Hola colegas
Acabamos de traducir un libro interesante de Brendan Burns, que habla sobre patrones de diseño para sistemas distribuidos

Además, la traducción del libro "
Mastering Kubernetes " (2ª edición) ya está en su apogeo y el libro del autor sobre Docker está a punto de ser publicado en septiembre, y habrá una publicación separada al respecto.
Creemos que la próxima parada en este camino es un libro sobre Prometeo, por lo que hoy traemos a su atención una traducción de un breve artículo de Björn Wenzel sobre la estrecha interacción entre Prometeo y Kubernetes. Por favor recuerde participar en la encuesta.
Monitorear el clúster de Kubernetes es un negocio muy importante. El clúster contiene una tonelada de información que le permite responder preguntas de la categoría: ¿cuánta memoria y espacio en disco hay disponible ahora, cómo se usa activamente la CPU? ¿Qué contenedor consume cuántos recursos? Esto también incluye preguntas sobre el estado de las aplicaciones que se ejecutan en el clúster.
Una de las herramientas para tal trabajo se llama Prometeo. Es compatible con la Cloud Native Computing Foundation, originalmente Prometheus fue desarrollado por SoundCloud. Conceptualmente, Prometeo es muy simple:
Arquitectura
El servidor Prometheus puede funcionar, por ejemplo, en un clúster de Kubernetes y recibir la configuración a través de un archivo especial. Esta configuración, en particular, contiene información acerca de dónde se encuentra el terminal para recopilar datos después del intervalo especificado. Luego, el servidor Prometheus solicita métricas de estos terminales en un formato especial (generalmente están disponibles en
/metrics ) y las almacena en una base de datos de series de tiempo. El siguiente es un breve ejemplo: un pequeño archivo de configuración que solicita métricas de un módulo
node_exporter implementado como agente en cada nodo:
scrape_configs: - job_name: "node_exporter" scrape_interval: "15s" target_groups: - targets: ['<ip>:9100']
Primero definimos el nombre del trabajo
job_name , luego este nombre se puede usar para solicitar métricas en Prometheus, luego el
scrape_interval datos de
scrape_interval y un grupo de servidores que ejecutan
node_exporter . Ahora Prometheus le preguntará al servidor cada 15 segundos la
path /metrics de las métricas actuales. Se parece a esto:
Primero, se proporciona el nombre de la métrica, luego la firma (información entre llaves) y, finalmente, el valor de la métrica. Lo más interesante es la función de búsqueda de estas métricas. Prometheus tiene un
lenguaje de consulta muy poderoso para este propósito.
La idea principal de Prometheus, ya descrita anteriormente, es esta: Prometheus en un intervalo dado sondea el puerto en busca de métricas y las almacena en una base de datos de series de tiempo. Si Prometheus no puede eliminar las métricas en sí, entonces hay otra funcionalidad llamada pushgateway. La puerta de enlace pushgateway acepta métricas enviadas por trabajos externos, y Prometheus recopila información de esta puerta de enlace en un intervalo especificado.
Otro componente opcional de la arquitectura Prometheus es el
alertmanager . El componente
alertmanager permite establecer límites y, en caso de excederlos, enviar notificaciones por correo electrónico, holgura u opsgenie.
Además, el servidor Prometheus contiene muchas
características integradas , por ejemplo, puede solicitar instancias ec2 en la API de Amazon o solicitar pods, nodos y servicios de Kubernetes. También tiene muchos
exportadores , por ejemplo, el
node_exporter mencionado
node_exporter . Dichos exportadores pueden trabajar, por ejemplo, en el nodo donde está instalada una aplicación como MySQL y en un intervalo determinado para sondear la aplicación en busca de métricas y proporcionarlas en el terminal / métricas, y el servidor Prometheus puede recopilar estas métricas desde allí.
Además, no es difícil escribir su propio exportador, por ejemplo, para una aplicación que proporciona métricas como información jvm. Existe, por ejemplo, una
biblioteca desarrollada por Prometheus para exportar tales métricas. Esta biblioteca se puede usar junto con Spring, y también le permite definir sus propias métricas. Aquí hay un ejemplo de la página
client_java :
@Controller public class MyController { @RequestMapping("/") @PrometheusTimeMethod(name = "my_controller_path_duration_seconds", help = "Some helpful info here") public Object handleMain() {
Esta es una métrica que describe la duración del método, y ahora se pueden proporcionar otras métricas a través del terminal o empujadas a través de la puerta de acceso.
Uso en Kubernetes Cluster
Como mencioné, para usar Prometheus en el clúster de Kubernetes hay capacidades integradas para eliminar información del hogar, el nodo y el servicio. Lo más interesante es que Kubernetes está especialmente diseñado para trabajar con Prometeo. Por ejemplo,
kubelet y
kube-apiserver proporcionan métricas
kube-apiserver en Prometheus, por lo que el monitoreo es muy simple.
En este ejemplo, para empezar, uso el gráfico oficial de timón.
Por mi parte, cambié un poco la configuración del gráfico de timón predeterminado. En primer lugar, necesitaba activar
rbac en la instalación de Prometheus, de lo contrario, Prometheus no pudo recopilar información de
kube-apiserver . Por lo tanto, escribí mi propio archivo values.yaml, que describe cómo se debe mostrar el gráfico de timón.
