
Hoy, finalmente, el programa principal de la conferencia ha comenzado. La tasa de aceptación este año fue solo del 8%, es decir debe ser lo mejor de lo mejor de lo mejor. Los flujos aplicados y de investigación están claramente separados, además hay varias actividades relacionadas por separado. Las transmisiones aplicadas parecen más interesantes, los informes provienen principalmente de las especialidades (Google, Amazon, Alibaba, etc.). Te contaré sobre las actuaciones a las que pude asistir.
Datos para bien
El día comenzó con una presentación suficientemente larga que los datos deberían ser útiles y utilizados para el bien. Está
hablando un
profesor de la Universidad de California (vale la pena señalar que hay muchas mujeres en KDD, tanto entre estudiantes como entre hablantes). Todo esto se expresa en la abreviatura FATES:
- Justicia: sin prejuicios en los pronósticos del modelo, todo es neutral y tolerante al género.
- Responsabilidad: debe haber alguien o algo responsable de las decisiones tomadas por la máquina.
- Transparencia: transparencia y explicabilidad de las decisiones.
- Ética: cuando se trabaja con datos, se debe hacer especial hincapié en la ética y la privacidad.
- Seguridad y protección: el sistema debe ser seguro (no dañino) y protegido (resistente a las influencias manipuladoras del exterior)
Este manifiesto, desafortunadamente, más bien expresa un deseo y está débilmente relacionado con la realidad. El modelo será políticamente correcto solo si se eliminan todos los signos; la responsabilidad de transferir a alguien específico siempre es muy difícil; cuanto más se desarrolla el DS, más difícil es interpretar lo que sucede dentro del modelo; sobre ética y privacidad, hubo algunos buenos ejemplos el primer día, pero de lo contrario, los datos a menudo se tratan con bastante libertad.
Bueno, uno no puede dejar de admitir que los modelos modernos a menudo no son seguros (un piloto automático puede deshacerse de un automóvil con conductor) y no están protegidos (puede recoger ejemplos que rompen el trabajo de una red neuronal sin siquiera saber cómo funciona la red). Un trabajo reciente e interesante de
DeepExplore : un sistema para buscar vulnerabilidades en redes neuronales genera, entre otras cosas, imágenes que hacen que el piloto automático se desvierta.

La siguiente es otra definición de Data Science como "DS es el estudio de extracción de datos de forma de valor". En principio, bastante bien. Al comienzo del discurso, el orador mencionó específicamente que DS a menudo mira los datos solo desde el momento del análisis, mientras que el ciclo de vida completo es mucho más amplio, y esto, entre otras cosas, se reflejó en la definición.
Bueno, hubo algunos ejemplos de trabajo de laboratorio.
Nuevamente analizaremos la tarea de evaluar la influencia de muchos factores en el resultado, pero no desde la posición de la publicidad, sino en general. Hay un
artículo aún no publicado. Considere, por ejemplo, la cuestión de qué actores elegir para la película para reunir una buena taquilla. Analizamos las listas de actuación de las películas más taquilleras y tratamos de predecir la contribución de cada uno de los actores. Pero! Existen los llamados
factores de confusión que afectan la efectividad de un actor (por ejemplo, a Stallone le irá bien en una película de acción de thrash, pero no en una comedia romántica). Para elegir el correcto, debe encontrar todos los factores de confusión y evaluarlos, pero nunca estaremos seguros de haber encontrado a todos. En realidad, el artículo propone un nuevo enfoque: desconfigurador. En lugar de resaltar los factores de confusión, introducimos explícitamente variables latentes y las evaluamos en un modo no supervisado, y luego estudiamos el modelo basado en ellas. Todo suena bastante extraño, porque parece una variante simple de incrustaciones, lo nuevo no está claro.
Se mostraron algunas bellas imágenes, ejemplos de cómo avanzan en la IA de su universidad, etc.
Comercio electrónico y perfilado
Fui a la sección de aplicaciones sobre comercio. Al principio hubo algunos informes muy interesantes, al final hubo una cierta cantidad de gachas, pero primero lo primero.
Nuevo usuario modelado y predicción de abandono
El interesante
trabajo de Snapchat para predecir flujos de salida. Los chicos usan la idea, que también ejecutamos con éxito hace unos 4 años: antes de predecir el flujo de salida, los usuarios deben dividirse en grupos según el tipo de comportamiento. Al mismo tiempo, el espacio vectorial por los tipos de acciones que resultaron ser bastante pobres, de solo unos pocos tipos de interacciones (nosotros, a su debido tiempo, tuvimos que hacer una selección de signos para pasar de trescientos a uno y medio), pero enriquecen el espacio con estadísticas adicionales y lo consideran como una serie de tiempo , como resultado, los clústeres se obtienen no tanto sobre lo que hacen los usuarios, sino sobre
la frecuencia con que lo hacen.
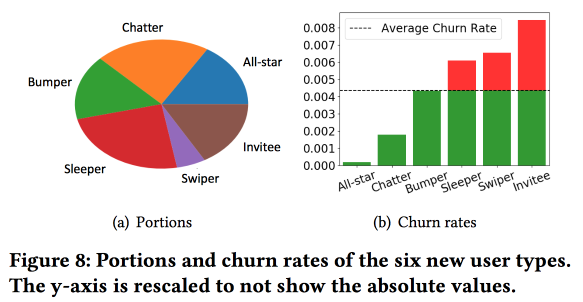
Una observación importante: la red tiene el "núcleo" de los usuarios más conectados y activos con un tamaño de 1,7 millones de personas. Al mismo tiempo, el comportamiento y la retención del usuario dependen en gran medida de si puede comunicarse con alguien del "núcleo".
Entonces comenzamos a construir un modelo. Tomemos a los recién llegados en una quincena (511 mil), características simples y redes de ego (tamaño y densidad), y veamos si están asociados con el "núcleo", etc. Alimentamos el comportamiento del usuario con LSTM y obtenemos la precisión del pronóstico de salida ligeramente más alta que la de logreg (en un 7-8%). Pero entonces comienza la diversión. Para tener en cuenta los detalles de los clústeres individuales, entrenaremos varios LSTM en paralelo y adjuntaremos una capa de atención en la parte superior. Como resultado, dicho esquema comienza a funcionar tanto en la agrupación (cuál de los LSTM recibió atención) como en el pronóstico de salida. Proporciona otro aumento de calidad de + 5-7%, y logreg ya se ve pálido. Pero! En realidad, sería justo compararlo con un registro segmentado entrenado por separado para grupos (que se puede obtener de manera más simple).
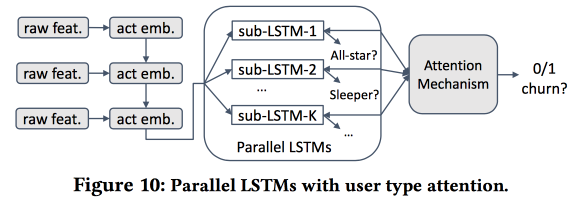
Pregunté sobre la interpretabilidad: después de todo, los flujos de salida a menudo se predicen no para obtener un pronóstico, sino para comprender qué factores influyen en él. El orador estaba claramente listo para esta pregunta: para esto, se usan y analizan grupos dedicados, que aquellos en los que los pronósticos de salida son más altos se distinguen de los demás.
Representación universal del usuario
Los chicos de Alibaba
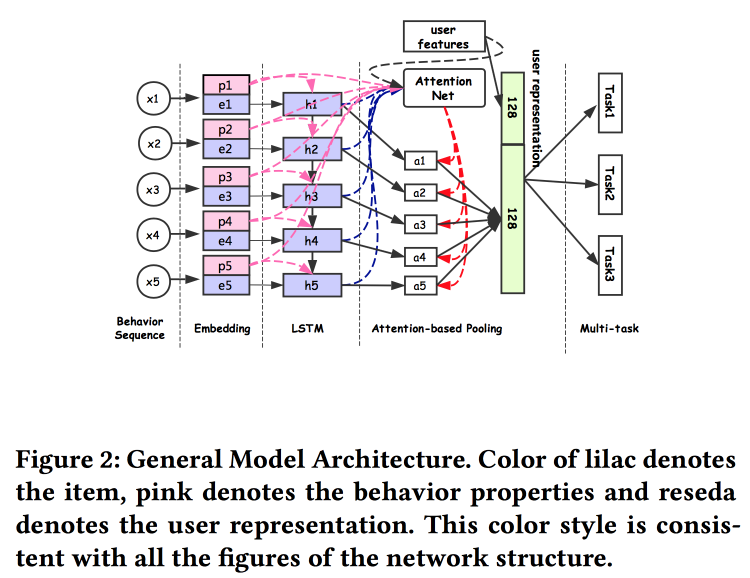
hablan sobre cómo construir asociaciones de usuarios. Resulta que tener muchos envíos de usuarios es malo: muchos no están finalizados, las fuerzas se desperdician. Se las arreglaron para hacer una presentación universal y mostrar que funciona mejor. Naturalmente en redes neuronales. La arquitectura es bastante estándar, ya de una forma u otra se ha descrito repetidamente en la conferencia. Los datos del comportamiento del usuario se introducen en la entrada, los desarrollamos, le damos todo a LSTM, colgamos una capa de atención en la parte superior y, al lado, una cuadrícula adicional para características estáticas, coronando con una multitarea (de hecho, varias cuadrículas pequeñas para una tarea específica) . Entrenamos todo esto juntos, la salida con atención será la incrustación del usuario.
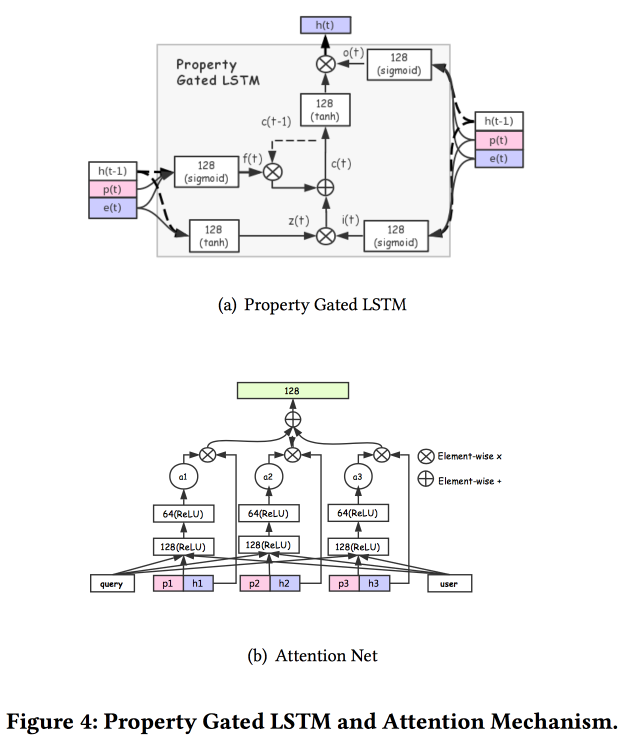
Hay varias adiciones más complejas: además de la atención simple, agregan una red de atención "en profundidad", y también usan una versión modificada de LSTM - LSTM de propiedad cerrada
Tareas en las que se ejecuta todo esto: predicción de CTR, predicción de preferencia de precio, aprender a clasificar, predicción de seguimiento de moda, predicción de preferencia de tienda. El conjunto de datos para 10 días incluye 6 * 10
9 ejemplos de capacitación.
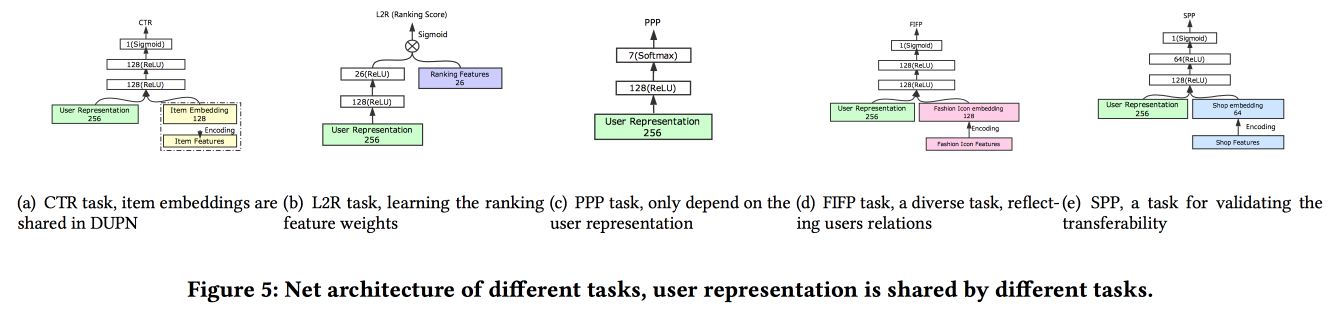
Luego hubo una persona inesperada: entrenaron todo esto en TensorFlow, en un clúster de CPU de 2000 máquinas con 15 núcleos cada una, lleva 4 días completar los datos durante 10 días. Por lo tanto, continúan entrenando día tras día (10 horas en este grupo). Acerca de GPU / FPGA no tuve tiempo de preguntar :(. La adición de una nueva tarea se realiza a través del reentrenamiento en su conjunto o mediante el reentrenamiento de una cuadrícula poco profunda (ajuste fino de red). Las tareas específicas de la prueba A / B mostraron un aumento del 2-3% para varios indicadores.
Predicción de retorno del producto E-tail
Ellos predicen la devolución de bienes por parte del usuario después de la compra, el
trabajo es presentado por IBM. Desafortunadamente, no hay texto en acceso abierto hasta ahora. Devolver bienes es un problema grave por valor de $ 200 mil millones al año. Para construir un pronóstico de rendimiento, utiliza un modelo de hipergrafía que conecta productos y cestas, utilizando esta cesta intentan encontrar los más cercanos por hipergrafía, después de lo cual estiman la probabilidad de un retorno. Para evitar una devolución, una tienda en línea tiene muchas posibilidades, por ejemplo, ofreciendo un descuento por retirar ciertos productos de la cesta.
Inmediatamente notamos que hay una diferencia significativa entre canastas con duplicados (por ejemplo, dos camisetas idénticas de diferentes tamaños) y sin ellas, por lo tanto, debemos construir modelos diferentes para estos dos casos.
El algoritmo general se llama HyperGo:
- Estamos construyendo una hipergrafía para representar compras y devoluciones con información del usuario, producto, cesta.
- Luego, usamos el corte del gráfico local basado en una caminata aleatoria para obtener información local para el pronóstico.
- Consideramos por separado las canastas con tomas y sin tomas.
- Utilizamos métodos bayesianos para evaluar el impacto de un producto individual en la canasta.
Compare la calidad de la previsión de rentabilidad con KNN para cestas, ponderada según Jacquard KNN, racionando por el número de duplicados, obtenemos un aumento en el resultado. Un enlace a GitHub parpadeó en las diapositivas, pero no pudieron encontrar su fuente, y no hay ningún enlace en el artículo.
OpenTag: extracción de valor de atributo abierto de perfiles de producto
Interesante
trabajo de Amazon. Desafío: mina varios hechos para que Alexa responda mejor las preguntas. Dicen lo complicado que es todo, los viejos sistemas no saben cómo trabajar con nuevas palabras, a menudo requieren una gran cantidad de reglas escritas a mano y heurísticas, los resultados son más o menos. Por supuesto, las redes neuronales con la arquitectura de atención embednig-LSTM ya familiar ayudarán a resolver todos los problemas, pero haremos que LSTM se doble, y también
colocaremos el campo aleatorio condicional en la parte superior.

Resolveremos el problema de etiquetar una secuencia de palabras. Las etiquetas mostrarán dónde comenzamos y terminamos las secuencias de ciertos atributos (por ejemplo, el sabor y la composición de la comida para perros), y LSTM intentará predecirlos. Como un moño y una reverencia hacia Mechanical Turk, se utiliza el entrenamiento de modelo activo. Para seleccionar ejemplos que deben enviarse para un marcado adicional, use la heurística "para tomar esos ejemplos donde las etiquetas se intercambian con mayor frecuencia entre eras".
Aprendizaje y transferencia de representaciones de ID en comercio electrónico
En su
trabajo, los colegas de Alibaba vuelven nuevamente al tema de la construcción de empotramientos, esta vez mirando no solo a los usuarios, sino también a los ID en principio: para productos, marcas, categorías, usuarios, etc. Las sesiones de interacción se utilizan como fuente de datos y también se tienen en cuenta atributos adicionales. Los saltosgramas se utilizan como el algoritmo principal.
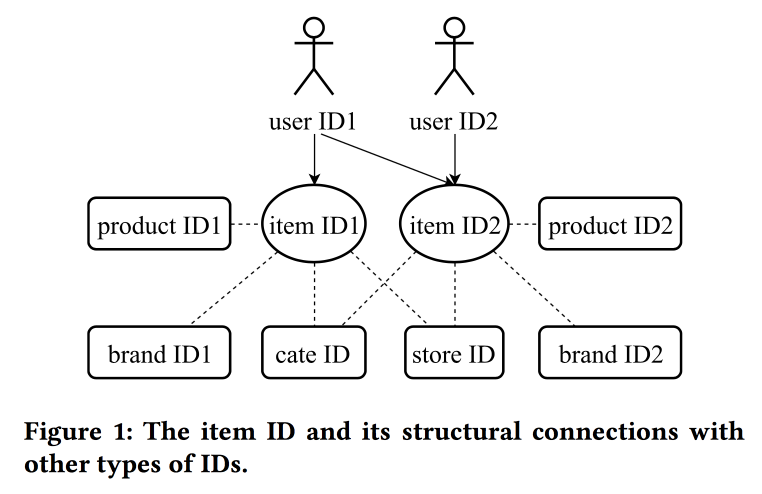
El hablante tiene una pronunciación muy fuerte con un fuerte acento chino, para entender lo que está sucediendo es casi imposible. Uno de los "trucos" del trabajo es la mecánica de transferir representaciones con falta de información, por ejemplo, de elementos al usuario a través del promedio (rápidamente, no es necesario que aprenda todo el modelo). A partir de elementos antiguos, puede inicializar otros nuevos (aparentemente por similitud de contenido), así como transferir la vista del usuario de un dominio (electrónica) a otro (ropa).
En general, no está del todo claro dónde está la novedad, aparentemente, los detalles necesitan ser desenterrados; Además, no está claro cómo esto se compara con la historia anterior sobre las representaciones unificadas de los usuarios.
Selección de parámetros en línea para problemas de clasificación basados en la web
Muy interesante el
trabajo de amigos en LinkedIn. La esencia del trabajo es seleccionar los parámetros óptimos de la operación del algoritmo en línea, teniendo en cuenta varios objetivos en competencia. Como alcance, considere la cinta e intente aumentar el número de sesiones de ciertos tipos:
- Sesión con alguna acción viral (AV).
- Reanudar sesión de envío (JA).
- Interacción de contenido en la sesión Feed (EFS).
La función de clasificación en el algoritmo es un promedio ponderado de los pronósticos de conversión para estos tres objetivos. En realidad, los pesos son aquellos parámetros que intentaremos optimizar en línea. Inicialmente, formulan una tarea empresarial como "maximizar el número de sesiones de virus mientras mantienen los otros dos tipos al menos en un cierto nivel", pero luego los transforman un poco para facilitar la optimización.
