Todos los días, los usuarios comprometen millones de actividades en línea. El proyecto FACETz DMP necesita estructurar estos datos y segmentarlos para identificar las preferencias del usuario. En el artículo, hablaremos sobre cómo el equipo segmentó una audiencia de 600 millones de personas, procesó 5 mil millones de eventos diariamente y trabajó con estadísticas usando Kafka y HBase.
El material se basa en una transcripción de un
informe de Artyom Marinov , especialista en big data de Directual, de la conferencia SmartData 2017.
Mi nombre es Artyom Marinov, quiero hablar sobre cómo rediseñamos la arquitectura del proyecto FACETz DMP cuando trabajé en Data Centric Alliance. Por qué lo hicimos, a qué condujo, hacia dónde nos dirigimos y qué problemas encontramos.
DMP (Data Management Platform) es una plataforma para recopilar, procesar y agregar datos de usuario. Los datos son muchas cosas diferentes. La plataforma tiene alrededor de 600 millones de usuarios. Son millones de cookies que se conectan a Internet y realizan diversos eventos. En general, un día en promedio se ve más o menos así: vemos alrededor de 5.5 mil millones de eventos por día, de alguna manera se extienden por día, y en el pico alcanzan aproximadamente 100 mil eventos por segundo.

Los eventos son varias señales de usuario. Por ejemplo, una visita a un sitio: vemos desde qué navegador va el usuario, su agente de uso y todo lo que podemos extraer. A veces vemos cómo y para qué consultas de búsqueda llegó al sitio. También pueden ser varios datos del mundo fuera de línea, por ejemplo, lo que paga con cupones de descuento, etc.
Necesitamos guardar estos datos y marcar al usuario en los llamados grupos de segmentos de audiencia. Por ejemplo, los segmentos pueden ser una "mujer" que "ama a los gatos" y está buscando "servicio de automóvil", ella "tiene un automóvil de más de tres años".
¿Por qué segmentar a un usuario? Hay muchas aplicaciones para esto, por ejemplo, publicidad. Varias redes publicitarias pueden optimizar los algoritmos de publicación de anuncios. Si está anunciando su servicio de automóvil, puede configurar una campaña de tal manera que solo las personas que tienen un automóvil antiguo muestren información, excluyendo a los propietarios de otros nuevos. Puede cambiar dinámicamente el contenido del sitio, puede usar los datos para la puntuación: hay muchas aplicaciones.
Los datos se obtienen de muchos lugares completamente diferentes. Puede ser una configuración directa de píxeles: si el cliente quiere analizar su audiencia, coloca el píxel en el sitio, una imagen invisible que se descarga de nuestro servidor. La conclusión es que vemos la visita del usuario a este sitio: puede guardarlo, comenzar a analizar y comprender el retrato del usuario, toda esta información está disponible para nuestro cliente.

Se pueden obtener datos de varios socios que ven muchos datos y desean monetizarlos de varias maneras. Los socios pueden suministrar datos en tiempo real y realizar cargas periódicas en forma de archivos.
Requisitos clave:
- Escalabilidad horizontal;
- Evaluación del volumen de la audiencia;
- Conveniencia de monitoreo y desarrollo;
- Buena velocidad de reacción a los eventos.
Uno de los requisitos clave del sistema es la escalabilidad horizontal. Hay un momento en el que cuando está desarrollando un portal o una tienda en línea, puede estimar la cantidad de usuarios (cómo crecerá, cómo cambiará) y comprender aproximadamente cuántos recursos se necesitan y cómo la tienda vivirá y se desarrollará con el tiempo.
Cuando desarrolle una plataforma similar a DMP, debe estar preparado para el hecho de que cualquier sitio grande, el Amazon condicional, puede poner su píxel en él, y tendrá que trabajar con el tráfico de todo este sitio, mientras no debe caer, y los indicadores los sistemas no deberían cambiar de alguna manera.
También es bastante importante poder comprender el volumen de cierta audiencia para que un anunciante potencial u otra persona pueda elaborar un plan de medios. Por ejemplo, una persona acude a usted y le pide que averigüe cuántas mujeres embarazadas de Novosibirsk están buscando una hipoteca para evaluar si tiene sentido apuntarlas o no.
Desde el punto de vista del desarrollo, debe ser capaz de monitorear fríamente todo lo que sucede en su sistema, depurar parte del tráfico real, etc.
Uno de los requisitos del sistema más importantes es una buena velocidad de reacción a los eventos. Cuanto más rápido respondan los sistemas a los eventos, mejor será obvio. Si está buscando entradas para el teatro, si ve algún tipo de oferta de descuento después de un día, dos días o incluso una hora, esto puede ser irrelevante, ya que ya podría comprar entradas o asistir a una actuación. Cuando está buscando un taladro, lo está buscando, encuentre, compre, cuelgue un estante, y después de un par de días comienza el bombardeo: "¡Compre un taladro!".
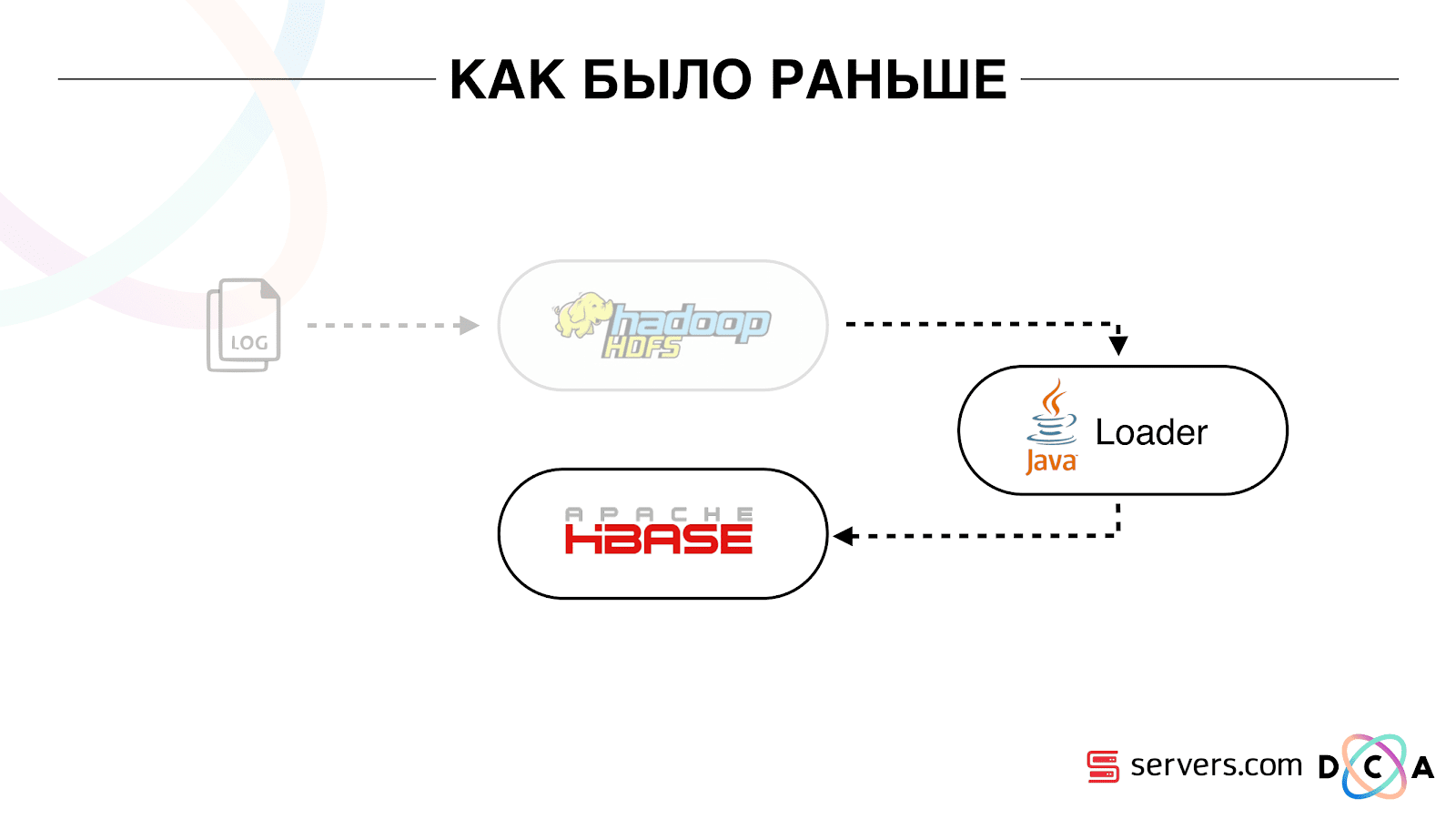
Como era antes
El artículo en su conjunto trata sobre el reciclaje de la arquitectura. Me gustaría decirle cuál fue nuestro punto de partida, cómo funcionó todo antes de los cambios.
Todos los datos que teníamos, ya sea un flujo directo de datos o registros, se almacenaron en HDFS - almacenamiento de archivos distribuidos. Luego hubo un cierto proceso que se inició periódicamente, tomó todos los archivos no procesados de HDFS y los convirtió en solicitudes de enriquecimiento de datos en HBase ("solicitudes PUT").
¿Cómo almacenamos datos en HBase?
Esta es una base de datos columnar de series temporales. Ella tiene el concepto de una clave de fila: esta es la clave con la que almacena sus datos. Usamos el ID de usuario como clave, el ID de usuario, que generamos cuando vemos al usuario por primera vez. Dentro de cada clave, los datos se dividen en Familia de columnas: entidades a cuyo nivel puede administrar la metainformación de sus datos. Por ejemplo, puede almacenar mil versiones de registros para los "datos" de la familia de columnas y almacenarlos durante dos meses, y para la familia de columnas "sin procesar": un año, como opción.
