Se cree que el desarrollo lleva aproximadamente el 10% del tiempo, y la depuración lleva el 90%. Quizás esta afirmación es exagerada, pero cualquier desarrollador estará de acuerdo en que la depuración es un proceso extremadamente intensivo en recursos, especialmente en sistemas grandes de subprocesos múltiples.
Por lo tanto, la optimización y sistematización del proceso de depuración puede traer beneficios significativos en forma de horas hombre ahorradas, aumentando la velocidad de resolución de problemas y, en última instancia, aumentando la lealtad de sus usuarios.
 Sergey Shchegrikovich
Sergey Shchegrikovich (dotmailer) en la conferencia
DotNext 2018 Piter sugirió considerar la depuración como un proceso que se puede describir y optimizar. Si todavía no tiene un plan claro para encontrar errores, debajo del video cortado y la transcripción del texto del informe de Sergey.
(Y al final de la publicación, agregamos
el atractivo de
John Skeet a todos los afiliados, asegúrese de mirar)
Mi objetivo es responder a la pregunta: cómo solucionar errores de manera eficiente y cuál debería ser el enfoque. Creo que la respuesta a esta pregunta es un proceso. El proceso de depuración, que consiste en reglas muy simples, y las conoce bien, pero probablemente las use sin saberlo. Por lo tanto, mi tarea es sistematizarlos y mostrar cómo ser más efectivos usando un ejemplo.
Desarrollaremos un lenguaje común para la comunicación durante la depuración, y también veremos un camino directo para encontrar los principales problemas. En mis ejemplos, mostraré lo que sucedió debido a una violación de estas reglas.
Utilidades de depuración
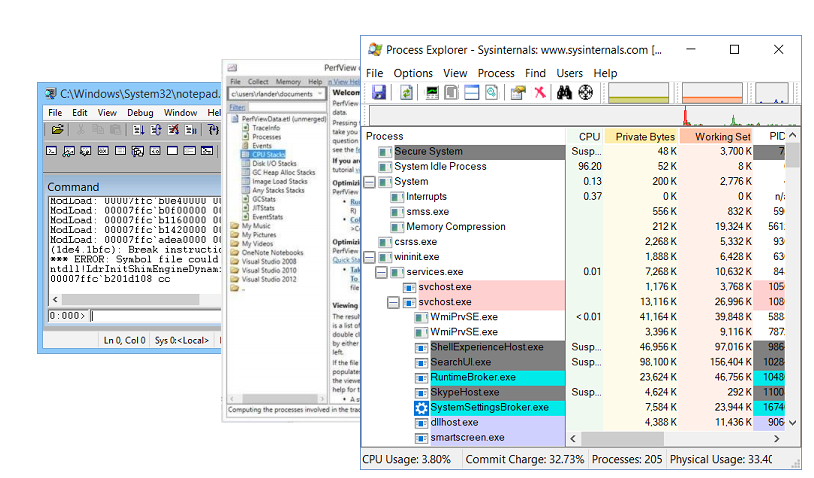
Por supuesto, cualquier depuración no es posible sin las utilidades de depuración. Mis favoritos son:
- Windbg , que además del depurador en sí, tiene una rica funcionalidad para estudiar volcados de memoria. Un volcado de memoria es una porción del estado de un proceso. En él puede encontrar el valor de los campos de los objetos, las pilas de llamadas, pero, desafortunadamente, el volcado de memoria es estático.
- PerfView es un generador de perfiles escrito sobre la tecnología ETW .
- Sysinternals es una utilidad escrita por Mark Russinovich , que le permite profundizar un poco más en el dispositivo del sistema operativo.
Servicio que cae
Comencemos con un ejemplo de mi vida en el que mostraré cómo la naturaleza no sistemática del proceso de depuración conduce a la ineficiencia.
Probablemente, esto les sucedió a todos, cuando vienes a una nueva empresa en un nuevo equipo para un nuevo proyecto, desde el primer día que quieres obtener beneficios irreparables. Así fue conmigo. En ese momento, teníamos un servicio que recibía html para entrada y salida de imágenes para salida.
El servicio fue escrito bajo .Net 3.0 y fue hace mucho tiempo. Este servicio tenía una pequeña característica: se bloqueó. Cayó a menudo, aproximadamente una vez cada dos o tres horas. Arreglamos esto elegantemente: establezca las propiedades de reinicio en las propiedades del servicio después de la caída.
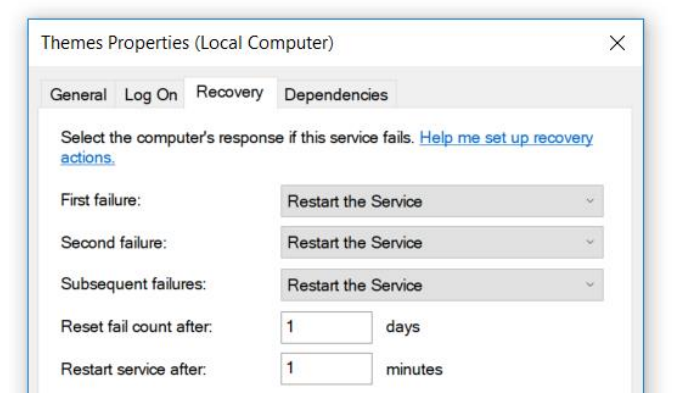
El servicio no fue crítico para nosotros y pudimos sobrevivir. Pero me uní al proyecto y lo primero que decidí hacer fue arreglarlo.
¿A dónde van los desarrolladores de .NET si algo no funciona? Ellos van a EventViewer. Pero allí no encontré nada excepto el registro de que el servicio cayó. No hubo mensajes sobre el error nativo, ni una pila de llamadas.
Hay una herramienta probada para saber qué hacer a continuación: envolvemos todo el
main en
try-catch .
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); }
La idea es simple:
try-catch funcionará, nos molestará, lo leeremos y arreglaremos el servicio. Compilamos, implementamos en producción, el servicio se bloquea, no hay error. Agrega otra
catch .
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); } catch { LogError(); }
Repetimos el proceso: el servicio se bloquea, no hay errores en los registros. Lo último que puede ayudar es
finally , que siempre se llama.
try { ProcessRequest(); } catch (Exception ex) { LogError(ex); } catch { LogError(); } finally { LogEndOfExecution(); }
Compilamos, implementamos, el servicio se bloquea, no hay errores. Pasan tres días detrás de este proceso, ahora ya vienen pensamientos de que finalmente debemos comenzar a pensar y hacer otra cosa. Puede hacer muchas cosas: intente reproducir el error en la máquina local, observe los volcados de memoria, etc. Parecieron otros dos días y arreglaré este error ...
Han pasado dos semanas.
