
Del 18 al 19 de agosto, Tele2 organizó un Data Science Hackathon. Este hackathon se enfoca en el análisis de diálogos de soporte técnico en redes sociales, acelerando y simplificando las interacciones con los clientes.
La tarea no tenía una métrica específica que necesitaba ser optimizada; la tarea podría inventarse por usted mismo. Lo principal es mejorar el servicio. El jurado de la competencia fueron los directores de varias áreas de Tele2, así como Pavel Pleskov, el conocido en la comunidad de ciencia de datos del gran maestro de Kaggle.
Debajo del corte, la historia del equipo que tomó el 1er lugar.
Cuando un colega me invitó a participar en este hackathon, acepté bastante rápido.
Estaba interesado en el tema de PNL, y también había algunos desarrollos de redes neuronales que quería probar en la práctica.
Los organizadores de Hackathon enviaron pequeños fragmentos de conjuntos de datos por adelantado que daban una idea de qué tipo de datos estaría disponible en el evento.
Los datos resultaron ser bastante sucios, los trolls extraños entraron en los diálogos, no siempre era obvio qué tipo de pregunta responde el operador.
Se hizo evidente que no sería fácil implementar la idea en las 24 horas asignadas, así que me tomé 1 día libre del trabajo y lo dediqué a preparar la red neuronal que quería probar. Esto nos permitió no perder el tiempo del hackathon buscando errores, sino centrarnos en casos de aplicaciones y negocios.
La oficina de Tele2 se encuentra en el territorio de Nueva Moscú en el parque empresarial Rumyantsevo. En cuanto a mí, llegar allí durante bastante tiempo, pero el parque empresarial causa una buena impresión (con la excepción de las líneas eléctricas).
 Líneas eléctricas contra el fondo de un centro de negocios
Líneas eléctricas contra el fondo de un centro de negociosJusto en la estación de metro, los organizadores nos recibieron y nos mostraron cómo llegar a la oficina. El edificio del centro de negocios en sí está ocupado por muchas empresas, la oficina de Tele2 se encuentra en el quinto piso. A los participantes de Hackathon se les asignó un área especial dentro de la oficina, había una cocina, un área de relajación con una PlayStation y otomanas. Particularmente satisfecho con la velocidad del wi-fi, no se observaron problemas inherentes a los eventos en masa.
 Desayuno
DesayunoEl conjunto de datos real proporcionado por Tele2 consistió en 3 grandes archivos CSV con diálogos de soporte técnico: diálogos en redes sociales, telegramas y correo electrónico. En total, más de 4 millones de visitas son lo que necesita para entrenar una red neuronal.
¿Qué era una red neuronal?
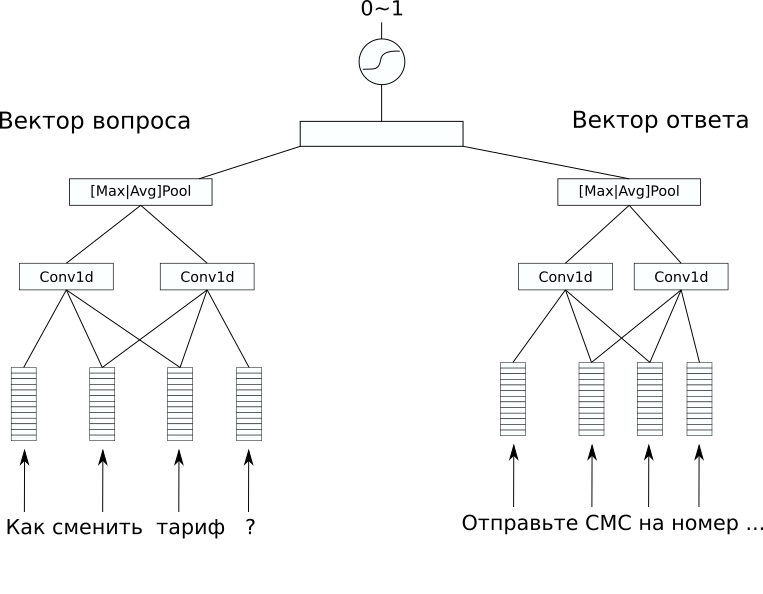 Arquitectura de red
Arquitectura de redEn el conjunto de datos no hubo un marcado adicional que sería interesante predecir, pero quería resolver un problema supervisado. Por lo tanto, decidimos intentar predecir las respuestas a las preguntas, por lo que se puede hacer al menos un simple bot de chat de dicho modelo. Para esto, elegimos la arquitectura CDSSM (Modelo de similitud semántica profunda de convolución). Este es uno de los modelos simples de redes neuronales para comparar textos por significado, que fue originalmente propuesto por Microsoft para clasificar los resultados de búsqueda de Bing.
Su esencia es la siguiente: primero, cada texto se convierte en un vector usando una secuencia de convolución y capas de agrupación.
Luego, los vectores resultantes se comparan de alguna manera. En nuestro problema, una capa lineal adicional que combina ambos vectores con un sigmoide como función de activación dio un buen resultado. Los pesos de la red que codifica las oraciones en vectores pueden ser los mismos para un par de textos (tales redes se llaman siameses) y pueden diferir.
En nuestro caso, la variante con diferentes pesos dio el mejor resultado, ya que los textos de la pregunta y la respuesta fueron significativamente diferentes.
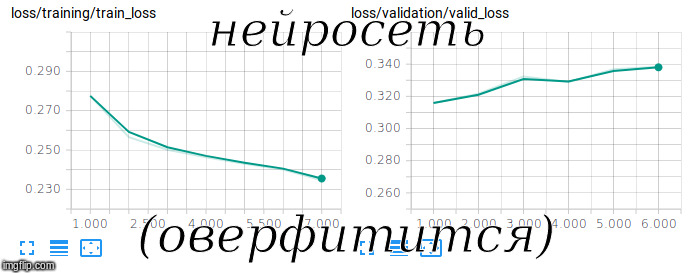 Intentando entrenar una red siamesa
Intentando entrenar una red siamesaFastText con RusVectōrēs se utilizó como
incrustaciones pre-entrenadas; es resistente a los errores tipográficos, que a menudo se encuentran en las preguntas de los usuarios.
Para entrenar un modelo de este tipo, necesita ser entrenado no solo en ejemplos positivos, sino también negativos. Para hacer esto, agregamos pares aleatorios de preguntas y respuestas en una proporción de 1 a 10 al conjunto de entrenamiento.
Para evaluar la calidad en una muestra tan desequilibrada, se utilizó la métrica ROC-AUC. Después de 3 horas de entrenamiento en la GPU, logramos alcanzar un valor de 0.92 en esta métrica.
Con este modelo, es posible resolver no solo el problema directo, elegir la respuesta adecuada a la pregunta, sino también lo contrario, encontrar errores del operador, respuestas de baja calidad y extrañas a las preguntas de los usuarios.
Logramos encontrar algunas de estas respuestas directamente en el hackathon e incluirlas en la presentación final. Me parece que esto causó la mayor impresión en el jurado.
También se puede encontrar una aplicación interesante en la representación vectorial de textos que la red genera en el proceso de su trabajo.
Al usarlo, puede buscar anomalías en las preguntas y respuestas mediante
varios métodos no supervisados .
Como resultado, nuestra decisión fue bien tomada tanto desde el punto de vista técnico como desde el punto de vista comercial. El resto de los equipos, básicamente, intentaron resolver el problema del análisis clave y el modelado temático, por lo que nuestra solución difirió favorablemente. Como resultado, tomamos el 1er lugar, nos separamos satisfechos y cansados.
 En la foto (de izquierda a derecha): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (autor) y Shvetsov Egor
En la foto (de izquierda a derecha): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (autor) y Shvetsov Egor¿Qué más leer?