Anteriormente
hablamos sobre la supercomputadora japonesa más poderosa para la investigación en física nuclear. Se está creando una supercomputadora exaflops Post-K en Japón: los japoneses serán de los primeros en lanzar una máquina con tanta potencia informática.
La puesta en servicio está prevista para 2021.
La semana pasada, Fujitsu habló sobre las características técnicas del chip A64FX, que formará la base de la nueva "máquina". Le diremos más sobre el chip y sus capacidades.
 / foto Toshihiro Matsui CC / computadora supercomputadora japonesa K
/ foto Toshihiro Matsui CC / computadora supercomputadora japonesa KEspecificaciones A64FX
Se espera que las capacidades informáticas de Post-K sean casi diez veces
más altas que el rendimiento de la supercomputadora
IBM Summit más potente (a
partir de junio de 2018 ).
La supercomputadora debe un rendimiento similar al chip basado en el brazo A64FX. Este chip
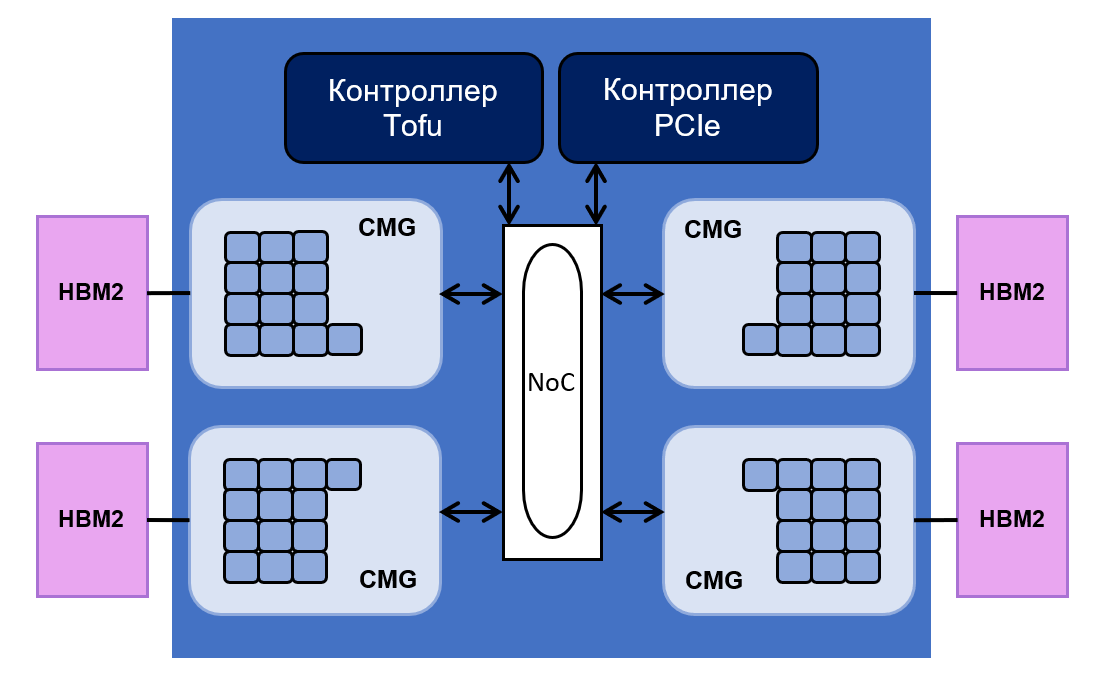
consta de 48 núcleos para operaciones informáticas y cuatro núcleos para controlarlos. Todos ellos están divididos de manera uniforme en cuatro grupos: Grupos de memoria central (CMG).
Cada grupo tiene 8 MB de caché L2. Está conectado al controlador de memoria y a la interfaz NoC ("
red en un chip "). NoC conecta varios CMG con controladores PCIe y Tofu. Este último es responsable de la comunicación entre el procesador y el resto del sistema. El controlador Tofu tiene diez puertos con un rendimiento de 12.5 GB / s.
El diseño del chip es el siguiente:
La memoria total
HBM2 del procesador es de 32 gigabytes, y su rendimiento es igual a 1024 GB / s. Fujitsu dice que el rendimiento del procesador en operaciones de coma flotante alcanza 2.7 teraflops para operaciones de 64 bits, 5.4 teraflops para 32 bits y 10.8 teraflops para 16 bits.
La creación de Post-K es monitoreada por los editores de recursos Top500, quienes compilan una lista de los sistemas informáticos más potentes. Según ellos, para lograr el rendimiento en un exaflops, se utilizan más de 370 mil procesadores A64FX en una supercomputadora.
El dispositivo usará primero la tecnología de extensión de vector llamada Extensión de vector escalable (SVE). Se diferencia de otras
arquitecturas SIMD en que no
limita la longitud de los registros vectoriales, sino que establece un rango válido para ellos. SVE admite vectores de 128 a 2048 bits de longitud. Por lo tanto, cualquier programa se puede ejecutar en otros procesadores que admitan SVE, sin la necesidad de volver a compilar.
