Nota perev. : El autor del artículo original, Nicolas Leiva, es un arquitecto de soluciones de Cisco que decidió compartir con sus colegas, ingenieros de redes, cómo funciona la red Kubernetes desde adentro. Para hacer esto, explora su configuración más simple en el clúster, utilizando activamente el sentido común, su conocimiento de las redes y las utilidades estándar de Linux / Kubernetes. Resultó voluminoso, pero muy claramente.
Además del hecho de que la
guía Kubernetes The Hard Way de Kelsey Hightower simplemente funciona (¡
incluso en AWS! ), Me gustó que la red se mantuviera limpia y simple; y esta es una gran oportunidad para comprender el papel, por ejemplo, de la Interfaz de red de contenedores (
CNI ). Dicho esto, agregaré que la red de Kubernetes no es realmente muy intuitiva, especialmente para los principiantes ... y también no olviden que "
simplemente no existe una red para contenedores".
Aunque ya hay buenos materiales sobre este tema (ver enlaces
aquí ), no pude encontrar un ejemplo tal que combinaría todo lo necesario con las conclusiones de los equipos que los ingenieros de redes aman y odian, demostrando lo que realmente está sucediendo detrás de escena. Por lo tanto, decidí recopilar información de muchas fuentes; espero que esto ayude y que comprenda mejor cómo todo está conectado entre sí. Este conocimiento es importante no solo para probarse a sí mismo, sino también para simplificar el proceso de diagnóstico de problemas. Puede seguir el ejemplo en su clúster desde
Kubernetes The Hard Way : todas las direcciones IP y configuraciones se toman desde allí (a partir de las confirmaciones para mayo de 2018, antes de usar
contenedores Nabla ).
Y comenzaremos desde el final, cuando tengamos tres controladores y tres nodos de trabajo:
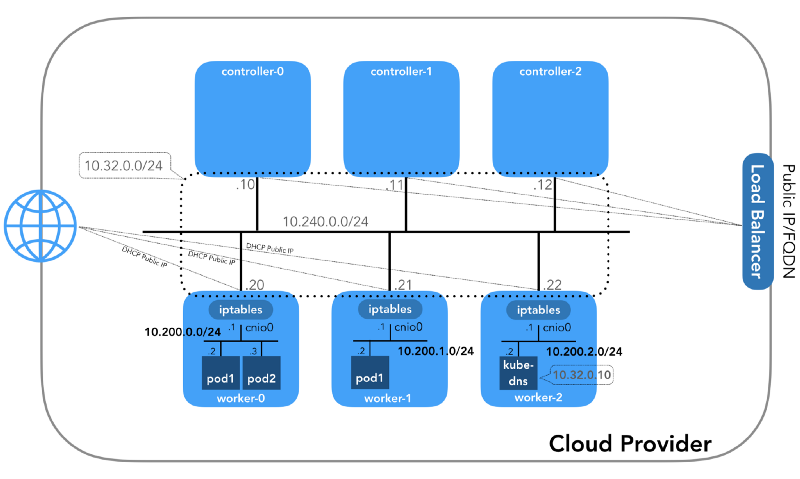
¡Puede notar que también hay al menos tres subredes privadas aquí! Un poco de paciencia, y todos serán considerados. Recuerde que aunque nos referimos a prefijos de IP muy específicos, simplemente están tomados de
Kubernetes The Hard Way , por lo que solo tienen importancia local, y usted es libre de elegir cualquier otro bloque de direcciones para su entorno de acuerdo con
RFC 1918 . Para el caso de IPv6, habrá un artículo de blog separado.
Red de host (10.240.0.0/24)
Esta es una red interna de la cual todos los nodos son parte. Definido por el
--private-network-ip en
GCP o la
--private-ip-address en
AWS cuando se asignan recursos informáticos.
Inicializando nodos de controlador en GCP
for i in 0 1 2; do gcloud compute instances create controller-${i} \
(
controllers_gcp.sh )
Inicialización de nodos de controlador en AWS
for i in 0 1 2; do declare controller_id${i}=`aws ec2 run-instances \
(
controllers_aws.sh )
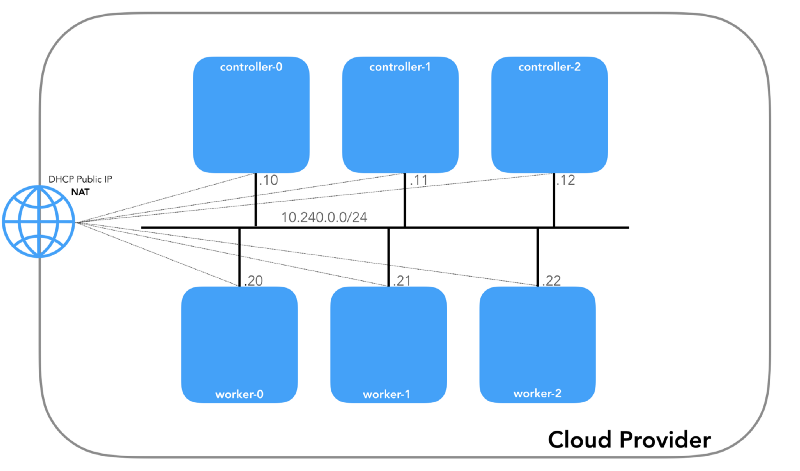
Cada instancia tendrá dos direcciones IP: privadas de la red host (controladores -
10.240.0.1${i}/24 , trabajadores -
10.240.0.2${i}/24 ) y una pública, designada por el proveedor de la nube, de la que hablaremos más adelante. Cómo llegar a
NodePorts .
