
Tenemos dos enfoques para la recuperación de desastres: un clúster "extendido" (instalación activa-activa) y una plataforma con máquinas virtuales (réplicas) apagadas. Tienen varios puntos para guardar instantáneas.
Existe una solicitud de tolerancia a desastres, y muchos de nuestros clientes realmente la necesitan. Por lo tanto, comenzamos a elaborar ambos esquemas como parte de nuestra producción.
Los métodos tienen pros y contras, ahora te contaré sobre ellos.
Racimo estirado
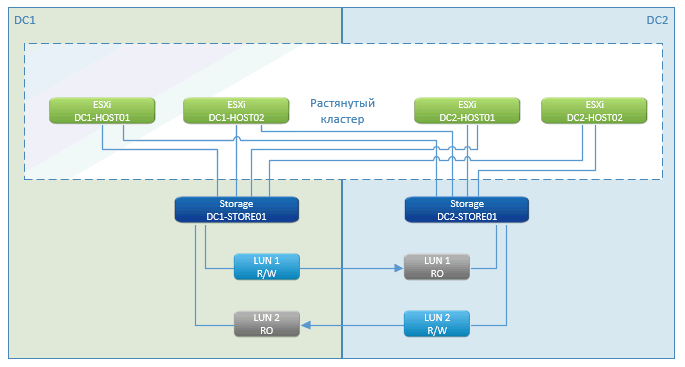
Como puede ver, esta es una historia estándar de clúster de metro. En los pros: tiempo de inactividad casi cero, una pausa solo al momento de iniciar las máquinas virtuales. Esta característica funciona: VMware High Availability (HA). Ella ve que los hosts se pierden e inmediatamente reinicia la VM en el sitio remoto.
El lanzamiento se realiza inmediatamente desde el almacenamiento, que se encuentra en el clúster.
El almacenamiento con un clúster geodistribuido es una característica de marketing de NetApp. Otros fabricantes tienen algo con un nombre similar. En esencia, esta es una replicación asincrónica pensada de un lado a otro. Escribimos a un nodo en la red local y sincronizamos a través de canales de comunicación especializados con otro.
En caso de falla de uno de los sistemas de almacenamiento, el resto (en otro sitio) presenta la ruta a los discos a los hosts restantes. Las máquinas virtuales que han muerto se reinician en ellas. Todo sucede automáticamente: el centro de datos se bloqueó, todo se reinició, el almacenamiento funcionó, VMware funcionó. El cliente vio que todo parpadeaba y se reiniciaba.
Se puede perder el único caché de la RAM de la VM. Pero si la base de datos la descartó, entonces la pérdida es cero en el tiempo.
Si perdemos la comunicación entre los sitios, entonces todo continúa funcionando en su lugar y, tan pronto como se restablece la conexión, comienza a sincronizarse.
La desventaja es el alto precio. Porque en realidad necesita un doble SHD (además, similar en tipo, velocidad y volumen de discos del primer SHD en el sitio principal), que no puede usarse de alguna manera, excepto como reserva. Además del enlace al almacenamiento para el clúster de metro, estos son puentes FC, red FC y más.
Tenemos dos DPC, entre ellos un paquete FC a lo largo de dos haces (cuatro líneas ópticas oscuras y DWDM). Estas son dos piezas de hierro, cada una proporciona un ancho de banda de 200 Gbps para FC y Ethernet.
Alternativa con DR

Existe un software con un nombre intuitivamente memorable: VMware vCloud Availability para Cloud-to-Cloud DR.
Este es un sistema para crear una VM idéntica en un sitio remoto una vez, relativamente hablando, en 15 minutos. Un sistema para presentar todo esto de la manera correcta a los mecanismos de control de la nube está conectado a él en una cinta eléctrica.
Es decir, la tecnología VMware Replication está en el backend. En caso de falla, iniciamos manualmente el plan de recuperación ante desastres en el segundo sitio, automáticamente deja de intentar replicarse, luego registra la VM en vCloud Director, personaliza las direcciones IP (para que no tenga que cambiarse a la VM) e inicia la VM en el orden necesario. En nuestra solución, no es necesario cambiar el direccionamiento, estiramos las redes a ambos centros de datos.
Las máquinas se replican constantemente, pero no todo el centro de datos, sino solo los seleccionados son procesos críticos. Se replica de vez en cuando, el intervalo mínimo es de 15 minutos (este es un caso ideal cuando todo vuela y hay un servidor de replicación dedicado y un mínimo de cambios en la VM). En la práctica, tienes una copia hace media hora o una hora. Si algo salió mal, entonces los datos que cayeron en el intervalo se perdieron. 15 minutos es la pregunta del agente que recopila la nueva replicación. Veeam dice que pueden tomar menos de 15 minutos, pero en realidad también es más largo en la práctica si no usan las funciones de almacenamiento. No vi en una máquina industrial (no en una prueba) que sería de otra manera.
Durante mucho tiempo, NetApp, como muchos otros fabricantes de sistemas de almacenamiento, tiene la tecnología SnapMirror, que le permite cambiar el trabajo de replicación de hipervisores a sistemas de almacenamiento, y VMware Replication puede usarlo.
A medida que se ejecuta el servicio de replicación, el tren llega lejos. Pero es barato.
¿Por qué sigue siendo barato? Debido a que puede usar cualquier almacenamiento en cualquier lado (de diferentes fabricantes, diferentes clases), no necesita asignar un gran volumen de discos por adelantado.
No es necesario asignar un gran grupo de discos, dentro del cual se cortan las lunas. Simplemente ocupa un lugar en el almacenamiento local y se aplica al hecho de la disponibilidad del registro desde la máquina virtual. Debido a esto, el lugar en el sistema de almacenamiento está óptimamente ocupado, si se usa para otras tareas. Y se utiliza, ya que no brindamos ese servicio a todos los clientes.
Menos: debe configurar la replicación a nivel de VM, es decir, controlar que todo esté configurado correctamente, que esta es la máquina, asegurarse de que la replicación pase, que no haya errores. Cree planes de DR para cada cliente, realice sus pruebas.
En el primer caso, el almacenamiento se toma, condicionalmente, infraestructuralmente, casi por sectores (más precisamente, por objetos). Y luego una máquina puede caerse debido a una tarea que se cae debido a algunas razones de software relacionadas con un error en niveles altos, o debido a problemas de accesibilidad. Esto sucede un poco más a menudo que si toma solo niveles bajos.
En plus - DR almacena varios puntos. Puede revertir algunas instantáneas.
Fuera del sistema operativo invitado, necesita software adicional.
Para llevar todas las redes necesarias a Vcloud Director, necesitamos el trabajo de nuestro administrador. En general, toda la conectividad de red en esta versión permanece con nuestro administrador. Para un cliente en la nube, esto significa una aplicación, que también lleva tiempo.
La replicación también se configura a través de la aplicación. VM agregada: debe enviar una solicitud para replicarla. No cae en las tareas de replicación automáticamente. Es necesario prestar atención al administrador.
La diferencia
Como resultado, el precio puede diferir en más de dos veces. La replicación multiplicará el costo del espacio en disco por dos o más (dos copias completas + historial de cambios), más algo para el servicio y la reserva de recursos informáticos. En el caso del clúster de metro, el costo del espacio se multiplicará por dos, pero el espacio en sí costará significativamente más, además de que necesita reservar firmemente nodos en un sitio remoto. Es decir, los recursos informáticos deben multiplicarse por dos, no podemos utilizarlos para nada más.
En el caso del clúster de metro, podemos usar solo los mismos tipos de discos para que haya un espejo completo. Si en el centro de datos principal algunas de las unidades son rápidas, algunas lentas a 10 mil revoluciones por minuto, entonces se necesita una configuración idéntica. En el caso de una réplica, son posibles discos más lentos en el sitio de copia de seguridad, lo que es más barato debido al almacenamiento. Pero al cambiar a una reserva, el rendimiento será menor. Es decir, si almacena algo en el SSD en el clúster principal y se replica en discos normales, entonces el almacenamiento será mucho más barato a costa de ralentizar la infraestructura de reserva.
En este momento estamos eligiendo lo que se incluirá en una versión anterior, por lo que queremos consultar: ¿puede decirnos brevemente cómo organiza sus sitios de DR y qué le gustaría que hicieran en general?