Hace un año, agregamos a nuestro agente una colección de métricas de los atributos del disco SMART en los servidores del cliente. En ese momento, no los agregamos a la interfaz y se los mostramos a los clientes. El hecho es que no tomamos métricas a través de smartctl, pero extraemos ioctl directamente del código para que esta funcionalidad funcione sin instalar smartmontools en los servidores del cliente.
El agente no elimina todos los atributos disponibles, sino solo los más significativos en nuestra opinión y los menos específicos del proveedor (de lo contrario, tendría que mantener una base de disco similar a smartmontools).
Ahora, las manos finalmente han llegado al punto de verificar lo que filmamos allí. Y se decidió comenzar con el atributo "indicador de desgaste de medios", que muestra el porcentaje del recurso de grabación SSD restante. Debajo del corte algunas historias en imágenes sobre cómo se gasta este recurso en la vida real en los servidores.
¿Hay algún SSD muerto?
Se cree que los SSD nuevos y más productivos se lanzan con más frecuencia que los viejos logran ser asesinados. Por lo tanto, lo primero fue interesante mirar a los más asesinados en términos de grabación de disco de recursos. El valor mínimo para todos los SSD de todos los clientes es del 1%.
Inmediatamente le escribimos al cliente sobre esto, resultó ser un Dedik en Hetzner. El soporte de alojamiento reemplazó inmediatamente a ssd:

Sería muy interesante ver cómo se ve la situación desde el punto de vista del sistema operativo cuando SSD deja de prestar servicio a un registro (ahora estamos buscando la oportunidad de simular deliberadamente SSD para ver las métricas de este escenario :)
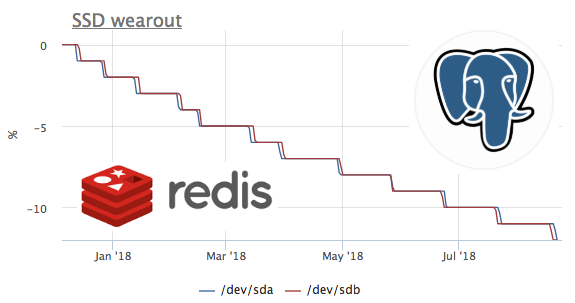
¿Qué tan rápido se matan los SSD?
Desde que comenzamos a recopilar métricas hace un año, y no estamos eliminando métricas, es posible observar esta métrica a tiempo. Desafortunadamente, el servidor con la tasa de flujo más alta se conectó al okmeter hace solo 2 meses.

En este gráfico, vemos cómo en 2 meses quemaron el 8% del recurso de grabación. Es decir, con el mismo perfil de grabación, estos ssd serán suficientes para 100 / (8/2) = 25 meses. No sé mucho o poco, pero veamos qué tipo de carga hay.

Vemos que solo ceph funciona con el disco, pero entendemos que ceph es solo una capa. En este caso, el cliente ceph actúa como un repositorio para el clúster de kubernetes en varios nodos, veamos qué dentro de k8s genera más escrituras de disco:

Los valores absolutos no coinciden probablemente debido al hecho de que ceph está trabajando en el clúster y el registro de redis está aumentando debido a la replicación de datos. Pero el perfil de carga le permite decir con confianza que el registro inicia exactamente redis. Veamos qué pasa en el rábano:

aquí puede ver que, en promedio, se ejecutan menos de 100 solicitudes por segundo, lo que puede cambiar los datos. Recuerde que redis tiene 2 formas de escribir datos en el disco :
- RDB : instantáneas periódicas de toda la base de datos en el disco, al iniciar redis, leemos el último volcado en la memoria y perdemos datos entre los volcados
- AOF : escribimos un registro de todos los cambios, al inicio redis pierde este registro y todos los datos aparecen en la memoria, solo perdemos datos entre fsync de este registro
Como probablemente todos ya hayan adivinado en este caso, RDB se usa con una frecuencia de volcado de 1 minuto:

