En la película Mission Impossible 3, se mostró el proceso de creación de las famosas máscaras de espías, gracias a las cuales algunos personajes se vuelven indistinguibles de otros. Según la trama, al principio se requería fotografiar a la persona a quien el héroe quería convertir desde varios ángulos. En 2018, un simple modelo de cara en 3D puede que ni siquiera se imprima, sino que al menos se cree en forma digital, y se base en una sola foto. Un investigador de VisionLabs describió en detalle el proceso en el evento Yandex "
Mundo a través de los ojos de los robots " de la serie Data & Science, con detalles sobre métodos y fórmulas específicos.
Buenas tardes Mi nombre es Nikolai, trabajo para VisionLabs, una compañía de visión por computadora. Nuestro perfil principal es el reconocimiento facial, pero también tenemos tecnologías que son aplicables en realidad aumentada y virtual. En particular, tenemos una tecnología para construir una cara en 3D a partir de una foto, y hoy hablaré sobre ello.

Comencemos con una historia sobre lo que es. En la diapositiva, verá la foto original de Jack Ma y un modelo 3D construido a partir de esta foto en dos variaciones: con y sin textura, solo geometría. Esta es la tarea que estamos resolviendo.

También queremos poder animar este modelo, cambiar la dirección de nuestra mirada, expresión facial, agregar expresiones faciales, etc.
La aplicación se encuentra en diferentes áreas. Los más obvios son los juegos, incluida la realidad virtual. También puede hacer probadores virtuales: pruebe con anteojos, barbas y peinados. Puede imprimir en 3D, porque algunas personas están interesadas en accesorios personalizados para su cara. Y puede hacer caras para los robots: tanto imprimir como mostrar en alguna pantalla del robot.

Comenzaré diciéndole cómo generar caras 3D en general, y luego pasaremos a la tarea de reconstrucción 3D como una tarea de generación inversa. Después de eso, nos centraremos en la animación y pasaremos a los desafíos que surgen en esta área.

¿Cuál es la tarea de generar caras? Nos gustaría tener alguna forma de generar caras tridimensionales que difieran en forma y expresión. Aquí hay dos filas con ejemplos. La primera fila muestra caras de diferentes formas, que pertenecen a diferentes personas. Y debajo está la misma cara con una expresión diferente.

Una forma de resolver el problema de generación son los modelos deformables. La cara más a la izquierda de la diapositiva es un tipo de modelo promediado al que podemos aplicar deformaciones ajustando los controles deslizantes. Aquí hay tres controles deslizantes. En la fila superior hay caras en la dirección de aumentar la intensidad del control deslizante, en la fila inferior, en la dirección de disminuir. Por lo tanto, tendremos varios parámetros personalizables. Al instalarlos, puede darle a las personas diferentes formas.

Un ejemplo de un modelo deformable es el famoso modelo de rostro de Basilea, construido a partir de escaneos faciales. Para construir un modelo deformable, primero debe llevar a algunas personas, llevarlas a un laboratorio especial y dispararles a la cara con un equipo especial, traduciéndolos en 3D. Luego, en base a esto, puedes hacer nuevas caras.

¿Cómo se arregla matemáticamente? Podemos imaginar un modelo tridimensional de una cara como un vector en un espacio tridimensional. Aquí n es el número de vértices en el modelo, cada vértice corresponde a tres coordenadas en 3D, y así obtenemos 3n coordenadas.

Si tenemos un conjunto de escaneos, cada escaneo está representado por dicho vector, y tenemos un conjunto de n de tales vectores.
Además, podemos construir nuevas caras como combinaciones lineales de vectores desde nuestra base de datos. Al mismo tiempo, nos gustaría que los coeficientes sean significativos. Obviamente, no pueden ser completamente arbitrarios, y pronto mostraré por qué. Se puede establecer una de las restricciones para que todos los coeficientes se encuentren en el rango de 0 a 1. Esto debe hacerse, porque si los coeficientes son completamente arbitrarios, las caras resultarán inverosímiles.

