Hola a todos!
Netracker ha estado desarrollando y suministrando aplicaciones empresariales para el mercado global de operadores de telecomunicaciones durante muchos años. El desarrollo de tales soluciones es bastante complicado: cientos de personas participan en proyectos y el número de proyectos activos en las decenas.
Anteriormente, los productos eran monolíticos, pero ahora nos estamos moviendo con confianza hacia aplicaciones de microservicio. DevOps se enfrentó a una tarea bastante ambiciosa: proporcionar este salto tecnológico.
Como resultado, obtuvimos un concepto de ensamblaje exitoso, que queremos compartir como una mejor práctica. La descripción de la implementación con detalles técnicos será bastante voluminosa; no lo haremos en el marco de este artículo.
En el caso general, el ensamblaje es la transformación de algunos artefactos en otros.
A quien le interesará
Aquellas empresas que suministran software listo para usar a una organización completamente externa y cobran por él.
Así es como se vería el desarrollo sin entrega externa:
- El departamento de TI de la planta desarrolla software para su empresa.
- La empresa se dedica a la contratación externa para un cliente extranjero. El cliente compila y opera este código independientemente en su propio servidor web.
- La compañía suministra software a clientes externos, pero bajo una licencia de código abierto. La mayor parte de la responsabilidad queda aliviada.
Si no se enfrenta a un suministro externo, gran parte de lo que se escribe a continuación parecerá redundante o incluso paranoico.
En la práctica, todo debe hacerse de conformidad con los requisitos internacionales para las licencias y el cifrado utilizados, de lo contrario surgirán al menos consecuencias legales.
Un ejemplo de violación es tomar el código de una biblioteca con una licencia GPL3 e incrustarlo en una aplicación comercial.
La aparición de microservicios requiere cambio
Hemos adquirido una amplia experiencia en el montaje y entrega de aplicaciones monolíticas.
Varios servidores Jenkins, miles de trabajos de CI, varias líneas de ensamblaje totalmente automatizadas basadas en Jenkins, docenas de ingenieros dedicados de lanzamiento, su propio grupo de expertos en gestión de la configuración.
Históricamente, el enfoque en la empresa era este: los desarrolladores escriben el código fuente y DevOps inventa y escribe la configuración del sistema de ensamblaje.
