Hola a todos!
Hoy hablaremos sobre la experiencia de uno de nuestros proyectos DevOps. Decidimos implementar una nueva aplicación para Linux usando .Net Core en una arquitectura de microservicio.
Esperamos que el proyecto se desarrolle activamente y que haya cada vez más usuarios. Por lo tanto, debe ser fácilmente escalable tanto en términos de funcionalidad como de rendimiento.
Necesitamos un sistema tolerante a fallas: si uno de los bloques de funcionalidad no funciona, el resto debería funcionar. También queremos asegurar una integración continua, incluida la implementación de la solución en los servidores del cliente.
Por lo tanto, utilizamos las siguientes tecnologías:
- .Net Core para la implementación de microservicios. Nuestro proyecto usó la versión 2.0,
- Kubernetes para orquestación de microservicios,
- Docker para crear imágenes de microservicio,
- bus de integración Rabbit MQ y Mass Transit,
- Elasticsearch y Kibana para iniciar sesión,
- TFS para implementar la canalización de CI / CD.
Este artículo compartirá los detalles de nuestra solución.

Esta es una transcripción de nuestro discurso en la reunión de .NET, aquí hay un
enlace al video del discurso.
Nuestro desafío comercial
Nuestro cliente es una empresa federal en la que hay comerciantes; estas son personas responsables de cómo se presentan los productos en las tiendas. Y hay supervisores: estos son los líderes de los comerciantes.
La compañía tiene un proceso de capacitación y evaluación del trabajo de los comerciantes por parte de los supervisores, que necesitaba ser automatizado.
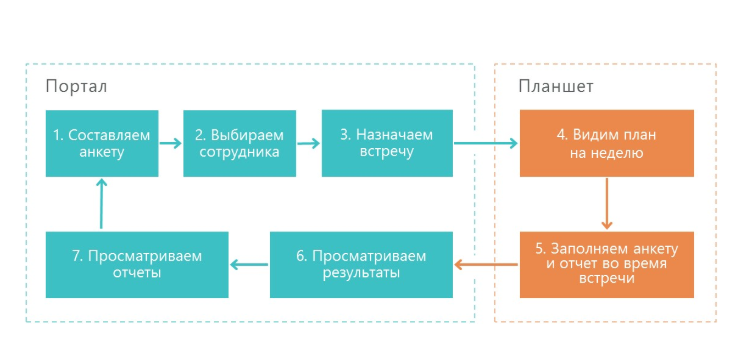
Así es como funciona nuestra solución:
1. El supervisor elabora un cuestionario: esta es una lista de verificación de lo que debe verificar en el trabajo del comerciante.
2. Luego, el supervisor selecciona al empleado cuyo trabajo será verificado. Se asigna la fecha de interrogatorio.
3. Luego, la actividad se envía al dispositivo móvil del supervisor.
4. Luego se completa el cuestionario y se envía al portal.
5. El portal genera resultados y varios informes.
Los microservicios nos ayudarán a resolver tres problemas:
1. En el futuro, queremos expandir fácilmente la funcionalidad, ya que hay muchos procesos comerciales similares en la empresa.
2. Queremos que la solución sea tolerante a fallas. Si alguna parte deja de funcionar, la solución podrá restaurar su trabajo por sí sola, y el fallo de una parte no afectará en gran medida el funcionamiento de la solución en su conjunto.
3. La empresa para la que estamos implementando la solución tiene muchas sucursales. En consecuencia, el número de usuarios de la solución está en constante crecimiento. Por lo tanto, quería que esto no afectara el rendimiento.
Como resultado, decidimos usar microservicios en este proyecto, que requería una serie de decisiones no triviales.
Qué tecnologías ayudaron a implementar esta solución:
• Docker simplifica la distribución de la distribución de la solución. La distribución en nuestro caso es un conjunto de imágenes de microservicio.
• Como hay muchos microservicios en nuestra solución, necesitamos administrarlos. Para esto usamos Kubernetes.
• Implementamos microservicios usando .Net Core.
• Para actualizar rápidamente la solución en el cliente, debemos implementar una integración y entrega continua conveniente.
