El reconocimiento automático de imágenes satelitales o aéreas es la forma más prometedora de obtener información sobre la ubicación de varios objetos en el suelo. El rechazo de la segmentación manual de imágenes es especialmente relevante cuando se trata de procesar grandes áreas de la superficie de la tierra en poco tiempo.
Recientemente, tuve la oportunidad de aplicar habilidades teóricas y probarme en el campo del aprendizaje automático en un proyecto de segmentación de imagen real. El objetivo del proyecto es el reconocimiento de rodales forestales, a saber, coronas de árboles en imágenes satelitales de alta resolución. Debajo del corte, compartiré mi experiencia y resultados.
Cuando se trata del procesamiento de imágenes, la segmentación puede recibir la siguiente definición: esta es la presencia en la imagen de áreas características que se describen igualmente en este espacio de características.
Distinga entre brillo, contorno, textura y segmentación semántica.
La segmentación de imagen semántica (o semántica) consiste en resaltar áreas de la imagen, cada una de las cuales corresponde a un atributo específico. En términos generales, los problemas de segmentación semántica son difíciles de algoritmizar, por lo que las redes neuronales convolucionales que muestran buenos resultados se usan ampliamente actualmente para la segmentación de imágenes.
Declaración del problema.
El problema de segmentación binaria se está resolviendo: las imágenes en color (imágenes de satélite de alta resolución) se envían a la entrada de la red neuronal, en la que es necesario resaltar las áreas de píxeles que pertenecen a la misma clase: árboles.
Datos de origen
A mi disposición había un conjunto de mosaicos de imágenes satelitales de un área rectangular en la que encaja el polígono. Dentro de él, y debes buscar árboles. El polígono o multipolígono se presenta como un archivo GeoJSON. En mi caso, los mosaicos estaban en formato png de tamaño 256 por 256 píxeles en color verdadero. (por desgracia, sin IR) Numeración de mosaicos en la forma /zoom/x/y.png.
Se garantiza que todos los mosaicos en el conjunto se obtienen de imágenes satelitales tomadas aproximadamente en la misma época del año (finales de primavera - principios de otoño, dependiendo del clima de una región en particular) y un día en un ángulo similar a la superficie, donde se permitió una ligera capa de nubes.
Preparación de datos
Dado que el área del polígono deseado puede ser menor que esta área rectangular, lo primero que debe hacer es excluir los mosaicos que van más allá de los límites del polígono. Para hacer esto, se escribió un script simple que selecciona los mosaicos necesarios del polígono del archivo GeoJSON. Funciona de la siguiente manera. Para empezar, las coordenadas de todos los vértices del polígono se
convierten en números de mosaico y se agregan a una matriz. También hay un desplazamiento relativo al origen. Para la inspección visual, se genera una imagen donde un píxel es igual a un mosaico. El polígono en la imagen se rellena teniendo en cuenta el desplazamiento utilizando PIL. Después de eso, la imagen se transfiere a una matriz, desde donde se seleccionan los mosaicos necesarios, que caen dentro del polígono.
from PIL import Image, ImageDraw
 Resultado visual de convertir un polígono en un conjunto de mosaicos
Resultado visual de convertir un polígono en un conjunto de mosaicosModelo de red
Para resolver los problemas de segmentación de imágenes,
existen varios modelos de redes neuronales convolucionales. Decidí usar
U-Net , que ha demostrado su eficacia en las tareas de segmentación de imágenes binarias. La arquitectura U-Net consiste en las llamadas rutas de contratación y expansivas, que están conectadas por probros en las etapas de tamaño apropiado, y primero reducen la resolución de la imagen y luego la aumentan, combinándola previamente con los datos de la imagen y pasando a través de otras capas convolución Por lo tanto, la red actúa como una especie de filtro. Los bloques de compresión y descompresión se presentan como un conjunto de bloques de una determinada dimensión. Y cada bloque consta de operaciones básicas: convolución, ReLu y agrupación máxima. Hay implementaciones del modelo U-Net en Keras, Tensorflow, Caffe y PyTorch. Yo usé Keras.
Crear un conjunto de entrenamiento
Para aprender este modelo de Unet, necesitas imágenes. Lo primero que se me ocurrió fue la idea de tomar datos de OpenStreetMap y generar máscaras para el entrenamiento basado en ellos. Pero como resultó en mi caso, la precisión de los polígonos que necesito deja mucho que desear. También necesitaba la presencia de árboles individuales, que no siempre se mapean. Por lo tanto, tuve que abandonar tal empresa. Pero vale la pena decir que, para otros objetos, como carreteras o edificios, este enfoque puede ser
efectivo .

Como la idea de generar automáticamente una muestra de entrenamiento basada en datos OSM tuvo que ser abandonada, decidí marcar manualmente un área pequeña. Para hacer esto, utilicé el editor JOSM, donde utilicé imágenes de terreno disponibles como sustrato, que coloqué en un servidor local. Luego surgió otro problema: no encontré la oportunidad de encender la visualización de la cuadrícula de mosaico utilizando herramientas JOSM normales. Por lo tanto, un par de líneas simples en .htaccess en el mismo servidor desde un directorio diferente comenzaron a emitir un mosaico vacío con un borde de píxeles para cualquier solicitud del formulario grid_tile / z / x / y.png y agregaron una capa tan improvisada a JOSM. Que bicicleta
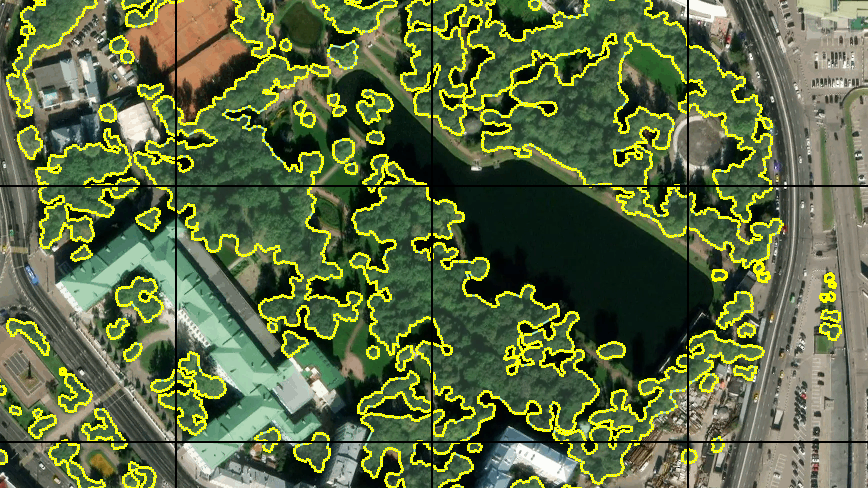
Primero, marqué unos 30 azulejos. Con una tableta gráfica y un "modo de dibujo rápido" en JOSM, no tomó mucho tiempo. Comprendí que tal cantidad no es suficiente para un entrenamiento completo, pero decidí comenzar con esto. Además, el entrenamiento en tantos datos será lo suficientemente rápido.
Entrenamiento y primer resultado
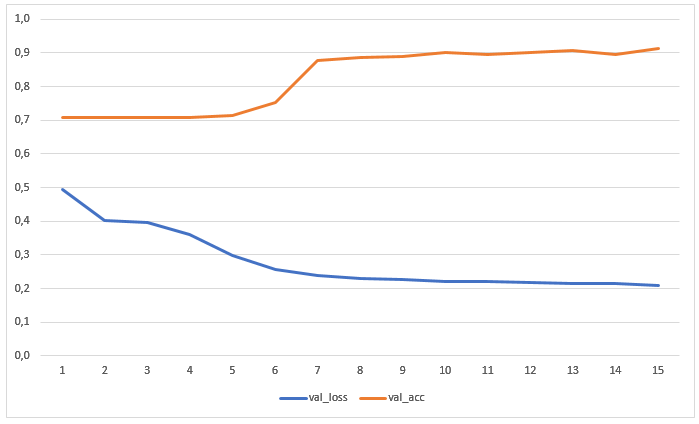
La red ha sido entrenada durante 15 eras sin aumento previo de datos. El gráfico muestra los valores de pérdidas y precisión en la muestra de prueba:
El resultado del reconocimiento de imágenes que no estaban en el entrenamiento ni en la muestra de prueba resultó ser bastante sensato:

Después de un estudio más exhaustivo de los resultados, algunos problemas quedaron claros. Muchas fallas ocurrieron en las áreas sombreadas de las imágenes: la red encontró árboles a la sombra donde no estaban, o exactamente lo contrario. Esto era de esperarse, ya que había pocos ejemplos de este tipo en el conjunto de capacitación. Pero no esperaba que algunas piezas de la superficie del agua y los techos oscuros del perfil de metal (presumiblemente) fueran reconocidos como árboles. También hubo imprecisiones con el césped. Se decidió mejorar la muestra agregando una mayor cantidad de imágenes con secciones controvertidas, por lo que la muestra de entrenamiento casi se duplicó.
