
El segundo día del programa principal de KDD. Debajo del corte nuevamente, muchas cosas interesantes: desde el aprendizaje automático en Pinterest hasta varias formas de excavar en tuberías de agua. Incluyendo el discurso del premio Nobel de economía: una historia sobre cómo la NASA trabaja con la telemetría y muchas incrustaciones de gráficos :)
Diseño de mercado y mercado computarizado.
Una buena actuación del
premio Nobel que trabajó con Shapley en los mercados. El mercado es una cosa artificial cuyo dispositivo inventa la gente. Existen los llamados mercados de productos básicos, cuando compra un determinado producto y no le importa quién, solo importa a qué precio (por ejemplo, el mercado de valores). Y hay mercados equivalentes cuando el precio no es el único factor (y a veces no lo es en absoluto).
Por ejemplo, la distribución de niños en las escuelas. Anteriormente, en los EE. UU., El esquema funcionaba así: los padres escriben la lista de escuelas por prioridad (1, 2, 3, etc.), las escuelas primero consideran a quienes las han indicado como número 1, las clasifican según sus criterios escolares y toman todo lo que pueden tomar. . Para aquellos que no golpearon, tomamos la segunda escuela y repetimos el procedimiento. Desde el punto de vista de la teoría de juegos, el esquema es muy malo: los padres tienen que comportarse "estratégicamente", no es práctico decir honestamente sus preferencias: si no ingresas a la escuela 1, en la segunda ronda, la escuela 2 ya estará llena y no entrarás en ella, incluso si sus características son más altas que las que fueron aceptadas en la primera ronda. En la práctica, la falta de respeto por la teoría de juegos se traduce en corrupción y acuerdos internos entre padres y escuelas. Los matemáticos han propuesto otro algoritmo: "aceptación diferida". La idea principal es que la escuela no da su consentimiento de inmediato, sino que simplemente mantiene una lista clasificada de candidatos "en memoria", y si alguien va más allá de la cola, inmediatamente se niega. En este caso, existe una estrategia dominante para los padres: primero vamos a la escuela 1, si en algún momento tenemos un rechazo, luego vamos a la escuela 2 y no tenemos miedo de perder nada: las posibilidades de llegar a la escuela 2 son las mismas que si fuéramos a ella de inmediato Sin embargo, este esquema se implementó "en producción". No se informaron los resultados de la prueba A / B.
Otro ejemplo es el trasplante de riñón. A diferencia de muchos otros órganos, puede vivir con un riñón, por lo que a menudo surge una situación en la que alguien está listo para darle un riñón a otra persona, pero no abstracto, sino específico (debido a las relaciones personales). Sin embargo, la probabilidad de que el donante y el receptor sean compatibles es muy pequeña, y debe esperar a otro órgano. Existe una alternativa: el intercambio renal. Si dos pares son un donante y un receptor y son incompatibles por dentro, pero son compatibles entre los dos, entonces puede intercambiar: 4 operaciones simultáneas de extracción / implantación. El sistema ya funciona para esto. Y si hay un órgano "libre" que no está vinculado a un par específico, entonces puede dar lugar a una cadena completa de intercambios (en la práctica hubo cadenas de hasta 30 trasplantes).
Ahora hay muchos mercados similares similares: desde Uber al mercado de publicidad en línea, y todo cambia muy rápidamente debido a la informatización. Entre otras cosas, la "privacidad" está cambiando mucho: como ejemplo, el orador citó un estudio realizado por un estudiante que demostró que en los EE. UU. Después de las elecciones, el número de viajes para visitar en Acción de Gracias disminuyó debido a viajes entre estados con diferentes opiniones políticas. El estudio se realizó en un conjunto de datos anónimos de coordenadas telefónicas, pero el autor identificó con bastante facilidad la "casa" del propietario del teléfono, es decir conjunto de datos desanonimizado.
Por separado, el orador caminó sobre el desempleo tecnológico. Sí, los automóviles no tripulados los privarán de muchos (el 6% de los empleos en los EE. UU. Están en riesgo), pero crearán nuevos empleos (para mecánicos de automóviles). Por supuesto, el conductor mayor ya no podrá volver a entrenar y para él será un duro golpe. En esos momentos, debe concentrarse no en cómo prevenir los cambios (no funcionará), sino en cómo ayudar a las personas a superarlos de la manera más indolora posible. A mediados del siglo pasado, durante la mecanización de la agricultura, muchas personas perdieron sus empleos, pero nos alegra que ahora la mitad de la población no tenga que ir a trabajar en el campo. Desafortunadamente, esto solo se habla de opciones de mitigación implementadas para aquellos que enfrentan desempleo tecnológico, el orador no sugirió ...
Y sí, nuevamente sobre la justicia. Es imposible hacer que la distribución del modelo de pronóstico sea la misma en todos los grupos, el modelo perderá su significado. ¿Qué se puede hacer, en teoría, para que la distribución de ERRORES del primer y segundo tipo sea la misma para todos los grupos? Ya parece mucho más sensato, pero no está claro cómo lograr esto en la práctica. Le dio un enlace a un interesante artículo sobre práctica legal: en los Estados Unidos, un juez decide si se liberará bajo fianza
según el pronóstico de LD .
Recomendaciones I
Me confundí en el horario y llegué al discurso equivocado, pero aún en el tema: el primer bloque en los sistemas de recomendación.
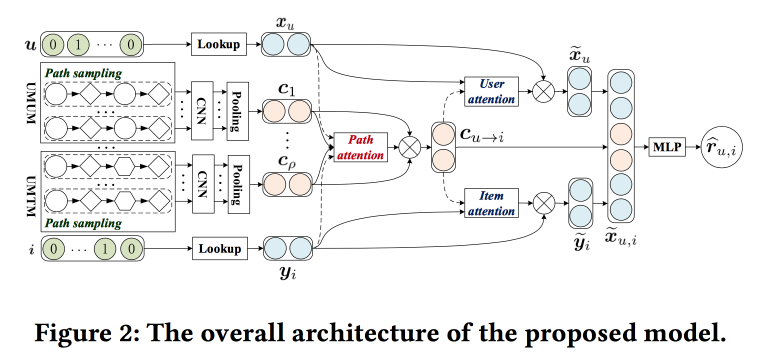
Aprovechando el contexto basado en Meta-path para la recomendación Top N con mecanismo de co-atención
Los chicos están tratando de mejorar las recomendaciones analizando las rutas en el gráfico. La idea es bastante simple. Hay un recomendador de red neuronal "clásico" con incrustaciones para objetos y usuarios y una parte completamente conectada en la parte superior. Hay recomendaciones en el gráfico, incluidas las que tienen marcas de red neuronal. Intentemos combinar todo esto en un solo mecanismo. Comencemos construyendo un "meta-gráfico" que une a los usuarios, películas y atributos (actor / director / género, etc.), en el gráfico aleatorio de walk-om, tomamos muestras de una serie de caminos, lo alimentamos a la red de convolución, agregamos incrustaciones de usuario en el lateral y objeto, y más allá ponemos atención (aquí un poco complicado, con sus propias características para diferentes ramas). Para obtener la respuesta final, coloque un perceptrón con dos capas ocultas en la parte superior.
Aplicaciones de Internet para consumidores
En el receso entre informes, paso a la presentación donde originalmente quería: los oradores invitados de LinkedIn, Pinterest y Amazon hablan aquí. Todas las chicas y todos los jefes de los departamentos de DS.
Recomendaciones contextuales neralinas para comunidades activas LinkedIn
La conclusión es estimular el desarrollo y la activación de la comunidad en LinkedIn. Me perdí la mitad del desarrollo, la última recomendación: explotar patrones locales. Por ejemplo, en India, los estudiantes a menudo después de la graduación intentan contactar a los graduados de la misma universidad de cursos anteriores con una carrera establecida. LinkedIn tiene esto en cuenta al construir y al hacer recomendaciones.
Pero simplemente crear una comunidad no es suficiente, es necesario que haya actividad: los usuarios publican contenido, reciben y hacen comentarios. Muestre la correlación de los comentarios recibidos con el número de publicaciones en el futuro. Muestre cómo se conecta en cascada la información en todo el gráfico. Pero, ¿qué pasa si un nodo no está involucrado en la cascada? Enviar aviso!
Luego hubo muchas conversaciones con la historia de ayer sobre trabajar con notificaciones y la cinta. Aquí también utilizan el enfoque de optimización multipropósito de "maximizar una de las métricas mientras se mantienen las otras dentro de ciertos límites". Para controlar la carga, introdujimos nuestro sistema de control de tráfico aéreo, que limita la carga de las notificaciones por usuario (pudieron reducir las bajas y las quejas en un 20% sin perder la participación). ATC decide si el envío puede enviarse al usuario o no, y este envío lo prepara otro sistema llamado Concourse, que funciona en modo de transmisión (¡como el nuestro, en
Samza !). Era sobre ella que ayer se contó mucho. Concourse también tiene un socio fuera de línea llamado Beehive, pero poco a poco se está transmitiendo cada vez más.
