Ya está claro por el nombre que un navegador sin cabeza es algo sin cabeza. En el contexto de una interfaz de usuario, es una herramienta indispensable para un desarrollador, con la que puede probar el código, verificar la calidad y el cumplimiento del diseño. Vitaliy Slobodin en Frontend Conf decidió que era necesario conocer más de cerca el dispositivo de esta herramienta.
Bajo los componentes y características de corte de Headless Chrome, escenarios interesantes para usar Headless Chrome. La segunda parte sobre Puppeteer es una conveniente biblioteca Node.js para administrar el modo Headless en Google Chrome y Chromium.
Sobre el orador: Vitaliy Slobodin, un antiguo desarrollador de PhantomJS, quien lo cerró y lo enterró. A veces ayuda a Konstantin Tokarev (
annulen ) en la versión "resucitada" de QtWebKit, el mismo QtWebKit, donde hay soporte para ES6, Flexbox y muchos otros estándares modernos.
A Vitaliy le encanta explorar navegadores, explorar WebKit, Chrome, etc. en su tiempo libre y más. Hoy hablaremos sobre los navegadores, es decir, sobre los navegadores sin cabeza y toda su familia de fantasmas.
¿Qué es un navegador sin cabeza?
Ya por el nombre está claro que esto es algo sin cabeza. En un contexto de navegador, esto significa lo siguiente.
- No tiene una representación real del contenido , es decir, dibuja todo en la memoria.
- Debido a esto, consume menos memoria , ya que no hay necesidad de dibujar imágenes o PNG de gigabytes que las personas intentan poner en el backend usando una bomba.
- Funciona más rápido porque no necesita renderizar nada en la pantalla real.
- Tiene una interfaz de programación para la gestión . Usted pregunta: ¿no tiene una interfaz, botones, ventanas? ¿Cómo gestionarlo? Por lo tanto, por supuesto, tiene una interfaz para la administración.
- Una propiedad importante es la capacidad de instalar en un servidor Linux desnudo . Esto es necesario para que si tiene un Ubuntu o Red Hat recién instalado, simplemente puede soltar el binario o colocar el paquete allí, y el navegador funcionará de inmediato. No se necesita chamanismo ni magia vudú.
