Hola Habr! Mi nombre es Sergey Prutskikh, estoy a cargo de la dirección de monitoreo de Sberbank-Technology. El objetivo principal de nuestra organización es el desarrollo y prueba de productos de software para Sberbank. Para esto, la compañía tiene una gran infraestructura de TI: 15 mil servidores se dividen en aproximadamente 1,500 entornos de prueba, que están relacionados con más de 500 sistemas automatizados. En total, unos 10 mil especialistas trabajan con ellos.
En 2015, comenzamos a crear un servicio de monitoreo centralizado. Además, todo estaba limitado no solo a la implementación. Era necesario elaborar muchas regulaciones, instrucciones, así como la relación entre las unidades de Sbertech en el marco de la supervisión. En esta publicación, te contaré en detalle cómo elegimos la plataforma, sobre qué principios creamos todo y con qué terminamos.

Los principales objetivos e ideología del proyecto.
Estos son los objetivos que perseguimos en el proyecto:
- Obtención de datos confiables sobre el tamaño y la composición de la infraestructura de TI;
- Optimización del uso de las instalaciones de TI;
- Reducir los costos de soporte y operación de la infraestructura de TI de los entornos de desarrollo y prueba;
- Soporte para infraestructura de TI en preparación para el desarrollo y pruebas;
- Información inmediata de especialistas sobre problemas en el trabajo de entornos de prueba;
- La auditoría de cumplimiento de entornos de prueba y AFM industriales no es una tarea muy típica para nosotros;
- Recopilación de datos para informes sobre los resultados de las pruebas, proporcionando la medición de parámetros críticos en todas las etapas de las pruebas
Mirando hacia el futuro, puedo decir que todas las metas en un grado u otro ya se han completado hasta la fecha. Y algunos problemas relacionados, el monitoreo también ayudó a resolver.
Además de los objetivos, formulamos principios, una ideología, a la que nos adherimos a lo largo del proyecto:
- La satisfacción del usuario es uno de los principales indicadores de monitoreo. En la conferencia ITSMf 2017, hablé sobre el monitoreo de la infraestructura de TI, y el quinto NO está en ese informe: "NO obligue a sus empleados a trabajar con el sistema de monitoreo". El punto es motivar, no obligar. Esto se logra a través de KPI construidos adecuadamente. Al comienzo del servicio, estos KPI pueden no aparecer todavía. Sin embargo, es muy importante desde los primeros días de monitoreo comenzar a beneficiar a los clientes potenciales.
- Tiempo mínimo de refinamiento. Para esto utilizamos elementos ágiles. Ayudan a proporcionar nuevas funciones lo más rápido posible y reciben comentarios de los clientes.
- La apertura del sistema, tanto para las mejoras, que se expresa en la creación de una sola cartera de pedidos, las solicitudes a las que cualquier empleado puede escribir, y en términos de proporcionar información, nuestro servicio le permite obtener información sobre la configuración de monitoreo, que, por regla general, está oculta.
- Alto grado de integración en el trabajo diario. Nuestra prioridad es implementar la funcionalidad que los usuarios necesitan a diario. Esto ayudó en un tiempo relativamente corto a popularizar el servicio de monitoreo dentro de la empresa.
La elección del sistema de monitoreo
En casi todos los proyectos en los que participé, tarde o temprano apareció una tabla comparando la funcionalidad de varios sistemas, en los que un sistema en particular tenía una ventaja obvia.
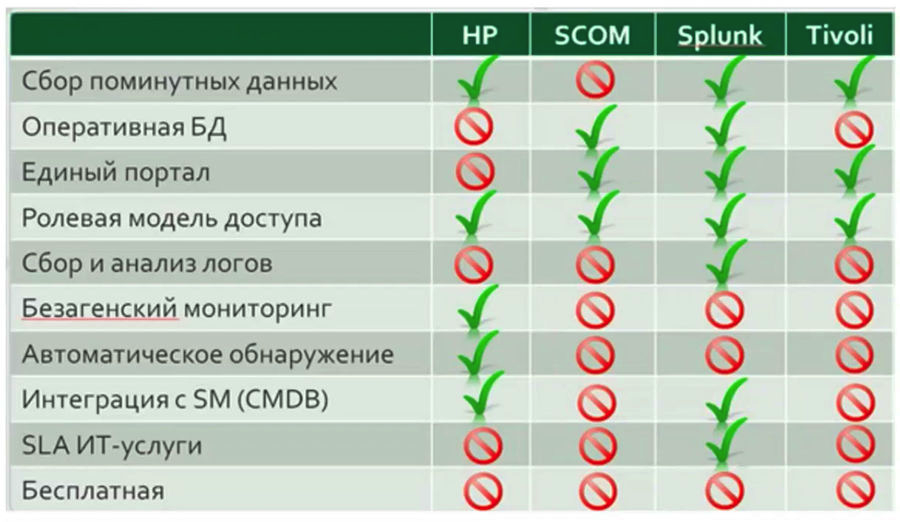
En mi opinión, dicho análisis comparativo
no puede hacerse antes del inicio inmediato de trabajar con el servicio de monitoreo, y aún más, no vale la pena tomar una decisión sobre la elección de una u otra solución basada en este análisis. Mientras el sistema de su empresa no funcione durante al menos un corto período de tiempo, es imposible juzgar sin ambigüedades qué funciones específicas de su empresa tendrán demanda. Estas tablas pueden ayudar si desea cambiar el sistema de monitoreo por alguna razón.
Comparación con otras instalaciones de Zabbix
Puede hablar mucho sobre cómo comparar el tamaño de varias instalaciones de sistemas de monitoreo, pero todas las características seleccionadas para esto, en mi opinión, son bastante subjetivas. Para que tenga una idea más precisa del tamaño de nuestra instalación, decidí dar ejemplos de servicios similares en otras empresas, de los que hablaron los representantes de Zabbix en la conferencia de Highload.
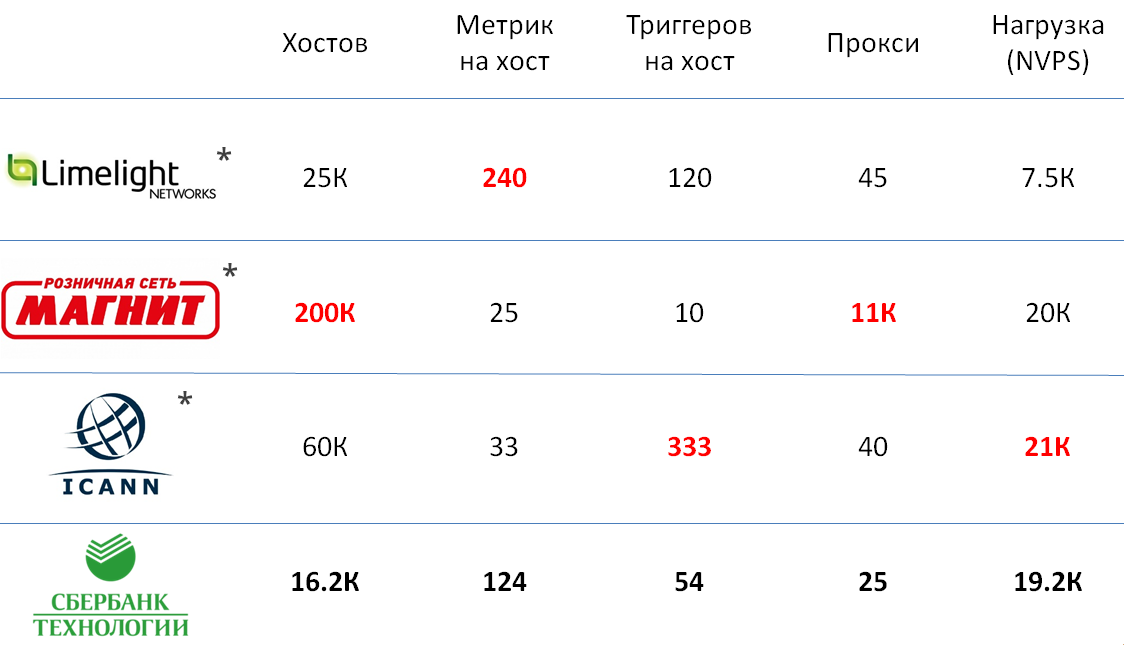
Como puede ver, la instancia de Zabbix en Sbertech no es muy inferior a las instalaciones más grandes, y en términos de la carga total está a la par con ellas.
Beneficios de Zabbix
En la segunda mitad de 2017, realizamos un piloto Zabbix para monitorear la infraestructura de PROM. Luego formulamos una serie de criterios cualitativos que atribuimos a las ventajas absolutas de Zabbix:
- Código abierto Posibilidades ilimitadas de procesamiento y personalización.
- Apertura del mecanismo y fuente de recopilación de métricas. En las soluciones empresariales comerciales, muchas métricas son incomprensibles: varias botnets, pérdidas de memoria, que incluso el soporte técnico del proveedor a menudo no puede explicar. Zabbix no tiene ese problema: siempre se puede decir claramente cómo recopila ciertas métricas. Por lo tanto, la credibilidad del sistema por parte de los administradores del sistema aumenta.
- Relativa facilidad de escala , principalmente debido a la introducción de servidores proxy adicionales, a los que puede transferir parte de la carga. Si alcanza el límite de rendimiento de una instancia, es posible aumentar la segunda y combinar ambas en un sistema de visualización (Grafana).
