 Para que el monitoreo sea útil, tenemos que resolver diferentes escenarios de problemas probables y diseñar paneles y disparadores de tal manera que entiendan de inmediato la causa del incidente.
Para que el monitoreo sea útil, tenemos que resolver diferentes escenarios de problemas probables y diseñar paneles y disparadores de tal manera que entiendan de inmediato la causa del incidente.
En algunos casos, entendemos bien cómo funciona este o aquel componente de la infraestructura, y luego se sabe de antemano qué métricas serán útiles. Y a veces eliminamos casi todas las métricas posibles con el máximo detalle y luego observamos cómo ciertos problemas son visibles en ellas.
Hoy veremos cómo y por qué los postgres Write-Ahead Log (WAL) se pueden hinchar. Como de costumbre, ejemplos de la vida real en imágenes.
Un poco de teoría WAL en postgresql
Cualquier cambio en la base de datos se registra primero en el WAL, y solo después de eso, los datos en la página en la memoria caché del búfer se cambian y se marcan como sucios, que deben guardarse en el disco. Además, el proceso CHECKPOINT se inicia periódicamente, lo que guarda todas las páginas sucias en el disco y el número de segmento WAL, hasta el cual todas las páginas modificadas ya están escritas en el disco.
Si, por alguna razón, postgresql se bloquea y comienza de nuevo, todos los segmentos WAL del último punto de control se reproducirán durante el proceso de recuperación.
Los segmentos WAL que preceden al punto de control ya no nos serán útiles para la recuperación de la base de datos posterior al bloqueo, pero en el postgres WAL también participa en el proceso de replicación, y la copia de seguridad de todos los segmentos para la Recuperación de punto en el tiempo - PITR también se puede configurar.
Un ingeniero experimentado probablemente ya entendió todo, cómo se rompe en la vida real :)
¡Veamos los gráficos!
WAL hinchazón # 1
Nuestro agente de monitoreo para cada instancia encontrada de postgres calcula la ruta en el disco al directorio con wal y elimina tanto el tamaño total como la cantidad de archivos (segmentos):
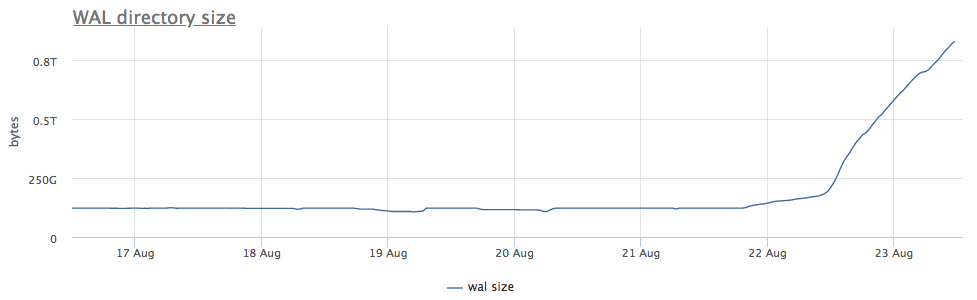
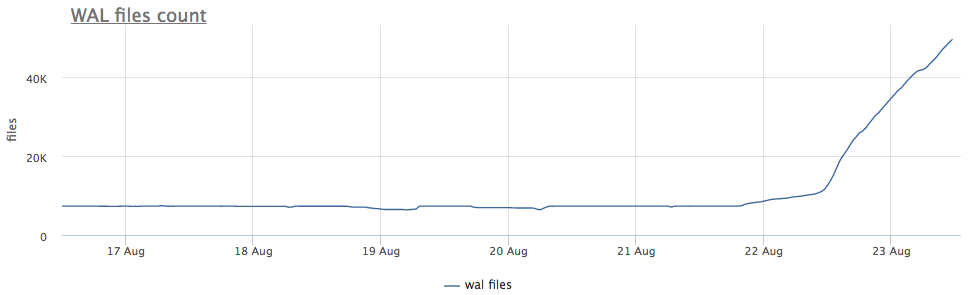
En primer lugar, observamos cuánto tiempo llevamos ejecutando CHECKPOINT.