Usando SVE (ya que es una función SIMD), el procesador puede realizar simultáneamente cálculos con varias matrices de datos. Aquí hay un ejemplo de una de estas instrucciones para la función NEON, que se usó para la computación vectorial en otras arquitecturas de procesador Arm:
vadd.i32 q1, q2, q3
Agrega cuatro enteros de 32 bits del registro q2 de 128 bits con los números correspondientes en el registro q3 de 128 bits y escribe la matriz resultante en q1. El equivalente de esta operación en C se ve así:
for(i = 0; i < 4; i++) a[i] = b[i] + c[i];
Además, SVE admite la vectorización automática. Un vectorizador automático analiza los ciclos en el código y, si es posible, utiliza registros vectoriales para ejecutarlos. Esto mejora el rendimiento del código.
Por ejemplo, una función en C:
void vectorize_this(unsigned int *a, unsigned int *b, unsigned int *c) { unsigned int i; for(i = 0; i < SIZE; i++) { a[i] = b[i] + c[i]; } }
Se compilará de la siguiente manera (para un procesador Arm de 32 bits):
104cc: ldr.w r3, [r4, #4]! 104d0: ldr.w r1, [r2, #4]! 104d4: cmp r4, r5 104d6: add r3, r1 104d8: str.w r3, [r0, #4]! 104dc: bne.n 104cc <vectorize_this+0xc>
Si usa la vectorización automática, se verá así:
10780: vld1.64 {d18-d19}, [r5 :64] 10784: adds r6, #1 10786: cmp r6, r7 10788: add.w r5, r5, #16 1078c: vld1.32 {d16-d17}, [r4] 10790: vadd.i32 q8, q8, q9 10794: add.w r4, r4, #16 10798: vst1.32 {d16-d17}, [r3] 1079c: add.w r3, r3, #16 107a0: bcc.n 10780 <vectorize_this+0x70>
Aquí, los registros SIMD q8 y q9 se cargan con datos de las matrices a las que apuntan r5 y r4. Después de eso, la instrucción vadd agrega cuatro valores enteros de 32 bits a la vez. Esto aumenta la cantidad de código, pero de esta manera se procesan muchos más datos para cada iteración del bucle.
¿Quién más crea supercomputadoras exaflops?
Las supercomputadoras Exaflops no solo se crean en Japón. Por ejemplo, también se está trabajando en China y Estados Unidos.
En China, crea Tianhe-3 (Tianhe-3). Su prototipo ya se
está probando en el Centro Nacional de Supercomputación en Tianjin. Se planea completar la versión final de la computadora en 2020.
 / foto O01326 CC / Tianhe-2 Supercomputadora - predecesora de Tianhe-3
/ foto O01326 CC / Tianhe-2 Supercomputadora - predecesora de Tianhe-3En el corazón de Tianhe-3 se
encuentran los procesadores de fitio chino. El dispositivo contiene 64 núcleos,
tiene un rendimiento de 512 gigaflops y un ancho de banda de memoria de 204.8 GB / s.
También se creó un prototipo funcional para una máquina de la serie
Sunway . Está siendo probado en el Centro Nacional de Supercomputadoras en Jinan. Según los desarrolladores, alrededor de 35 aplicaciones operan actualmente en la computadora; estos son simuladores biomédicos, aplicaciones para procesar grandes datos y programas para estudiar el cambio climático. Se espera que el trabajo en la computadora se complete en la primera mitad de 2021.
En cuanto a los Estados Unidos, los estadounidenses
planean crear su computadora exaflops para 2021. El proyecto se llama Aurora A21, y el
Laboratorio Nacional Argonne del Departamento de Energía de EE. UU. , Así como Intel y Cray están trabajando en ello.
Este año, los investigadores ya han
seleccionado diez proyectos para el Programa Aurora de Ciencias Tempranas, cuyos participantes serán los primeros en usar el nuevo sistema de alto rendimiento. Entre ellos había programas para crear un
mapa de neuronas cerebrales, estudiar la materia oscura y desarrollar un simulador de acelerador de partículas.
Las computadoras Exaflops permitirán construir modelos complejos para la investigación, por lo que muchos proyectos científicos esperan la creación de tales máquinas. Uno de los más ambiciosos es el Human Brain Project (HBP), cuyo objetivo es crear un modelo completo del cerebro humano y estudiar los cálculos neuromórficos. Según los científicos de HBP, el uso de nuevos sistemas exaflops se puede encontrar desde los primeros días de su existencia.
Lo que hacemos en IT-GRAD: • IaaS • Alojamiento de PCI DSS • Cloud -152
Contenido de nuestro Blog corporativo IaaS: