Hola a todos! Esta vez quiero escribir sobre cómo logré ganar la competencia
Mini AI Cup 2 . Como en mi
último artículo , prácticamente no habrá detalles de implementación. Esta vez la tarea fue menos voluminosa, pero sin embargo, hubo muchos matices y pequeñas cosas que afectan el comportamiento del bot. Como resultado, incluso después de casi tres semanas de trabajo activo en el bot, todavía había ideas sobre cómo mejorar la estrategia.
Debajo del corte muchos gifs y tráfico.
Los persistentes lo descubrirán, el resto huirá con horror (de los comentarios en la breve parte comprimida).Aquellos que son demasiado vagos para leer mucho pueden ir al penúltimo spoiler del artículo para ver una breve descripción concisa del algoritmo , y luego pueden comenzar a leer desde el principio .Enlace a la fuente
en el github .
Selección de herramienta
Como la última vez, me llevó mucho tiempo pensar por dónde empezar. La elección fue, entre otras cosas, entre dos lenguajes: Java, familiar para mí, y ya bastante olvidado de los días de estudiante C ++. Pero desde el principio me pareció que el principal obstáculo para escribir un buen bot no sería tanto la velocidad de desarrollo como la productividad de la solución final, sin embargo, la elección cayó en C ++.
Después de la exitosa experiencia de usar mi propio visualizador para depurar el bot en competiciones anteriores, esta vez tampoco quería prescindir de uno. Pero el visualizador que escribí para mí en Qt para
CodeWars no me pareció una solución ideal, y decidí usar
este visualizador. También se realizó bajo CodeWars, pero no requirió un procesamiento serio para su uso en esta competencia. La relativa simplicidad de conexión y la conveniencia de invocar renderizado en cualquier parte del código jugado a su favor.
Como antes, realmente quería depurar cualquier tic en el juego: la capacidad de ejecutar una estrategia en un momento arbitrario del juego probado. Dado que el visualizador de complementos no pudo resolver este problema, con la ayuda del par #ifdef (en el que también envolví los fragmentos de código responsables de la representación) agregué a cada tick el guardado de la clase Context, que contenía todos los valores necesarios de las variables del tick anterior. En esencia, la solución fue similar a la que usé en Code Wizards, pero esta vez el enfoque no fue tan espontáneo. Después de simular todo el juego, se le pidió que ingrese el número de la marca del juego, que debe reiniciarse. La información sobre el estado de las variables antes de este tick se tomó de la matriz, así como la línea recibida por la estrategia de entrada, lo que me permitió jugar los movimientos de mi estrategia en el orden necesario.
Inicio
El día que se abrieron las reglas, no pasé y la primera noche miré lo que nos espera. No dudó en indignarse con el formato de entrada json (sí, es conveniente, pero algunos participantes comienzan a dominar nuevos YP viejos y olvidados en tales competiciones, y comenzar con el análisis json no es el más agradable), miró la extraña fórmula de movimiento y de alguna manera comenzó a formar el futuro estrategias (para entender el artículo en el futuro es útil leer las
reglas ). Durante 2 días escribí un montón de clases como Ejection, Virus, Player y otras, leyendo json, conectando una biblioteca de un solo archivo para iniciar sesión ... Y en la tarde de la apertura de un sandbox sin clasificar, ya tenía una estrategia que era casi idéntica en principio a C ++, pero significativamente, un código mucho más grande.
Y luego ... comencé a descubrir opciones, cómo desarrollarlas. Pensamientos en ese momento:
- La búsqueda de estados mundiales no puede reducirse a aquellos valores que pueden dominar el minimax y las modificaciones;
- Los campos potenciales son buenos, pero responden mal la pregunta de cómo el mundo cambiará los próximos n ticks;
- La genética y algoritmos similares funcionarán, pero solo se proporcionan 20 ms por golpe, y la profundidad de cálculo sería deseable, a primera vista, más de lo que las sensaciones se pueden procesar con el GA. Sí, y puedes jugar con la selección de parámetros de mutación "felices para siempre".
Definitivamente decidí una cosa: necesitamos hacer una simulación del mundo. Después de todo, ¿pueden los cálculos aproximados "vencer" a un cálculo frío y preciso? Tales consideraciones, por supuesto, me llevaron a buscar en el código que se suponía que era responsable de simular el mundo en el servidor, porque esta vez se puso en el dominio público junto con las reglas. Después de todo, ¿no hay nada mejor que un código que describa con precisión las reglas del mundo?
Así que pensé exactamente hasta que comencé a estudiar el código que se suponía que probaría nuestros bots en el servidor y localmente. Inicialmente, en términos de comprensión y corrección del código, todo no era muy bueno, y los organizadores, junto con los participantes, comenzaron a procesarlo activamente. Durante la prueba beta (capturada un par de días después), los cambios en el motor del juego fueron muy serios, y muchos no comenzaron a participar hasta el momento en que el motor de prueba no se estabiliza. Pero al final, en mi opinión, esperaron un motor que funcionara bien para un juego muy adecuado para el formato de competición. Tampoco comencé a implementar enfoques serios hasta que el corredor local se estabilizó, y durante la primera semana no se hizo nada más sensato en mi bot, excepto el visualizador atornillado.
En la víspera del primer fin de semana en el telegrama, los organizadores crearon un grupo separado en el que se suponía que las personas podrían ayudar a corregir y mejorar el corredor local. También participé en el trabajo sobre el motor del mundo. Después de las discusiones en este chat, como prueba, realicé 2 solicitudes de extracción a la ubicación del corredor: ajustando la fórmula de
alimentación (y pequeños cambios en el orden de alimentación) a las reglas, y fusionando varias partes en un agárico mientras
mantenía la inercia y el centro de masa ). Entonces comencé a pensar en cómo insertar una física de colisión sensata en este código, porque la física presente en el mundo del juego en ese momento funcionaba muy ilógicamente. Como las colisiones entre los dos agáricos no se describieron en las reglas, les pedí a los organizadores criterios según los cuales mi implementación de tal lógica sería aceptable. La respuesta fue esta: los agáricos en una colisión deben ser "blandos" (es decir, podrían toparse un poco entre sí), mientras que la lógica de una colisión con las paredes no debe tocarse (es decir, las paredes simplemente deben detener los agáricos, pero no alejarlos). Y mi siguiente
solicitud de extracción fue una alteración grave de la física.
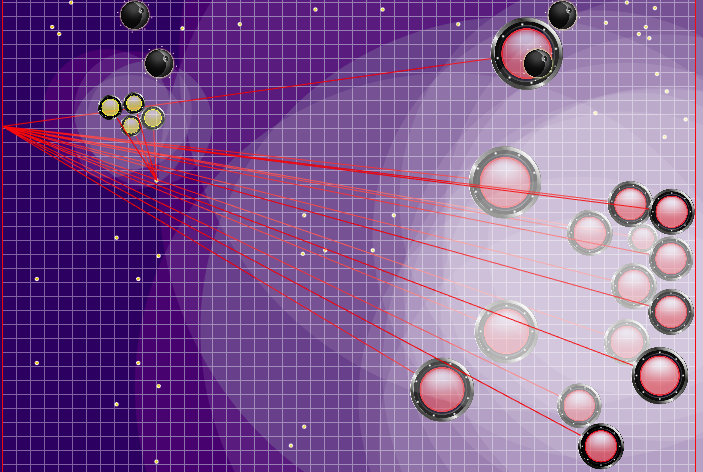
Antes y después de la alteración de la física.Tal física de colisión fue: Y se volvió así después de las actualizaciones:
Y se volvió así después de las actualizaciones:
También me gustaría destacar
esta solicitud de extracción, que redujo significativamente el código confuso con el análisis de estado y una gran cantidad de errores encontrados (y potenciales) en algo mucho más inteligible.
Escribir una simulación
Después de llevar el código de la configuración regional del corredor a una forma sensata, gradualmente comencé a transferir el código de simulación del mundo desde la configuración regional del corredor a mi bot. En primer lugar, era, por supuesto, un código para simular el movimiento de agáricos, y al mismo tiempo un código para calcular la física de las colisiones. Tomó un par de tardes salvar el código rediseñado de la reescritura de errores (la transferencia lógica no se realizó copiando el código) y estimaciones aproximadas de la profundidad de los cálculos.
