
Los tiempos en que una de las tareas más urgentes de la visión por computadora era la capacidad de distinguir fotografías de perros de fotografías de gatos, ya están en el pasado. Por el momento, las redes neuronales pueden realizar tareas mucho más complejas e interesantes para el procesamiento de imágenes. En particular, la red con la arquitectura Máscara R-CNN le permite seleccionar los contornos ("máscaras") de diferentes objetos en las fotografías, incluso si hay varios objetos de este tipo, tienen diferentes tamaños y se superponen parcialmente. La red también es capaz de reconocer las poses de las personas en la imagen.
A principios de este año, tuve la oportunidad de participar en la competencia Data Science Bowl 2018 en Kaggle con fines educativos. Con fines educativos, utilicé uno de esos modelos que algunos participantes que ocupan puestos altos presentan generosamente. Era una red neuronal Mask R-CNN desarrollada recientemente por Facebook Research. (Vale la pena señalar que el equipo ganador aún usaba una arquitectura diferente: U-Net. Aparentemente, era más adecuado para tareas biomédicas, que incluían el Data Science Bowl 2018).
Dado que el objetivo era familiarizarse con las tareas de Deep Learning y no ocupar un lugar alto, después del final de la competencia, hubo un fuerte deseo de comprender cómo funciona la red neuronal utilizada "bajo el capó". Este artículo es una compilación de información obtenida de documentos originales de arXiv.org y varios artículos sobre Medium. El material es de naturaleza puramente teórica (aunque al final hay enlaces sobre la aplicación práctica), y no contiene más de lo que hay en las fuentes indicadas. Pero hay poca información sobre el tema en ruso, por lo que quizás el artículo sea útil para alguien.
Todas las ilustraciones están tomadas de fuentes ajenas y pertenecen a sus legítimos propietarios.
Tipos de tareas de visión por computadora
Por lo general, las tareas modernas de visión por computadora se dividen en cuatro tipos (no era necesario cumplir con las traducciones de sus nombres, incluso en fuentes en ruso, por lo tanto, en inglés, para no crear confusión):
- Clasificación : clasificación de la imagen por el tipo de objeto que contiene;
- Segmentación semántica : definición de todos los píxeles de objetos de una determinada clase o fondo en la imagen. Si se superponen varios objetos de la misma clase, sus píxeles no se pueden separar entre sí;
- Detección de objetos : detección de todos los objetos de las clases especificadas y determinación del marco de trabajo para cada uno de ellos;
- Segmentación de instancias : definición de píxeles que pertenecen a cada objeto de cada clase por separado;
Usando el ejemplo de una imagen con globos de
[9], esto se puede ilustrar de la siguiente manera:
Desarrollo evolutivo de la máscara R-CNN
Los conceptos subyacentes a la máscara R-CNN pasaron por un desarrollo gradual a través de la arquitectura de varias redes neuronales intermedias que resolvieron diferentes tareas de la lista anterior. Probablemente, la forma más fácil de comprender los principios de funcionamiento de esta red es considerar secuencialmente todas estas etapas.
Sin detenerse en cosas básicas como la propagación hacia atrás, la función de activación no lineal y lo que es una red neuronal multicapa en general, una breve explicación de cómo funcionan las capas de redes neuronales de convolución probablemente todavía valga la pena (R-CNN).
Convolución y MaxPooling
Una capa convolucional le permite combinar los valores de píxeles adyacentes y resaltar características más generales de la imagen. Para hacer esto, la imagen se desliza secuencialmente por una ventana cuadrada de un tamaño pequeño (3x3, 5x5, 7x7 píxeles, etc.) llamada kernel (kernel). Cada elemento central tiene su propio coeficiente de peso multiplicado por el valor de ese píxel de la imagen en la que se superpone actualmente el elemento central. Luego se suman los números obtenidos para toda la ventana, y esta suma ponderada da el valor del siguiente signo.
Para obtener una matriz ("mapa") de atributos de toda la imagen, el núcleo se desplaza secuencialmente horizontal y verticalmente. En las siguientes capas, la operación de convolución ya se aplica a los mapas característicos obtenidos de las capas anteriores. Gráficamente, el proceso puede ilustrarse de la siguiente manera:
Una imagen o tarjetas de características dentro de una capa se pueden escanear no por una sino por varios filtros independientes, lo que proporciona no una tarjeta, sino varias (también se denominan "canales"). El ajuste de los pesos de cada filtro se realiza utilizando el mismo procedimiento de retropropagación.
Obviamente, si el núcleo del filtro durante el escaneo no va más allá de la imagen, la dimensión del mapa de características será menor que la de la imagen original. Si desea mantener el mismo tamaño, aplique los llamados rellenos, valores que complementan la imagen en los bordes y que luego son capturados por el filtro junto con los píxeles reales de la imagen.
Además de los rellenos, los cambios dimensionales también se ven afectados por los pasos: los valores del paso con el que la ventana se mueve alrededor de la imagen / mapa.
La convolución no es la única forma de obtener una característica generalizada de un grupo de píxeles. La forma más fácil de hacer esto es seleccionar un píxel de acuerdo con una regla dada, por ejemplo, el máximo. Esto es exactamente lo que hace la capa MaxPooling.
A diferencia de la convolución, maxpooling se aplica generalmente a grupos de píxeles disjuntos.
R-CNN
La arquitectura de red R-CNN (Regiones con CNN) fue desarrollada por un equipo de UC Berkley para aplicar redes neuronales de convolución a una tarea de detección de objetos. Los enfoques para resolver los problemas que existían en ese momento se acercaron al máximo de sus capacidades y su rendimiento no mejoró significativamente.
CNN funcionó bien en la clasificación de imágenes, y en la red dada se aplicaron esencialmente para la misma. Para hacer esto, no toda la imagen fue alimentada a la entrada de CNN, sino regiones asignadas preliminarmente de una manera diferente, en la que se supone que deben estar algunos objetos. En ese momento, había varios enfoques de este tipo, los autores eligieron la
Búsqueda selectiva , aunque indican que no hay razones particulares para la preferencia.
Una arquitectura preparada también se utilizó como red CNN:
CaffeNet (AlexNet). Dichas redes neuronales, como otras para el conjunto de imágenes ImageNet, se clasifican en 1000 clases. R-CNN fue diseñado para detectar objetos de un número menor de clases (N = 20 o 200), por lo que la última capa de clasificación de CaffeNet fue reemplazada por una capa con salidas N + 1 (con una clase adicional para el fondo).
La búsqueda selectiva devolvió aproximadamente 2,000 regiones de diferentes tamaños y relaciones de aspecto, pero CaffeNet acepta imágenes de un tamaño fijo de 227x227 píxeles como entrada, por lo que tuvo que modificarlas antes de enviar regiones a la entrada de red. Para esto, la imagen de la región se incluyó en el cuadrado más pequeño. A lo largo del lado (más pequeño) a lo largo del cual se formaron los campos, se agregaron varios píxeles "contextuales" (que rodean la región) de la imagen, el resto del campo no se llenó con nada. El cuadrado resultante fue escalado a un tamaño de 227x227 y alimentado a la entrada de CaffeNet.

A pesar de que CNN se entrenó para reconocer las clases N + 1, al final solo se usó para extraer un vector de características fijo de 4096 dimensiones. N SVM lineales se dedicaron a la determinación directa del objeto en la imagen, cada uno de los cuales llevó a cabo una clasificación binaria de acuerdo con su tipo de objetos, determinando si había tal cosa en la región transferida o no. En el documento original, el siguiente esquema ilustra todo el procedimiento:
Los autores sostienen que el proceso de clasificación en SVM es muy productivo, siendo esencialmente solo operaciones matriciales. Los vectores de características obtenidos de CNN se combinan en todas las regiones en una matriz 2000x4096, que luego se multiplica por una matriz 4096xN con pesos SVM.
Cabe señalar que las regiones obtenidas mediante la Búsqueda selectiva solo
pueden contener algunos objetos, y no el hecho de que los contengan en su totalidad. La
métrica Intersección sobre Unión (IoU) determina si se debe considerar o no una región que contiene un objeto. Esta métrica es la relación del área de intersección de una región candidata rectangular con un rectángulo que realmente abarca el objeto al área de unión de estos rectángulos. Si la relación excede un valor umbral predeterminado, se considera que la región candidata contiene el objeto deseado.
IoU también se usó para filtrar un número excesivo de regiones que contienen un objeto particular (supresión no máxima). Si el IoU de una región con una región que recibió el resultado máximo para el mismo objeto estaba por encima de un umbral, la primera región simplemente se descartó.
Durante el procedimiento de análisis de errores, los autores también desarrollaron un método que permite reducir el error de seleccionar el marco envolvente del objeto: la regresión del cuadro delimitador. Después de clasificar los contenidos de la región candidata, se determinaron cuatro parámetros usando regresión lineal basada en atributos de CNN - (dx, dy, dw, dh). Describieron cuánto debe desplazarse el centro del marco de la región por x e y, y cuánto cambiar su ancho y altura para cubrir con mayor precisión el objeto reconocido.
Por lo tanto, el procedimiento para detectar objetos por la red R-CNN se puede dividir en los siguientes pasos:
- Resalte las regiones candidatas mediante la Búsqueda selectiva.
- Convertir una región al tamaño aceptado por CNN CaffeNet.
- Obtención utilizando el vector de características CNN 4096-dimensional.
- Realización de N clasificaciones binarias de cada vector de características utilizando N SVM lineales.
- Regresión lineal de los parámetros del marco regional para una cobertura de objetos más precisa
Los autores señalaron que la arquitectura que desarrollaron también funcionó bien en el problema de segmentación semántica.
R-cnn rápido
A pesar de los buenos resultados, el rendimiento de R-CNN aún era bajo, especialmente para redes más profundas que CaffeNet (como VGG16). Además, la capacitación para el regresor del cuadro delimitador y SVM requería guardar una gran cantidad de atributos en el disco, por lo que era costoso en términos de tamaño de almacenamiento.
Los autores de Fast R-CNN propusieron acelerar el proceso debido a un par de modificaciones:
- Para pasar por CNN no cada una de las 2000 regiones candidatas por separado, sino toda la imagen. Las regiones propuestas se superponen en el mapa de características comunes resultante;
- En lugar de la capacitación independiente de tres modelos (CNN, SVM, regresor bbox), combine todos los procedimientos de capacitación en uno.
La conversión de signos que cayeron en diferentes regiones a un tamaño fijo se realizó mediante el procedimiento
RoIPooling . Una ventana de región de ancho w y altura h se dividió en una cuadrícula que tenía celdas H × W de tamaño h / H × w / W. (Los autores del documento utilizaron W = H = 7). Para cada una de estas celdas, se realizó la agrupación máxima para seleccionar solo un valor, dando así la matriz de características H × W resultante.
No se usaron SVM binarios, en cambio, las características seleccionadas se transfirieron a una capa totalmente conectada y luego a dos capas paralelas: softmax con salidas K + 1 (una para cada clase + 1 para el fondo) y regresor de cuadro delimitador.
La arquitectura de red general se ve así:
Para el entrenamiento conjunto del clasificador softmax y el regresor bbox, se utilizó la función de pérdida combinada:
L(p,u,tu,v)=Lcls(p,u)+ lambda[u ge1]Lloc(tu,v)
Aquí:
u - la clase del objeto realmente representado en la región candidata;
Lcls(p,u)=− log(pu) - pérdida de registro para la clase u;
v=(vx,vy,vw,vh) - cambios reales en el marco de la región para una cobertura más precisa del objeto;
tu=(tux,tuy,tuw,tuh) - cambios previstos en el marco de la región;
Lloc - función de pérdida entre cambios de trama predichos y reales;
[u ge1] - función de indicador igual a 1 cuando
u ge1 , y 0 cuando viceversa. Clase
u=0 se indica el fondo (es decir, la ausencia de objetos en la región).
lambda - coeficiente diseñado para equilibrar la contribución de ambas funciones de pérdida al resultado general. En todos los experimentos de los autores del documento, sin embargo, fue igual a 1.
Los autores también mencionan que utilizaron la descomposición SVD truncada de la matriz de peso para acelerar los cálculos en una capa totalmente conectada.
R-cnn más rápido
Después de las mejoras realizadas en Fast R-CNN, el cuello de botella de la red neuronal resultó ser el mecanismo para generar regiones candidatas. En 2015, un equipo de Microsoft Research pudo hacer este paso significativamente más rápido. Sugirieron calcular regiones no a partir de la imagen original, sino nuevamente a partir de un mapa de características obtenidas de CNN. Para esto, se agregó un módulo llamado Red de Propuesta de Región (RPN). Toda la arquitectura es la siguiente:
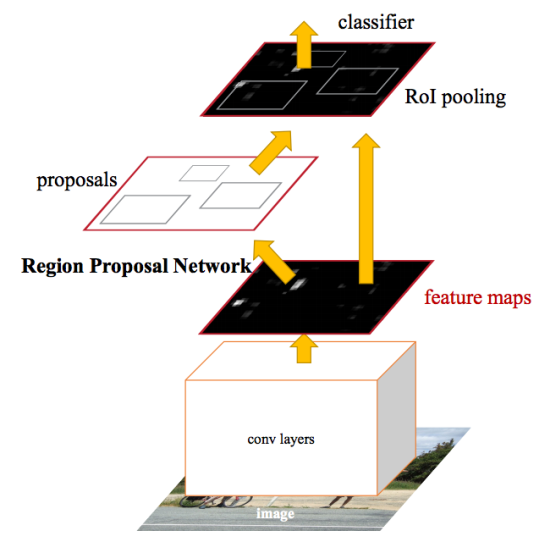
En el marco de la RPN, de acuerdo con la CNN extraída, se deslizan en una "mini red neuronal" con una pequeña ventana (3x3). Los valores obtenidos con su ayuda se transfieren a dos capas paralelas totalmente conectadas: la capa de regresión de caja (reg) y la capa de clasificación de caja (cls). Los resultados de estas capas se basan en los llamados anclajes: k marcos para cada posición de la ventana deslizante, que tienen diferentes tamaños y relaciones de aspecto. La capa de registro para cada ancla de este tipo produce 4 coordenadas, corrigiendo la posición del marco envolvente; La capa cls produce dos números cada uno: la probabilidad de que el marco contenga al menos algún objeto o de que no lo contenga. En el documento, esto se ilustra mediante el siguiente esquema:
El proceso de aprendizaje reg y cls capas combinadas; tienen una función de pérdida en común, que es la suma de las funciones de pérdida de cada uno de ellos, con un coeficiente de equilibrio.
Ambas capas RPN proporcionan solo ofertas para regiones candidatas. Los que tienen más probabilidades de contener un objeto se pasan al módulo de detección y refinamiento de objetos, que todavía se implementa como Fast R-CNN.
Para compartir las características obtenidas en CNN entre el RPN y el módulo de detección, el proceso de capacitación de toda la red se construye iterativamente utilizando varios pasos:
- La parte RPN se inicializa y se entrena para identificar las regiones candidatas.
- Usando las regiones RPN propuestas, la parte Fast R-CNN se vuelve a entrenar.
- Se utiliza una red de detección entrenada para inicializar pesos para RPN. Sin embargo, las capas de convolución general son fijas y solo se vuelven a ajustar las capas específicas de RPN.
- Con capas de convolución fijas, Fast R-CNN finalmente se ajusta.
El esquema propuesto no es el único, e incluso en su forma actual puede continuarse con otros pasos iterativos, pero los autores del estudio original realizaron experimentos precisamente después de dicho entrenamiento.
Máscara r-cnn
Mask R-CNN desarrolla la arquitectura Faster R-CNN agregando otra rama que predice la posición de la máscara que cubre el objeto encontrado, y así resuelve el problema de segmentación de instancias. La máscara es solo una matriz rectangular, en la que 1 en alguna posición significa que el píxel correspondiente pertenece a un objeto de una clase dada, 0, que el píxel no pertenece al objeto.

La visualización de máscaras multicolores en las imágenes de origen puede dar imágenes coloridas:

Los autores del documento dividen condicionalmente la arquitectura desarrollada en una red CNN para calcular las características de la imagen, denominada columna vertebral y cabeza, la unión de las partes responsables de predecir el marco envolvente, clasificar el objeto y determinar su máscara. La función de pérdida es común para ellos e incluye tres componentes:
L=Lcls+Lbox+Lmask
La extracción de la máscara se realiza en un estilo independiente de la clase: las máscaras se predicen por separado para cada clase, sin conocimiento previo de lo que se representa en la región, y luego la máscara de la clase que ganó el clasificador independiente simplemente se selecciona. Se argumenta que este enfoque es más efectivo que confiar en el conocimiento a priori de la clase.
Una de las principales modificaciones derivadas de la necesidad de predecir la máscara es un cambio en el procedimiento
RoIPool (que calcula la matriz de características para la región candidata) al llamado
RoIAlign . El hecho es que el mapa de características obtenido de CNN tiene un tamaño más pequeño que la imagen original, y la región que cubre el número entero de píxeles en la imagen no se puede mostrar en una región proporcional del mapa con el número entero de características:
En RoIPool, el problema se resolvió simplemente redondeando los valores fraccionarios a enteros. Este enfoque funciona bien al seleccionar el marco adjunto, pero la máscara calculada sobre la base de dichos datos es demasiado inexacta.
Por el contrario, RoIAlign no utiliza el redondeo, todos los números siguen siendo válidos y la interpolación bilineal sobre los cuatro puntos enteros más cercanos se utiliza para calcular los valores de los atributos.
En el documento original, la diferencia se explica de la siguiente manera:
Aquí, el mapa sombreado denota un mapa de características y continuo: la visualización en el mapa de características de la región candidata a partir de la fotografía original. Debe haber 4 grupos en esta región para una agrupación máxima con 4 atributos indicados por puntos en la figura. A diferencia del procedimiento RoIPool, que debido al redondeo simplemente alinearía la región con coordenadas enteras, RoIAlign deja los puntos en sus lugares actuales, pero calcula los valores de cada uno de ellos utilizando la interpolación bilineal de acuerdo con los cuatro signos más cercanos.
Interpolación bilinealLa interpolación bilineal de la función de dos variables se lleva a cabo mediante la aplicación de la interpolación lineal, primero en la dirección de una de las coordenadas, luego en la otra.
Sea necesario interpolar el valor de la función.
f(x,y) en el punto P con valores conocidos de la función en los puntos circundantes
Q11=(x1,y1),Q12=(x1,y2),Q21=(x2,y1),Q22=(x2,y2) (Ver imagen a continuación). Para hacer esto, primero se interpolan los valores de los puntos auxiliares R1 y R2, y luego el valor en el punto P se interpola en función de ellos.
R1=(x,y1)
R2=(x,y2)
f(R1)≈ frac(x2−x)(x2−x1)f(Q11)+ frac(x−x1)(x2−x1)f(Q21)
f(R2)≈ frac(x2−x)(x2−x1)f(Q12)+ frac(x−x1)(x2−x1)f(Q22)
f(P)≈(y2−y)(y2−y1)f(R1)+(y−y1)(y2−y1)f(R2)
( — ,
)
Además de los altos resultados en las tareas de segmentación de instancias y detección de objetos, Mask R-CNN demostró ser adecuado para determinar la postura de las personas en la fotografía (estimación de la postura humana). El punto clave aquí es la selección de puntos clave (puntos clave), como el hombro izquierdo, el codo derecho, la rodilla derecha, etc., mediante los cuales puede dibujar un marco de la posición de una persona: para determinar los puntos de referencia, la red neuronal se entrena de tal manera que proporciona máscaras, en de los cuales solo un píxel (el mismo punto) tenía un valor de 1, y el resto - 0 (una máscara activa). Al mismo tiempo, la red está entrenando para emitir K máscaras de un solo píxel, una para cada tipo de punto de referencia.
para determinar los puntos de referencia, la red neuronal se entrena de tal manera que proporciona máscaras, en de los cuales solo un píxel (el mismo punto) tenía un valor de 1, y el resto - 0 (una máscara activa). Al mismo tiempo, la red está entrenando para emitir K máscaras de un solo píxel, una para cada tipo de punto de referencia.Característica de redes piramidales
En experimentos con Mask R-CNN, junto con el CNN ResNet-50/101 habitual como columna vertebral, también se realizaron estudios sobre la viabilidad de utilizar Feature Pyramid Network (FPN). Demostraron que el uso de FPN en la red troncal le da a Mask R-CNN un aumento tanto en precisión como en rendimiento. Esto hace que sea útil describir la mejora de la misma manera, a pesar de que un documento separado está dedicado a ella y tiene poco que ver con la serie de artículos bajo consideración.El propósito de Feature Pyramids, como las pirámides de imagen, es mejorar la calidad de detección de objetos, teniendo en cuenta una amplia gama de sus posibles tamaños.En Feature Pyramid Network, los mapas de características extraídos por sucesivas capas de CNN con dimensiones decrecientes se consideran algún tipo de "pirámide" jerárquica llamada vía ascendente. Además, los mapas de características de los niveles inferior y superior de la pirámide tienen sus ventajas y desventajas: los primeros tienen una alta resolución, pero una baja capacidad semántica de generalización; el segundo, por el contrario:La arquitectura FPN le permite combinar las ventajas de las capas superior e inferior al agregar una ruta de arriba hacia abajo y conexiones laterales. Para esto, el mapa de cada capa superior se amplía al tamaño de la capa subyacente y su contenido se agrega elemento por elemento. En las predicciones finales, se usan las cartas resultantes de todos los niveles.Esquemáticamente, esto se puede representar de la siguiente manera:El aumento del tamaño del mapa de nivel superior (muestreo ascendente) se realiza mediante el método más simple: el vecino más cercano, es decir, aproximadamente así:Enlaces utiles
Documentos de investigación originales en arXiv.org:1. R-CNN: https://arxiv.org/abs/1311.25242. Fast R-CNN: https://arxiv.org/abs/1504.080833. R-CNN más rápido : https://arxiv.org/abs/1506.014974. Máscara R-CNN: https://arxiv.org/abs/1703.068705. Feature Pyramid Network: https://arxiv.org/abs/1612.03144En medio. com sobre el tema de la máscara R-CNN hay muchos artículos, son fáciles de encontrar. Como referencias traigo solo las que leí:6. Comprensión simple de la máscara RCNN : un breve resumen de los principios de la arquitectura resultante.7. Una breve historia de las CNN en la segmentación de imágenes: de R-CNN a enmascarar R-CNN- La historia del desarrollo de la red en el mismo orden cronológico que en este artículo.8. De R-CNN a Máscara R-CNN es otra consideración de las etapas de desarrollo.9) Splash of Color: segmentación de instancias con Mask R-CNN y TensorFlow : implementación de la red neuronal en la biblioteca de Opensource de Matterport.El último artículo, además de describir los principios de Mask R-CNN, ofrece la oportunidad de probar la red en la práctica: para colorear globos en diferentes colores en imágenes en blanco y negro.Además, puede practicar con la red neuronal en el modelo que utilicé en la competencia de kaggle Data Science Bowl 2018 (pero no solo con este modelo, por supuesto; puede encontrar muchas cosas interesantes en las secciones Kernels y Discusiones):10. Máscara R- CNN en PyTorch por Heng CherKeng. La implementación implica una serie de pasos de implementación; el autor proporciona instrucciones. El modelo requiere PyTorch 0.4.0, soporte para computación GPU, NVIDIA CUDA. Si mi propio sistema no cumple con los requisitos, puedo recomendar imágenes AMI de Deep Learning para máquinas virtuales de Amazon (las instancias se pagan, con facturación por hora, el tamaño mínimo adecuado, aparentemente, es p2.xlarge).También me encontré aquí en el centro, un artículo sobre el uso de la red de Matterport en el procesamiento de imágenes con platos (aunque sin fuente). Espero que el autor solo esté contento con la mención adicional:11. ConvNets. Prototipo de un proyecto usando Mask R-CNN