Esta primavera, se celebró un importante concurso retro de OpenAI, que se dedicó al aprendizaje de refuerzo, meta aprendizaje y, por supuesto, Sonic. Nuestro equipo ocupó el cuarto lugar de más de 900 equipos. El campo de entrenamiento con refuerzo es ligeramente diferente del aprendizaje automático estándar, y este concurso fue diferente de una competencia típica de RL. Pido detalles bajo cat.
TL; DR
Una línea de base ajustada adecuadamente no necesita trucos adicionales ... prácticamente.
Introducción en el entrenamiento de refuerzo
El aprendizaje reforzado es un área que combina la teoría del control óptimo, la teoría de juegos, la psicología y la neurobiología. En la práctica, el aprendizaje por refuerzo se utiliza para resolver problemas de toma de decisiones y buscar estrategias de comportamiento óptimas, o políticas que son demasiado complejas para la programación "directa". En este caso, el agente está capacitado en el historial de interacciones con el medio ambiente. El entorno, a su vez, al evaluar las acciones del agente, le proporciona una recompensa (escalar): cuanto mejor sea el comportamiento del agente, mayor será la recompensa. Como resultado, la mejor política se aprende del agente que ha aprendido a maximizar la recompensa total por todo el tiempo de interacción con el medio ambiente.
Como un simple ejemplo, puedes jugar BreakOut. En este viejo juego de la serie Atari, una persona / agente necesita controlar la plataforma horizontal inferior, golpear la pelota y romper gradualmente todos los bloques superiores con ella. Cuanto más derribado, mayor es la recompensa. En consecuencia, lo que ve una persona / agente es una imagen de pantalla y es necesario tomar una decisión en qué dirección mover la plataforma inferior.
Si está interesado en el tema de la capacitación de refuerzo, le aconsejo un curso introductorio genial de HSE , así como su contraparte de código abierto más detallada. Si quieres algo que puedas leer, pero con ejemplos, un libro inspirado en estos dos cursos. Revisé / completé / ayudé a crear todos estos cursos, y por lo tanto sé por mi propia experiencia que proporcionan una base excelente.
Sobre la tarea
El objetivo principal de esta competencia era conseguir un agente que pudiera jugar bien en la serie de juegos SEGA: Sonic The Hedgehog. OpenAI recién comenzaba a importar juegos de SEGA a su plataforma para entrenar a agentes de RL y, por lo tanto, decidió promover un poco este momento. Incluso el artículo fue lanzado con el dispositivo de todo y una descripción detallada de los métodos básicos.
Los 3 juegos de Sonic fueron compatibles, cada uno con 9 niveles, en los que, al mover una lágrima llorosa, incluso podrías jugar, recordando tu infancia (después de comprarlos en Steam primero).
El estado del entorno (lo que vio el agente) fue la imagen del simulador, una imagen RGB, y como acción se le pidió al agente que eligiera qué botón en el joystick virtual presionar: saltar / izquierda / derecha y así sucesivamente. El agente recibió puntos de recompensa, así como en el juego original, es decir. para recoger anillos, así como para la velocidad de pasar el nivel. De hecho, teníamos un sonic original frente a nosotros, solo que era necesario hacerlo con la ayuda de nuestro agente.
La competencia se llevó a cabo del 5 de abril al 5 de junio, es decir. solo 2 meses, lo que parece bastante pequeño. Nuestro equipo pudo reunirse e ingresar a la competencia solo en mayo, lo que nos hizo aprender mucho sobre la marcha.
Líneas de base
Como líneas de base, se proporcionaron guías de capacitación completas para la capacitación Rainbow (enfoque DQN) y PPO (enfoque de Gradiente de Políticas) en uno de los niveles posibles en Sonic y la presentación del agente resultante.
La versión Rainbow se basó en el proyecto anyrl poco conocido, pero PPO usó las viejas líneas de base de OpenAI y nos pareció mucho más preferible.
Las líneas de base publicadas diferían de los enfoques descritos en el artículo por su mayor simplicidad y conjuntos más pequeños de "hacks" para acelerar el aprendizaje. Por lo tanto, los organizadores arrojaron ideas y establecieron la dirección, pero la decisión sobre el uso y la implementación de estas ideas se dejó al participante en la competencia.
Con respecto a las ideas, me gustaría agradecer a OpenAI por su apertura, e individualmente a John Schulman por los consejos, ideas y sugerencias que expresó al comienzo de esta competencia. Nosotros, como muchos participantes (y aún más recién llegados al mundo de RL), esto nos permitió enfocarnos mejor en el objetivo principal de la competencia: el meta aprendizaje y la mejora de la generalización de agentes, de lo que hablaremos ahora.
Características de la evaluación de decisiones.