Gcp
$ gcloud compute instances list NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS controller-0 us-west1-c n1-standard-1 10.240.0.10 35.231.XXX.XXX RUNNING worker-1 us-west1-c n1-standard-1 10.240.0.21 35.231.XX.XXX RUNNING ...
Aws
$ aws ec2 describe-instances --query 'Reservations[].Instances[].[Tags[?Key==`Name`].Value[],PrivateIpAddress,PublicIpAddress]' --output text | sed '$!N;s/\n/ /' 10.240.0.10 34.228.XX.XXX controller-0 10.240.0.21 34.173.XXX.XX worker-1 ...
Todos los nodos deben poder hacer ping entre sí si las
políticas de seguridad son correctas (y si el
ping instalado en el host).
Red de hogar (10.200.0.0/16)
Esta es la red en la que viven los pods. Cada nodo de trabajo utiliza una subred de esta red. En nuestro caso,
POD_CIDR=10.200.${i}.0/24 para el
worker-${i} .
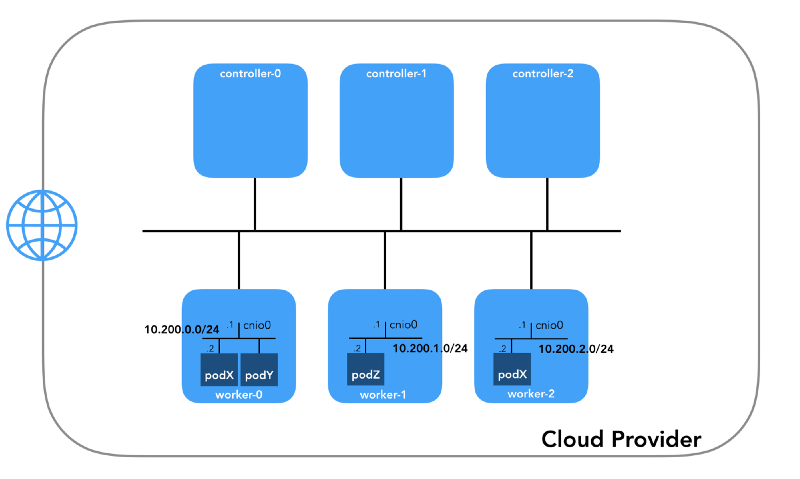
Para comprender cómo está configurado todo, retroceda y mire
el modelo de red de Kubernetes , que requiere lo siguiente:
- Todos los contenedores pueden comunicarse con cualquier otro contenedor sin usar NAT.
- Todos los nodos pueden comunicarse con todos los contenedores (y viceversa) sin usar NAT.
- La IP que ve el contenedor debe ser la misma que otros lo ven.
Todo esto se puede implementar de muchas maneras, y Kubernetes pasa la configuración de la red al
complemento CNI .
