y qué hace esta herramienta? Este es un script bash que se ejecuta a través de todas las instancias en el equilibrador de carga, las destruye de una en una, asegurando la creación de nuevas en su lugar.
Si perdí una de mis instancias con la versión 1.0.0 y apareció una nueva, 1.1.1, me gustaría eliminar todas las 1.0.0, transfiriendo todo a la nueva versión. Porque siempre avanzo. Permítame recordarle que no me gusta cuando el servidor de aplicaciones vive durante mucho tiempo.
En uno de los proyectos, cada siete días, tenía un script de control que destruía todas las instancias de mi cuenta. Entonces el servidor no tenía más de siete días. Otra cosa (mi favorita) es marcar los servidores como "manchados" usando SSH en una caja y destruirlos cada hora usando un script; no queremos que la gente haga esto manualmente.
Dichos scripts de control le permiten tener siempre la última versión con errores corregidos y actualizaciones de seguridad.
Puede usar el script simplemente ejecutando:
aws-ha-relesae.sh -a my-scaling-group
-a es tu grupo de escalado automático. El script pasará por todas las instancias de su grupo de escalado automático y lo reemplazará. Puede ejecutarlo no solo manualmente, sino también desde la herramienta CI.
Puede hacer esto en QA o en producción. Puede hacerlo incluso en su cuenta local de AWS. Haces lo que quieras, cada vez usando el mismo mecanismo.
De vuelta a Amazon. Tenemos una nueva instancia:

Después de actualizar la página en el navegador, donde vimos previamente la versión 1.0.0, obtenemos:

Lo interesante es que desde que creamos el script de creación de AMI, podemos probar la creación de AMI.
Hay algunas herramientas excelentes, como ServerScript o Serverspec.
Serverspec le permite crear especificaciones de estilo Ruby para probar cómo se ve su servidor de aplicaciones. Por ejemplo, a continuación doy una prueba que verifica que nginx esté instalado en el servidor.
require 'spec_helper' describe package('nginx') do it { should be_installed } end describe service('nginx') do it { sould be_enabled } it { sould be_running } end describe port(80) do it { should be_listening } end
Nginx debe estar instalado y ejecutándose en el servidor y escuchando en el puerto 80. Puede decir que el usuario X debe estar disponible en el servidor. Y puede poner todas estas pruebas en su lugar. Por lo tanto, cuando crea una AMI, la herramienta CI puede verificar si esta AMI es adecuada para un propósito determinado. Sabrá que AMI está listo para la producción.
En lugar de una conclusión
Mary Poppendieck es probablemente una de las mujeres más increíbles de las que he oído hablar. En un momento, habló sobre cómo se ha desarrollado el desarrollo de software lean a lo largo de los años. Y cómo se asoció con 3M en los años 60, cuando la compañía realmente se dedicaba al desarrollo esbelto.
Y ella hizo la pregunta: ¿cuánto tiempo le tomará a su organización implementar los cambios asociados con una línea de código? ¿Puedes hacer que este proceso sea confiable y repetible?
Como regla general, esta pregunta siempre se refería al código de software. ¿Cuánto tiempo me llevará corregir un error en esta aplicación cuando se implementa en producción? Pero no hay ninguna razón por la que no podamos usar la misma pregunta para infraestructura o bases de datos.
Trabajé para una compañía llamada OpenTable. En él, llamamos a esto la duración del ciclo. Y en OpenTable tenía siete semanas. Y esto es relativamente bueno. Conozco empresas que tardan meses en enviar un código a producción. En OpenTable, revisamos el proceso durante cuatro años. Esto llevó mucho tiempo, porque la organización es grande: 200 personas. Y redujimos el tiempo del ciclo a tres minutos. Esto fue posible gracias a las mediciones del efecto de nuestras transformaciones.
Ahora todo está escrito. Tenemos tantas herramientas y ejemplos, hay GitHub. Por lo tanto, tome ideas de conferencias como DevOops, impleméntelas en su organización. No intentes implementar todo. Toma una cosa pequeña y véndela. Mostrar a alguien ¡El impacto de un pequeño cambio se puede medir, medir y seguir adelante!
Paul Stack llegará a San Petersburgo a la conferencia DevOops 2018 con un informe "Pruebas de sistemas sostenibles con el caos" . Paul hablará sobre la metodología Chaos Engineering y mostrará cómo usar esta metodología en proyectos reales.