Lo más interesante comenzó a la hora de evaluar a los agentes. En las competencias / puntos de referencia típicos de RL, los algoritmos se prueban en el mismo entorno en el que fueron entrenados, lo que contribuye a algoritmos que son buenos para recordar y tienen muchos hiperparámetros. En el mismo concurso, la prueba del algoritmo se llevó a cabo en los nuevos niveles de Sonic (que nunca se mostraron a nadie), desarrollados por el equipo de OpenAI específicamente para este concurso. La guinda del pastel fue el hecho de que en el proceso de prueba, el agente también recibió una recompensa durante el paso del nivel, lo que hizo posible volver a entrenar directamente en el proceso de prueba. Sin embargo, en este caso valió la pena recordar que las pruebas fueron limitadas tanto en tiempo, 24 horas como en ticks del juego, 1 millón. Al mismo tiempo, OpenAI apoyó firmemente la creación de agentes que pudieran volver a entrenarse rápidamente a nuevos niveles. Como ya se mencionó, obtener y estudiar tales soluciones fue el objetivo principal de OpenAI durante esta competencia.
En el entorno académico, la dirección de estudiar políticas que pueden adaptarse rápidamente a las nuevas condiciones se llama meta aprendizaje, y en los últimos años se ha estado desarrollando activamente.
Además, en contraste con las competencias habituales de kaggle, donde todo el envío se reduce al envío de su archivo de respuestas, en esta competencia (y de hecho en las competencias de RL) el equipo debía envolver su solución en un contenedor acoplable con la API dada, recopilarla y enviarla Imagen del acoplador. Esto aumentó el umbral para ingresar a la competencia, pero hizo que el proceso de decisión fuera mucho más honesto: los recursos y el tiempo para la imagen del acoplador eran limitados, respectivamente, los algoritmos demasiado pesados y / o lentos simplemente no pasaron la selección. Me parece que este enfoque para la evaluación es mucho más preferible, ya que permite a los investigadores sin un "grupo doméstico de DGX y AWS" competir a la par con los amantes de los modelos 50000 de vidrio. Espero ver más de este tipo de competencia en el futuro.
El equipo
Kolesnikov Sergey ( scitator )
RL entusiasta. En el momento de la competencia, un estudiante del Instituto de Física y Tecnología de Moscú, MIPT, escribió y defendió un diploma de la competencia NIPS: Learning to Run del año pasado (un artículo sobre el cual también debe escribirse).
Senior Data Scientist @ Dbrain - Traemos al mundo real concursos listos para producción con docker y recursos limitados.
Pavlov Mikhail ( fgvbrt )
Desarrollador de Investigación Senior DiphakLab . Repetidamente participó y ganó premios en hackatones y competencias de entrenamiento reforzado.
Sergeev Ilya ( sergeevii123 )
RL entusiasta. Golpeé uno de los hackathons RL de Deephack y todo comenzó. Data Scientist @ Avito.ru - visión por computadora para varios proyectos internos.
Sorokin Ivan ( 1ytic )
Comprometido en el reconocimiento de voz en speechpro.ru .
Enfoques y solución
Después de una prueba rápida de las líneas de base propuestas, nuestra elección recayó en el enfoque OpenAI: PPO, como una opción más formada e interesante para desarrollar nuestra solución. Además, a juzgar por su artículo para esta competencia, el agente PPO se ocupó un poco mejor de la tarea. Del mismo artículo, nacieron las primeras mejoras que utilizamos en nuestra solución, pero lo primero es lo primero:
Entrenamiento colaborativo de PPO en todos los niveles disponibles
La línea base establecida se entrenó en solo uno de los 27 niveles de Sonic disponibles. Sin embargo, con la ayuda de pequeñas modificaciones, fue posible paralelizar el entrenamiento de una vez a los 27 niveles. Debido a la mayor diversidad en el entrenamiento, el agente resultante tuvo una generalización mucho mayor y una mejor comprensión del dispositivo del mundo de Sonic, y por lo tanto logró un orden de magnitud mejor.
Entrenamiento adicional durante las pruebas
Volviendo a la idea principal de la competencia, el metaaprendizaje, era necesario encontrar un enfoque que tuviera la máxima generalización y pudiera adaptarse fácilmente a los nuevos entornos. Y para la adaptación, fue necesario volver a capacitar al agente existente para el entorno de prueba, lo que, de hecho, se realizó (en cada nivel de prueba, el agente tomó 1 millón de pasos, que fue suficiente para adaptarse a un nivel específico). Al final de cada uno de los juegos de prueba, el agente evaluó el premio recibido y optimizó su política utilizando la historia que acaba de recibir. Es importante señalar aquí que con este enfoque es importante no olvidar toda su experiencia previa y no degradarse en condiciones específicas, lo que, en esencia, es el principal interés del meta aprendizaje, ya que dicho agente pierde inmediatamente toda su capacidad existente para generalizar.
