
Al abrir su cafetería, le gustaría saber la respuesta a la siguiente pregunta: "¿dónde está la otra cafetería más cercana a este punto?" Esta información lo ayudará a comprender mejor a sus competidores.
Este es un ejemplo del problema de búsqueda del "
vecino más cercano ", que se estudia ampliamente en informática. Dado un conjunto de información y un nuevo punto, ¿y necesita encontrar a qué punto de los existentes será el más cercano? Tal pregunta surge en muchas situaciones cotidianas en áreas como la investigación del genoma, la búsqueda de imágenes y las recomendaciones de Spotify.
Pero, a diferencia del ejemplo del café, las preguntas sobre el vecino más cercano a menudo son muy complicadas. En las últimas décadas, las mejores mentes entre los científicos informáticos se han propuesto encontrar las mejores formas de resolver este problema. En particular, trataron de hacer frente a las complicaciones derivadas del hecho de que en diferentes conjuntos de datos puede haber definiciones muy diferentes de la "proximidad" de los puntos entre sí.
Y ahora, un equipo de informáticos ha ideado una forma completamente nueva de resolver el problema de encontrar al vecino más cercano. En un
par de documentos, cinco científicos describieron en detalle el primer método generalizado para resolver el problema de encontrar el vecino más cercano para datos complejos.
"Este es el primer resultado que cubre una amplia gama de espacios utilizando una sola técnica algorítmica", dijo
Peter Indik , especialista en TI del Instituto de Tecnología de Massachusetts, una figura influyente en el campo de los desarrollos relacionados con esta tarea.
Diferencia de distancia
Estamos tan apegados a la única forma de determinar la distancia que es fácil perder de vista la posibilidad de otras formas. Por lo general, medimos la distancia como Euclidiana, como una línea recta entre dos puntos. Sin embargo, hay situaciones en las que otras definiciones tienen más sentido. Por ejemplo, la
distancia de Manhattan le hace girar 90 grados, como si se moviera a lo largo de una red rectangular de carreteras. Para medir una distancia que podría ser de 5 kilómetros en línea recta, es posible que deba cruzar la ciudad 3 km en una dirección y luego 4 más en la otra.
También es posible hablar de distancias no en un sentido geográfico. ¿Cuál es la distancia entre dos personas en una red social, o dos películas, o dos genomas? En estos ejemplos, la distancia indica el grado de similitud.
Hay docenas de métricas de distancia, cada una de las cuales es adecuada para una tarea específica. Tomemos, por ejemplo, dos genomas. Los biólogos los comparan usando la "
distancia de Levenshtein " o la distancia de edición. La distancia de edición entre dos secuencias del genoma es el número de adiciones, eliminaciones, inserciones y sustituciones necesarias para convertir una de ellas en otra.
La distancia de edición y la distancia euclidiana son dos conceptos diferentes de distancia, y es imposible reducir uno a otro. Esta incompatibilidad existe para muchos pares de métricas de distancia, y es un obstáculo para los científicos informáticos que intentan desarrollar algoritmos para encontrar el vecino más cercano. Esto significa que un algoritmo que funciona para un tipo de distancia no funcionará para otro; más precisamente, así fue hasta ahora, hasta que apareció un nuevo tipo de búsqueda.
 Alexander Andoni
Alexander AndoniCírculo al cuadrado
El enfoque estándar para encontrar el vecino más cercano es dividir los datos existentes en subgrupos. Si, por ejemplo, sus datos describen la ubicación de las vacas en el pasto, entonces puede encerrarlas en un círculo. Luego ponemos una nueva vaca en el prado y hacemos la pregunta: ¿en cuál de los círculos cae? Está prácticamente garantizado que el vecino más cercano de la nueva vaca estará en el mismo círculo.
Luego repite el proceso. Divida los círculos en subcircuitos, divida más estas celdas, y así sucesivamente. Como resultado, hay una celda con solo dos puntos: el existente y el nuevo. Este punto existente será tu vecino más cercano.
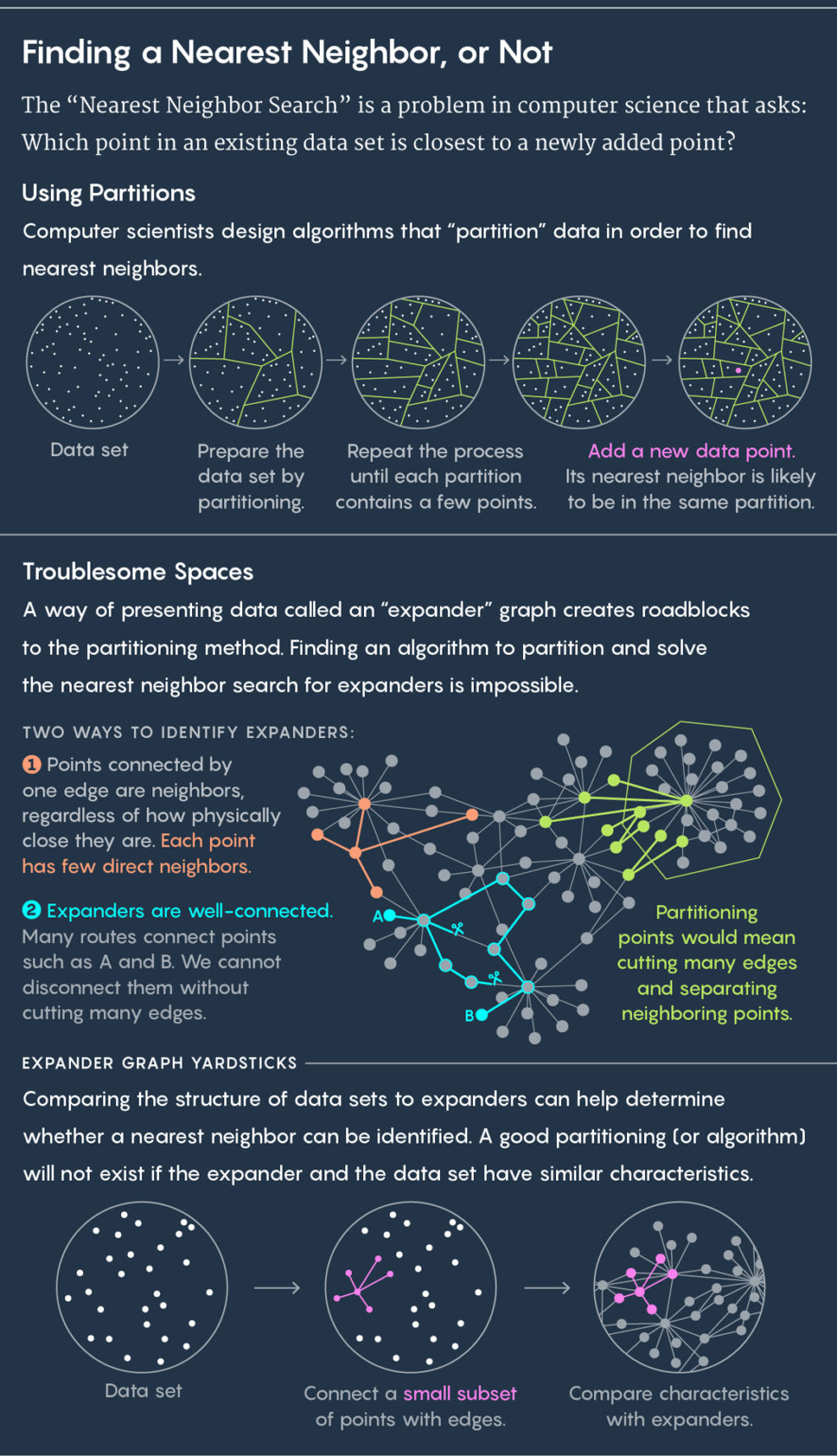 Arriba está la división de datos en celdas. A continuación se muestra el uso del gráfico de extensión.
Arriba está la división de datos en celdas. A continuación se muestra el uso del gráfico de extensión.Los algoritmos dibujan celdas, los buenos algoritmos las dibujan rápida y bien, es decir, para que no haya una situación en la que una nueva vaca caiga en un círculo y su vecino más cercano termine en otro círculo. "Queremos que los puntos cercanos en estas celdas aparezcan con mayor frecuencia en el mismo disco entre ellos, y que los distantes sean raros", dijo
Ilya Razenshtein , especialista en informática de Microsoft Research, coautor del nuevo trabajo, que también involucró a
Alexander Andoni de la Universidad de Columbia. ,
Assaf Naor de Princeton,
Alexander Nikolov de la Universidad de Toronto y
Eric Weingarten de la Universidad de Columbia.
Durante muchos años, los científicos informáticos han ideado varios algoritmos para dibujar tales células. Para datos pequeños, como donde un punto está determinado por un pequeño número de valores, por ejemplo, la ubicación de una vaca en una pradera, los algoritmos crean el llamado "
Diagramas de Voronoi " que responden con precisión la pregunta sobre el vecino más cercano.
Para los datos multidimensionales, en los que un punto puede determinarse por cientos o miles de valores, los diagramas de Voronoi requieren demasiada potencia informática. En cambio, los programadores dibujan celdas utilizando "
hashing localmente sensible "
, descrito por primera
vez por Indik y Rajiv Motwani en 1998. Los algoritmos de LF dibujan celdas al azar. Por lo tanto, trabajan más rápido, pero con menos precisión: en lugar de encontrar el vecino más cercano exacto, garantizan que un punto se encuentre a una distancia determinada del vecino más cercano real. Esto se puede imaginar como una recomendación de la película de Netflix, que no es perfecta, pero lo suficientemente buena.
Desde finales de la década de 1990, los científicos informáticos han creado algoritmos LF que brindan soluciones aproximadas para la tarea de encontrar el vecino más cercano para métricas de distancia dadas. Los algoritmos eran muy especializados, y el algoritmo desarrollado para una métrica de distancia no podía usarse para otra.
“Puede crear un algoritmo muy efectivo para la distancia euclidiana o de Manhattan, para algunos casos específicos. Pero no teníamos un algoritmo que funcionara en una gran clase de distancias ", dijo Indik.
Como los algoritmos que funcionan con una métrica no se pueden usar para otra, los programadores idearon una estrategia alternativa. A través de un proceso llamado "incrustación", impusieron una métrica, para la cual no tenían un buen algoritmo, en la métrica para la que era. Sin embargo, la correspondencia de las métricas generalmente era inexacta, algo así como una clavija cuadrada en un agujero redondo. En algunos casos, la incrustación no funcionó en absoluto. Era necesario encontrar una forma universal de responder la pregunta sobre el vecino más cercano.
 Ilya Razenshtein
Ilya RazenshteinResultado inesperado
En un nuevo trabajo, los científicos abandonaron la búsqueda de algoritmos especiales. En cambio, hicieron una pregunta más amplia: ¿qué impide el desarrollo de un algoritmo en una determinada métrica de distancia?
Decidieron que la culpa era de la desagradable situación asociada con el gráfico expansivo o
expansor . Un expansor es un tipo especial de gráfico, un conjunto de puntos conectados por bordes. Los gráficos tienen su propia métrica de distancia. La distancia entre dos puntos del gráfico es el número mínimo de líneas necesarias para ir de un punto a otro. Puede imaginar un gráfico que represente las conexiones entre las personas en las redes sociales, y luego la distancia entre las personas será igual al número de conexiones que las separan. Si, por ejemplo, Julian Moore tiene un amigo que tiene un amigo que tiene a Kevin Bacon como amigo, entonces la distancia de Moore a Bacon es de tres.
Un expansor es un tipo especial de gráfico que tiene dos propiedades conflictivas a primera vista. Tiene una alta conectividad, es decir, dos puntos no se pueden desconectar sin cortar varios bordes. Al mismo tiempo, la mayoría de los puntos están conectados a un número muy pequeño de otros. Debido a esto, la mayoría de los puntos están lejos el uno del otro.
Una combinación única de estas propiedades (buena conectividad y un pequeño número de bordes) lleva al hecho de que en los expansores es imposible realizar una búsqueda rápida del vecino más cercano. Cualquier intento de dividirlo en celdas separará los puntos que se encuentran cerca uno del otro.
"Cualquier forma de cortar el expansor en dos partes requiere cortar varias costillas, lo que divide muchos vértices muy separados", dijo Weingarten, coautor del trabajo.
Para el verano de 2016, Andoni, Nyokolov, Rasenstein y Vanguarten sabían que para los expansores no se podía encontrar un buen algoritmo para encontrar el vecino más cercano. Pero querían demostrar que es imposible construir tales algoritmos para muchas otras métricas de distancia, métricas, cuando se buscan buenos algoritmos para los cuales los científicos informáticos se han detenido.
Para encontrar evidencia de la imposibilidad de tales algoritmos, necesitaban encontrar una manera de integrar la métrica del expansor en otras métricas de distancia. Con este método, podrían determinar que otras métricas tienen propiedades similares a las propiedades del expansor, lo que les impide hacer buenos algoritmos.
 Eric Weingarten
Eric WeingartenCuatro informáticos acudieron a Assaf Naoru, un matemático de la Universidad de Princeton, cuyo trabajo previo era muy adecuado para el tema de los expansores. Le pidieron que ayudara a probar que los expansores pueden integrarse en varios tipos de métricas. Naor regresó rápidamente con una respuesta, pero no la que esperaban de él.
"Le pedimos a Assaf que nos ayudara con esta declaración, y él demostró lo contrario", dijo Andoni.
Naor demostró que los expansores no encajan en una gran clase de métricas de distancia conocidas como "
espacios normados " (que también incluye métricas como los espacios euclidianos y Manhattan). Según la evidencia de Naor, los científicos siguieron la siguiente cadena lógica: si los expansores no encajan en la métrica de distancia, entonces debería haber una buena manera de dividirlos en células (ya que, como demostraron, las propiedades de los expansores son el único obstáculo para esto). Por lo tanto, debe haber un buen algoritmo para encontrar el vecino más cercano, incluso si nadie lo ha encontrado aún.
Cinco investigadores publicaron sus hallazgos en un
documento que completaron en noviembre y subieron en abril. Fue seguido por un segundo trabajo, que completaron este año y
publicado en agosto. En él, utilizaron la información obtenida al escribir el primer trabajo para encontrar un algoritmo rápido para encontrar el vecino más cercano para espacios normados.
"El primer trabajo demostró la existencia de una forma de dividir la métrica en dos partes, pero no había una receta para hacerlo rápidamente", dijo Weingarten. "En el segundo trabajo, argumentamos que hay una manera de separar los puntos y, además, que esta separación se puede hacer usando algoritmos rápidos".
Como resultado, los nuevos trabajos por primera vez generalizan la búsqueda del vecino más cercano en datos multidimensionales. En lugar de desarrollar algoritmos especializados para métricas específicas, los programadores tienen un enfoque universal para encontrar algoritmos.
"Este es un método ordenado para desarrollar algoritmos para encontrar el vecino más cercano en cualquiera de las métricas de distancia que necesita", dijo Weingarten.