Aquí está todo nuestro conjunto de tecnologías:
• .Net Core que utilizamos para crear microservicios,
• Microservice está empaquetado en una imagen Docker,
• La integración continua y la entrega continua se implementan utilizando TFS,
• El front end se implementa en angular,
• Para monitorear y registrar utilizamos Elasticsearch y Kibana,
• RabbitMQ y Mass Transit se utilizan como bus de integración.
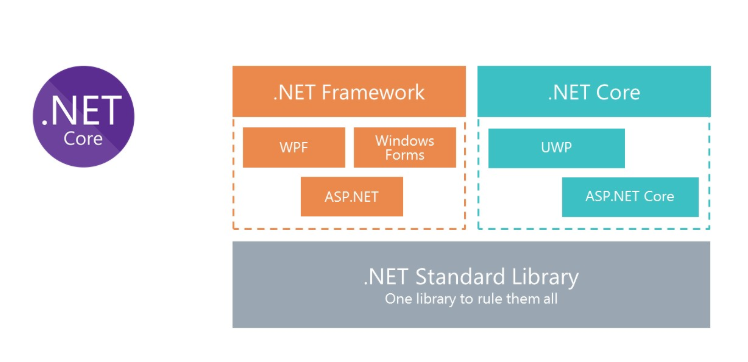
Soluciones .NET Core para Linux
Todos sabemos cuál es el clásico .Net Framework. La principal desventaja de la plataforma es que no es multiplataforma. En consecuencia, no podemos ejecutar soluciones en .Net Framework para Linux en Docker.
Para proporcionar la capacidad de usar C # en Docker, Microsoft repensó .Net Framework y creó .Net Core. Y para usar las mismas bibliotecas, Microsoft creó la especificación .Net Standard Library. Los ensamblados de .Net Standart Library se pueden usar tanto en .Net Framework como .Net Core.
Kubernetes - para orquestación de microservicios
Kubernetes se usa para administrar y agrupar contenedores Docker. Estas son las principales ventajas de Kubernetes que hemos aprovechado:
- proporciona la capacidad de configurar fácilmente el entorno de microservicios,
- simplifica la gestión ambiental (Dev, QA, Stage),
- Fuera de la caja proporciona la capacidad de replicar microservicios y equilibrio de carga en réplicas.
Arquitectura de soluciones
Al comienzo del trabajo, nos preguntamos cómo dividir la funcionalidad en microservicios. La división se realizó sobre el principio de una responsabilidad única, solo a un nivel mayor. Su tarea principal es hacer que los cambios en un servicio afecten lo menos posible a otros microservicios. Como resultado, en nuestro caso, los microservicios comenzaron a realizar un área separada de funcionalidad.
Como resultado, hemos aparecido servicios dedicados a la planificación de cuestionarios, un microservicio para mostrar resultados, un microservicio para trabajar con una aplicación móvil y otros microservicios.
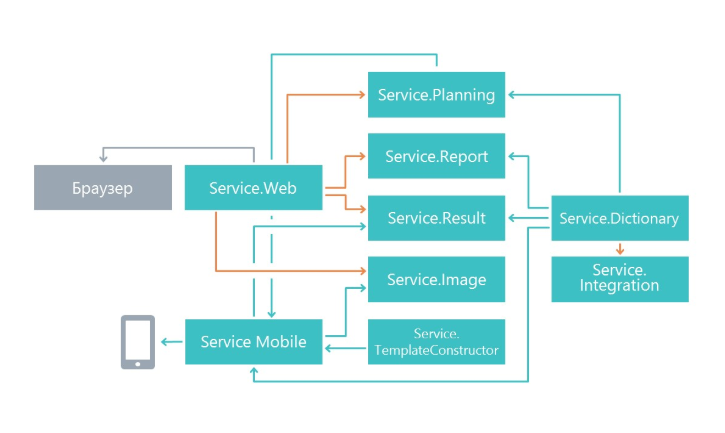
Opciones para interactuar con clientes externos.
Microsoft en su libro sobre microservicios, "
.NET Microservices. .NET Container Application Architecture ”ofrece tres implementaciones posibles de interacción con microservicios. Revisamos los tres y elegimos el más adecuado.