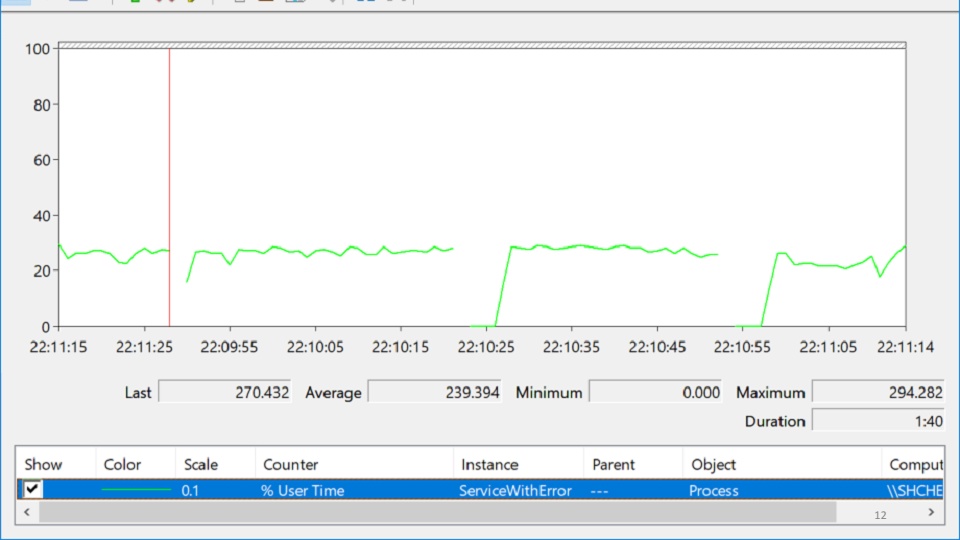
Miré en PerformanceMonitor, donde vi un servicio que falla, luego sube y luego vuelve a caer. Esta condición se llama
desesperación y se ve así:
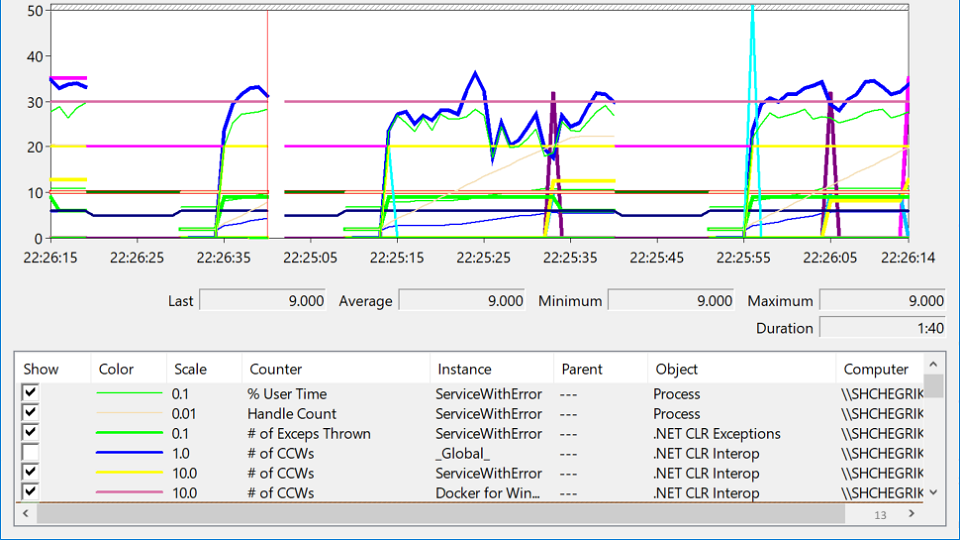
En esta variedad de etiquetas, ¿estás tratando de descubrir dónde está realmente el problema? Después de varias horas de meditación, el problema aparece de repente:
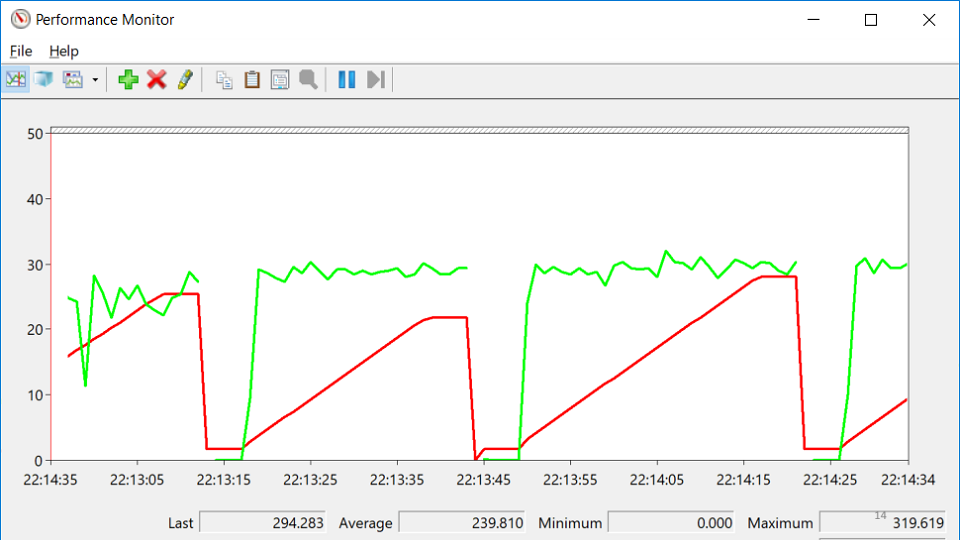
La línea roja es el número de identificadores nativos que posee el proceso. Un identificador nativo es una referencia a un recurso del sistema operativo: archivo, registro, clave de registro, mutex, etc. Por alguna extraña combinación de circunstancias, la caída en el crecimiento en el número de manijas coincide con los momentos en que el servicio cayó. Esto lleva a la idea de que en algún lugar hay una fuga de manijas.
Tomamos un volcado de memoria, lo abrimos en WinDbg. Comenzamos a ejecutar comandos. Intentemos ver la cola de finalización de aquellos objetos que la aplicación debería liberar.
0:000> !FinalizeQueue
Al final de la lista, encontré un navegador web.
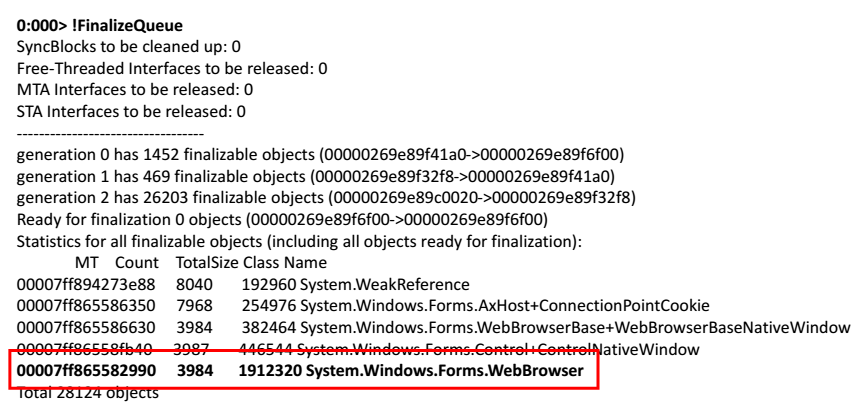
La solución es simple: tome WebBrowser y llame a
dispose para ello:
private void Process() { using (var webBrowser = new WebBrowser()) {
Las conclusiones de esta historia se pueden extraer de la siguiente manera: dos semanas son demasiado largas y demasiado largas para encontrar una
dispose no invitada; que encontramos una solución al problema: suerte, dado que no había un enfoque específico, no había una naturaleza sistemática.
Después de eso, tuve una pregunta: ¿cómo debutar efectivamente y qué hacer?
Para hacer esto, solo necesita saber tres cosas:
- Reglas de depuración
- Algoritmo para encontrar errores.
- Técnicas de depuración proactiva.
Reglas de depuración
- Repite el error.
- Si no ha solucionado el error, entonces no está solucionado.
- Comprende el sistema.
- Verifica el enchufe.
- Divide y vencerás.
- Refréscate.
- Este es tu error.
- Cinco por qué.
Estas son reglas bastante claras que se describen a sí mismas.
Repite el error. Una regla muy simple, porque si no puede cometer un error, entonces no hay nada que arreglar. Pero hay diferentes casos, especialmente para los errores en un entorno multiproceso. De alguna manera, tuvimos un error que apareció solo en los procesadores Itanium y solo en los servidores de producción. Por lo tanto, la primera tarea en el proceso de depuración es encontrar una configuración del banco de pruebas en el que se reproduciría el error.
Si no ha solucionado el error, entonces no está solucionado. A veces esto sucede: un rastreador de errores contiene un error que apareció hace medio año, nadie lo ha visto durante mucho tiempo y existe el deseo de simplemente cerrarlo. Pero en este momento perdemos la oportunidad de saber, la oportunidad de comprender cómo funciona nuestro sistema y qué es lo que realmente le sucede. Por lo tanto, cualquier error es una nueva oportunidad para aprender algo, aprender más sobre su sistema.
Comprende el sistema. Brian Kernighan dijo una vez que si éramos tan inteligentes para escribir este sistema, entonces debemos ser doblemente inteligentes para debutarlo.