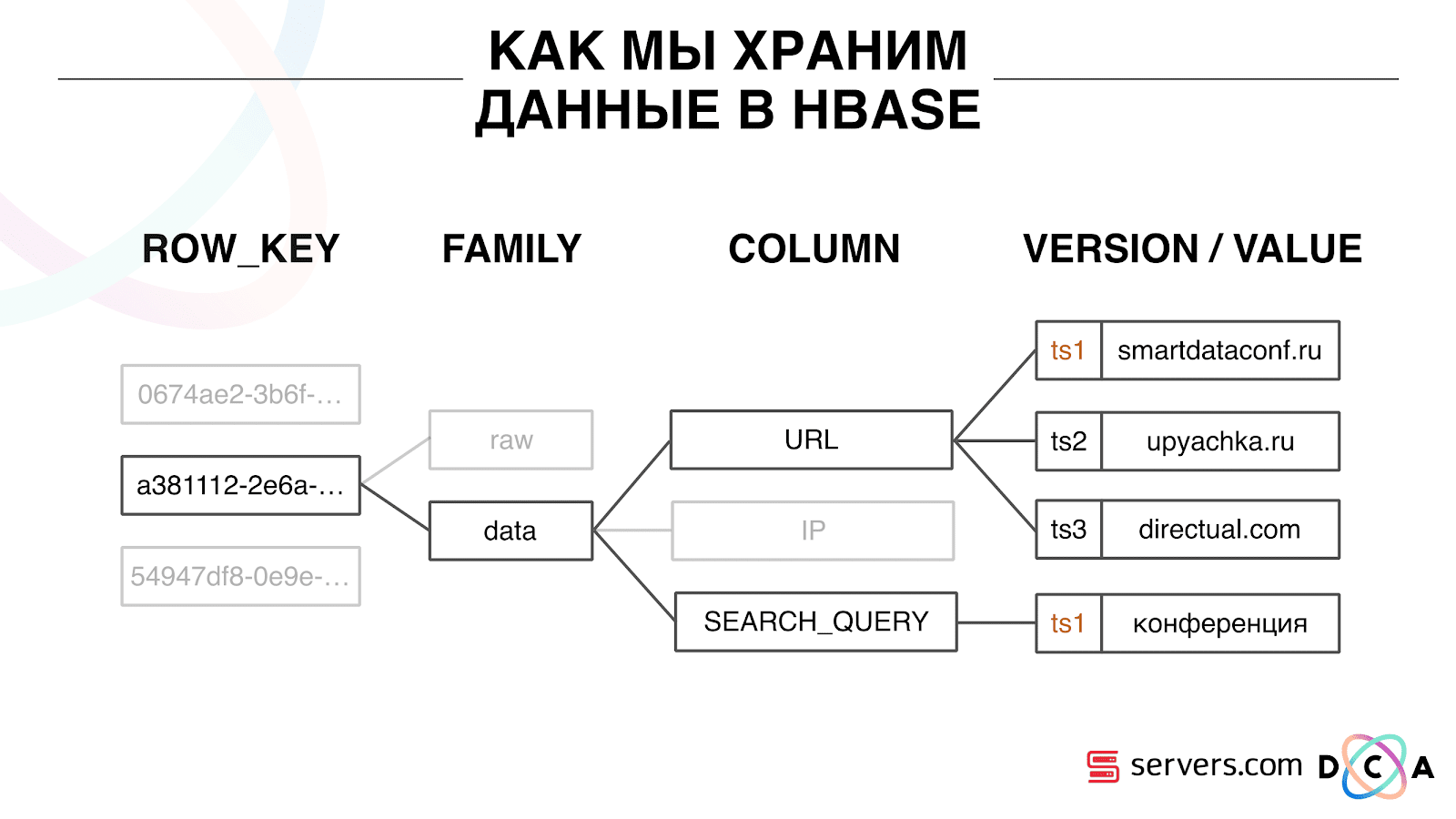
Dentro de la familia de columnas, hay muchos calificadores de columna (en adelante columna). Utilizamos varios atributos de usuario como columna. Podría ser la URL a la que fue, dirección IP, consulta de búsqueda. Y lo más importante, se almacena mucha información dentro de cada columna. Dentro de la columna URL se puede indicar que el usuario fue a smartdataconf.ru, luego a algunos otros sitios. Y la marca de tiempo se usa como la versión: ve un historial ordenado de visitas de usuarios. En nuestro caso, podemos determinar que el usuario llegó al sitio web de smartdataconf con la palabra clave "conferencia", porque tienen la misma marca de tiempo.
Trabajar con HBase
Hay varias opciones para trabajar con HBase. Pueden ser solicitudes PUT (solicitud de cambio de datos), solicitud GET ("dame todos los datos sobre el usuario Vasya", etc.). Puede ejecutar solicitudes SCAN: exploración secuencial de subprocesos múltiples de todos los datos en HBase. Usamos esto antes para marcar en segmentos de audiencia.
Había una tarea llamada Motor de análisis, se ejecutaba una vez al día y escaneaba HBase en varios subprocesos. Para cada usuario, ella levantó toda la historia de HBase y la revisó a través de un conjunto de scripts analíticos.

¿Qué es un script analítico? Este es un tipo de caja negra (clase java), que recibe todos los datos del usuario como entrada y proporciona un conjunto de segmentos que considera adecuados como salida. Le damos todo al script que vemos: IP, visitas, UserAgent, etc., y en el resultado los scripts dan: "esta es una mujer, ama a los gatos, no le gustan los perros".
Estos datos se entregaron a los socios, se consideraron las estadísticas. Era importante para nosotros entender cuántas mujeres hay en general, cuántos hombres, cuántas personas aman a los gatos, cuántas tienen o no tienen automóvil, etc.
Almacenamos estadísticas en MongoDB y escribimos incrementando un contador de segmento específico para cada día. Teníamos una gráfica del volumen de cada segmento para cada día.
Este sistema fue bueno para su tiempo. Permitía escalar horizontalmente, crecer, permitía estimar el volumen de la audiencia, pero tenía una serie de inconvenientes.
No siempre era posible entender lo que estaba sucediendo en el sistema, mirar los registros. Mientras estábamos en el hoster anterior, la tarea a menudo cayó por varias razones. Había un clúster Hadoop de más de 20 servidores, una vez al día uno de los servidores se bloqueaba de manera estable. Esto llevó al hecho de que la tarea podría caer parcialmente y no calcular los datos. Era necesario tener tiempo para reiniciarlo y, dado que funcionó durante varias horas, hubo una serie de ciertos matices.
Lo más básico que la arquitectura existente no cumplió fue que el tiempo de reacción al evento fue demasiado largo. Incluso hay una historia sobre este tema. Había una compañía que emitía micropréstamos a la población en las regiones, y nos asociamos con ellos. Su cliente llega al sitio, llena una solicitud de microcrédito, la empresa debe responder en 15 minutos: ¿están listos para otorgar un préstamo o no? Si está listo, inmediatamente transfirieron dinero a la tarjeta.
Todo funcionó bastante bien. El cliente decidió verificar cómo sucede generalmente: tomaron una computadora portátil separada, instalaron un sistema limpio, visitaron muchas páginas en Internet y fueron a su sitio. Ven que hay una solicitud y, en respuesta, decimos que todavía no hay datos. El cliente pregunta: "¿Por qué no hay datos?"
Explicamos: hay un cierto retraso antes de que el usuario realice una acción. Los datos se envían a HBase, se procesan y solo entonces el cliente recibe el resultado. Parecería que si el usuario no vio el anuncio, todo está en orden, no pasará nada malo. Pero en esta situación, el usuario podría no recibir un préstamo debido al retraso.
Este no es un caso aislado, y fue necesario cambiar a un sistema en tiempo real. ¿Qué queremos de ella?

Queremos escribir datos en HBase tan pronto como lo veamos. Vimos una visita, enriquecimos todo lo que sabemos y lo enviamos a Storage. Tan pronto como los datos en Almacenamiento hayan cambiado, debe ejecutar de inmediato todo el conjunto de scripts analíticos que tenemos. Queremos la conveniencia de monitoreo y desarrollo, la capacidad de escribir nuevos scripts, depurarlos en fragmentos de tráfico real. Queremos entender en qué está ocupado el sistema en este momento.
Lo primero con lo que comenzamos es resolver el segundo problema: segmentar al usuario inmediatamente después de cambiar los datos sobre él en HBase. Inicialmente, teníamos nodos de trabajo (se iniciaron tareas de reducción de mapas en ellos) ubicados en el mismo lugar que HBase. En varios casos, fue muy bueno: los cálculos se realizan junto a los datos, las tareas funcionan con bastante rapidez y pasa poco tráfico por la red. Está claro que la tarea consume algunos recursos, ya que ejecuta scripts analíticos complejos.
Cuando vamos a trabajar en tiempo real, la naturaleza de la carga en HBase cambia. Pasamos a lecturas aleatorias en lugar de lecturas secuenciales. Es importante que se espere la carga en HBase: no podemos permitir que alguien ejecute la tarea en el clúster de Hadoop y estropee el rendimiento de HBase.
Lo primero que hicimos fue mover HBase a servidores separados. También modificó BlockCache y BloomFilter. Luego hicimos un buen trabajo sobre cómo almacenar datos en HBase. Prácticamente reelaboraron el sistema del que hablé al principio y cosecharon los datos en sí.

De lo obvio: almacenamos IP como una cadena y nos volvimos largos en números. Se clasificaron algunos datos, se llevaron a cabo actividades de vocabulario, etc. La conclusión es que debido a esto, pudimos sacudir HBase aproximadamente dos veces, de 10 TB a 5 TB. HBase tiene un mecanismo similar a los desencadenantes en una base de datos normal. Este es un mecanismo coprocesador. Escribimos un coprocesador que, cuando un usuario cambia a HBase, envía la identificación de usuario a Kafka.
La identificación de usuario está en Kafka. Además hay un cierto servicio "segmentador". Lee el flujo de identificadores de usuario y ejecuta en ellos los mismos scripts que antes, solicitando datos de HBase. El proceso se lanzó en el 10% del tráfico, observamos cómo funciona. Todo estuvo bastante bien.

Luego, comenzamos a aumentar la carga y vimos una serie de problemas. Lo primero que vimos fue que el servicio funciona, se segmenta y luego se cae de Kafka, se conecta y comienza a funcionar nuevamente. Varios servicios: se ayudan mutuamente. Luego, el siguiente se cae, otro y así sucesivamente en un círculo. Al mismo tiempo, la alineación de usuarios para la segmentación casi no se está clasificando.
Esto se debió a la peculiaridad del mecanismo de los latidos del corazón en Kafka, entonces todavía era la versión 0.8. Heartbeat es cuando los consumidores le dicen al corredor si están vivos o no, en nuestro caso, informa el segmentador. Sucedió lo siguiente: recibimos un paquete de datos bastante grande y lo enviamos para su procesamiento. Por un tiempo funcionó, mientras funcionó, no se envió ningún latido. Los corredores creían que el consumidor estaba muerto y lo apagaron.
El consumidor trabajó hasta el final, desperdiciando preciosas CPU, trató de decir que el paquete de datos estaba resuelto y que el siguiente podría ser tomado, pero fue rechazado porque el otro le quitó lo que estaba trabajando. Lo arreglamos haciendo que nuestro fondo latiera, luego la verdad llegó una versión más nueva de Kafka donde solucionamos este problema.
Entonces surgió la pregunta: ¿en qué tipo de hardware deberían instalar nuestros segmentadores? La segmentación es un proceso intensivo en recursos (vinculado a la CPU). Es importante que el servicio no solo consuma mucha CPU, sino que también cargue la red. Ahora el tráfico alcanza los 5 Gbit / seg. La pregunta era: dónde colocar los servicios, en muchos servidores pequeños o un poco grandes.
En ese momento, ya nos mudamos a
server.com en metal desnudo. Hablamos con los chicos de los servidores, nos ayudaron, hicieron posible probar el trabajo de nuestra solución tanto en un pequeño número de servidores caros como en muchos de bajo costo con CPU potentes. Elegimos la opción adecuada, calculando el costo unitario de procesar un evento por segundo. Por cierto, la elección recayó en Dell R230 suficientemente potente y al mismo tiempo extremadamente asequible, lo lanzaron, todo funcionó.
Es importante que después de que el segmentador haya marcado al usuario en segmentos, el resultado de su análisis recaiga en Kafka, en un determinado tema Resultado de segmentación.
Además, podemos conectarnos de manera independiente a estos datos por diferentes consumidores que no interferirán entre sí. Esto nos permite proporcionar datos de forma independiente a cada socio, ya sean algunos socios externos, DSP interno, Google, estadísticas.
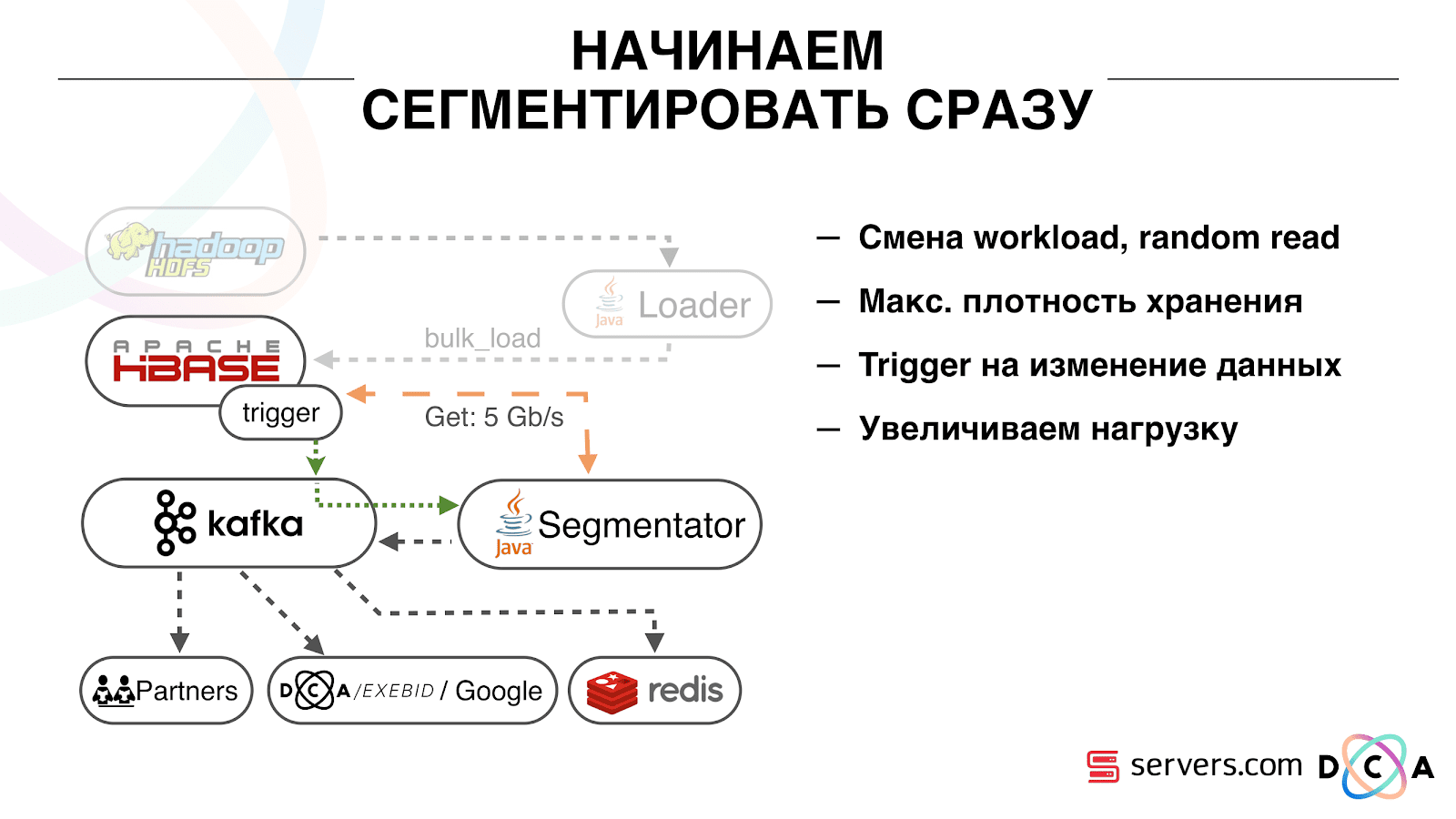
Con las estadísticas, también hay un punto interesante: antes podríamos aumentar el valor de los contadores en MongoDB, cuántos usuarios estaban en un segmento determinado durante un día determinado. Ahora, esto no se puede hacer porque ahora analizamos a cada usuario después de que completa un evento, es decir, Varias veces al día.
Por lo tanto, tuvimos que resolver el problema de contar el número único de usuarios en la transmisión. Para hacer esto, utilizamos la estructura de datos HyperLogLog y su implementación en Redis. La estructura de datos es probabilística. Esto significa que puede agregar identificadores de usuario allí, los identificadores en sí no se almacenarán, por lo que puede almacenar millones de identificadores únicos en HyperLogLog extremadamente compacto, y esto tomará hasta 12 kilobytes por clave.
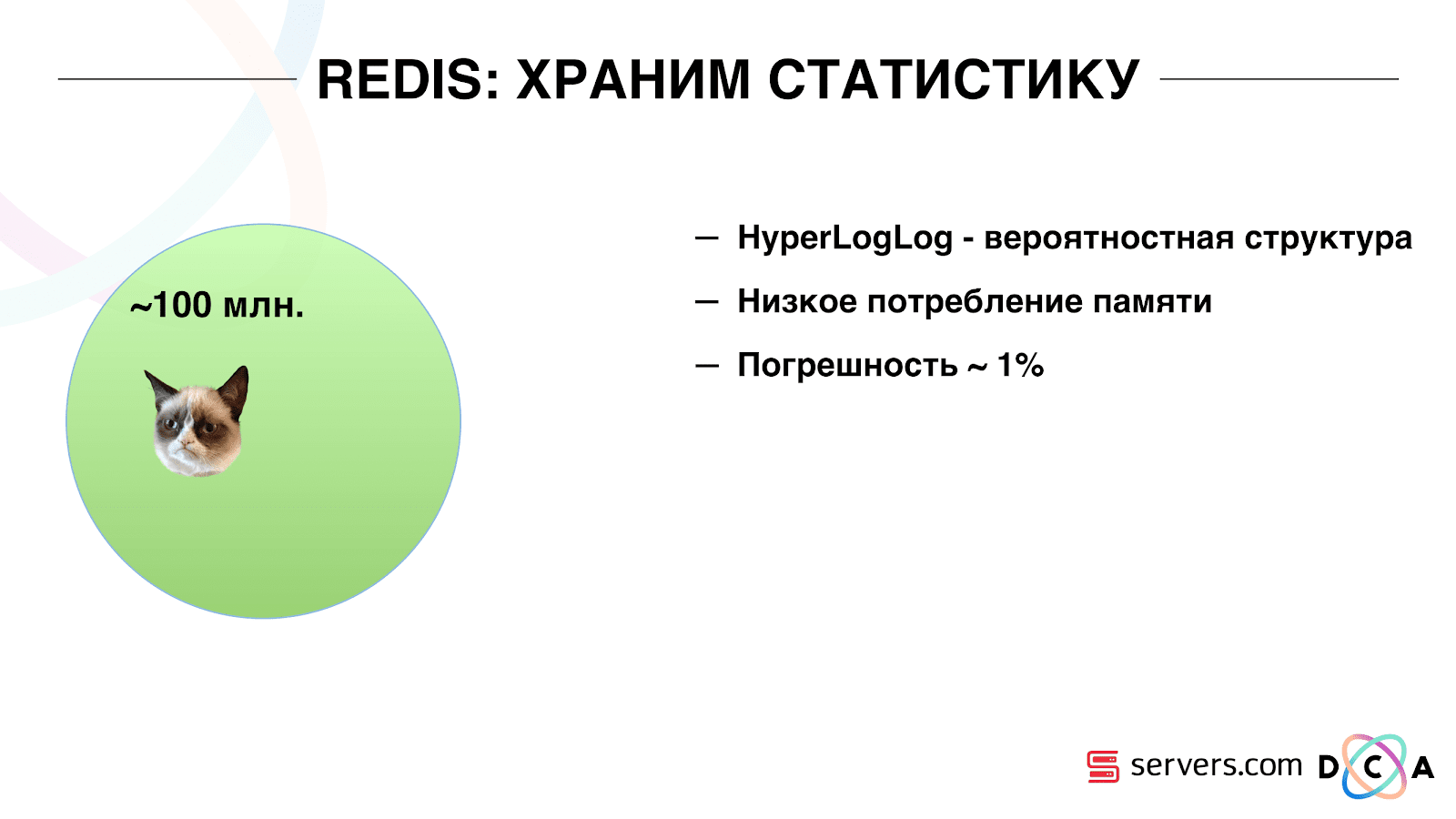
No puede obtener los identificadores usted mismo, pero puede averiguar el tamaño de este conjunto. Dado que la estructura de datos es probabilística, hay algún error. Por ejemplo, si tiene un segmento "le gustan los gatos", al solicitar el tamaño de este segmento para un día determinado, recibirá 99,2 millones y esto significará algo así como "de 99 millones a 100 millones".
También en HyperLogLog puede obtener el tamaño de la unión de varios conjuntos. Digamos que tiene dos segmentos: "ama a las focas" y "ama a los perros". Digamos los primeros 100 millones, el segundo 1 millón. Uno puede preguntarse: "¿Cuántos animales les gustan?" y obtenga la respuesta "aproximadamente 101 millones" con un error del 1%. Sería interesante calcular cuánto se ama tanto a los gatos como a los perros al mismo tiempo, pero hacerlo es bastante difícil.

Por un lado, puede averiguar el tamaño de cada conjunto, conocer el tamaño de la unión, sumar, restar uno del otro y obtener la intersección. Pero debido al hecho de que el tamaño del error puede ser mayor que el tamaño de la intersección final, el resultado final puede tener la forma "de -50 a 50 mil".

Hemos trabajado bastante sobre cómo aumentar el rendimiento al escribir datos en Redis. Inicialmente, alcanzamos 200 mil operaciones por segundo. Pero cuando cada usuario tiene más de 50 segmentos, registrando información sobre cada usuario, 50 operaciones. Resulta que tenemos un ancho de banda bastante limitado y, en este ejemplo, no podemos escribir información sobre más de 4 mil usuarios por segundo, esto es varias veces menos de lo que necesitamos.
Hicimos un "procedimiento almacenado" por separado en Redis a través de Lua, lo cargamos allí y comenzamos a pasarle una cadena con la lista completa de segmentos de un usuario. El procedimiento interno cortará la cadena pasada en las actualizaciones necesarias de HyperLogLog y guardará los datos, por lo que llegamos a aproximadamente 1 millón de actualizaciones por segundo.
Un poco duro: Redis es de un solo subproceso, puede fijarlo a un núcleo de procesador y una tarjeta de red a otro y lograr otro 15% de rendimiento, ahorrando en el cambio de contexto. Además de esto, el punto importante es que no puede simplemente agrupar la estructura de datos, porque las operaciones para obtener el poder de las uniones de conjuntos no están agrupadas
Kafka es una gran herramienta
Usted ve que Kafka es nuestra principal herramienta de transporte en el sistema.
Tiene la esencia del "tema". Aquí es donde escribe los datos, pero en esencia: la cola. En nuestro caso, hay varias colas. Uno de ellos son los identificadores de usuarios a los que es necesario segmentar. El segundo es la segmentación de resultados.
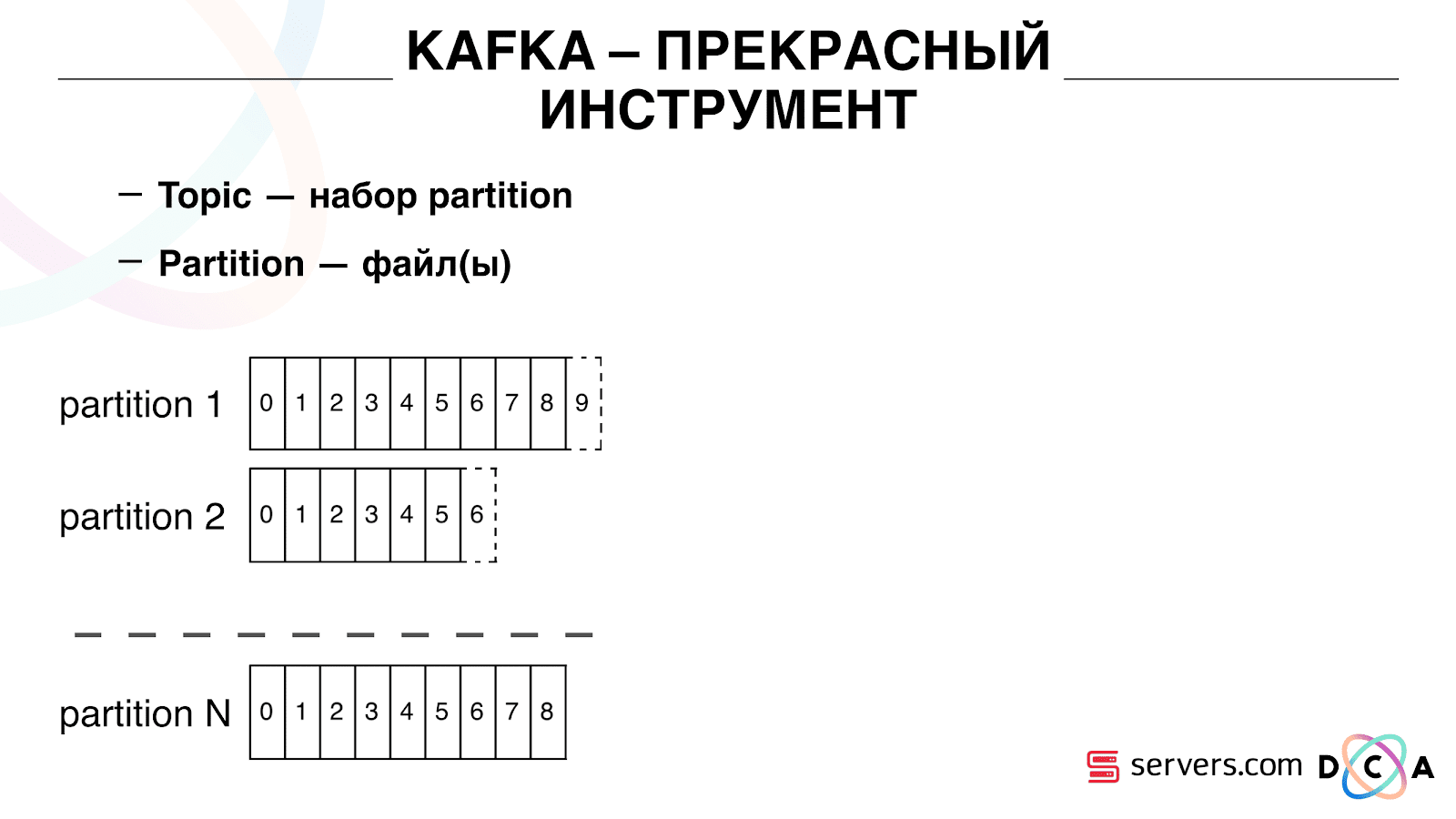
Un tema es un conjunto de particiones. Se divide en algunas piezas. Cada partición es un archivo en el disco duro. Cuando sus productores escriben datos, escriben fragmentos de texto al final de la partición. Cuando sus consumidores leen los datos, simplemente leen desde estas particiones.
Lo importante es que puede conectar de forma independiente varios grupos de consumidores, ya que consumirán datos sin interferir entre sí. Esto se determina por el nombre del grupo de consumidores y se logra de la siguiente manera.
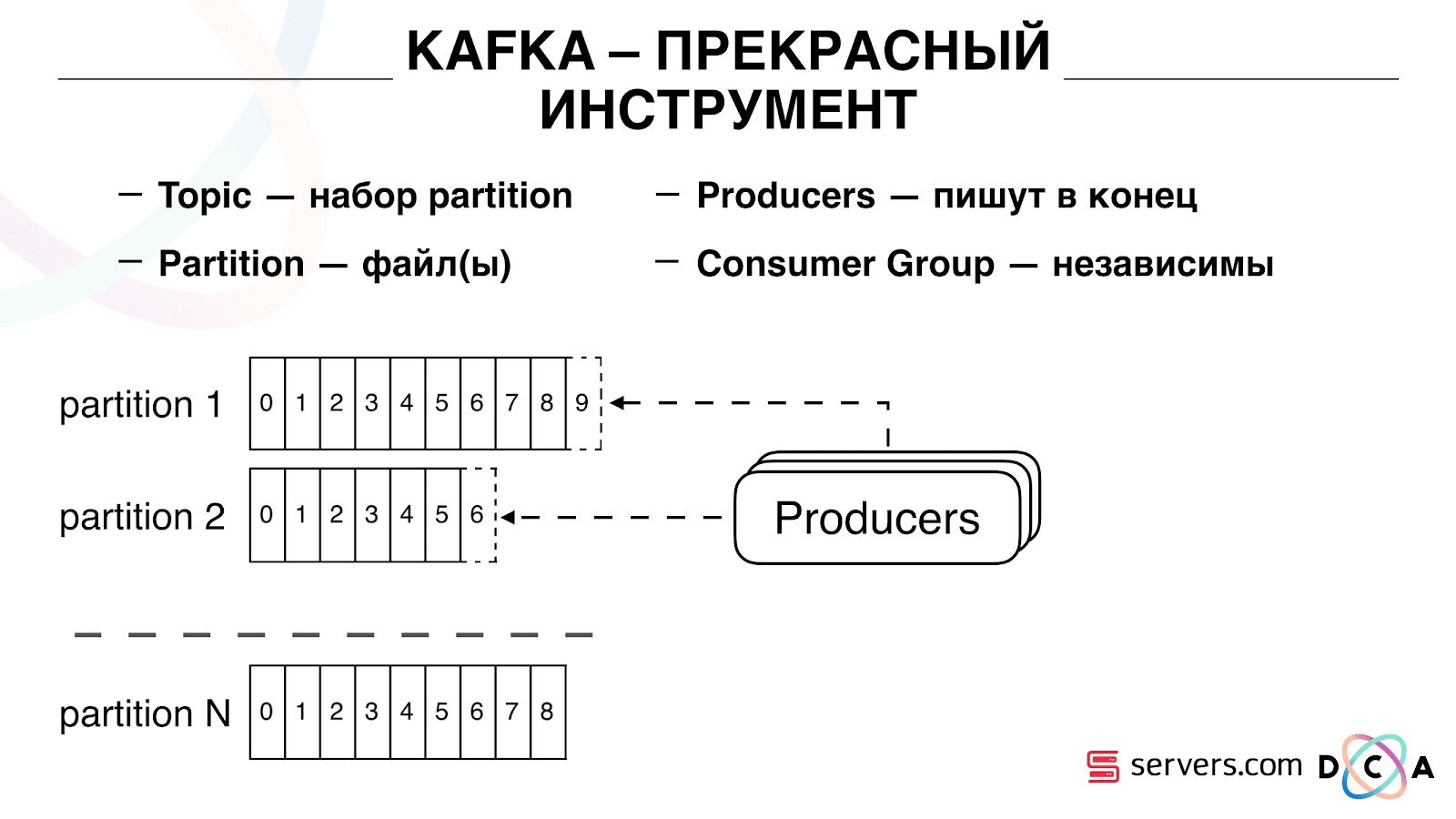
Existe una compensación, la posición donde el grupo de consumidores se encuentra ahora en cada partición. Por ejemplo, el grupo A consume el séptimo mensaje de la partición1 y el quinto de la partición2. El grupo B, independiente de A, tiene otro desplazamiento.
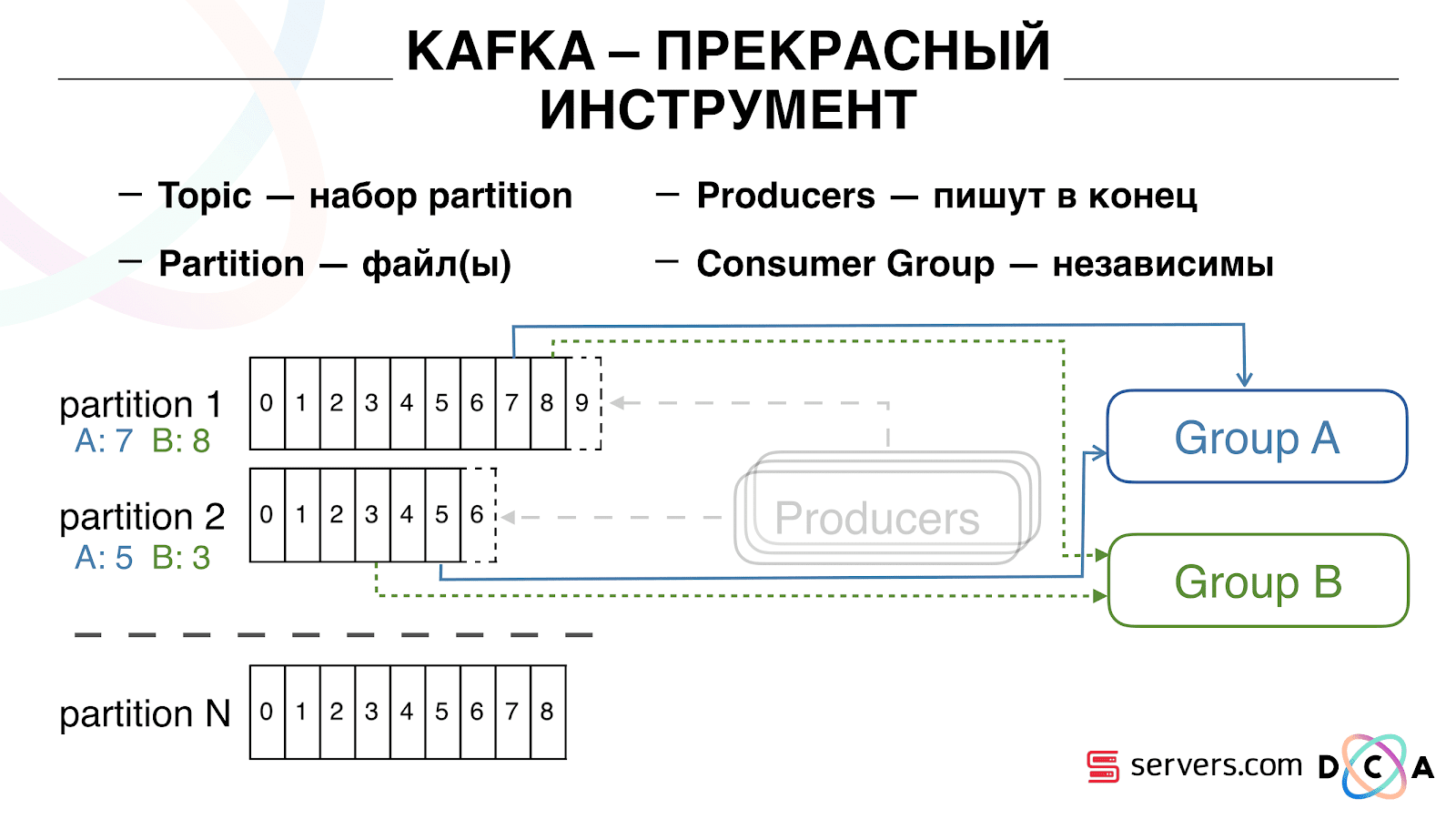 Puede escalar su grupo de consumidores horizontalmente, agregar otro proceso o servidor. Esto sucederá la reasignación de la partición (el corredor de Kafka asignará a cada consumidor una lista de particiones para el consumo) Esto significa que el primer grupo de consumidores comenzará a consumir solo la partición 1, y el segundo solo consumirá la partición 2. Si algunos de los consumidores mueren (por ejemplo, el latido no llega), se produce una nueva reasignación , cada consumidor recibe una lista de particiones actualizada para su procesamiento.
Puede escalar su grupo de consumidores horizontalmente, agregar otro proceso o servidor. Esto sucederá la reasignación de la partición (el corredor de Kafka asignará a cada consumidor una lista de particiones para el consumo) Esto significa que el primer grupo de consumidores comenzará a consumir solo la partición 1, y el segundo solo consumirá la partición 2. Si algunos de los consumidores mueren (por ejemplo, el latido no llega), se produce una nueva reasignación , cada consumidor recibe una lista de particiones actualizada para su procesamiento. Es bastante conveniente. Primero, puede manipular el desplazamiento para cada grupo de consumidores. Imagine que hay un socio al que transfiere datos de este tema con los resultados de la segmentación. Él escribe que perdió accidentalmente el último día de datos como resultado de un error. Y usted, para el grupo de consumidores de este cliente, simplemente retroceda un día y vierta todo el día de datos en él. También podemos tener nuestro propio grupo de consumidores, conectarnos con el tráfico de producción, ver lo que sucede y depurar datos reales.Entonces, hemos logrado que comenzamos a segmentar a los usuarios cuando cambian, podemos conectar de manera independiente a los nuevos consumidores, escribimos estadísticas y podemos verlo. Ahora debe obtener los datos escritos en HBase inmediatamente después de que nos lleguen.
Es bastante conveniente. Primero, puede manipular el desplazamiento para cada grupo de consumidores. Imagine que hay un socio al que transfiere datos de este tema con los resultados de la segmentación. Él escribe que perdió accidentalmente el último día de datos como resultado de un error. Y usted, para el grupo de consumidores de este cliente, simplemente retroceda un día y vierta todo el día de datos en él. También podemos tener nuestro propio grupo de consumidores, conectarnos con el tráfico de producción, ver lo que sucede y depurar datos reales.Entonces, hemos logrado que comenzamos a segmentar a los usuarios cuando cambian, podemos conectar de manera independiente a los nuevos consumidores, escribimos estadísticas y podemos verlo. Ahora debe obtener los datos escritos en HBase inmediatamente después de que nos lleguen.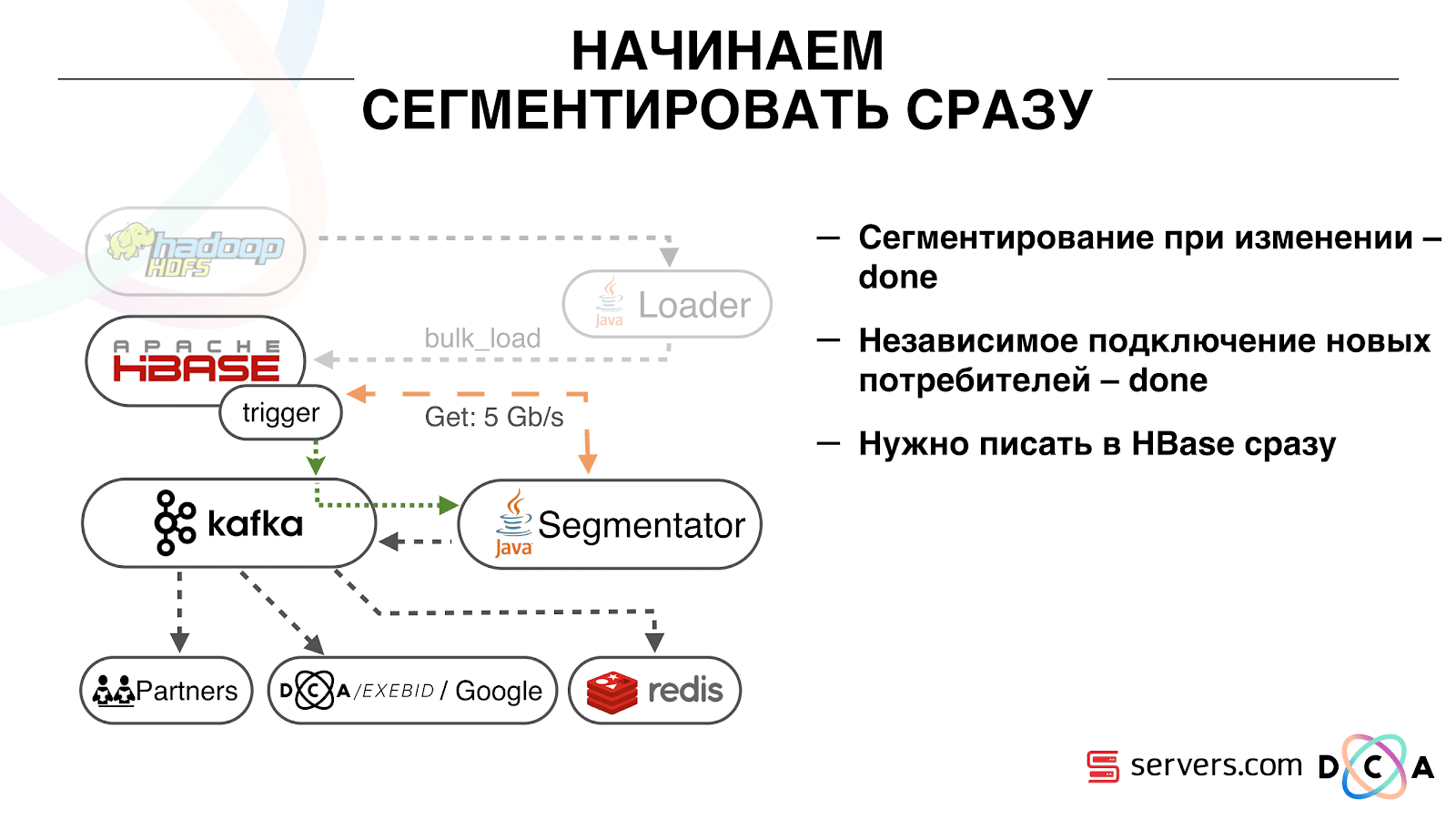 Cómo lo hicimos Solía haber carga de datos por lotes. Había un Batch Loader, procesaba archivos de registro de actividad del usuario: si un usuario realizaba 10 visitas, el lote venía para 10 eventos, se registraba en HBase en una operación. Solo hubo un evento por segmentación. Ahora queremos escribir cada evento por separado en el almacenamiento. Aumentaremos en gran medida la secuencia de escritura y la secuencia de lectura. El número de eventos por segmentación también aumentará.
Cómo lo hicimos Solía haber carga de datos por lotes. Había un Batch Loader, procesaba archivos de registro de actividad del usuario: si un usuario realizaba 10 visitas, el lote venía para 10 eventos, se registraba en HBase en una operación. Solo hubo un evento por segmentación. Ahora queremos escribir cada evento por separado en el almacenamiento. Aumentaremos en gran medida la secuencia de escritura y la secuencia de lectura. El número de eventos por segmentación también aumentará. Lo primero que hicimos fue portar HBase al SSD. Por medios estándar, esto no se hace particularmente. Esto se hizo usando HDFS. Puede decir que un directorio específico en HDFS debe estar en dicho grupo de discos. Hubo un problema genial con el hecho de que cuando llevamos HBase a la SSD y lo apagamos, todas las instantáneas llegaron allí, y nuestras SSD terminaron bastante rápido.Esto también se solucionó, comenzamos a exportar instantáneamente instantáneas a un archivo, escribir en otro directorio HDFS y eliminar toda la metainformación sobre las instantáneas. Si necesita restaurar, tome el archivo guardado, importe y restaure. Esta operación es muy poco frecuente, afortunadamente.También en el SSD sacaron Write Ahead Log, retorcieron MemStore, activaron el bloque de caché en la opción de escritura. Le permite colocarlos de inmediato en el caché de bloque al grabar datos. Esto es muy conveniente porque en nuestro caso, si registramos los datos, es muy probable que se lean de inmediato. Esto también dio algunas ventajas.Luego, cambiamos todas nuestras fuentes de datos para escribir datos en Kafka. Ya desde Kafka registramos datos en HDFS para mantener la compatibilidad con versiones anteriores, incluso para que nuestros analistas puedan trabajar con datos, ejecutar tareas de MapReduce y analizar sus resultados.Conectamos un grupo de consumidores separado que escribe datos en HBase. Este es, de hecho, un contenedor que lee de Kafka y forma los PUT en HBase.
Lo primero que hicimos fue portar HBase al SSD. Por medios estándar, esto no se hace particularmente. Esto se hizo usando HDFS. Puede decir que un directorio específico en HDFS debe estar en dicho grupo de discos. Hubo un problema genial con el hecho de que cuando llevamos HBase a la SSD y lo apagamos, todas las instantáneas llegaron allí, y nuestras SSD terminaron bastante rápido.Esto también se solucionó, comenzamos a exportar instantáneamente instantáneas a un archivo, escribir en otro directorio HDFS y eliminar toda la metainformación sobre las instantáneas. Si necesita restaurar, tome el archivo guardado, importe y restaure. Esta operación es muy poco frecuente, afortunadamente.También en el SSD sacaron Write Ahead Log, retorcieron MemStore, activaron el bloque de caché en la opción de escritura. Le permite colocarlos de inmediato en el caché de bloque al grabar datos. Esto es muy conveniente porque en nuestro caso, si registramos los datos, es muy probable que se lean de inmediato. Esto también dio algunas ventajas.Luego, cambiamos todas nuestras fuentes de datos para escribir datos en Kafka. Ya desde Kafka registramos datos en HDFS para mantener la compatibilidad con versiones anteriores, incluso para que nuestros analistas puedan trabajar con datos, ejecutar tareas de MapReduce y analizar sus resultados.Conectamos un grupo de consumidores separado que escribe datos en HBase. Este es, de hecho, un contenedor que lee de Kafka y forma los PUT en HBase.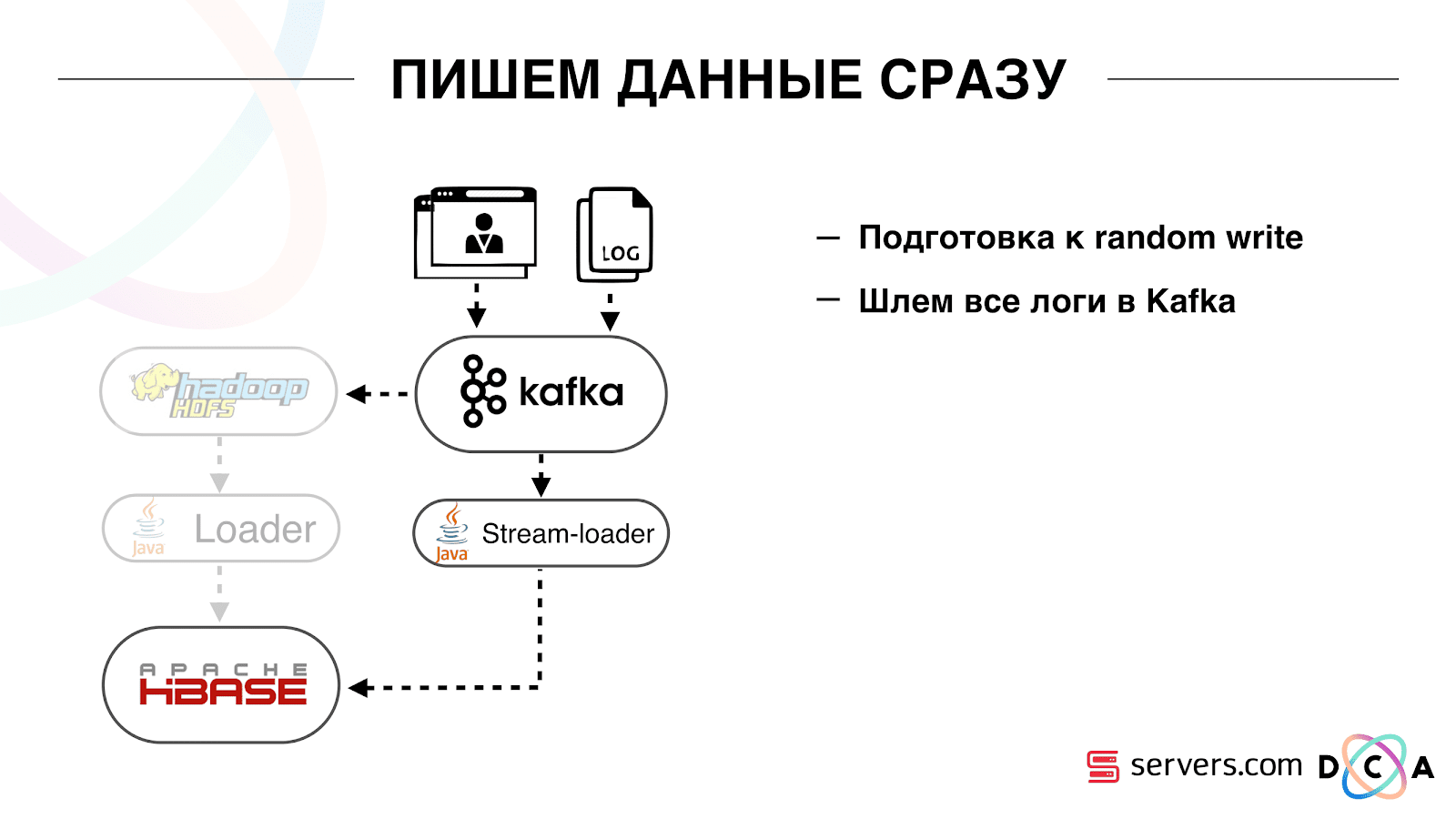 Lanzamos dos circuitos en paralelo para no romper la compatibilidad con versiones anteriores y no degradar el rendimiento del sistema. Se lanzó un nuevo esquema solo con un cierto porcentaje de tráfico. Con un 10%, todo fue genial. Pero a mayor carga, los segmentadores no podían hacer frente al flujo de segmentación.
Lanzamos dos circuitos en paralelo para no romper la compatibilidad con versiones anteriores y no degradar el rendimiento del sistema. Se lanzó un nuevo esquema solo con un cierto porcentaje de tráfico. Con un 10%, todo fue genial. Pero a mayor carga, los segmentadores no podían hacer frente al flujo de segmentación. Recopilamos la métrica "cuántos mensajes había en Kafka antes de que se leyera desde allí". Esta es una buena métrica. Inicialmente, recopilamos la métrica "cuántos mensajes en bruto hay ahora", pero no dice nada especial. Usted mira: "Tengo un millón de mensajes en bruto", ¿y qué? Para interpretar este millón, necesita saber qué tan rápido está funcionando el segmentador (consumidor), lo que no siempre está claro.Con esta métrica, verá de inmediato que los datos se escriben en la cola, que se tomarán de ella, y verá cuánto esperan que se procesen. Vimos que no teníamos tiempo para segmentar, y el mensaje estaba en la cola varias horas antes de leerlo.Simplemente podría agregar capacidad, pero sería demasiado
Recopilamos la métrica "cuántos mensajes había en Kafka antes de que se leyera desde allí". Esta es una buena métrica. Inicialmente, recopilamos la métrica "cuántos mensajes en bruto hay ahora", pero no dice nada especial. Usted mira: "Tengo un millón de mensajes en bruto", ¿y qué? Para interpretar este millón, necesita saber qué tan rápido está funcionando el segmentador (consumidor), lo que no siempre está claro.Con esta métrica, verá de inmediato que los datos se escriben en la cola, que se tomarán de ella, y verá cuánto esperan que se procesen. Vimos que no teníamos tiempo para segmentar, y el mensaje estaba en la cola varias horas antes de leerlo.Simplemente podría agregar capacidad, pero sería demasiado costoso . Por lo tanto, tratamos de optimizar.Autoescalado
Tenemos HBase El usuario está cambiando, su identificador está volando en Kafka. El tema se divide en particiones, la partición de destino se selecciona por ID de usuario. Esto significa que cuando ve al usuario "Vasya" - él va a la partición 1. Cuando ve "Petya" - a la partición 2. Esto es conveniente - puede lograr que verá un consumidor en una instancia de su servicio, y el segundo - por el otro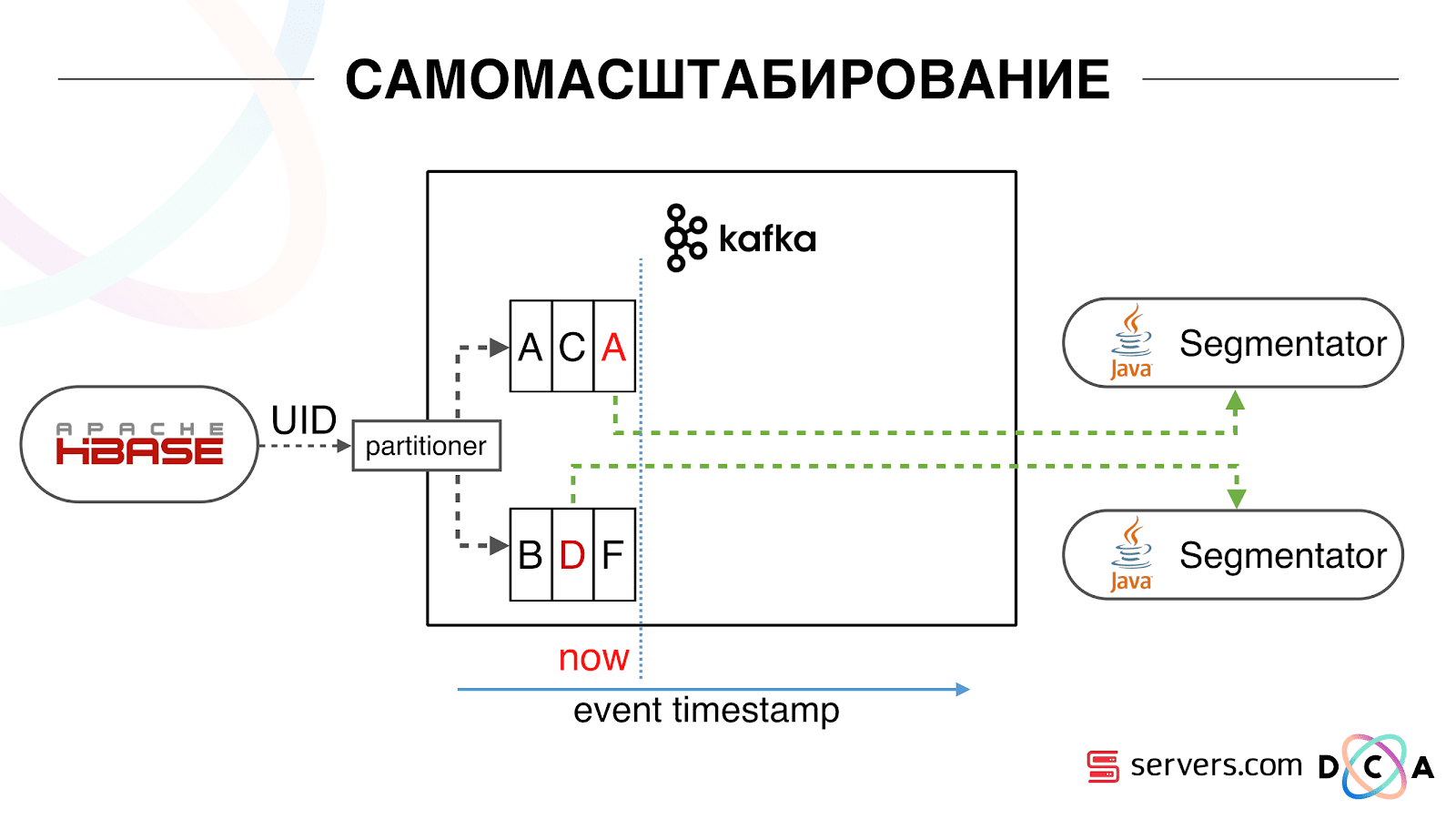 Comenzamos a ver lo que estaba sucediendo. Un comportamiento típico del usuario en Internet es ir a algún sitio web y abrir varias pestañas de fondo. El segundo es ir al sitio y hacer unos pocos clics para llegar a la página de destino.Observamos la cola de segmentación y vemos lo siguiente: el usuario A visitó la página. 5 más eventos provienen de este usuario, cada uno significa una apertura de página. Procesamos cada evento del usuario. Pero, de hecho, los datos en HBase contienen las 5 visitas. Procesamos las 5 visitas por primera vez, la segunda vez, etc., estamos desperdiciando recursos de la CPU.
Comenzamos a ver lo que estaba sucediendo. Un comportamiento típico del usuario en Internet es ir a algún sitio web y abrir varias pestañas de fondo. El segundo es ir al sitio y hacer unos pocos clics para llegar a la página de destino.Observamos la cola de segmentación y vemos lo siguiente: el usuario A visitó la página. 5 más eventos provienen de este usuario, cada uno significa una apertura de página. Procesamos cada evento del usuario. Pero, de hecho, los datos en HBase contienen las 5 visitas. Procesamos las 5 visitas por primera vez, la segunda vez, etc., estamos desperdiciando recursos de la CPU.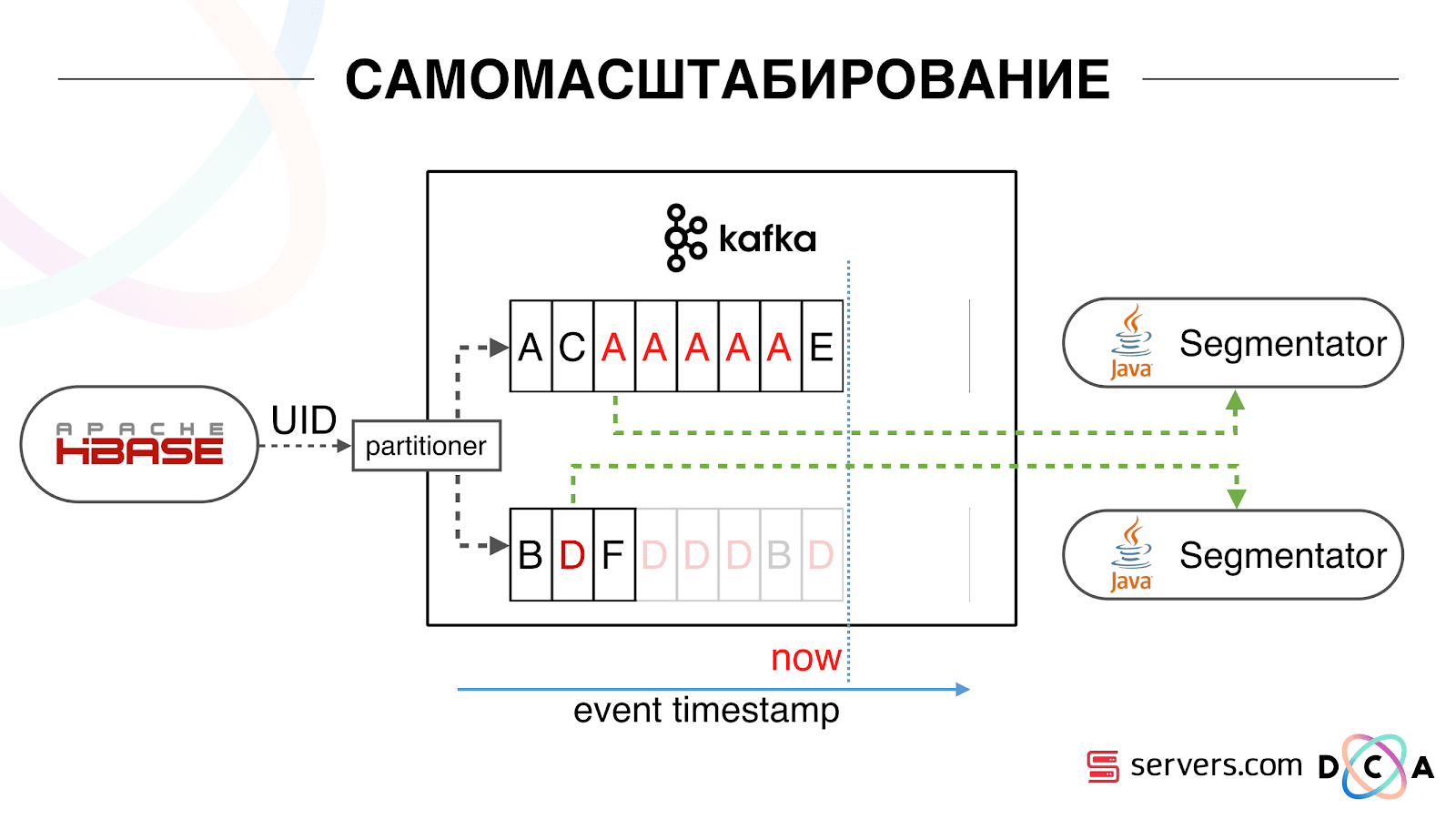 Por lo tanto, comenzamos a almacenar un cierto caché local en cada uno de los segmentadores con la fecha en que analizamos por última vez a este usuario. Es decir, lo procesamos, escribimos su ID de usuario y marca de tiempo en el caché. Cada mensaje kafka también tiene una marca de tiempo, simplemente la comparamos: si la marca de tiempo en la cola es menor que la fecha de la última segmentación, ya hemos analizado al usuario para estos datos, y simplemente puede omitir este evento.Los eventos de usuario (Rojo A) pueden ser diferentes y se salen de orden. El usuario puede abrir varias pestañas de fondo, abrir varios enlaces seguidos, tal vez el sitio tenga varios de nuestros socios a la vez, cada uno de los cuales envía estos datos.Nuestro píxel puede ver la visita del usuario, y luego alguna otra acción: nos enviaremos su casco a nosotros mismos. Llegan cinco eventos, estamos procesando la primera A roja. Si el evento ha llegado, entonces ya está en HBase. Vemos eventos, ejecutamos un conjunto de scripts. Vemos el siguiente evento, y todos los mismos eventos, porque ya están grabados. Lo ejecutamos nuevamente y guardamos el caché con la fecha, lo comparamos con la marca de tiempo del evento.
Por lo tanto, comenzamos a almacenar un cierto caché local en cada uno de los segmentadores con la fecha en que analizamos por última vez a este usuario. Es decir, lo procesamos, escribimos su ID de usuario y marca de tiempo en el caché. Cada mensaje kafka también tiene una marca de tiempo, simplemente la comparamos: si la marca de tiempo en la cola es menor que la fecha de la última segmentación, ya hemos analizado al usuario para estos datos, y simplemente puede omitir este evento.Los eventos de usuario (Rojo A) pueden ser diferentes y se salen de orden. El usuario puede abrir varias pestañas de fondo, abrir varios enlaces seguidos, tal vez el sitio tenga varios de nuestros socios a la vez, cada uno de los cuales envía estos datos.Nuestro píxel puede ver la visita del usuario, y luego alguna otra acción: nos enviaremos su casco a nosotros mismos. Llegan cinco eventos, estamos procesando la primera A roja. Si el evento ha llegado, entonces ya está en HBase. Vemos eventos, ejecutamos un conjunto de scripts. Vemos el siguiente evento, y todos los mismos eventos, porque ya están grabados. Lo ejecutamos nuevamente y guardamos el caché con la fecha, lo comparamos con la marca de tiempo del evento. Gracias a esto, el sistema obtuvo la propiedad de autoescalabilidad. El eje y es el porcentaje de lo que hacemos con las ID de usuario cuando nos llegan. Verde: el trabajo que realizamos lanzó el script de segmentación. Amarillo: no hicimos esto porque Ya segmentado exactamente estos datos.
Gracias a esto, el sistema obtuvo la propiedad de autoescalabilidad. El eje y es el porcentaje de lo que hacemos con las ID de usuario cuando nos llegan. Verde: el trabajo que realizamos lanzó el script de segmentación. Amarillo: no hicimos esto porque Ya segmentado exactamente estos datos.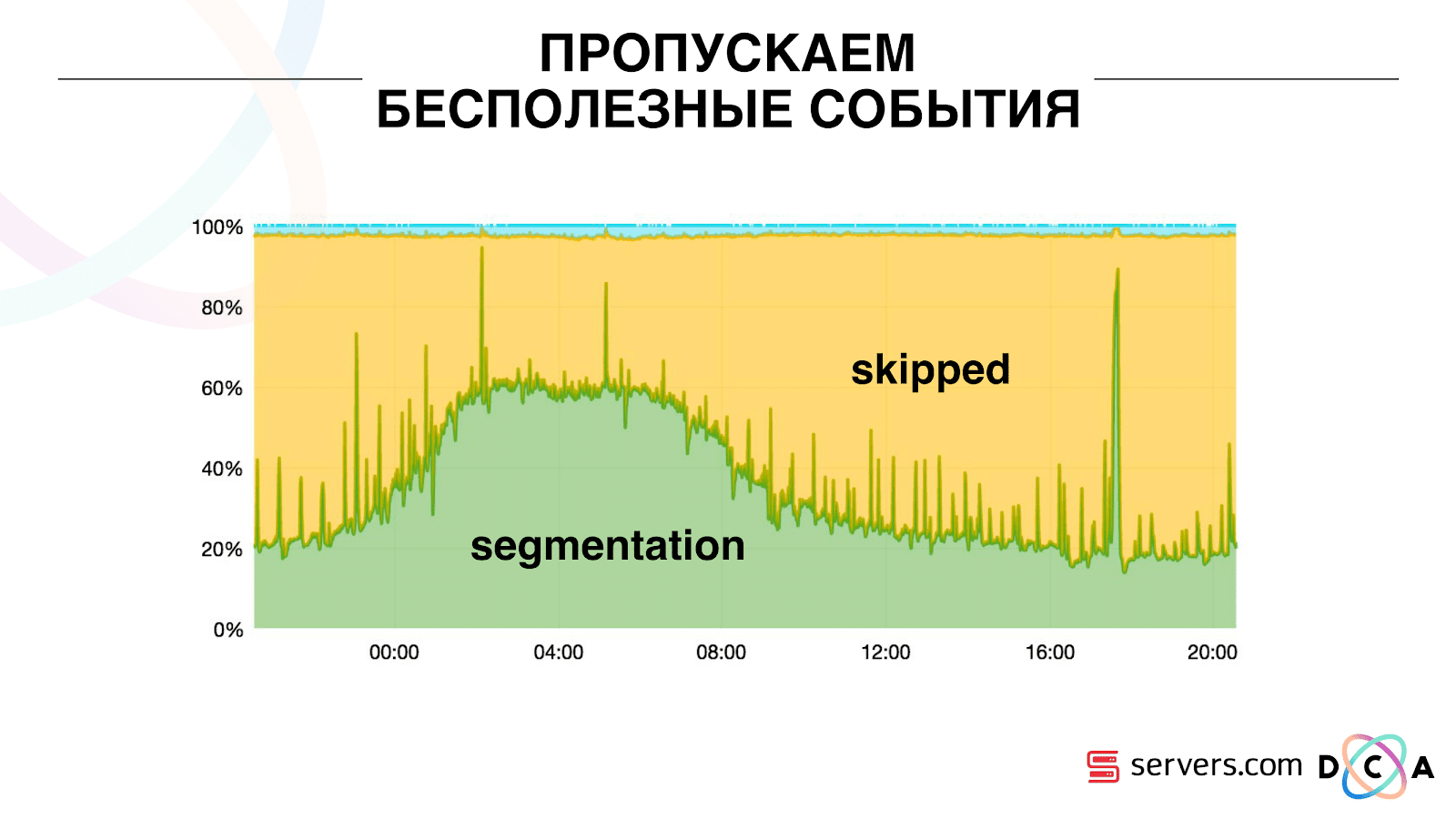 Se puede ver que hay recursos por la noche, hay menos flujo de datos y puede segmentar cada segundo evento. Un día de recursos más pequeño, y segmentamos solo el 20% de los eventos. Un salto al final del día: el socio subió archivos de datos que no habíamos visto antes, y tuvieron que ser segmentados "honestamente".El sistema en sí se adapta al crecimiento de la carga. Si tenemos un socio muy grande, procesamos los mismos datos pero con un poco menos de frecuencia. En este caso, las características del sistema se deteriorarán en la noche, la segmentación se retrasará no por 2-3 segundos, sino por un minuto. Por la mañana, agregue los servidores y vuelva a los resultados deseados.Por lo tanto, ahorramos aproximadamente 5 veces en los servidores. Ahora trabajamos en 10 servidores, por lo que tomaría 50-60.La pequeña cosa azul en la parte superior son los bots. Esta es la parte más difícil de la segmentación. Tienen una gran cantidad de visitas, crean una carga muy grande en la plancha. Vemos cada bot en un servidor separado. Podemos recopilar en él un caché local con una lista negra de bots. Introdujo un simple antifraude: si un usuario realiza demasiadas visitas durante un tiempo determinado, entonces algo está mal con él, lo agregamos a la lista negra por un tiempo. Esta es una pequeña franja azul, alrededor del 5%. Nos dieron otro 30% de ahorro en CPU.Por lo tanto, hemos logrado lo que vemos en todo el proceso de procesamiento de datos en cada etapa. Vemos métricas de cuánto fue el mensaje en Kafka. Por la noche, algo apagado en alguna parte, el tiempo de procesamiento aumentó a un minuto, luego se soltó y volvió a la normalidad.
Se puede ver que hay recursos por la noche, hay menos flujo de datos y puede segmentar cada segundo evento. Un día de recursos más pequeño, y segmentamos solo el 20% de los eventos. Un salto al final del día: el socio subió archivos de datos que no habíamos visto antes, y tuvieron que ser segmentados "honestamente".El sistema en sí se adapta al crecimiento de la carga. Si tenemos un socio muy grande, procesamos los mismos datos pero con un poco menos de frecuencia. En este caso, las características del sistema se deteriorarán en la noche, la segmentación se retrasará no por 2-3 segundos, sino por un minuto. Por la mañana, agregue los servidores y vuelva a los resultados deseados.Por lo tanto, ahorramos aproximadamente 5 veces en los servidores. Ahora trabajamos en 10 servidores, por lo que tomaría 50-60.La pequeña cosa azul en la parte superior son los bots. Esta es la parte más difícil de la segmentación. Tienen una gran cantidad de visitas, crean una carga muy grande en la plancha. Vemos cada bot en un servidor separado. Podemos recopilar en él un caché local con una lista negra de bots. Introdujo un simple antifraude: si un usuario realiza demasiadas visitas durante un tiempo determinado, entonces algo está mal con él, lo agregamos a la lista negra por un tiempo. Esta es una pequeña franja azul, alrededor del 5%. Nos dieron otro 30% de ahorro en CPU.Por lo tanto, hemos logrado lo que vemos en todo el proceso de procesamiento de datos en cada etapa. Vemos métricas de cuánto fue el mensaje en Kafka. Por la noche, algo apagado en alguna parte, el tiempo de procesamiento aumentó a un minuto, luego se soltó y volvió a la normalidad. Podemos monitorear cómo nuestras acciones con el sistema afectan su rendimiento, podemos ver cuánto se ejecuta el script, dónde es necesario optimizar y cuánto se puede guardar. Podemos ver el tamaño de los segmentos, la dinámica del tamaño de los segmentos, evaluar su asociación e intersección. Esto se puede hacer para más o menos los mismos tamaños de segmento.
Podemos monitorear cómo nuestras acciones con el sistema afectan su rendimiento, podemos ver cuánto se ejecuta el script, dónde es necesario optimizar y cuánto se puede guardar. Podemos ver el tamaño de los segmentos, la dinámica del tamaño de los segmentos, evaluar su asociación e intersección. Esto se puede hacer para más o menos los mismos tamaños de segmento.¿Qué te gustaría refinar?
Tenemos un clúster Hadoop con algunos recursos informáticos. Está ocupado: los analistas trabajan en él durante el día, pero por la noche es prácticamente libre. En general, podemos contenerizar y ejecutar el segmentador como un proceso separado dentro de nuestro clúster. Queremos almacenar estadísticas con mayor precisión para calcular con mayor precisión el volumen de la intersección. También necesitamos optimización en la CPU. Esto afecta directamente el costo de la decisión.Para resumir: Kafka es bueno, pero, como con cualquier otra tecnología, debe comprender cómo funciona por dentro y qué le sucede. Por ejemplo, la garantía de prioridad de mensajes solo funciona dentro de la partición. Si envía un mensaje que va a diferentes particiones, no está claro en qué orden se procesarán.Los datos reales son muy importantes. Si no hubiéramos probado el tráfico real, lo más probable es que no hubiéramos visto problemas con los bots, con las sesiones de los usuarios. Desarrollaría algo en el vacío, correría y se acostaría. Es importante monitorear lo que considera necesario monitorear, y no monitorear lo que no piensa.Minuto de publicidad. Si le gustó este informe de la conferencia SmartData, tenga en cuenta que SmartData 2018 se llevará a cabo en San Petersburgo el 15 de octubre, una conferencia para aquellos que están inmersos en el mundo del aprendizaje automático, el análisis y el procesamiento de datos. El programa tendrá muchas cosas interesantes, el sitio ya tiene sus primeros oradores e informes.