• Servicio API Gateway
La API de servicio de Gateway es una implementación de fachada para solicitudes de usuarios de otros servicios. El problema con la solución es que si la fachada no funciona, entonces toda la solución dejará de funcionar. Decidieron abandonar este enfoque por tolerancia a fallas.
• API Gateway con Azure API Management
Microsoft proporciona la capacidad de usar una fachada de nube en Azure. Pero esta solución no encajaba, porque íbamos a implementar la solución no en la nube, sino en los servidores del cliente.
• Comunicación directa de cliente a microservicio
Como resultado, nos queda la última opción: interacción directa del usuario con microservicios. Lo elegimos a el.
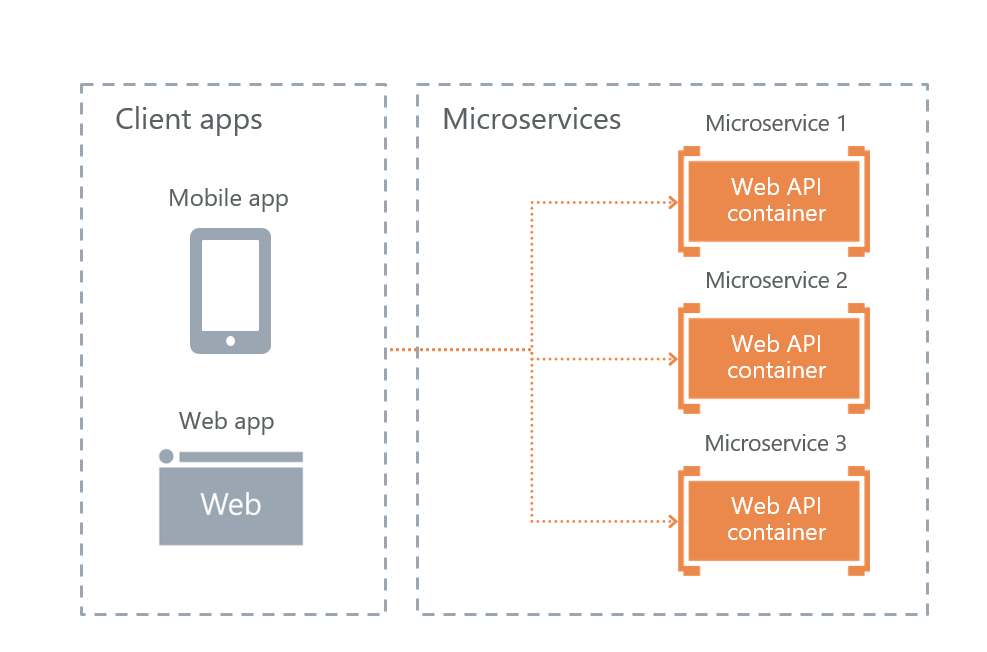
Es más en tolerancia a fallas. La desventaja es que parte de la funcionalidad deberá reproducirse en cada servicio por separado. Por ejemplo, era necesario configurar la autorización por separado en cada microservicio al que los usuarios tienen acceso.
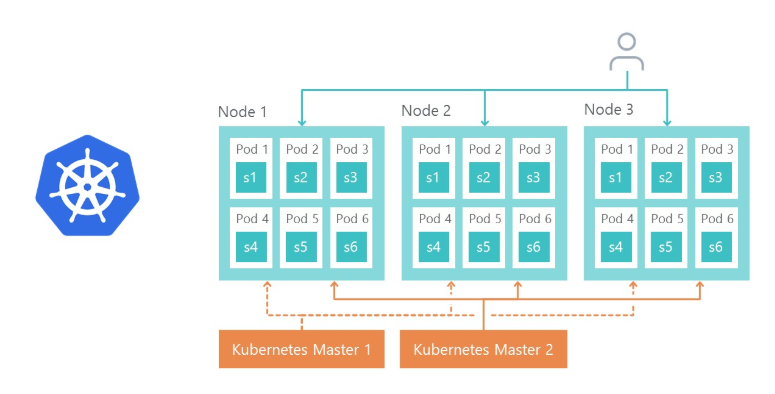
Por supuesto, surge la pregunta de cómo equilibraremos la carga y cómo se implementará la tolerancia a fallas. Aquí todo es simple: el Controlador de Ingreso Kubernetes hace esto.

