
Ahora todos hablan mucho sobre inteligencia artificial y su aplicación en todas las áreas de la empresa. Sin embargo, hay algunas áreas donde, desde la antigüedad, ha dominado un tipo de modelo, la llamada "caja blanca": regresión logística. Una de esas áreas es la calificación de crédito bancario.
Hay varias razones para esto:
- Los coeficientes de regresión pueden explicarse fácilmente, a diferencia de los cuadros negros como el refuerzo, que pueden incluir más de 500 variables
- La administración todavía no confía en el aprendizaje automático debido a la dificultad de interpretar modelos
- Existen requisitos no escritos del regulador para la interpretación de los modelos: en cualquier momento, por ejemplo, el Banco Central puede solicitar una explicación: por qué se rechazó un préstamo al prestatario
- Las empresas utilizan programas externos de minería de datos (por ejemplo, minero rápido, SAS Enterprise Miner, STATISTICA o cualquier otro paquete) que le permiten aprender rápidamente cómo construir modelos sin siquiera tener habilidades de programación.
Estas razones hacen que sea casi imposible utilizar modelos complejos de aprendizaje automático en algunas áreas, por lo que es importante poder "exprimir al máximo" una simple regresión logística que sea fácil de explicar e interpretar.
En esta publicación, hablaremos sobre cómo, al construir la puntuación, abandonamos los paquetes de minería de datos externos a favor de las soluciones de código abierto en forma de Python, aumentamos la velocidad de desarrollo varias veces y también mejoramos la calidad de todos los modelos.
Proceso de puntuación
El proceso clásico de construir modelos de puntuación en regresión se ve así:
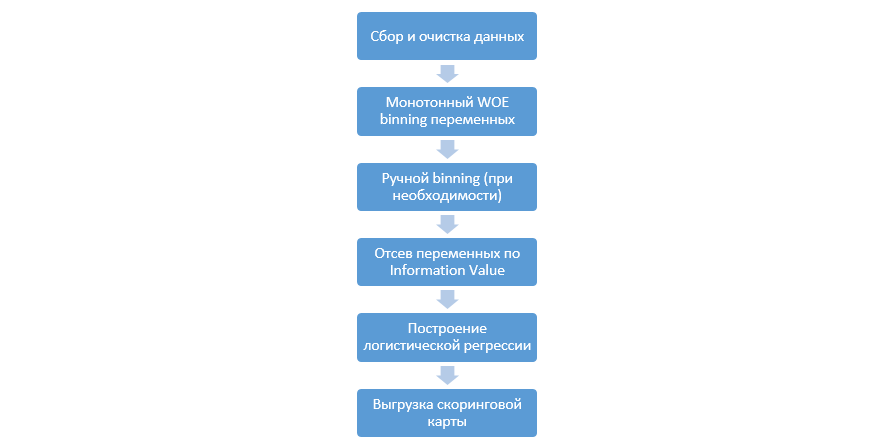
Puede variar de una compañía a otra, pero las etapas principales permanecen constantes. Siempre necesitamos realizar un binning de variables (en contraste con el paradigma de aprendizaje automático, donde en la mayoría de los casos solo se necesita una codificación categórica), su selección por valor de información (IV) y carga manual de todos los coeficientes y contenedores para su posterior integración en DSL.
Este enfoque para construir tarjetas de puntuación funcionó bien en los años 90, pero las tecnologías de los paquetes de minería de datos clásicos están muy desactualizadas y no permiten el uso de nuevas técnicas, como, por ejemplo, la regularización L2 en regresión, que puede mejorar significativamente la calidad de los modelos.
En un momento, como estudio, decidimos reproducir todos los pasos que los analistas realizan al construir la puntuación, complementarlos con el conocimiento de los científicos de datos y automatizar todo el proceso tanto como sea posible.
Mejora de Python
Como herramienta de desarrollo, elegimos Python por su simplicidad y buenas bibliotecas, y comenzamos a seguir todos los pasos en orden.
El primer paso es recopilar datos y generar variables; esta etapa es una parte importante del trabajo de los analistas.
En Python, puede cargar los datos recopilados de la base de datos usando pymysql.