Tomamos métricas de pg_stat_bgwriter:
- checkpoints_timed - contador de lanzamientos de puntos de control que ocurrieron con la condición de que el tiempo desde el último punto de control se haya excedido en más de pg_settings.checkpoint_timeout
- checkpoints_req : contador de inicios del punto de control con la condición de que se supere el tamaño de wal desde el último punto de control
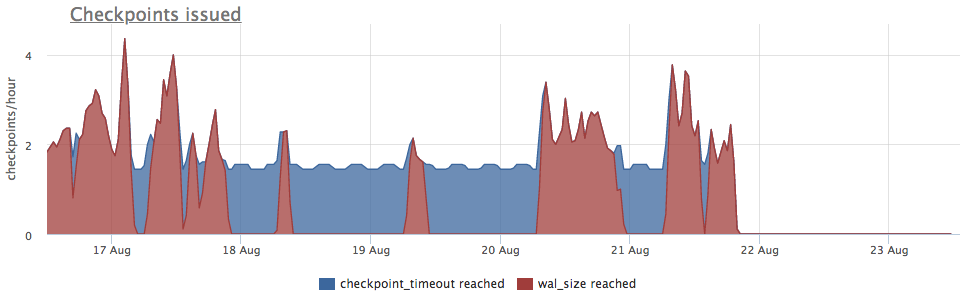
Vemos que el punto de control no se ha lanzado durante mucho tiempo. En este caso, es imposible entender directamente la razón por la que NO se inicia este proceso (pero sería genial, por supuesto), pero sabemos que en postgres surgen muchos problemas debido a las largas transacciones.
Comprobamos:

Además, está claro qué hacer:
- matar una transacción
- lidiar con las razones por las que es largo
- espera, pero comprueba que hay suficiente espacio
Otro punto importante: en las réplicas conectadas a este servidor, ¡wal también está hinchado !
Archivo WAL
Te recuerdo en ocasiones: ¡la replicación no es una copia de seguridad!
Una buena copia de seguridad debería permitirle recuperarse en cualquier momento. Por ejemplo, si alguien "accidentalmente" realizó
DELETE FROM very_important_tbl;
Entonces deberíamos poder restaurar la base de datos al estado exactamente antes de esta transacción. Esto se llama PITR (recuperación en un punto en el tiempo) y se implementa en postgresql con copias de seguridad periódicas completas de la base de datos + guardando todos los segmentos de WAL después del volcado.
La configuración archive_command es responsable de hacer una copia de seguridad de wal, postgres simplemente inicia el comando que especificó, y si se completa sin un error, se considera que el segmento se ha copiado con éxito. Si ocurre un error, lo intentará hasta la victoria, el segmento estará en el disco.
Bueno, y como ilustración, gráficos de wal archivado roto:
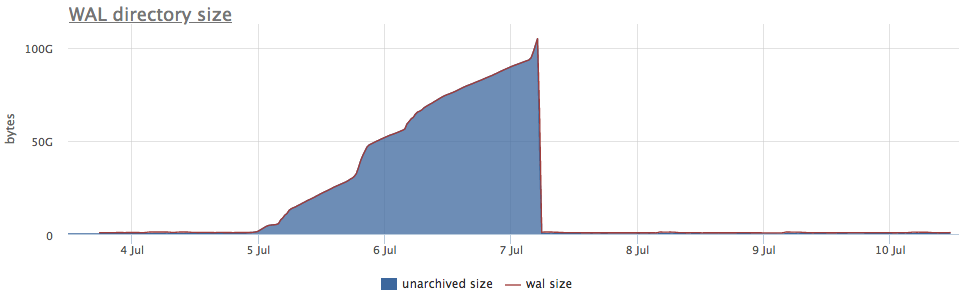
Aquí, además del tamaño de todos los segmentos wal, hay un tamaño no archivado : este es el tamaño de los segmentos que aún no se consideran guardados con éxito.
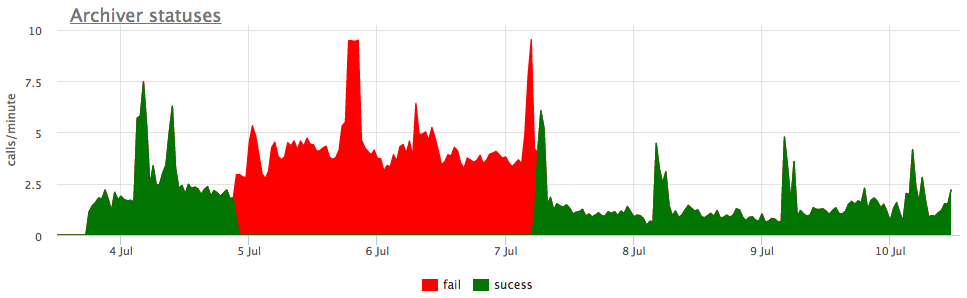
Consideramos los estados según los contadores de pg_stat_archiver. Para la cantidad de archivos, realizamos un disparo automático para todos los clientes, ya que a menudo se descompone, especialmente cuando se utiliza algo de almacenamiento en la nube como destino (S3, por ejemplo).
Retraso de replicación
La replicación de streaming en progreso funciona mediante la transferencia y reproducción de wal en réplicas. Si por alguna razón la réplica se queda atrás y no pierde una cierta cantidad de segmentos, el asistente almacenará segmentos pg_settings.wal_keep_segments para ella. Si la réplica se queda atrás en un mayor número de segmentos, ya no podrá conectarse al maestro (tendrá que volver a verterla).
Para garantizar la preservación de cualquier número deseado de segmentos, la funcionalidad de las ranuras de replicación apareció en 9.4, que se discutirá más adelante.
Ranuras de replicación
Si la replicación se configura usando la ranura de replicación y hubo al menos una conexión de réplica exitosa a la ranura, entonces, en caso de que la réplica desaparezca, los postgres almacenarán todos los nuevos segmentos wal hasta que se agote el lugar.
Es decir, una ranura de replicación olvidada puede causar hinchazón de la pared. Pero afortunadamente, podemos monitorear el estado de las ranuras a través de pg_replication_slots.
Así es como se ve en un ejemplo en vivo:
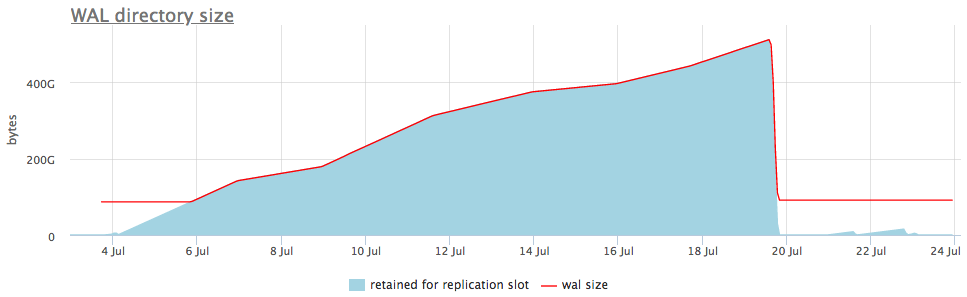

En el gráfico superior, junto al tamaño de la pared, siempre mostramos una ranura con el número máximo de segmentos acumulados, pero también hay un gráfico detallado que mostrará qué ranura está hinchada.
Una vez que comprendamos qué tipo de ranura está recopilando datos, podemos reparar las réplicas asociadas con él o simplemente eliminarlo.
Cité los casos más comunes de inflamación de la pared, pero estoy seguro de que hay otros casos (a veces también se encuentran errores en postgres). Por lo tanto, es importante controlar el tamaño de la pared y responder a los problemas antes de que se agote el espacio en disco y la base de datos deje de atender solicitudes.
Nuestro servicio de monitoreo ya sabe cómo recopilar todo esto, visualizarlo y alertarlo correctamente. Y también tenemos una opción de entrega local para aquellos a quienes la nube no se adapta.