El nodo 1, el nodo 2 y el nodo 3 son réplicas del mismo microservicio. Si falla una de las réplicas, el equilibrador de carga redirigirá automáticamente la carga a otros microservicios.
Arquitectura física
Así es como organizamos nuestra infraestructura de soluciones:
• Cada microservicio tiene su propia base de datos (si él, por supuesto, la necesita), otros servicios no acceden a la base de datos de otro microservicio.
• Los microservicios se comunican entre sí solo a través del bus RabbitMQ + Mass Transit, así como a través de solicitudes HTTP.
• Cada servicio tiene su propia responsabilidad claramente definida.
• Para iniciar sesión utilizamos Elasticsearch y Kibana y la biblioteca para trabajar con
Serilog .
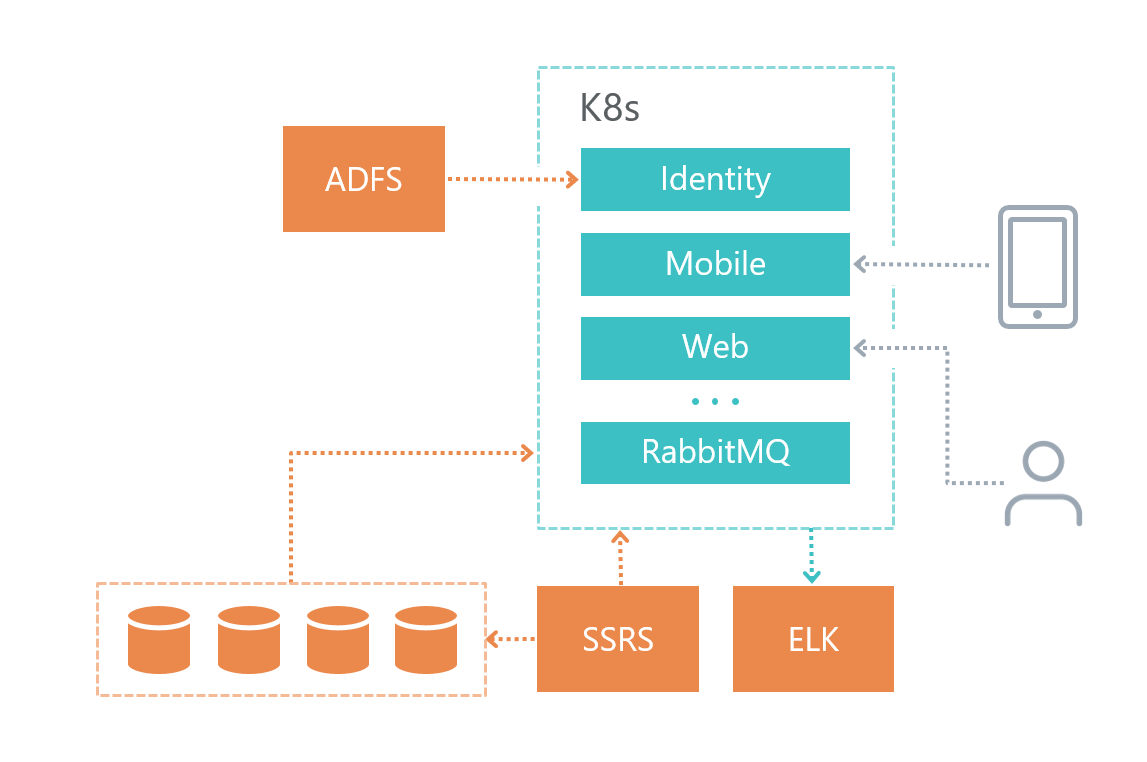
El servicio de base de datos se implementó en una máquina virtual separada, y no en Kubernetes, porque Microsoft DBMS no recomienda usar Docker en entornos de productos.