Aquí me gustaría dar a los parámetros un significado probabilístico. Es decir, queremos ver un conjunto de parámetros y comprender si es probable que una persona resulte o no. Con esto queremos que las distorsiones bajas correspondan a caras distorsionadas.

Aquí te explicamos cómo hacerlo. Podemos aplicar el método del componente principal a un conjunto de escaneos. En la salida, obtenemos la cara promedio S0, obtenemos la matriz V, un conjunto de componentes principales, y también obtenemos variaciones de datos a lo largo de los componentes principales. Luego, podemos ver de nuevo la generación de caras, representaremos las caras como una cara promedio, más la matriz de los componentes principales, multiplicada por el vector de parámetros.
El valor de los parámetros es la intensidad de los controles deslizantes de los que hablé en una de las diapositivas anteriores. Y también podemos asignar algún valor probabilístico al vector de parámetros. En particular, podemos aceptar que este vector sea gaussiano.

Por lo tanto, obtenemos un método que le permite generar caras en 3D, y esta generación está controlada por los siguientes parámetros. Como en la diapositiva anterior, tenemos dos conjuntos de parámetros, dos vectores α id y α exp, son los mismos que en la diapositiva anterior, pero α id es responsable de la forma de la cara, y α exp será responsable de la emoción.
También aparece un nuevo vector T: un vector de textura. Tiene la misma dimensión que el vector de forma, y cada vértice en este vector tiene tres valores RGB. De manera similar, se genera un vector de textura utilizando el vector de parámetros β. Aquí no se formalizan los parámetros que serán responsables de iluminar la cara y su posición, sino que también existen.

Aquí hay ejemplos de caras que se pueden generar utilizando un modelo deformado. Tenga en cuenta que difieren en forma, color de piel y también se dibujan en diferentes condiciones de iluminación.
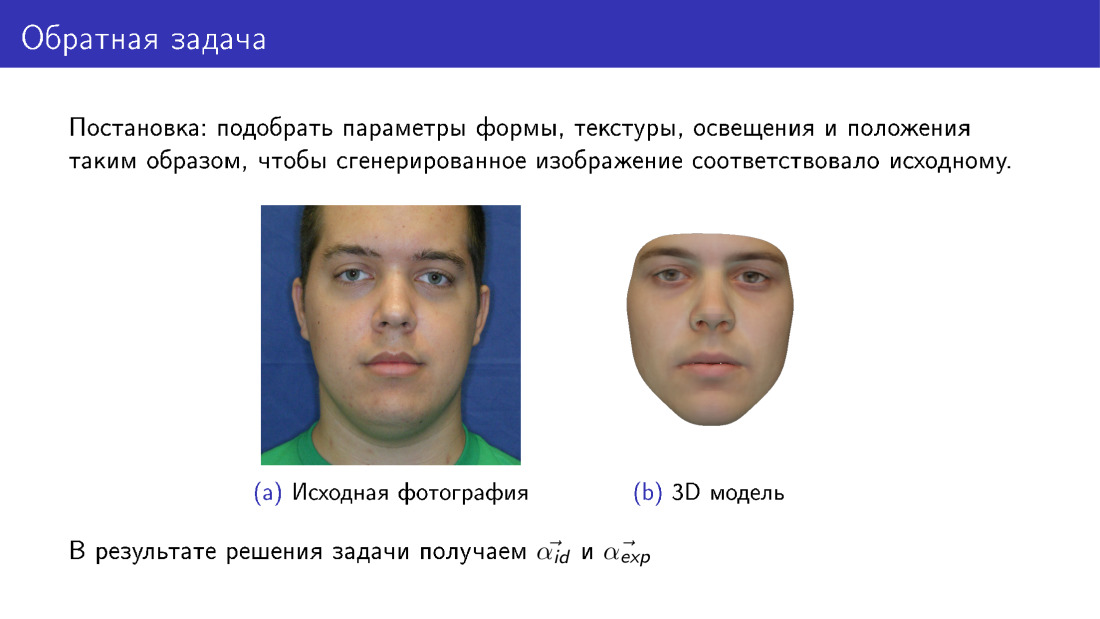
Ahora podemos pasar a la reconstrucción 3D. Esto se llama el problema inverso, porque queremos seleccionar dichos parámetros para el modelo deformable para que la cara que dibujemos sea lo más similar posible al original. Esta diapositiva difiere de la primera en que la cara aquí es completamente sintética a la derecha. Si en la primera diapositiva nuestra textura fue tomada de una fotografía, entonces aquí la textura fue tomada de un modelo deformable.
En la salida, tendremos todos los parámetros, en la diapositiva se presentan la identificación α y la α exp, y también tendremos iluminación, parámetros de textura, etc.