Un pequeño ejemplo de la regla. Nuestro monitoreo dibuja gráficos:
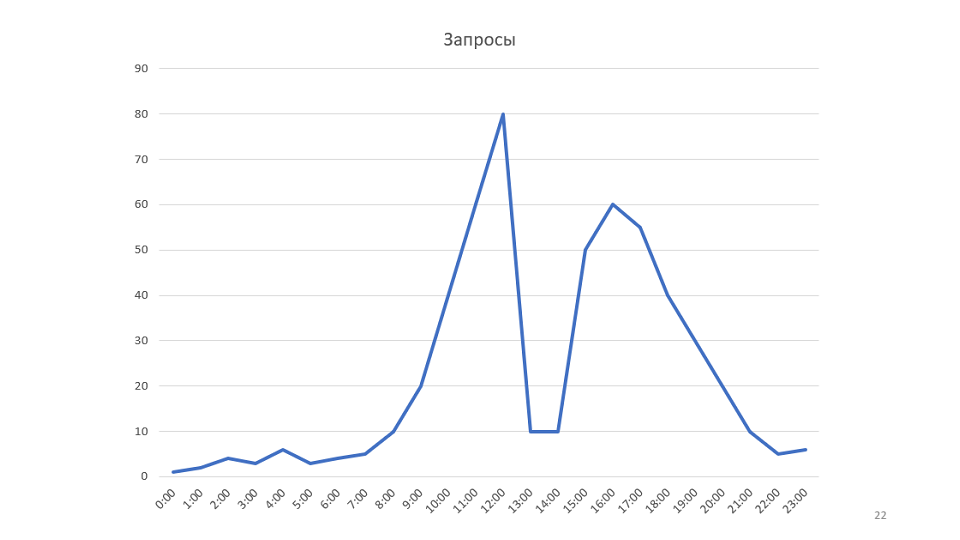
Este es un gráfico del número de solicitudes procesadas por nuestro servicio. Una vez que lo miramos, se nos ocurrió la idea de que sería posible aumentar la velocidad del servicio. En este caso, el horario aumenta, puede ser posible reducir el número de servidores.
La optimización del rendimiento web se realiza simplemente: tomamos PerfView, lo ejecutamos en la máquina de producción, elimina el rastro en 3-4 minutos, llevamos este rastro a la máquina local y comenzamos a estudiarlo.
Una de las estadísticas que muestra PerfView es el recolector de basura.
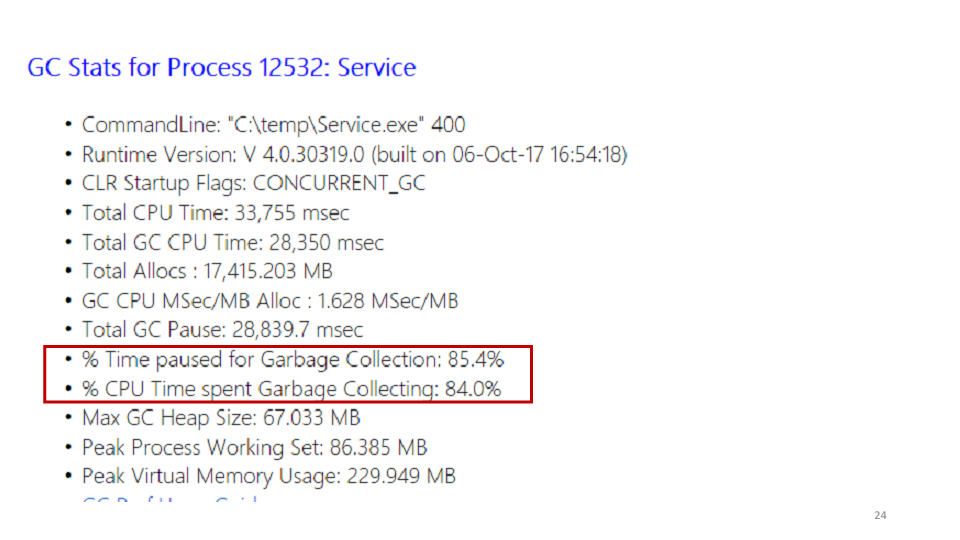
Al observar estas estadísticas, vimos que el servicio pasa el 85% de su tiempo recolectando basura. Puede ver en PerfView exactamente dónde se pasa este tiempo.
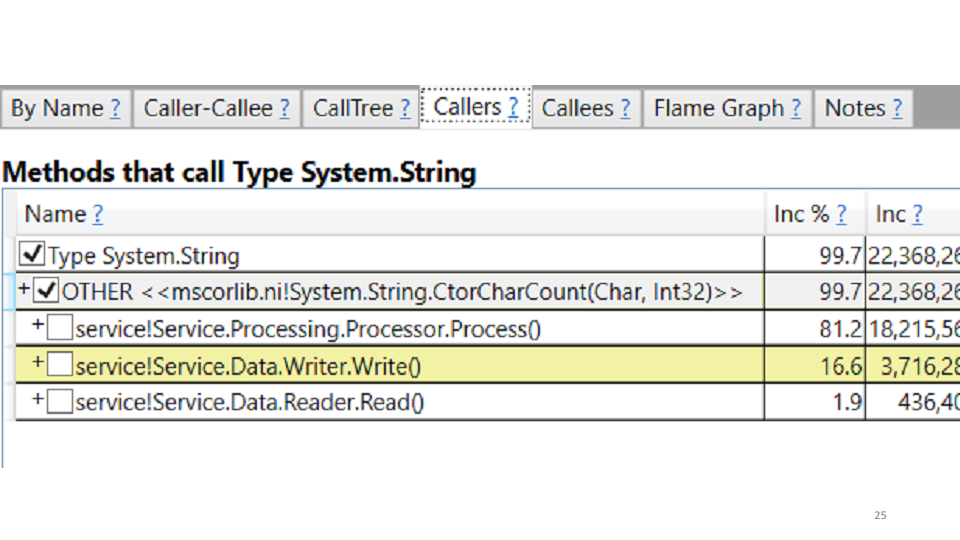
En nuestro caso, esto está creando cadenas. La corrección en sí misma se sugiere: reemplazamos todas las cadenas con StringBuilders. A nivel local, obtenemos un aumento de la productividad del 20-30%. Implementar en producción, ver los resultados en comparación con el calendario anterior:
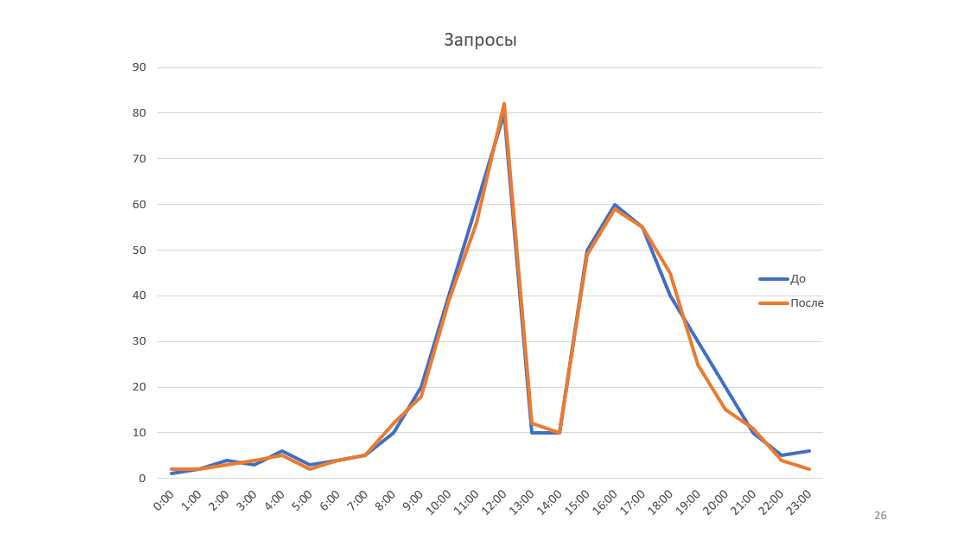
La regla "Comprender el sistema" no se trata solo de comprender cómo están ocurriendo las interacciones en su sistema, cómo van los mensajes, sino de intentar modelar su sistema.
En el ejemplo, el gráfico muestra el ancho de banda. Pero si observa todo el sistema desde el punto de vista de la teoría de colas, resulta que el rendimiento de nuestro sistema depende de un solo parámetro: la velocidad de llegada de nuevos mensajes. De hecho, el sistema simplemente no tenía más de 80 mensajes a la vez, por lo que no hay forma de optimizar esta programación.