Este es un navegador típico basado en WebKit. No puede obtener una idea de los componentes, esto es solo una imagen visual.

Solo estamos interesados en el componente superior de la interfaz de usuario del navegador. Esta es la misma interfaz de usuario: ventanas, menús, notificaciones emergentes y todo lo demás.

Así es como se ve el navegador sin cabeza. ¿Nota la diferencia? Eliminamos completamente la interfaz de usuario. El ya no existe.
Solo queda el navegador .
Hoy hablaremos de Headless Chrome (). ¿Cuál es la diferencia entre ellos? De hecho, Chrome es una versión de marca de Chromium, que tiene códecs patentados, el mismo H.264, integración con los servicios de Google y todo lo demás. Chromium es solo una implementación de código abierto.

Fecha de nacimiento de Chrome sin cabeza: 2016. Si se encuentra con él, puede hacerme una pregunta difícil: "¿Cómo es eso, recuerdo las noticias de 2017?" El hecho es que un equipo de ingenieros de Google contactó a los desarrolladores de PhantomJS en 2016, cuando recién comenzaban a implementar el modo Headless en Chrome. Escribimos Google Docks completo, cómo implementaremos la interfaz, etc. Entonces Google quería hacer una interfaz totalmente compatible con PhantomJS. Fue solo entonces que el equipo de ingenieros tomó la decisión de no hacer tal compatibilidad.
Hablaremos sobre la interfaz de administración (API), que es el protocolo Chrome DevTools, más adelante y veremos qué puede hacer con él.
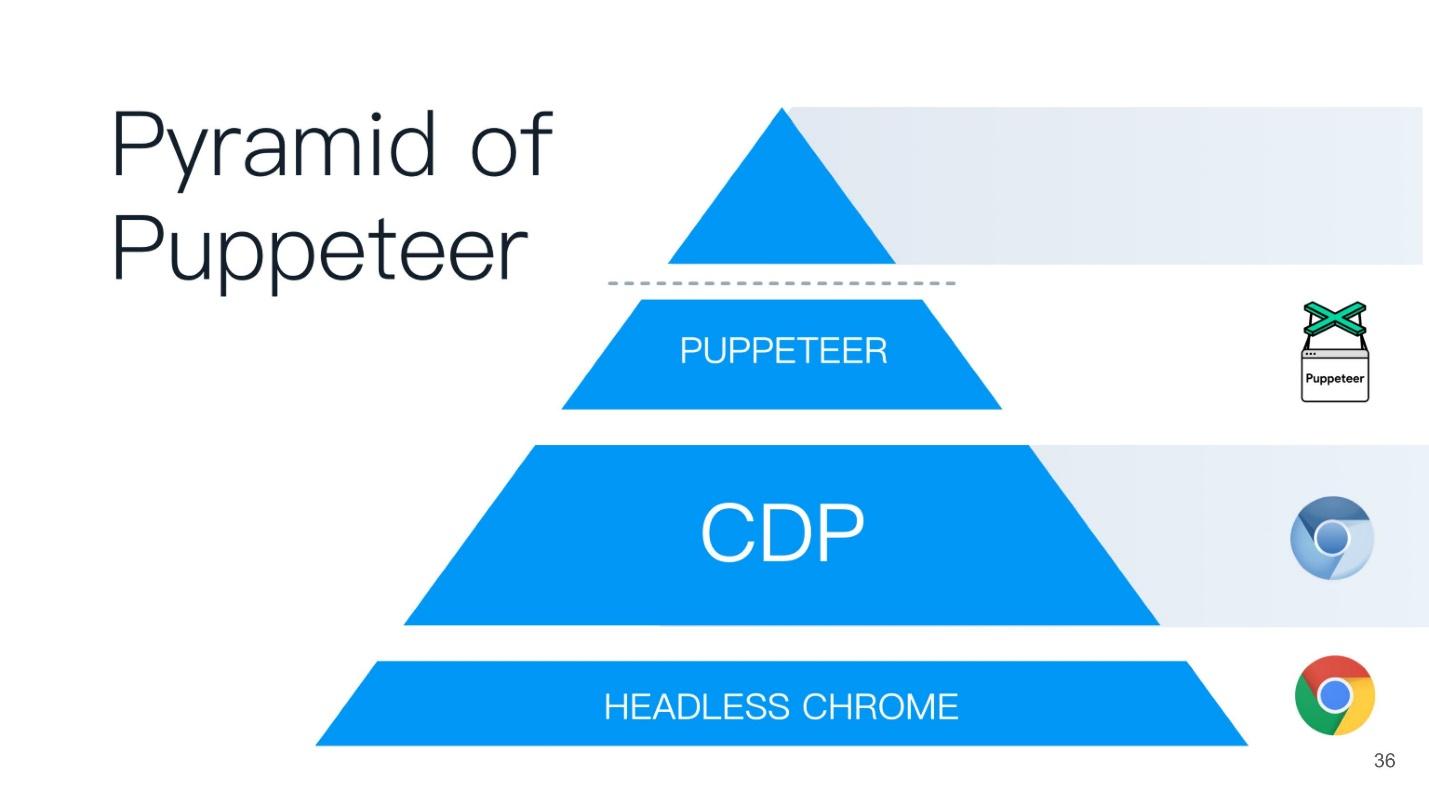
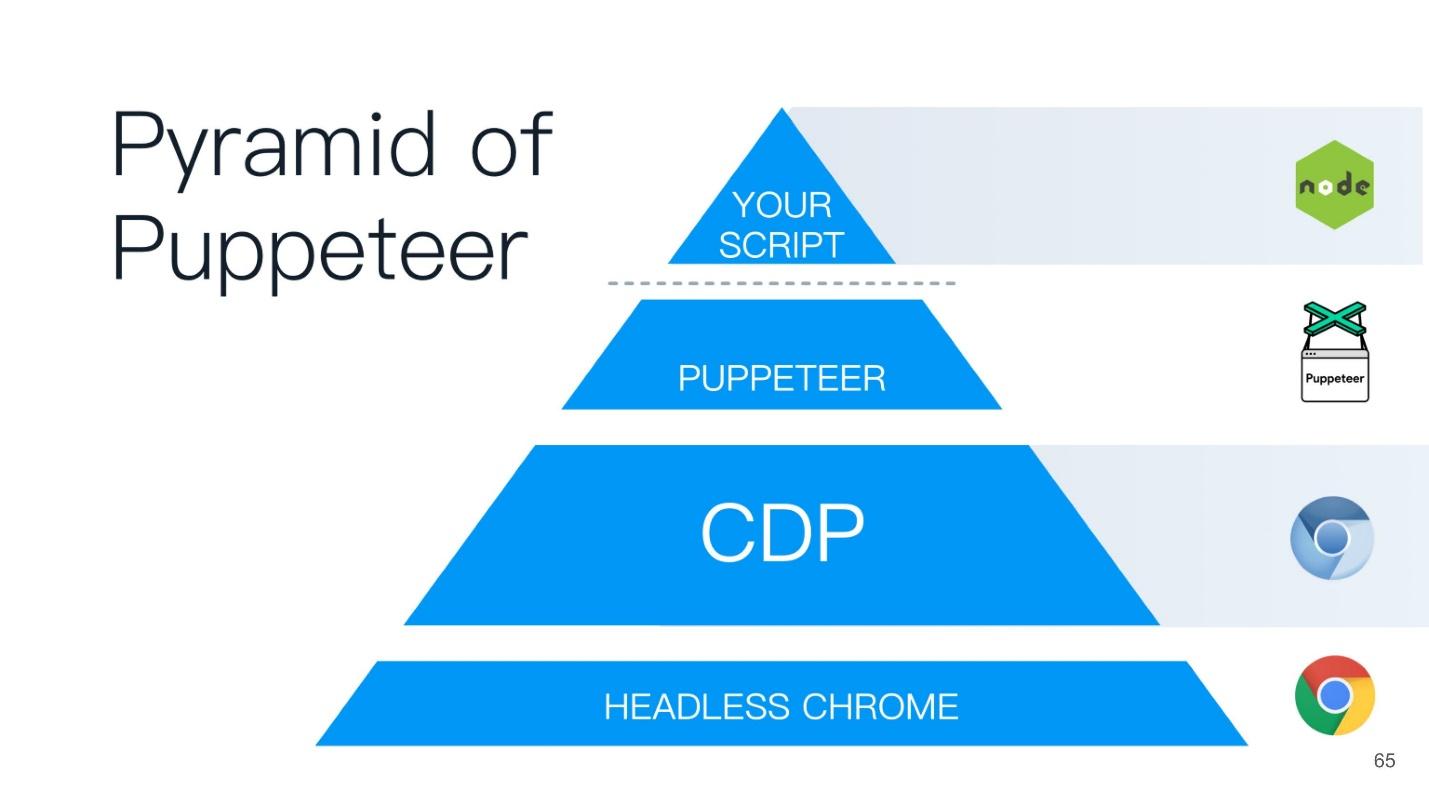
Este artículo se basará en el principio de la pirámide del titiritero (del titiritero inglés). Se elige un buen nombre: ¡el titiritero es el que controla a todos los demás!
En la base de la pirámide se encuentra Chrome sin cabeza - Chrome sin cabeza, ¿qué es?
Cromo sin cabeza
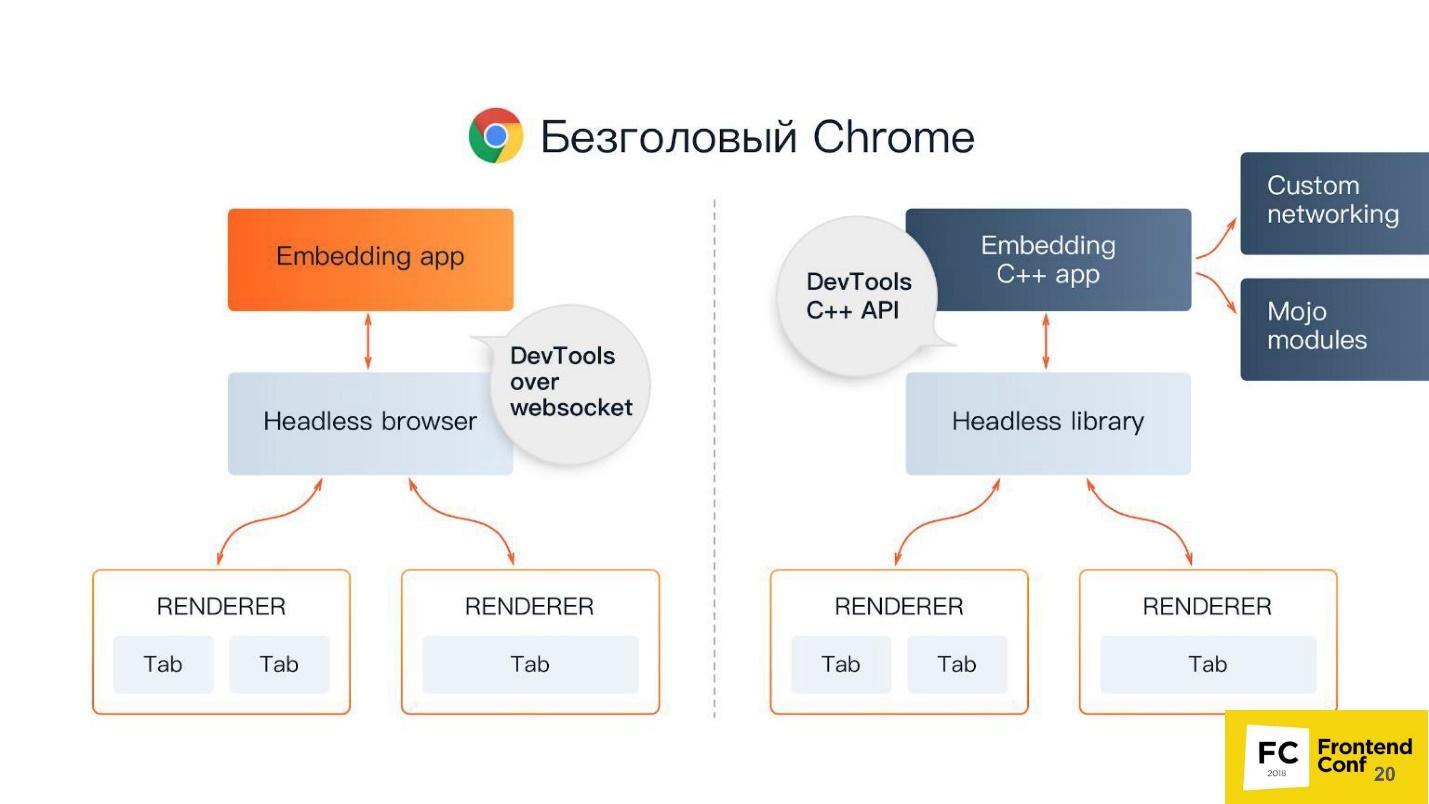
En el centro, navegador sin cabeza, el mismo cromo o cromo (generalmente cromo). Tiene los llamados renderizadores (RENDERER): procesos que dibujan el contenido de la página (su ventana). Además, cada pestaña necesita su propio procesador, por lo que si abre muchas pestañas, Chrome iniciará tantos procesos para la representación.
Además de todo esto es su aplicación. Si tomamos Chromium o Chrome sin cabeza, entonces Chrome estará encima, o alguna aplicación en la que puedas incrustarlo. El análogo más cercano se puede llamar Steam. Todo el mundo sabe que, en esencia, Steam es solo un navegador del sitio web de Steam. Él, por supuesto, no es decapitado, sino similar a este esquema.
Hay 2 formas de incrustar Chrome sin cabeza en su aplicación (o usarla):
- Estándar cuando tomas Puppeteer y usas Headless Chrome.
- Cuando toma el componente de biblioteca sin cabeza , es decir, una biblioteca que implementa el modo sin cabeza y lo integra en su aplicación, por ejemplo, en C ++.
Usted puede preguntar, ¿por qué C ++ está en la parte frontal? La respuesta es la API DevTools C ++. Puede implementar y usar las funciones de Chrome sin cabeza de diferentes maneras. Si utiliza Puppeteer, la comunicación con un navegador sin cabeza se realizará a través de sockets web. Si incrusta la biblioteca Headless en una aplicación de escritorio, utilizará la interfaz nativa, que está escrita en C ++.
Pero además de todo esto, todavía tiene cosas adicionales, que incluyen:
- Redes personalizadas: implementación personalizada de interacción con la red. Supongamos que trabaja en un banco o en una agencia gubernamental, que consta de tres letras y comienza con "F", y utiliza un protocolo de autenticación o autorización muy complicado que no es compatible con los navegadores. Por lo tanto, es posible que necesite un controlador personalizado para su red. Simplemente puede tomar su biblioteca ya implementada y usarla en Chrome.
- Módulos Mojo . El análogo más cercano de Mojo son las carpetas nativas en Node.js a sus bibliotecas nativas escritas en C ++. Mojo hace lo mismo: toma su biblioteca nativa, escribe una interfaz Mojo para ella y luego puede llamar a los métodos de su biblioteca nativa en su navegador.
Componentes de cromo
Nuevamente escucho una pregunta difícil: “¿Por qué necesito este terrible esquema? Escribo debajo (inserte el nombre de su marco favorito) ".
Creo que un desarrollador debe saber cómo funciona su herramienta. Si escribe debajo de React, debe saber cómo funciona React. Si escribe debajo de Angular, debe saber qué tiene Angular debajo del capó.
Porque en el caso de algo, por ejemplo, un error fatal o un error muy grave en la producción, tienes que lidiar con las "agallas", y simplemente puedes perderte allí: dónde, qué y cómo. Si, por ejemplo, escribe pruebas o usa Headless Chrome, también puede encontrar algunos de sus comportamientos extraños y errores. Por lo tanto, te diré brevemente qué cromo tiene componentes. Cuando vea un seguimiento de pila grande, ya sabrá qué forma de excavar y cómo solucionarlo.
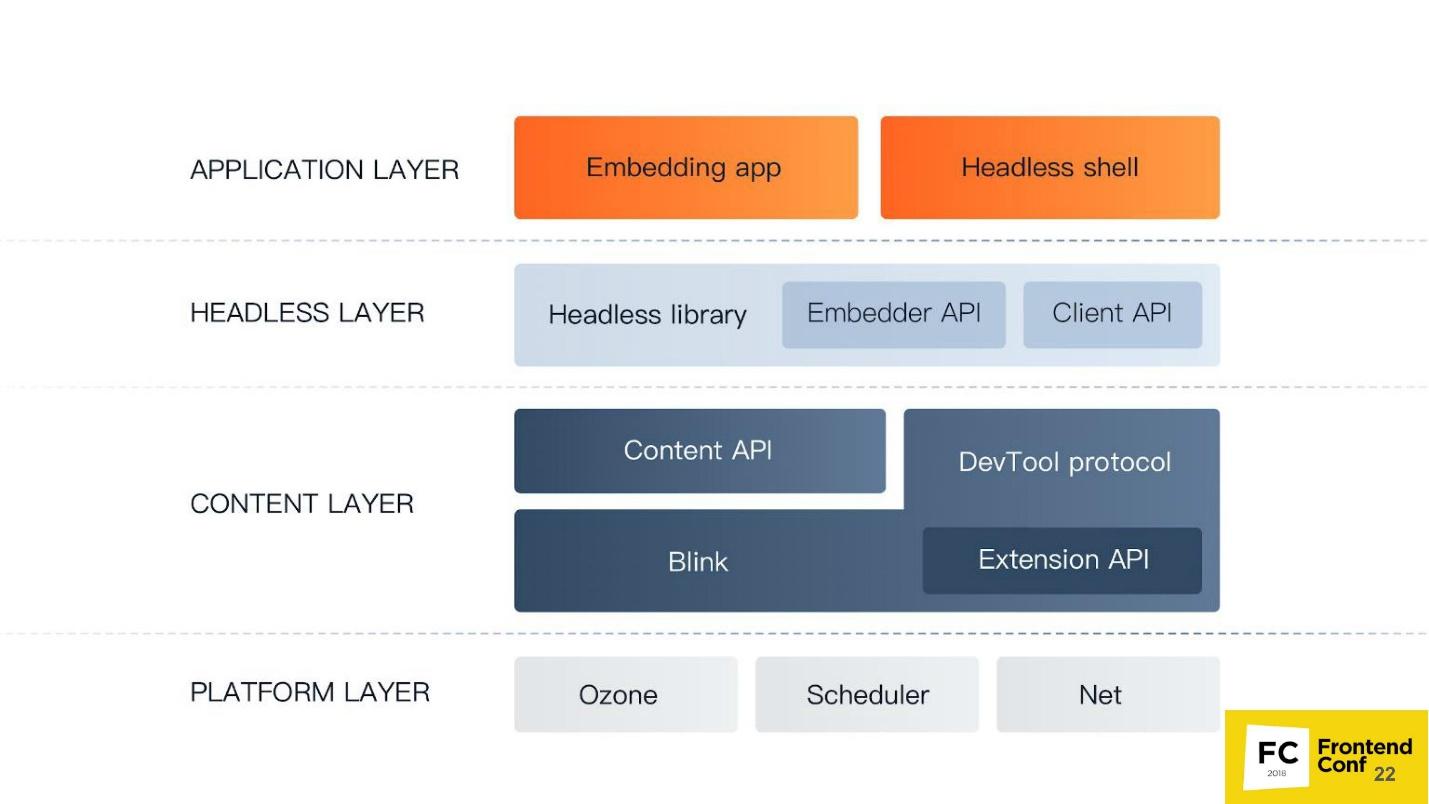
El nivel más bajo de la
capa de Plataforma . Sus componentes:
- Ozone , el administrador de ventanas abstracto en Chrome, es con lo que interactúa el administrador de ventanas del sistema operativo. En Linux, es un servidor X o Wayland. En Windows, es un administrador de ventanas de Windows.
- Scheduler es el mismo planificador sin el cual no estamos en ninguna parte, porque todos sabemos que Chrome es una aplicación multiproceso, y necesitamos resolver de alguna manera todos los hilos, procesos y todo lo demás.
- Net : el navegador siempre debe tener un componente para trabajar con la red, por ejemplo, analizar HTTP, crear encabezados, editar, etc.
La
capa de contenido es el componente más grande que tiene Chrome. Incluye:
- Blink es un motor web basado en WebCore de WebKit. Puede tomar HTML como una cadena, analizar, ejecutar JavaScript, y eso es todo. Ya no sabe cómo hacer nada: ni trabajar con la red ni dibujar: todo esto sucede además de Blink.
Blink incluye: una versión altamente modificada de WebCore, un motor web para trabajar con HTML y CSS; V8 (motor de JavaScript); así como una API para todas las extensiones que utilizamos en Chrome, como un bloqueador de anuncios. También incluye el protocolo DevTools.
- Content API es una interfaz con la que puede usar fácilmente todas las funciones del motor web. Dado que hay tantas cosas dentro de Blink (probablemente más de un millón de interfaces), para no perderse en todos estos métodos y funciones, necesita una API de contenido. Ingresa HTML, el motor lo procesará automáticamente, analizará el DOM, creará CSS OM, ejecutará JavaScript, ejecutará temporizadores, controladores y todo lo demás.
Nivel de
capa sin cabeza - nivel de navegador sin cabeza:
- Biblioteca sin cabeza .
- Interfaz API de incrustación para incrustar la biblioteca sin cabeza en la aplicación.
- Client API es una interfaz que utiliza Puppeteer.
Capa de aplicación Capa de aplicación :
- Su aplicación (aplicación de incrustación );
- Gadgets, por ejemplo, Shell sin cabeza .
Ahora, levántese un poco más de las profundidades, actívelo, ahora la interfaz se irá.
Protocolo de Chrome DevTools
Todos nos encontramos con el protocolo Chrome DevTools, porque utilizamos el panel de desarrollador en Chrome o el depurador remoto, las mismas herramientas de desarrollo. Si ejecuta las herramientas de desarrollador de forma remota, la comunicación con el navegador se realiza utilizando el protocolo DevTools. Cuando instale el depurador, vea la cobertura del código, use la geolocalización u otra cosa; todo esto se controla mediante DevTools.
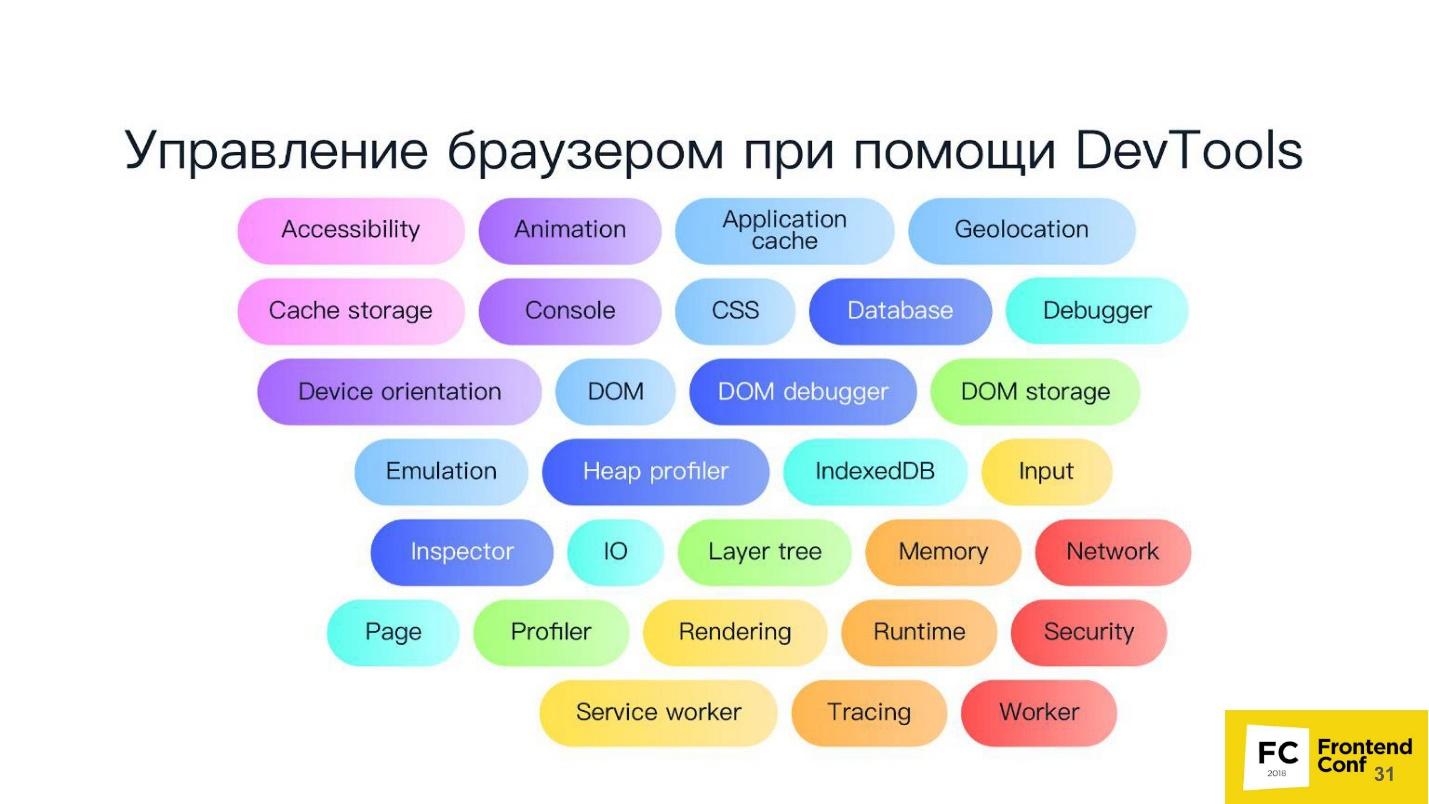
De hecho, el protocolo DevTools tiene una gran cantidad de métodos. Su herramienta de desarrollador no tiene acceso, probablemente al 80% de ellos. Realmente, ¡puedes hacer todo allí!
Veamos de qué se trata este protocolo. De hecho, es muy simple. Tiene 2 componentes:
- Objetivo DevTools: la pestaña que está inspeccionando;
- Cliente DevTools: digamos que este es un panel de desarrollador que se inicia de forma remota.

Se comunican usando JSON simple:
- Hay un identificador para el comando, el nombre del método a ejecutar y algunos parámetros.
- Enviamos una solicitud y obtenemos una respuesta que también parece muy simple: un identificador que se necesita porque todos los comandos que se ejecutan utilizando el protocolo son asíncronos. Para que podamos comparar siempre qué respuesta con qué equipo recibimos, necesitamos un identificador.
- Hay un resultado En nuestro caso, es un objeto de resultado con los siguientes atributos: tipo: "número", valor: 2, descripción: "2" , no se produjo ninguna excepción: wasThrown: false.
Pero entre otras cosas, su pestaña puede enviarle eventos. Suponga que cuando ocurre un evento en una página, o si hay una excepción en una página, recibirá una notificación a través de este protocolo.

Titiritero
Puede instalar Puppeteer usando su administrador de paquetes favorito, ya sea hilo, npm o cualquier otro.
Usarlo también es fácil: solo solicítelo en su script Node.js, y ya puede usarlo.

Usando el enlace
https://try-puppeteer.appspot.com, puede escribir un script directamente en el sitio, ejecutarlo y obtener el resultado directamente en el navegador. Todo esto se implementará utilizando Headless Chrome.
Considere el script más simple en Node.js:
const puppeteer = require('puppeteer'); (async() => { const browser = await puppeteer.launch() ; const page = await browser.newPage(); await page.goto('http://devconf.ru/') ; await page.emulateMedia('screen') ; await page.pdf({ path: './devconf.pdf, printBackground: true }); await browser.close() ; })();
Aquí simplemente abrimos la página e imprimimos en PDF. Veamos el funcionamiento de este script en tiempo real:
Todo estará bien, pero no está claro qué hay dentro. Por supuesto, tenemos un navegador sin cabeza, pero no vemos nada. Por lo tanto, Titiritero tiene una bandera especial llamada sin cabeza: falso:
const browser = await puppeteer.launch({ headless: false });
Es necesario para iniciar el navegador sin cabeza en modo headful, cuando puede ver alguna ventana y ver qué sucede con su página en tiempo real, es decir, cómo interactúa su script con su página.
Esto se verá el mismo script cuando agreguemos esta bandera. Aparece una ventana del navegador a la izquierda, más claramente.
Ventajas del titiritero:+ Esta es la biblioteca Node.js para Chrome sin cabeza.
+ Soporte para versiones heredadas de Node.js> = 6.
+ Fácil instalación.
+ API de alto nivel para administrar toda esta máquina gigante.
Chrome sin cabeza se instala fácilmente y sin intervención del sistema. En la primera instalación, Puppeteer descarga la versión de Chromium y la instala directamente en la carpeta node_modules específicamente para su arquitectura y sistema operativo. No necesita descargar nada extra, lo hace automáticamente. También puede usar su versión favorita de Chrome, que está instalada en su sistema. Usted también puede hacer esto: Puppeteer le proporciona dicha API.
Desafortunadamente, también hay desventajas, si tomamos solo la instalación básica.
Contra titiriteros :
-
Sin funciones de nivel superior : sincronización de marcadores y contraseñas; soporte de perfil; aceleración de hardware, etc.
-
La representación del software es el menos más significativo. Todos los cálculos y la representación tienen lugar en su CPU. Pero aquí, los ingenieros de Google pronto nos sorprenderán: ya se está trabajando en la implementación de la aceleración de hardware. Ya puedes intentar usarlo si eres valiente y valiente.
- Hasta hace poco, no había soporte para extensiones, ¡ahora sí lo hay! Si es un desarrollador astuto, puede tomar su AdBlock favorito, especificar cómo lo usará Puppeteer y se bloquearán todos los anuncios.
-
No hay soporte de audio / video . Porque, bueno, por qué el audio y el video del navegador sin cabeza.
¿Qué puede titiritero:- Sesiones de aislamiento.
- Temporizadores virtuales.
- Intercepción de solicitudes de red.
Y un par de cosas geniales que mostraré un poco más.
Aislamiento de sesión
¿Qué es, con qué se come y no nos asfixiamos? - ¡No te ahogues!
El aislamiento de la sesión es un
"repositorio" separado para cada pestaña . Cuando inicia Puppeteer, puede crear una nueva página, y cada nueva página puede tener su propio repositorio, que incluye:
- cocineros
- almacenamiento local;
- caché
Todas las páginas vivirán independientemente unas de otras. Esto es necesario, por ejemplo, para mantener la atomicidad de las pruebas.
El aislamiento de la sesión
ahorra recursos y tiempo al iniciar sesiones paralelas . Suponga que está probando un sitio que se está creando en modo de desarrollo, es decir, el paquete no está minimizado y pesa 20 MB. Si solo desea almacenarlo en caché, puede decirle a Puppeteer que use un caché común a todas las páginas que se crean, y este paquete se almacenará en caché.