Aumento de datos
Para aumentar aún más la cantidad de datos, decidí rotar la imagen en un ángulo arbitrario. En primer lugar, probé el módulo estándar keras.preprocessing.image.ImageDataGenerator. Cuando gira mientras conserva la escala, las áreas vacías permanecen en los bordes de las imágenes, cuyo relleno se establece mediante el parámetro
fill_mode . Simplemente puede rellenar estas áreas con color especificándolas en
cval , pero quería un giro completo, con la esperanza de que la selección fuera más completa, e implementé el generador yo mismo. Esto permitió aumentar el tamaño en más de diez veces.
 fill_mode = más cercano
fill_mode = más cercanoMi generador de datos pega cuatro mosaicos vecinos en un mosaico de fuente única de 512x512 px. El ángulo de rotación se elige aleatoriamente, teniendo en cuenta que los intervalos permitidos de x e y se calculan para el centro del mosaico resultante, en el que no va más allá del mosaico original. Las coordenadas del centro se eligen aleatoriamente teniendo en cuenta los intervalos permitidos. Por supuesto, todas estas transformaciones se aplican al par de máscaras de mosaico. Todo esto se repite para varios grupos de fichas vecinas. De un grupo puede obtener más de una docena de fichas con diferentes secciones del terreno giradas en diferentes ángulos.
 Un ejemplo del resultado del generador.
Un ejemplo del resultado del generador.Aprendiendo con más datos
Como resultado, el tamaño de la muestra de entrenamiento fue de 1881 imágenes, también aumenté el número de eras a 30:
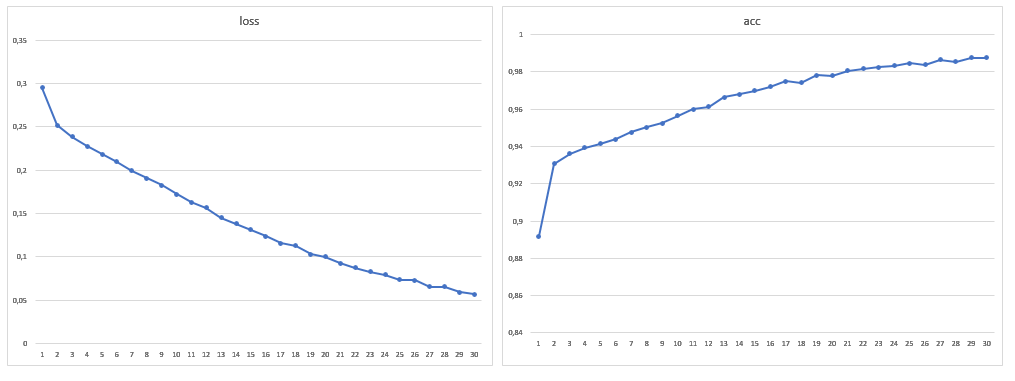
Después de entrenar el modelo en un nuevo volumen de datos, ya no se detectaron problemas con la segmentación errónea de los techos y el agua. No fue posible deshacerse de los errores en la sombra, pero se hicieron menos en el ojo, así como los errores con el césped. Cabe señalar que, en general, la gran mayoría de los errores es que la red ve árboles donde no están, y no al revés. La precisión lograda puede mejorarse mediante el uso de imágenes satelitales con una gran cantidad de canales y modificando la arquitectura de red para una tarea específica.

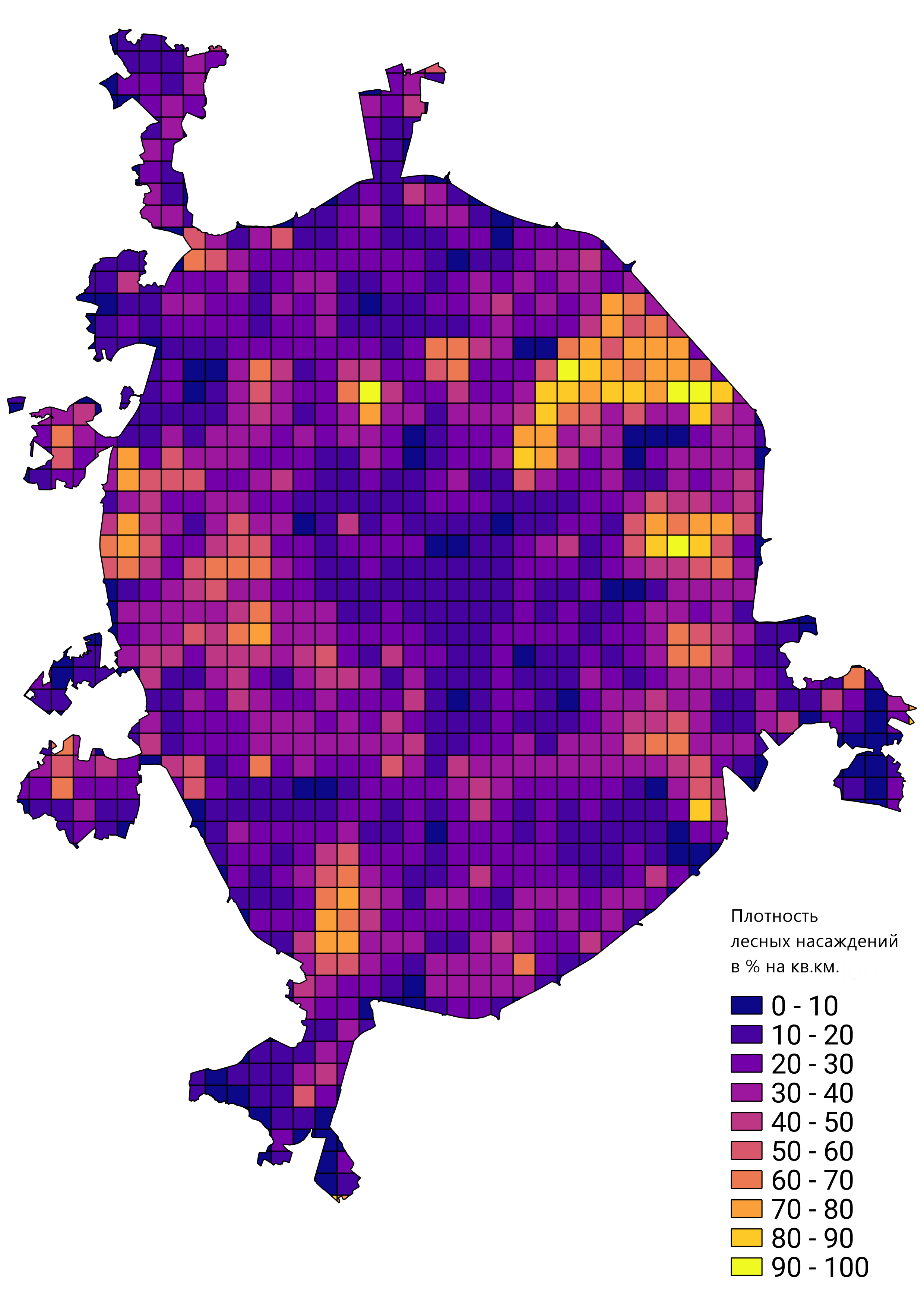
En general, estaba satisfecho con el resultado del trabajo realizado, y el prototipo de red capacitado se aplicó para resolver problemas reales. Por ejemplo, calcular la densidad de los rodales forestales en Moscú: