Hola colegas
Esperamos comenzar la traducción de un
libro pequeño pero realmente
básico sobre la implementación de las capacidades de IA en Python antes de finales de agosto.

Mr. Gift, tal vez, no necesita publicidad adicional (para los curiosos, el
perfil del maestro en GitHub):

El artículo que se ofrece hoy hablará brevemente sobre la biblioteca Ray, desarrollada en la Universidad de California (Berkeley) y mencionada en el libro de Peter por petite. Esperamos que, como adelanto temprano, lo que necesites. Bienvenido bajo gato
Con el desarrollo de algoritmos y técnicas de aprendizaje automático, cada vez más aplicaciones de aprendizaje automático deben ejecutarse en muchas máquinas a la vez, y no pueden prescindir de la concurrencia. Sin embargo, la infraestructura para realizar el aprendizaje automático en clústeres todavía se forma situacionalmente. Ahora ya existen buenas soluciones (por ejemplo, servidores de parámetros o búsqueda de hiperparámetros) y sistemas distribuidos de alta calidad (por ejemplo, Spark o Hadoop), creados originalmente no para trabajar con IA, pero los profesionales a menudo crean la infraestructura para sus propios sistemas distribuidos desde cero. Se gasta mucho esfuerzo extra en esto.
Como ejemplo, considere un algoritmo conceptualmente simple, por ejemplo,
Estrategias evolutivas para el aprendizaje por refuerzo . En el pseudocódigo, este algoritmo se ajusta a una docena de líneas, y su implementación en Python es ligeramente mayor. Sin embargo, el uso efectivo de este algoritmo en una máquina o clúster más grande requiere una ingeniería de software significativamente más sofisticada. En la implementación de este algoritmo de los autores de este artículo, hay miles de líneas de código, aquí es necesario determinar protocolos de comunicación, estrategias de serialización y deserialización de mensajes, así como varios métodos de procesamiento de datos.
Uno de
los objetivos de
Ray es ayudar a un profesional a convertir un algoritmo prototipo que se ejecuta en una computadora portátil en una aplicación distribuida de alto rendimiento que funciona de manera eficiente en un clúster (o en una sola máquina multinúcleo) agregando relativamente pocas líneas de código. En términos de rendimiento, dicho marco debería tener todas las ventajas de un sistema optimizado manualmente y no requerir que el usuario piense en la programación, la transferencia de datos y los bloqueos de la máquina.
Marco AI gratuitoEnlace con otros marcos de aprendizaje profundo : Ray es totalmente compatible con marcos de aprendizaje profundo como TensorFlow, PyTorch y MXNet, por lo que en muchas aplicaciones es completamente natural usar uno o más marcos de aprendizaje profundo con Ray (por ejemplo, en nuestras bibliotecas de aprendizaje reforzado activamente aplicar TensorFlow y PyTorch).
Comunicación con otros sistemas distribuidos : hoy en día, se utilizan muchos sistemas distribuidos populares, sin embargo, la mayoría de ellos fueron diseñados sin tener en cuenta las tareas asociadas con la IA, por lo tanto, no tienen el rendimiento requerido para soportar la IA y no tienen una API para expresar los aspectos aplicados de la IA. En los sistemas distribuidos modernos no hay (necesarias, dependiendo del sistema) tales características necesarias:
- Soporte de tareas de nivel de milisegundos y soporte para millones de tareas por segundo
- Paralelismo anidado (paralelización de tareas dentro de tareas, por ejemplo, simulaciones paralelas al buscar hiperparámetros) (consulte la siguiente figura)
- Dependencias arbitrarias entre tareas, dinámicamente durante la ejecución (por ejemplo, para no tener que esperar, ajustándose al ritmo de los trabajadores lentos)
- Tareas que operan en un estado variable compartido (por ejemplo, pesos en redes neuronales o un simulador)
- Soporte para recursos heterogéneos (CPU, GPU, etc.)
 Un ejemplo simple de concurrencia anidada. En nuestra aplicación, se realizan dos experimentos en paralelo (cada uno de ellos es una tarea a largo plazo), y en cada experimento se simulan varios procesos paralelos (cada proceso también es una tarea).
Un ejemplo simple de concurrencia anidada. En nuestra aplicación, se realizan dos experimentos en paralelo (cada uno de ellos es una tarea a largo plazo), y en cada experimento se simulan varios procesos paralelos (cada proceso también es una tarea).Hay dos formas principales de usar Ray: a través de sus API de bajo nivel y a través de bibliotecas de alto nivel. Las bibliotecas de alto nivel se crean sobre API de bajo nivel. Actualmente, incluyen
Ray RLlib (una biblioteca escalable para aprendizaje de refuerzo) y
Ray.tune , una biblioteca eficiente para búsqueda distribuida de hiperparámetros.
Ray API de bajo nivelEl propósito de Ray API es proporcionar una expresión natural de los patrones y aplicaciones computacionales más comunes, sin limitarse a patrones fijos como MapReduce.
Gráficos dinámicos de tareasLa primitiva básica en la aplicación (tarea) Ray es un gráfico dinámico de tareas. Es muy diferente del gráfico computacional en TensorFlow. Mientras que en TensorFlow un gráfico computacional representa una red neuronal y se ejecuta muchas veces en cada aplicación separada, en Ray el gráfico de tareas corresponde a la aplicación completa y se ejecuta solo una vez. El gráfico de tareas no se conoce de antemano. Se crea dinámicamente mientras la aplicación se está ejecutando, y la ejecución de una tarea puede desencadenar la ejecución de muchas otras tareas.
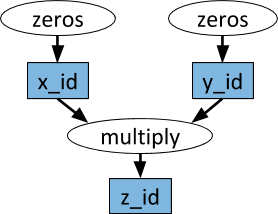 Un ejemplo de un gráfico computacional. En los óvalos blancos, se muestran las tareas, y en los rectángulos azules: objetos. Las flechas indican que algunas tareas dependen de objetos, mientras que otras crean objetos.
Un ejemplo de un gráfico computacional. En los óvalos blancos, se muestran las tareas, y en los rectángulos azules: objetos. Las flechas indican que algunas tareas dependen de objetos, mientras que otras crean objetos.Las funciones arbitrarias de Python se pueden realizar como tareas, y en cualquier orden pueden depender del resultado de otras tareas. Vea el ejemplo a continuación.
ActoresSolo con la ayuda de funciones remotas y el manejo de tareas anterior, es imposible lograr que varias tareas funcionen simultáneamente en el mismo estado mutable compartido. Tal problema con el aprendizaje automático surge en diferentes contextos, donde se puede compartir el estado del simulador, los pesos en la red neuronal o algo completamente diferente. La abstracción del actor se usa en Ray para encapsular un estado mutable compartido entre muchas tareas. Aquí hay un ejemplo ilustrativo que demuestra cómo hacer esto con el simulador Atari.
import gym @ray.remote class Simulator(object): def __init__(self): self.env = gym.make("Pong-v0") self.env.reset() def step(self, action): return self.env.step(action)
A pesar de su simplicidad, el actor es muy flexible en su uso. Por ejemplo, un simulador o una política de red neuronal puede encapsularse en un actor, también puede usarse para capacitación distribuida (como con un servidor de parámetros) o para proporcionar políticas en una aplicación "en vivo".
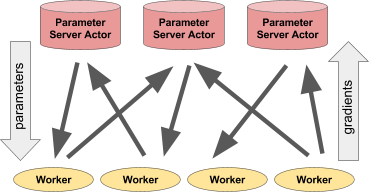 Izquierda: el actor proporciona pronósticos / acciones a varios procesos del cliente. Derecha: Muchos actores del servidor de parámetros realizan capacitación distribuida para muchos flujos de trabajo.Ejemplo de servidor de parámetros
Izquierda: el actor proporciona pronósticos / acciones a varios procesos del cliente. Derecha: Muchos actores del servidor de parámetros realizan capacitación distribuida para muchos flujos de trabajo.Ejemplo de servidor de parámetrosEl servidor de parámetros se puede implementar como un actor Ray de la siguiente manera:
@ray.remote class ParameterServer(object): def __init__(self, keys, values): # , . values = [value.copy() for value in values] self.parameters = dict(zip(keys, values)) def get(self, keys): return [self.parameters[key] for key in keys] def update(self, keys, values): # , # for key, value in zip(keys, values): self.parameters[key] += value
Aquí hay un
ejemplo más completo .
Para crear una instancia de un servidor de parámetros, hacemos esto.
parameter_server = ParameterServer.remote(initial_keys, initial_values)
Para crear cuatro trabajadores de larga duración, extrayendo y actualizando constantemente los parámetros, lo haremos.
@ray.remote def worker_task(parameter_server): while True: keys = ['key1', 'key2', 'key3'] # values = ray.get(parameter_server.get.remote(keys)) # updates = … # parameter_server.update.remote(keys, updates) # 4 for _ in range(4): worker_task.remote(parameter_server)
Ray Bibliotecas de alto nivelRay RLlib es una biblioteca de aprendizaje de refuerzo escalable diseñada para su uso en múltiples máquinas. Se puede habilitar utilizando los scripts de capacitación proporcionados como ejemplo, así como a través de la API de Pytho. Actualmente, incluye implementaciones de algoritmos:
- A3C
- Dqn
- Estrategias evolutivas
- PPO
Se está trabajando en la implementación de otros algoritmos. RLlib es totalmente compatible con el
gimnasio OpenAI .
Ray.tune es una biblioteca eficiente para la búsqueda distribuida de hiperparámetros. Proporciona una API de Python para aprendizaje profundo, aprendizaje de refuerzo y otras tareas que requieren mucha potencia de procesamiento. Aquí hay un ejemplo ilustrativo de este tipo:
from ray.tune import register_trainable, grid_search, run_experiments
Los resultados actuales se pueden visualizar dinámicamente utilizando herramientas especiales, por ejemplo, Tensorboard y VisKit de rllab (o leer directamente los registros JSON). Ray.tune admite búsqueda en cuadrícula, búsqueda aleatoria y más algoritmos de parada temprana no triviales como HyperBand.
Más sobre Ray