Puede
serializar sesiones para su uso posterior . Escribe una prueba que verifica una determinada acción en su sitio. Pero tiene un problema: el sitio requiere autorización. No agregará constantemente antes en cada prueba para obtener autorización en el sitio. Puppeteer le permite iniciar sesión en el sitio una vez y luego reutilizar esta sesión en el futuro.
Temporizadores virtuales
Es posible que ya esté utilizando temporizadores virtuales. Si movió el control deslizante en una herramienta de desarrollador que acelera o ralentiza la animación (¡y se lavó las manos después de eso, por supuesto!), Entonces en ese momento usó temporizadores virtuales en el navegador.
El navegador puede usar temporizadores virtuales en lugar de reales para
"desplazarse" hacia adelante para acelerar la carga de la página o completar la animación. Supongamos que tienes la misma prueba, vas a la página principal y allí la animación durante 30 segundos. No es beneficioso para nadie que la prueba espere todo este tiempo. Por lo tanto, simplemente puede acelerar la animación para que se complete instantáneamente cuando se cargue la página y su prueba continúe.
Puede
detener el tiempo mientras se ejecuta la solicitud de red . Por ejemplo, prueba la reacción de su aplicación cuando una solicitud que se ha enviado al backend tarda mucho tiempo en ejecutarse o regresa con un error. Puedes detener el tiempo: Titiritero lo permite.
En la siguiente diapositiva, hay otra opción:
detener y continuar con el renderizador. En el modo experimental, fue posible decirle al navegador que no se procesara y luego, si es necesario, solicitar una captura de pantalla. Luego, Chrome sin cabeza renderizaría rápidamente todo, haría una captura de pantalla y nuevamente dejaría de dibujar cualquier cosa. Desafortunadamente, los desarrolladores ya han logrado cambiar el principio de funcionamiento de esta API y ya no existe tal función.
Una vista esquemática de los temporizadores virtuales a continuación.
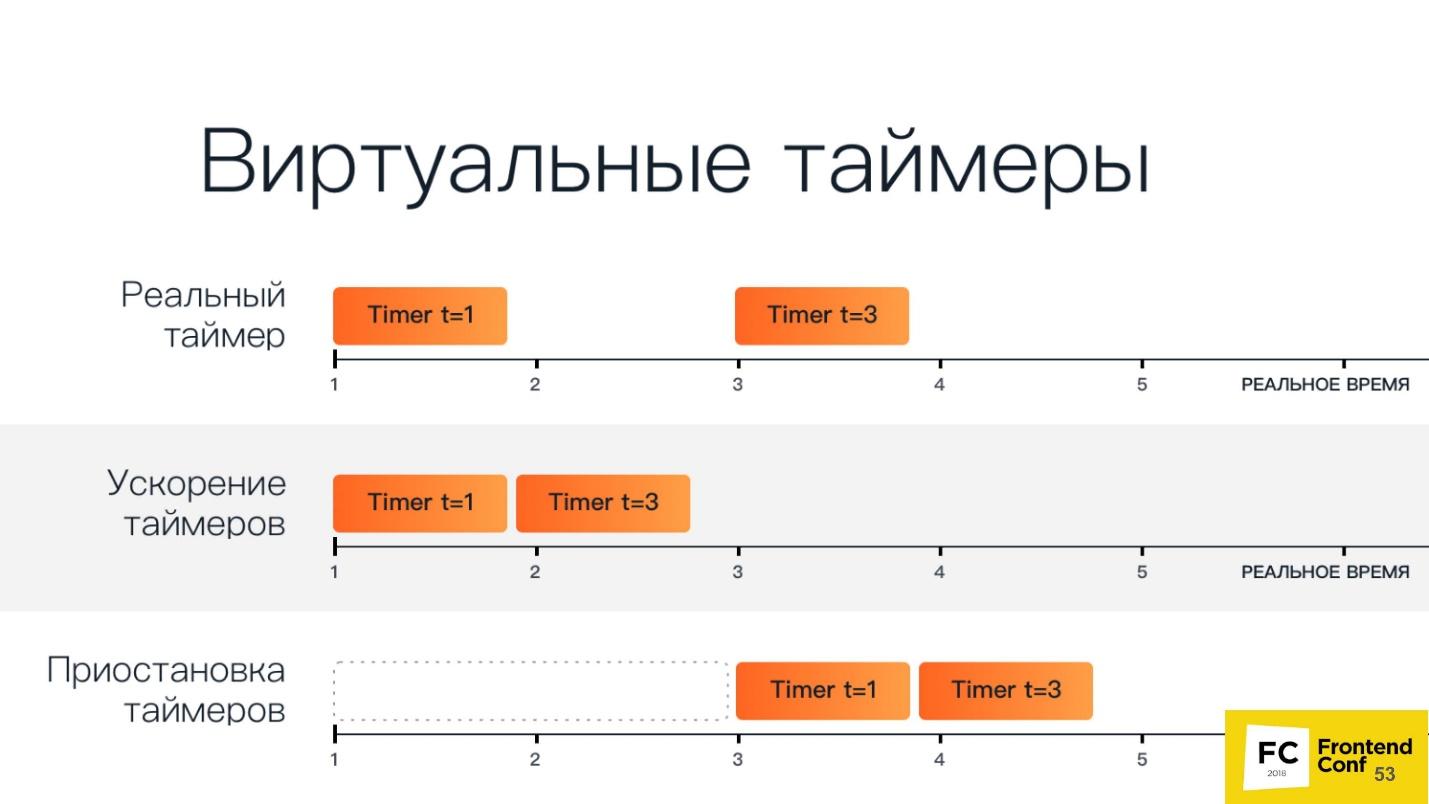
La línea superior tiene dos temporizadores regulares: el primero comienza en la primera unidad de tiempo y se ejecuta en una unidad de tiempo, el segundo comienza en la tercera unidad de tiempo y se ejecuta en tres unidades de tiempo.
Acelerando los temporizadores: comienzan uno tras otro. Cuando los detenemos, tenemos un período de tiempo después del cual comienzan todos los temporizadores.
Considera esto como un ejemplo. A continuación se muestra un fragmento de código que esencialmente carga la página de animación de codepen.io y espera:
(async() => { const browser = await puppeteer.launch(); const page = await browser.newPage(); const url = 'https ://codepen.o/ajerez/full/EaEEOW/';
Esta demostración de implementación durante la presentación es solo animación.
Ahora, usando el protocolo Chrome DevTools, enviaremos un método llamado Animation.setPlaybackRate, pasaremos una tasa de reproducción con un valor de 12 como parámetros:
const url = 'https://codepen.o/ajerez/full/EaEEOW/';
Cargamos el mismo enlace, y el animashka comenzó a funcionar mucho más rápido. Esto se debe al hecho de que usamos un temporizador virtual y aceleramos la reproducción de la animación 12 veces.
