
Muchas personas que estudian el aprendizaje automático están familiarizadas con el proyecto OpenAI, uno de los fundadores del cual es Elon Musk, y utilizan la plataforma
OpenAI Gym para entrenar sus modelos de redes neuronales.
El gimnasio contiene un gran conjunto de entornos, algunos de ellos son varios tipos de simulaciones físicas: los movimientos de animales, humanos,
robots . Estas simulaciones se basan en el motor de física
MuJoCo , que es gratuito con fines educativos y científicos.
En este artículo, crearemos una simulación física extremadamente simple similar al entorno OpenAI Gym, pero basada en el motor de física gratuito Bullet (
PyBullet ). Y también cree un agente para trabajar con este entorno.
PyBullet es un módulo de Python para crear un entorno de simulación física basado en el motor de física
Bullet Physics . Al igual que MuJoCo, a menudo se usa como estimulación de varios robots, que están interesados en tener
un artículo con ejemplos reales.
Hay una Guía de inicio
rápido bastante buena para PyBullet que contiene enlaces a ejemplos en la página de origen en
GitHub .
PyBullet le permite cargar modelos ya creados en formato URDF, SDF o MJCF. En las fuentes hay una biblioteca de
modelos en estos formatos, así como entornos completamente simulados de simuladores de
robots reales.En nuestro caso, nosotros mismos crearemos el entorno usando PyBullet. La interfaz del entorno será
similar a la interfaz de OpenAI Gym. De esta manera podemos capacitar a nuestros agentes tanto en nuestro entorno como en el entorno del gimnasio.
Todo el código (iPython), así como el funcionamiento del programa, se pueden ver en
Google Colaboratory .
Medio ambiente
Nuestro entorno consistirá en una pelota que puede moverse a lo largo del eje vertical dentro de un cierto rango de alturas. La pelota tiene masa y la gravedad actúa sobre ella, y el agente debe, controlando la fuerza vertical aplicada a la pelota, llevarla al objetivo. La altitud objetivo cambia con cada reinicio de la experiencia.

La simulación es muy simple y, de hecho, puede considerarse como una simulación de algún motor elemental.
Para trabajar con el entorno, se utilizan 3 métodos:
restablecer (reiniciar el experimento y crear todos los objetos del entorno),
paso (aplicar la acción seleccionada y obtener el estado resultante del entorno),
renderizar (visualización visual del entorno).
Al inicializar el entorno, es necesario conectar nuestro objeto a la simulación física. Hay 2 opciones de conexión: con una interfaz gráfica (GUI) y sin (DIRECTA). En nuestro caso, es DIRECTA.
pb.connect(pb.DIRECT)
restablecer
Con cada nuevo experimento, restablecemos la simulación
pb.resetSimulation () y creamos todos los objetos del entorno nuevamente.
En PyBullet, los objetos tienen 2 formas: una
forma de colisión y una
forma visual . El primero lo utiliza el motor físico para calcular colisiones de objetos y, para acelerar el cálculo de la física, generalmente tiene una forma más simple que un objeto real. El segundo es opcional y se usa solo cuando se forma la imagen del objeto.
Los formularios se recopilan en un solo objeto (cuerpo):
MultiBody . Un cuerpo puede estar formado por una forma (par
CollisionShape / Visual Shape ), como en nuestro caso, o varias.
Además de las formas que componen el cuerpo, es necesario determinar su masa, posición y orientación en el espacio.
Algunas palabras sobre cuerpos de múltiples objetos.Como regla, en casos reales, para simular varios mecanismos, se utilizan cuerpos que consisten en muchas formas. Al crear el cuerpo, además de la forma básica de colisiones y visualización, se transfieren al cuerpo cadenas de formas de objetos secundarios (
Enlaces ), su posición y orientación con respecto al objeto anterior, así como los tipos de conexiones (articulaciones) de los objetos entre sí (
Junta ). Los tipos de conexiones pueden ser fijas, prismáticas (deslizándose en el mismo eje) o rotacionales (girando en un eje). Los últimos 2 tipos de conexiones le permiten configurar los parámetros de los tipos de motores correspondientes (
JointMotor ), como la fuerza de actuación, la velocidad o el par, simulando así los motores de las "articulaciones" del robot. Más detalles en la
documentación .
