Hola Habr! Hoy quiero hablar sobre cómo el aprendizaje profundo nos ayuda a comprender mejor el arte. El artículo está dividido en partes de acuerdo con las tareas que resolvimos:
- buscar una imagen en la base de datos de una fotografía tomada por un teléfono móvil;
- determinación del estilo y género de una imagen que no está en la base de datos.
Todo esto se convertiría en parte del servicio de base de datos Arthive y sus aplicaciones móviles.
La tarea de identificar las pinturas era encontrar la imagen correspondiente de la imagen proveniente de la aplicación móvil en la base de datos, gastando menos de un segundo en esto. El procesamiento completo en el dispositivo móvil se excluyó en la etapa de estudio previo al diseño. Además, resultó que es imposible realizar con seguridad en un dispositivo móvil la separación de la imagen del fondo en condiciones reales de disparo. Por lo tanto, decidimos que nuestro servicio aceptará la foto completa del teléfono móvil como entrada, con todas las distorsiones, ruidos y posibles solapamientos parciales.

¿Ayudaremos a Dasha a encontrar estas pinturas en una base de datos de más de 200,000 imágenes?
La base de arte de Arthive incluye casi 250,000 imágenes, junto con varios metadatos. La base se actualiza constantemente, de decenas a cientos de imágenes por día. Incluso bombeado con una resolución limitada (no más de 1400 píxeles en la mayoría de los lados), las imágenes ocupan más de 80 gigabytes. Desafortunadamente, la base de datos está "sucia": hay archivos rotos o demasiado pequeños, imágenes sin alinear y sin procesar, imágenes duplicadas. Sin embargo, en general, estos son buenos datos.
Comparación de pinturas
Veamos cómo se ven las imágenes en la base de datos:
Básicamente, las imágenes en la base de datos están alineadas, recortadas a los bordes del lienzo, los colores se conservan.
Y así es como se verían las solicitudes de dispositivos móviles:

Los colores casi siempre están distorsionados: se encuentra iluminación compleja, deslumbramiento, incluso se encuentran reflejos de otras pinturas en el vidrio. Las imágenes en sí mismas están distorsionadas en perspectiva, se pueden recortar parcialmente o, por el contrario, ocupan menos de la mitad de la imagen, se pueden cerrar parcialmente, por ejemplo, las personas.
Para identificar imágenes, debe poder comparar imágenes de consultas con imágenes en la base de datos.
Para comparar imágenes propensas a la distorsión de perspectiva y distorsión de color, utilizamos la coincidencia de puntos clave. Para hacer esto, encontramos puntos clave con descriptores en las imágenes, buscamos su correspondencia y luego mostramos homogéneamente los puntos correspondientes utilizando el método RANSAC. Esto generalmente se hace de la misma manera que se describe en el ejemplo de OpenCV . Si el número de puntos "internos" encontrados por RANSAC es lo suficientemente grande, y la transformación homográfica encontrada parece plausible (no tiene fuertes escalas o rotaciones), entonces podemos suponer que las imágenes deseadas son una y la misma imagen sujeta a distorsiones de perspectiva .
Un ejemplo de mapeo de puntos clave:

Ejemplo de coincidencia negativa Comparación de pinturas del ejemplo anterior. Por supuesto, la búsqueda de puntos clave suele ser un proceso bastante lento, pero para buscar en la base de datos puede encontrar los puntos clave de todas las imágenes por adelantado y guardar algunas. En nuestros experimentos, llegamos a la conclusión de que menos de 1000 puntos son suficientes para una búsqueda confiable de pinturas. Cuando se usan 64 bytes por punto (coordenadas + descriptor AKAZE) para almacenar 1024 puntos, 64 kbytes por imagen o aproximadamente 15 GB por base son suficientes.
La comparación de imágenes por puntos clave en nuestro caso tomó aproximadamente 15 ms, es decir, para una enumeración completa de una base de datos de 250,000 imágenes, se tarda aproximadamente 1 hora. Esto es mucho
Por otro lado, si aprendemos a seleccionar rápidamente de la base de datos completa varios (por ejemplo, 100) de los candidatos más probables, alcanzaremos el tiempo objetivo de 1 segundo por solicitud.