La función de calificación para cada marca en ese momento era +1 para la comida que como y -1 para la comida que comió el enemigo, así como valores ligeramente mayores para comer los agáricos del otro. En las constantes para comer otros agáricos, inicialmente había una diferencia entre comer a mi oponente, mi oponente (y, por supuesto, una multa muy grande por comer mi último agarika por el oponente), así como dos oponentes diferentes entre sí (después de un par de días, el último coeficiente se convirtió en 0). Además, la velocidad total para todos los ticks anteriores de la simulación, cada tick se multiplicó por 1 + 1e-5 para alentar a mi bot a realizar acciones más útiles al menos un poco antes, y al final de la simulación, la velocidad para el último tick se agregó como un bono, también muy pequeño . Para simular el movimiento de agáricos, se seleccionaron puntos en el borde del mapa con un paso de 15 grados desde las coordenadas medias aritméticas de todos mis agáricos, y se seleccionó un punto, al simular el movimiento en el que la función de estimación adquirió el mayor valor. Y ya con una simulación aparentemente tan primitiva y una evaluación simple en ese momento, el bot se afianzó con bastante confianza en el top 10.
Demostración de puntos, el comando de movimiento al que el algoritmo simuló originalmente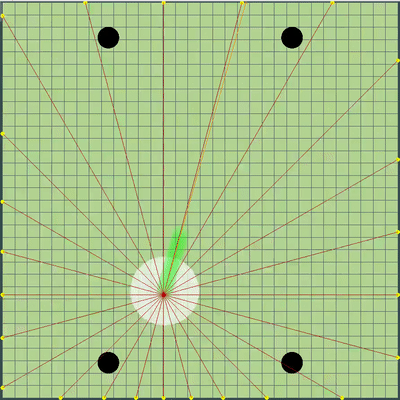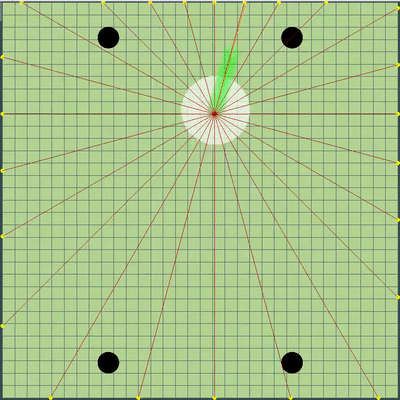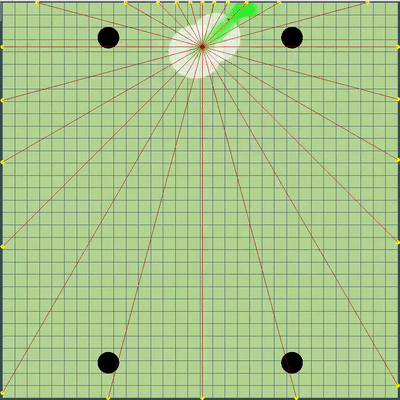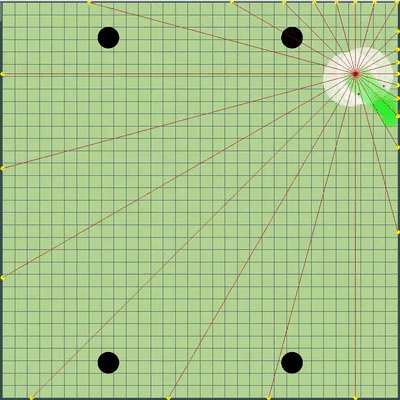 Puntos, el comando de movimiento al que se le dio durante varias simulaciones. Si se mira muy de cerca, el comando final dado a veces se cambia en relación con los puntos que se buscan, pero estas son consecuencias de alteraciones futuras.
Puntos, el comando de movimiento al que se le dio durante varias simulaciones. Si se mira muy de cerca, el comando final dado a veces se cambia en relación con los puntos que se buscan, pero estas son consecuencias de alteraciones futuras. Durante la tarde del viernes y sábado, se agregó una simulación de fusión de agáricos, una simulación de "debilitamiento" en los virus y adivinar el TTF del oponente. El TTF del oponente era un valor calculado bastante interesante, y era posible entender en qué punto el oponente se dividió o llegó al virus solo al atrapar el momento del vuelo no controlado, que podría durar desde un número muy pequeño de ticks con una gran viscosidad y hasta el vuelo a través de todo el mapa. Dado que las colisiones con agárico pueden conducir a un ligero exceso de su velocidad máxima, para calcular el TTF del oponente, verifiqué que su velocidad en dos tics seguidos realmente corresponde a la velocidad con la que se pueden obtener dos ticks seguidos en vuelo libre (en vuelo libre, los agáricos volaron estrictamente rectos y con ralentizando cada tic estrictamente igual a la viscosidad). Esto eliminó casi por completo la posibilidad de falsos positivos. Además, durante la prueba de esta lógica, noté que un TTF más grande siempre corresponde a una identificación más grande del agárico (del que más tarde me convencí al transferir el código de
explosión en el virus y
procesar la división ), que también valía la pena usar.