Tomó nota de algunos puntos más:
- La deduplicación es importante y de alta calidad, dada la presencia de muchos canales y contenido.
- Es importante tener una plataforma. Y tienen un equipo de plataforma dedicado, y los programadores trabajan allí.
Enfoque de Pinterest para el aprendizaje automático
Un
portavoz de Pinterest ahora habla y habla sobre dos grandes tareas que usan ML: feed (homefeed) y search. El orador dice de inmediato que el producto final es el resultado del trabajo no solo de los científicos de datos, sino también de los ingenieros y programadores de ML: se han asignado personas a todos ellos.
La cinta (la situación cuando no hay intención del usuario) se construye de acuerdo con el siguiente modelo:
- Entendemos al usuario: utilizamos información del perfil, gráfico, interacción con los pines (que vi que pateé), construimos incrustaciones de acuerdo con el comportamiento y los atributos.
- Entendemos el contenido: lo miramos en todos los aspectos: visual, textual, quién es el autor, qué tableros participan, quién reacciona. Es muy importante recordar que las personas en una imagen a menudo ven cosas diferentes: alguien tiene un acento azul en el diseño, alguien tiene una chimenea y alguien tiene una cocina.
- En conjunto: un procedimiento de tres pasos: generamos candidatos (recomendaciones + suscripciones), personalizamos (utilizando el modelo de clasificación) y combinamos de acuerdo con las políticas y las reglas comerciales.
Para recomendaciones, usan una caminata aleatoria debajo del gráfico de pin de la placa de usuario, presentan PinSage, del que hablaron
ayer . La personalización ha evolucionado desde la ordenación del tiempo, a través de un modelo lineal y GBDT hasta una red neuronal (desde 2017). Al recopilar la lista final, es importante no olvidarse de las reglas comerciales: frescura, variedad, filtros adicionales. Comenzamos con la heurística, ahora estamos avanzando hacia el modelo de optimización de contexto en su conjunto con respecto a los objetivos.
En una situación de búsqueda (cuando hay una intención) se mueven un poco diferente: tratan de comprender mejor la intención. Para hacer esto, use las técnicas de comprensión y expansión de consultas, y la extensión se realiza no solo por autocompletado, sino a través de una hermosa navegación visual. Utilizan diferentes técnicas para trabajar con imágenes y textos. Comenzamos en 2014 sin aprendizaje profundo, lanzamos Visual Search con aprendizaje profundo en 2015, en 2016 agregamos detección de objetos con análisis semántico y búsqueda, recientemente lanzamos el servicio Lens: apuntas la cámara del teléfono inteligente al sujeto y obtienes alfileres. En el aprendizaje profundo, utilizan activamente tareas múltiples: hay un bloque común que construye la incrustación de imágenes. y otras redes en la parte superior para resolver diferentes problemas.
Además de estas tareas, ML se usa mucho más donde: notificaciones / publicidad / spam / pronósticos, etc.
Un poco sobre las lecciones aprendidas:
- Debemos recordar sobre los prejuicios, uno de los "ricos enriquecidos" más peligrosos (la tendencia del aprendizaje automático a transferir tráfico a objetos ya populares).
- Es obligatorio probar y monitorear: la implementación de la cuadrícula al principio colapsó en gran medida todos los indicadores, luego resultó que debido a la distribución de errores de las características se había desviado durante mucho tiempo y aparecieron vacíos en línea.
- La infraestructura y la plataforma son muy importantes, con un énfasis especial en la conveniencia y la paralelización de los experimentos, pero debe poder cortar los experimentos fuera de línea.
- Métrica y comprensión: fuera de línea no garantiza en línea, pero para la interpretación de modelos hacemos herramientas.
- Creación de un ecosistema sostenible: sobre el filtro de basura y el clickbait, asegúrese de agregar comentarios negativos a la interfaz de usuario y al modelo.
- Recuerde tener una capa para incorporar reglas de negocios.
Amplio gráfico de conocimiento de Amazon
Ahora está jugando una
niña de Amazon.
Hay gráficos de conocimiento (nodos de entidad, bordes de atributos, etc.) que se crean automáticamente, por ejemplo, en Wikipedia. Ayudan a resolver muchos problemas. Nos gustaría obtener algo similar para los productos, pero hay muchos problemas con esto: no hay datos de entrada estructurados, los productos son dinámicos, hay muchos aspectos que no encajan en el modelo de gráfico de conocimiento (es discutible, en mi opinión, en lugar de "no mentir sin una complicación grave de la estructura "), Muchas verticales y" entidades sin nombre ". Cuando el concepto fue "vendido" a la gerencia y recibió el visto bueno, los desarrolladores dijeron que era un "proyecto por cien años", y como resultado lo lograron en 15 meses-hombre.
Comenzamos extrayendo entidades del directorio de Amazon: aquí hay algún tipo de estructura, aunque es de crowdsourcing y está sucia. Luego, conectaron OpenTag (descrito con más detalle ayer) para el procesamiento de textos. Y el tercer componente fue Ceres, una herramienta para analizar desde la web, teniendo en cuenta el árbol DOM. La idea es que al anotar una de las páginas del sitio, puede analizar fácilmente el resto; después de todo, todos son generados por una plantilla (pero hay muchos matices). Para hacer esto, utilizamos el sistema de marcado Vertex (comprado por Amazon en 2011): hacen un marcado en él, basado en él, se crea un conjunto de xpath para aislar atributos, y la regresión logística determina cuáles son aplicables en una página en particular. Para fusionar información de diferentes sitios, use bosque aleatorio. También usan entrenamiento activo, se envían páginas complejas para remarcado manual. Al final, hacen una limpieza supervisada del conocimiento: un clasificador simple, por ejemplo, una marca / no una marca.
A continuación, un poco de por vida. Distinguen dos tipos de objetivos. Los “roofshots” son los objetivos a corto plazo que logramos al mover el producto, y los “Moonshots” son los objetivos que superamos los límites y el liderazgo global.
Inserciones y representantes
Después del almuerzo fui a la sección sobre cómo construir incrustaciones, principalmente para gráficos.
Encontrar ejercicios similares con una representación semántica unificada
Los chicos
resuelven el problema de encontrar tareas similares en algunos sistemas de aprendizaje en línea chinos. Las asignaciones se describen por texto, imágenes y un conjunto de kontsetov relacionados. La contribución de los desarrolladores es reunir información de estas fuentes. Las convoluciones se hacen para imágenes, las incrustaciones se entrenan para conceptos, y también para palabras. Las incrustaciones de palabras se pasan al LSTM basado en la atención junto con información sobre conceptos e imágenes. Obtenga alguna representación del trabajo.

El bloque descrito anteriormente se convierte en una red siamesa, en la que también se agrega atención y en la salida un puntaje de similitud.
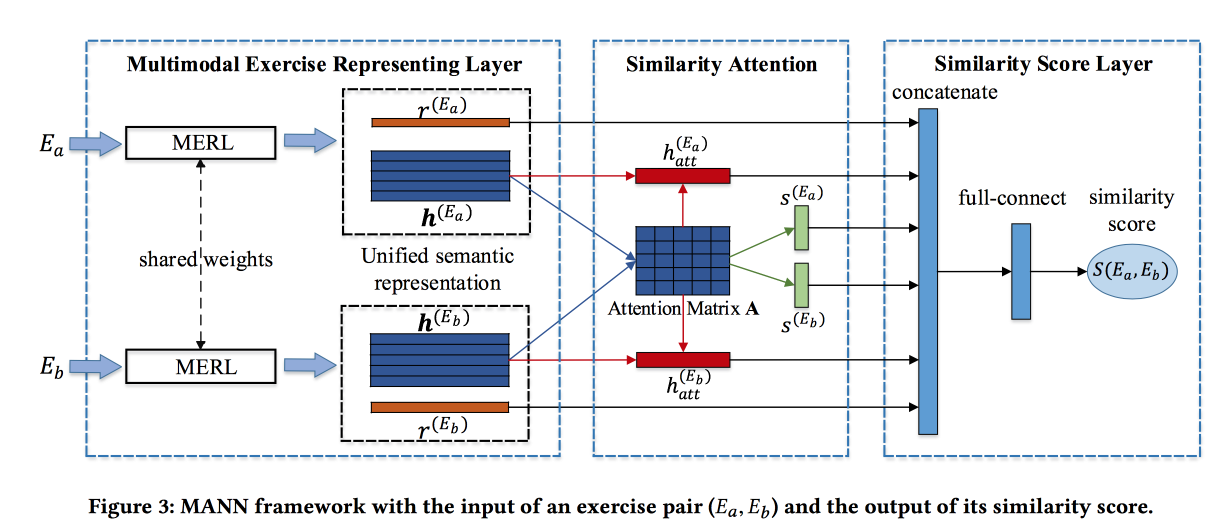
Enseñan en un conjunto de datos marcado de 100 mil ejercicios y 400 mil pares (un total de 1.5 millones de ejercicios). Agregue negativas duras muestreando ejercicios con los mismos conceptos. Las matrices de atención se pueden usar para interpretar la similitud.
Incrustación de red preservada por proximidad de orden arbitrario
Los chicos
están construyendo una variante muy interesante de incrustaciones para gráficos. Primero, los métodos basados en caminatas y en base a vecinos son criticados por enfocarse en la "proximidad" de cierto nivel (correspondiente a la longitud de la caminata). Ofrecen un método que tiene en cuenta la proximidad del pedido deseado y con pesos controlados.
La idea es muy simple. Tomemos una función polinómica y aplíquela a la matriz de adyacencia del gráfico, y factorizamos el resultado por SVD. En este caso, el grado de un miembro particular del polinomio es el nivel de proximidad, y el peso de este miembro es la influencia de este nivel en el resultado. Naturalmente, esta idea descabellada no es factible: después de elevar la matriz de adyacencia a una potencia, se vuelve más densa, no cabe en la memoria y se factoriza dicha figura.
Sin las matemáticas, es basura, porque si aplicas la función polinómica al resultado DESPUÉS de la expansión, obtenemos exactamente lo mismo que si la expansión se aplicara a una matriz grande. En realidad no realmente. Consideramos SVD aproximadamente y dejamos solo los valores propios superiores, pero después de aplicar el polinomio, el orden de los valores propios puede cambiar, por lo que debe tomar números con un margen.

El algoritmo cautiva con su simplicidad y muestra resultados sorprendentes en la tarea de predicción de enlaces.

NetWalk: un enfoque de integración profunda flexible para la detección de anomalías en redes dinámicas
Como su nombre lo indica,
construiremos las incrustaciones de gráficos basadas en caminatas. Pero no solo, sino en modo de transmisión, ya que resolvemos el problema de buscar anomalías en redes dinámicas (ayer hubo trabajo sobre este tema). Para leer y actualizar rápidamente las incrustaciones, utilizan el concepto de "
depósito ", en el que se encuentra una muestra del gráfico y se actualiza estocásticamente cuando se reciben cambios.
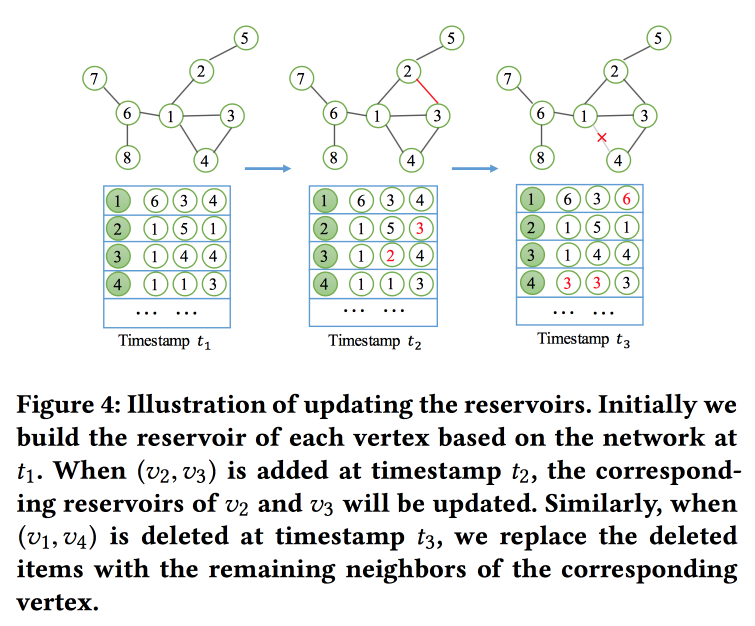
Para el entrenamiento, formulan una tarea bastante complicada con varios objetivos, los principales son la proximidad de las incrustaciones para los nodos en una ruta y los errores mínimos al restaurar la red con un codificador automático.
Integración de red con conocimiento de taxonomía jerárquica
Otra
opción para construir incrustaciones para un gráfico, esta vez basado en un modelo de generación probabilístico. La calidad de las incrustaciones se mejora mediante el uso de información de una taxonomía jerárquica (por ejemplo, un dominio de conocimiento para redes de citas o una categoría de productos para productos en e-tail). El proceso de generación se basa en algunos "temas", algunos de los cuales están vinculados a nodos en una taxonomía, y otros a un nodo específico.
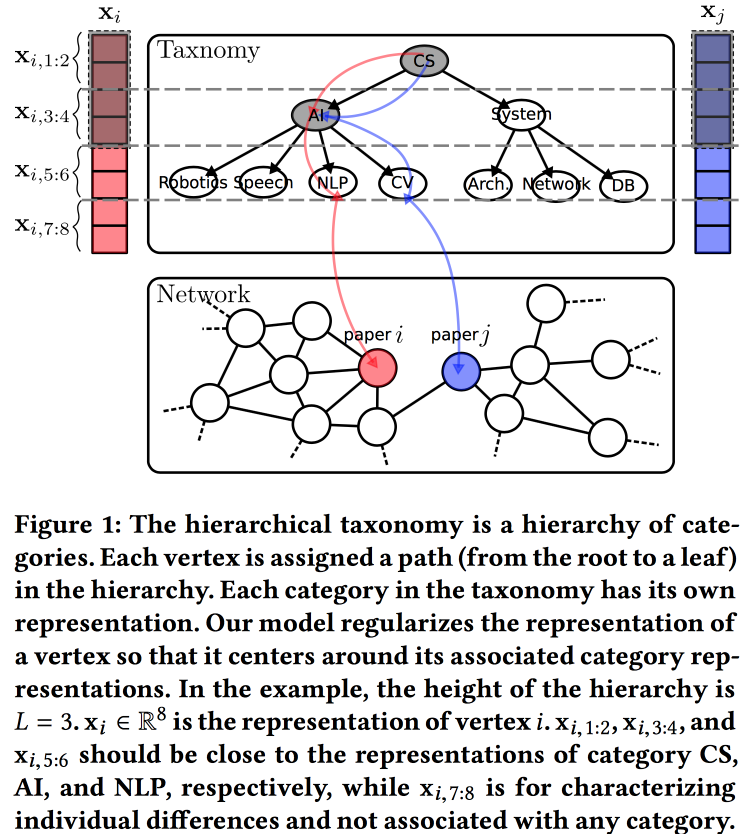
Asociamos la distribución normal a priori con una media cero con los parámetros de la taxonomía, los parámetros de un vértice particular en la taxonomía: la distribución normal con el promedio igual al parámetro de la taxonomía, y la distribución normal con la media cero y la dispersión infinita para los parámetros libres del vértice. Generamos el entorno del vértice utilizando la distribución de Bernoulli, donde la probabilidad de éxito es proporcional a la proximidad de los parámetros de los nodos. Optimizamos todo este coloso con el
algoritmo EM .
Integración de red recursiva profunda con equivalencia regular
Las técnicas comunes de incrustación no funcionan para todas las tareas. Por ejemplo, considere el papel de una tarea de nodo. Para determinar el papel, no son importantes los vecinos específicos (que generalmente se miran), sino la estructura gráfica en la vecindad del vértice y algunos patrones en él. Al mismo tiempo, es muy difícil buscar algorítmicamente estos patrones (equivalencia regular) directamente, pero para gráficos grandes no es realista.
Por lo tanto, iremos por el
otro lado . Para cada nodo, calculamos los parámetros asociados con su gráfico: grado, densidad, diferentes centralidades, etc. Las incrustaciones no se pueden construir solo sobre ellas, pero se puede usar la recursividad, porque la presencia del mismo patrón implica que los atributos de los vecinos de dos nodos con el mismo rol deberían ser similares. Lo que significa que puedes apilar más capas.
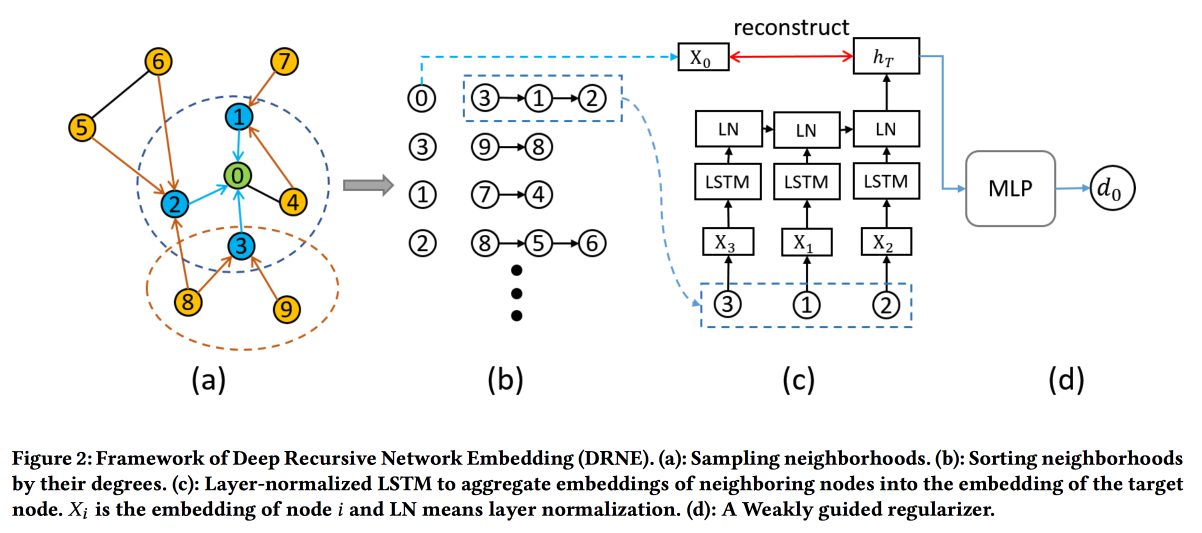
Las validaciones muestran que omiten las líneas base estándar de DeepWalk y node2wek en muchas tareas.
Incrustar red temporal a través de la formación de vecindario
El último trabajo de incrustación de gráficos para hoy. Esta vez veremos la dinámica: evaluaremos tanto el momento de la conexión como todos los hechos de interacción en el tiempo. Tome la red de citas como ejemplo, donde la interacción es una publicación conjunta.
Usamos el Proceso de Hawkes para modelar cómo las interacciones de vértices pasadas afectan sus interacciones futuras. HP . attention . log likelihood . .
Safety
. , . , ML , , .
Using Machine Learning to Assess the Risk of and Prevent Water Main Breaks
: , , — . , . , ( - , ), 1-2 % . ,
.
data miner-
Data Science for Social Good . , , :

, . : , GBDT. -1 % .
base line-: « » , , « , » . ML, , .
27 32- , , , ( , — ). , $1,2 .
, , , 1940-, , ( ) .
Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding
NASA
( ). — . , . , .
ML . LSTM , . ( , ). , , . , . , .
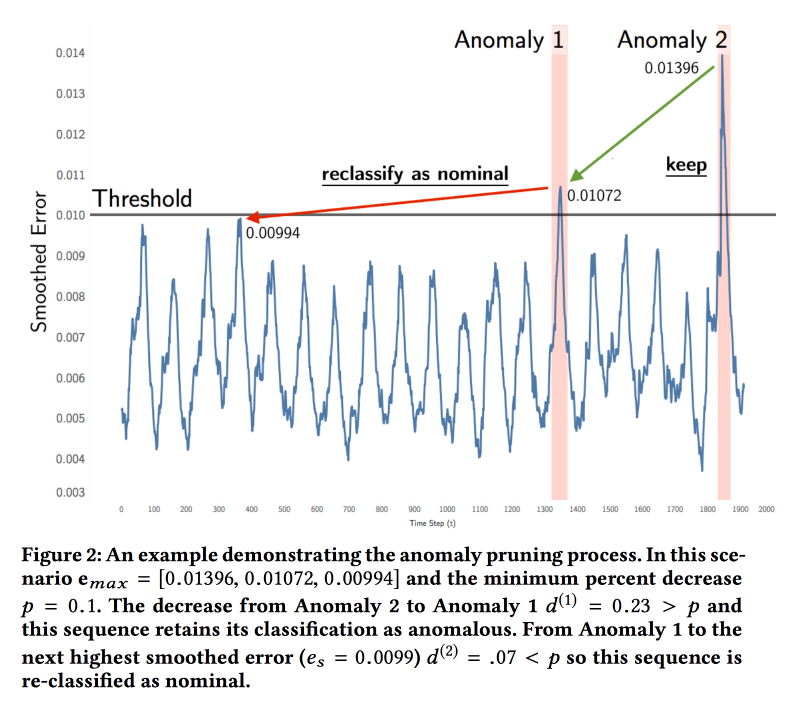
:
soil moisture active passive Curiosity c Mars Science Laboratory. 122 , 80 %. , , . , , .
Explaining Aviation Safety Incidents Using Deep Temporal Multiple Instance Learning
, , . Safety Incidents, , . , . .
, - , . «», .. , . , , . , , .
GRU ,
Multiple Instances Learning . , «» — , . « , , — » ( = ). max pooling .

cross entropy loss . base line
MI-SVM ADOPT.
ActiveRemediation: The Search for Lead Pipes in Flint, Michigan
, ,
.
. 120 . , 2013 , : . , 2014-. 2015- — . , . , …
— , . , . .
. «», . : , , , . , , — , …
6 . , 20 %. data scientist-.
, 19 , , , . , « ». , , XGBoost - . ( 7 % , ).