Verifica el enchufe. Si abre la documentación de cualquier electrodoméstico, definitivamente se escribirá allí: si el electrodoméstico no funciona, verifique que el enchufe esté insertado en el tomacorriente. Después de varias horas en el depurador, a menudo me encuentro pensando que solo tenía que volver a compilar o simplemente elegir la última versión.
La regla de "comprobar el enchufe" trata sobre hechos y datos. La depuración no comienza ejecutando WinDbg o PerfView en máquinas de producción, sino que verifica hechos y datos. Si el servicio no responde, es posible que no se esté ejecutando.
Divide y vencerás. Esta es la primera y probablemente la única regla que incluye la depuración como proceso. Se trata de hipótesis, su promoción y prueba.
Uno de nuestros servicios no quería detenerse.
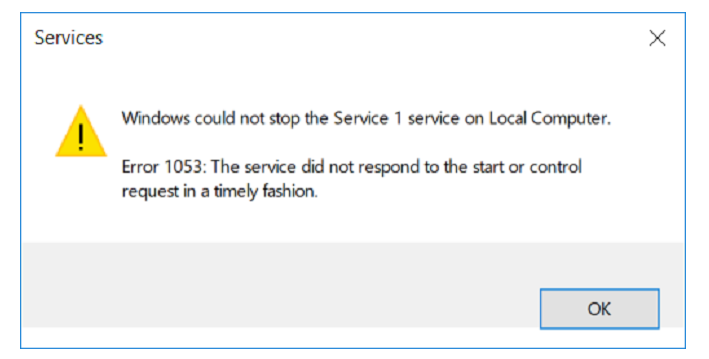
Hacemos una hipótesis: tal vez hay un ciclo en el proyecto que procesa algo sin fin.
Puede probar la hipótesis de diferentes maneras, una opción es tomar un volcado de memoria.
~*e!ClrStack pilas de llamadas del volcado y todos los hilos usando el
~*e!ClrStack . Comenzamos a mirar y ver tres corrientes.
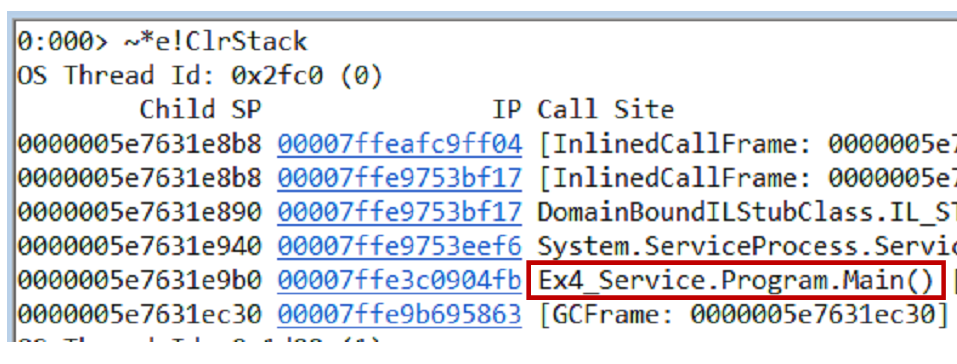
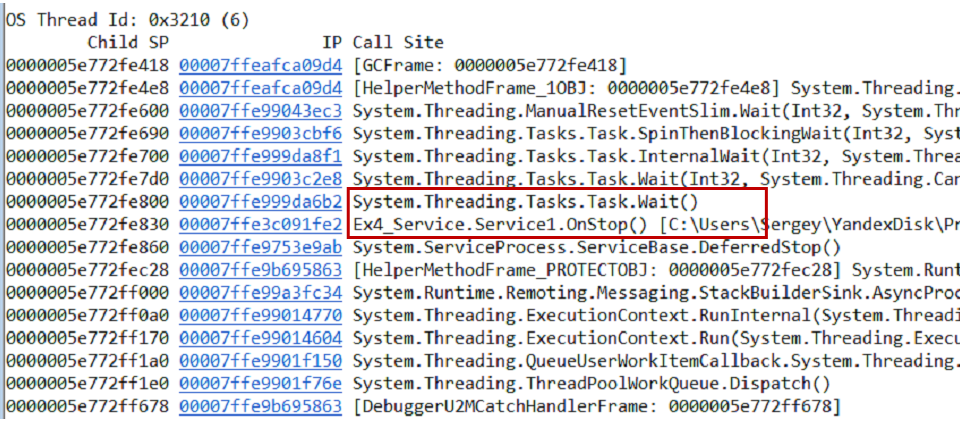
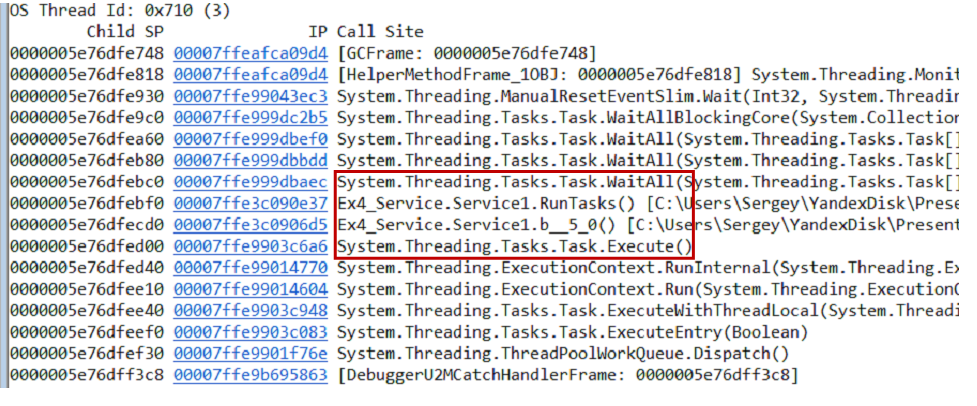
El primer hilo está en Principal, el segundo está en el controlador
OnStop() , y el tercer hilo estaba esperando algunas tareas internas. Por lo tanto, nuestra hipótesis no está justificada. No hay bucle, todos los hilos están esperando algo. Muy probablemente punto muerto.
Nuestro servicio funciona de la siguiente manera. Hay dos tareas: inicialización y trabajo. La inicialización abre una conexión a la base de datos, el trabajador comienza a procesar los datos. La comunicación entre ellos ocurre a través de un indicador común, que se implementa utilizando
TaskCompletionSource .
Hacemos la segunda hipótesis: quizás tenemos un punto muerto de una tarea para la segunda. Para verificar esto, puede ver cada tarea por separado a través de WinDbg.
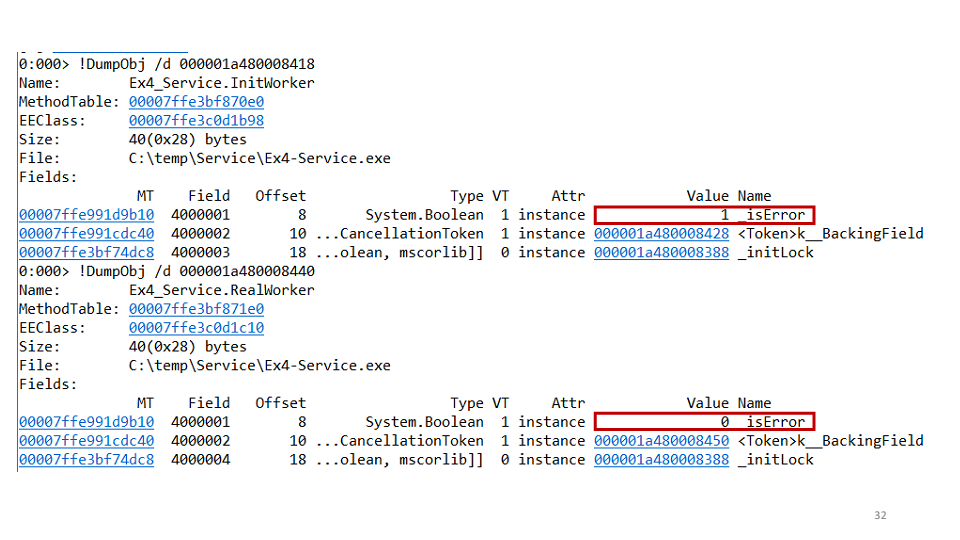
Resulta que una de las tareas cayó, y la segunda no. En el proyecto, vimos el siguiente código:
await openAsync(); _initLock.SetResult(true);
Significa que la tarea de inicialización abre la conexión y luego establece
TaskCompletionSource en verdadero. Pero, ¿qué pasa si una excepción cae aquí? Entonces no tenemos tiempo para establecer
SetResult en verdadero, por lo que la solución a este error fue así:
try { await openAsync(); _initLock.SetResult(true); } catch(Exception ex) { _initLock.SetException(ex); }
En este ejemplo, presentamos dos hipótesis: el bucle infinito y el punto muerto. La regla "divide y vencerás" ayuda a localizar el error. Las aproximaciones sucesivas resuelven tales problemas.