Después de observar las divisiones constantes en los 3 primeros (lo que les permitió recolectar alimentos significativamente en el mapa), como prueba, agregué un comando de división permanente al bot si no había enemigo en el radio de visibilidad, y el domingo por la mañana encontré a mi bot en la segunda línea de la clasificación. Manejar un puñado de pequeños agáricos aumentó enormemente la clasificación, pero perderlos fue mucho más fácil si te topas con un oponente. Y dado que el miedo a ser comido por mis agáricos era muy condicional (la penalización era solo por comer en una simulación, pero no por acercarse a un oponente que podía comer), lo primero fue agregar una penalización por cruzar con un oponente que podía comer. Y esta misma evaluación funcionó como un bono por perseguir a un oponente. Después de verificar el consumo de CPU con mi estrategia, decidí agregar una ronda de simulación más cuando se realizó la división en el primer tic (esta lógica, por supuesto, también tuvo que transferirse a mi código desde la ubicación del corredor), y luego la simulación fue exactamente la misma que antes . Este tipo de lógica no era muy adecuada para "disparar" al enemigo (aunque a veces por accidente se dividió en un momento muy adecuado), pero fue muy bueno para recolectar alimentos más rápido, que era lo que toda la parte superior estaba haciendo en ese momento. Dichas modificaciones nos permitieron ingresar la próxima semana en la primera línea de la calificación, aunque el margen no fue significativo.
En ese momento, esto fue suficiente, la "columna vertebral" de la estrategia se resolvió, la estrategia parecía bastante primitiva y ampliable. Pero lo que realmente noté fue el consumo de CPU y la estabilidad general del código. Por lo tanto, principalmente las tardes de la siguiente parte de la semana de trabajo se dedicaron a mejorar la precisión de las simulaciones (que el visualizador ayudó mucho), estabilizar el código (valgrind) y algunas optimizaciones de la velocidad del trabajo.
Vamos adelante
Mi siguiente estrategia enviada, que mostró un resultado significativamente mejor y se adelantó a los oponentes (en ese momento), contenía dos cambios significativos: agregar un campo potencial para recolectar alimentos y duplicar el número de simulaciones si hay un oponente con un TTF desconocido cerca.
El campo potencial para recolectar alimentos en la primera versión era bastante simple y toda su esencia era recordar alimentos que desaparecieron de la zona de visibilidad, reduciendo el potencial en aquellos lugares cerca de donde estaba el bot enemigo y reduciendo a cero en mi zona de visibilidad (con la restauración posterior cada n garrapatas de acuerdo con las reglas). Esto parecía una mejora útil, pero en la práctica, en mi opinión subjetiva, la diferencia era pequeña o completamente ausente. Por ejemplo, en tarjetas con alta inercia y velocidad, el bot a menudo saltaba la comida y luego intentaba volver a ella, mientras perdía mucha velocidad. Sin embargo, si decidiera mantener la velocidad y simplemente ignorara la comida omitida, comería mucho más.
