
Así que el quinto, último día de KDD terminó. Logré escuchar algunos informes interesantes de Facebook y Google AI, recordar tácticas de fútbol y generar algunos químicos. Acerca de esto y no solo: debajo del corte. ¡Nos vemos en un año en Anchorage, la capital de Alaska!
Sobre el aprendizaje de Big Data para problemas de datos pequeños
El informe de la mañana del
profesor chino fue duro. El orador claramente cargó libremente durante la preparación, a menudo se extravió, comenzó a saltar diapositivas y, en lugar de hablar por la vida, trató de cargar el cerebro adormecido con las matemáticas.
El bosquejo general de la historia giraba en torno a la idea de que lejos de estar siempre hay muchos datos. Hay, por ejemplo, una larga cola en la que hay muchos ejemplos diversos. Hay conjuntos de datos con una gran cantidad de clases, que, aunque grandes en sí mismos, tienen solo unos pocos registros para cada clase. Como ejemplo de tal conjunto de datos, citó a
Omniglot : caracteres escritos a mano de 50 alfabetos, 1623 clases y 20 imágenes por clase en promedio. Pero, de hecho, en esta perspectiva, también puede considerar conjuntos de datos de tareas de recomendación, cuando tenemos muchos usuarios y no tantas calificaciones para cada uno de ellos individualmente.
¿Qué se puede hacer para facilitar la vida de ML en tal situación? Primero de todo Trate de incorporar el conocimiento del área temática. Esto se puede hacer en una variedad de formas: esto es ingeniería de características, regularización específica y refinamiento de la arquitectura de red. Otra solución común es el aprendizaje por transferencia, creo que casi todos los que trabajaron con imágenes comenzaron actualizando algunos ImageNet a partir de sus datos. En el caso de Omniglot, el donante natural para la transferencia será
MNIST .
Una forma de transferencia puede ser el
aprendizaje de tareas múltiples , sobre el que se ha hablado KDD varias veces. El desarrollo de MTL puede considerarse el enfoque de
metaaprendizaje : al entrenar el algoritmo en muestras de una variedad de tareas, podemos APRENDER no solo parámetros, sino también hiperparámetros (por supuesto, solo si nuestro procedimiento es diferenciable).
Continuando con el tema de las tareas múltiples, podemos llegar al concepto de aprendizaje continuo de por vida, que se puede mostrar más claramente con el ejemplo de la robótica. El robot debe ser capaz de resolver diferentes problemas y, al aprender una nueva tarea, utilizar la experiencia previa. Pero puede considerar este enfoque con el ejemplo de Omniglot: después de aprender uno de los personajes, puede continuar aprendiendo el siguiente, utilizando la experiencia acumulada. Es cierto, un peligroso problema de
olvido catastrófico nos espera a lo largo de este camino, cuando el algoritmo comienza a olvidar lo que ha aprendido antes (para combatir esto, aconseja regularizar el
EWC ).
Además, el orador habló sobre varios de sus trabajos en esta dirección.
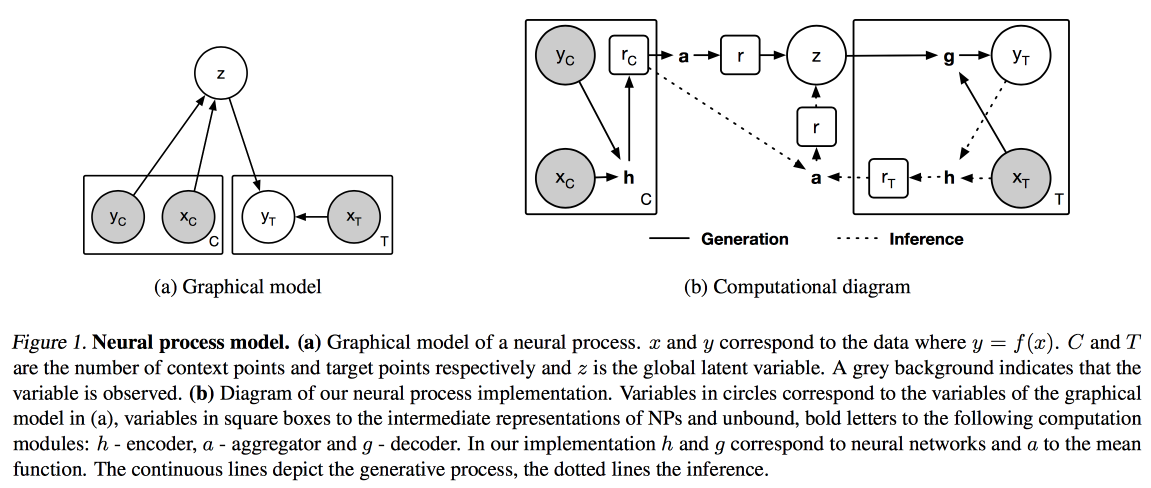
Procesos neuronales (una analogía del proceso gaussiano para redes neuronales) y
Distil and Transfer Learning (optimización del aprendizaje de transferencia para el caso en el que no tomamos como base un modelo previamente entrenado, sino que entrenamos el nuestro en modo multitarea).