SSD + RAID
Según nuestras observaciones, existen tres configuraciones principales del subsistema de disco de los servidores con la presencia de SSD:
- en el servidor 2 SSD recogidos en raid-1 y todo vive allí
- el servidor tiene HDD + raid-10 de ssd, generalmente se usa para RDBMS clásicos (sistema, WAL y parte de los datos en el HDD, y en el SSD los datos más populares en términos de lectura)
- el servidor tiene un SSD independiente (JBOD), generalmente usado para cassandra tipo nosql
Si los SSD se recopilan en la incursión-1, la grabación va a ambos discos, por lo que el desgaste se realiza a la misma velocidad:
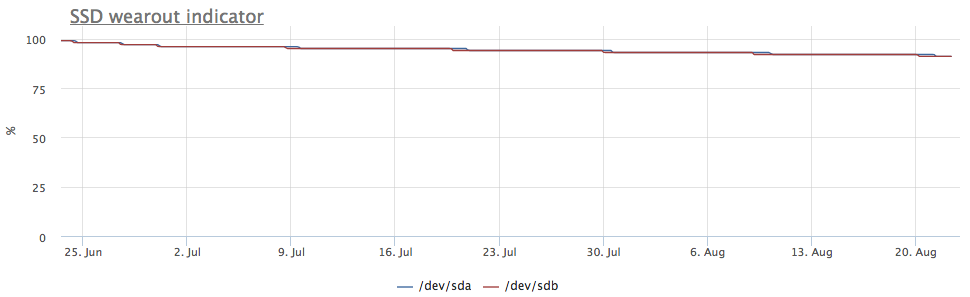
Pero el servidor me llamó la atención, en el que la imagen es diferente:

En este caso, solo se montan particiones mdraid (todas las matrices raid-1):

Las métricas de grabación también muestran que hay más entradas en / dev / sda:

Resultó que una de las particiones en / dev / sda se usa como intercambio, y el intercambio de E / S en este servidor es bastante notable:

Depreciación de SSD y PostgreSQL
En realidad, quería ver la tasa de desgaste de SSD en varias cargas de escritura en Postgres, pero por regla general, se usan con mucho cuidado en las bases de datos de SSD cargadas y la grabación masiva va al HDD. Mientras buscaba un caso adecuado, me encontré con un servidor muy interesante:

El desgaste de dos ssd en raid-1 durante 3 meses fue del 4%, pero a juzgar por la velocidad de grabación de WAL, este postgres escribe menos de 100 Kb / s:
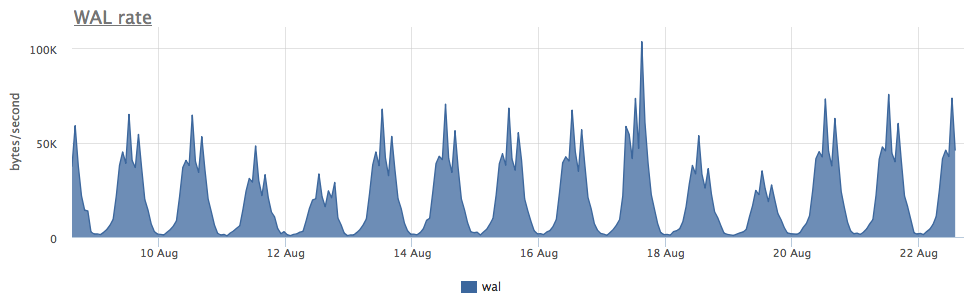
Resultó que postgres usa activamente archivos temporales, trabajando con los cuales crea un flujo constante de escritura en el disco:

Dado que postgresql con diagnóstico es bastante bueno, podemos, hasta la solicitud, averiguar qué es exactamente lo que tenemos que solucionar:

Como puede ver aquí, este SELECT en particular genera un montón de archivos temporales. En general, en los postgres SELECT, a veces generan un registro sin ningún archivo temporal; aquí ya hablamos de esto.
Total
- La cantidad de escritura en el disco que crea Redis + RDB no depende de la cantidad de modificaciones en la base de datos, sino del tamaño del intervalo de volcado de la base de datos (y, en general, este es el nivel más alto de amplificación de escritura en los almacenes de datos que conozco)
- El intercambio activo en ssd es malo, pero si necesita agregar jitter al desgaste de ssd (para confiabilidad de raid-1), entonces podría ser una opción :)
- Además de WAL y archivos de datos, las bases de datos aún pueden escribir todo tipo de datos temporales en el disco.
En okmeter.io creemos que para llegar al fondo de la causa del problema, el ingeniero necesita muchas métricas sobre todas las capas de la infraestructura. Estamos haciendo todo lo posible para ayudar :)