Potencial campo de recolección de alimentos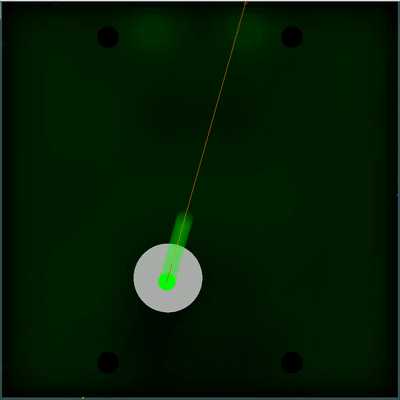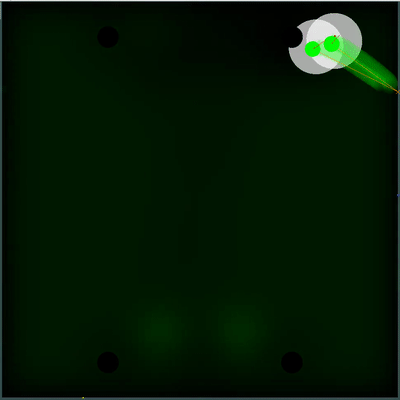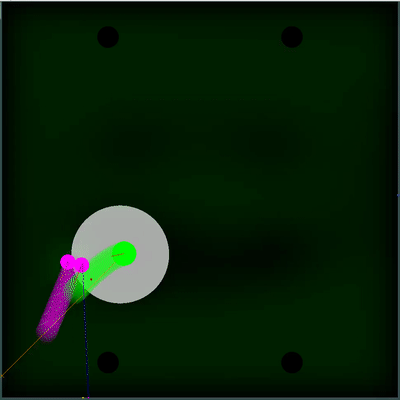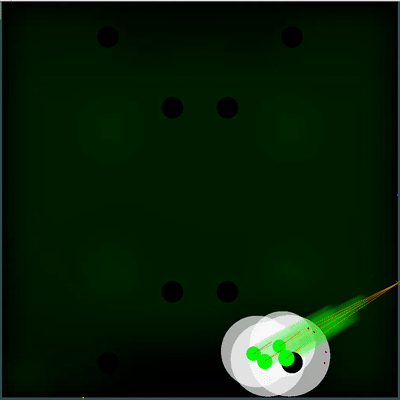 Puede prestar atención a cómo cada 40 tics el campo se vuelve un poco más brillante. Cada 40 ticks, el campo se actualiza de acuerdo con la forma en que se agregan los alimentos en el mapa, y la probabilidad de que aparezcan alimentos es "untada" uniformemente en todo el campo. Si en esta marca vemos que hay comida que veríamos en la marca anterior, la probabilidad de la aparición de esta comida no está "manchada" con el resto, sino que se establece por puntos específicos (la comida aparece cada 40 marcas estrictamente simétricamente).
Puede prestar atención a cómo cada 40 tics el campo se vuelve un poco más brillante. Cada 40 ticks, el campo se actualiza de acuerdo con la forma en que se agregan los alimentos en el mapa, y la probabilidad de que aparezcan alimentos es "untada" uniformemente en todo el campo. Si en esta marca vemos que hay comida que veríamos en la marca anterior, la probabilidad de la aparición de esta comida no está "manchada" con el resto, sino que se establece por puntos específicos (la comida aparece cada 40 marcas estrictamente simétricamente). Una utilidad subjetiva completamente diferente resultó ser una doble simulación del enemigo con diferentes TTF: el mínimo y el máximo posible (en caso de que no conozca el TTF para todos los agáricos visibles en el mapa). Y si antes mi robot pensaba que el grupo enemigo de agáricos se convertiría en un todo y se movería lentamente, entonces ahora eligió el peor de los dos escenarios y no se arriesgó a estar cerca del enemigo, de quien sabe menos de lo que le gustaría.
Después de obtener una ventaja significativa, traté de aumentarla agregando una definición del punto en el que el oponente le indica a sus agáricos que se muevan, y aunque este punto se calculó en la mayoría de los casos con bastante precisión, esto solo no mejoró los resultados del bot. Según mis observaciones, se volvió aún peor que el caso cuando los agáricos del oponente simplemente se movían en la misma dirección y a la misma velocidad que si el oponente no hubiera hecho nada, por lo que estas ediciones se guardaron en una rama de guitarra separada hasta tiempos mejores.
La definición del equipo contrario que se utilizó más tarde Los rayos de los agáricos del oponente muestran al presunto equipo que el oponente le dio a sus agáricos en la marca anterior. Los rayos azules son la dirección exacta en la que el agarik cambió de dirección en el último tic. El negro es el pretendido. Era posible determinar con mayor precisión la dirección del equipo solo si el agar estaba completamente en la zona de nuestra visibilidad (era posible calcular el efecto de las colisiones sobre el cambio en su velocidad). La intersección de los rayos es el equipo previsto del oponente. Gif hecho sobre la base del juego aicups.ru/session/200710 , alrededor de 3.000 ticks.
Los rayos de los agáricos del oponente muestran al presunto equipo que el oponente le dio a sus agáricos en la marca anterior. Los rayos azules son la dirección exacta en la que el agarik cambió de dirección en el último tic. El negro es el pretendido. Era posible determinar con mayor precisión la dirección del equipo solo si el agar estaba completamente en la zona de nuestra visibilidad (era posible calcular el efecto de las colisiones sobre el cambio en su velocidad). La intersección de los rayos es el equipo previsto del oponente. Gif hecho sobre la base del juego aicups.ru/session/200710 , alrededor de 3.000 ticks. También hubo intentos de transferir la función de evaluación a la evaluación de la masa ganada, intentos de cambiar la función de evaluar el peligro del oponente ... Pero nuevamente, todos esos cambios en los sentimientos empeoraron aún más. Lo único que fue útil con la función de evaluar el peligro de estar cerca del enemigo fue otra optimización del rendimiento junto con extender esta estimación a un radio mucho mayor que el radio de intersección con el enemigo (esencialmente todo el mapa, pero con una disminución cuadrática, si se simplifica ligeramente) hacer presencia en cinco o más radios del oponente en la región de 1/25 del peligro máximo de ser comido). El último cambio también no planificado condujo al hecho de que mis agariks tenían mucho miedo de acercarse a un enemigo significativamente más grande, así como en el caso de sus tamaños muy superiores, estaban más inclinados a moverse hacia el oponente. Por lo tanto, resultó ser un reemplazo exitoso y no intensivo en recursos para el código planeado para el futuro, que se suponía que era responsable del miedo a un ataque de un oponente a través de la división (y un poco de ayuda en tal ataque para mí más adelante).
Después de intentos largos y relativamente infructuosos de mejorar algo, volví a predecir la dirección del movimiento del oponente. Decidí probarlo si no es solo para reemplazar a los rivales ficticios, luego hice lo que hice con la opción TTF mínima y máxima: simule dos veces y elija la mejor. Pero para esto, la CPU podría no ser suficiente, y en muchos juegos de mi bot simplemente podrían desconectarse del sistema debido a un apetito insaciable. Por lo tanto, antes de implementar esta opción, agregué una definición aproximada del tiempo empleado y, si se excedían los límites, comencé a reducir el número de movimientos de simulación. Al agregar una doble simulación del enemigo para el caso cuando conozco el lugar al que se dirige, nuevamente recibí un aumento bastante serio en la mayoría de los ajustes del juego, excepto en el que requiere más recursos (con alta inercia / baja velocidad / baja viscosidad), que debido a una fuerte disminución en la profundidad Las simulaciones podrían empeorar aún más.
Antes del comienzo de los 25k juegos de tick, se hicieron dos mejoras más útiles: la penalización por terminar la simulación lejos del centro del mapa, así como recordar la posición anterior del oponente si dejaba la línea de visión (además de simular su movimiento en ese momento).
La implementación de la penalización para la posición final del bot en la simulación fue un campo de peligro estático precalculado con cero peligro en un radio ligeramente mayor que la mitad de la longitud del campo de juego y aumentando gradualmente a medida que te alejas del campo de juego. La aplicación de la multa de este campo en los puntos finales de la simulación casi no requirió una CPU y evitó carreras adicionales en las esquinas, a veces salvando al enemigo de los ataques. Y la memorización con simulación posterior de rivales en su mayor parte nos permitió evitar dos problemas a veces manifestados. El primer problema se presenta en el GIF a continuación. El segundo problema era que si un enemigo más grande se perdía del campo de visión (por ejemplo, después de la fusión de sus partes), era posible unirse "exitosamente" en él, alimentando además a un oponente ya peligroso.Ejemplo de un campo de peligro al final de un giro en una esquina y garrapatas desperdiciadas ,
,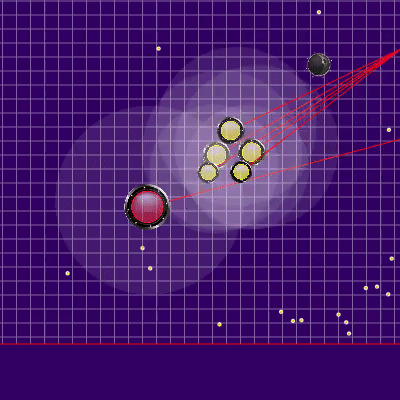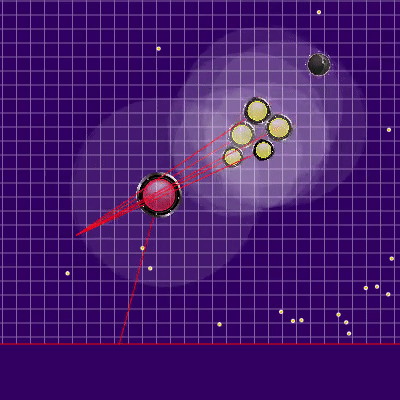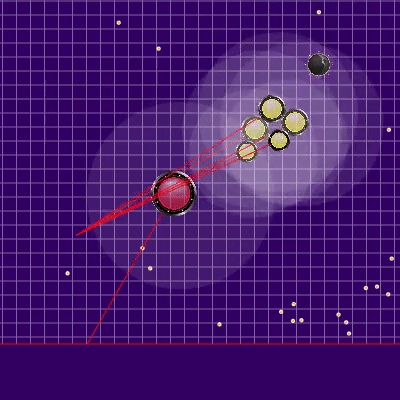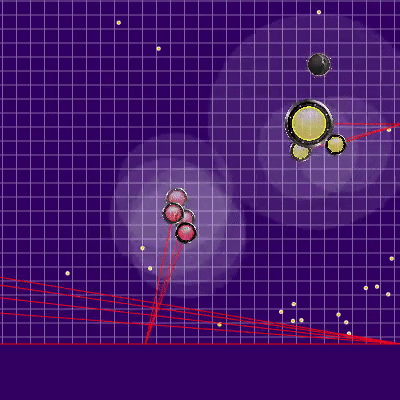 , . , .
, . , . Además, se agregaron puntos de simulación de movimiento a los puntos en el borde del mapa: a cada agarik de rivales y dentro de un radio de la coordenada media aritmética de mi agariki cada 45 grados. El radio se estableció en avgDistance de las coordenadas medias aritméticas de mis agáricos.Nuevos puntos de simulación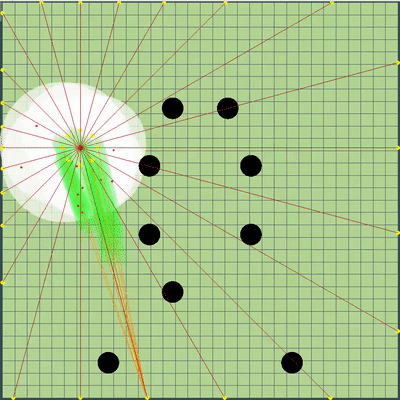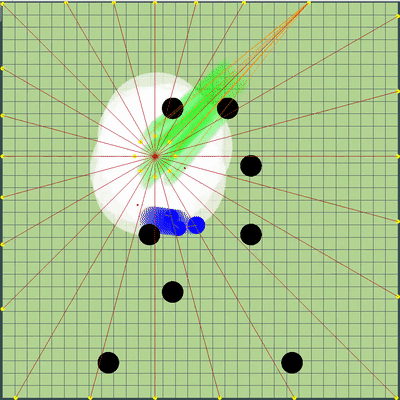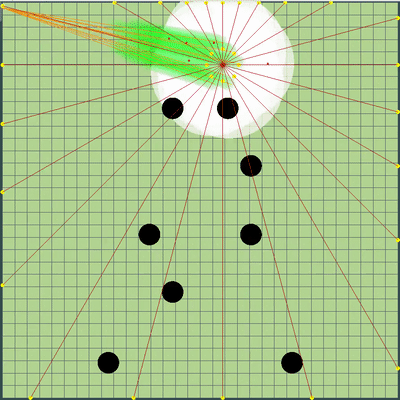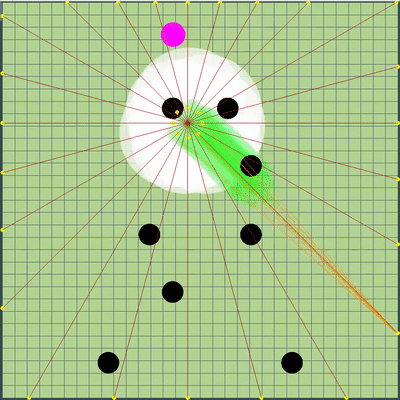 . «» , . .
. «» , . . Preparación final
En el momento de la apertura de los juegos para 25k ticks y pasar a la final, tenía un margen sólido, pero no planeaba relajarme.Junto con los nuevos juegos de 25k, llegaron las noticias: los juegos durante la final también durarán 25k, y el límite de tiempo de la estrategia para los ticks se ha vuelto un poco más. Después de evaluar el tiempo que mi estrategia pasa en el juego en las nuevas condiciones, decidí agregar otra versión de la simulación: hacemos todo como de costumbre, pero durante la simulación en el momento se dividen. Esto, entre otras cosas, requería el uso de la simulación encontrada en el paso anterior, pero con un cambio de 1 movimiento (por ejemplo, si encontramos que dividir 7 tics del actual, entonces el próximo movimiento repetimos lo mismo, pero ya haremos la división en el sexto movimiento). Esto agregó significativamente ataques agresivos a los rivales, pero se comió un poco más de tiempo de estrategia.Debería haber una descripción concisa del algoritmo:
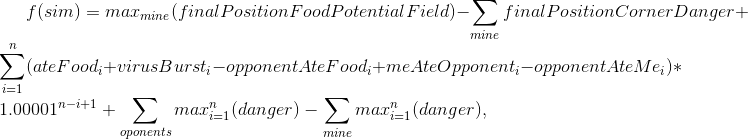
- f — , ;
- sim — ( , , TTF , );
- finalPositionFoodPotentialField — , , ;
- finalPositionCornerDanger — . , ;
- n — , . 10 50 ;
- ateFood — i;
- virusBurst — i;
- opponentAteFood — i;
- meAteOpponent — ;
- opponentAteMe — ;
- mine/opponents — . Es decir — ;
- danger — , , .
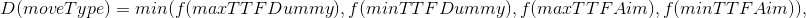
- moveType — , ;
- max/min TTF — , TTF ( TTF );
- dummy/aim — Dummy ( , ).
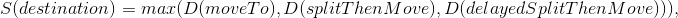
- destination — , ;
- moveTo — , n “ ” ;
- splitThenMove — split ;
- delayedSplitThenMove — , split .
1 . Es decir splitThenMove moveTo, delayedSplitThenMove 7 6 , 6 5 .. , — 7 . .
destination :
- 15 ( — ). 24 ;
- , ( );
- :
- “” , ;
- 8 . .
destination , .
Todas las mejoras adicionales se relacionaron exclusivamente con la eficiencia de las simulaciones en caso de falta de TL: optimización de la secuencia de desconexión de ciertas partes de la lógica dependiendo de la CPU consumida. En la mayoría de los juegos, se suponía que esto no cambiaría nada, pero llegar a algo más correcto no funcionó.Puntos finales en la final. 808 2424 , . .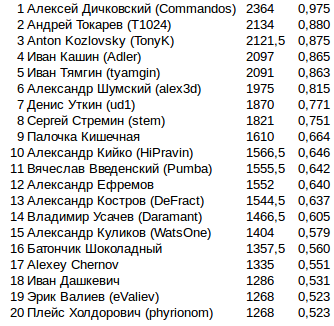
En lugar de una conclusión
En general, el comienzo de esta competencia resultó bastante aceitado, pero en la primera semana y media la tarea se llevó a una forma bastante jugable con la ayuda de los participantes. Inicialmente, la tarea era muy variable, y elegir el enfoque correcto para resolverlo no parecía una tarea trivial. Aún más interesante fue encontrar formas de mejorar el algoritmo sin volar más allá de los límites del consumo de CPU. Muchas gracias a los organizadores por la competencia y por presentar los códigos fuente del mundo para acceso abierto. Este último, por supuesto, les agregó problemas al principio, pero facilitó enormemente (si no es que lo dijo, lo que hizo posible en principio) que los participantes comprendieran el dispositivo del simulador mundial. ¡Un agradecimiento especial por la oportunidad de elegir un premio! Entonces el premio salió mucho más útil :-) ¿Por qué necesito otro MacBook?