
Hoy en KDD 2018 es un día de seminario, junto con una gran conferencia que comienza mañana, varios grupos reunieron a los oyentes sobre algunos temas específicos. He estado en dos de esos partidos.
Análisis de series de tiempo
Por la mañana quería ir a un seminario sobre análisis
gráfico , pero estuvo detenido durante 45 minutos, así que cambié al siguiente, sobre análisis de series de tiempo. De repente, una
profesora rubia de California abre el seminario con el tema "Inteligencia artificial en medicina". Extraño, porque para esto hay una pista separada en la habitación de al lado. Entonces resulta que ella tiene varios estudiantes graduados que hablarán sobre series de tiempo aquí. Pero, en realidad, al punto.
Inteligencia Artificial en Medicina
Los errores médicos son la causa del 10% de las muertes en los EE. UU., Esta es una de las tres causas principales de muerte en el país. El problema es que no hay suficientes médicos; los que están sobrecargados, y las computadoras tienen más probabilidades de crear problemas para los médicos de lo que pueden resolver, al menos los médicos lo hacen. Sin embargo, la mayoría de los datos no se utilizan realmente para la toma de decisiones. Todo esto debe ser combatido. Por ejemplo, una bacteria,
Clostridium difficile, es altamente virulenta y resistente a los medicamentos. Durante el año pasado, ella ha infligido $ 4 mil millones en daños. Tratemos de evaluar el riesgo de infección en función de la serie temporal de registros médicos. A diferencia de los trabajos anteriores, tomamos muchos signos (vector de 10k para cada día) y construiremos modelos individuales para cada hospital (de muchas maneras, aparentemente, una medida necesaria, ya que todos los hospitales tienen su propio conjunto de datos). Como resultado, obtenemos una precisión de aproximadamente 0,82 AUC con una predicción de riesgo de CDI después de 5 días.
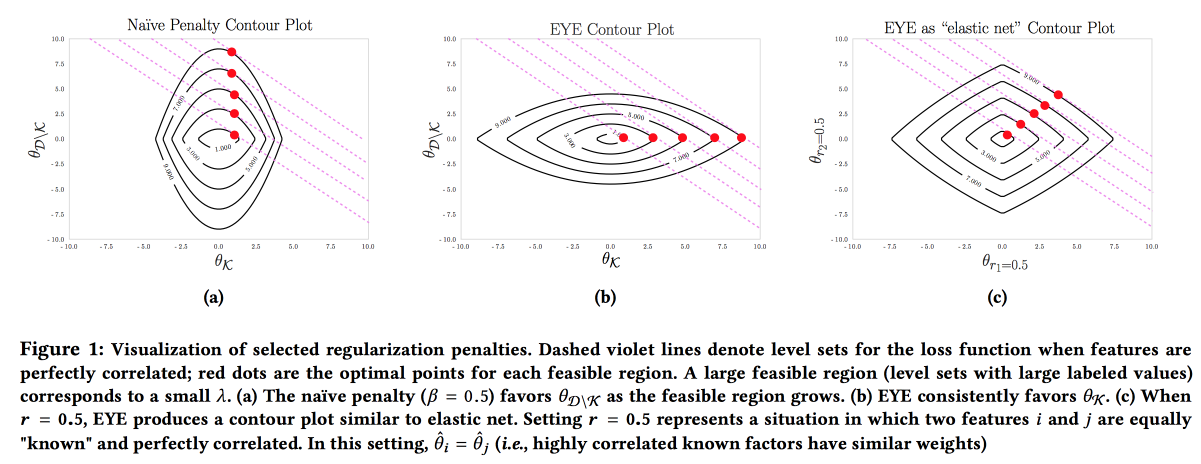
Es importante que el modelo sea preciso, interpretable y robusto; debemos mostrar lo que podemos hacer para prevenir la enfermedad. Dicho modelo se puede construir utilizando activamente el conocimiento del área temática. Es el deseo de interpretabilidad lo que a menudo reduce la cantidad de características y conduce a la creación de modelos simples. Pero incluso un modelo simple con un gran espacio de características pierde la capacidad de interpretación, y el uso de la regularización L1 a menudo conduce al hecho de que el modelo selecciona aleatoriamente una de las características colineales. Como resultado, los médicos no creen en el modelo, a pesar de un buen AUC. Los autores proponen usar un tipo diferente de regularización
EYE (estimación de rendimiento experta). Dado que existen datos conocidos sobre el efecto en el resultado, resulta que el modelo se centra en las características necesarias. Da buenos resultados, incluso si el experto la fastidió, además, al comparar la calidad con las regularizaciones estándar, puede evaluar cuánto tiene razón el experto.
A continuación, procedemos al análisis de series de tiempo. Resulta que para mejorar la calidad en ellos es importante buscar invariantes (de hecho, conducir a alguna forma canónica). En un
artículo reciente, un grupo de profesores propuso un enfoque basado en dos redes convolucionales. El primero, Sequence Transformer, lleva la serie a una forma canónica, y el segundo, Sequence Decoder, resuelve el problema de clasificación.
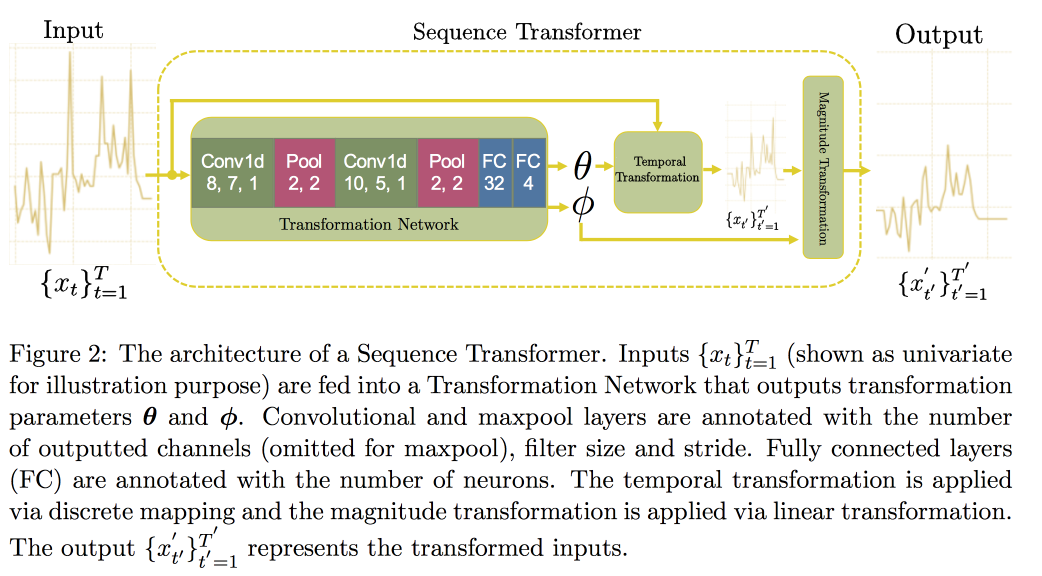
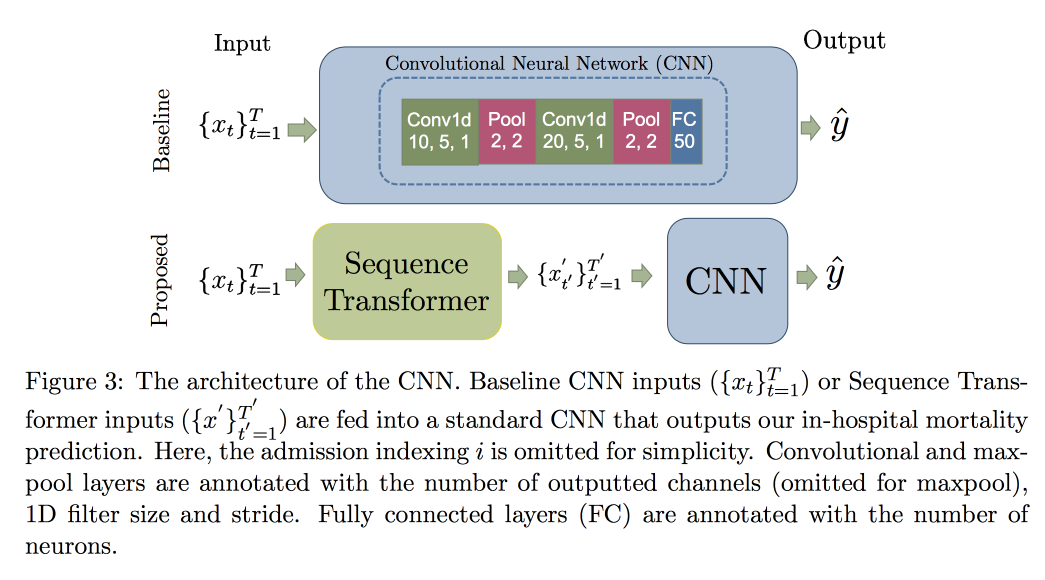
El uso de CNN, en lugar de RNN, se explica por el hecho de que funcionan con filas de longitud fija. Comprobado en el
conjunto de datos MIMIC, trató de predecir la muerte en el hospital dentro de las 48 horas. El resultado fue una mejora de 0.02 AUC en comparación con CNN simple con capas adicionales, pero los intervalos de confianza se superponen.
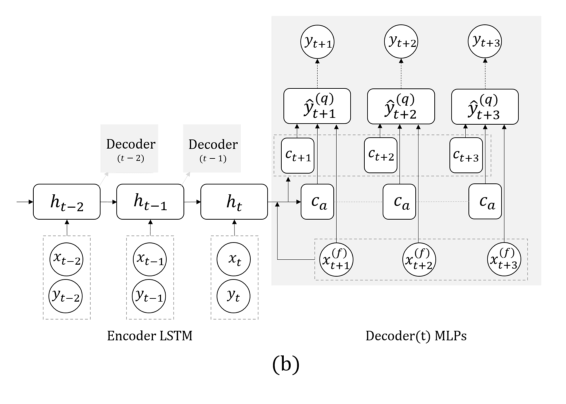
Ahora otra tarea: pronosticaremos únicamente sobre la base de la serie real, sin señales externas (que comieron, etc.). Aquí, el equipo propuso reemplazar el RNN para predecir algunos pasos adelante con una cuadrícula con varias salidas, sin recurrencia entre ellos. La explicación de esta solución es que no se acumula un error durante la recursividad. Combina esta técnica con la anterior (busca invariantes). Inmediatamente después de la presentación del profesor, el postdoc habló en detalle sobre este modelo, así que aquí terminamos, señalando solo que al validar es importante observar no solo el error general, sino también la clasificación de errores de casos peligrosos de glucosa demasiado alta o baja.
Lancé una pregunta sobre la retroalimentación del modelo: si bien esta es una pregunta abierta, dicen que deberíamos tratar de comprender qué cambios en la distribución de los síntomas ocurren como resultado del hecho de la intervención y cuáles son los cambios naturales causados por factores externos. En realidad, la presencia de tales cambios complica enormemente la situación: es imposible volver a entrenar el modelo, ya que la calidad es degradante, mezclar al azar (no tratar a alguien y verificar si morirá) no es ético, pero aprender de los datos donde todos fueron tratados de acuerdo con la recomendación del modelo está garantizado sesgo ...
Generación de ruta de muestra
Un ejemplo de cómo no hacer presentaciones: muy rápido, difícil de escuchar y captar la idea es casi imposible. El trabajo en sí está disponible
aquí .