Lo más importante en esta regla son las hipótesis, porque con el tiempo se convierten en patrones. Y dependiendo de la hipótesis, usamos diferentes acciones.
Refréscate. Esta regla es que solo necesita levantarse de la mesa y caminar, beber agua, jugo o café, hacer cualquier cosa, pero lo más importante es distraerse de su problema.
Hay un muy buen método llamado pato. De acuerdo con el método, debemos informar sobre el problema del
agachamiento . Puedes usar un colega como
pato . Además, no tiene que responder, solo escuchar y estar de acuerdo. Y a menudo, después de la primera conversación sobre el problema, usted mismo encuentra una solución.
Este es tu error. Diré sobre esta regla con un ejemplo.
Hubo un problema en una
AccessViolationException . Mirando en la pila de llamadas, vi que ocurrió cuando generamos la consulta LinqToSql dentro del cliente sql.

De este error quedó claro que en algún lugar se viola la integridad de la memoria. Afortunadamente, en ese momento ya utilizamos el sistema de gestión de cambios. Como resultado, después de un par de horas quedó claro lo que sucedió: instalamos .Net 4.5.2 en nuestras máquinas de producción.
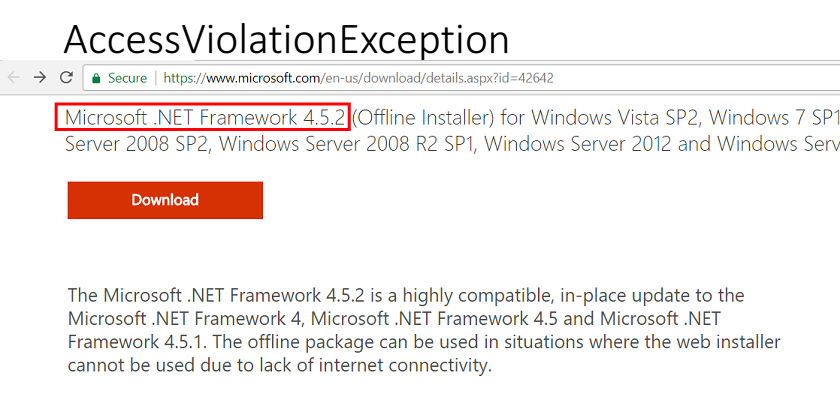
En consecuencia, enviamos el error a Microsoft, lo examinan, nos comunicamos con ellos, solucionan el error en .Net 4.6.1.
Para mí, esto resultó en 11 meses de trabajo con el soporte de Microsoft, por supuesto, no todos los días, pero tardó 11 meses en solucionarse. Además, les enviamos docenas de gigabytes de volcados de memoria, colocamos cientos de ensamblados privados para detectar este error. Y durante todo este tiempo, no pudimos decirles a nuestros clientes que Microsoft tenía la culpa, no nosotros. Por lo tanto, el error siempre es tuyo.
Cinco por qué. Nosotros en nuestra empresa usamos Elastic. Elastic es bueno para la agregación de registros.
Vienes a trabajar por la mañana, y Elastic miente.
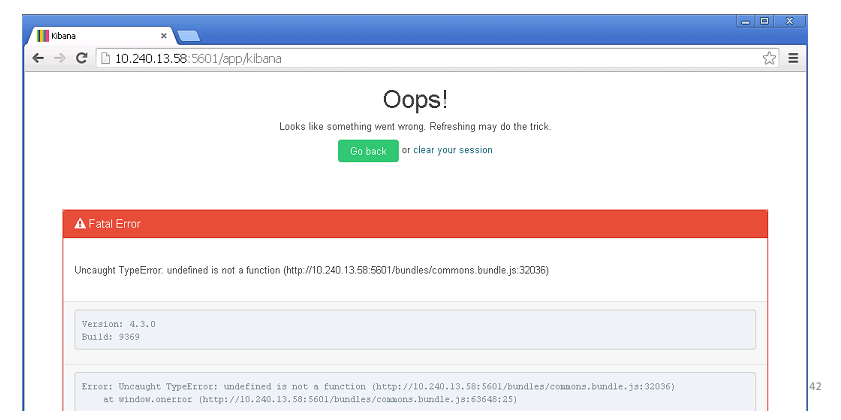
La primera pregunta es ¿por qué es elástico? Casi de inmediato quedó claro: los nodos maestros cayeron. Coordinan el trabajo de todo el grupo y cuando caen, todo el grupo deja de responder. ¿Por qué no se levantaron? Tal vez debería haber un inicio automático? Después de buscar la respuesta, encontramos que la versión del complemento no coincide. ¿Por qué cayeron los nodos maestros? Fueron asesinados por OOM Killer. Esto es así en las máquinas Linux, que en caso de falta de memoria cierra procesos innecesarios. ¿Por qué no hay suficiente memoria? Porque ha comenzado el proceso de actualización, que se deduce de los registros del sistema. ¿Por qué funcionó antes, pero no ahora? Y debido a que agregamos nuevos nodos una semana antes, en consecuencia, los nodos maestros necesitaban más memoria para almacenar índices y configuraciones de clúster.
Las preguntas "¿por qué?" Ayuda a encontrar la raíz del problema. En el ejemplo, podríamos desactivar la ruta correcta muchas veces, pero la solución completa se ve así: actualizamos el complemento, iniciamos servicios, aumentamos la memoria y tomamos una nota para el futuro, que la próxima vez, al agregar nuevos nodos al clúster, debemos asegurarnos de que haya suficiente memoria en el Maestro Nodos
La aplicación de estas reglas le permite revelar problemas reales, cambia su enfoque para resolver estos problemas y ayuda a comunicarse. Pero sería aún mejor si estas reglas formaran un sistema. Y existe tal sistema, se llama algoritmo de depuración.
Algoritmo de depuración
Por primera vez, leí sobre el algoritmo de depuración en el libro de John Robbins 'Depuración de aplicaciones'. Describe el proceso de depuración de la siguiente manera:
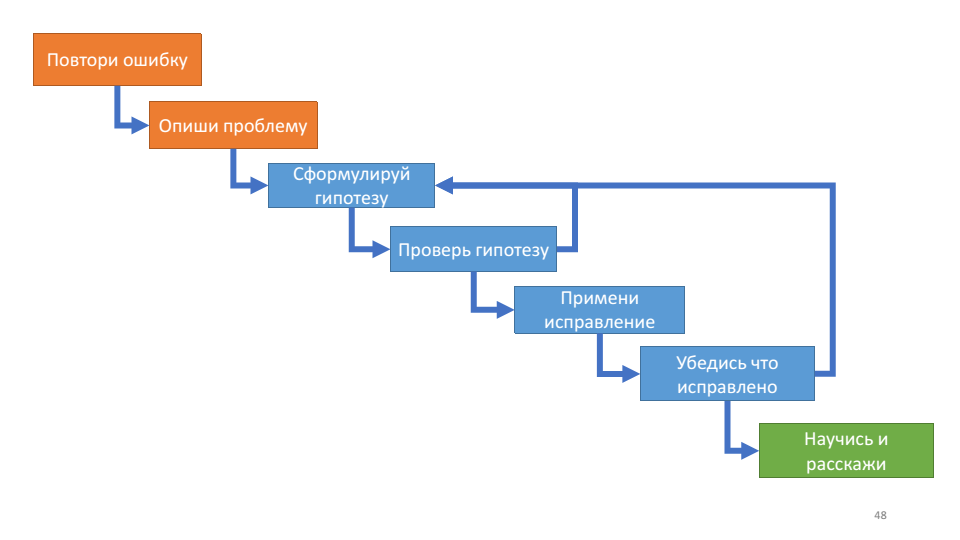
Este algoritmo es útil para su ciclo interno: trabajar con una hipótesis.
Con cada vuelta del ciclo podemos comprobarnos: ¿sabemos más sobre el sistema o no? Si presentamos hipótesis, verifique, no funcionan, no aprendemos nada nuevo sobre el funcionamiento del sistema, entonces probablemente sea hora de refrescarse. Dos preguntas actuales en este punto: qué hipótesis has probado y qué hipótesis estás probando ahora.
Este algoritmo coincide muy bien con las reglas de depuración de las que hablamos anteriormente: repita el error, este es su error, describa el problema, comprenda el sistema, formule una hipótesis, divida y conquiste, pruebe la hipótesis, verifique el enchufe, asegúrese de que esté solucionado, cinco por qué.
Tengo un buen ejemplo para este algoritmo. Una excepción recayó en uno de nuestros servicios web.
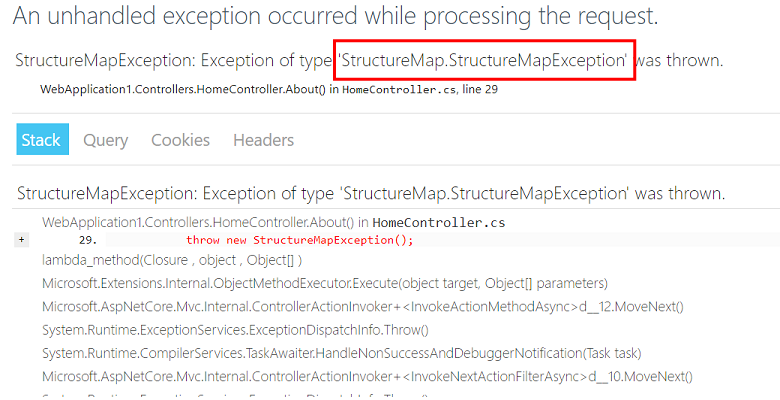
Nuestro primer pensamiento no es nuestro problema. Pero de acuerdo con las reglas, este sigue siendo nuestro problema.
Primero, repite el error. Por cada mil solicitudes, hay aproximadamente una
StructureMapException , por lo que podemos reproducir el problema.
En segundo lugar, estamos tratando de describir el problema: si el usuario realiza una solicitud http para nuestro servicio en el momento en que StructureMap está tratando de hacer una nueva dependencia, entonces se produce una excepción.
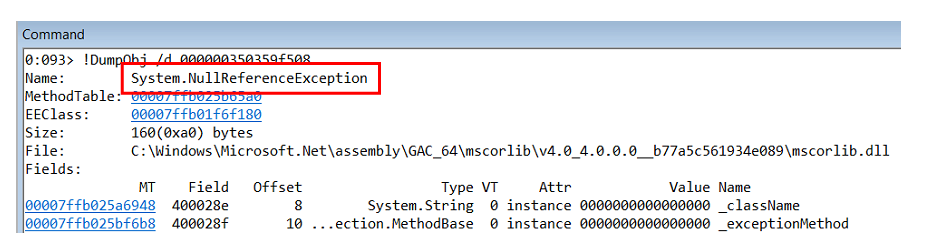
En tercer lugar, planteamos la hipótesis de que StructureMap es un contenedor y hay algo dentro que arroja una excepción interna. Probamos la hipótesis usando procdump.exe.
procdump.exe -ma -e -f StructureMap w3wp.exe
Resulta que adentro hay una
NullReferenceException .
Al estudiar la pila de llamadas de esta excepción, entendemos que ocurre dentro del generador de objetos en el propio StructureMap.
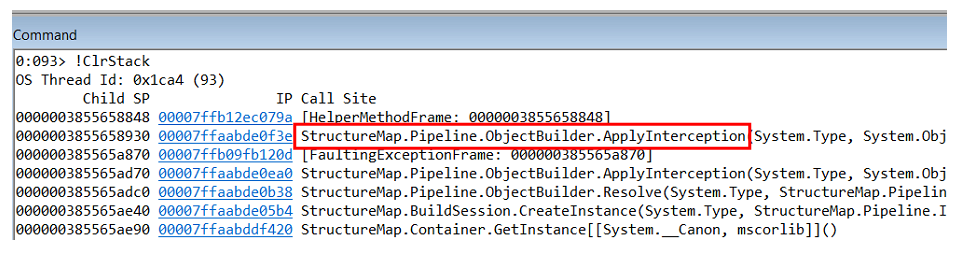
Pero
NullReferenceException no es el problema en sí, sino la consecuencia. Necesita comprender dónde ocurre y quién lo genera.
Presentamos la siguiente hipótesis: por alguna razón, nuestro código devuelve una dependencia nula. Dado que en .Net todos los objetos en la memoria están ubicados uno por uno, si miramos los objetos en el montón que se encuentran antes de la
NullReferenceException , probablemente apunten al código que arrojó la excepción.
En WinDbg hay un comando: Lista de objetos cercanos
!lno . Muestra que el objeto que nos interesa es la función lambda, que se utiliza en el siguiente código.
public CompoundInterceptor FindInterceptor(Type type) { CompoundInterceptop interceptor; if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) { lock (_locker) { if (!_analyzedInterceptors.TryGetValue(type, out interceptor)) { var interceptorArray = _interceptors.FindAll(i => i.MatchesType(type)); interceptor = new CompoundInterceptor(interceptorArray); _analyzedInterceptors.Add(type, interceptor); } } } return interceptor; }
En este código, primero verificamos si el valor en el
Dictionary _analyzedInterceptors en
_analyzedInterceptors , si no lo encontramos, luego agregamos un nuevo valor dentro del
lock .
En teoría, este código nunca puede devolver nulo. Pero el problema aquí está en
_analyzedInterceptors , que usa un
Dictionary regular en un entorno de subprocesos múltiples, no un
ConcurrentDictionary .
Se encontró la raíz del problema, actualizamos a la última versión de StructureMap, implementada, nos aseguramos de que todo estuviera solucionado. El último paso de nuestro algoritmo es "aprender y contar". En nuestro caso, fue una búsqueda en el código de todos los
Dictionary que se usan en la cerradura y verificar que todos se usan correctamente.
Entonces, el algoritmo de depuración es un algoritmo intuitivo que ahorra mucho tiempo. Se centra en la hipótesis, y esto es lo más importante en la depuración.
Depuración proactiva
En esencia, la depuración proactiva responde a la pregunta "qué sucede cuando aparece un error".
La importancia de las técnicas de depuración proactiva se puede ver en el diagrama del ciclo de vida del error.
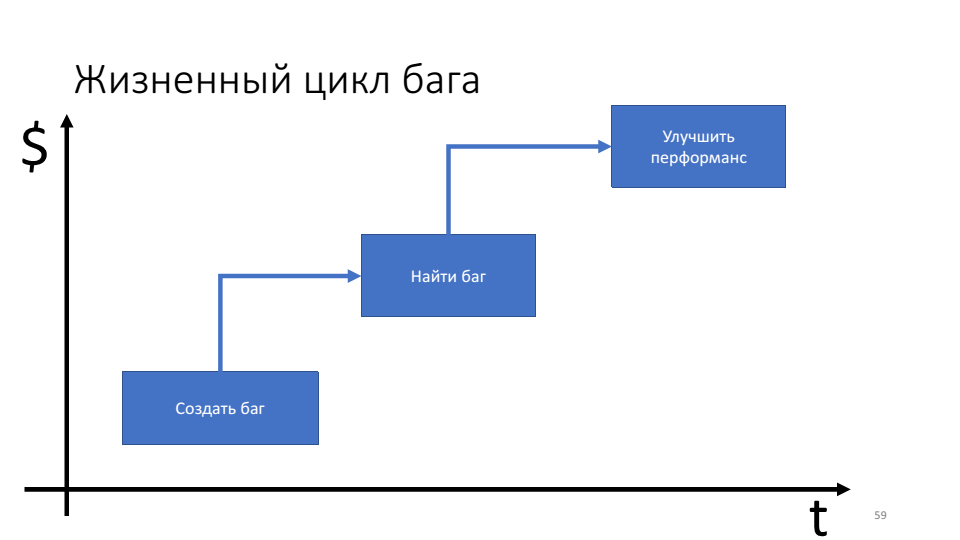
El problema es que cuanto más dura el error, más recursos (tiempo) gastamos en él.