El servicio de registro también se implementó en una máquina virtual separada por razones de tolerancia a fallas: si tenemos problemas con Kubernetes, entonces podemos descubrir cuál es el problema.
Implementación: cómo organizamos los entornos de desarrollo y producto
Nuestra infraestructura tiene 3 espacios de nombres en Kubernetes. Los tres entornos acceden a un servicio de base de datos y un servicio de registro. Y, por supuesto, cada entorno mira su propia base de datos.
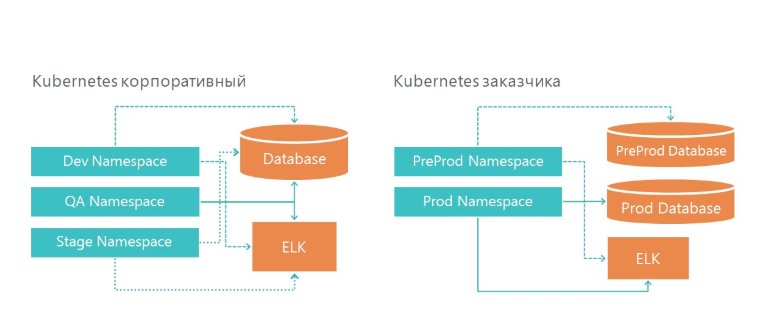
En la infraestructura del cliente, también tenemos dos entornos: preproducción y producción. En producción, tenemos servidores de bases de datos separados para la preventa y el entorno del producto. Para el registro, hemos asignado un servidor ELK en nuestra infraestructura y en la infraestructura del cliente.
¿Cómo implementar 5 entornos con 10 microservicios cada uno?
En promedio, tenemos 10 servicios por proyecto y tres entornos: QA, DEV, Stage, en el que se implementan aproximadamente 30 microservicios en total. ¡Y esto es solo en la infraestructura de desarrollo! Agregue 2 entornos más en la infraestructura del cliente y obtenemos 50 microservicios.
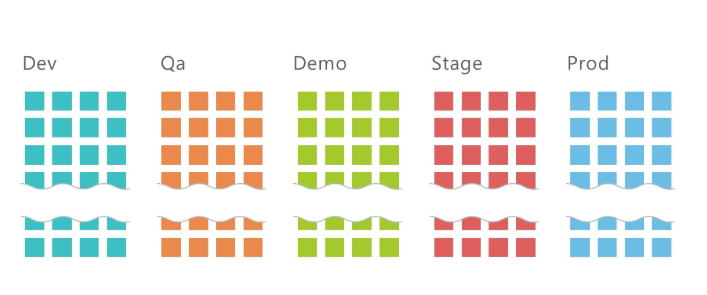
Está claro que tal cantidad de servicios debe de alguna manera ser administrada. Kubernetes nos ayuda con esto.
Para implementar un microservicio, debe
• Expandir secreto,
• Implementar despliegue,
• Ampliar el servicio.
Sobre secreto escribe abajo.
La implementación es una instrucción para Kubernetes, sobre la base de la cual lanzará el contenedor Docker de nuestro microservicio. Aquí está el comando para el que se implementa la implementación:
kubectl apply -f .\(yaml deployment-) --namespace=DEV apiVersion: apps/v1beta1 kind: Deployment metadata: name: imtob-etr-it-dictionary-api spec: replicas: 1 template: metadata: labels: name: imtob-etr-it-dictionary-api spec: containers: - name: imtob-etr-it-dictionary-api image: nexus3.company.ru:18085/etr-it-dictionary-api:18289 resources: requests: memory: "256Mi" limits: memory: "512Mi" volumeMounts: - name: secrets mountPath: /app/secrets readOnly: true volumes: - name: secrets secret: secretName: secret-appsettings-dictionary
Este archivo describe cómo se llama la implementación (imtob-etr-it-dictionary-api), qué imagen necesita usar para la ejecución, además de otras configuraciones. En la sección secreta, personalizaremos nuestro entorno.
Después de implementar la implementación, debemos implementar el servicio, si es necesario.