Bonos de exploración
Profundizando en las condiciones de remuneración de un nivel, el agente recibió una recompensa por avanzar a lo largo de la coordenada x, respectivamente, podía quedar atrapado en algunos niveles, cuando primero tenía que avanzar y luego retroceder. Se decidió hacer una adición a la recompensa para el agente, la llamada exploración basada en el conteo , cuando el agente recibió una pequeña recompensa si estaba en un estado en el que aún no se encontraba. Se implementaron dos tipos de bonificación de exploración: según la imagen y según la coordenada x del agente. El premio basado en la imagen se calculó de la siguiente manera: para cada ubicación de píxeles en la imagen, se contó cuántas veces se encontró cada valor para un episodio, el premio fue inversamente proporcional al producto en todas las ubicaciones de píxeles de cuántas veces se encontraron los valores en estos lugares para un episodio. La recompensa basada en la coordenada x se consideró de manera similar: para cada coordenada x (con cierta precisión) se contó cuántas veces estuvo el agente en esta coordenada para el episodio, la recompensa es inversamente proporcional a esta cantidad para la coordenada x actual.
Experimentos mixtos
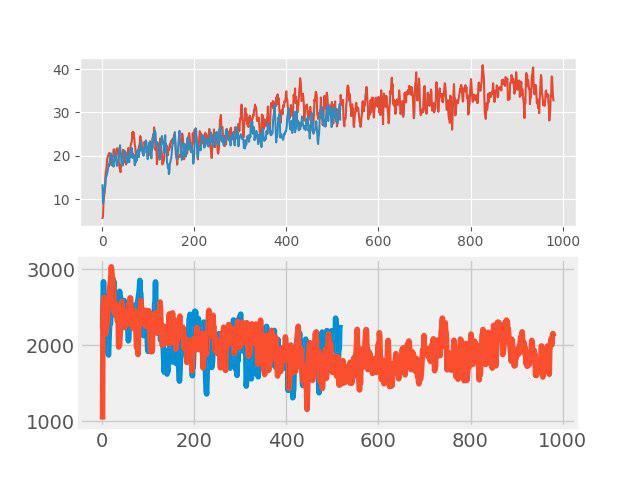
En “enseñar con un maestro” recientemente, un método simple pero efectivo de aumento de datos, el llamado confusión La idea es muy simple: se agrega dos imágenes de entrada arbitrarias y se asigna una suma ponderada de las etiquetas correspondientes a esta nueva imagen (por ejemplo, 0.7 perro + 0.3 gato). En tareas como la clasificación de imágenes y el reconocimiento de voz, la confusión muestra buenos resultados. Por lo tanto, fue interesante probar este método para RL. El aumento se realizó en cada lote grande, que consta de varios episodios. Las imágenes de entrada se mezclaron en píxeles, pero con las etiquetas no todo fue tan simple. Los valores devueltos, valores y neglogpacs se combinaron mediante una suma ponderada, pero la acción (acciones) se eligió del ejemplo con el coeficiente máximo. Tal solución no mostró un aumento tangible (aunque, al parecer, debería haber un aumento en la generalización), pero no empeoró la línea de base. Los gráficos a continuación comparan el algoritmo PPO con confusión (rojo) y sin confusión (azul): en la parte superior está la recompensa durante el entrenamiento, en la parte inferior está la duración del episodio.
Selección de la mejor política inicial.
Esta mejora fue una de las últimas e hizo una contribución muy significativa al resultado final. A nivel de capacitación, se capacitaron varias políticas diferentes con diferentes hiperparámetros. En el nivel de prueba, para los primeros episodios, se probó cada uno de ellos, y para capacitación adicional, se eligió la política que dio la máxima recompensa de prueba para su episodio.
Bloopers
Y ahora sobre la cuestión de lo que se intentó, pero "no voló". Después de todo, este no es un nuevo artículo de SOTA para ocultar algo.
- Cambio de arquitectura de red: activación de SELU , auto-atención, bloques SE
- Neuroevolución
- Creando tus propios niveles de Sonic: todo estaba preparado, pero no había suficiente tiempo
- Meta-entrenamiento a través de MAML y REPTILE
- Conjunto de varios modelos y capacitación adicional durante la prueba de cada modelo usando muestreo de importancia
Resumen
Después de 3 semanas desde el final de la competencia, OpenAI publicó los resultados . En 11 niveles adicionales creados adicionalmente, nuestro equipo recibió un honorable 4to lugar, saltando del 8vo en una prueba pública y superando las líneas oscuras oscuras de OpenAI.
Los principales puntos distintivos que "volaron" en el primer 3ki:
- Sistema de acciones mejorado (creó sus propios botones, eliminó los adicionales);
- Investigación de estados a través de hash de la imagen de entrada;
- Más niveles de entrenamiento;
Además, quiero señalar que en este concurso, además de ganar, se alentó activamente la descripción de sus decisiones, así como los materiales que ayudaron a otros participantes, también hubo una nominación separada para esto. Lo cual, nuevamente, aumentó el concurso de lámparas.
Epílogo
Personalmente, me gustó mucho esta competencia, así como el tema del meta aprendizaje. Durante la participación, me familiaricé con una gran lista de artículos ( ni siquiera olvidé algunos de ellos) y aprendí una gran cantidad de enfoques diferentes que espero aplicar en el futuro.
En la mejor tradición de participar en la competencia, todo el código está disponible y publicado en github .