Las reglas de depuración y el algoritmo de depuración nos centran en el momento en que se encuentra el error y podemos averiguar qué hacer a continuación. De hecho, queremos cambiar nuestro enfoque en el momento en que se creó el error. Creo que deberíamos hacer el Producto mínimo depurable (MDP), es decir, un producto que tenga el conjunto mínimo de infraestructura necesario para una depuración eficiente en la producción.
MDP consta de dos cosas: función de condición física y método de USO.
Funciones de acondicionamiento físico. Fueron popularizados por Neil Ford y coautores en el libro Building Evolutionary Architectures. En esencia, las funciones de aptitud física, según los autores del libro, se ven así: hay una arquitectura de aplicación que podemos cortar en diferentes ángulos, obteniendo propiedades arquitectónicas como
mantenibilidad ,
rendimiento , etc., y para cada sección debemos escribir una prueba: aptitud -función Por lo tanto, una función de aptitud es una prueba de arquitectura.
En el caso de MDP, la función de aptitud es una prueba de depuración. Puede usar cualquier cosa que desee para escribir tales pruebas: NUnit, MSTest, etc. Pero, dado que la depuración a menudo funciona con herramientas externas, demostraré el uso de Pester (marco de prueba de unidad powershell) como ejemplo. Su ventaja aquí es que funciona bien con la línea de comando.
Por ejemplo, dentro de la empresa acordamos que utilizaremos bibliotecas específicas para iniciar sesión; al iniciar sesión usaremos patrones específicos; Los caracteres pdb siempre deben asignarse al servidor de símbolos. Estas serán las convenciones que probaremos en nuestras pruebas.
Describe 'Debuggability' { It 'Contains line numbers in PDBs' { Get-ChildItem -Path . -Recurse -Include @("*.exe", "*. dll ") ` | ForEach-Object { &symchk.exe /v "$_" /s "\\network\" *>&1 } ` | Where-Object { $_ -like "*Line nubmers: TRUE*" } ` | Should -Not –BeNullOrEmpty } }
Esta prueba verifica que todos los caracteres pdb se dieron al servidor de símbolos y se dieron correctamente, es decir, aquellos que contienen números de línea en su interior. Para hacer esto, tome la versión compilada de la producción, encuentre todos los archivos exe y dll, pase todos estos binarios a través de la utilidad syschk.exe, que se incluye en el paquete de herramientas de depuración para Windows. La utilidad syschk.exe comprueba el binario con el servidor de símbolos y, si encuentra un archivo pdb allí, imprime un informe al respecto. En el informe, buscamos la línea "Números de línea: VERDADERO". Y en la final comprobamos que el resultado no es "nulo o vacío".
Estas pruebas deben integrarse en una tubería de implementación continua. Después de que las pruebas de integración y las pruebas unitarias han pasado, se lanzan las funciones de aptitud.
Mostraré un ejemplo más al verificar las bibliotecas necesarias en el código.
Describe 'Debuggability' { It 'Contains package for logging' { Get-ChildItem -Path . -Recurse -Name "packages.config" ` | ForEach-Object { Get-Content "$_" } ` | Where-Object { $_ -like "*nlog*" } ` | Should -Not –BeNullOrEmpty } }
En la prueba, tomamos todos los archivos package.config e intentamos encontrar las bibliotecas nlog en ellos. De manera similar, podemos verificar que el campo de identificación de correlación se use dentro del campo nlog.
UTILICE métodos. Lo último que consiste en MDP es la métrica que necesita recopilar.
Lo demostraré con el ejemplo del método USE, que fue popularizado por Brendan Gregg.
La idea es simple: si hay algún problema en el código, es suficiente tomar tres métricas: utilización (saturación), errores (errores), que ayudarán a comprender dónde está el problema.Algunas compañías, por ejemplo Circonus (hacen monitoreo suave), construyen sus paneles en forma de métricas designadas.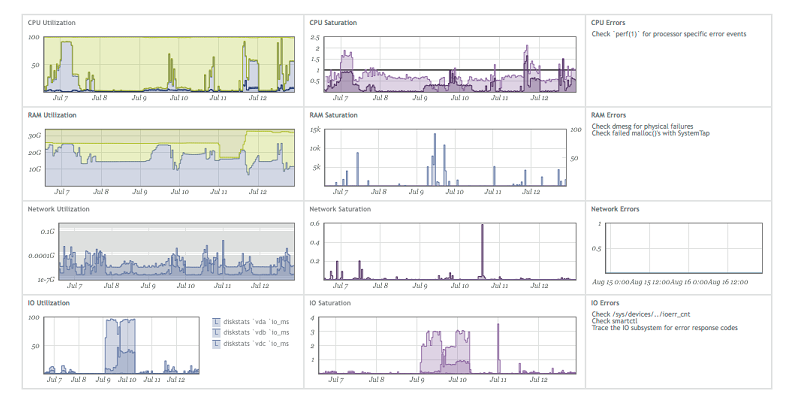 Si observa en detalle, por ejemplo, la memoria, entonces el uso es la cantidad de memoria libre, la saturación es la cantidad de accesos al disco, los errores son cualquier error que haya aparecido. Por lo tanto, para que los productos sean convenientes para la depuración, debe recopilar métricas USE para todas las funciones y todas las partes del subsistema.Si toma una característica comercial, lo más probable es que pueda distinguir tres métricas en ella:
Si observa en detalle, por ejemplo, la memoria, entonces el uso es la cantidad de memoria libre, la saturación es la cantidad de accesos al disco, los errores son cualquier error que haya aparecido. Por lo tanto, para que los productos sean convenientes para la depuración, debe recopilar métricas USE para todas las funciones y todas las partes del subsistema.Si toma una característica comercial, lo más probable es que pueda distinguir tres métricas en ella:- Uso: tiempo de procesamiento de la solicitud.
- La saturación es la longitud de la cola.
- Errores: cualquier situación excepcional.
Como ejemplo, veamos un gráfico del número de solicitudes procesadas que realiza uno de nuestros sistemas. Como puede ver, el servicio no ha procesado solicitudes durante las últimas tres horas.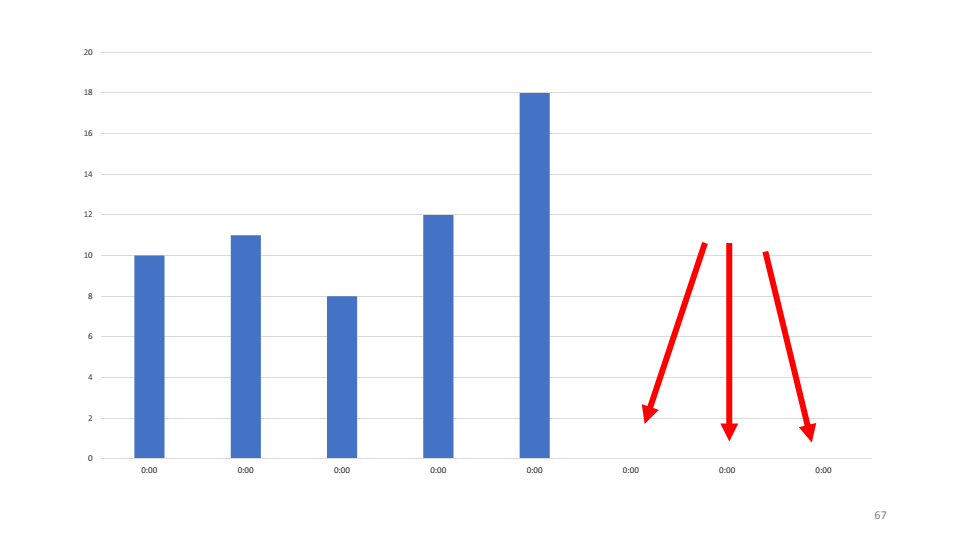 La primera hipótesis que formulamos es que el servicio ha caído y necesitamos reiniciarlo. Al verificar, resulta que el servicio está funcionando, utiliza 4-5% de la CPU.