Dijimos que queremos asegurarnos de que el modelo generado se vea como una fotografía. Esta similitud se determina utilizando la función de energía. Aquí solo tomamos la diferencia píxel por píxel de las imágenes en aquellos píxeles en los que creemos que la cara es visible. Por ejemplo, si se gira la cara, se producirá una superposición. Por ejemplo, parte del pómulo estará cubierto por la nariz. Y la matriz de visibilidad M debería mostrar tal superposición.
En esencia, la reconstrucción 3D es para minimizar esta función de energía. Pero para resolver este problema de minimización, sería bueno tener inicialización y regularización. La regularización es necesaria por una razón obvia, ya que dijimos que si no regularizamos los parámetros y los hacemos completamente arbitrarios, podemos obtener caras distorsionadas. La inicialización es necesaria porque la tarea en su conjunto es compleja, tiene mínimos locales y no desea ocuparse de ellos.

¿Cómo se puede hacer la inicialización? Para esto, puede usar 68 puntos clave de la cara. Desde 2013-2014, han aparecido muchos algoritmos que permiten detectar 68 puntos con una precisión bastante buena, y ahora se están acercando a una saturación de su precisión. Por lo tanto, tenemos una manera de detectar de manera confiable 68 puntos de la cara.
Podemos agregar un nuevo término a nuestra función de energía, que dirá que queremos que las proyecciones de los mismos 68 puntos del modelo coincidan con los puntos clave de la cara. Marcamos estos puntos en el modelo, luego de alguna manera deformamos el modelo, lo giramos, proyectamos los puntos y nos aseguramos de que las posiciones de los puntos coincidan. En la foto de la izquierda hay puntos de dos colores, violeta y amarillo. El algoritmo detectó algunos puntos, mientras que otros se proyectaron a partir del modelo. Marcar puntos en el modelo a la derecha, pero para los puntos a lo largo del borde de la cara, no se marca un punto, sino una línea completa. Esto se hace porque cuando se gira la cara, las marcas de estos puntos deben cambiar y el punto se selecciona con una línea.

Aquí está el término del que hablé, es la diferencia de coordenadas de dos vectores que describen los puntos clave de la cara y los puntos clave proyectados desde el modelo.

Volvamos a la regularización y consideremos todo el problema desde la perspectiva de la conclusión bayesiana. La probabilidad de que el vector α sea igual a algo dado en una imagen conocida es proporcional al producto de la probabilidad de observar la imagen para un α dado, multiplicado por la probabilidad α. Si tomamos el logaritmo negativo de esta expresión, que tendremos que minimizar, veremos que el término responsable de la regularización tendrá una forma concreta aquí. En particular, este es el segundo término. Recordando que previamente supusimos que el vector α es gaussiano, vemos que el término responsable de la regularización es la suma de los cuadrados de los parámetros reducidos a variaciones a lo largo de los componentes principales.