Los muchachos desarrollan su resultado de pronóstico anterior varios pasos adelante. Hay dos ideas principales en el trabajo anterior: en lugar de RNN, use una red con varias salidas para diferentes puntos en el tiempo, más en lugar de números específicos, tratamos de predecir distribuciones y evaluar cuantiles. Todo esto se llama
MQ-RNN / CNN (Multi-Horizont Forecasting Quantil regression).
Esta vez tratamos de refinar el pronóstico mediante el procesamiento posterior. Considerado dos enfoques. Como parte de la primera, estamos tratando de "calibrar" la distribución de la red neuronal utilizando datos posteriores y aprendiendo la matriz de covarianza de salidas y observaciones, la llamada contracción de covarianza. El método es bastante simple y funciona, pero quiero más. El segundo enfoque fue utilizar modelos generativos para construir una "muestra de ruta": utilizan el enfoque generativo para el pronóstico (GAN, VAE). Se obtuvieron resultados buenos pero inestables con la ayuda de
WaveNet, desarrollado para la
generación de sonido.
Graficar redes estructuradas
Un trabajo interesante sobre la transferencia del "conocimiento del área temática" en la red neuronal. Mostraron el ejemplo de predecir el nivel de delincuencia en el espacio (por regiones de la ciudad) y el tiempo (por días y horas). La principal dificultad: fuertes datos escasos y la presencia de eventos locales raros. Como resultado, muchos métodos no funcionan bien, en promedio todavía es posible adivinar a diario, pero no para áreas y horas específicas. Intentemos combinar una estructura de alto nivel y micropatrones en una red neuronal.
Construimos un gráfico de comunicación usando códigos postales y determinamos la influencia de uno sobre el otro usando el
Proceso de Hawkes Multivariante . Luego, sobre la base del gráfico obtenido, construimos la topología de la red neuronal, vinculando los bloques de las regiones de la ciudad con un crimen que mostró una correlación.
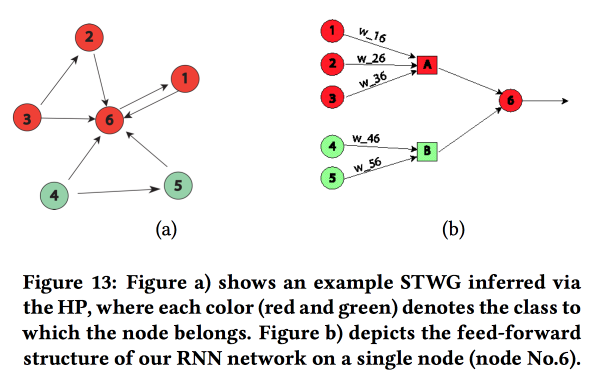
Comparamos este enfoque con otros dos: la capacitación en una cuadrícula para un distrito o en una cuadrícula para un grupo de regiones con una tasa de criminalidad similar, mostró un aumento en la precisión. Para cada región, se introduce un LSTM de dos capas con dos capas completamente conectadas.
Además de los delitos, también mostraron ejemplos de trabajo sobre predicción de tráfico. Aquí, el gráfico para construir una red ya está tomado geográficamente por kNN. No está del todo claro cuánto se pueden comparar sus resultados con otros (cambiaron libremente las métricas en el análisis), pero en general, la heurística para construir una red parece adecuada.
Enfoque no paramétrico para el pronóstico de conjunto
Los conjuntos son un tema muy popular, pero no siempre es obvio cómo derivar el resultado de pronósticos individuales. En su trabajo, los autores proponen un
nuevo enfoque .
A menudo, los conjuntos simples funcionan bien, incluso mejor. que el nuevo
modelo bayesiano promediando y promediando-NN. La regresión tampoco es mala, pero a menudo da resultados extraños en términos de elegir pesos (por ejemplo, dará a algunos pronósticos un peso negativo, etc.). De hecho, la razón de esto a menudo radica en el hecho de que el método de agregación utiliza algunas suposiciones sobre cómo se distribuye el error de pronóstico (por ejemplo, de acuerdo con Gauss o normal), pero cuando se usa, se olvidan de verificar esta suposición. Los autores intentaron proponer un enfoque libre de suposiciones.
Consideramos dos procesos aleatorios: el Proceso de generación de datos (DGP) modela la realidad y puede depender del tiempo, y el Proceso de generación de pronósticos (FGP) modela la construcción de pronósticos (hay muchos de ellos, uno por miembro del conjunto). La diferencia entre estos dos procesos también es un proceso aleatorio, que trataremos de analizar.
- Recopilamos datos históricos y construimos la densidad de distribución de errores para los predictores usando la Estimación de densidad del núcleo.
- Luego, construimos un pronóstico y lo convertimos en una variable aleatoria agregando el error construido.
- Luego resolvemos el problema de maximizar la probabilidad.
El método resultante es casi como EMOS (Ensemble Model Output Statistics) con un error gaussiano y mucho mejor con no gaussiano. A menudo, en realidad, por ejemplo, (
Wikipedia Page Traffic Dataset ) es un error no gaussiano.
LSTM anidado: modelado de taxonomía y dinámica temporal en redes sociales basadas en la ubicación
El trabajo es presentado por autores de Google. Estamos tratando de predecir la próxima verificación de usuario. utilizando su historia de chekins recientes y metadatos de lugares, en primer lugar, su relación con etiquetas / categorías. Las categorías son de tres niveles, utilizamos los dos niveles superiores: la categoría principal describe la intención del usuario (por ejemplo, el deseo de comer) y la categoría secundaria describe las preferencias del usuario (por ejemplo, al usuario le gusta la comida española). Se debe mostrar que la categoría subsidiaria del próximo cheque obtiene más ingresos de la publicidad en línea.
Utilizamos dos LSTM anidados: el superior, como de costumbre, según la secuencia de controles, y el anidado, según las transiciones en el árbol de categorías de padre a hijo.
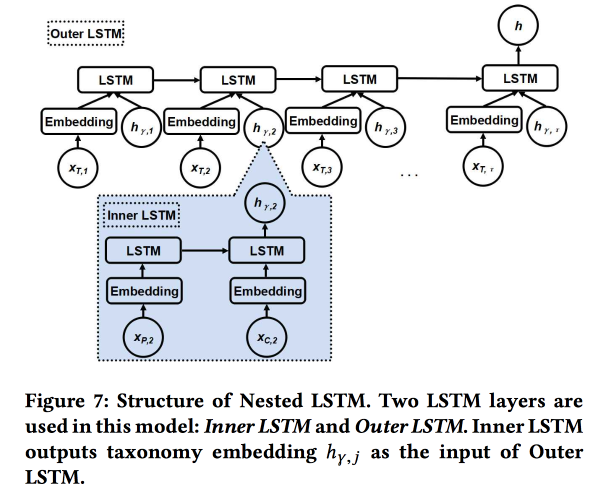
Resulta 5-7% mejor en comparación con LSTM simple con incrustaciones de categoría sin procesar. Además, demostramos que las uniones de transición LSTM en el árbol de categorías se ven más hermosas que las simples y están mejor agrupadas.
Identificando cambios en el espacio semántico evolutivo
Discurso bastante alegre del
profesor chino . La conclusión es tratar de entender cómo las palabras cambian su significado.
Ahora todo el mundo está entrenando con éxito la inserción de palabras, funcionan bien, pero estar capacitado en diferentes momentos no es adecuado para la comparación: debe hacer alianzas.
- Puede tomar el viejo para la inicialización, pero esto no ofrece garantías.
- Puede aprender la función de transformación para alinear, pero no siempre funciona, ya que las dimensiones no siempre se comparten por igual.
- ¡Y puedes usar topología, no espacio vectorial!