Los servicios son necesarios cuando se necesita acceso al microservicio desde el exterior. Por ejemplo, cuando desea que un usuario u otro microservicio pueda realizar una solicitud Get a otro microservicio.
kubectl apply -f .\imtob-etr-it-dictionary-api.yml --namespace=DEV apiVersion: v1 kind: Service metadata: name: imtob-etr-it-dictionary-api-services spec: ports: - name: http port: 80 targetPort: 80 protocol: TCP selector: name: imtob-etr-it-dictionary-api
Por lo general, la descripción del servicio es pequeña. En él vemos el nombre del servicio, cómo se puede acceder y el número de puerto.
Como resultado, para implementar el entorno, necesitamos
• un conjunto de archivos con secretos para todos los microservicios,
• un conjunto de archivos con la implementación de todos los microservicios,
• un conjunto de archivos con los servicios de todos los microservicios.
Almacenamos todos estos scripts en el repositorio de git.
Para implementar la solución, obtuvimos un conjunto de tres tipos de scripts:
• carpeta con secretos: estas son configuraciones para cada entorno,
• carpeta con despliegue para todos los microservicios,
• carpeta con servicios para algunos microservicios,
en cada uno: aproximadamente diez equipos, uno para cada microservicio. Para mayor comodidad, hemos creado una página con scripts en Confluence, que nos ayuda a implementar rápidamente un nuevo entorno.
Aquí hay un script de implementación de implementación (hay conjuntos similares para secreto y para servicio):
Script de implementaciónkubectl apply -f. \ imtob-etr-it-image-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-mobile-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-planning-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-result-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-web.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-report-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-template-constructor-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-dictionary-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it -integration-api.yml --namespace = DEV
kubectl apply -f. \ imtob-etr-it-identity-api.yml --namespace = DEV
Implementación de CI / CD
Cada servicio está en su propia carpeta, además tenemos una carpeta con componentes comunes.
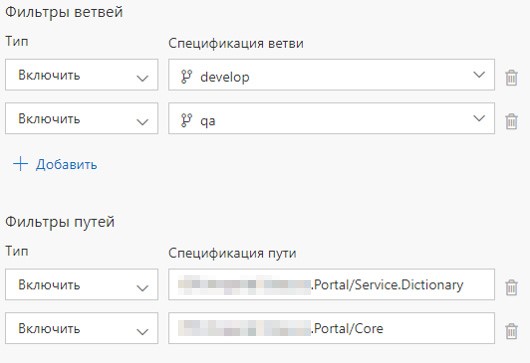
También hay una definición de compilación y una definición de lanzamiento para cada microservicio. Configuramos el lanzamiento de Build Definion cuando nos comprometemos con el servicio apropiado o cuando nos comprometemos con la carpeta correspondiente. Si se actualizan los contenidos de la carpeta con componentes comunes, se implementan todos los microservicios.
¿Cuáles son las ventajas de tal organización Build?
1. La solución está en un repositorio de git,
2. Al cambiar en varios microservicios, el ensamblaje comienza en paralelo con los agentes de ensamblaje libres,
3. Cada definición de compilación presenta una secuencia de comandos simple desde la compilación de la imagen y empujándola al registro Nexus.
Definición de compilación y definición de lanzamiento
Cómo implementar un agente VSTS, lo describimos anteriormente
en este artículo .
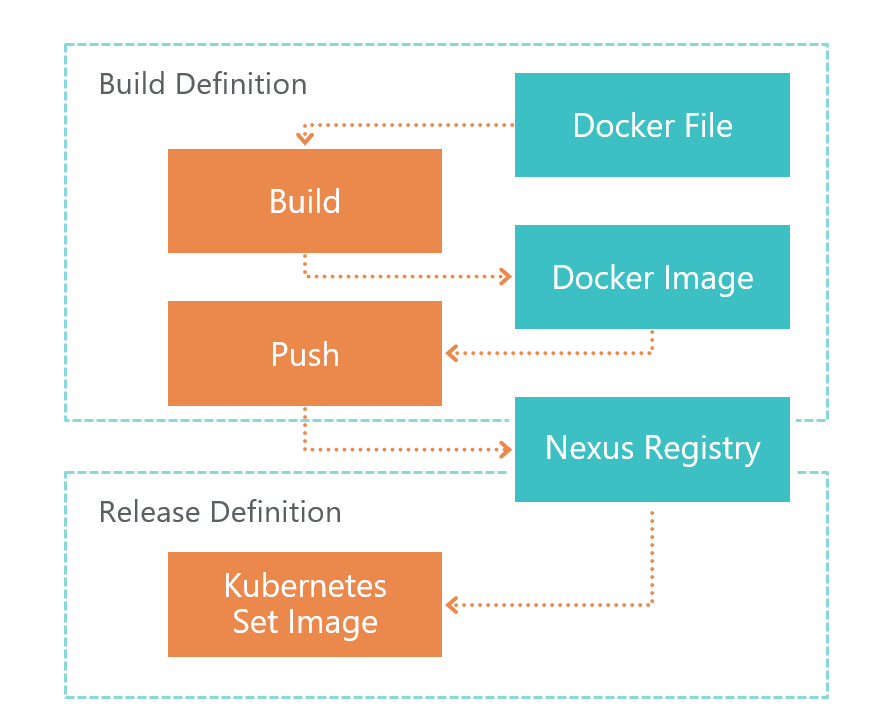
Primero viene la definición de construcción. En el comando TFS VSTS, el agente inicia la compilación Dockerfile. Como resultado, obtenemos la imagen de un microservicio. Esta imagen se guarda localmente en el entorno donde se ejecuta el agente VSTS.
Después de la compilación, se inicia Push, que envía la imagen que recibimos en el paso anterior al Registro Nexus. Ahora se puede usar externamente. Nexus Registry es un tipo de Nuget, no solo para bibliotecas, sino también para imágenes de Docker y más.
Una vez que la imagen esté lista y sea accesible desde el exterior, debe implementarla. Para esto tenemos Release Release. Aquí todo es simple: ejecutamos el comando set image:
kubectl set image deployment/imtob-etr-it-dictionary-api imtob-etr-it-dictionary-api=nexus3.company.ru:18085/etr-it-dictionary-api:$(Build.BuildId)Después de eso, actualizará la imagen para el microservicio deseado y lanzará un nuevo contenedor. Como resultado, nuestro servicio ha sido actualizado.
Ahora comparemos la compilación con y sin Dockerfile.
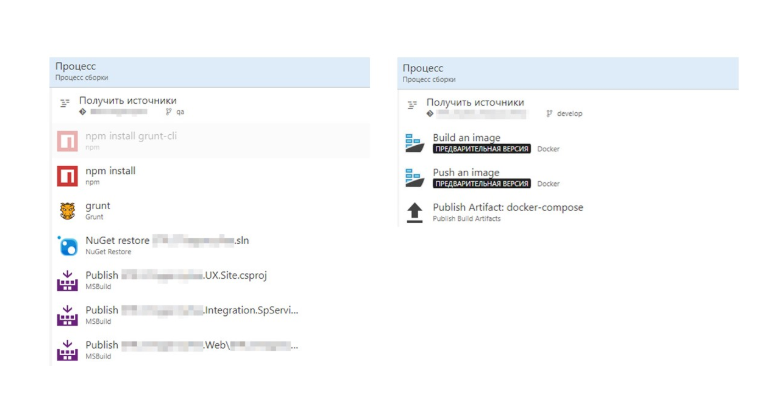
Sin el Dockerfile, obtenemos muchos pasos, que tienen muchos detalles .Net. A la derecha vemos una construcción de imagen Docker. Todo se ha vuelto mucho más fácil.
Todo el proceso de construcción de la imagen se describe en el Dockerfile. Este ensamblaje se puede depurar localmente.

Total: obtuvimos un CI / CD simple y transparente
1. Separación de desarrollo y despliegue. El ensamblaje se describe en Dockerfile y se encuentra en los hombros del desarrollador.
2. Al configurar CI / CD, no necesita conocer los detalles y las características del ensamblaje; el trabajo se realiza solo con el Dockerfile.