Como resultado, teníamos dos o tres configuraciones de ensamblaje típicas diseñadas para operar en el ecosistema corporativo. Esquemáticamente, se ve así:
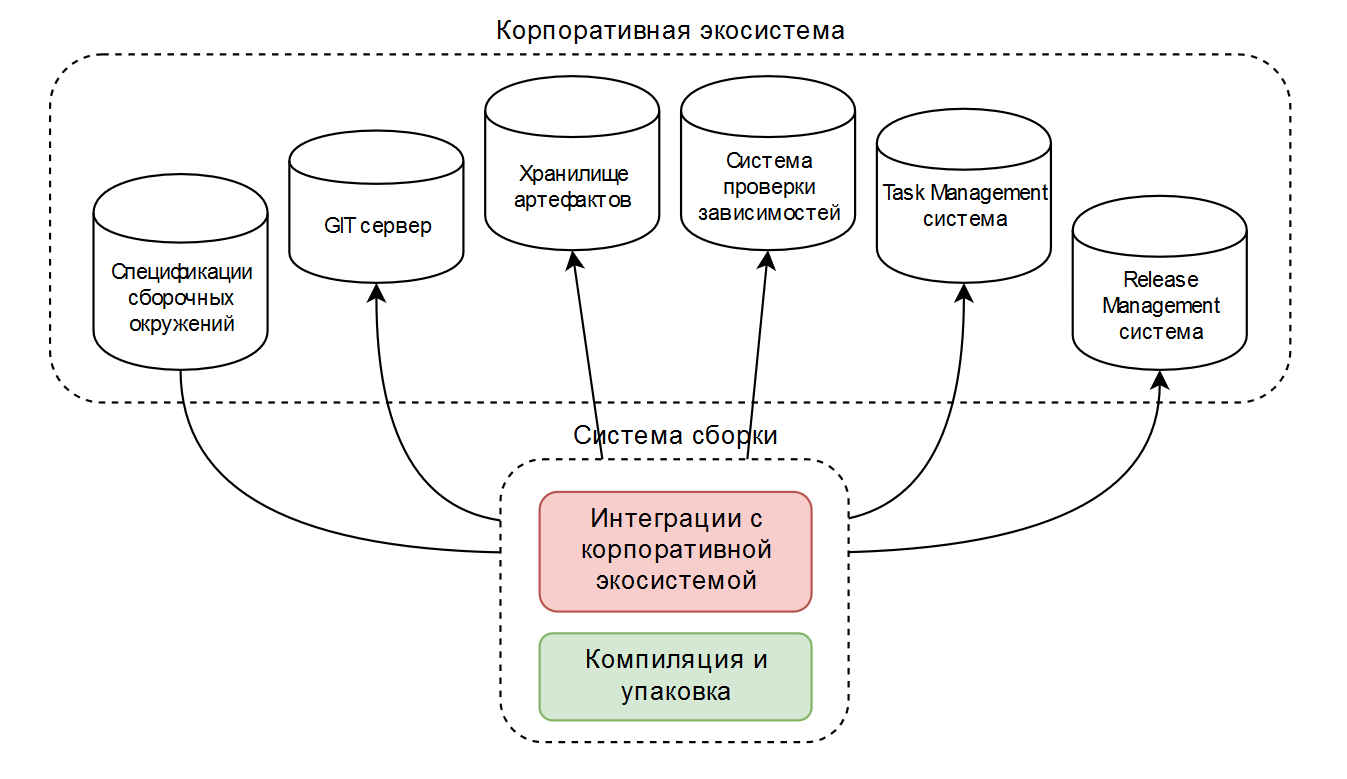
La herramienta de compilación suele ser hormiga o experto, y algo se implementa mediante complementos disponibles públicamente, algo se escribe solo. Esto funciona bien cuando una empresa utiliza un conjunto limitado de tecnologías.
Los microservicios difieren de las aplicaciones monolíticas principalmente en la variedad de tecnologías.
Resulta muchas configuraciones de ensamblaje para al menos cada lenguaje de programación. El control centralizado se vuelve imposible.
Es necesario simplificar los scripts de ensamblaje tanto como sea posible y permitir a los desarrolladores editarlos de forma independiente.
Además de la compilación y el empaquetado simples (en el diagrama en verde ), estos scripts contienen mucho código para la integración con el ecosistema corporativo (en el diagrama en rojo ).
Por lo tanto, se decidió percibir el ensamblaje como una "caja negra", en la que un entorno de ensamblaje "inteligente" puede resolver todos los problemas, excepto la compilación y el embalaje en sí.
Al comienzo del trabajo no estaba claro cómo obtener dicho sistema. Tomar decisiones arquitectónicas para las tareas de DevOps requiere experiencia y conocimiento. ¿Cómo conseguirlos? Las opciones posibles están a continuación:
- Busca información en Internet.
- Experiencia propia y conocimiento del equipo de DevOps. Para hacer esto, es bueno hacer que este equipo de programadores tenga una experiencia versátil.
- Experiencia y conocimiento adquiridos fuera del equipo de DevOps. Muchos desarrolladores de la empresa tienen buenas ideas: debe escucharlas. La comunicación es útil.
- ¡Inventamos y experimentamos!
¿Necesito automatización?
Para responder a esta pregunta, debe comprender en qué etapa de la evolución se encuentran nuestros enfoques de ensamblaje. En general, una tarea pasa por los siguientes niveles.
- Nivel inconsciente

Necesitamos lanzar un ensamblaje por semana, nuestros muchachos están bien. Esto es natural, ¿por qué hablar de eso?
- El nivel de "artesano", que finalmente se transforma en el nivel de "esquivador"

Es necesario producir dos ensamblajes por día de manera estable y sin errores. Tenemos a Vasya, lo hace bien, y nadie más que él gasta esta vez.