Imágenes y textos
Hoy decidí caminar sobre informes aplicados, en la mañana sobre trabajar con textos, imágenes y videos.
Servicio de conversión de corpus
La frecuencia de las publicaciones está creciendo muy rápidamente, es difícil trabajar con esto, especialmente teniendo en cuenta el hecho de que casi toda la búsqueda se realiza en el texto. IBM
ofrece sus servicios para marcar gabinetes de conocimiento científico 3.0. El flujo de trabajo principal se ve así:
- Parsim PDF, reconoce texto en imágenes.
- Verificamos si hay un modelo para esta forma de texto, si es así, hacemos un extracto semántico con él.
- Si no hay modelo, enviamos para anotación y capacitación.
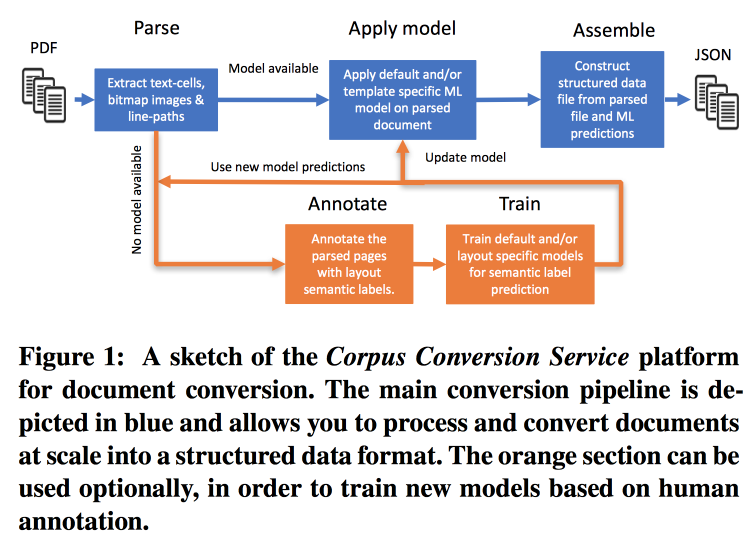
Para entrenar modelos, comenzamos con la agrupación por estructura. Dentro de un clúster que utiliza crowdsourcing, diseñamos varias páginas. Resulta lograr una precisión> 98% cuando se entrena en el marcado de 200-300 documentos. Hay un fuerte desequilibrio de clase en el marcado (casi todo está marcado como texto), por lo que debe observar la precisión de todas las clases y la matriz de confusión.
Los modelos tienen una estructura jerárquica. Por ejemplo, un modelo reconoce una tabla y el otro corta en filas / columnas / encabezados (y sí, una tabla puede anidarse en una tabla). Como modelo, se utiliza una red convolucional.
Por todo esto, ensamblaron un transportador en Docker con Kubernetes y están listos para descargar su corpus de texto por una tarifa razonable. Pueden trabajar no solo con texto PDF, sino también con escaneos; admiten idiomas orientales. Además de simplemente extraer el texto, están trabajando en extraer el gráfico de conocimiento, prometen contar los detalles en el próximo KDD.
Expansión de consultas raras a través de redes generativas adversarias en publicidad de búsqueda
Los motores de búsqueda obtienen la mayor cantidad de dinero de la publicidad, y la publicidad se muestra según lo que el usuario esté buscando. Pero la comparación no siempre es obvia. Por ejemplo, a pedido de boletos aéreos, mostrar anuncios de boletos de autobús baratos no es muy correcto, pero expedia funcionará bien, pero no se puede entender esto por palabras clave. Los modelos de aprendizaje automático pueden ayudar, pero no funcionan bien con consultas raras.
Para resolver este problema, para expandir la consulta de búsqueda,
entrenaremos la GAN condicional de acuerdo con el modelo de secuencia a secuencia. Usamos redes recurrentes (GRU de 2 capas) como arquitectura. Estamos modificando min-max desde GAN, tratando de apuntar a agregar palabras clave para las que hubo clics en los anuncios.
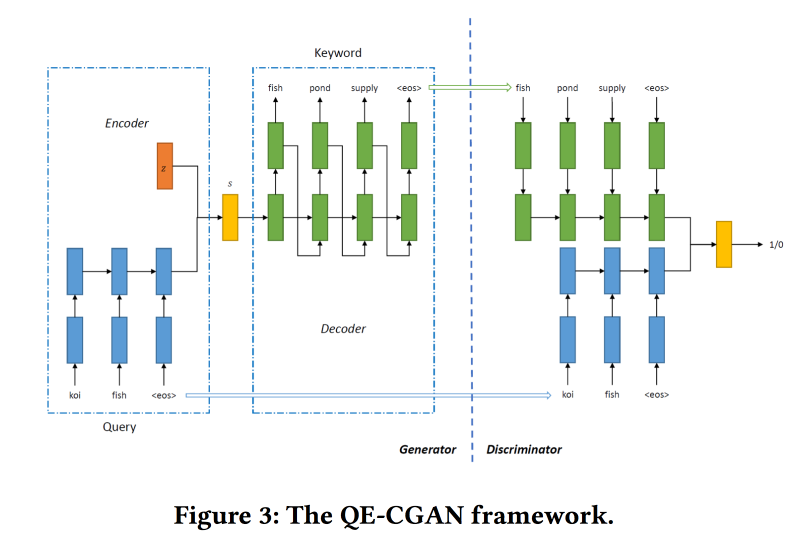
Conjunto de datos para capacitación sobre 14 millones de consultas y 4 millones de palabras clave publicitarias. El modelo propuesto funciona mejor en la larga cola de la solicitud, para lo cual se realizó. Pero en la cabeza, el rendimiento no es mayor.
Aprendizaje métrico profundo colaborativo para la comprensión de video
El trabajo es presentado por los chicos de Google AI. Quieren crear buenas incorporaciones de video y luego usarlas en videos similares, recomendaciones, anotaciones automáticas, etc. Funciona de la siguiente manera:
- Del video, tomamos muestras de cuadros: una imagen y una parte de la pista de audio.
- Extraemos características de las imágenes que Inception aprendió previamente.
- Hacemos lo mismo con el fragmento de audio (no se mostró la arquitectura de red específica). En los signos obtenidos colgamos mallas completamente conectadas con tirones por marcos. Nos normalizamos por L2.
- A continuación, un punto interesante: estamos tratando de asegurarnos de que los videos similares estén cerca en términos de similitud colaborativa. Para hacer esto, utilizamos la pérdida de triplete en el entrenamiento (tomamos un objeto, lo muestreamos de manera similar y diferente, nos aseguramos de que las incrustaciones de lo diferente estén más alejadas del original que lo similar). No olvides que necesitas usar minería negativa.

Se usan para un inicio en frío en videos similares, pero hay un par de problemas: por similitud visual, pueden encontrar videos en otro idioma o videos sobre un tema diferente (especialmente relevante para el formato de video "tablero y conferenciante"). Le aconsejamos que use metainformación adicional sobre el video.
Hay un problema con las recomendaciones: debe coincidir con el historial de navegación y 5 mil millones de videos de Youtube. Para acelerar el trabajo, calculamos para el usuario el vector de incrustación promedio de los videos vistos. Comprobado en las
lentes de
película , sacó trailers de Youtube para su análisis. Mostraron que para los usuarios con un pequeño número de calificaciones funciona mejor.
En el problema de la anotación de video, se utiliza el enfoque
de mezcla de expertos : se entrenan en logreg para incrustarlos en cada posible anotación. Chequeado en
Youtube-8 y mostró un muy buen resultado.
Desambiguación de nombres en AMiner: agrupación, mantenimiento y humanos en el bucle
AMiner : un gráfico para la academia, que proporciona varios servicios para trabajar con literatura. Uno de los problemas: colisiones de nombres de autores y entidades. Se ofrece un algoritmo automático con alguna forma de aprendizaje activo para la solución.
El proceso consta de tres etapas: mediante una búsqueda de texto, recopilamos candidatos (documentos con nombres similares de autores), clúster (con determinación automática del número de clústeres) y compilamos perfiles.

Para considerar la similitud en la agrupación, necesita algún tipo de presentación (emeding). Se puede obtener utilizando el modelo global (en todo el gráfico) o local (para aquellos candidatos que muestrearon). Los patrones de capturas globales que se pueden transferir a nuevos documentos y las ayudas locales tienen en cuenta las características individuales: combinaremos. Para obtener incrustaciones globales, también usan la red siamesa entrenada en la pérdida de triplete, y para las locales: un codificador automático de gráficos (dejé las imágenes en el artículo en aras de ahorrar espacio).
La pregunta más dolorosa es ¿cuántos grupos tengo? El enfoque
X-means no escala a una gran cantidad de grupos; RNN se usa para predecir su número: K grupos se muestrean de un conjunto marcado, luego N ejemplos de estos grupos. Entrenan la red para revelar el número inicial de grupos.

Los datos llegan lo suficientemente rápido, 500 mil por mes, pero lleva semanas ejecutar todo el modelo. Para una rápida inicialización, utilizan la selección de candidatos para búsqueda de texto e IPN para incrustaciones globales. Un punto importante: las personas que marcan lo que debería y no debería estar en el grupo están incluidas en el proceso de aprendizaje. En estos datos, el modelo se vuelve a entrenar.
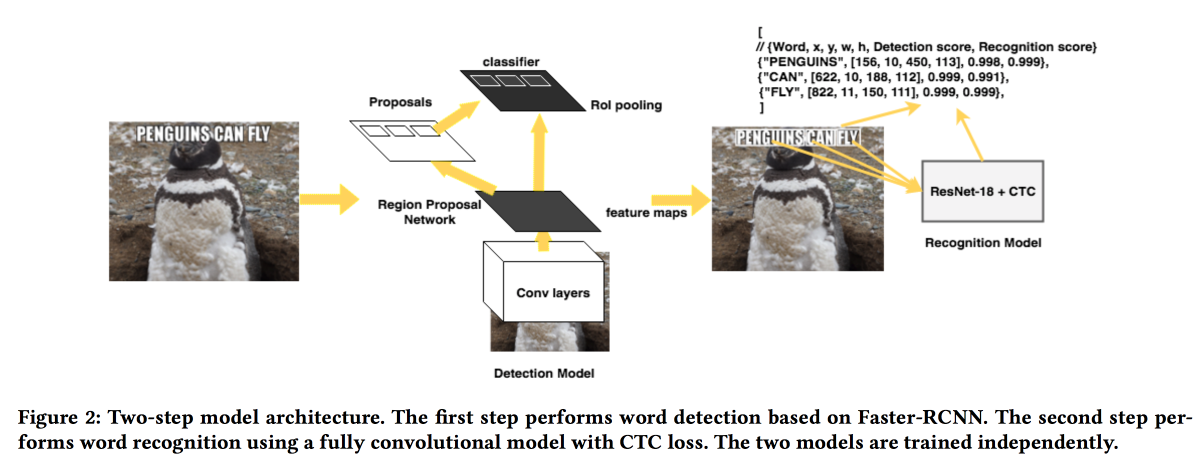
Rosetta: sistema a gran escala para la detección y reconocimiento de texto en imágenes
Los chicos de FB
presentarán su solución para extraer textos de imágenes. El modelo funciona en dos etapas: la primera red determina el texto, la segunda lo reconoce.
Faster-RCNN se utilizó como detector con el reemplazo de
ResNet con
SuffleNet para acelerar el trabajo. Para el reconocimiento, usaron ResNet18 y se entrenaron con la
pérdida de CTC .
Para mejorar la convergencia, utilizamos varios trucos:
- Durante el entrenamiento, se introdujo un pequeño ruido en el resultado del detector.
- Los textos se estiraron horizontalmente en un 20%.
- Aprendizaje curricular utilizado: ejemplos gradualmente complicados (por el número de caracteres).
Ciencias naturales
La última sección de contenido de la conferencia estuvo dedicada a las "ciencias naturales". Un poco de química, fútbol y más.
Detección de efecto de tratamiento heterogéneo controlado por tasa de descubrimiento falso para experimento controlado en línea
Trabajo muy interesante sobre el análisis de pruebas A / B. El problema con la mayoría de los sistemas de análisis es que observan el efecto promedio, mientras que en realidad, la mayoría de los usuarios reaccionan al cambio de manera positiva y negativa, y se puede lograr más si comprende a quién se dirigió la función y quién no

Puede dividir a los usuarios en cohortes por adelantado y evaluar el efecto por ellos, pero con un aumento en el número de cohortes, aumenta el número de falsos positivos (puede intentar reducirlos usando el método
Bonferoni , pero es demasiado conservador). Además, debe conocer las cohortes de antemano. Los chicos sugieren usar una combinación de varios enfoques: combinar el mecanismo de detección de efectos heterogéneos (HTE) con métodos de filtrado de falsos positivos.
Para detectar un efecto heterogéneo, una matriz con
x=0/1 0/1 (en el grupo o no) y el efecto se transforma en una matriz en la que en lugar de
0/1 encuentra el número
(x — p)/p(1-p) , donde
p es la probabilidad de inclusión en la prueba A continuación, se enseña un modelo para predecir el efecto de
x (regresión lineal o de lazo). Aquellos usuarios para quienes el resultado es significativamente diferente del pronóstico son candidatos para la separación en un efecto "heterogéneo".
Luego, probamos dos métodos para el filtro falso positivo:
Benjamini-Hochberg y
Knockoffs . El primero es mucho más fácil de implementar, pero el segundo es más flexible y muestra resultados más interesantes.
Maldición del ganador: estimación del sesgo para los efectos totales de las características en experimentos controlados en línea
Los chicos de AirBnB hablaron un poco sobre cómo mejoraron el sistema de análisis de experimentos. El problema principal es que al experimentar con muchos sesgos, consideramos el sesgo de selección en este trabajo: seleccionamos experimentos con el mejor resultado
observado , pero esto significa que seleccionaremos con mayor frecuencia experimentos en los que el resultado observado es demasiado alto en relación con el real.
Como resultado, al combinar experimentos, el efecto final es menor que la suma de los efectos de los experimentos. Pero conociendo este sesgo, puede intentar evaluarlo y restarlo utilizando el aparato estadístico (suponiendo que la diferencia entre los efectos reales y observados se distribuya normalmente). En resumen, algo como esto:

Y si agrega
bootstrap , incluso puede construir intervalos de confianza para una estimación imparcial del efecto.
Descubrimiento automático de tácticas en datos de partidos de fútbol espacio-temporales
Interesante trabajo sobre la divulgación de las tácticas de los equipos de fútbol. Los datos del partido están disponibles en forma de secuencias de acciones (pase / toque / golpe, etc.), alrededor de 2000 acciones por partido. Combina atributos continuos (coordenadas / tiempo) y discretos (jugador). Es importante expandir los datos utilizando el conocimiento del área temática (agregue el rol del jugador y el tipo de pase, por ejemplo), pero no siempre funciona. Además, diferentes tipos de usuarios están interesados en diferentes tipos de patrones: entrenadores - exitosos, delantero - defensivo, periodista - únicos.
El método propuesto es el siguiente:
- Divida el flujo en fases para la transición de la pelota entre los equipos.
- Fases del clúster utilizando deformación dinámica del tiempo como distancia. Cómo determinar el número de clústeres, no contados.
- Clasificamos los grupos por propósito (para quienes buscamos tácticas).
- Minimizamos los patrones dentro del grupo (minería de patrones secuenciales CM-SPADE ), abandonamos las coordenadas de acuerdo con los segmentos de campo (flanco izquierdo / derecho, medio, penalización).
- Clasifique los patrones nuevamente.
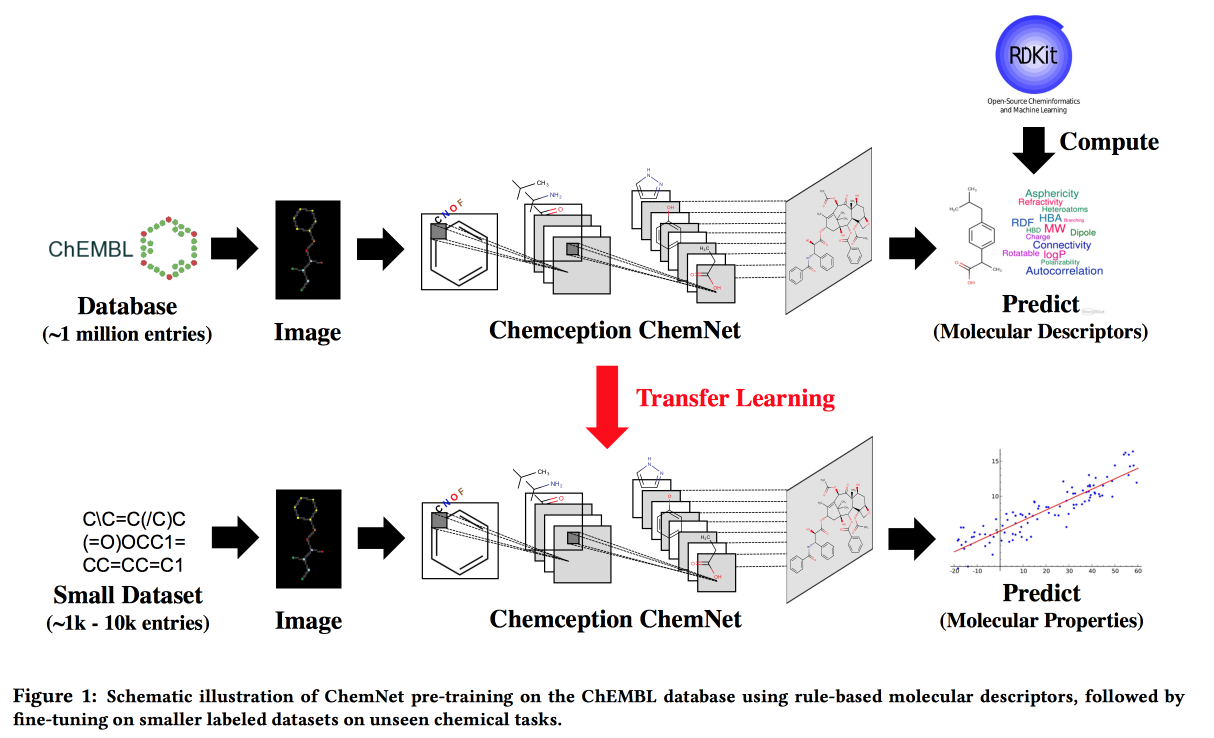
Uso de etiquetas basadas en reglas para un aprendizaje supervisado débil: una ChemNet para la propiedad química transferible P
Trabaje para situaciones en las que no hay grandes datos, pero existen modelos teóricos con reglas jerárquicas. Usando la teoría, construimos una red neuronal "experta". Aplicable a la tarea de desarrollar compuestos químicos con propiedades deseadas.
Me gustaría, por analogía con las imágenes, obtener una red en la que las capas correspondan a diferentes niveles de abstracción: átomos / grupos funcionales / fragmentos / moléculas. En el pasado, había enfoques para grandes conjuntos de datos etiquetados, por ejemplo, SMILE2Vect: use
SMILE para traducir una fórmula en texto y luego aplique técnicas para construir incrustaciones para textos.
Pero, ¿qué pasa si no hay un gran conjunto de datos marcado? Enseñamos a ChemNet usando
RDKit para los objetivos que puede predecir, y luego transferimos el aprendizaje para resolver el problema. Mostramos que podemos competir con modelos entrenados en datos etiquetados. Puede aprender en capas, lo que significa lograr el objetivo: desglosar las capas por nivel de abstracción.
PrePeP: una herramienta para la identificación y caracterización de compuestos de interferencia de análisis panorámico
Desarrollamos medicamentos , utilizamos la ciencia de datos para seleccionar candidatos. Hay moléculas que reaccionan con muchas sustancias. No se pueden usar como medicamentos, pero a menudo aparecen en las etapas iniciales de la prueba. Estas son las moléculas de
DOLOR que filtraremos .
Hay dificultades: los datos son descargados y arrogantes (107 mil), las clases están desequilibradas (positivos 0.5%) y los químicos quieren obtener un modelo interpretado. Combine los datos de la estructura gráfica (
gSpan ) de la molécula y las huellas dactilares químicas. Lucharon con el equilibrio al embolsar muestras negativas, árboles enseñados, pronósticos agregados por mayoría de votos.