- API genial : en mi opinión, esta es una de las principales ventajas de Zabbix. Una API de alta calidad, bien desarrollada y comprensible abre enormes oportunidades para la integración con sistemas relacionados, automatización, etc.
- Monitorear objetos dinámicos es un poco, pero agradable. En Zabbix, este monitoreo es simple e intuitivo, lo que le permite lograr buenos resultados muy rápidamente. Los objetos dinámicos son cualquier objeto que aparece y desaparece en los servidores durante su vida útil: sistemas de archivos, interfaces de red y otros. Por lo tanto, es necesario automatizar la configuración y la eliminación de estos objetos de la supervisión.
- Un número relativamente pequeño de componentes. En soluciones comerciales, cada componente es un subsistema separado con su propia base, que debe instalarse por separado. Y Zabbix es un sistema único, en el que todos los métodos de monitoreo se concentran a la vez: agente, sin agente, red y otros, solo 14 tipos.
- Visualización de datos con Grafana. La integración con Grafana hace posible construir gráficos y crear paneles realmente convenientes.
- Disponibilidad de monitorear la disponibilidad de servicios de TI. Zabbix tiene un subsistema incorporado que puede calcular la disponibilidad de servicios de TI para uso futuro en SLA.
- La flexibilidad para crear métricas y sus valores umbral. Aquí Zabbix tiene una amplia oportunidad para configurar métricas de monitoreo complejas:
- En primer lugar, es la creación de métricas calculadas : sobre la base de varias métricas simples, se calcula una compleja.
- el preprocesamiento del valor de la métrica está disponible; esto es, por ejemplo, cuando carga una gran matriz de datos en Zabbix, y luego, antes de colocar una métrica específica en la base de datos, Zabbix analiza la matriz y extrae exactamente los datos que desea guardar como métrica .
- métricas maestras. Es posible recopilar una matriz de datos sobre un objeto en una encuesta en una métrica grande y luego usarla como fuente de datos para otras métricas. Esto le permite reducir la cantidad de consultas y sincronizar la recopilación de todas las métricas a tiempo.
- Posibilidad de monitoreo interno. Zabbix, como producto de código abierto, tiene problemas de rendimiento. Sin embargo, un sistema de monitoreo interno bien pensado ayuda a lidiar rápidamente con estos problemas.
Desventajas de Zabbix
Para ser justos, no puedo evitar mencionar los principales, en mi opinión, las deficiencias de Zabbix. También puede hacer una lista decente de ellos:
- Bajo grado de automatización de backend. Haré una reserva de que no tuve la oportunidad de experimentar con todas las variantes del DBMS. Nuestra empresa utiliza Oracle DBMS como un backend de Zabbix. Las operaciones masivas pueden tomar más de una hora, por ejemplo, actualizar o cambiar las métricas, que están vinculadas a una gran cantidad de objetos (15 mil nodos de red).
- Falta de herramientas integradas de administración de agentes de monitoreo. Dichos productos están disponibles en productos comerciales. Zabbix todavía no tiene esto. Ni siquiera hay una actualización del kit de herramientas para los agentes. Por supuesto, todo se puede hacer de forma independiente, pero sería mejor sacar estas características de la caja.
- Hasta ahora, baja elaboración de monitoreo de la disponibilidad de servicios de TI. Es genial que haya monitoreo, pero necesita desarrollarse más. Ahora no es posible restringir de alguna manera el acceso del usuario a ninguna parte individual del modelo de recursos de servicio (en adelante, CPM). Si el árbol de CPM es grande, la interfaz web comienza a ralentizarse. Y las posibilidades de personalizar el cálculo de disponibilidad en este subsistema siguen siendo bajas.
- Largas actualizaciones. La última actualización de la base de datos nos llevó unas ocho horas. En este momento, el servicio de monitoreo no estaba disponible. Alternativamente, puede solicitar scripts de soporte y actualizar por separado.
- La modesta funcionalidad del subsistema de visualización incorporado. Grafana resuelve este problema, pero la visualización integrada deja mucho que desear.
- Monitoreo DBMS integrado (ODBC). El hecho es que dicho monitoreo abre una conexión separada para Zabbix cada vez que se sondea la métrica. Y si su base de datos es grande (con una gran cantidad de métricas recopiladas), entonces el conjunto de conexiones puede llenarse y la base de datos dejará de responder, incluso para los sistemas de destino. Zabbix tiene una herramienta de monitoreo alternativa (por ejemplo, DBforBIX), pero configurarla para una gran cantidad de objetos es una tarea bastante laboriosa. Además, para esto necesitas escribir una automatización por separado.
- Falta de flexibilidad de inventario para la infraestructura de TI. Por un lado, es bueno tenerlo. Por otro lado, parece una pestaña separada para cualquier objeto de monitoreo en el que hay un conjunto de campos de inventario con nombres codificados. Para cambiar algo, debe ingresar al código fuente de la interfaz. También es imposible cambiar el número de estos campos y tamaños; existe el riesgo de romper algo durante la próxima actualización.
- Falta de automatización para construir mapas de red. A modo de comparación, podemos citar el HP OpenView Network Node Manager, que es perfectamente capaz de construir mapas de topología de red en modo automático. Zabbix tendrá que construir todo manualmente. Quizás, por esta razón, esta funcionalidad prácticamente no está en demanda entre nosotros.
- Falta de flexibilidad en el modelo a seguir. Zabbix proporciona solo cuatro roles de usuario con capacidades fijas. Además, no hay forma de salir de la caja para restringir el acceso de los usuarios a la API de Zabbix. Es decir, si el usuario tiene acceso a la interfaz, entonces automáticamente tiene acceso a la API. Para nosotros, esto llevó al hecho de que los usuarios con solicitudes ineptas cargaron seriamente el sistema. Además, no hay forma de dar acceso al usuario, por ejemplo, para leer métricas sin acceso, para editar la configuración del objeto de monitoreo.
Arquitectura del sistema
Ahora algunas palabras sobre los indicadores cuantitativos y la arquitectura de nuestro sistema.
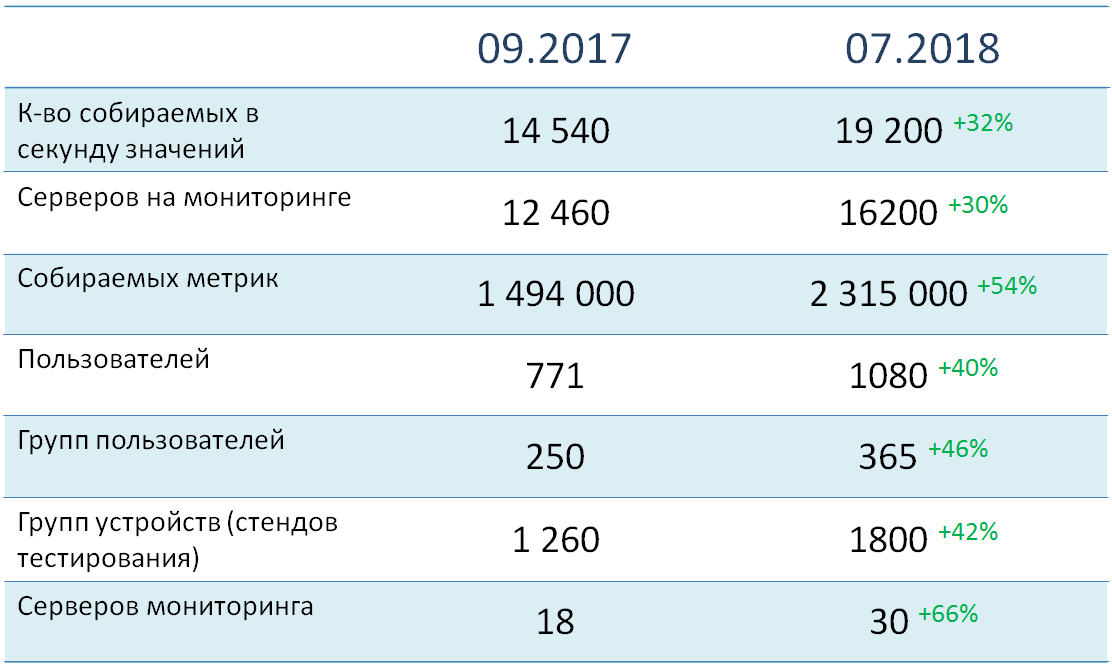
En este momento, hay más de 16 mil objetos (principalmente servidores) bajo supervisión, de los cuales se recopilan casi dos millones y medio de métricas en total. Su carga total en el sistema es de aproximadamente 19 mil valores por segundo. Todos los objetos de monitoreo se distribuyen en más de 1800 grupos de dispositivos, la gran mayoría de los cuales corresponden a entornos de prueba específicos. Actualmente, más de 1000 usuarios están registrados en el sistema, que se dividen en 365 grupos funcionales.
Como puede ver, prestamos mucha atención a la distribución de dispositivos y usuarios en grupos. Esto le permite aumentar significativamente la precisión de las alertas de nuestro servicio.
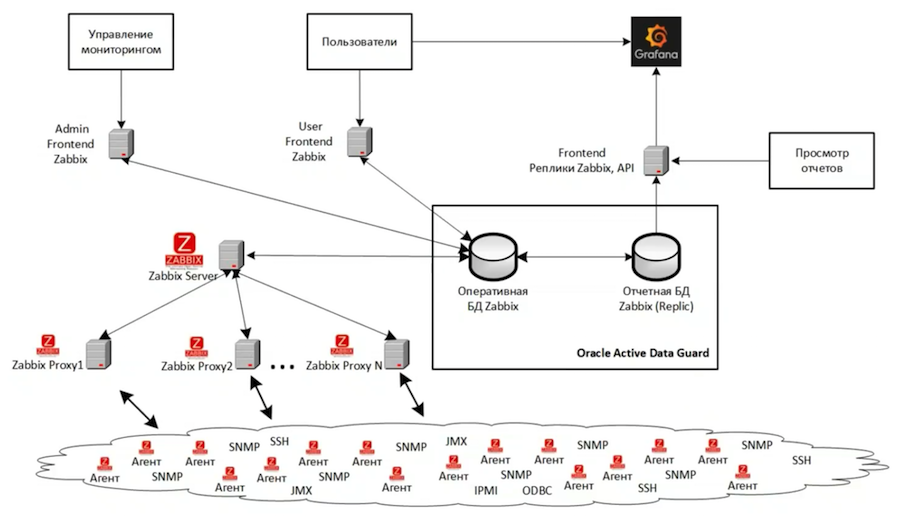
En total, tenemos tres instancias de Zabbix. El diagrama muestra la arquitectura de la más grande de ellas, que monitorea la infraestructura principal de TI de desarrollo y pruebas. Otra instancia supervisa la infraestructura de monitoreo. Y la tercera instancia se usa con nosotros para el desarrollo y prueba de nuevas herramientas de monitoreo. La estructura completa de la instancia principal se virtualiza sobre la base de VMWare. En general, si es posible, es mejor no utilizar ningún sistema de virtualización, ya que es mucho más difícil buscar y resolver problemas de rendimiento en el caso de la infraestructura virtual.
El backend se basa en Oracle Active Data Guard y consta de dos bases de datos: la principal y la réplica. Tenemos tres frentes:
- Para tareas administrativas: está configurado para realizar operaciones pesadas, complejas y a largo plazo que cargan mucho el servidor;
- Personalizado: con configuraciones más estrictas que no permiten a los usuarios sobrecargar demasiado el sistema de monitoreo principal;
- Para la presentación de informes, analiza la réplica y se ha adaptado para interactuar con bases de datos de solo lectura. Grafana está conectado a él, proporcionando una visualización de alta calidad de los datos de monitoreo.
Características de implementación
En esta historia, decidí no centrarme en la funcionalidad básica que se implementa en casi cualquier monitoreo: arreglar fallas, recopilar información sobre el rendimiento o la disponibilidad de los sistemas de TI. Me centraré en las características distintivas de nuestro servicio.
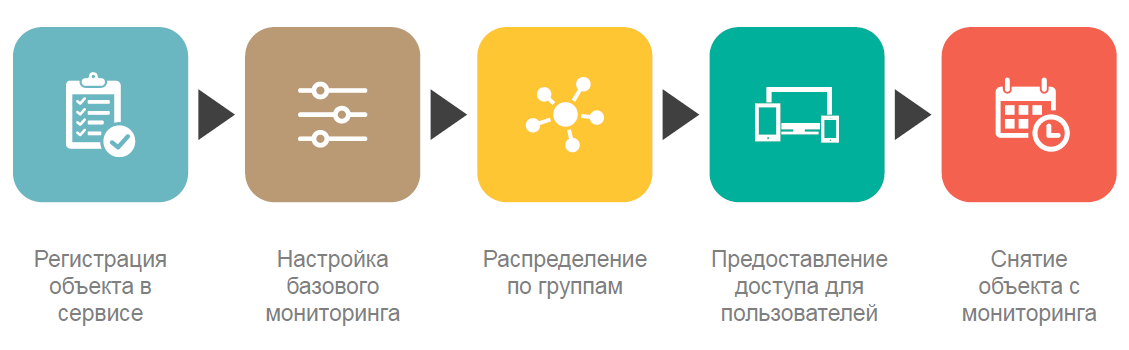
Estas características incluyen principalmente un alto grado de automatización de tareas típicas. Prácticamente no pasamos tiempo configurando servidores para el monitoreo, brindando acceso a los resultados del monitoreo, sino que nos enfocamos principalmente en desarrollar el servicio y agregarle nuevas características no estándar. Más de 200 scripts de automatización desarrollados desde el momento en que el servicio de monitoreo se puso en operación de prueba nos ayuda mucho en esto.
Pero antes de registrar el agente en Zabbix, aún debe instalarse. Como escribí anteriormente, uno de los inconvenientes de Zabbix es la falta de herramientas de administración de agentes de monitoreo. Por lo tanto, para instalar agentes, hemos organizado un trabajo separado como parte de nuestros procesos DevOps. La siguiente figura muestra el diagrama de instalación del agente.
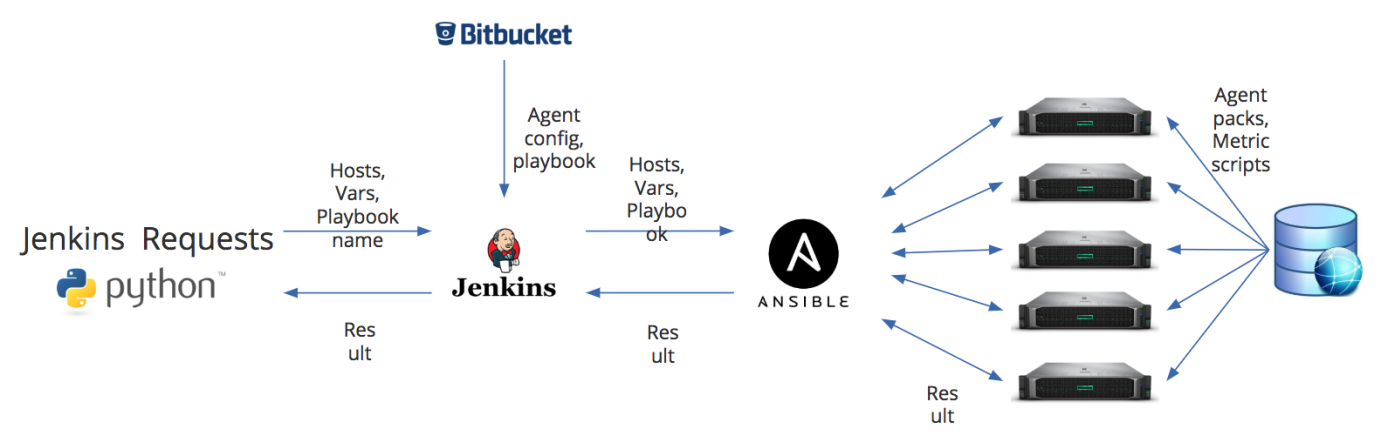
Tenemos dos puntos de entrada principales. Este es un script de Python: a través de la API REST, pasa información al trabajo Jenkins sobre los hosts en los que desea instalar o actualizar el agente, una lista de variables adicionales, así como el nombre del libro de jugadas que necesita ejecutar en Ansible. O los datos predeterminados pueden provenir de Bitbucket. Pero en Jenkins, se pueden reemplazar por completo de acuerdo con las variables que pasamos. Y esto nos ayuda, por ejemplo, a actualizar agentes que son monitoreados por diferentes servidores proxy. La peculiaridad de nuestro proceso es que la configuración del agente Zabbix se forma casi sobre la marcha.
Informes
Ya al comienzo del proyecto, quedó claro que las herramientas de informes estándar proporcionadas por las herramientas de Zabbix no nos permitirían satisfacer todas nuestras necesidades. En este sentido, sobre la base de la arquitectura de microservicios, se implementó un subsistema de informes separado, que amplía significativamente las capacidades de los informes de monitoreo básicos. Ahora tenemos más de veinte informes en funcionamiento. Aquí hay algunos ejemplos junto con los objetivos que se están implementando:

Alertas
A lo largo del trabajo del servicio, las alertas por correo electrónico han evolucionado. Así es como se ven en este momento:
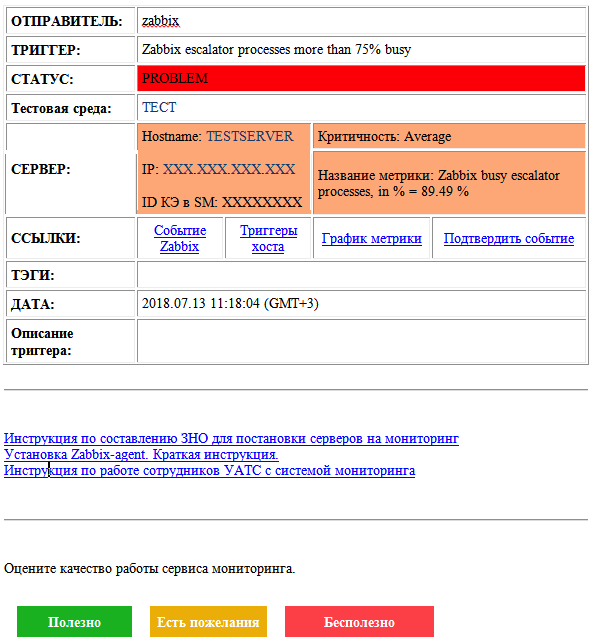
Hay información sobre el problema y su estado, así como sobre el objeto de supervisión. Hay enlaces a métricas y eventos relacionados, un campo para describir el problema, enlaces a instrucciones y un formulario de comentarios. Para accidentes más críticos, nosotros, por supuesto, también tenemos una distribución de SMS.
Tales alertas informativas nos permitieron minimizar la comunicación de la mayoría de nuestros usuarios con el propio Zabbix. Es suficiente recibir esta lista de correo. Agrupamos bien a los usuarios: hay 365 grupos para 1080 personas. Por lo tanto, el boletín resulta bastante punteado y, en consecuencia, no es molesto. Muchos de nuestros usuarios casi han olvidado que, de hecho, tenemos Zabbix: utilizan el boletín de Grafana y el sistema de visualización.
Integración con los procesos de gestión.
El proyecto inicialmente involucró la integración de monitoreo con algunos de nuestros procesos de administración de infraestructura de TI. Si el servicio de monitoreo ha registrado un accidente, puede crear un ticket para él, para aquellos equipos que trabajan más con Jira. Para los departamentos de servicio, es posible crear incidentes en HP Service Manager:

Basado en Zabbix, también se desarrolló y automatizó una metodología para optimizar la utilización de la infraestructura de TI. Se optimizan tres parámetros principales: la cantidad de CPU, RAM y discos duros. Esta técnica funciona sobre la base de un promedio móvil y un percentil 90. Basado en esta técnica, cualquier objeto o servidor cae en una de tres categorías: subcargado, cargado de manera óptima, sobrecargado.
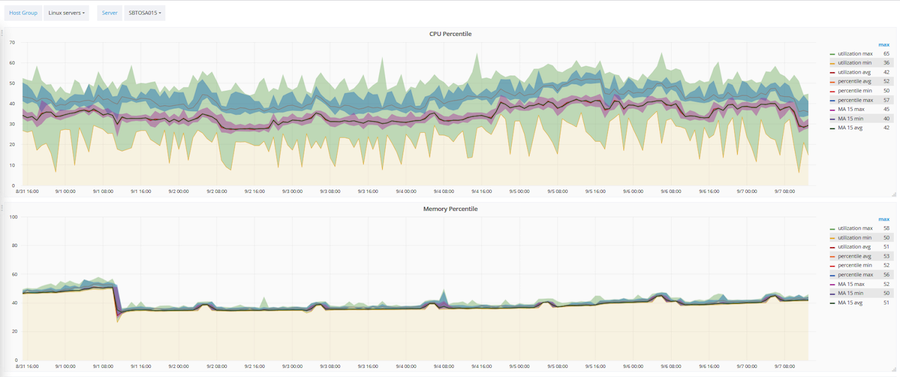
Lo anterior muestra cómo se aplica esta técnica a un servidor específico. El corredor rosa es el valor de la media móvil. Amplio corredor verde: datos sin procesar. Y el azul es un percentil 90.
La integración con la base de datos de configuración permitió automatizar la mayoría de las tareas asociadas con la provisión de acceso y la creación de un modelo de servicio-recurso. , . , , , .
Zabbix . , .
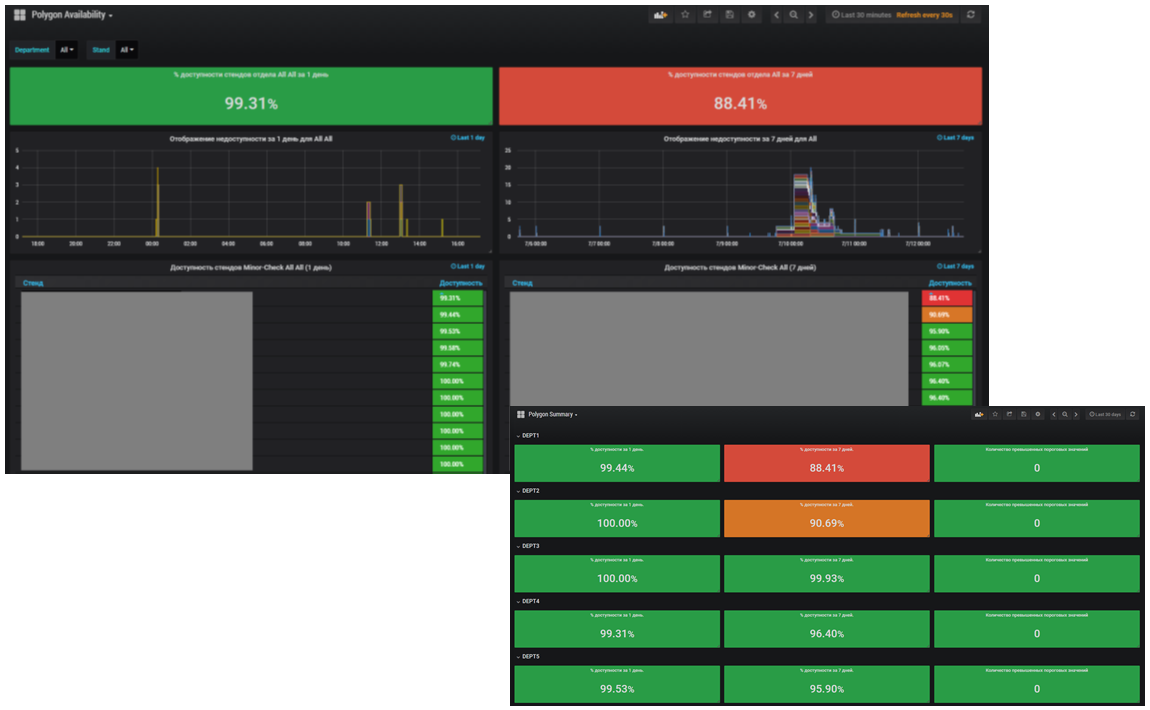
, . , . .