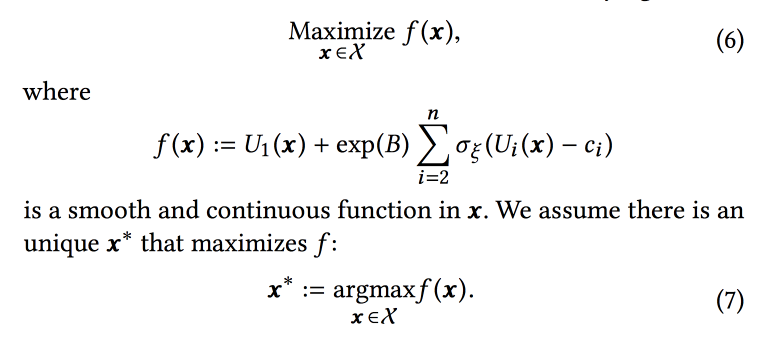
Simulamos los datos con un conjunto de distribuciones binomiales (el usuario se convertirá al objetivo deseado o no, habiendo visto la cinta con ciertos parámetros), donde la probabilidad de éxito con los parámetros dados es un
proceso gaussiano (propio para cada tipo de conversión). A continuación, usamos la
muestra de Thompson con bandidos "infinitamente
resistentes " para seleccionar los parámetros óptimos (no en línea, sino fuera de línea en datos históricos, por lo que durante mucho tiempo). Dan algunos consejos: use puntos en negrita para construir la cuadrícula inicial y asegúrese de agregar
un muestreo
codicioso de epsilon (con la probabilidad de que epsilon intente un punto aleatorio en el espacio), de lo contrario, puede pasar por alto el máximo global.
Simulan tomar muestras fuera de línea una vez por hora (necesita muchas muestras), el resultado es una cierta distribución de parámetros óptimos. Además, cuando un usuario ingresa desde esta distribución, toma parámetros específicos para construir la cinta (es importante hacer esto consistentemente con la semilla del ID de usuario para la inicialización, de modo que la cinta del usuario no cambie radicalmente).
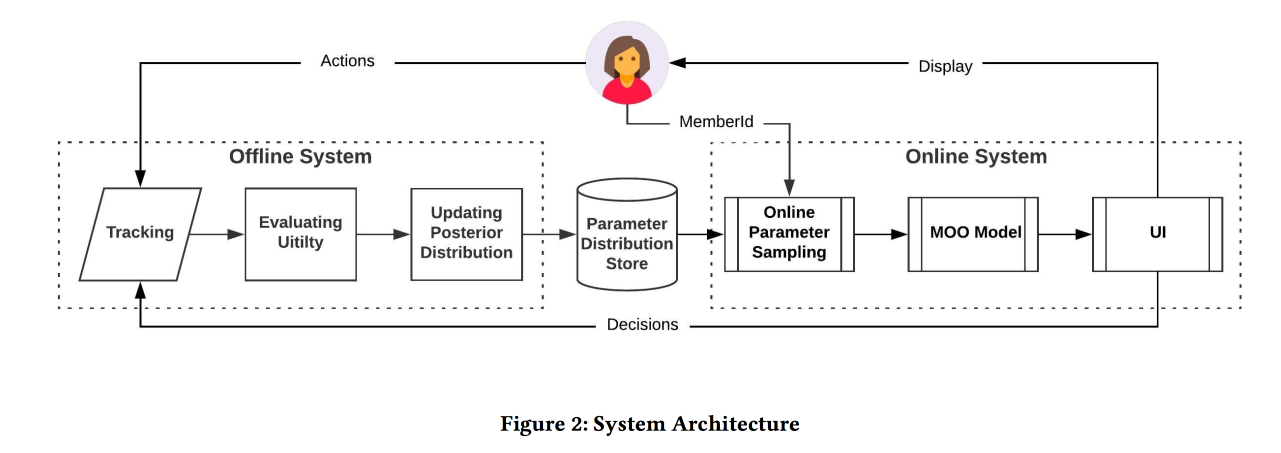
Según los resultados del experimento A / B, recibieron un aumento en el envío de currículums en un 12% y me gusta en un 3%. Comparte algunas observaciones:
- Es más fácil probar más que intentar agregar más información al modelo (por ejemplo, el día de la semana / hora).
- Asumimos independencia de objetivos en este enfoque, pero no está claro si lo es (más bien, no). Sin embargo, el enfoque funciona.
- Las empresas deben establecer objetivos y umbrales.
- Es importante excluir a una persona del proceso y dejar que haga algo útil.
Optimización casi en tiempo real de notificaciones basadas en actividades
Otro
trabajo de LinkedIn, esta vez sobre la gestión de notificaciones. Tenemos personas, eventos, canales de entrega y objetivos a largo plazo para aumentar la participación del usuario sin una negatividad significativa en forma de quejas y cancelaciones de suscripciones. La tarea es importante y difícil, y debe hacer todo bien: a las personas adecuadas en el momento adecuado para enviar el contenido correcto en el canal correcto y en la cantidad correcta.
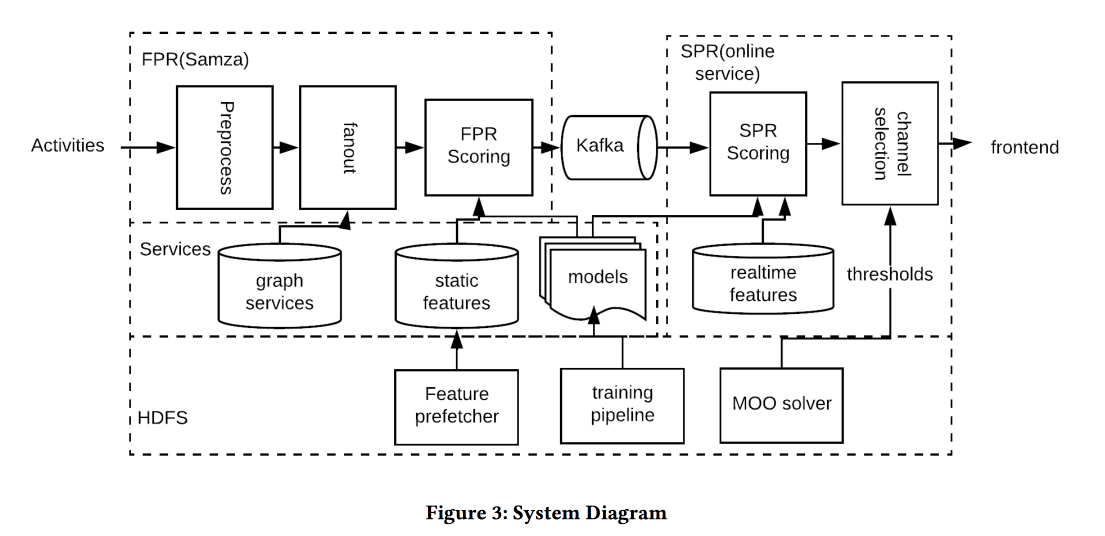
La arquitectura del sistema en la imagen de arriba, la esencia de lo que está sucediendo es aproximadamente la siguiente:
- Filtramos cualquier spam en la entrada.
- Personas adecuadas: un casco para todos los que están fuertemente conectados con el autor / contenido, equilibrando el umbral de la fuerza de la comunicación, gestionando la cobertura y la relevancia.
- El momento adecuado: envíe contenido de inmediato, para lo cual es importante (eventos de amigos), el resto se puede guardar para canales menos dinámicos.
- El contenido correcto: ¡usa logreg! Se construye un modelo de pronóstico de un clic en un montón de signos, por separado para el caso cuando una persona está en la aplicación y cuando no.
- Canal correcto: establecemos diferentes umbrales de relevancia, el más estricto para presionar, más bajo, si el usuario ahora está en la aplicación, incluso más bajo, para el correo (contiene todo tipo de resúmenes / anuncios).
- Volumen correcto: el modelo de circuncisión por volumen está en la salida, también considera la relevancia, se recomienda hacerlo individualmente (un buen umbral heurístico es una puntuación mínima de los objetos enviados en los últimos días)
En la prueba A / B recibió un pequeño aumento en el número de sesiones.
Personalización en tiempo real usando incrustaciones para el ranking de búsqueda en Airbnb
Y ese fue el
mejor documento de solicitud de AirBnB. Objetivo: optimizar la emisión de ubicaciones y resultados de búsqueda similares. Decidimos a través de la construcción de incrustaciones de ubicaciones y usuarios en un espacio para evaluar aún más la similitud. Es importante recordar que existe un historial a largo plazo (preferencias del usuario) y a corto plazo (intención del usuario / sesión actual).
Sin más preámbulos, usamos para construir ubicaciones de word2vec en secuencias de clics en sesiones de búsqueda (una sesión - un documento). Pero aún hacemos algunas modificaciones (KDD, después de todo):
- Tomamos la sesión durante la cual hubo una reserva.
- Lo que en última instancia está reservado, lo mantenemos como un contexto global para todos los elementos de la sesión durante la actualización de w2v.
- Los negativos en el entrenamiento se muestrean en la misma ciudad.

La efectividad de dicho modelo se verifica de tres maneras estándar:
- Comprobar sin conexión: qué tan rápido podemos subir al hotel correcto en la sesión de búsqueda.
- Pruebas realizadas por asesores: construyeron una herramienta especial para visualizar otras similares.
- Prueba A / B: spoiler, CTR ha crecido significativamente, las reservas no han aumentado, pero ahora suceden antes
Intentamos clasificar los resultados de los resultados de búsqueda no solo por adelantado, sino también para reorganizar (por lo tanto, en tiempo real) al recibir una respuesta: haga clic en una oración e ignore otra. El enfoque consiste en recopilar los lugares cliqueados e ignorados en dos grupos, encontrar incrustaciones en cada centroide (hay una fórmula especial) y luego, en la clasificación, aumentamos los clics, bajamos como saltos.
La prueba A / B recibió un aumento en las reservas, el enfoque resistió la prueba del tiempo: se inventó hace un año y medio y todavía está girando en producción.
¿Y si necesitas buscar en otra ciudad? No podrá priorizar con clics, no hay información sobre la actitud de los usuarios hacia los lugares en este acuerdo. Para evitar este problema, presentamos "incrustaciones de contenido". Primero, crearemos un espacio discreto simple de letreros (barato / costoso, en el centro / en las afueras, etc.) del tamaño de aproximadamente 500 mil tipos (para lugares y personas). A continuación, construimos incrustaciones por tipo. Cuando aprenda, no olvide agregar un claro negativo en las denegaciones (cuando el propietario del lugar no haya confirmado la reserva).
Graficar redes neuronales convolucionales para sistemas de recomendación a escala web
Trabaja desde Pinterest por recomendación de alfileres. Consideramos los pines de usuario del gráfico bipartito y agregamos características de red a las recomendaciones. El gráfico es muy grande: 3 mil millones de pines, 16 mil millones de interacciones; no se pudieron realizar incrustaciones de gráficos clásicos. ,
GraphSAGE , ( , message passing),
PinSAGE . , , .
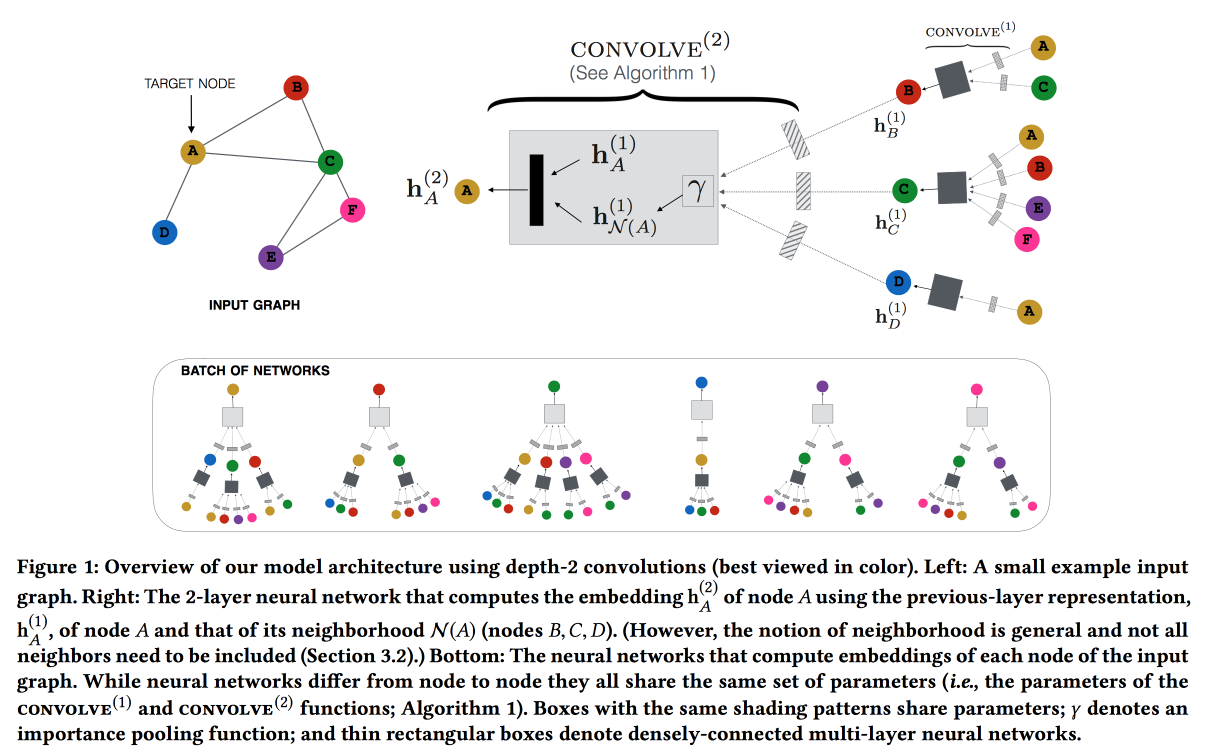
« »:
- max margin loss.
- CPU/GPU: CPU ( GPU ) GPU. , .
- , random walk-.
- Curriculum Learning: hard negative-. .
- Map reduce, .
, , . , /-.
Q&R: A Two-Stage Approach Toward Interactive Recommendation
« , , ?» — YouTube
. : « ?». «» (, , YouTube , ).
YouTube Video-RNN, ID . , ID , (post fusion). (- -
GRU , LSTM LSTM).

7 , 8-, . , 8 % , --. /-
interleaving- +0,7 % , +1,23 % .
: 18 % , +4 % .
Graph and social nets
, , , .
Graph Classification using Structural Attention
, « ». , , .
, , .
, LSTM , attention-, , . . , , , .
: , , . attention, , LSTM self-attention, ( ). «», , .
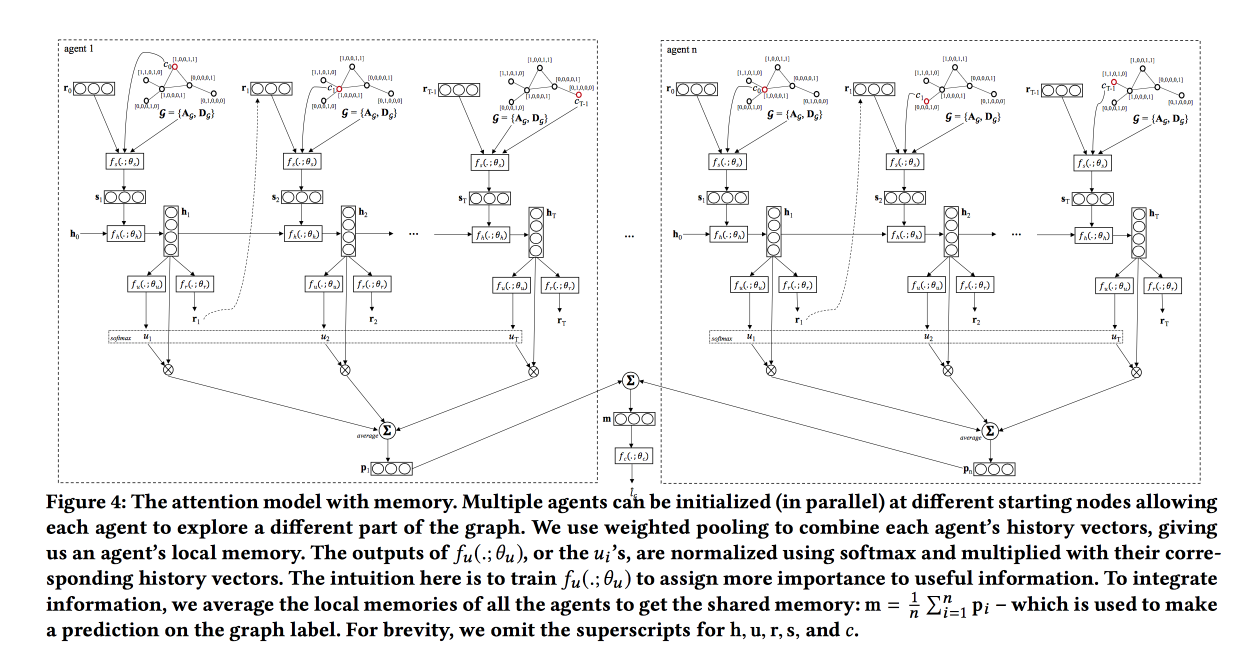
, baseline — . ,
TreeLSTM .
SpotLight: Detecting Anomalies in Streaming Graphs
, , -, , . « ». , , .
«» . - - , .
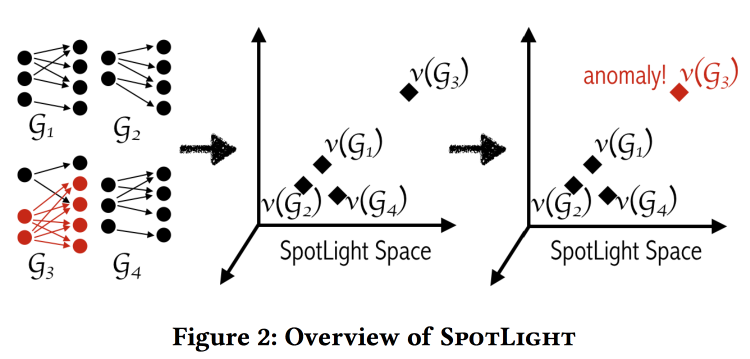
: , . . . , / .
, .
labeled DARPA dataset . , baseline- (.. ).
Adversarial Attacks on Graph Networks
. Adversary , , ..: / . , — ( — )? .
, :
- «» .
- «» .
- «» .
- , (poisoning).
. , , , — . . .
, unnoticeability: , ?
Multi-Round Influence maximization
. , , .
, ( , ).
-- :
- : , .
- : , .
- - : inffluencer- . , .
Reverse-Reachable sets: inffluencer-, , .
EvoGraph: An Effective and Efficient Graph Upscaling Method for Preserving Graph Properties
. ,
, .
, , power law. , , «» , : «» .

, , .
.
data science . De hecho , . .
All models are wrong, but some are useful — data science, , , . «» ( , , adversarial ..)
www.embo.org/news/articles/2015/the-numbers-speak-for-themselves — (overfitting, selection bias, , ..)
1762
The Equitable Life Assurance Society , .
Ahora las compañías de seguros lo pasan mal: en 2011, la discriminación por motivos de sexo finalmente se prohibió, ahora no se puede tener en cuenta el género en los seguros (lo cual es muy difícil, incluso si oculta explícitamente la característica "género", es probable que el modelo se aproxime por otras razones). Esto llevó a un efecto interesante en el Reino Unido:- Las mujeres conducen con mayor precisión y tienen menos probabilidades de tener accidentes, por lo que el seguro era más barato para ellas.
- Después de nivelar, el costo del seguro para las mujeres aumentó y para los hombres disminuyó.
- El mercado funciona: como resultado, hay más hombres y menos mujeres en las carreteras.
- A medida que la "precisión" promedio de los conductores en las carreteras disminuyó, hubo más accidentes.
- Después de lo cual, el seguro, por supuesto, comenzó a subir de precio.
- Los seguros de viaje comenzaron a eliminar aún más a los conductores limpios.
Como resultado, obtuvieron la "espiral de la muerte".
Este tema se hace eco de la presentación de apertura del día. F - Justicia, este es un castillo de nubes inalcanzable. Los modelos de ML aprenden a separar ejemplos (incluidas las personas) en el espacio de atributos, por lo tanto, no pueden ser "justos" por definición.