“El complemento CNI es responsable de agregar una interfaz de red al espacio de nombres de red del contenedor (por ejemplo, un extremo de un par de veth ) y de realizar los cambios necesarios en el host (por ejemplo, conectar el segundo extremo de veth a un puente). Luego debe asignar una interfaz IP y configurar las rutas de acuerdo con la sección Administración de la dirección IP llamando al complemento IPAM deseado ". (de la especificación de interfaz de red de contenedores )
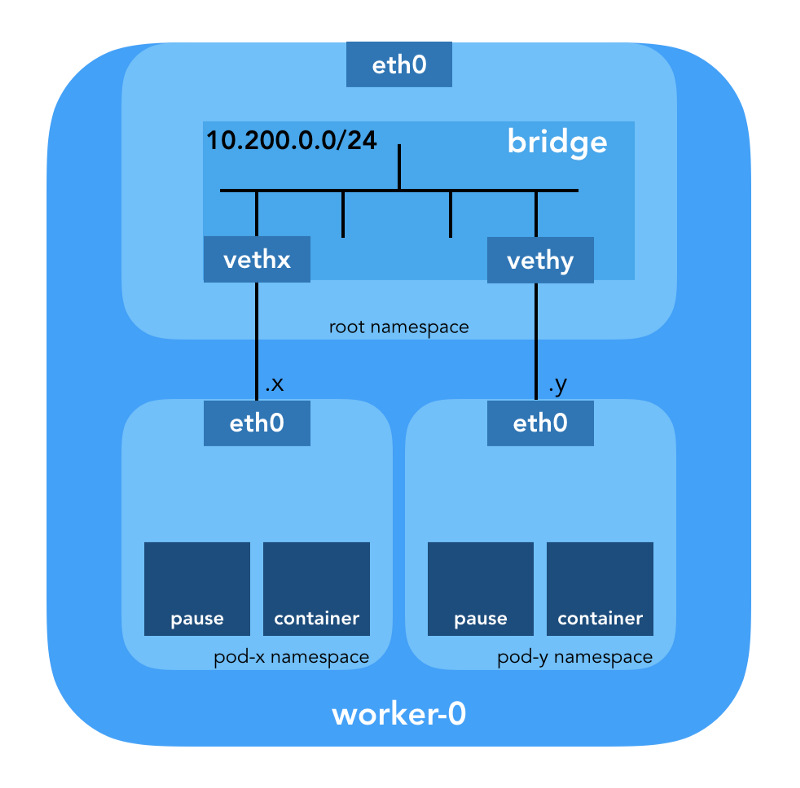
Espacio de nombres de red
“El espacio de nombres envuelve el recurso del sistema global en una abstracción que es visible para los procesos en este espacio de nombres de tal manera que tengan su propia instancia aislada del recurso global. Los cambios en el recurso global son visibles para otros procesos incluidos en este espacio de nombres, pero no son visibles para otros procesos ". ( de la página del manual de espacios de nombres )
Linux proporciona siete espacios de nombres diferentes (
Cgroup ,
IPC ,
Network ,
Mount ,
PID ,
User ,
UTS ). Los espacios de nombres de red (
CLONE_NEWNET ) definen los recursos de red que están disponibles para el proceso: "Cada espacio de nombres de red tiene sus propios dispositivos de red, direcciones IP, tablas de enrutamiento IP,
/proc/net , números de puerto, etc."
( del artículo " Espacios de nombres en funcionamiento ") .
Dispositivos virtuales Ethernet (Veth)
"Un par de red virtual (veth) ofrece una abstracción en forma de" tubería ", que se puede utilizar para crear túneles entre espacios de nombres de red o para crear un puente a un dispositivo de red física en otro espacio de red. Cuando se libera el espacio de nombres, todos los dispositivos veth en él se destruyen ". (desde la página del manual de espacios de nombres de red )
Baje al suelo y vea cómo se relaciona todo con el clúster. En primer lugar,
los complementos de red en Kubernetes son diversos, y los complementos CNI son uno de ellos (
¿por qué no CNM? ).
Kubelet en cada nodo le dice al contenedor de
tiempo de ejecución qué
complemento de red usar. La interfaz de red de contenedor (
CNI ) se encuentra entre el tiempo de ejecución del contenedor y la implementación de la red. Y ya el complemento CNI configura la red.
“El complemento CNI se selecciona pasando la --network-plugin=cni línea de comando --network-plugin=cni a Kubelet. Kubelet lee el archivo desde --cni-conf-dir (el valor predeterminado es /etc/cni/net.d ) y usa la configuración CNI de este archivo para configurar la red para cada archivo ". (de los requisitos del complemento de red )
Los binarios reales del complemento CNI están en
-- cni-bin-dir (el valor predeterminado es
/opt/cni/bin ).
Tenga en cuenta que los
kubelet.service llamada de
kubelet.service incluyen
--network-plugin=cni :
[Service] ExecStart=/usr/local/bin/kubelet \\ --config=/var/lib/kubelet/kubelet-config.yaml \\ --network-plugin=cni \\ ...
En primer lugar, Kubernetes crea un espacio de nombres de red para el hogar, incluso antes de llamar a cualquier complemento. Esto se implementa utilizando el contenedor de
pause especial, que "sirve como el" contenedor principal "para todos los contenedores de hogar"
(del artículo " El Contenedor de pausa Todopoderoso ") . Kubernetes luego ejecuta el complemento CNI para adjuntar el contenedor de
pause a la red. Todos los contenedores de pod utilizan el
netns este contenedor de
pause .
{ "cniVersion": "0.3.1", "name": "bridge", "type": "bridge", "bridge": "cnio0", "isGateway": true, "ipMasq": true, "ipam": { "type": "host-local", "ranges": [ [{"subnet": "${POD_CIDR}"}] ], "routes": [{"dst": "0.0.0.0/0"}] } }
La
configuración CNI utilizada indica el uso del complemento de
bridge para configurar el puente de software de Linux (L2) en el espacio de nombres raíz llamado
cnio0 (el
nombre predeterminado es
cni0 ), que actúa como una puerta de enlace (
"isGateway": true ).