3. Actualizamos solo los microservicios modificados.
A continuación, debe configurar RabbitMQ en el K8S: escribimos un
artículo separado sobre esto.
Entorno
De una forma u otra, necesitamos configurar microservicios. La parte principal del entorno se configura en el archivo de configuración raíz Appsettings.json. Este archivo contiene configuraciones que son independientes del entorno.
Esas configuraciones que dependen del entorno se almacenan en la carpeta de secretos en el archivo appsettings.secret.json. Tomamos el enfoque descrito en el artículo
Administración de la configuración de la aplicación ASP.NET Core en Kubernetes .
var configuration = new ConfigurationBuilder() .AddJsonFile($"appsettings.json", true) .AddJsonFile("secrets/appsettings.secrets.json", optional: true) .Build();
El archivo appsettings.secrets.json contiene la configuración de los índices de Elastic Search y la cadena de conexión de la base de datos.
{ "Serilog": { "WriteTo": [ { "Name": "Elasticsearch", "Args": { "nodeUris": "http://192.168.150.114:9200", "indexFormat": "dev.etr.it.ifield.api.dictionary-{0:yyyy.MM.dd}", "templateName": "dev.etr.it.ifield.api.dictionary", "typeName": "dev.etr.it.ifield.api.dictionary.event" } } ] }, "ConnectionStrings": { "DictionaryDbContext": "Server=192.168.154.162;Database=DEV.ETR.IT.iField.Dictionary;User Id=it_user;Password=PASSWORD;" } }
Agregar archivo de configuración a Kubernetes
Para agregar este archivo, debe implementarlo en el contenedor Docker. Esto se hace en el archivo de implementación de Kubernetis. La implementación describe en qué carpeta se debe crear el archivo secreto c y con qué secreto es necesario asociar el archivo.
apiVersion: apps/v1beta1 kind: Deployment metadata: name: imtob-etr-it-dictionary-api spec: replicas: 1 template: metadata: labels: name: imtob-etr-it-dictionary-api spec: containers: - name: imtob-etr-it-dictionary-api image: nexus3.company.ru:18085/etr-it-dictionary-api:18289 resources: requests: memory: "256Mi" limits: memory: "512Mi" volumeMounts: - name: secrets mountPath: /app/secrets readOnly: true volumes: - name: secrets secret: secretName: secret-appsettings-dictionary
Puede crear un secreto en Kubernetes utilizando la utilidad kubectl. Vemos aquí el nombre del secreto y la ruta al archivo. También indicamos el nombre del entorno para el que creamos un secreto.
kubectl create secret generic secret-appsettings-dictionary
--from-file=./Dictionary/appsettings.secrets.json --namespace=DEMOConclusiones
Contras del enfoque elegido
1. Umbral de entrada alto. Si está haciendo un proyecto de este tipo por primera vez, habrá mucha información nueva.
2. Microservicios → diseño más complejo. Es necesario aplicar muchas soluciones no obvias debido al hecho de que no tenemos una solución monolítica, sino una de microservicio.
3. No todo está implementado para Docker. No todo se puede ejecutar en la arquitectura de microservicios. Por ejemplo, mientras SSRS no está en la ventana acoplable.
Ventajas de un enfoque autoevaluado
1. Infraestructura como código
La descripción de la infraestructura se almacena en el control de origen. En el momento de la implementación, no necesita adaptar el entorno.
2. Escalado tanto a nivel de funcionalidad como a nivel de rendimiento fuera de la caja.
3. Los microservicios están bien aislados
Prácticamente no hay partes críticas, cuyo fallo conduce a la inoperancia del sistema en su conjunto.
4. Entrega rápida de cambios
Solo se actualizan los microservicios en los que ha habido actualizaciones. Si no tiene en cuenta el tiempo de coordinación y otras cosas relacionadas con el factor humano, la actualización de un microservicio se realiza en 2 minutos o menos.
Conclusiones para nosotros
1. En .NET Core, puede y debe implementar soluciones industriales.
2. K8S realmente facilitó la vida, simplificó la actualización de entornos, facilita la configuración de servicios.
3. TFS se puede usar para implementar CI / CD para Linux.