Crearemos 3 cuerpos: Ball, Plane (Earth) y Target Pointer. El último objeto tendrá solo una forma de visualización y masa cero, por lo tanto, no participará en la interacción física entre los cuerpos:
Defina la gravedad y el tiempo del paso de simulación.
pb.setGravity(0,0,-10) pb.setTimeStep(1./60)
Para evitar que la pelota caiga inmediatamente después de comenzar la simulación, equilibramos la gravedad.
pb_force = 10 * PB_BallMass pb.applyExternalForce(pb_ballId, -1, [0,0,pb_force], [0,0,0], pb.LINK_FRAME)
paso
El agente selecciona acciones basadas en el estado actual del entorno, después de lo cual llama al método de
pasos y recibe un nuevo estado.
Se definen 2 tipos de acción: aumento y disminución de la fuerza que actúa sobre la pelota. Los límites de fuerza son limitados.
Después de cambiar la fuerza que actúa sobre la pelota,
se inicia un nuevo paso de simulación física
pb.stepSimulation () , y los siguientes parámetros se devuelven al agente:
observación - observaciones (estado del medio ambiente)
recompensa - recompensa por la acción perfecta
hecho - la bandera del final de la experiencia
info - información adicional
Como estado del entorno, se devuelven 3 valores: la distancia al objetivo, la fuerza actual aplicada a la pelota y la velocidad de la pelota. Los valores se devuelven normalizados (0..1), ya que los parámetros ambientales que determinan estos valores pueden variar dependiendo de nuestro deseo.
La recompensa por la acción perfecta es 1 si la pelota está cerca del objetivo (altura del objetivo más / menos el valor de balanceo aceptable
TARGET_DELTA ) y 0 en otros casos.
El experimento se completa si la pelota sale de la zona (cae al suelo o vuela alto). Si la pelota llega a la meta, el experimento también termina, pero solo después de un cierto tiempo (pasos
STEPS_AFTER_TARGET del experimento). Por lo tanto, nuestro agente está entrenado no solo para avanzar hacia la meta, sino también para detenerse y estar cerca de ella. Dado que la recompensa cuando está cerca de la meta es 1, una experiencia exitosa debe tener una recompensa total igual a
STEPS_AFTER_TARGET .
Como información adicional para mostrar estadísticas, se devuelve el número total de pasos realizados dentro del experimento, así como el número de pasos realizados por segundo.
renderizar
PyBullet tiene 2 opciones de representación de imagen: representación de GPU basada en OpenGL y CPU basada en TinyRenderer. En nuestro caso, solo es posible una implementación de CPU.
Para obtener el marco actual de la simulación, es necesario determinar la
matriz de especies y la
matriz de proyección , y luego obtener la imagen
rgb del tamaño dado de la cámara.
camTargetPos = [0,0,5]
Al final de cada experimento, se genera un video basado en las imágenes recopiladas.
ani = animation.ArtistAnimation(plt.gcf(), render_imgs, interval=10, blit=True,repeat_delay=1000) display(HTML(ani.to_html5_video()))
Agente
El código de usuario de GitHub
jaara se tomó como base para el Agente, como un ejemplo simple y comprensible de implementar la capacitación de refuerzo para el entorno del Gimnasio.
El agente contiene 2 objetos:
Memoria : un almacenamiento para la formación de ejemplos de entrenamiento, y
Brain es la red neuronal que entrena.
La red neuronal entrenada se creó en TensorFlow utilizando la biblioteca Keras, que recientemente se ha
incluido por completo en TensorFlow.
La red neuronal tiene una estructura simple: 3 capas, es decir. Solo 1 capa oculta.
La primera capa contiene 512 neuronas y tiene un número de entradas igual al número de parámetros del estado del medio (3 parámetros: distancia al objetivo, fuerza y velocidad de la pelota). La capa oculta tiene una dimensión igual a la primera capa: 512 neuronas, en la salida está conectada a la capa de salida. El número de neuronas de la capa de salida corresponde al número de acciones realizadas por el Agente (2 acciones: disminución y aumento de la fuerza de actuación).
Por lo tanto, el estado del sistema se suministra a la entrada de la red, y en la salida tenemos un beneficio para cada una de las acciones.
Para las dos primeras capas,
ReLU (unidad lineal rectificada) se utiliza como funciones de activación, para la última, una
función lineal (la suma de los valores de entrada es simple).
En función del error,
MSE (error estándar), como algoritmo de optimización:
RMSprop (Propagación cuadrática media cuadrática).
model = Sequential() model.add(Dense(units=512, activation='relu', input_dim=3)) model.add(Dense(units=512, activation='relu')) model.add(Dense(units=2, activation='linear')) opt = RMSprop(lr=0.00025) model.compile(loss='mse', optimizer=opt)
Después de cada paso de simulación, el Agente guarda los resultados de este paso en forma de una lista
(s, a, r, s_) :
s - observación previa (estado del medio ambiente)
a - acción completada
r : recompensa recibida por la acción realizada
s_ - observación final después de la acción
Después de eso, el Agente recibe de la memoria un conjunto aleatorio de ejemplos para períodos anteriores y forma un paquete de capacitación (
lote ).
Los estados iniciales de los pasos aleatorios seleccionados de la memoria se toman como valores de entrada (
X ) del paquete.
Los valores reales de la salida de aprendizaje (
Y ' ) se calculan de la siguiente manera: en la salida (
Y ) de la red neuronal para s habrá valores de la
función Q para cada una de las acciones
Q (s) . De este conjunto, el agente seleccionó la acción con el valor más alto
Q (s, a) = MAX (Q (s)) , la completó y recibió el premio
r . El nuevo valor de
Q para la acción seleccionada
a será
Q (s, a) = Q (s, a) + DF * r , donde
DF es el factor de descuento. Los valores de salida restantes seguirán siendo los mismos.
STATE_CNT = 3 ACTION_CNT = 2 batchLen = 32
El entrenamiento de red se lleva a cabo en el paquete formado
self.model.fit(x, y, batch_size=32, epochs=1, verbose=0)
Después de completar el experimento, se genera un video
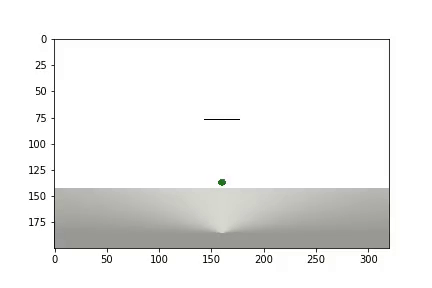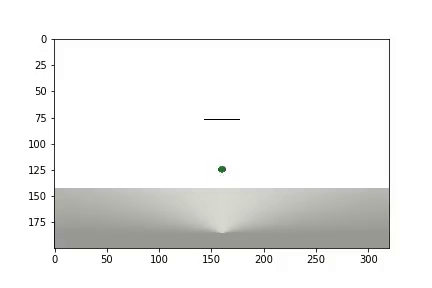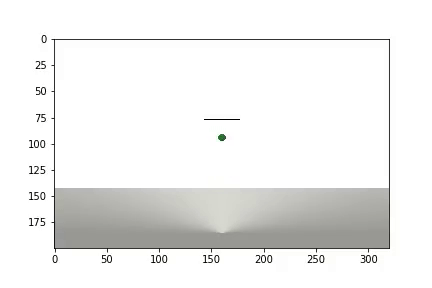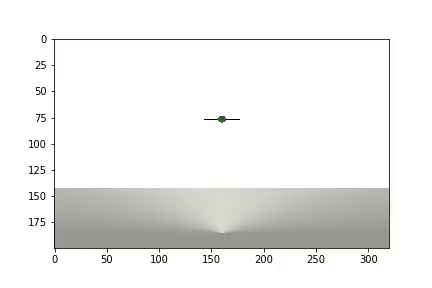
y se muestran las estadísticas
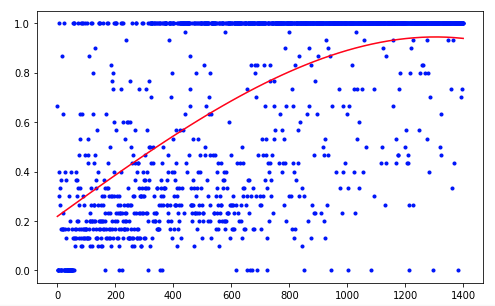
El agente necesitó 1.200 ensayos para lograr un resultado del 95 por ciento (número de pasos exitosos). Y en el 50º experimento, el Agente había aprendido a mover la pelota hacia el objetivo (los experimentos fallidos desaparecen).
Para mejorar los resultados, puede intentar cambiar el tamaño de las capas de red (LAYER_SIZE), el parámetro del factor de descuento (GAMMA) o la tasa de disminución en la probabilidad de elegir una acción aleatoria (LAMBDA).
Nuestro agente tiene la arquitectura más simple: DQN (Deep Q-Network). En una tarea tan simple, es suficiente para obtener un resultado aceptable.
El uso, por ejemplo, de la arquitectura DDQN (Double DQN) debería proporcionar una capacitación más fluida y precisa. Y la red RDQN (DQN recurrente) podrá rastrear los patrones de cambio ambiental a lo largo del tiempo, lo que permitirá deshacerse del parámetro de velocidad de bola, reduciendo el número de parámetros de entrada de red.
También puede ampliar nuestra simulación agregando una masa de bola variable o el ángulo de inclinación de su movimiento.
Pero esta es la próxima vez.