También se configurará un par par para conectar el hogar al puente recién creado:
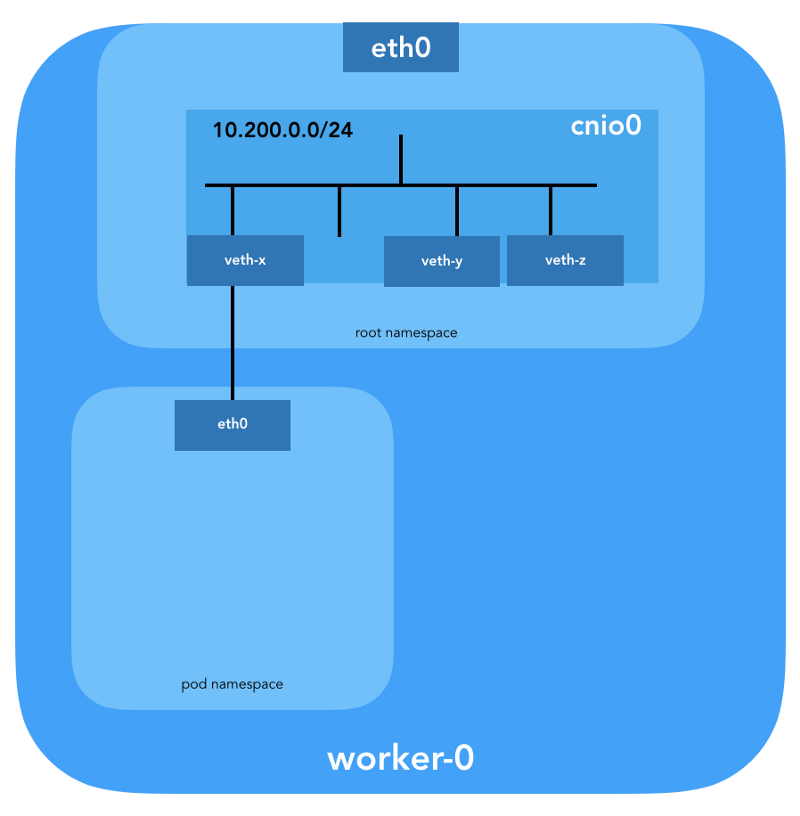
Para asignar información L3, como direcciones IP, se llama al
complemento IPAM (
ipam ). En este caso, se usa el tipo
host-local , "que almacena el estado localmente en el sistema de archivos del host, lo que garantiza la unicidad de las direcciones IP en un host"
(de la host-local ) . El complemento IPAM devuelve esta información al complemento anterior (
bridge ), de modo que todas las rutas especificadas en la configuración se pueden configurar (
"routes": [{"dst": "0.0.0.0/0"}] ). Si no se especifica
gw , se
toma de la subred . La ruta predeterminada también se configura en el espacio de nombres de red del hogar, apuntando al puente (que se configura como la primera subred IP del hogar).
Y el último detalle importante: solicitamos enmascarar (
"ipMasq": true ) para el tráfico proveniente de la red de
"ipMasq": true . Realmente no necesitamos NAT aquí, pero esta es la configuración en
Kubernetes The Hard Way . Por lo tanto, para completar, debo mencionar que las entradas en las
iptables complemento de
bridge están configuradas para este ejemplo en particular. Todos los paquetes del hogar, cuyo destinatario no está en el rango
224.0.0.0/4 ,
estarán detrás de NAT , que no cumple con el requisito "todos los contenedores pueden comunicarse con cualquier otro contenedor sin usar NAT". Bueno, probaremos por qué no se necesita NAT ...

Enrutamiento de hogar
Ahora estamos listos para personalizar las vainas. Miremos todos los espacios de red de los nombres de uno de los nodos de trabajo y analicemos uno de ellos después de crear la implementación de
nginx desde aquí . Usaremos
lsns con la opción
-t para seleccionar el tipo de espacio de nombres deseado (es decir,
net ):
ubuntu@worker-0:~$ sudo lsns -t net NS TYPE NPROCS PID USER COMMAND 4026532089 net 113 1 root /sbin/init 4026532280 net 2 8046 root /pause 4026532352 net 4 16455 root /pause 4026532426 net 3 27255 root /pause
Usando la opción
-i para
ls podemos encontrar sus números de inodo:
ubuntu@worker-0:~$ ls -1i /var/run/netns 4026532352 cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af 4026532280 cni-7cec0838-f50c-416a-3b45-628a4237c55c 4026532426 cni-912bcc63-712d-1c84-89a7-9e10510808a0
También puede enumerar todos los espacios de nombres de red utilizando
ip netns :
ubuntu@worker-0:~$ ip netns cni-912bcc63-712d-1c84-89a7-9e10510808a0 (id: 2) cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af (id: 1) cni-7cec0838-f50c-416a-3b45-628a4237c55c (id: 0)
Para ver todos los procesos que se ejecutan en el espacio de red
cni-912bcc63–712d-1c84–89a7–9e10510808a0 (
4026532426 ), puede ejecutar, por ejemplo, el siguiente comando:
ubuntu@worker-0:~$ sudo ls -l /proc/[1-9]*/ns/net | grep 4026532426 | cut -f3 -d"/" | xargs ps -p PID TTY STAT TIME COMMAND 27255 ? Ss 0:00 /pause 27331 ? Ss 0:00 nginx: master process nginx -g daemon off; 27355 ? S 0:00 nginx: worker process
Se puede ver que además de
pause en este pod, lanzamos
nginx . El contenedor de
pause comparte los espacios de nombres
net e
ipc con todos los demás contenedores de pod. Recuerde el PID de
pause - 27255; Volveremos a ello.
Ahora veamos qué dice
kubectl sobre este pod:
$ kubectl get pods -o wide | grep nginx nginx-65899c769f-wxdx6 1/1 Running 0 5d 10.200.0.4 worker-0
Más detalles:
$ kubectl describe pods nginx-65899c769f-wxdx6
Name: nginx-65899c769f-wxdx6 Namespace: default Node: worker-0/10.240.0.20 Start Time: Thu, 05 Jul 2018 14:20:06 -0400 Labels: pod-template-hash=2145573259 run=nginx Annotations: <none> Status: Running IP: 10.200.0.4 Controlled By: ReplicaSet/nginx-65899c769f Containers: nginx: Container ID: containerd://4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 Image: nginx ...
Vemos el nombre del pod -
nginx-65899c769f-wxdx6 - y la ID de uno de sus contenedores (
nginx ), pero no se ha dicho nada sobre la
pause . Excave un nodo de trabajo más profundo para que coincida con todos los datos. Recuerde que
Kubernetes The Hard Way no utiliza
Docker , por lo tanto, para obtener detalles sobre el contenedor, consulte la utilidad de consola
containerd - ctr
(consulte también el artículo " Integración de containerd con Kubernetes, reemplazando Docker, listo para la producción " - transferencia aprox. ) :
ubuntu@worker-0:~$ sudo ctr namespaces ls NAME LABELS k8s.io
Conociendo el
k8s.io containerd (
k8s.io ), puede obtener el ID del contenedor
nginx :
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep nginx 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 docker.io/library/nginx:latest io.containerd.runtime.v1.linux
... y
pause también:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep pause 0866803b612f2f55e7b6b83836bde09bd6530246239b7bde1e49c04c7038e43a k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux 21640aea0210b320fd637c22ff93b7e21473178de0073b05de83f3b116fc8834 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
La ID del contenedor
nginx que termina en
…983c7 coincide con lo que obtuvimos de
kubectl . Veamos si podemos descubrir qué contenedor de
pause pertenece al pod
nginx :
ubuntu@worker-0:~$ sudo ctr -n k8s.io task ls TASK PID STATUS ... d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 27255 RUNNING 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 27331 RUNNING
¿Recuerda que los procesos con PID 27331 y 27355 se ejecutan en el espacio de nombres de red
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ?
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 { "ID": "d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6", "Labels": { "io.cri-containerd.kind": "sandbox", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382", "pod-template-hash": "2145573259", "run": "nginx" }, "Image": "k8s.gcr.io/pause:3.1", ...
... y:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 { "ID": "4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7", "Labels": { "io.cri-containerd.kind": "container", "io.kubernetes.container.name": "nginx", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382" }, "Image": "docker.io/library/nginx:latest", ...
Ahora sabemos con certeza qué contenedores se están ejecutando en este pod (
nginx-65899c769f-wxdx6 ) y el espacio de nombres de red (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
- nginx (ID:
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 ); - pausa (ID:
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 ).

¿Cómo se conecta esto a (
nginx-65899c769f-wxdx6 ) a la red? Usamos el PID 27255 recibido previamente desde
pause para ejecutar comandos en su espacio de nombres de red (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
ubuntu@worker-0:~$ sudo ip netns identify 27255 cni-912bcc63-712d-1c84-89a7-9e10510808a0
Para estos fines, usaremos
nsenter con la opción
-t que define el PID de destino y
-n sin especificar un archivo para ingresar al espacio de nombres de red del proceso de destino (27255). Esto es lo que dirá
ip link show :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 3: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:58:0a:c8:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
... y
ifconfig eth0 :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ifconfig eth0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.200.0.4 netmask 255.255.255.0 broadcast 0.0.0.0 inet6 fe80::2097:51ff:fe39:ec21 prefixlen 64 scopeid 0x20<link> ether 0a:58:0a:c8:00:04 txqueuelen 0 (Ethernet) RX packets 540 bytes 42247 (42.2 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 177 bytes 16530 (16.5 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Esto confirma que la dirección IP obtenida anteriormente a través de
kubectl get pod está configurada en la interfaz
eth0 . Esta interfaz es parte de un
par veth , uno de los cuales está en el hogar y el otro en el espacio de nombres raíz. Para descubrir la interfaz del segundo extremo, utilizamos
ethtool :
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ethtool -S eth0 NIC statistics: peer_ifindex: 7
Vemos que si el
ifindex fiesta es 7. Verifique que esté en el espacio de nombres raíz. Esto se puede hacer usando el
ip link :
ubuntu@worker-0:~$ ip link | grep '^7:' 7: veth71f7d238@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cnio0 state UP mode DEFAULT group default
Para estar seguros de esto finalmente, veamos:
ubuntu@worker-0:~$ sudo cat /sys/class/net/veth71f7d238/ifindex 7
Genial, ahora todo está claro con el enlace virtual. Usando
brctl veamos quién más está conectado al puente de Linux:
ubuntu@worker-0:~$ brctl show cnio0 bridge name bridge id STP enabled interfaces cnio0 8000.0a580ac80001 no veth71f7d238 veth73f35410 vethf273b35f
Entonces, la imagen es la siguiente:
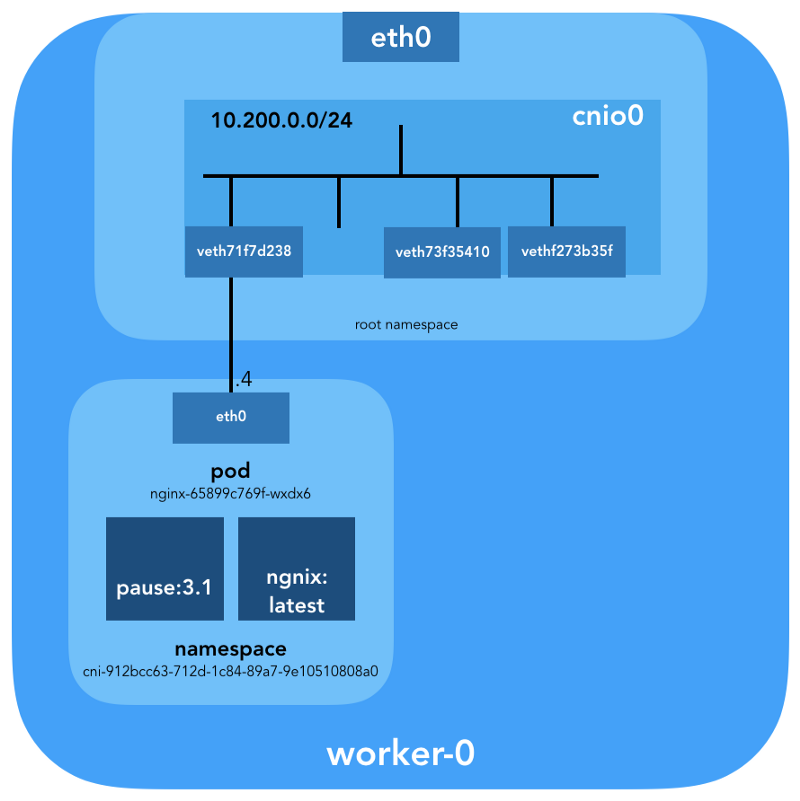
Verificación de enrutamiento
¿Cómo reenviamos el tráfico? Veamos la tabla de enrutamiento en el pod de espacio de nombres de red:
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ip route show default via 10.200.0.1 dev eth0 10.200.0.0/24 dev eth0 proto kernel scope link src 10.200.0.4
Al menos sabemos cómo llegar al espacio de nombres raíz (
default via 10.200.0.1 ). Ahora veamos la tabla de enrutamiento del host:
ubuntu@worker-0:~$ ip route list default via 10.240.0.1 dev eth0 proto dhcp src 10.240.0.20 metric 100 10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1 10.240.0.0/24 dev eth0 proto kernel scope link src 10.240.0.20 10.240.0.1 dev eth0 proto dhcp scope link src 10.240.0.20 metric 100
Sabemos cómo reenviar paquetes a un enrutador VPC (VPC
tiene un enrutador "implícito", que
generalmente tiene una segunda dirección desde el espacio de la dirección IP principal de la subred). Ahora: ¿El enrutador VPC sabe cómo llegar a la red de cada hogar? No, no lo hace, por lo tanto, se supone que las rutas serán configuradas por el complemento CNI o
manualmente (como en el manual). Aparentemente, el
complemento AWS CNI hace exactamente eso por nosotros en AWS. Recuerde que hay
muchos complementos CNI , y estamos considerando un ejemplo de una
configuración de red simple :
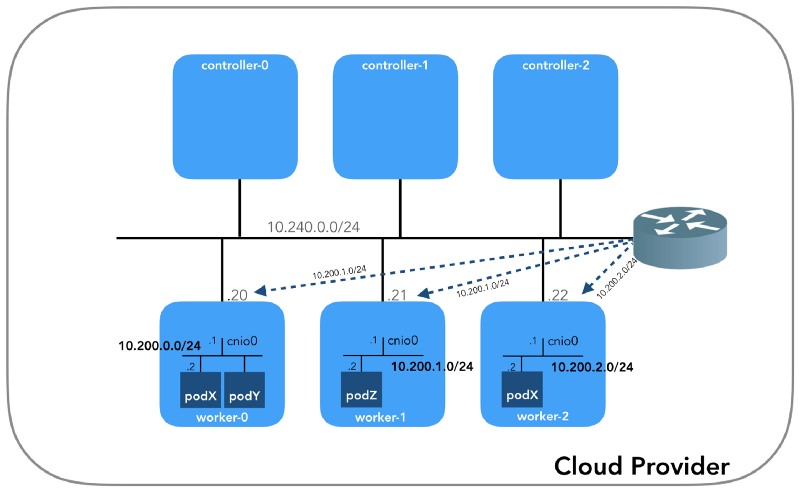
Inmersión profunda en NAT
kubectl create -f busybox.yaml cree dos contenedores
