 El código del proyecto está disponible en el repositorio.
El código del proyecto está disponible en el repositorio.Introduccion
Cuando leía las descripciones de la aparición de personajes en los libros, siempre me interesaba cómo se veían en la vida. Es bastante posible imaginar a una persona como un todo, pero la descripción de los detalles más notables es una tarea difícil, y los resultados varían de persona a persona. Muchas veces no pude imaginar nada más que una cara muy borrosa del personaje hasta el final del trabajo. Solo cuando el libro se convierte en una película, la cara borrosa se llena de detalles. Por ejemplo, nunca podría imaginar cómo se ve la cara de Rachel del libro "
Chica en el tren ". Pero cuando salió la película, pude hacer coincidir la cara de Emily Blunt con el personaje de Rachel. Ciertamente, las personas involucradas en la selección de actores toman mucho tiempo para representar correctamente a los personajes en el guión.
Este problema me inspiró y motivó a encontrar una solución. Después de eso, comencé a estudiar la literatura sobre aprendizaje profundo en busca de algo similar. Afortunadamente, se han realizado bastantes estudios sobre la síntesis de imágenes a partir de texto. Estas son algunas de las que construí:
[los
proyectos usan redes de confrontación generativas, GSS (Generative adversarial network, GAN) / aprox. perev. ]
Después de estudiar la literatura, elegí una arquitectura que se simplificó en comparación con StackGAN ++ y que resuelve bastante bien mi problema. En las siguientes secciones, explicaré cómo resolví este problema y compartiré los resultados preliminares. También describiré algunos de los detalles de programación y capacitación en los que pasé mucho tiempo.
Análisis de datos
Sin lugar a dudas, el aspecto más importante del trabajo son los datos utilizados para entrenar el modelo. Como dijo el profesor Andrew Eun en sus cursos de deeplearning.ai: "En el campo del aprendizaje automático, no es el que tiene el mejor algoritmo, sino el que tiene los mejores datos". Así comenzó mi búsqueda de un conjunto de datos en caras con descripciones textuales buenas, ricas y diversas. Me encontré con diferentes conjuntos de datos, ya sea solo caras, o caras con nombres, o caras con una descripción del color de los ojos y la forma de la cara. Pero no había ninguno que necesitaba. Mi última opción fue utilizar
un proyecto inicial : generar una descripción de datos estructurales en un lenguaje natural. Pero tal opción agregaría ruido adicional a un conjunto de datos ya bastante ruidoso.
Pasó el tiempo, y en algún momento
apareció un nuevo proyecto
Face2Text . Era una colección de una base de datos de descripciones detalladas de personas. Agradezco a los autores del proyecto por el conjunto de datos proporcionado.
El conjunto de datos contenía descripciones textuales de 400 imágenes seleccionadas al azar de la base de datos LFW (caras etiquetadas). Se limpiaron las descripciones para eliminar características ambiguas y menores. Algunas descripciones contenían no solo información sobre los rostros, sino también algunas conclusiones hechas sobre la base de las imágenes, por ejemplo, "la persona en la foto es probablemente un criminal". Todos estos factores, así como el pequeño tamaño del conjunto de datos, han llevado al hecho de que mi proyecto hasta ahora solo demuestra evidencia de la operatividad de la arquitectura. Posteriormente, este modelo puede escalarse a un conjunto de datos más grande y diverso.
Arquitectura
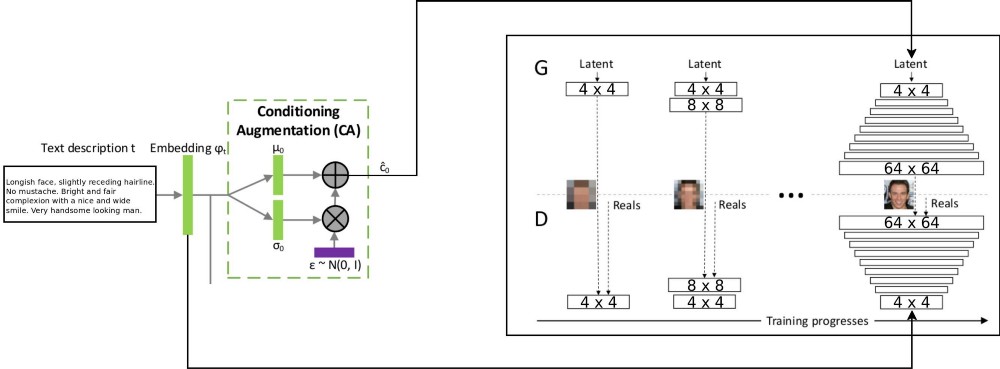
La arquitectura del proyecto T2F combina dos arquitecturas stackGAN para codificar texto condicionalmente incrementado, y ProGAN (
crecimiento progresivo del GSS ) para sintetizar imágenes faciales. La arquitectura original de stackgan ++ utilizaba varios GSS con diferentes resoluciones espaciales, y decidí que este era un enfoque demasiado serio para cualquier tarea de distribución de correspondencia. Pero ProGAN usa solo un GSS, entrenado progresivamente en resoluciones cada vez más detalladas. Decidí combinar estos dos enfoques.
Hay una explicación del flujo de datos: las descripciones de texto se codifican en el vector final incrustando en la red LSTM (Embedded) (psy_t) (ver diagrama). Luego, la incrustación se transmite a través del bloque de Aumento de Acondicionamiento (una capa lineal) para obtener la parte de texto del vector propio (usando la técnica de reparametrización VAE) para el GSS como entrada. La segunda parte del vector propio es ruido aleatorio gaussiano. El vector propio resultante se alimenta al generador GSS, y la incrustación se alimenta a la última capa discriminadora para la distribución condicional de correspondencia. La capacitación de los procesos de GSS es exactamente la misma que en el artículo sobre ProGAN: en capas, con un aumento de la resolución espacial. Se introduce una nueva capa utilizando la técnica de desvanecimiento para evitar borrar resultados de aprendizaje anteriores.
Implementación y otros detalles.
La aplicación fue escrita en python usando el marco PyTorch. Solía trabajar con paquetes de tensorflow y keras, pero ahora quería probar PyTorch. Me gustó usar el depurador de python incorporado para trabajar con la arquitectura de red, todo gracias a la estrategia de ejecución temprana. Tensorflow también activó recientemente el modo de ejecución ansioso. Sin embargo, no quiero juzgar qué marco es mejor, solo quiero enfatizar que el código para este proyecto fue escrito usando PyTorch.
Algunas partes del proyecto me parecen reutilizables, especialmente ProGAN. Por lo tanto, escribí un código separado para ellos como una
extensión del módulo PyTorch, y también se puede usar en otros conjuntos de datos. Solo es necesario indicar la profundidad y el tamaño de las características del GSS. GSS puede ser entrenado progresivamente para cualquier conjunto de datos.
Detalles de entrenamiento
Entrené bastantes versiones de la red usando diferentes hiperparámetros. Los detalles del trabajo son los siguientes:
- El discriminador no tiene operaciones de lote o norma de capa, por lo que la pérdida de WGAN-GP puede crecer de manera explosiva. Utilicé penalización de deriva con lambda igual a 0.001.
- Para controlar su propia diversidad, obtenida del texto codificado, es necesario utilizar la distancia Kullback - Leibler en las pérdidas del generador.
- Para que las imágenes resultantes coincidan mejor con la distribución de texto entrante, es mejor usar la versión WGAN del discriminador correspondiente (Matching-Aware).
- El tiempo de desvanecimiento para los niveles superiores debe exceder el tiempo de desvanecimiento para los niveles inferiores. Usé el 85% como valor de desvanecimiento al entrenar.
- Descubrí que los ejemplos de mayor resolución (32 x 32 y 64 x 64) producen más ruido de fondo que los ejemplos de menor resolución. Creo que esto se debe a la falta de datos.
- Durante un entrenamiento progresivo, es mejor dedicar más tiempo a resoluciones más bajas y reducir el tiempo dedicado a trabajar con resoluciones más altas.
El video muestra el lapso de tiempo del generador. El video se compila a partir de imágenes con diferentes resoluciones espaciales obtenidas durante el entrenamiento del GSS.
Conclusión
Según los resultados preliminares, se puede juzgar que el proyecto T2F es viable y tiene aplicaciones interesantes. Supongamos que se puede usar para componer photobots. O para los casos en que es necesario aumentar la imaginación. Continuaré trabajando para escalar este proyecto en conjuntos de datos como Flicker8K, subtítulos de Coco, etc.
El crecimiento progresivo de GSS es una tecnología fenomenal para un entrenamiento GSS más rápido y estable. Se puede combinar con varias tecnologías modernas mencionadas en otros artículos. GSS se puede utilizar en diferentes áreas de MO.