Al final, la esencia de la solución: construimos un gráfico knNN en los vecinos de la palabra en diferentes períodos para evaluar el cambio de significado y tratar de entender si hay un cambio significativo. Para esto utilizamos el modelo
Bayesian Surprise . De hecho, nos fijamos en la
divergencia KL de la distribución de una hipótesis (anterior) y una hipótesis sujeta a observaciones (posterior); esto es una sorpresa. Con palabras y gráficos cnn, usamos Dirichlet en función de las frecuencias de vecinos en el pasado como una distribución a priori y lo comparamos con el multinomio real en la historia reciente. Total:
- Cortamos la historia.
- Construimos empotramientos (LINE con preservación de inicialización).
- Consideramos KNN en los embebidos.
- Agradezco la sorpresa.
Validamos tomando dos palabras aleatorias con la misma frecuencia e intercambiando entre sí: el aumento de la calidad como sorpresa es del 80%. Luego tomamos 21 palabras con derivaciones de significado conocidas y vemos si podemos encontrarlas automáticamente. Las fuentes abiertas aún no tienen una descripción detallada de este enfoque, pero
hay una en SIGIR 2018 .
AdKDD y TargetAd
Después del almuerzo, me mudé a un seminario sobre publicidad en línea. Hay muchos más oradores de la industria y todos están pensando en cómo ganar más dinero.
Tecnología publicitaria en airbnb
Al ser una gran empresa con un gran equipo de DS, AirBnB invierte bastante en promocionarse correctamente y sus ofertas internas en sitios externos. Uno de los desarrolladores habló un poco sobre los desafíos.
Comencemos con la publicidad en un motor de búsqueda: al buscar hoteles en Google, las dos primeras páginas son publicidad :(. Pero el usuario a menudo ni siquiera entiende esto, porque la publicidad es muy relevante. Esquema estándar: hacemos coincidir las solicitudes de publicidad por palabras clave y obtenemos el significado del patrón / patrón ( ciudad, barata o de lujo, etc.)
Después de seleccionar a los candidatos, organizamos una subasta entre ellos (ahora el
segundo precio generalizado se usa en todas partes). Al participar en la subasta, el objetivo es maximizar el efecto en un presupuesto fijo, utilizando un modelo con una combinación de la probabilidad de un clic y los ingresos: Oferta = P (clic | consulta de búsqueda) * valor de reserva. Un punto importante: no gaste todo el dinero demasiado rápido, así que agregue Spend pacer.
AirBnB tiene un poderoso sistema para pruebas A / B, pero no se puede aplicar aquí, ya que controla la mayor parte del proceso de Google. Allí prometieron agregar más herramientas para los anunciantes, los grandes jugadores realmente están ansiosos.
Problema separado: contacto del usuario con publicidad en varios lugares. Viajamos en promedio un par de veces al año, el ciclo de preparación de un viaje y reserva es muy largo (semanas e incluso meses), hay varios canales en los que podemos llegar al usuario y necesitamos dividir el presupuesto por canal. Este tema es muy doloroso, existen métodos simples (linealmente, con cuidado, por el último clic o por los resultados de la
prueba de levantamiento ). AirBnB probó dos nuevos enfoques: basados en los modelos de Markov y
el modelo de Shapley .
Con el modelo de Markov, todo está más o menos claro: estamos construyendo una cadena discreta, los nodos en los que corresponden a los puntos de contacto con la publicidad, también hay un nodo para la conversión. De acuerdo con los datos, seleccionamos pesos para las transiciones, otorgamos más presupuesto a los nodos donde la probabilidad de transición es mayor. Les hice una pregunta: ¿por qué usar una cadena de Markov simple, mientras que es más lógico usar MDP? Dijeron que están trabajando en este tema.
Más interesante con Shapley: de hecho, este es un esquema conocido desde hace mucho tiempo para evaluar el efecto aditivo, en el que se consideran diferentes combinaciones de efectos, se evalúa el efecto de cada uno de ellos y luego se determina un agregado para cada efecto individual. La dificultad es que puede haber sinergia entre los efectos (con menos frecuencia antagonismo), y el resultado de la suma no es igual a la suma de los resultados. En general, una teoría bastante interesante y hermosa, le
aconsejo que lea .