- Nivel de manufactura

Las cosas han ido muy lejos. Necesitas 20 asambleas por día, Vasya no puede hacer frente, y ahora un equipo de diez personas ya está sentado. Tienen un jefe, planes, vacaciones, baja por enfermedad, motivación, trabajo en equipo, entrenamientos, tradiciones y reglas. Esta es una especialización, su trabajo debe ser estudiado.
En este nivel, la tarea se separa del ejecutor concreto y, por lo tanto, se convierte en un proceso.
El resultado será una descripción clara, resuelta, corregida y corregida cientos de veces del proceso con texto.
- El nivel de "producción automatizada"

Los requisitos modernos para los ensamblajes están creciendo: todo debe ser rápido, confiable, se deben proporcionar 800 ensamblajes por día. Esto es crítico, porque sin tales volúmenes la empresa perderá ventajas competitivas.
Se está produciendo una costosa automatización, y un par de DevOps calificados pueden mantener el proceso en ejecución. La ampliación adicional ya no es un problema.
No todas las tareas deben alcanzar la última etapa de la automatización.
A menudo, un artesano con una línea de comando resolverá los problemas de manera fácil y efectiva.
La automatización "congela" el proceso, reduce el costo de operación y aumenta el costo del cambio.
Puede ir inmediatamente al ensamblaje del automóvil, pero el sistema será inconveniente, no mantendrá el ritmo de los requisitos del negocio y, como resultado, quedará obsoleto.
¿Qué son los ensamblajes y por qué el problema no se resuelve con sistemas de ensamblaje prefabricados?

Utilizamos la siguiente clasificación para determinar los niveles de agregación de ensamblaje.
L1 Una pequeña parte independiente de una gran aplicación. Puede ser un componente, microservicio o una biblioteca auxiliar. El ensamblaje L1 es una solución a problemas técnicos lineales: compilación, empaquetado, trabajo con dependencias. Maven, gradle, npm, grunt y otros sistemas de compilación hacen un gran trabajo al respecto. Hay cientos de ellos.
El ensamblaje L1 se debe realizar con herramientas de terceros ya preparadas.
L2 +. Entidades de integración. Las entidades L1 se combinan en formaciones más grandes, por ejemplo, en aplicaciones de microservicio completas. Varias de estas aplicaciones se pueden agrupar como una solución única. Usamos el signo "+", porque dependiendo del nivel de agregación de ensamblaje, se puede asignar un nivel de L3 o incluso L4.
Un ejemplo de tales ensamblajes en el mundo de terceros es la preparación de distribuciones de Linux. Metapaquetes allí.
Además de tareas técnicas bastante complejas (como esta: ru.wikipedia.org/wiki/Dependency_hell ). Los ensamblajes L2 + son a menudo el producto final y, por lo tanto, tienen muchos requisitos de proceso: un sistema de derechos, fijación de personas responsables, ausencia de errores legales, suministro de diversos documentos.
En L2 +, la automatización prioriza los requisitos del proceso.
Si la solución automática no funciona, ya que es conveniente para las personas interesadas, no se implementará.
Los ensamblajes L2 + probablemente se realizarán mediante una herramienta patentada diseñada específicamente para los procesos de la compañía. ¿Crees que los gestores de paquetes de Linux solo piensan en eso?
Nuestras mejores practicas
La infraestructura
Disponibilidad permanente de hierro.
Toda la infraestructura de ensamblaje se encuentra en servidores cerrados dentro de la red corporativa. En algunos casos, los servicios comerciales en la nube son posibles.
Autonomía
En todos los procesos de CI, Internet no está disponible. Todos los recursos necesarios se reflejan y almacenan en caché internamente. Parcialmente, incluso github.com (¡gracias, npm!) La mayoría de estos problemas los resuelve Artifactory.
Por lo tanto, estamos tranquilos cuando eliminamos artefactos de Maven Central o cerramos repositorios populares. Hay un ejemplo: community.oracle.com/community/java/javanet-forge-sunset .
La duplicación reduce significativamente el tiempo de ensamblaje, libera el canal corporativo de Internet. Menos recursos críticos de red aumentan la estabilidad de la construcción.
Tres repositorios para cada tipo de artefacto.
- Dev es un repositorio donde cualquiera puede publicar artefactos de cualquier origen. Aquí puede experimentar con enfoques fundamentalmente nuevos sin adaptarlos a los estándares corporativos desde el primer día.
- La puesta en escena es un repositorio poblado solo con una tubería de ensamblaje.
- Lanzamiento: conjuntos individuales, listos para entrega externa. Se llena con una operación de transferencia especial con confirmación manual.
Regla de 30 días
Desde los repositorios de Dev y Staging, eliminamos todo lo anterior a 30 días. Esto ayuda a garantizar que todos tengan las mismas oportunidades de publicación al gastar una cantidad finita de espacio en el disco del servidor.
La versión se almacena para siempre, el archivado se realiza si es necesario.
Entorno de montaje limpio
A menudo, después de los ensamblajes, los archivos auxiliares permanecen en el sistema, lo que puede afectar otros procesos de ensamblaje. Ejemplos tipicos:
- el problema más común es un caché dañado por un ensamblaje incorrecto (cómo tratar los cachés, que se describe a continuación);
- algunas utilidades, como npm, dejan los archivos de servicio en el directorio $ HOME que afectan todos los lanzamientos posteriores de estas utilidades;
- un ensamblado particular puede gastar todo el espacio en disco en alguna partición / tmp, lo que conducirá a una falta de disponibilidad general del entorno.
Por lo tanto, es mejor abandonar el entorno unificado a favor de los contenedores acoplables. Los contenedores deben contener solo el software necesario para un ensamblaje específico con versiones fijas.
DevOps mantiene una colección de imágenes acoplables de ensamblaje, que se actualiza constantemente. Al principio había unos seis, luego tenía menos de 30, luego configuramos la generación automática de imágenes de la lista de software. Ahora solo especifique requisitos como require ('maven 3.3.9', 'python') y el entorno está listo.
Autodiagnóstico
No solo es necesario organizar el soporte de los usuarios para las solicitudes, también debemos analizar el comportamiento de nuestro propio sistema. Constantemente recopilamos registros, buscamos en ellos palabras clave que muestren problemas.
En un sistema "en vivo", es suficiente escribir de 20 a 30 expresiones regulares para que para cada ensamblaje pueda decir la razón de su caída en el nivel:
- Bloqueo del servidor Git
- el espacio en disco se ha agotado;
- error de compilación debido a la falla del desarrollador;
- Error conocido en Docker.
Si algo ha caído, pero no se ha detectado un solo problema conocido, esta es una ocasión para reponer la colección de máscaras.
Luego vamos al usuario y le decimos que tiene una compilación y esto se puede solucionar de esta manera.
Se sorprenderá de la cantidad de problemas que los usuarios no informan en soporte. Es mejor repararlos por adelantado y en un momento conveniente. A menudo, un error de publicación menor se ignora durante dos semanas, y el viernes por la noche resulta que esto bloquea la salida externa.
Elegimos cuidadosamente de qué sistemas depende el ensamblaje
Idealmente, en general, garantizar la autonomía completa del ensamblaje, pero la mayoría de las veces esto es imposible. Para los ensamblados basados en Java, necesita al menos un artefacto para la duplicación; consulte la autonomía anterior. Cada sistema integrado aumenta el riesgo de falla. Es deseable que todos los sistemas funcionen en modo HA decente.
Interfaz de línea de montaje
Interfaz única para llamar al ensamblaje
Realizamos cualquier tipo de montaje con un solo sistema. Las asambleas de todos los niveles (L1, L2 +) se describen por código de programa y se llaman a través de un trabajo de Jenkins.
Sin embargo, este enfoque no es ideal. Es mejor utilizar los mecanismos de generación automática de trabajos de Jenkins: por ejemplo, 1 trabajo = 1 repositorio git o 1 trabajo = 1 rama git. Esto logrará lo siguiente:
- los registros de conjuntos heterogéneos no se confunden en una historia en la página de trabajo de Jenkins;
- de hecho, obtienes trabajos asignados cómodos para un equipo o para un desarrollador; La sensación de comodidad se puede mejorar ajustando los gráficos de los resultados de junit, cobertura, sonar.
Libertad para elegir tecnología
Iniciar la compilación es una llamada al script de bash "./build.sh". Y luego, cualquier sistema de ensamblaje, lenguajes de programación y todo lo demás que se necesitará para completar una tarea comercial. Esto proporciona un enfoque para el ensamblaje como una caja negra.
Publicación inteligente
La línea de montaje intercepta las publicaciones de la caja negra y las coloca en el almacenamiento corporativo. Para esto, se resuelven automáticamente problemas aburridos como la generación de nombres de imágenes de acoplador y la elección del repositorio adecuado para su publicación.
Los repositorios de puesta en escena y lanzamiento siempre tienen orden. Se requiere para soportar los detalles de publicaciones de diferentes tipos: maven, npm, file, docker.
Descriptor de montaje
Build.sh describe cómo compilar código, pero esto no es suficiente para un contenedor de ensamblaje.
También debes saber:
- qué entorno de montaje usar;
- variables de entorno disponibles en build.sh;
- qué publicaciones se realizarán;
- Otras opciones específicas.
Hemos elegido una manera conveniente de describir esta información en forma de un archivo yaml que se parece remotamente a .gitlab-ci.yaml.
Parametrización de montaje
El usuario puede especificar parámetros arbitrarios sin ejecutar el comando git commit justo al comienzo del ensamblaje.
Hemos implementado esto definiendo variables de entorno directamente desde la interfaz de trabajo de Jenkins.
Por ejemplo, transferimos la versión de la biblioteca dependiente a dicho parámetro de ensamblaje y, en algunos casos, redefinimos esta versión a alguna experimental. Sin dicho mecanismo, el usuario tendría que ejecutar el comando "git commit" cada vez.
Portabilidad del sistema
Debe poder reproducir el proceso de ensamblaje no solo en el servidor principal de CI, sino también en la computadora del desarrollador. Esto ayuda a depurar scripts de compilación complejos. Además, en lugar de Jenkins, a veces será más conveniente usar Gitlab CI. Por lo tanto, el sistema de compilación debe ser una aplicación Java independiente. Lo implementamos como un complemento de gradle.
Un artefacto se puede publicar con diferentes nombres.
Hay dos requisitos opuestos para la publicación que pueden surgir simultáneamente.
Por un lado, para el almacenamiento a largo plazo y la administración de versiones, es necesario garantizar la unicidad de los nombres de los artefactos publicados. Esto al menos protegerá los artefactos de ser sobrescritos.
Por otro lado, a veces es conveniente tener un artefacto real con un nombre fijo como último. Por ejemplo, el desarrollador no necesita conocer la versión exacta de la dependencia cada vez, solo puede trabajar con la última.
El artefacto en este caso se publica con dos o más nombres, ya que se adapta a todos.
Por ejemplo:
- un nombre único con una marca de tiempo o UUID, para aquellos que necesitan precisión;
- el nombre "último" - para sus desarrolladores, que siempre recogen el último código;
- el nombre "<versión principal> .x-latest" es para un equipo vecino que está listo para recoger las últimas versiones, pero solo dentro del marco de una determinada especialidad.
Maven hace algo similar en su enfoque de SNAPSHOT.
Menos restricciones de seguridad
Todos pueden comenzar el montaje. Esto no dañará a nadie, ya que el ensamblaje solo crea artefactos.
Cumplimiento legal
Control de interacciones externas del proceso de montaje.
El ensamblaje no puede usar nada prohibido en el proceso de su trabajo.
Para esto, se implementa el registro del tráfico de red y el acceso a los cachés de archivos. Obtenemos el registro de la actividad de red del ensamblaje en forma de una lista de URL con hashes sha256 de los datos recibidos. Además, cada url se valida:
- lista blanca estática;
- base de datos dinámica de artefactos permitidos (por ejemplo, para dependencias de maven-, rpm-, npm-). Cada adicción se considera individualmente. Un permiso automático o una prohibición de uso puede funcionar, y también puede comenzar una larga discusión con los abogados.
Contenido transparente de los artefactos publicados.
A veces, la tarea es proporcionar una lista de software de terceros dentro de cualquier ensamblaje. Para hacer esto, crearon un analizador de composición simple que analiza todos los archivos y archivos en el ensamblado, reconoce al tercero por hash y hace un informe.
El código fuente emitido no se puede eliminar de GIT
A veces es posible que necesite encontrar el código fuente mirando el artefacto binario compilado hace dos años. Para hacer esto, es necesario asignar etiquetas en Git automáticamente con salida externa, así como prohibir su eliminación.
Logistica y Contabilidad
Todos los ensamblajes se almacenan en la base de datos.
Usamos el repositorio de archivos en Artifactory para estos fines. Contiene toda la información de respaldo: quién lo lanzó, cuáles fueron los resultados de los controles, qué artefactos se publicaron, qué git hash se utilizó, etc.
Sabemos cómo reproducir el ensamblaje con la mayor precisión posible
Según los resultados del montaje, almacenamos la siguiente información:
- el estado exacto del código que se recopiló;
- con qué parámetros se realizó el lanzamiento;
- qué comandos se llamaron;
- qué acceso a los recursos externos ocurrió;
- entorno de montaje usado.
Si es necesario, podemos responder con precisión la pregunta de cómo se ensambló.
Comunicación bidireccional de la asamblea con el boleto JIRA
Asegúrese de poder resolver los siguientes problemas:
- para el ensamblaje, cree una lista de boletos JIRA incluidos en él;
- escriba en el boleto JIRA en qué ensambles está incluido.
Se proporciona una estrecha comunicación bidireccional entre el ensamblado y git commit. Y luego, a partir del texto de los comentarios, ya puede encontrar todos los enlaces a JIRA.
Velocidad
Sistema de montaje de cachés
La ausencia de un caché experto puede aumentar el tiempo de construcción en una hora.
El caché viola el aislamiento del entorno del ensamblaje y la limpieza del ensamblaje. Este problema se puede resolver determinando su origen para cada artefacto almacenado en caché. Tenemos cada archivo de caché asociado con un enlace https desde el que se descargó una vez. Además, procesamos la lectura de un caché como dirección de red.
Cachés de recursos de red
El crecimiento geográfico de la empresa lleva a la necesidad de transferir archivos de 300 MB entre continentes. Se gasta mucho tiempo, especialmente si tiene que hacer esto con frecuencia.
Repositorios de Git, imágenes acoplables de entornos de ensamblaje, almacenamiento de archivos: todo debe almacenarse en caché cuidadosamente. Bueno, por supuesto, periódicamente limpio.
Montaje - lo más rápido posible, todo lo demás - luego
La primera etapa: hacemos el montaje e inmediatamente, sin gestos innecesarios, damos el resultado.
La segunda etapa: validación, análisis, contabilidad y otra burocracia. Esto puede hacerse ya en un trabajo separado de Jenkins y sin límites de tiempo estrictos.
Cual es el resultado
- Lo principal es que el ensamblaje se ha vuelto claro para los desarrolladores , ellos mismos pueden desarrollarlo y optimizarlo.
- La base ha sido creada para construir procesos de negocio que dependen del ensamblaje: instalación, administración de problemas, pruebas, administración de versiones, etc.
- El equipo de DevOps ya no escribe scripts de ensamblaje: los desarrolladores lo hacen.
- Los requisitos corporativos complejos se convirtieron en un informe transparente con una lista final de verificaciones.
- Cualquiera puede construir cualquier repositorio simplemente llamando a build.sh a través de una única interfaz. Es suficiente para él simplemente especificar las coordenadas git del código fuente. Esta persona puede ser gerente de equipo, ingeniero de control de calidad / TI, etc.
Y unos pocos números
- . 15 Jenkins job build.sh. 15 docker-, , . . .
- . . 2200 . — on-commit-.
- 300 git-, .
- 30 , (25 ) — docker.
- , :
- glide, golang, promu;
- maven, gradle;
- python & pip;
- ruby;
- nodejs & npm;
- docker;
- rpm build tools & gcc;
- Android ADT;
- ;
- legacy-;
- .