Hagamos un experimento ahora, pase el índice de reproducción: 0, y vea qué sucede. Y aquí estará esto: no hay animación en absoluto, no se reproduce. Los valores cero y negativos simplemente detienen la animación completa por completo.
Trabajar con solicitudes de red.
Puede
interceptar solicitudes de red configurando el siguiente indicador:
await page.setRequestlnterception(true);
En este modo, aparece un evento adicional que se activa cuando se envía o recibe una solicitud de red.
Puede
cambiar la solicitud sobre la marcha . Esto significa que puede cambiar completamente todos sus contenidos (cuerpo) y sus encabezados, inspeccionar, incluso cancelar la solicitud.
Esto es necesario para
procesar la autorización o autenticación , incluida la autenticación básica a través de HTTP.
También puede hacer
cobertura de código (JS / CSS) . Con Puppeteer, puede automatizar todo esto. Todos conocemos utilidades que pueden cargar una página, mostrar qué clases se usan en ella, etc. ¿Pero estamos satisfechos con ellos? Creo que no
El navegador sabe mejor qué selectores y clases se utilizan: ¡es un navegador! Él siempre sabe qué JavaScript se ejecutó, qué no, qué CSS se usa, cuál no.
El protocolo Chrome DevTools viene al rescate:
await Promise.all ( [ page.coverage.startJSCoverage(), page.coverage.startCSSCoverage() ]); await page.goto('https://example.com'); const [jsCoverage, cssCoverage] = await Promise,all([ page.coverage.stopJSCoverage(), page.coverage.stopCSSCoverage() ]):
En las dos primeras líneas, lanzamos una característica relativamente nueva que le permite conocer la cobertura del código. Ejecute JS y CSS, vaya a alguna página, luego diga, deténgase, y podremos ver los resultados. Y estos no son algunos resultados imaginarios, sino aquellos que el navegador ve debido al motor.
Entre otras cosas, ya hay un complemento que para Puppeteer lo exporta todo a Estambul.
En la parte superior de la pirámide del Titiritero hay un guión que escribiste en Node.js, es como el padrino en todos los puntos inferiores.
Pero ... "no todo está tranquilo en el reino danés ...", como escribió William Shakespeare.
¿Qué hay de malo con los navegadores sin cabeza?
Los navegadores sin cabeza tienen problemas a pesar de que todas sus características interesantes pueden hacer mucho.
Diferencia en el renderizado de páginas en diferentes plataformas.
Realmente amo este artículo y constantemente hablo sobre ello. Miremos esta foto.

Aquí hay una página normal con texto plano: a la derecha, renderizado en Chrome en Linux, a la izquierda, en Windows. Aquellos que prueban con capturas de pantalla saben que siempre se establece un valor, llamado "margen de error", que determina cuándo la captura de pantalla se considera idéntica y cuándo no.
De hecho, el problema es que no importa cómo intente establecer este umbral, el error siempre irá más allá de esta línea y aún recibirá resultados falsos positivos. Esto se debe al hecho de que todas las páginas, e incluso las fuentes web, se representan de manera diferente en las tres plataformas: en Windows de acuerdo con un algoritmo, en MacOS de manera diferente, en Linux en general en un zoológico.
No puede simplemente tomar y probar con capturas de pantalla .
Dirá: "Solo necesito una máquina de referencia donde ejecutaré todas estas pruebas y compararé capturas de pantalla". Pero, de hecho, esto es muy inconveniente, ya que debe esperar a CI y desea verificar aquí localmente en su máquina si ha roto algo. Si tiene capturas de pantalla de referencia en una máquina Linux y tiene una Mac, entonces habrá resultados falsos.
Por lo tanto, digo que no pruebes con capturas de pantalla, olvídalo.
Por cierto, si todavía quieres probar con capturas de pantalla, hay un maravilloso artículo de Roman Dvornov, "
Pruebas unitarias con capturas de pantalla: romper la barrera del sonido ". Esto es pura ficción de detectives.
Cerraduras
A muchos proveedores de contenido grande no les gusta cuando raspa o obtiene su contenido de manera ilegal. Imagina que soy un importante proveedor de contenido y quiero jugar el mismo juego contigo. Hay dos solicitudes GET en dos navegadores diferentes.
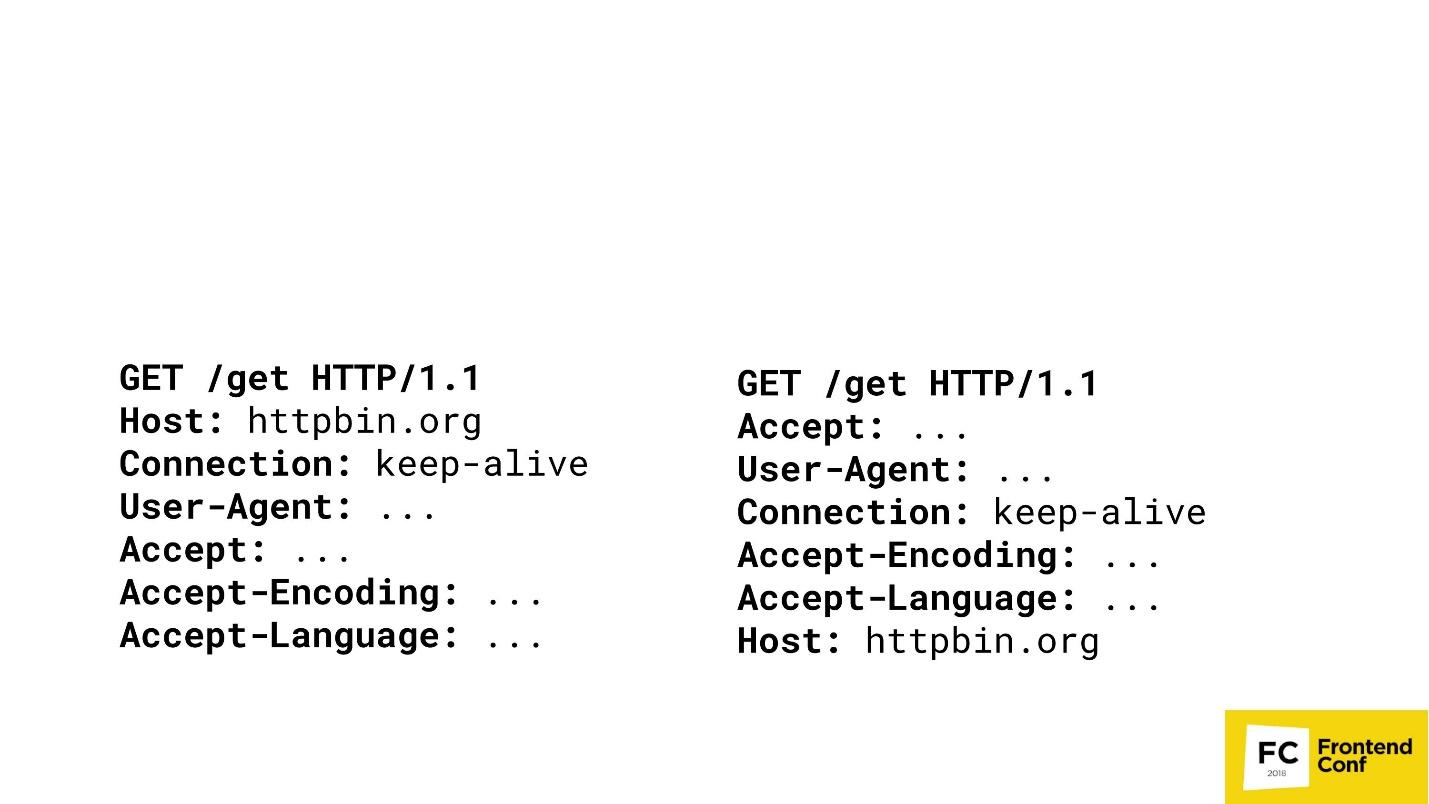
¿Puedes adivinar dónde está Chrome aquí? La opción "ambos" no se acepta: Chrome es solo una. Lo más probable es que no pueda responder esta pregunta, y yo, como proveedor de contenido principal, puedo: a la derecha - PhantomJS, y a la izquierda - Chrome.

Puedo llegar al punto en el que detectaré sus navegadores (qué es exactamente Chrome o Firefox) haciendo coincidir el orden de los encabezados HTTP en sus solicitudes. Si el host va primero, lo sé claramente, este es Chrome. Entonces no puedo comparar. Sí, por supuesto, hay algoritmos más complejos: verificamos no solo el orden, sino también los valores, etc. etc. Pero es importante que pueda emitir sus títulos, verificar quién es usted y luego simplemente bloquearlo o no bloquearlo.
No se pueden implementar algunas funciones (Flash)
¿Alguna vez has estudiado en profundidad, directamente hardcore, Flash en los navegadores? De alguna manera miré, luego no dormí durante seis meses.
Todos recordamos cómo solíamos ver YouTube cuando todavía había Flash: el video gira, todo está bien. Pero en el momento en que se crea un objeto incrustado en una página como Flash, siempre solicita una ventana real de su sistema operativo. Es decir, además de la ventana de su navegador, había otra ventana de su sistema operativo dentro de la ventana Flash de YouTube. Flash no puede funcionar a menos que le dé una ventana real, no solo una ventana real, sino una ventana visible en su pantalla. Por lo tanto, algunas funciones no se pueden implementar en navegadores sin cabeza, incluido Flash.
Automatización completa y bots
Como dije antes, los grandes proveedores de contenido tienen mucho miedo cuando escribes arañas o acaparamientos que simplemente roban información que se proporciona por una tarifa.
Se utilizan varios trucos. Hay artículos sobre cómo detectar navegadores sin cabeza. Puedo decir que
no podrá detectar navegadores sin cabeza . Todos los métodos descritos allí están anulados. Por ejemplo, hubo métodos de detección usando Canvas. Recuerdo que incluso hubo una secuencia de comandos que vio al ratón moverse por la pantalla y llenó el lienzo. Somos personas y movemos el mouse lentamente, y Headless Chrome es mucho más rápido. El script entendió que Canvas se llena demasiado rápido, lo que significa que es muy probable que Chrome no tenga cabeza. También evitamos esto, solo ralentizar el navegador no es un problema.
No hay una API estándar (única)
Si observó implementaciones sin cabeza en otros navegadores, ya sea Safari o Firefox, allí se implementa todo utilizando la API webdriver. Chrome tiene el protocolo Chrome DevTools. En Edge, nada está claro en absoluto: qué hay allí, qué no.
WebGL?
La gente también pide WebGL en modo sin cabeza. Este
enlace le permite acceder al rastreador de errores de Google Chrome. Allí, los desarrolladores votan activamente por la implementación del modo sin cabeza para WebGL, y ya puede dibujar algo. Ahora están simplemente restringidos por el renderizado de hardware. Tan pronto como se complete la implementación del renderizado de hardware, WebGL estará automáticamente disponible, es decir, se puede hacer algo en segundo plano.
¡Pero no todo es tan malo!
Tenemos un segundo jugador en el mercado: el 11 de mayo de 2018 hubo
noticias de que Microsoft en su navegador Edge decidió implementar casi el mismo protocolo que se utiliza en Google Chrome. Crearon especialmente un consorcio donde están discutiendo un protocolo que quieren llevar a un estándar de la industria para que pueda tomar su script y ejecutarlo en Edge, Chrome y FireFox.
Pero hay un "pero": desafortunadamente, Microsoft Edge no tiene un modo sin cabeza. Tienen una boleta de votación donde la gente escribe: "¡Danos un modo sin cabeza!" - Pero están en silencio. Probablemente aserrando algo en secreto.
TODO (conclusión)
Le dije todo esto para que pueda acudir a su gerente o, si es gerente, al desarrollador y decirle: “¡Eso es!
Ya no queremos Selenium, ¡danos Titiritero! Lo probaremos en él ". Si esto sucede, me alegraré.
Pero si puede aprender, como yo, los navegadores que utilizan Puppeteer, publicar errores activamente o enviar una solicitud de extracción, me alegraré aún más. Esta
herramienta en OpenSource se encuentra en GitHub, está escrita en Node.js, puede pedirla prestada y contribuir a ella.
El caso de Puppeteer es único en el sentido de que hay dos equipos trabajando en Google: uno trata específicamente con Puppeteer y el otro con el modo sin cabeza. Si un usuario encuentra un error y escribe sobre él en GitHub, entonces si este error no está en Puppeteer, sino en Headless Chrome, el error va al comando Headless Chrome. Si lo arreglan allí, Puppeteer se actualiza muy rápidamente. Esto da como resultado un único ecosistema cuando la comunidad ayuda a mejorar el navegador.
Por lo tanto, le insto a que ayude a mejorar la herramienta, que no solo utiliza usted, sino también otros desarrolladores y evaluadores.
Datos de contacto:
- github.com/vitallium
- vk.com/vitallium
- twitter.com/vitalliumm
Frontend Conf Moscow : una conferencia especializada de desarrolladores front-end se llevará a cabo los días 4 y 5 de octubre en Moscú , en Infospace. Ya se ha publicado una lista de informes aceptados en el sitio web de la conferencia.
En nuestro boletín hacemos revisiones temáticas de discursos, hablamos de las transcripciones que se han publicado y de los eventos futuros. Regístrese para recibir las noticias primero.
Y este es un enlace a nuestro canal de Youtube en la parte frontal, contiene todos los discursos relacionados con el desarrollo de la parte cliente de los proyectos.