En un
artículo anterior, prometí revelar con más detalle algunos detalles que omití durante la investigación [Gmail se cuelga en Chrome en Windows - aprox. Per.], Incluidas las tablas de páginas, bloqueos, WMI y el error vmmap. Ahora relleno estos huecos junto con ejemplos de código actualizados. Pero primero, describa brevemente la esencia.
El punto era que un proceso que admite
Control Flow Guard (CFG) asigna memoria ejecutable, al tiempo que asigna memoria CFG que Windows nunca libera. Por lo tanto, si continúa asignando y liberando memoria ejecutable
en diferentes direcciones , el proceso acumula una cantidad arbitraria de memoria CFG. El navegador Chrome hace esto, lo que conduce a una pérdida de memoria casi ilimitada y se congela en algunas máquinas.
Cabe señalar que las congelaciones son difíciles de evitar si VirtualAlloc comienza a ejecutarse más de un millón de veces más lento de lo habitual.
Además de CFG, hay otra memoria desperdiciada, aunque no es tanto como afirma vmmap.
CFG y páginas
Tanto la memoria del programa como la memoria CFG se asignan en última instancia con páginas de 4 kilobytes (más sobre esto más adelante). Dado que 4 KB de memoria CFG pueden describir 256 KB de memoria de programa (más sobre eso más adelante), esto significa que si selecciona un bloque de memoria de 256 KB alineado con 256 KB, obtendrá una página CFG de 4 KB. Y si asigna un bloque ejecutable de 4 KB, aún obtendrá una página CFG de 4 KB, pero la mayor parte no se utilizará.
Todo es más complicado si se libera la memoria ejecutable. Si usa la función VirtualFree en un bloque de memoria ejecutable que no es un múltiplo de 256 KB o no está alineado a 256 KB, el sistema operativo debe realizar un análisis y verificar que alguna otra memoria ejecutable no use una página CFG. Los autores de CFG decidieron no molestarse, y simplemente dejar para siempre la memoria CFG asignada. Es muy desafortunado. Esto significa que cuando mi programa de prueba asigna y luego libera 1 gigabyte de memoria ejecutable alineada, deja 16 MB de memoria CFG.
En la práctica, resulta que cuando el motor JavaScript de Chrome asigna y luego libera 128 MB de memoria ejecutable alineada (no se usó todo, pero se asignó todo el rango y se liberó de inmediato), entonces permanecerán asignados hasta 2 MB de memoria CFG, aunque es trivial liberarlo por completo . Dado que Chrome asigna y libera memoria repetidamente en direcciones aleatorias, esto lleva al problema descrito anteriormente.
Memoria perdida adicional
En cualquier sistema operativo moderno, cada proceso obtiene su propio espacio de direcciones de memoria virtual, de modo que el sistema operativo aísla los procesos y protege la memoria. Esto se hace usando
una unidad de administración de memoria (MMU) y
tablas de páginas . La memoria está dividida en páginas de 4 KB. Esta es la cantidad mínima de memoria que le proporciona el sistema operativo. Cada página se indica mediante un registro de ocho bytes en la tabla de páginas, y los registros mismos se almacenan en páginas de 4 KB. Cada uno de ellos apunta a un máximo de 512 páginas diferentes de memoria, por lo que necesitamos una jerarquía de tablas de páginas. Para un espacio de direcciones de 48 bits en un sistema operativo de 64 bits, el sistema es el siguiente:
- Una tabla de Nivel 1 cubre 256 TB (48 bits), apuntando a 512 tablas de nivel 2 de página diferentes
- Cada tabla de nivel 2 cubre 512 GB, apuntando a 512 tablas de nivel 3
- Cada tabla de nivel 3 cubre 1 GB, apuntando a 512 tablas de nivel 4
- Cada tabla de nivel 4 abarca 2 MB, apuntando a 512 páginas físicas
MMU indexa la tabla del primer nivel en los primeros 9 (de 48) bits de la dirección, las tablas del segundo nivel en los siguientes 9 bits, y los niveles restantes reciben 9 bits, es decir, solo 36 bits. Los 12 bits restantes se usan para indexar páginas de 4 kilobytes de una tabla de 4to nivel. Bien bien
Si llena inmediatamente todos los niveles de las tablas, necesitará más de 512 GB de RAM, de modo que se llenen según sea necesario. Esto significa que al asignar una página de memoria, el sistema operativo selecciona algunas tablas de páginas, de cero a tres, dependiendo de si las direcciones asignadas están en un área no utilizada anteriormente de 2 MB, un área no utilizada previamente de 1 GB o un área previamente no utilizada de 512 GB (tabla de páginas de nivel 1 siempre se destaca).
En resumen, la asignación a direcciones aleatorias es mucho más costosa que la asignación a direcciones cercanas, ya que en el primer caso las tablas de páginas no se pueden compartir. Las fugas de CFG son raras, por lo que cuando
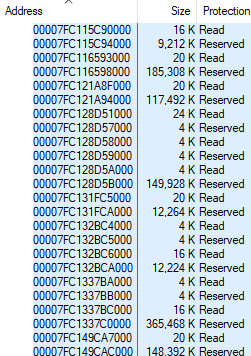
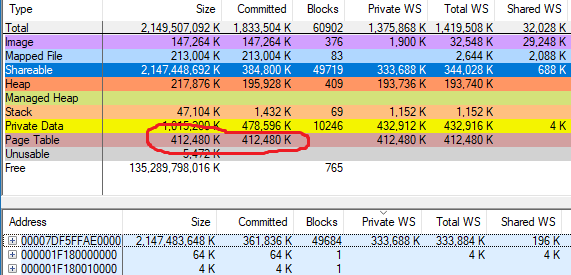
vmmap mostró
412,480 KB de tablas de páginas usadas en Chrome, supuse que los números eran correctos. Aquí hay una captura de pantalla de vmmap con el diseño de memoria chrome.exe del artículo anterior, pero con la línea de tabla de páginas:
Pero algo parecía mal. Decidí agregar un simulador de tabla de páginas a mi herramienta
VirtualScan . Calcula cuántas páginas de tablas de páginas se necesitan para toda la memoria asignada durante el proceso de escaneo. Solo necesita escanear la memoria asignada, agregando al contador uno cada número múltiple de 2 MB, 1 GB o 512 GB.
Se descubrió rápidamente que los resultados del simulador corresponden a vmmap en procesos normales, pero no en procesos con una gran cantidad de memoria CFG. La diferencia corresponde aproximadamente a la memoria CFG asignada. Para el proceso anterior, donde vmmap habla de 402.8 MB (412,480 KB) de tablas de páginas, mi herramienta muestra 67.7 MB.
Tiempo de escaneo, comprometido, tablas de páginas, bloques comprometidos
Total: 41.763s, 1457.7 MiB, 67.7 MiB, 32112, 98 bloques de código
CFG: 41.759s, 353.3 MiB, 59.2 MiB, 24866
Me aseguré del error vmmap ejecutando
VAllocStress , que en la configuración predeterminada hace que Windows asigne 2 gigabytes de memoria CFG. vmmap afirmó haber asignado 2 gigabytes de tablas de páginas:
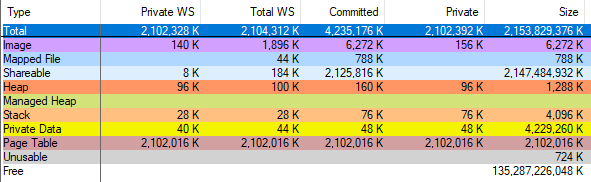
Y cuando completé el proceso a través del Administrador de tareas, vmmap mostró que la cantidad de memoria asignada disminuyó en solo 2 gigabytes. Entonces, vmmap está mal, mis cálculos con las tablas de páginas son correctos, y después de una fructífera
discusión en Twitter, envié un informe sobre el error de vmmap, que debería corregirse. La memoria CFG todavía consume muchas entradas de la tabla de páginas (59.2 MB en el ejemplo anterior), pero no tanto como dice vmmap, y después de solucionarlo no consumirá nada.
¿Qué es CFG y CFG?
Quiero dar un paso atrás y decir con más detalle qué es CFG.
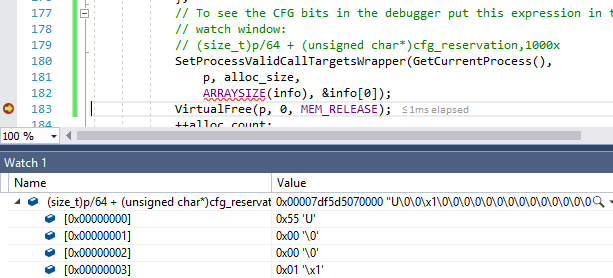
CFG significa Control Flow Guard. Este es un método de protección contra exploits reescribiendo punteros de función. Con CFG habilitado, el compilador y el sistema operativo juntos comprueban la validez del objetivo de la rama. Primero, el byte de control CFG correspondiente se carga desde el área CFG reservada de 2 TB. El proceso de 64 bits en Windows administra el espacio de direcciones de 128 TB, por lo que dividir la dirección por 64 le permite encontrar el byte CFG correspondiente para este objeto.
uint8_t cfg_byte = cfg_base[size_t(target_addr) / 64];Ahora tenemos un byte que debe describir qué direcciones en el rango de 64 bytes son destinos de rama válidos. Para hacer esto, el CFG trata el byte como cuatro valores de dos bits, cada uno de los cuales corresponde a un rango de 16 bytes. Este número de dos bits (cuyo valor es de cero a tres) se
interpreta de la siguiente manera :
- 0: todos los objetivos en este bloque de 16 bytes son objetivos no válidos de ramas indirectas
- 1 - la dirección de inicio en este bloque de 16 bytes es el objetivo válido de la rama indirecta
- 2 - asociado con llamadas CFG "suprimidas" ; la dirección es potencialmente inválida
- 3 - las direcciones no alineadas en este bloque de 16 bytes son objetivos válidos de una rama indirecta, sin embargo, una dirección alineada de 16 bytes es potencialmente inválida
Si el objetivo de la rama indirecta no es válido, el proceso finaliza y se evita la explotación. ¡Hurra!
De esto podemos concluir que para una seguridad máxima, los objetivos indirectos de la rama deben estar alineados en 16 bytes, y podemos entender por qué la memoria CFG para el proceso es aproximadamente 1/64 de la memoria del programa.
En realidad, CFG carga 32 bits a la vez, pero estos son detalles de implementación. Muchas fuentes describen la memoria CFG como un bit de 8 bytes en lugar de doble bit de 16 bytes. Mi explicación es mejor.
Por eso todo es malo
Gmail se cuelga por dos razones. Primero, escanear la memoria CFG en Windows 10 16299 o anterior es extremadamente lento. Vi cómo escanear el espacio de direcciones de un proceso lleva 40 segundos o más, y literalmente el 99,99% de este tiempo se escanea la memoria CFG reservada, aunque solo representa aproximadamente el 75% de los bloques de memoria fijos. No sé por qué el escaneo fue tan lento, pero lo arreglaron en Windows 10 17134, por lo que no tiene sentido estudiar el problema con más detalle.
El escaneo lento provocó una desaceleración porque Gmail quería redundancia CFG, y WMI mantuvo el bloqueo mientras duró el escaneo. Pero el bloqueo de reserva de memoria no se mantuvo durante todo el escaneo. En mi ejemplo, hay aproximadamente 49,000 bloques en el área de CFG, y la función
NtQueryVirtualMemory , que recibe y libera el bloqueo, se llamó una vez para cada uno de ellos. Por lo tanto, el bloqueo se obtuvo y liberó ~ 49,000 veces y cada vez se mantuvo durante menos de 1 milisegundo.
Pero aunque el bloqueo se liberó 49,000 veces, el proceso de Chrome por alguna razón no pudo obtenerlo. Esto es injusto!
Esa es la esencia del problema. Como escribí la última vez:
Esto se debe a que los bloqueos de Windows son inherentemente injustos , y si el subproceso libera el bloqueo y luego lo solicita de inmediato, puede obtenerlo para siempre.