Código para descargar de la base de datosdef con(): conn = pymysql.connect( host='10.100.10.100', port=3306, user='******* ', password='*****', db='mysql') return conn; df = pd.read_sql(''' SELECT * FROM idf_ru.data_for_scoring ''', con=con())
A continuación, reemplazamos los valores raros y faltantes con una categoría separada para evitar el sobreajuste, seleccionar el objetivo, eliminar las columnas adicionales y dividir por tren y prueba.
Preparación de datos def filling(df): cat_vars = df.select_dtypes(include=[object]).columns num_vars = df.select_dtypes(include=[np.number]).columns df[cat_vars] = df[cat_vars].fillna('_MISSING_') df[num_vars] = df[num_vars].fillna(np.nan) return df def replace_not_frequent(df, cols, perc_min=5, value_to_replace = "_ELSE_"): else_df = pd.DataFrame(columns=['var', 'list']) for i in cols: if i != 'date_requested' and i != 'credit_id': t = df[i].value_counts(normalize=True) q = list(t[t.values < perc_min/100].index) if q: else_df = else_df.append(pd.DataFrame([[i, q]], columns=['var', 'list'])) df.loc[df[i].value_counts(normalize=True)[df[i]].values < perc_min/100, i] =value_to_replace else_df = else_df.set_index('var') return df, else_df cat_vars = df.select_dtypes(include=[object]).columns df = filling(df) df, else_df = replace_not_frequent_2(df, cat_vars) df.drop(['credit_id', 'target_value', 'bor_credit_id', 'bchg_credit_id', 'last_credit_id', 'bcacr_credit_id', 'bor_bonuses_got' ], axis=1, inplace=True) df_train, df_test, y_train, y_test = train_test_split(df, y, test_size=0.33, stratify=df.y, random_state=42)
Ahora comienza la etapa más importante en la puntuación de regresión: debe escribir WOE-binning para variables numéricas y categóricas. En el dominio público, no encontramos opciones buenas y adecuadas para nosotros y decidimos escribirnos.
Este artículo de 2017 fue tomado como la base del binning numérico, así como también, categórico, ellos mismos escribieron desde cero. Los resultados fueron impresionantes (Gini en la prueba aumentó en 3-5 en comparación con los algoritmos de agrupación de programas externos de minería de datos).
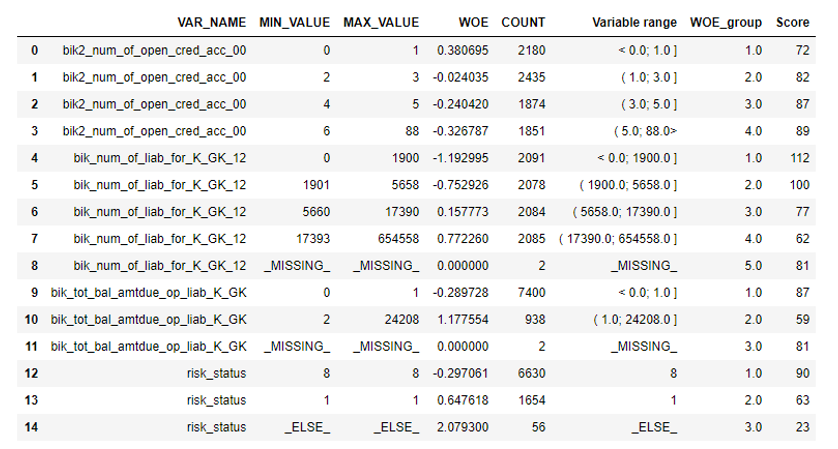
Después de eso, puede ver los gráficos o tablas (que luego escribimos en Excel) cómo se dividen las variables en grupos y verificar la monotonía:
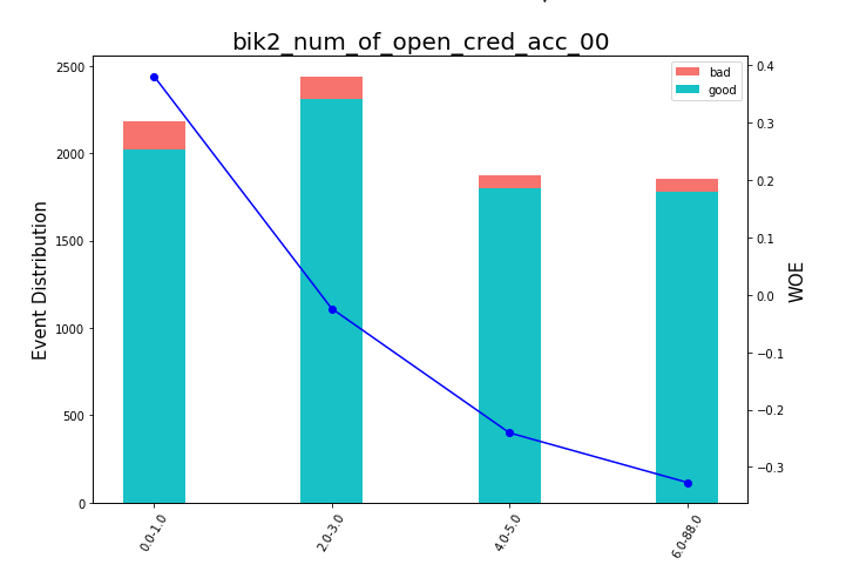
Renderizado de gráficos de frijoles def plot_bin(ev, for_excel=False): ind = np.arange(len(ev.index)) width = 0.35 fig, ax1 = plt.subplots(figsize=(10, 7)) ax2 = ax1.twinx() p1 = ax1.bar(ind, ev['NONEVENT'], width, color=(24/254, 192/254, 196/254)) p2 = ax1.bar(ind, ev['EVENT'], width, bottom=ev['NONEVENT'], color=(246/254, 115/254, 109/254)) ax1.set_ylabel('Event Distribution', fontsize=15) ax2.set_ylabel('WOE', fontsize=15) plt.title(list(ev.VAR_NAME)[0], fontsize=20) ax2.plot(ind, ev['WOE'], marker='o', color='blue')
Una función para el binning manual se escribió por separado, lo cual es útil, por ejemplo, en el caso de la variable "versión del sistema operativo", donde todos los teléfonos Android e iOS se agruparon manualmente.
Función de agrupamiento manual def adjust_binning(df, bins_dict): for i in range(len(bins_dict)): key = list(bins_dict.keys())[i] if type(list(bins_dict.values())[i])==dict: df[key] = df[key].map(list(bins_dict.values())[i]) else:
El siguiente paso es la selección de variables por valor de información. El valor predeterminado es 0.1 (todas las variables a continuación no tienen un buen poder predictivo).
Después de la verificación de la correlación se llevó a cabo. De las dos variables correlacionadas, debe eliminar la que tenga menos IV. La eliminación del corte se tomó 0,75.
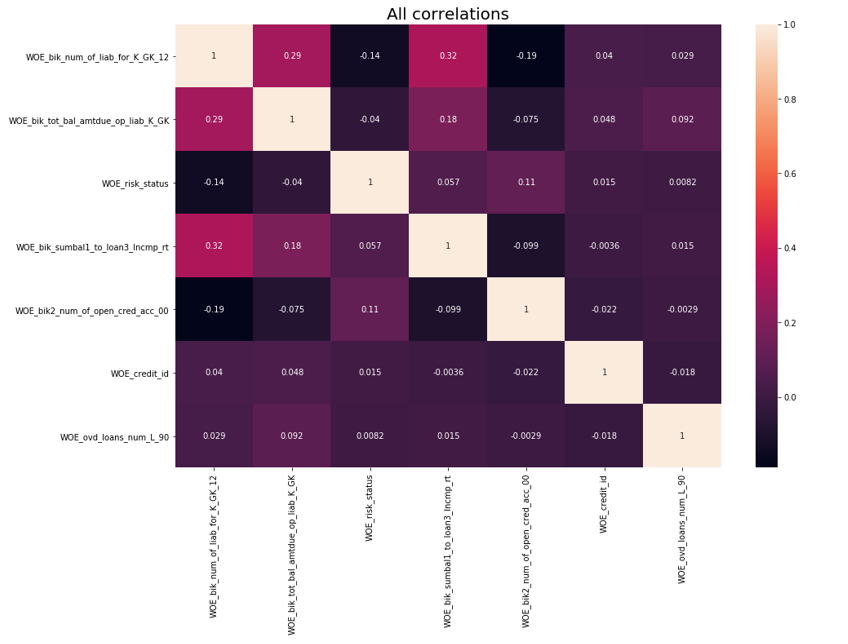
Eliminación de correlación def delete_correlated_features(df, cut_off=0.75, exclude = []):
Además de la selección por IV, agregamos una búsqueda recursiva para el número óptimo de variables por el método
RFE de sklearn.
Como vemos en el gráfico, después de 13 variables, la calidad no cambia, lo que significa que se pueden eliminar las adicionales. Para la regresión, más de 15 variables en la puntuación se consideran de mala forma, que en la mayoría de los casos se corrige con RFE.
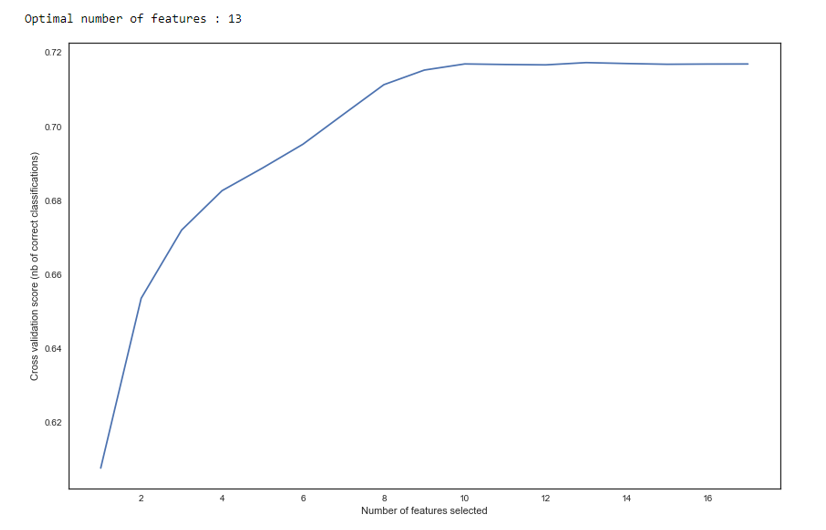
RFE def RFE_feature_selection(clf_lr, X, y): rfecv = RFECV(estimator=clf_lr, step=1, cv=StratifiedKFold(5), verbose=0, scoring='roc_auc') rfecv.fit(X, y) print("Optimal number of features : %d" % rfecv.n_features_)
A continuación, se construyó una regresión y se evaluaron sus métricas en validación cruzada y muestreo de prueba. Por lo general, todos miran el coeficiente de Gini (un buen artículo sobre él
aquí ).
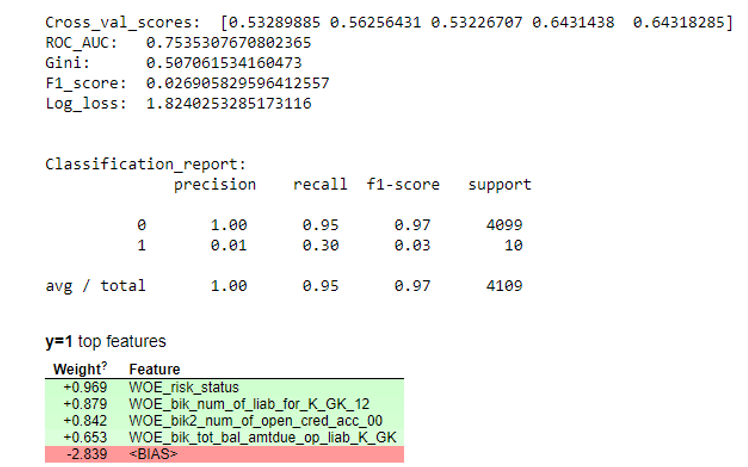
Resultados de la simulación def plot_score(clf, X_test, y_test, feat_to_show=30, is_normalize=False, cut_off=0.5):
Cuando nos aseguramos de que la calidad del modelo nos conviene, es necesario escribir todos los resultados (coeficientes de regresión, grupos bin, gráficos y variables de estabilidad de Gini, etc.) en Excel. Para esto, es conveniente usar xlsxwriter, que puede funcionar con datos e imágenes.
Ejemplos de hojas de Excel:
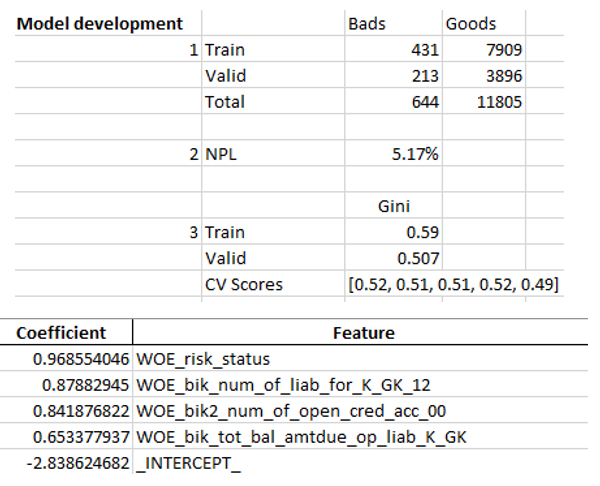
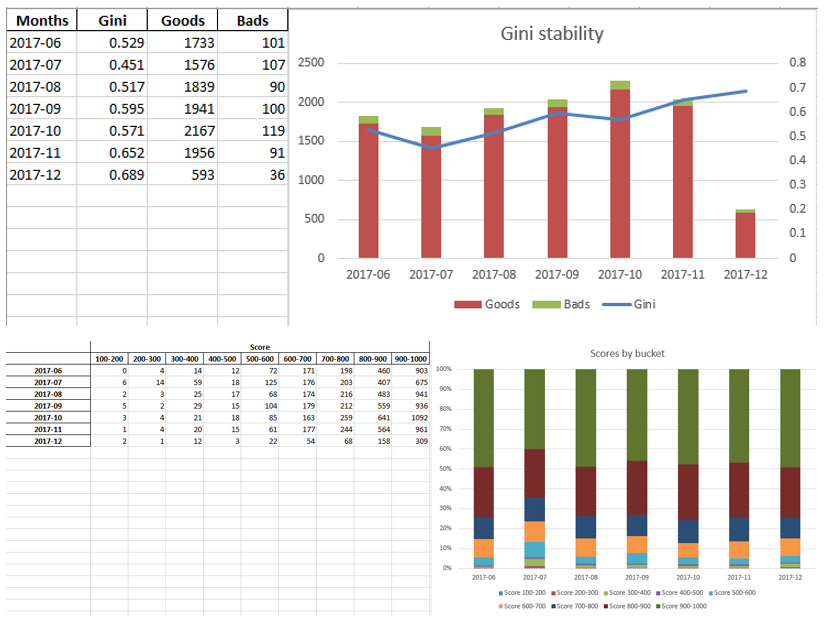
Al final, el excel final vuelve a ser visto por la gerencia, luego de lo cual se le entrega a TI para integrar el modelo en la producción.
Resumen
Como vimos, casi todas las etapas de puntuación se pueden automatizar para que los analistas no necesiten habilidades de programación para construir modelos. En nuestro caso, después de crear este marco, el analista solo necesita recopilar datos y especificar varios parámetros (indicar la variable objetivo, qué columnas eliminar, el número mínimo de contenedores, el coeficiente de corte para la correlación de variables, etc.), después de lo cual puede ejecutar el script en python, que construirá el modelo y producirá sobresalir con los resultados deseados.
Por supuesto, a veces es necesario corregir el código para las necesidades de un proyecto en particular, y no se puede hacer con un solo botón para ejecutar el script durante el modelado, pero incluso ahora vemos una mejor calidad que los paquetes de minería de datos utilizados en el mercado gracias a técnicas como el binning óptimo y monótono, la verificación de correlación , RFE, versión regularizada de regresión, etc.
Por lo tanto, gracias al uso de Python, redujimos significativamente el tiempo de desarrollo de las tarjetas de puntuación, así como también redujimos los costos laborales de los analistas.