busybox idénticos con el Controlador de replicación:
apiVersion: v1 kind: ReplicationController metadata: name: busybox0 labels: app: busybox0 spec: replicas: 2 selector: app: busybox0 template: metadata: name: busybox0 labels: app: busybox0 spec: containers: - image: busybox command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always
(
busybox.yaml )
Obtenemos:
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-g6pww 1/1 Running 0 4s 10.200.1.15 worker-1 busybox0-rw89s 1/1 Running 0 4s 10.200.0.21 worker-0 ...
Los pings de un contenedor a otro deberían ser exitosos:
$ kubectl exec -it busybox0-rw89s -- ping -c 2 10.200.1.15 PING 10.200.1.15 (10.200.1.15): 56 data bytes 64 bytes from 10.200.1.15: seq=0 ttl=62 time=0.528 ms 64 bytes from 10.200.1.15: seq=1 ttl=62 time=0.440 ms --- 10.200.1.15 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.440/0.484/0.528 ms
Para comprender el movimiento del tráfico, puede mirar los paquetes usando
tcpdump o
conntrack :
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 29 src=10.200.0.21 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
La IP de origen del pod 10.200.0.21 se traduce a la dirección IP del host 10.240.0.20.
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 28 src=10.240.0.20 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
En iptables, puede ver que los recuentos están aumentando:
ubuntu@worker-0:~$ sudo iptables -t nat -Z POSTROUTING -L -v Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination ... 5 324 CNI-be726a77f15ea47ff32947a3 all -- any any 10.200.0.0/24 anywhere /* name: "bridge" id: "631cab5de5565cc432a3beca0e2aece0cef9285482b11f3eb0b46c134e457854" */ Zeroing chain `POSTROUTING'
Por otro lado, si elimina
"ipMasq": true de la configuración del complemento CNI, puede ver lo siguiente (esta operación se realiza exclusivamente con fines educativos: ¡no recomendamos cambiar la configuración en un clúster de trabajo!):
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-2btxn 1/1 Running 0 16s 10.200.0.15 worker-0 busybox0-dhpx8 1/1 Running 0 16s 10.200.1.13 worker-1 ...
Ping aún debe pasar:
$ kubectl exec -it busybox0-2btxn -- ping -c 2 10.200.1.13 PING 10.200.1.6 (10.200.1.6): 56 data bytes 64 bytes from 10.200.1.6: seq=0 ttl=62 time=0.515 ms 64 bytes from 10.200.1.6: seq=1 ttl=62 time=0.427 ms --- 10.200.1.6 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.427/0.471/0.515 ms
Y en este caso, sin usar NAT:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 29 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Por lo tanto, verificamos que "todos los contenedores pueden comunicarse con cualquier otro contenedor sin usar NAT".
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 27 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Red de clúster (10.32.0.0/24)
Es posible que haya notado en el ejemplo
busybox que las direcciones IP asignadas a
busybox eran diferentes en cada caso. ¿Qué pasaría si quisiéramos hacer que estos contenedores estén disponibles para la comunicación desde otros hogares? Se podrían tomar las direcciones IP actuales del pod, pero cambiarán. Por esta razón, debe configurar el recurso del
Service , que enviará las solicitudes a muchos hogares de corta duración.
"El servicio en Kubernetes es una abstracción que define el conjunto lógico de hogares y las políticas mediante las cuales se puede acceder". (de la documentación de Kubernetes Services )
Hay varias formas de publicar un servicio; el tipo predeterminado es
ClusterIP , que establece la dirección IP desde el bloque CIDR del clúster (es decir, accesible solo desde el clúster). Un ejemplo de ello es el complemento DNS Cluster configurado en Kubernetes The Hard Way.
# ... apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "KubeDNS" spec: selector: k8s-app: kube-dns clusterIP: 10.32.0.10 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP # ...
(
kube-dns.yaml )
kubectl muestra que el
Service recuerda puntos finales y los traduce:
$ kubectl -n kube-system describe services ... Selector: k8s-app=kube-dns Type: ClusterIP IP: 10.32.0.10 Port: dns 53/UDP TargetPort: 53/UDP Endpoints: 10.200.0.27:53 Port: dns-tcp 53/TCP TargetPort: 53/TCP Endpoints: 10.200.0.27:53 ...
¿Cómo exactamente? ..
iptables nuevamente. Veamos las reglas creadas para este ejemplo. Su lista completa se puede ver con el comando
iptables-save .
Tan pronto como los paquetes son creados por el proceso (
OUTPUT ) o llegan a la interfaz de red (
PREROUTING ), pasan a través de las siguientes cadenas de
iptables :
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
Los siguientes objetivos corresponden a paquetes TCP enviados al puerto 53 en 10.32.0.10, y se transmiten al destinatario 10.200.0.27 con el puerto 53:
-A KUBE-SERVICES -d 10.32.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4 -A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-SEP-32LPCMGYG6ODGN3H -A KUBE-SEP-32LPCMGYG6ODGN3H -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.200.0.27:53
Lo mismo para los paquetes UDP (destinatario 10.32.0.10:53 → 10.200.0.27:53):
-A KUBE-SERVICES -d 10.32.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRUTK6XRXU43VLIG -A KUBE-SEP-LRUTK6XRXU43VLIG -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.200.0.27:53
Hay otros tipos de
Services en Kubernetes. En particular, Kubernetes The Hard Way
NodePort sobre
NodePort ; consulte
Prueba de humo: Servicios .
kubectl expose deployment nginx --port 80 --type NodePort
NodePort publica el servicio en la dirección IP de cada nodo, colocándolo en un puerto estático (se llama
NodePort ).
NodePort puede acceder desde fuera del clúster. Puede verificar el puerto dedicado (en este caso - 31088) usando
kubectl :
$ kubectl describe services nginx ... Type: NodePort IP: 10.32.0.53 Port: <unset> 80/TCP TargetPort: 80/TCP NodePort: <unset> 31088/TCP Endpoints: 10.200.1.18:80 ...
Under ahora está disponible en Internet como
http://${EXTERNAL_IP}:31088/ . Aquí
EXTERNAL_IP es la dirección IP pública de
cualquier instancia de trabajo . En este ejemplo, utilicé la dirección IP pública de
trabajador-0 . La solicitud es recibida por un host con una dirección IP interna de 10.240.0.20 (el proveedor de la nube está comprometido en NAT pública), sin embargo, el servicio se inicia realmente en otro host (
trabajador-1 , que puede verse en la dirección IP del punto final - 10.200.1.18):
ubuntu@worker-0:~$ sudo conntrack -L | grep 31088 tcp 6 86397 ESTABLISHED src=173.38.XXX.XXX dst=10.240.0.20 sport=30303 dport=31088 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=30303 [ASSURED] mark=0 use=1
El paquete se envía desde
trabajador-0 a
trabajador-1 , donde encuentra su destinatario:
ubuntu@worker-1:~$ sudo conntrack -L | grep 80 tcp 6 86392 ESTABLISHED src=10.240.0.20 dst=10.200.1.18 sport=14802 dport=80 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=14802 [ASSURED] mark=0 use=1
¿Tal circuito es ideal? Quizás no, pero funciona. En este caso, las reglas de
iptables programadas son las siguientes:
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx:" -m tcp --dport 31088 -j KUBE-SVC-4N57TFCL4MD7ZTDA -A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -j KUBE-SEP-UGTFMET44DQG7H7H -A KUBE-SEP-UGTFMET44DQG7H7H -p tcp -m comment --comment "default/nginx:" -m tcp -j DNAT --to-destination 10.200.1.18:80
En otras palabras, la dirección del destinatario de los paquetes con el puerto 31088 se transmite el 10.200.1.18. El puerto también está transmitiendo, desde 31088 a 80.
No mencionamos otro tipo de servicio,
LoadBalancer , que hace que el servicio esté disponible públicamente utilizando un equilibrador de carga del proveedor de la nube, pero el artículo ya resultó ser extenso.
Conclusión
Puede parecer que hay mucha información, pero solo tocamos la punta del iceberg. En el futuro voy a hablar sobre IPv6, IPVS, eBPF y un par de complementos CNI actuales e interesantes.
PD del traductor
Lea también en nuestro blog: