
Pude recoger mi estación de trabajo como estudiante. Lógicamente, preferí las soluciones informáticas de AMD. porque eso barato rentable en términos de precio / calidad. Recogí los componentes durante mucho tiempo, al final llegué con 40k con un conjunto de FX-8320 y RX-460 2GB. ¡Al principio este kit parecía perfecto! Mi compañero de cuarto y yo minamos un poco a Monero y mi set mostró 650h / s versus 550h / s en un set de i5-85xx y Nvidia 1050Ti. Es cierto que desde mi set en la habitación hacía un poco de calor por la noche, pero esto se decidió cuando compré un refrigerador de torre para la CPU.
La historia ha terminado
Todo era como en un cuento de hadas exactamente hasta que me interesé en el aprendizaje automático en el campo de la visión por computadora. Incluso más precisamente, hasta que tuve que trabajar con imágenes de entrada con una resolución de más de 100x100px (hasta este momento, mi FX de 8 núcleos se enfrentó rápidamente). La primera dificultad fue la tarea de determinar las emociones. 4 capas de ResNet, imagen de entrada de 100x100 y 3000 imágenes en el conjunto de entrenamiento. Y ahora, 9 horas de entrenamiento 150 eras en la CPU.
Por supuesto, debido a este retraso, el proceso de desarrollo iterativo sufre. En el trabajo, teníamos Nvidia 1060 6GB y entrenamiento para una estructura similar (aunque la regresión fue entrenada allí para localizar objetos) voló en 15-20 minutos - 8 segundos para una era de 3.5k imágenes. Cuando tienes ese contraste debajo de la nariz, la respiración se vuelve aún más difícil.
Bueno, ¿adivinas mi primer movimiento después de todo esto? Sí, fui a negociar 1050 Ti con mi vecino. Con argumentos sobre la inutilidad de CUDA para él, con una oferta para cambiar mi tarjeta por un cargo extra. Pero todo en vano. Y ahora estoy publicando mi RX 460 en Avito y revisando el preciado 1050Ti en los sitios de Citylink y TechnoPoint. Incluso en el caso de una venta exitosa de la tarjeta, tendría que encontrar otros 10k (soy estudiante, aunque funcione).
Google
Esta bien Voy a google cómo usar Radeon en Tensorflow. Sabiendo que esta era una tarea exótica, no esperaba encontrar nada sensato en particular. Recopile bajo Ubuntu, ya sea que se inicie o no, obtenga un ladrillo: frases extraídas de los foros.
Y entonces fui por el otro lado: no busqué Google Tensorflow AMD Radeon, sino Keras AMD Radeon. Al instante me lanza a la página de PlaidML . Lo inicio en 15 minutos (aunque tuve que degradar Keras a 2.0.5) y configurar la red para aprender. La primera observación: la era es de 35 segundos en lugar de 200.
Subir para explorar
Los autores de PlaidML son vertex.ai , que forma parte del grupo de proyectos Intel (!). El objetivo de desarrollo es la máxima plataforma cruzada. Por supuesto, esto agrega confianza al producto. Su artículo dice que PlaidML es competitivo con Tensorflow 1.3 + cuDNN 6 debido a la "optimización completa".
Sin embargo, continuamos. El siguiente artículo nos revela en cierta medida la estructura interna de la biblioteca. La principal diferencia de todos los demás marcos es la generación automática de núcleos de cálculo (en la notación de Tensorflow, el "núcleo" es el proceso completo de realizar una determinada operación en un gráfico). Para la generación automática de kernel en PlaidML, las dimensiones exactas de todos los tensores, constantes, pasos, tamaños de convolución y valores límite con los que tendrá que trabajar más tarde son muy importantes. Por ejemplo, se argumenta que la creación posterior de núcleos efectivos difiere para 1 y 32 lotes o para convoluciones de tamaños 3x3 y 7x7. Con estos datos, el marco en sí generará la forma más eficiente de paralelizar y ejecutar todas las operaciones para un dispositivo en particular con características específicas. Si observa Tensorflow, al crear nuevas operaciones, también necesitamos implementar el kernel para ellos, y las implementaciones son muy diferentes para los núcleos de un solo subproceso, multiproceso o compatibles con CUDA. Es decir PlaidML es claramente más flexible.
Vamos más allá La implementación está escrita en el lenguaje autoescrito Tile . Este lenguaje tiene las siguientes ventajas principales: la proximidad de la sintaxis a las anotaciones matemáticas (¡pero enloquece!):
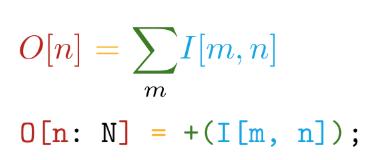
Y diferenciación automática de todas las operaciones declaradas. Por ejemplo, en TensorFlow, al crear una nueva operación personalizada, es muy recomendable que escriba una función para calcular los gradientes. Por lo tanto, al crear nuestras propias operaciones en el lenguaje Tile, solo necesitamos decir QUÉ queremos calcular sin pensar en CÓMO considerar esto en relación con los dispositivos de hardware.
Además, se realiza la optimización del trabajo con DRAM y un análogo de la caché L1 en la GPU. Recordemos el dispositivo esquemático:
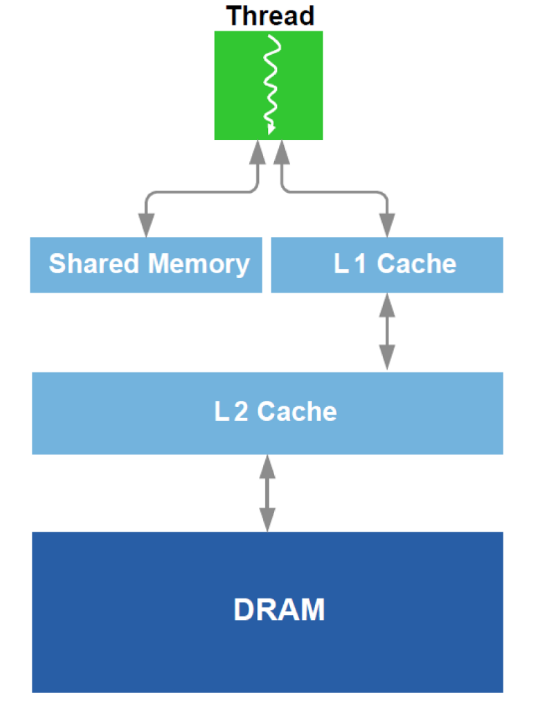
Para la optimización, se utilizan todos los datos disponibles sobre el equipo: tamaño de caché, ancho de línea de caché, ancho de banda DRAM, etc. Los métodos principales son asegurar la lectura simultánea de bloques lo suficientemente grandes desde DRAM (un intento de evitar el direccionamiento a diferentes áreas) y lograr que los datos cargados en la memoria caché se usen varias veces (un intento de evitar recargar los mismos datos varias veces).
Todas las optimizaciones se llevan a cabo durante la primera era de entrenamiento, mientras aumentan enormemente el tiempo de la primera ejecución:
Además, vale la pena señalar que este marco está vinculado a OpenCL . La principal ventaja de OpenCL es que es un estándar para sistemas heterogéneos y nada le impide ejecutar el núcleo en la CPU . Sí, aquí es donde se encuentra uno de los principales secretos de PlaidML multiplataforma.
Conclusión
Por supuesto, la capacitación en la RX 460 sigue siendo 5-6 veces más lenta que en la 1060, ¡pero puede comparar las categorías de precios de las tarjetas de video! Luego obtuve un RX 580 de 8 gb (¡me lo prestaron!) Y el tiempo que llevó ejecutar la era se redujo a 20 segundos, lo cual es casi comparable.
El blog vertex.ai tiene gráficos honestos (más es mejor):
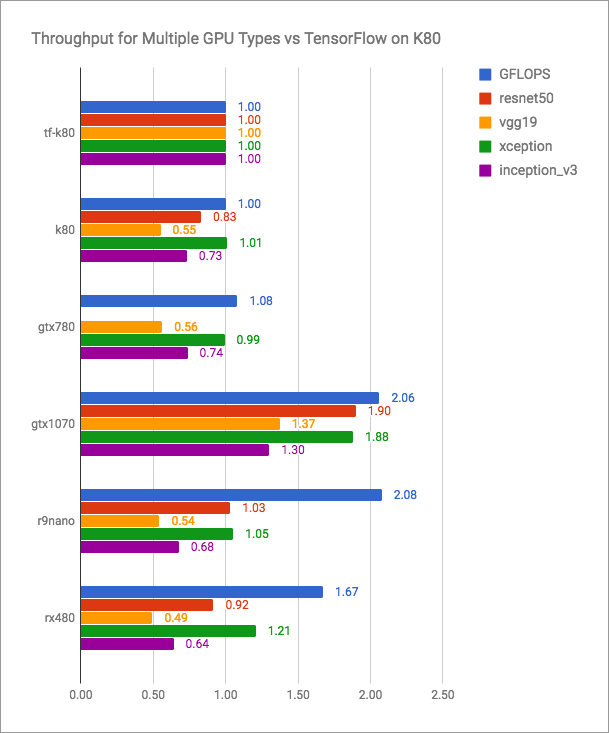
Se puede ver que PlaidML es competitivo con Tensorflow + CUDA, pero ciertamente no es más rápido para las versiones actuales. Pero los desarrolladores de PlaidML probablemente no planean entrar en una batalla tan abierta. Su objetivo es la universalidad, multiplataforma.
Dejaré aquí una tabla no bastante comparativa con mis mediciones de rendimiento:
| Dispositivo de computación | Tiempo de ejecución de la era (lote - 16), s |
|---|
| AMD FX-8320 tf | 200 |
| RX 460 2GB a cuadros | 35 |
| RX 580 8 GB a cuadros | 20 |
| 1060 6GB TF | 8 |
| 1060 a cuadros de 6 GB | 10 |
| Intel i7-2600 tf | 185 |
| Intel i7-2600 a cuadros | 240 |
| GT 640 a cuadros | 46 |
La última publicación del blog vertex.ai y las últimas ediciones en el repositorio están fechadas en mayo de 2018. Parece que si los desarrolladores de esta herramienta no dejan de lanzar nuevas versiones y cada vez más personas que se sienten ofendidas por Nvidia están familiarizadas con PlaidML, hablarán sobre vertex.ai con mucha más frecuencia.
¡Descubre tus radeones!