En el caso de AirBnB, la aplicación del modelo Shapley se parece a esto:
- Tenemos en los datos observados ejemplos con diferentes combinaciones de efectos y el resultado real.
- Rellene los vacíos en los datos (no se presentan todas las combinaciones) usando ML.
- Calculamos el préstamo para cada tipo de impacto de Shapley.
Microsoft: empujando los límites de {AI}
Un poco más sobre eso. ya que Microsoft se dedica a la publicidad, ahora desde el lado del sitio, principalmente Bing. Un poco de matanza:
- El mercado publicitario está creciendo muy rápidamente (exponencialmente).
- La publicidad en una página se canibaliza entre sí, debe analizar toda la página.
- La conversión en algunas páginas es mayor, a pesar de que el CTP es peor.
Hay alrededor de 70 modelos en el motor de publicidad Bing, 2000 experimentos fuera de línea, 400 en línea. Un cambio significativo en la plataforma cada semana. En general, trabajan incansablemente. ¿Cuáles son los cambios en la plataforma?
- El mito de una métrica: no funciona de esa manera, las métricas crecen y compiten.
- Rediseñamos el sistema de solicitudes de correspondencia publicitaria de PNL a DL, que se calcula en FPGA.
- Utilizan modelos federales y bandidos contextuales: los modelos internos producen probabilidad e incertidumbre, el bandido de arriba toma una decisión. Ella habló mucho sobre bandidos, se utilizan para lanzar modelos y lanzar a velocidad de crucero, eluden el hecho de que a menudo mejorar el modelo conduce a menores ingresos :(
- Es muy importante evaluar la incertidumbre (bueno, sí, sin ella no se puede construir un bandido).
- Para los pequeños anunciantes, la institución de la publicidad a través de bandidos no funciona, hay pocas estadísticas, es necesario hacer modelos separados para un arranque en frío.
- Es importante monitorear el rendimiento en diferentes cohortes de usuarios, ya que tienen un sistema automático para cortar según los resultados del experimento.
Hablamos un poco sobre el análisis de flujo de salida. No siempre las hipótesis de los vendedores sobre las causas del flujo de salida son verdaderas, debe profundizar más. Para hacer esto, debe construir modelos interpretables (o un modelo especial para explicar los pronósticos) y pensar mucho. Y luego haz los experimentos. Pero siempre es difícil hacer experimentos con el flujo de salida, recomiendan usar métricas de segundo orden y
un artículo de Google .
También usan algo como el Gráfico de conocimiento comercial, que describe el área temática: marcas, productos, etc. El gráfico se construye de forma totalmente automática, sin supervisión. Las marcas están marcadas con categorías, esto es importante, ya que en general no siempre es posible sin supervisión aislar la marca en su conjunto, pero dentro de un determinado tema de categoría la señal es más fuerte. Desafortunadamente, no encontré trabajos abiertos por su método.
Anuncios de Google
El mismo tipo que ayer habló sobre los conteos dice que todo es igual de triste y arrogante. Caminamos sobre varios temas.
Primera parte: Asignación robusta de anuncios estocásticos. Tenemos nodos presupuestados (anuncios) y nodos en línea (usuarios), y también hay algunos pesos entre ellos. Ahora debe elegir qué anuncios mostrar el nuevo nodo. Puede hacerlo con avidez (siempre por el peso máximo), pero luego corremos el riesgo de elaborar un presupuesto prematuramente y obtener una solución ineficaz (el límite teórico es la mitad del óptimo). Puede lidiar con esto de diferentes maneras, de hecho, aquí tenemos un conflicto tradicional entre revenu y wellfair.
Al elegir el método de asignación, se puede asumir un orden aleatorio de aparición de nodos en línea de acuerdo con alguna distribución, pero en la práctica también puede haber un orden de confrontación (es decir, con elementos de algún efecto opuesto). Los métodos en estos casos son diferentes, proporcionan enlaces a sus últimos artículos:
1 y
2 .
Segunda parte: Aprendizaje consciente de la percepción / fijación de precios robusta. Ahora estamos tratando de resolver la cuestión de elegir el precio de reserva para aumentar los ingresos de los sitios publicitarios. También consideramos el uso de otras subastas como la
subasta de Myerson ,
BINTAC , la reversión a la subasta del primer precio en caso de contacto con la reserva. No entran en detalles, envían a
su artículo .
Tercera parte: agrupación en línea. Nuevamente, resolvemos el problema de aumentar los ingresos, pero ahora pasamos del otro lado. Si pudiera comprar anuncios a granel (agrupación sin conexión), en muchas situaciones puede ofrecer una solución más óptima. Pero no puede hacer esto en una subasta en línea, necesita construir modelos complejos con memoria, y en condiciones difíciles RTB no lo empuja.
Luego aparece un modelo mágico, donde toda la memoria se reduce a un dígito (cuenta bancaria), pero el tiempo se acaba y el orador comienza a pasar frenéticamente por las diapositivas. , ,
.
Deep Policy optimization by Alibaba
«sponsored search». RL, — .
.
offline- , , online-, .
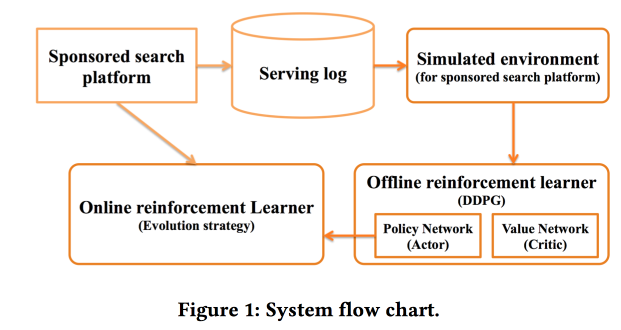
CTR ,
DDPG .
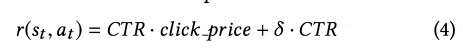
- , « »:
Criteo Large Scale Benchmark for Uplift Modeling
( ). Criteo
Criteo-UPLIFT1 (450 ) .
. -, , ( ). — (, ).
? . - , — , (AUUC).
Qini- (
Gini ), Qini, .
. : , . .
revert label. , , , , ; . , , .
, . .
Deep Net with Attention for Multi-Touch Attribution
, ,
Adobe . , , ! , attention- LSTM, . LSTM- .
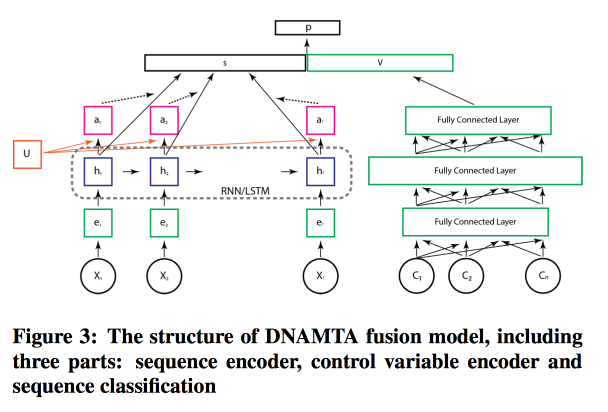
, attention- .
Conclusión
Luego hubo la sesión de apertura de pathos con un video IMAX en la mejor tradición de trailers exitosos, muchas gracias a todos los que ayudaron a organizar todo esto: un KDD récord en todos los aspectos (incluido el patrocinio de $ 1.2 millones), palabras de despedida de Lord Bytes (Ministro de Innovación Reino Unido) y una sesión de póster para la que ya no hay fuerza. Debemos prepararnos para mañana.