La primera hipótesis que formulamos es que el servicio ha caído y necesitamos reiniciarlo. Al verificar, resulta que el servicio está funcionando, utiliza 4-5% de la CPU.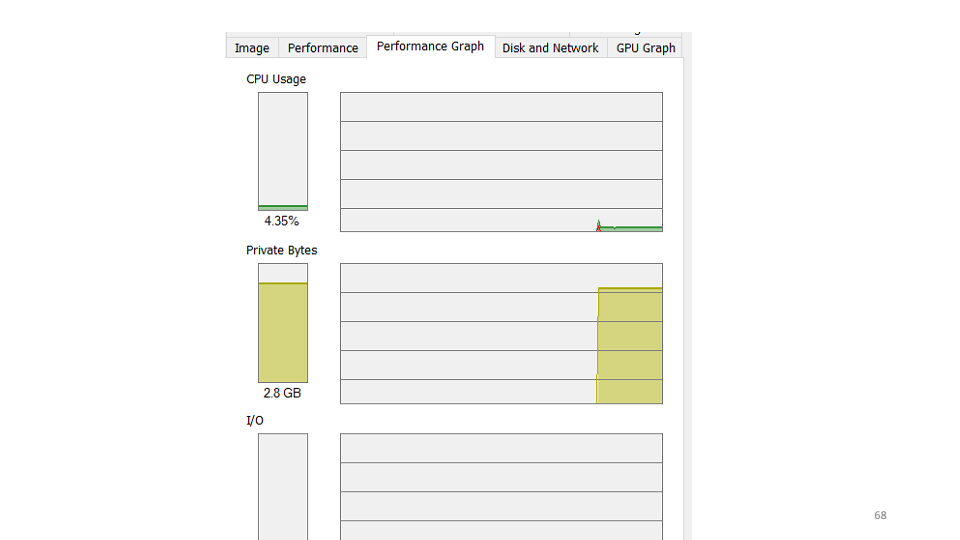 La segunda hipótesis es que un error cae dentro del servicio que no vemos. Utilizaremos la utilidad etrace.
La segunda hipótesis es que un error cae dentro del servicio que no vemos. Utilizaremos la utilidad etrace. etrace --kernel Process ^ --where ProcessName=Ex5-Service ^ --clr Exception
La utilidad le permite suscribirse a eventos ETW en tiempo real y mostrarlos en la pantalla.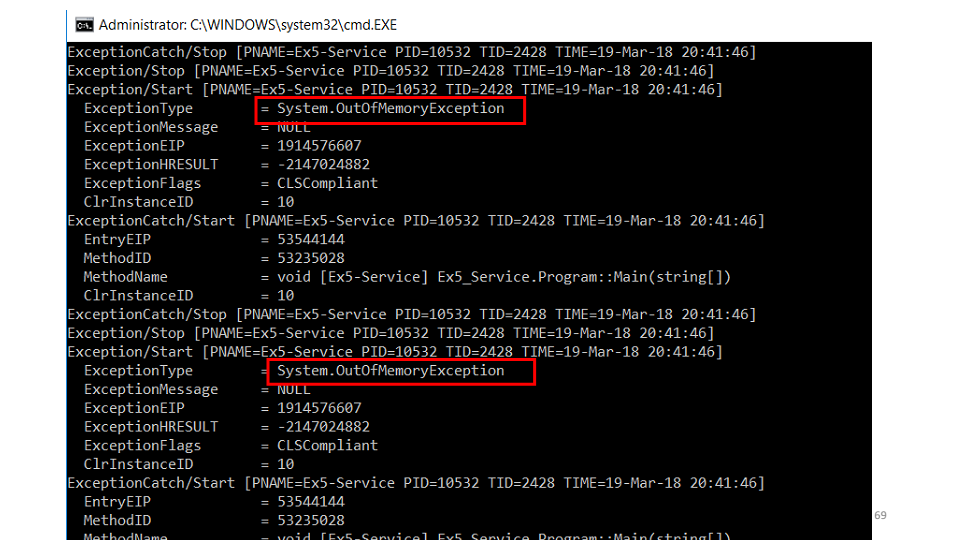 Vemos que está cayendo
Vemos que está cayendo OutOfMemoryException. Pero, la segunda pregunta, ¿por qué no está en los registros? La respuesta es rápida: la interceptamos, tratamos de limpiar la memoria, esperamos un poco y comenzamos a trabajar nuevamente. while (ShouldContinue()) { try { Do(); } catch (OutOfMemoryException) { Thread.Sleep(100); GC.CollectionCount(2); GC.WaitForPendingFinalizers(); } }
La siguiente hipótesis es que alguien se come toda la memoria. Según el volcado de memoria, la mayoría de los objetos están en la memoria caché. public class Cache { private static ConcurrentDictionary<int, String> _items = new ... private static DateTime _nextClearTime = DateTime.UtcNow; public String GetFromCache(int key) { if (_nextClearTime < DateTime.UtcNow) { _nextClearTime = DateTime.UtcNow.AddHours(1); _items.Clear(); } return _items[key]; } }
El código muestra que cada hora se debe borrar el caché. Pero el recuerdo no fue suficiente, ni siquiera llegaron a la limpieza. Veamos un ejemplo de la métrica USE cache.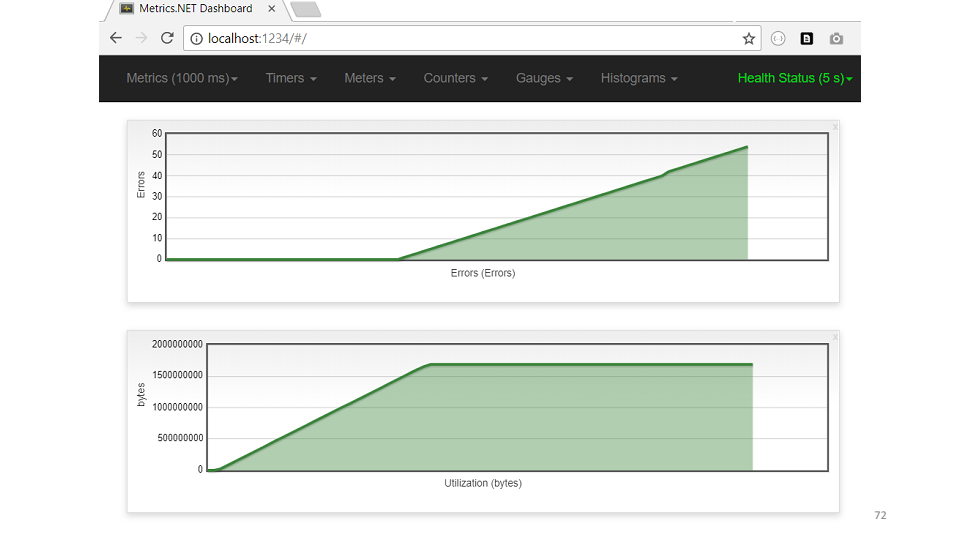 Según el cronograma, es inmediatamente visible: la memoria ha aumentado, los errores comenzaron de inmediato.Entonces, conclusiones sobre qué es la depuración proactiva.
Según el cronograma, es inmediatamente visible: la memoria ha aumentado, los errores comenzaron de inmediato.Entonces, conclusiones sobre qué es la depuración proactiva.- La depuración es un requisito de arquitectura. De hecho, lo que estamos desarrollando es un modelo del sistema. El sistema en sí es los bytes y bits que están en la memoria en los servidores de producción. La depuración proactiva sugiere que debe pensar en su entorno operativo.
- Reduzca la ruta de error en el sistema. Las técnicas de depuración proactiva incluyen verificar todos los métodos públicos y sus argumentos; lanzar una excepción tan pronto como aparezca, y no depurar hasta algún punto y así sucesivamente.
- El producto mínimo depurable es una buena herramienta para comunicarse entre sí y desarrollar requisitos para la depuración del producto.
Entonces, ¿cómo solucionar errores de manera eficiente?
- Utilice la depuración proactiva.
- Sigue el algoritmo.
- Prueba de hipótesis.
Esta vez, el patrocinador de nuestro anuncio es Jon Skeet. Incluso si no vas a Moscú para el nuevo DotNext , vale la pena ver el video (John se esforzó mucho).