No hace mucho tiempo, en el centro de datos en el que alquilamos servidores, ocurrió otro mini incidente. Como resultado, no hubo consecuencias graves para nuestro servicio; de acuerdo con las métricas disponibles, pudimos entender lo que estaba sucediendo literalmente en un minuto. Y luego imaginé cómo tendría que hacerme estallar el cerebro si solo faltaran 2 métricas simples. Debajo del corte, una historia corta en imágenes.
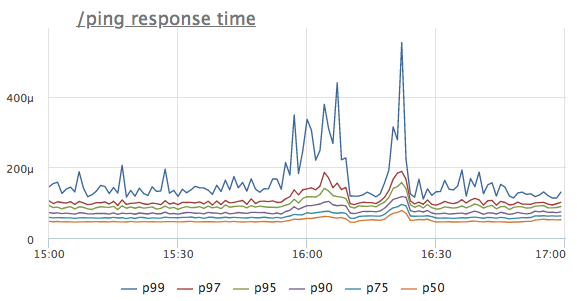
Imagine que vimos una anomalía en la línea de tiempo de respuesta de un determinado servicio. Para simplificar, tomamos el controlador / ping, que no accede ni a la base de datos ni a los servicios vecinos, sino que simplemente devuelve '200 OK' (es necesario para equilibradores de carga y k8s para el servicio de comprobación de estado)

¿Cuál es el primer pensamiento? Así es, el servicio no tiene suficientes recursos, ¡muy probablemente la CPU! Nos fijamos en el consumo del procesador:
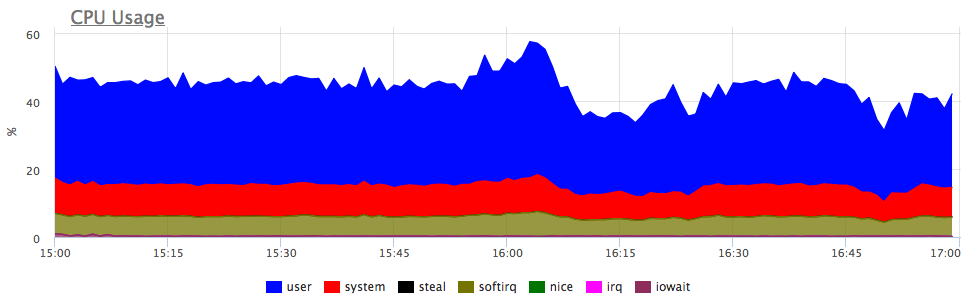
Sí, hay explosiones similares. A continuación, analizamos el consumo por servicios en el servidor:
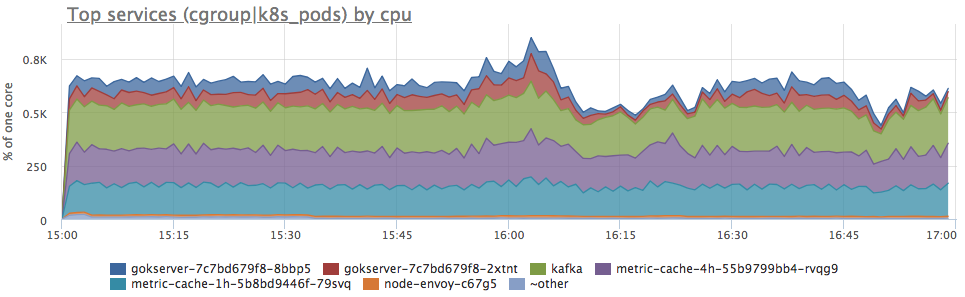
Vemos que el consumo de proca ha aumentado proporcionalmente para todos los servicios. No puede decir nada más explícitamente: puede ir y ver si el perfil de carga ha cambiado (ya que todos los componentes están conectados y un aumento en las solicitudes de entrada puede causar un aumento proporcional en el consumo de recursos) o comprender qué ha sido de los recursos del servidor.
Por supuesto, traté de preservar la intriga lo mejor que pude, pero al comienzo del artículo, probablemente ya adivinó que el servidor simplemente redujo la cantidad de tics de CPU disponibles. En dmesg, se parece a esto:
CPU3: Core temperature above threshold, cpu clock throttled (total events = 88981)
En términos generales, hemos reducido la frecuencia debido al sobrecalentamiento del procesador. Nos fijamos en la temperatura:
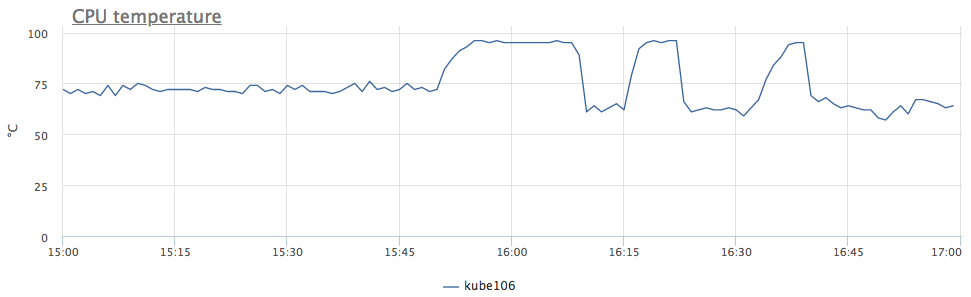
ahora todo está claro. Como tuvimos un comportamiento similar de inmediato en 6 servidores, nos dimos cuenta de que el problema está en DC, y no en todo, sino solo en ciertas filas de racks.
Pero volvamos a las métricas. Potencialmente queremos saber si los servidores se sobrecalentarán en el futuro, pero esta no es una razón para agregar un gráfico de temperaturas del procesador a todos los paneles y verificar esto cada vez.
Por lo general, los desencadenantes se utilizan para rastrear algunas métricas para optimizar el proceso. Pero, ¿qué umbral debo elegir para un disparador por temperatura del procesador?
Debido a la dificultad de elegir un buen umbral para el disparador, muchos ingenieros sueñan con un detector de anomalías, que sin configuraciones se encontrará, no sé qué :)El primer pensamiento es establecer el umbral de temperatura a la cual nuestro servicio comenzó a tener problemas. ¿Y si nunca has tenido un sobrecalentamiento? Por supuesto, puedes mirar mi horario y decidir por ti mismo que 95 ° C es lo que necesitas, pero pensemos un poco más.
¡El problema con nosotros no es por los grados, sino porque la frecuencia ha disminuido! Hagamos un seguimiento del número de tales eventos.
En Linux, esto se puede eliminar de sysfs:
/sys/devices/system/cpu/cpu*/thermal_throttle/package_throttle_count

Para ser sincero, ni siquiera mostramos esta métrica en ningún lado, solo tenemos un disparador automático para todos los clientes que se dispara cuando se alcanza el umbral "> 10 eventos / segundo". Según nuestras estadísticas, prácticamente no hay falsos positivos en este umbral.
Sí, este disparador rara vez funciona, pero cuando esto sucede, ¡hace la vida muy fácil!
En okmeter.io, la mayor parte del tiempo, nos dedicamos al desarrollo de nuestra base de datos de activadores automáticos, lo que facilita a nuestros clientes encontrar problemas desconocidos para ellos.