El bloqueo equitativo significa que dos hilos competidores lo recibirán a su vez. Pero esto significa muchos cambios de contexto caros, por lo que durante mucho tiempo no se usará el bloqueo.

Los bloqueos injustos son más baratos y no hacen que los hilos esperen en línea. Simplemente capturan la cerradura, como se menciona en
el artículo de Joe Duffy . Él también escribe:
La introducción de cerraduras injustas puede indudablemente provocar hambre. Pero estadísticamente, el tiempo en sistemas paralelos tiende a ser tan variable que cada hilo recibirá un turno para su ejecución, desde un punto de vista probabilístico.
¿Cómo correlacionar la declaración de Joe de 2006 sobre la rareza del hambre con mi experiencia en un problema 100% repetible y duradero? Creo que la razón principal es lo que sucedió en 2006. Intel
lanzó Core Duo , y las computadoras multinúcleo son ubicuas.
Después de todo, ¡resulta que este problema de hambre ocurre solo en un sistema de múltiples núcleos! En dicho sistema, el hilo WMI liberará el bloqueo, le indicará al hilo Chrome que se active y continúe. Dado que la transmisión WMI ya se está ejecutando, tiene una "desventaja" frente a la transmisión de Chrome, por lo que puede llamar fácilmente a
NtQueryVirtualMemory nuevamente y recuperar el bloqueo nuevamente antes de que Chrome tenga la oportunidad de hacerlo.
Obviamente, en un sistema de un solo núcleo, solo un hilo puede funcionar a la vez. Como regla general, Windows aumenta la prioridad de un nuevo subproceso, y aumentar la prioridad significa que cuando se libere el bloqueo, el nuevo subproceso de Chrome estará listo e inmediatamente
antes del subproceso de WMI. Esto le da al hilo de Chrome mucho tiempo para despertarse y obtener un bloqueo, y el hambre nunca llega.
¿Entiendes? En un sistema multinúcleo, un aumento de prioridad en la mayoría de los casos no afecta la transmisión WMI, ya que se ejecutará en un núcleo diferente.
Esto significa que un sistema con núcleos adicionales puede
responder más lentamente que un sistema con la misma carga de trabajo y menos núcleos. Otra conclusión es curiosa: si mi computadora tuviera una carga pesada (hilos de la prioridad correspondiente, trabajando en todos los núcleos del procesador), entonces podrían evitarse los bloqueos (no intente repetir esto en casa).
Por lo tanto,
las cerraduras injustas aumentan la productividad, pero pueden provocar hambre. Sospecho que la solución puede ser lo que yo llamo cerraduras "a veces justas". Digamos, el 99% de las veces serán injustas, pero en el 1% dará el bloqueo a otro proceso. Esto preservará los beneficios de la productividad con más, evitando el problema del hambre. Anteriormente, los bloqueos en Windows se distribuían de manera justa y probablemente puede volver parcialmente a esto, encontrando el equilibrio perfecto. Descargo de responsabilidad: no soy un experto en bloqueos o un ingeniero de sistemas operativos, pero estoy interesado en escuchar ideas al respecto, y al menos no soy
el primero en ofrecer algo así .
Linus Torvalds recientemente apreció la importancia de las cerraduras justas:
aquí y
aquí . Tal vez es hora de un cambio en Windows también.
Para resumir : bloquear durante unos segundos no es bueno, limita la concurrencia. Pero en los sistemas multinúcleo con bloqueos injustos, la eliminación y la recepción inmediata del bloqueo nuevamente se comporta
exactamente así : otros hilos no tienen forma de funcionar.
Casi un fracaso con ETW
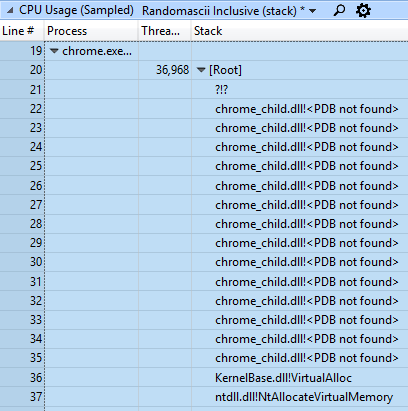
Para toda esta investigación, confié en el rastreo de ETW, por lo que me asusté un poco cuando, al comienzo de la investigación, resultó que Windows Performance Analyzer (WPA) no podía cargar los caracteres de Chrome. Estoy seguro de que, literalmente, la semana pasada todo funcionó. Que paso ...
Sucedió que Chrome M68 salió, y se vinculó usando lld-link en lugar del enlazador VC ++. Si ejecuta
dumpbin y mira la información de depuración, verá:
C:\b\c\b\win64_clang\src\out\Release_x64\./initialexe/chrome.exe.pdbBueno, probablemente a WPA no le gusten estas barras. Pero todavía no tiene sentido, porque cambié el enlazador a lld-link, y recuerdo que probé WPA antes de eso, entonces, ¿qué pasó ...
Resultó que la razón estaba en la nueva versión WPA 17134. Probé el diseño de lld-Link, y funcionó bien en WPA 16299. ¡Qué coincidencia! El nuevo vinculador y el nuevo WPA no eran compatibles.
Instalé la versión anterior de WPA para continuar con la investigación (xcopy desde una máquina con la versión anterior) e informé de un
error de lld-link , que los desarrolladores solucionaron rápidamente. Ahora puede volver a WPA 17134 cuando el M69 se ensambla con un enlazador fijo.
Wmi
El activador de congelación de WMI es un
complemento de Instrumental de administración de Windows , y no soy bueno en eso. Descubrí que en
2014 o antes, alguien se encontró con el problema del uso significativo de la CPU en
WmiPrvSE.exe dentro de
perfproc! GetProcessVaData , pero no proporcionaron suficiente información para comprender las causas del error. En algún momento, cometí un error y traté de averiguar qué una loca solicitud de WMI podría colgar a Gmail durante unos segundos. Conecté a
algunos expertos con la investigación y pasé mucho tiempo tratando de encontrar esta consulta mágica. Grabé la actividad de
Microsoft-Windows-WMI-Activity en trazas ETW, experimenté con PowerShell para encontrar todas las consultas Win32_Perf, y me perdí en algunas formas más indirectas que son demasiado aburridas para discutir. Al final, descubrí que un bloqueo de Gmail causó este contador,
Win32_PerfRawData_PerfProc_ProcessAddressSpace_Costly , desencadenado por un PowerShell de una sola línea:
measure-command {Get-WmiObject -Query “SELECT * FROM Win32_PerfFormattedData_PerfProc_ProcessAddressSpace_Costly”}
Luego me confundí
aún más por el nombre del contador (¿"querido"? ¿En serio?) Y porque este contador aparece y desaparece en función de factores que no entiendo.
Pero los detalles de WMI no importan. WMI no hizo nada malo, no realmente, simplemente escaneó la memoria. Escribir su propio código de escaneo resultó ser mucho más útil para investigar el problema.
Problemas para Microsoft
Chrome ha lanzado un parche, el resto es para Microsoft.
Acelere el escaneo de la región CFG - OK, ya está- Libere memoria CFG cuando se libere memoria ejecutable; al menos en el caso de una alineación de 256K, es fácil
- Considere una marca que permita asignar memoria ejecutable sin memoria CFG, o use PAGE_TARGETS_INVALID para este propósito. Tenga en cuenta que el manual de Windows Internals Part 1 7th Edition dice que "debe seleccionar páginas [CFG] con al menos un conjunto de bits {1, X}" - si Windows 10 implementa esto, entonces el indicador PAGE_TARGETS_INVALID (que actualmente utiliza el motor v8 ) evitará la asignación de memoria
- Se corrigió el cálculo de las tablas de páginas en vmmap para procesos con una gran cantidad de asignaciones de CFG
Actualizaciones de código
Actualicé los
ejemplos de código , especialmente VAllocStress. Se incluyen 20 líneas para demostrar cómo encontrar una reserva de CFG para un proceso. También agregué un código de prueba que usa
SetProcessValidCallTargets para verificar el valor de los bits CFG y demostrar los trucos necesarios para llamarlos con éxito (sugerencia: ¡llamar a través de GetProcAddress es probable que viole los CFG!)