, . 2017 :
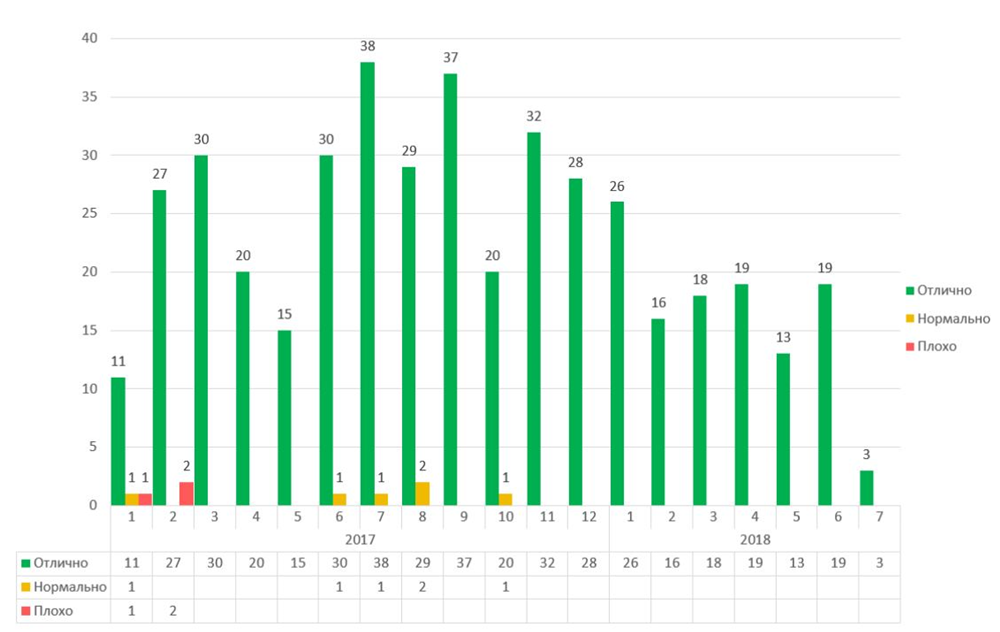
2017 .
, :
, . 70% . , , , .
2016 . . , , .
2016 . - , . . ,
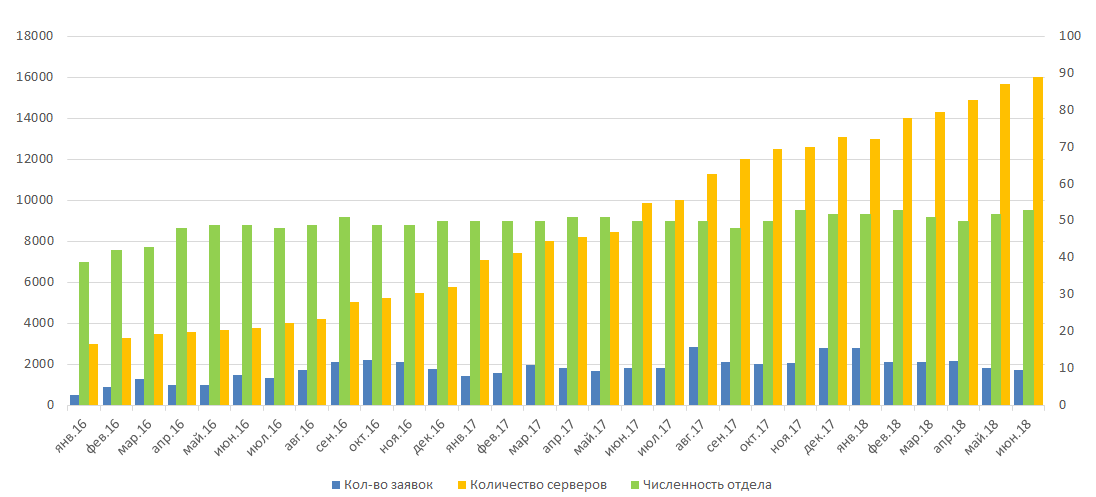
2016 , : 600 CPU, 7,5 50 .