Clasificación de similitud
Las redes de convolución profunda se han establecido como una buena forma de buscar imágenes similares. La red se utiliza para extraer características y calcular sobre la base de un descriptor que tiene la propiedad de que la distancia (Euclidiana, coseno u otra) entre los descriptores de imágenes similares será menor que para imágenes diferentes.
Puede entrenar la red de tal manera que para la imagen de la imagen desde la base y su imagen distorsionada de la foto, produzca descriptores cercanos y para diferentes imágenes, más distantes. Además, dicha red se utiliza para calcular descriptores de todas las imágenes en la base de datos y descriptores de fotos en las solicitudes. Puede seleccionar rápidamente las imágenes más cercanas y organizarlas según la distancia entre los descriptores.
La forma básica de entrenar una red para calcular un descriptor es usar una red siamesa.
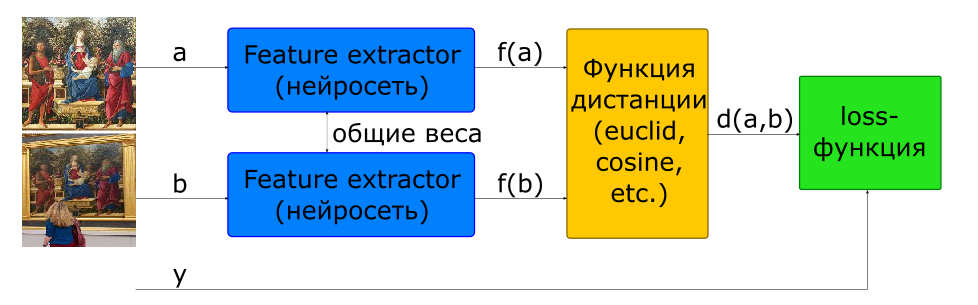
- imágenes de entrada
si y - una clase si es diferente
- descriptores de imagen
- distancia entre un par de vectores de características
- función objetivo
Para construir dicha arquitectura, una red que calcula un descriptor (Feature Extractor) se usa en el modelo 2 veces con pesos comunes. Se alimentan un par de imágenes a la entrada de red. La red del Extractor de características calcula los descriptores de imagen, luego la red calcula la distancia de acuerdo con la métrica especificada (generalmente se usa la distancia euclidiana o cosenoidal). La función objetivo del entrenamiento en red se construye de tal manera que para pares positivos (imágenes de una imagen) la distancia disminuye, y para negativos (imágenes de diferentes imágenes) aumenta. Para reducir la influencia de los pares negativos, la distancia entre ellos está limitada por el valor del margen.
Por lo tanto, podemos decir que en el proceso de aprendizaje, la red busca calcular descriptores de imágenes similares dentro de una hiperesfera con un radio de margen, y descriptores de diferentes, para salir de esta esfera.
Por ejemplo, esto podría verse como entrenar un descriptor bidimensional utilizando la red siamesa en el conjunto de datos MNIST.
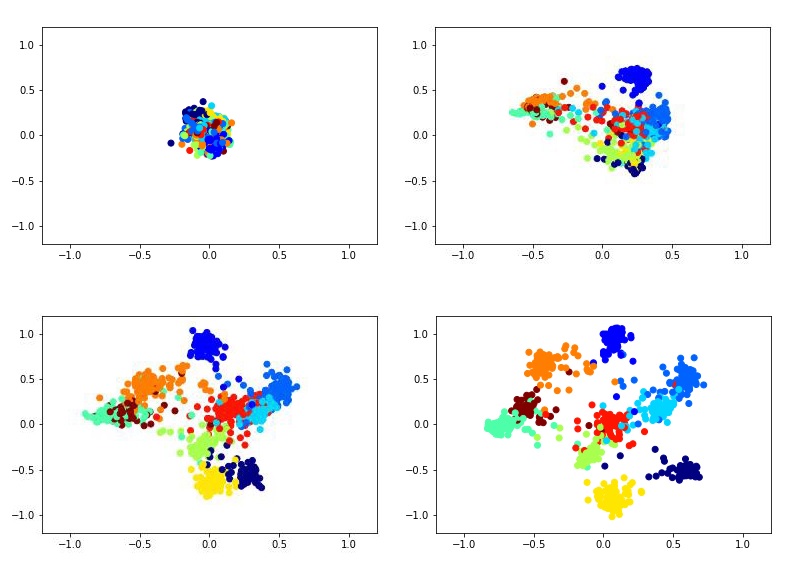
Animación de entrenamiento Para entrenar a la red siamesa, debe ingresar pares de imágenes y una etiqueta que sea igual a 1 si las imágenes pertenecen a la misma clase, o 0 si es diferente. Existe el problema de elegir la proporción de pares positivos y negativos. Idealmente, por supuesto, sería necesario enviar a la red de entrenamiento todas las combinaciones posibles de pares del conjunto de entrenamiento, pero esto es técnicamente imposible. Y la cantidad de pares negativos en este caso excede significativamente la cantidad de pares positivos, lo que tampoco tendrá un efecto muy bueno en el proceso de aprendizaje.
Parte del problema con la elección de la proporción de parejas para el entrenamiento se resuelve utilizando la arquitectura triplete.
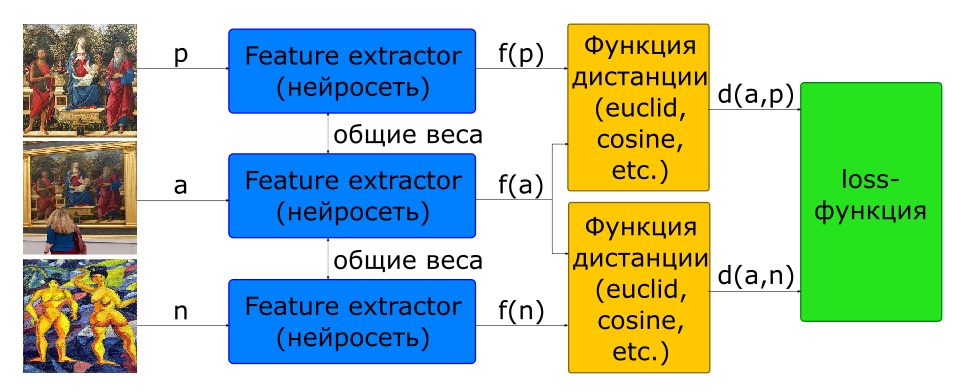
- imágenes de entrada: - una foto, - otro
- función objetivo
A la entrada de dicha red, se forman 3 imágenes de inmediato, formando un par positivo y negativo.
Además, casi todos los investigadores están de acuerdo en que la elección de pares negativos es crítica para el aprendizaje en red. La función objetivo para muchas muestras (pares para siameses, triples para triplete) resulta ser 0, si no violan la restricción de margen, por lo tanto, tales muestras no participan en el entrenamiento de la red. Con el tiempo, el proceso de aprendizaje se ralentiza aún más, ya que hay cada vez menos muestras con un valor distinto de cero de la función objetivo. Para resolver este problema, los pares negativos se eligen no por casualidad, sino buscando minería de casos difíciles. En la práctica, se seleccionan varios candidatos negativos para esto, para cada uno de los cuales se calcula un descriptor utilizando la última versión de los pesos de la red (de una era anterior o incluso de la actual). Al tener un descriptor, puede seleccionar un negativo en cada tres, de modo que se produzca una pérdida no nula conocida.