Hice los cambios más simples:
alertmanager.enabled: false , es decir, canceló la implementación de alertmanager en el clúster (no iba a usar alertmanager, creo que es más fácil configurar alertas con Grafana)kubeStateMetrics.enabled: false Creo que estas métricas solo devuelven cierta información sobre el número máximo de hogares. Cuando inicia el sistema por primera vez, esta información no es importante para mí.server.persistentVolume.enabled: false hasta que tenga un volumen persistente configurado de forma predeterminada- Cambié la configuración de la recopilación de información en Prometheus, como se hizo en la solicitud de extracción en github . El hecho es que en Kubernetes v1.7, las métricas de cAdvisor funcionan en un puerto diferente.
Después de eso, puedes iniciar Prometheus usando helm:
helm install stable/prometheus --name prometheus-monitoring -f prometheus-values.yamlEntonces instalamos el servidor Prometheus y, en cada nodo, lo instalamos en node_exporter. Ahora puede ir a la GUI web de Prometheus y ver información:
kubectl port-forward <prometheus-server-pod> 9090La siguiente captura de pantalla muestra para qué fines Prometheus recopila información (Estado / objetivos), y cuándo se disparó la información varias veces en el último:
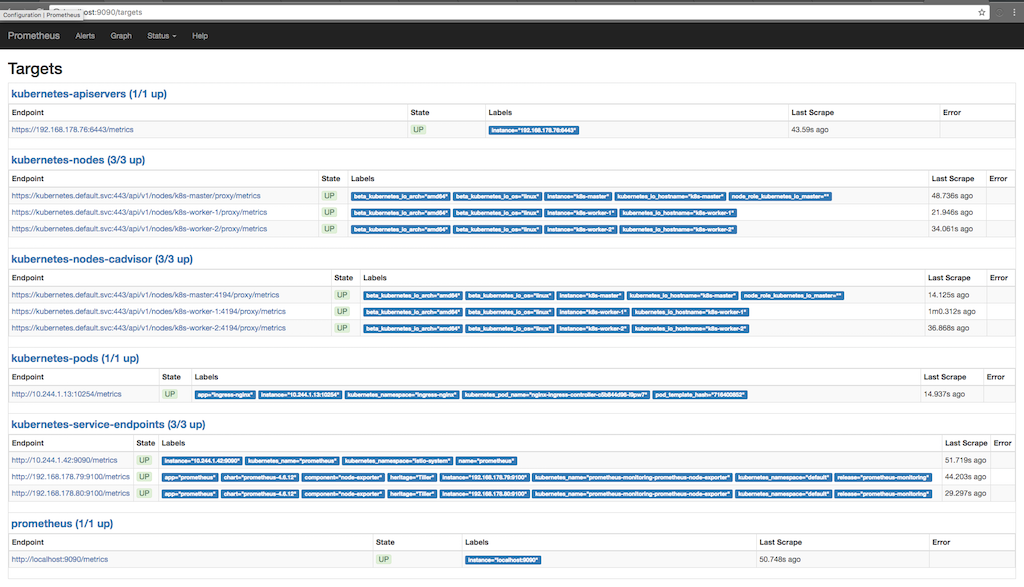
Aquí puede ver cómo Prometheus solicita métricas de un servidor, nodos, un asesor que se ejecuta en nodos y puntos finales de servicio kubernetes. Puede ver las métricas en detalle yendo a Graph y escribiendo una consulta para ver la información que nos interesa:

Aquí, por ejemplo, vemos almacenamiento gratuito en el punto de montaje "/". En la parte inferior del diagrama, se agregan firmas que Prometheus agrega o que ya están disponibles en node_exporter. Utilizamos estas firmas para solicitar solo el punto de montaje "/".
Métricas personalizadas con anotaciones
Como ya se mostró en la primera captura de pantalla, donde se derivan los objetivos para los que Prometheus solicita métricas, también hay una métrica para el hogar que funciona en el clúster. Una de las buenas características de Prometheus es la capacidad de tomar información de hogares enteros. Si el contenedor en el hogar proporciona métricas de Prometheus, entonces podemos recopilar estas métricas usando Prometheus automáticamente. Lo único que debemos cuidar es proporcionar a la instalación dos anotaciones; en mi caso,
nginx-ingress-controller hace esto fuera de la caja:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-ingress-controller namespace: ingress-nginx spec: replicas: 1 selector: matchLabels: app: ingress-nginx template: metadata: labels: app: ingress-nginx annotations: prometheus.io/port: '10254' prometheus.io/scrape: 'true' ...
Aquí vemos que la plantilla de implementación viene con dos anotaciones de Prometheus. El primero describe el puerto a través del cual Prometheus debería solicitar métricas, y el segundo activa la funcionalidad de recopilación de datos. Ahora, Prometheus solicita los
Kubernetes Api-Server anotados para recopilar información e intenta recopilar información del terminal / métrica.
Trabajo federado
Tenemos un proyecto en el que Prometheus se usa en modo federado. La idea es esta: recopilamos solo la información a la que solo se puede acceder desde el clúster (o es más fácil recopilar esta información desde el clúster), habilitamos el modo federado y obtenemos esta información utilizando el segundo Prometheus instalado fuera del clúster. Por lo tanto, es posible recopilar información de varios grupos de Kubernetes a la vez, capturando también otros componentes a los que no se puede acceder desde este grupo o que no están relacionados con este grupo. Además, no es necesario almacenar los datos recopilados en el clúster durante mucho tiempo, y si algo sale mal con el clúster, podemos recopilar información, por ejemplo, node_exporter, desde fuera del clúster.