Las autoridades no se atrevieron a cavar modelos de acuerdo con el pronóstico, pero les dieron a los muchachos un limpiador de suciedad, que podría llegar a las tuberías con relativamente poco daño, para verificar qué había allí: cobre o plomo. Con esta máquina, los muchachos comenzaron a practicar el "aprendizaje activo" y se convencieron de la efectividad del modelo. Después de analizar los datos retrospectivamente, consideramos que el uso del modelo en un formato de aprendizaje activo reduciría el exceso de costos del 16% al 3%. Además, señalaron que en el proceso de interacción con los científicos, las autoridades mejoraron significativamente su actitud hacia los datos: en lugar de folletos y tabletas dispersas, apareció un portal normal en Excel para monitorear el proceso de reemplazo del suministro de agua.
Después de analizar los datos retrospectivamente, consideramos que el uso del modelo en un formato de aprendizaje activo reduciría el exceso de costos del 16% al 3%. Además, señalaron que en el proceso de interacción con los científicos, las autoridades mejoraron significativamente su actitud hacia los datos: en lugar de folletos y tabletas dispersas, apareció un portal normal en Excel para monitorear el proceso de reemplazo del suministro de agua.Una tubería dinámica para la predicción del riesgo de incendio espacio-temporal
En conclusión, otro punto doloroso son las inspecciones de incendios. Sobre lo que sucede si no se llevan a cabo, nos enteramos en marzo de 2018. En los Estados Unidos, estos casos tampoco son raros. Al mismo tiempo, los recursos para inspeccionar a los bomberos son limitados; deben dirigirse a los lugares con mayor riesgo.
Existen modelos abiertos para evaluar el riesgo de incendios, pero están diseñados para incendios forestales y no son adecuados para la ciudad. Hay algún tipo de sistema en Nueva York, pero está cerrado. Por lo tanto, debe intentar
hacer el suyo .
En colaboración con los bomberos de Pittsburgh, los muchachos recolectaron datos sobre incendios durante varios años, agregaron información sobre demografía, ingresos, formas de negocios, etc., así como otras llamadas al departamento de bomberos que no están relacionadas con incendios. Y trataron de evaluar el riesgo de incendio con base en estos datos.
Se enseñan dos modelos diferentes de XGBoost: para hogares y bienes raíces comerciales. La calidad del trabajo se evaluó, en primer lugar, de acuerdo con
Kappa en vista del fuerte desequilibrio de las clases.
Agregar factores dinámicos (llamadas al departamento de bomberos, activación de detectores / alarmas) al modelo mejoró significativamente la calidad, pero para poder usarlos, el modelo tuvo que ser recalculado cada semana. Según el pronóstico, los modelos crearon un bozal web agradable para los inspectores de incendios que muestran dónde se encuentran los objetos con mayor riesgo.
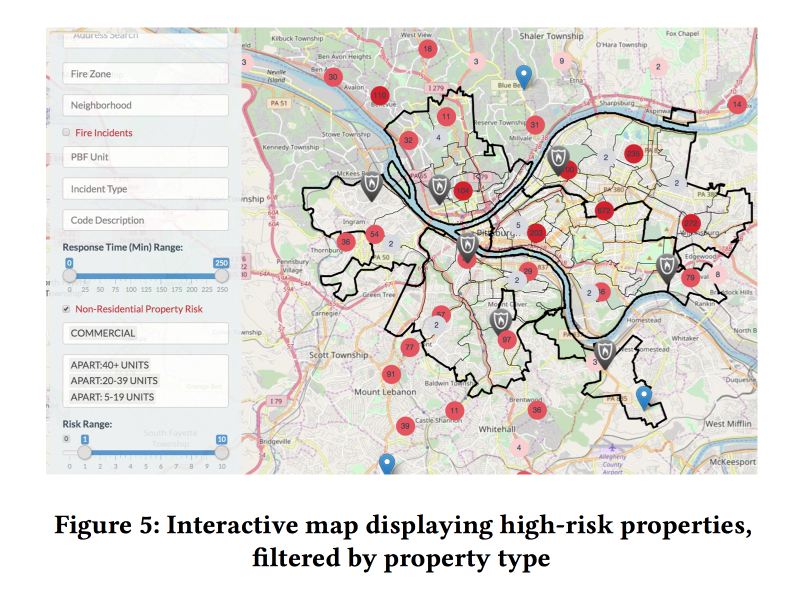
Se analizó la importancia de los síntomas. Entre las características importantes para el comercio estaban relacionadas con las falsas alarmas (aparentemente, el cierre va más allá). Pero para los hogares: la cantidad de impuestos pagados (hola imparcialidad, las inspecciones de incendios en las zonas pobres serán más frecuentes)