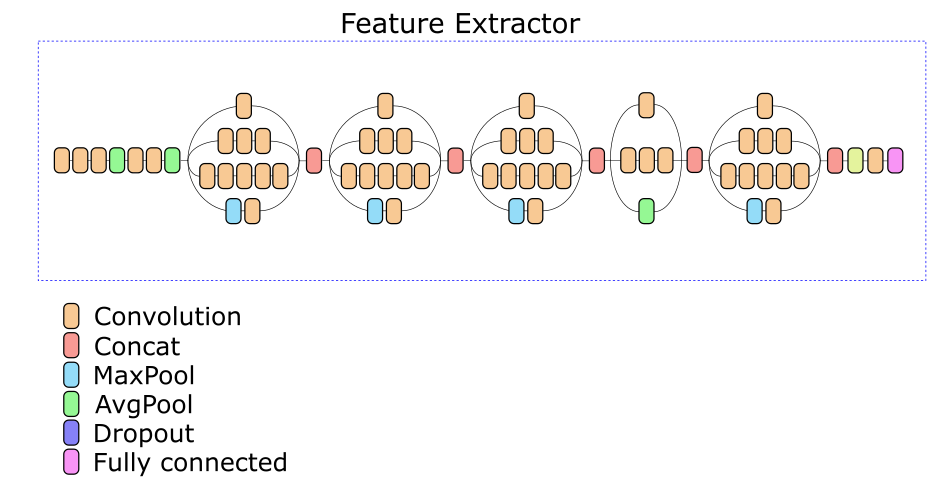
Para buscar imágenes similares, Feature Extractor se separa de la red y se usa para calcular descriptores. Para las imágenes en la base de datos, los descriptores se calculan por adelantado cuando se agregan. Por lo tanto, la tarea de encontrar imágenes similares es calcular el descriptor de imagen en la consulta y buscar los descriptores más cercanos a la métrica dada en la base de datos.
Nuestro Network Feature Extractor se basa en la arquitectura Inception v3. Una de las capas intermedias se seleccionó experimentalmente, en función de la salida de la cual se calcula un descriptor de 512 números reales.
Aumento de datos
Sería bueno si pudiéramos poner cada imagen en diferentes marcos, en diferentes paredes y tomar fotos cada vez desde un ángulo diferente en diferentes teléfonos. En la práctica, esto, por supuesto, es imposible. Por lo tanto, es necesario generar datos de entrenamiento.
Para generar datos, se recogieron alrededor de 500 fotografías de varias pinturas con diferentes fondos en diferentes condiciones de iluminación. Para cada foto, se seleccionaron 4 puntos correspondientes a las esquinas del lienzo de la imagen. Por cuatro puntos, podemos ajustar arbitrariamente cualquier imagen en el marco, reemplazando así la imagen y obteniendo una distorsión de perspectiva casi aleatoria de la imagen de la base de datos. Complementando este proceso con recorte aleatorio, ruido y distorsión de color, tenemos la oportunidad de generar imágenes completamente adecuadas que imitan fotografías de pinturas.

Separación de una imagen de un fondo.
La calidad del trabajo y los modelos para identificar pinturas, y modelos para clasificar géneros / estilos, dependen en gran medida de qué tan bien se separe la imagen del fondo. Idealmente, antes de alimentar una imagen en un modelo, debe encontrar las 4 esquinas de su lienzo y mostrar la perspectiva en un cuadrado. En la práctica, resultó ser muy difícil implementar un algoritmo que lo garantizara. Por un lado, hay una gran variedad de fondos, marcos y objetos que pueden caer dentro del marco cerca de la imagen. Por otro lado, hay pinturas dentro de las cuales hay contornos bastante notables de formas rectangulares (ventanas, fachadas de edificios, imagen en imagen). Como resultado, a menudo es muy difícil decir dónde termina la imagen y dónde comienza su entorno.
Al final, nos decidimos por una implementación simple basada en métodos clásicos de visión por computadora (detección de bordes + filtrado morfológico + análisis de componentes conectados), que le permite cortar con confianza los fondos monofónicos, pero no perder parte de la imagen.
Velocidad de trabajo
El algoritmo de procesamiento de consultas consta de los siguientes pasos principales:
- preparación: de hecho, se implementa un detector simple de la imagen, que funciona bien si la imagen contiene un fondo liso;
- calcular un descriptor de imagen usando una red profunda;
- clasificación de imágenes por distancia a los descriptores en la base de datos;
- buscar puntos clave en la imagen;
- verificar candidatos en orden de clasificación.
Probamos la velocidad de la red en 200 solicitudes, se obtuvo el siguiente tiempo de procesamiento para cada una de las etapas (tiempo en segundos):
| escenario | min | max | promedio |
|---|
| Preparación (búsqueda de imágenes) | 0.008 | 0,011 | 0,016 |
| Cálculo del descriptor (GPU) | 0,082 | 0,092 | 0,088 |
| KNN (k <500, CPU, fuerza bruta) | 0.199 | 0.820 | 0,394 |
| Búsqueda de puntos clave | 0,031 | 0.432 | 0,156 |
| Verificar puntos clave | 0.007 | 9.844 | 2,585 |
| Tiempo total de solicitud | 0.358 | 10,386 | 3.239 |
Dado que la verificación de candidatos se detiene inmediatamente, ya que la imagen se encuentra con suficiente confianza, podemos suponer que el tiempo mínimo de procesamiento de las solicitudes corresponde a las imágenes encontradas entre los primeros candidatos. El tiempo máximo de solicitud se obtiene para pinturas que no se encontraron en absoluto: el cheque se detiene después de 500 candidatos.
Se puede ver que la mayor parte del tiempo se dedica a la selección de candidatos y su verificación. Vale la pena señalar que la implementación de estos pasos se ha hecho muy poco óptima y tiene un gran potencial para la aceleración.
Búsqueda duplicada
Habiendo construido el índice completo de la base de pinturas, lo usamos para buscar duplicados en la base de datos. Después de aproximadamente 3 horas de ver la base de datos, se encontró que al menos 13657 imágenes se repiten en la base de datos dos veces (y unas tres).
Además, se encontraron casos muy interesantes que no son duplicados.
 Uno
Uno ,
dos . Parece que estas son dos etapas del mismo trabajo.
 Uno
Uno ,
dos ,
tres . No preste atención al nombre: las tres imágenes son diferentes.
Así como un ejemplo de una identificación falsa positiva por puntos clave.
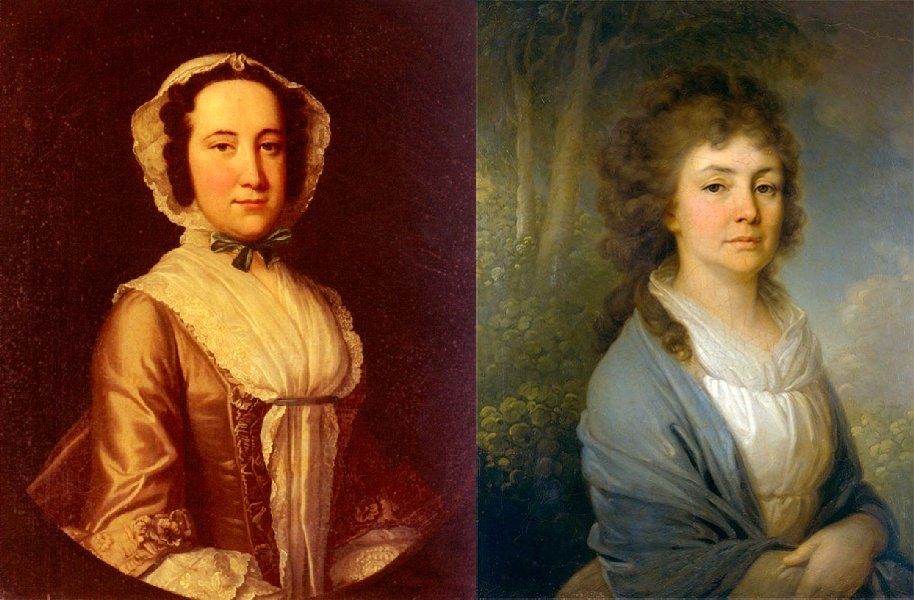 Uno
Uno ,
dos .
En lugar de una conclusión
En general, estamos satisfechos con el resultado del servicio.
En los conjuntos de prueba, se logra una precisión de identificación de más del 80%. En la práctica, a menudo resulta que si la imagen no se encuentra la primera vez, es suficiente fotografiarla desde un ángulo diferente y se encuentra. Los errores cuando se encuentra la imagen incorrecta, casi nunca ocurren.
En conjunto, la solución se envolvió en un contenedor acoplable y se entregó al cliente. Ahora la identificación de pinturas con fotos está disponible en aplicaciones que utilizan el servicio Arthive, por ejemplo, el Museo Pushkin, disponible en Play Market (sin embargo, separa la pintura del fondo, lo que requiere que el fondo sea claro, lo que a veces dificulta la fotografía).