Entonces, podemos escribir la función de energía completa, que contiene tres términos. El primer término es responsable de la textura, de la diferencia de píxeles entre la imagen generada y la imagen objetivo. El segundo término es responsable de los puntos clave, y el tercero es responsable de la regularización.
Los coeficientes de los términos en el proceso de minimización no están optimizados, simplemente se establecen.
Aquí, la función de energía se representa como una función de todos los parámetros. α id - parámetros de forma de la cara, α exp - parámetros de expresión, β - parámetros de textura, p - otros parámetros de los que hablamos pero no formalizamos, estos son parámetros de posición e iluminación.
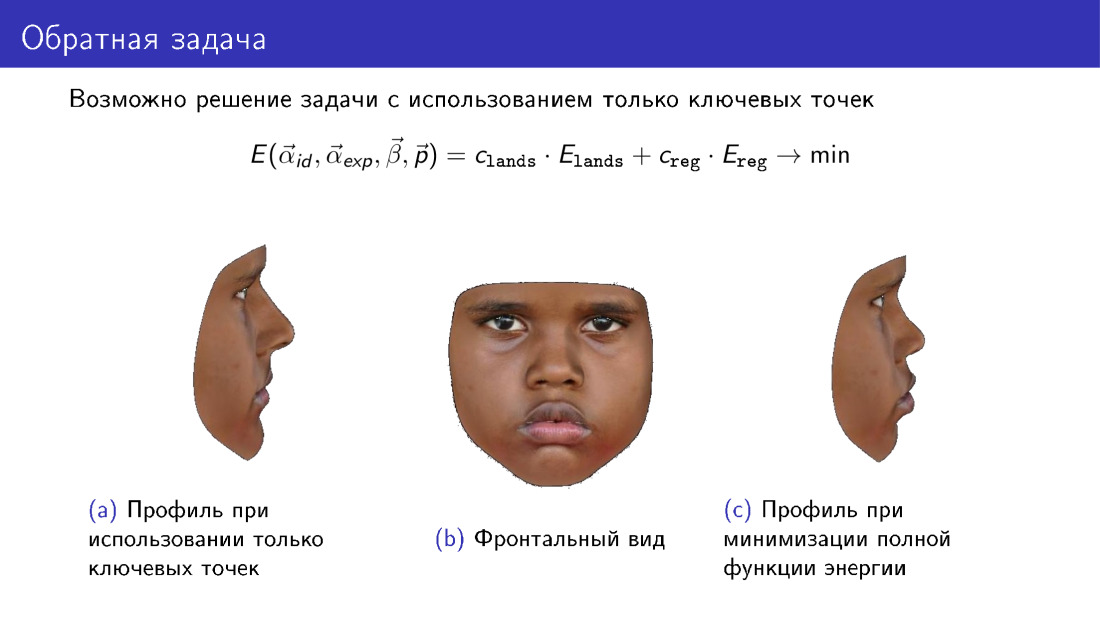
Detengámonos en este comentario. Esta función energética puede simplificarse. A partir de él, puede descartar el término responsable de la textura y utilizar solo la información transmitida por 68 puntos. Y esto le permitirá construir algún tipo de modelo 3D. Sin embargo, preste atención al perfil del modelo. A la izquierda hay un modelo construido solo en puntos clave. A la derecha hay un modelo que usa textura al construir. Tenga en cuenta que el perfil de la derecha es más consistente con la fotografía central, que representa la vista frontal de la cara.

La animación con el algoritmo existente para construir un modelo 3D de la cara funciona de manera bastante simple. Recuerde que al construir un modelo 3D, obtenemos dos vectores de parámetros, uno responsable de la forma y el otro de la expresión. Estos vectores de parámetros para el usuario y el avatar siempre tendrán los suyos. El usuario tiene un vector de parámetros de formulario, el avatar tiene uno diferente. Sin embargo, podemos hacer que los vectores responsables de la expresión se vuelvan iguales para ellos. Tomaremos los parámetros que son responsables de la expresión facial del usuario, y simplemente los sustituiremos en el modelo de avatar. Por lo tanto, transferiremos la expresión facial del usuario al avatar.
Hablemos de dos desafíos en esta área: la velocidad del trabajo y el modelo deformable limitado.

La velocidad es realmente un problema. Minimizar la función de energía total es una tarea computacionalmente intensiva. En particular, puede tomar de 20 a 40, un promedio de 30 segundos. Esto es lo suficientemente largo. Si construimos un modelo tridimensional solo en puntos clave, resultará mucho más rápido, pero la calidad se verá afectada por esto.

¿Cómo lidiar con este problema? Puede usar más recursos, algunas personas resuelven este problema en la GPU. Solo se pueden usar puntos clave, pero la calidad se verá afectada. Y puede usar métodos de aprendizaje automático.

A ver en orden. Aquí está el trabajo de 2016, en el que la expresión facial del usuario se transfiere a un video específico, puede controlar el video usando su cara. Aquí, la construcción del modelo 3D se lleva a cabo en tiempo real utilizando la GPU.

Estos son los métodos que utilizan el aprendizaje automático. La idea es que primero podamos tomar una gran base de caras, para cada cara usando un algoritmo largo pero preciso para construir modelos 3D, presentar cada modelo como un conjunto de parámetros y luego entrenar la cuadrícula para predecir estos parámetros. En particular, en este trabajo de 2016, se utiliza ResNet, que lleva una imagen a la entrada y proporciona los parámetros del modelo a la salida.

El modelo tridimensional se puede representar de otra manera. En este trabajo de 2017, el modelo 3D se presenta no como un conjunto de parámetros, sino como un conjunto de vóxeles. La red predice vóxeles, convirtiendo la imagen en una representación tridimensional. Vale la pena señalar que las opciones de capacitación en red son posibles para las cuales no se requieren modelos 3D.

Esto funciona de la siguiente manera. Aquí la parte más importante es la capa, que puede tomar los parámetros del modelo deformable como entrada y representar la imagen. Tiene una propiedad tan maravillosa que a través de ella puede hacer la propagación inversa del error. La red acepta una imagen como entrada, predice los parámetros, alimenta estos parámetros a una capa que representa la imagen, compara esta imagen con la entrada, recibe un error, propaga el error y continúa aprendiendo. Por lo tanto, la red aprende a predecir los parámetros del modelo tridimensional, teniendo solo imágenes como datos de entrenamiento. Y es muy interesante.

Hablamos mucho sobre la precisión, en particular, que se resiente si descartamos algunos términos de la función de la energía. Formalicemos lo que esto significa, cómo puede evaluar la precisión de la reconstrucción facial 3D. Para hacer esto, necesitamos una base de escaneos de verdad y verdad obtenidos utilizando equipos especiales, utilizando métodos con respecto a los cuales hay algunas garantías de precisión. Si existe tal base, entonces podemos comparar nuestros modelos reconstruidos con la verdad básica. Esto se hace simplemente: calculamos la distancia promedio desde los vértices de nuestro modelo, que construimos, hasta los vértices en la verdad del terreno, y normalizamos al tamaño del escaneo. Esto debe hacerse porque las caras son diferentes, algunas son más grandes, otras son más pequeñas y el error en la cara pequeña sería más pequeño, simplemente porque la cara misma es más pequeña. Por lo tanto, se necesita normalización.

Me gustaría hablar sobre nuestro trabajo, será en talleres, hay ECCV. Hacemos cosas similares, enseñamos a MobileNet a predecir los parámetros de un modelo deformable. Como datos de entrenamiento, utilizamos modelos 3D creados para fotografías del conjunto de datos de 300W. Evaluar la precisión basada en exploraciones BU4DFE.
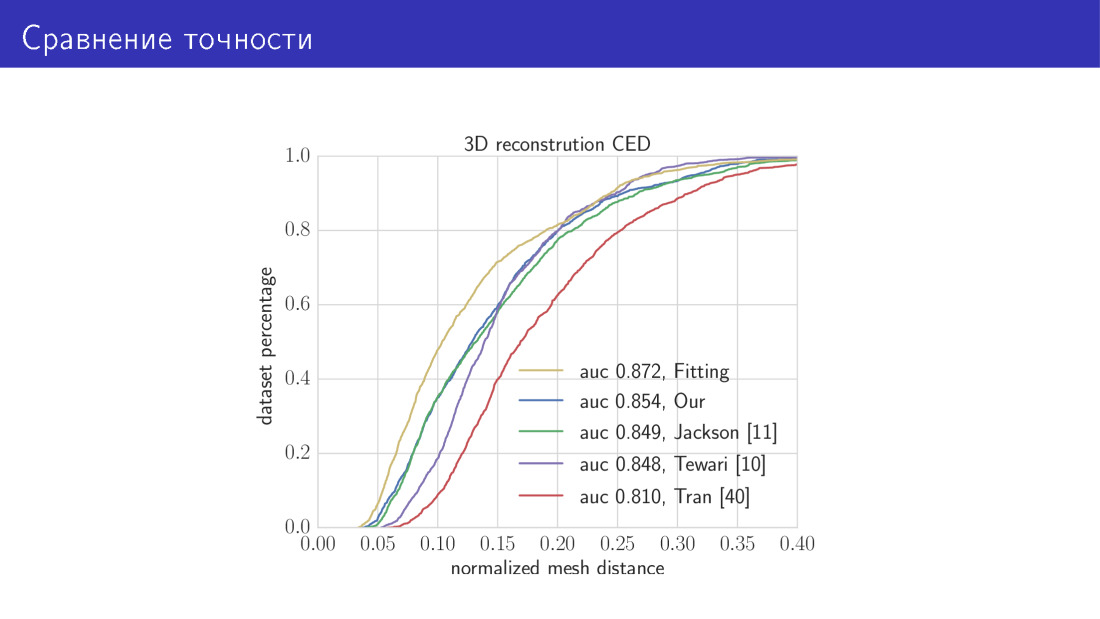
Aquí está el resultado. Comparamos nuestros dos algoritmos con el estado del arte. La curva amarilla en este gráfico es un algoritmo que toma 30 segundos y consiste en minimizar la función de energía total. Aquí, a lo largo del eje X, está el error del que acabamos de hablar, la distancia promedio entre los vértices. El eje Y es la fracción de imágenes en las que este error es menor que el del eje X. En este gráfico, cuanto mayor sea la curva, mejor. La siguiente curva es nuestra red basada en MobileNet. A continuación, los tres trabajos de los que hablamos. Red predictiva de parámetros y red predictiva de vóxel.
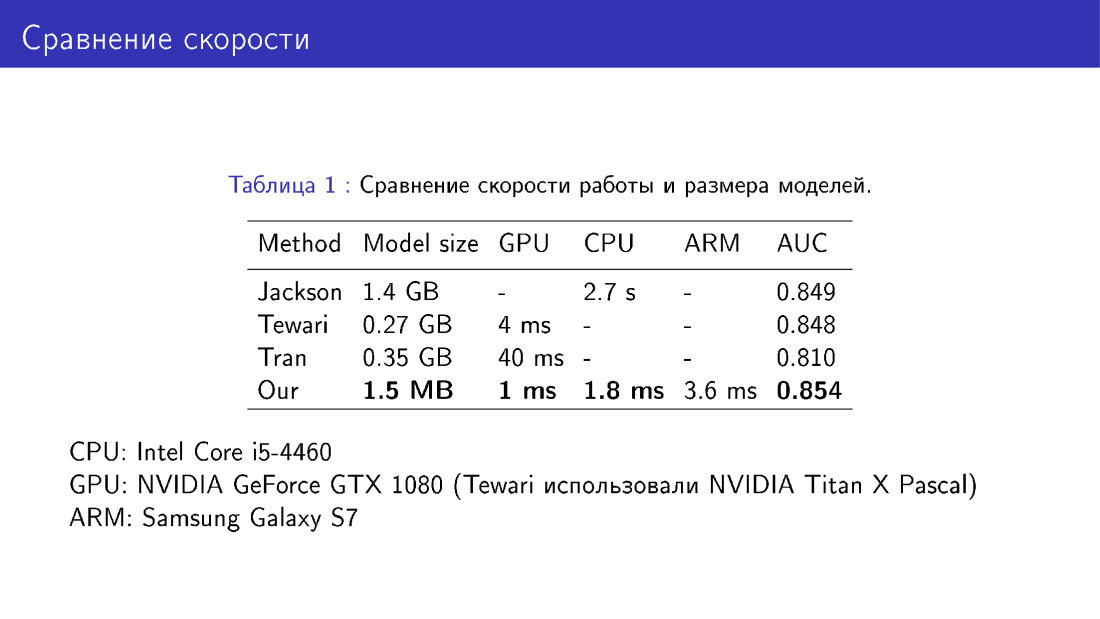
También comparamos nuestra red con sus pares en términos de tamaño y velocidad del modelo. Esto es una victoria porque usamos MobileNet, que es bastante fácil.
El segundo desafío es la limitación del modelo deformable.

Presta atención a la cara izquierda, mira las alas de la nariz. Hay sombras en las alas de la nariz. Los bordes de las sombras no coinciden con los bordes de la nariz en la foto, por lo tanto, se obtiene un defecto. La razón de esto puede ser que el modelo deformable, en principio, no puede construir la nariz de la forma requerida, porque este modelo deformable se obtuvo a partir de escaneos de solo 200 caras. Nos gustaría que la nariz sea correcta, como en la foto de la derecha. Por lo tanto, tenemos que ir más allá del marco del modelo deformable.

Esto se puede hacer usando la deformación no paramétrica de la malla. Aquí hay tres tareas que nos gustaría resolver: modificar la parte local de la cara, por ejemplo, la nariz, luego incrustarla en el modelo original de la cara, e incluso para que todo lo demás permanezca sin cambios.

Esto se puede hacer de la siguiente manera. Volvamos a la designación de la malla como un vector en un espacio tridimensional y observemos el operador de promedio. Este es un operador que en S con un encabezado reemplaza cada vértice con el promedio de sus vecinos. Los vecinos del pico son aquellos que están conectados por un borde.
Definiremos una determinada función de energía que describa la posición del vértice en relación con sus vecinos. Queremos que la posición del pico con respecto a sus vecinos permanezca sin cambios, o al menos no cambie mucho. Pero al mismo tiempo, modificaremos de alguna manera S. Esta función de energía se llama interna, porque también habrá algún término externo, que dirá que, por ejemplo, la nariz debe tomar una forma determinada.
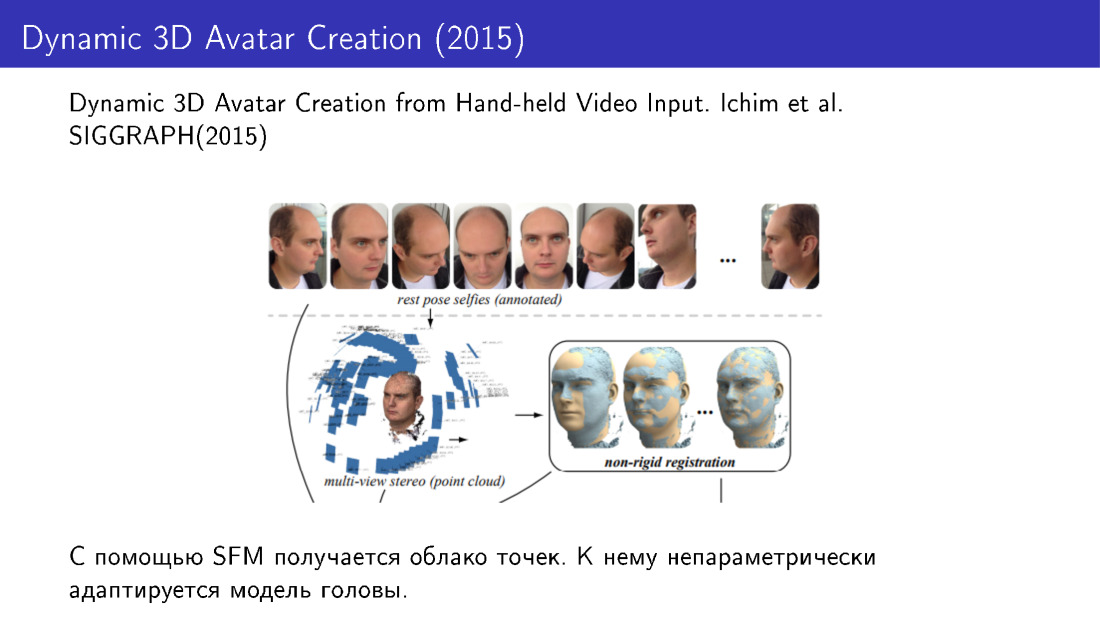
Dichas técnicas se utilizaron, por ejemplo, en el trabajo de 2015. Hicieron una reconstrucción facial en 3D a partir de varias fotografías. Tomamos varias fotos desde el teléfono, recibimos una nube de puntos y luego adaptamos el modelo de rostro a esta nube usando modificaciones no paramétricas.
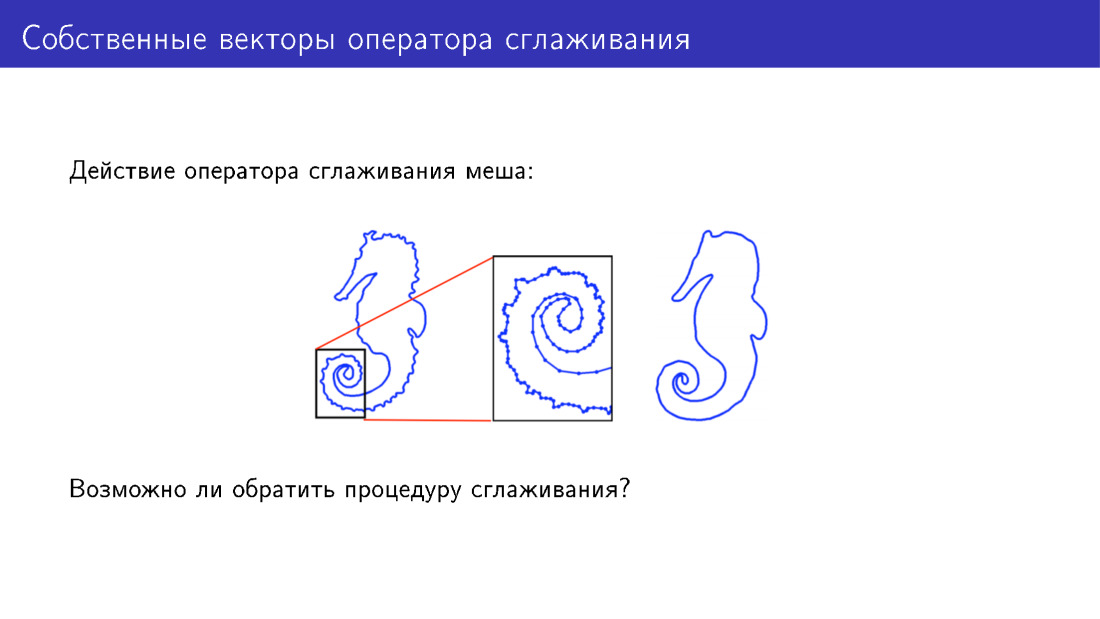
Puede ir más allá del modelo deformable de otra manera. Detengámonos en la acción del operador de suavizado. Aquí, por simplicidad, se presenta una malla bidimensional a la que se ha aplicado este operador. Hay muchos detalles sobre el modelo a la izquierda; en el modelo a la derecha, estos detalles se han suavizado. Pero, ¿podemos hacer algo para agregar detalles en lugar de eliminarlos?

. .
? -: - . . , 2016 . , .