
En el
artículo anterior sobre el tema de la gestión de riesgos del estado, revisamos los conceptos básicos: por qué las autoridades estatales deben administrar los riesgos, dónde buscarlos y cuáles son los enfoques para evaluarlos. Hoy hablaremos sobre el proceso de análisis de riesgos: cómo identificar las causas de su ocurrencia e identificar a los infractores.
Evaluación de riesgos
Para evaluar el riesgo, incluso en el marco de un enfoque estático, aunque dinámico, debe encontrar sus causas, condiciones de ocurrencia y determinar las características principales: la probabilidad y el daño potencial de la implementación.
Tomemos, por ejemplo, el despacho de aduana: al importar cualquier producto al país, excepto por una variedad de información diferente (costo, peso, embalaje, remitente, destinatario, etc.), se debe hacer una declaración en la declaración de acuerdo con un clasificador especial: la nomenclatura de productos de la actividad económica extranjera (FEA). Este código para las mercancías determina el arancel de acuerdo con el arancel de aduana (tasas TN FEA +).
El arancel de aduanas es un clasificador complejo: a primera vista, algunas mercancías pueden atribuirse a diferentes códigos con diferentes tipos de derechos. Por ejemplo, puede lidiar con equipos de minería complejos solo profundizando en sus dibujos. De ahí la tentación del importador de declarar el código incorrecto (pero similar a la verdad) para pagar menos dinero al presupuesto.
Así que
identificamos el riesgo : la declaración de un código de producto poco confiable en la declaración para subestimar los pagos de aduanas. La razón es la presencia en el clasificador de posiciones "limítrofes" con diferentes tasas de derechos.
Es más difícil detectar las condiciones para la ocurrencia de tal riesgo, cuándo y con qué bienes sucede en la práctica. Para hacer esto, debe realizar
un análisis de riesgos : estudiar el historial de observaciones de los objetos de control, averiguar cuándo y quién declaró el código de producto incorrecto e identificar algunas características generales de estos casos. Esto permitirá formular
reglas para la gestión futura del riesgo: qué objetos atribuiremos al riesgo y a qué auditoría se someterá.
La forma más fácil de obtener estas reglas es confiar en el juicio experto de sus empleados.
Reglas de expertos
Dichas reglas para identificar riesgos son especialistas en la materia. Se guían por su experiencia laboral o resumen las opiniones de colegas que todos los días se encuentran con infractores. El resultado son juicios simples de la forma "si ... entonces ...".
La probabilidad de ocurrencia de riesgo y el daño potencial de la amenaza en este caso se determina "a simple vista" o por estimaciones aproximadas.
La ventaja de las reglas expertas es la facilidad de su compilación e interpretación por parte del hombre. La desventaja es que un gran número de personas, tanto infractores como sujetos respetables de actividad económica, pueden caer simultáneamente bajo la regla. Por lo tanto, la efectividad del control será baja. Al mismo tiempo, pasarán algunos infractores, en los que el experto no podrá detectar y tener en cuenta los patrones.
Por ejemplo, una regla experta para el control de aduanas nos dice que todos los lotes de manzanas con un valor por debajo de cierto umbral se relacionan con entregas de riesgo:

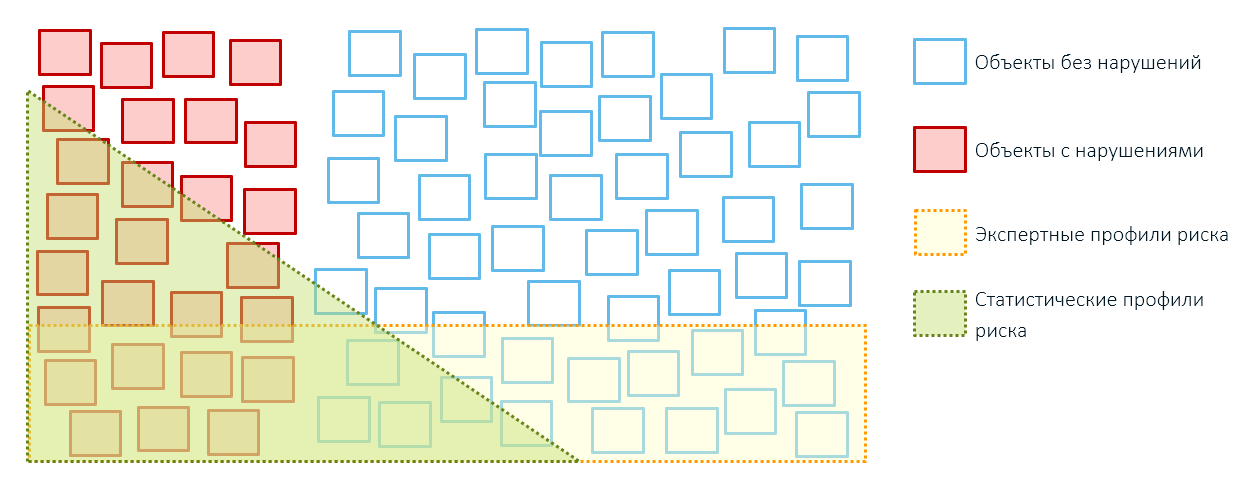
Cuando llevemos a cabo el control, encontraremos productos con irregularidades (rojo) y entregas bastante normales (verde), cuyo bajo costo se explica por descuentos individuales, la lucha del remitente con el exceso de existencias o el modelo económico de las empresas.
Cualquier cosa por encima de este umbral de valor condicional (línea roja) estará fuera de control (círculos grises). Pero si los verificamos también, encontraremos entregas verdaderamente legítimas y entregas cuyo valor real es incluso mayor que lo que se indicó en la declaración (círculos grises con un contorno punteado rojo) y para los cuales los pagos de aduanas no se pagan en su totalidad.
Por lo tanto, la aplicación de reglas expertas generalmente conduce a una cobertura excesiva de objetos de control y bajo rendimiento (recuerde, ¿nuestras cajas del primer artículo?):
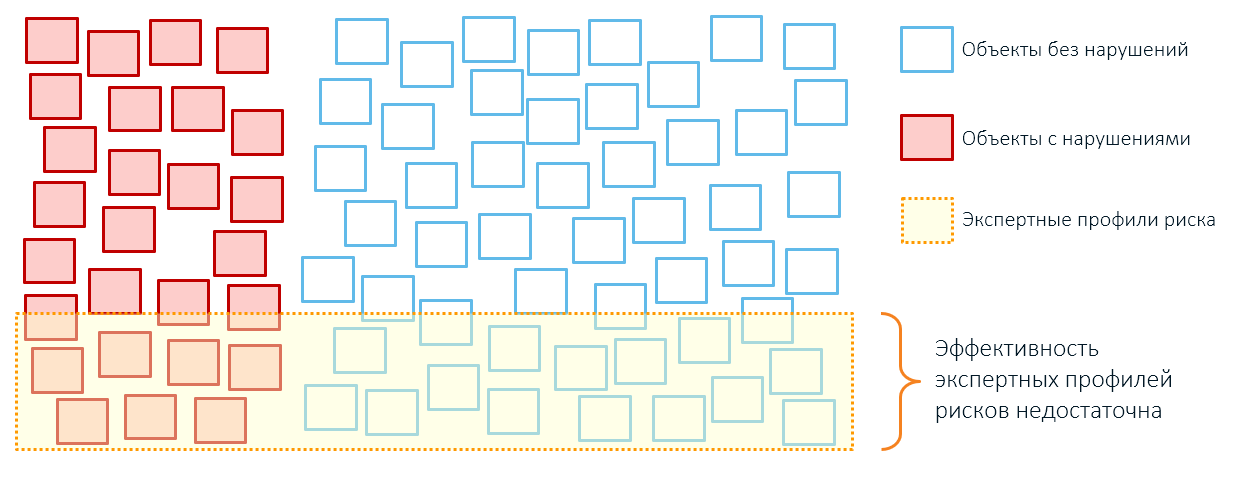
No se debe culpar a los expertos: la conciencia humana está limitada en los objetos con los que puede operar (una vez se publicó un curioso artículo sobre Habr, cuyo autor sugirió que su número se limita a siete). De ahí los grandes trazos en lugar de los detalles exactos: digamos, el riesgo de incendio se determina solo por el año en que se construyó el edificio, el área de ubicación y la categoría de residentes. Todas estas características una vez "jugadas": se produjo un incendio en una casa antigua, una habitación se incendió en un área disfuncional. Por lo tanto, los expertos esperan amenazas futuras precisamente de objetos de este tipo.
Pero no todos estos edificios "peligrosos" se van a quemar, incluso si caen bajo la regla de los expertos: muchas casas antiguas y de madera permanecen como si nada hubiera pasado. Algunas casas disfuncionales han estado sin fuego durante años. Es solo que el experto no pudo tener en cuenta algunas características individuales sutiles de los objetos peligrosos.
Aquí es donde entra en juego el aprendizaje automático que ayuda a crear
perfiles estadísticos de riesgo . Se forman cuando aplicamos tecnologías de análisis de datos al historial de violaciones e información sobre objetos controlados.
Perfiles estadísticos de riesgo
En este caso, resolvemos el problema de clasificación binaria: un algoritmo analítico especializado determina por sí mismo qué características de los objetos hacen posible atribuirlos a "malo" o "bueno". Si todo se hace correctamente, al final obtendremos evaluaciones de riesgo bastante precisas: condiciones detalladas y probabilidad calculada automáticamente más daño potencial (que, con un enfoque experto, también se determina de alguna manera "expertamente"). Estas características definen un "perfil de riesgo": qué, dónde, cuándo y qué miedo.
Los perfiles de riesgo estadísticos se crean de diferentes maneras. Puede basarse en un árbol de decisión o un bosque aleatorio. Puede aplicar una red neuronal complicada con una gran cantidad de capas ocultas.
Pero en SAS creemos que para el control del estado es mejor crear perfiles estadísticos de riesgo basados en algoritmos interpretados, por ejemplo,
regresión o
árbol de decisión . La práctica ha demostrado que es difícil para un organismo estatal orientarse incluso si es un pronóstico preciso pero incomprensible de una máquina, si no explica por qué esta persona respetada está marcada como villana.
La agencia estatal necesita comprender exactamente qué factores indican una amenaza y cuál de los infractores tiene las mismas características, ya que existen procedimientos para aprobar decisiones administrativas (un caso particular de los cuales son los perfiles de riesgo). El funcionario debe entender exactamente qué lanza "a la batalla", ya que es responsable del resultado del perfil de riesgo.
Cualquier verificación debe estar justificada y esta justificación debe expresarse en palabras. De lo contrario, debe sonrojarse ante el fiscal y explicar cómo resultó que la agencia estatal "pellizca" los negocios nacionales sobre la base de las misteriosas instrucciones de deus ex machina.
Por lo tanto, el perfil de riesgo estadístico también parece una regla que se puede leer y comprender. Solo la lista de características que describen posibles infractores es más grande y más compleja que la de los perfiles expertos:
 * Los valores de los parámetros de perfil se modifican y no corresponden a los reales.
* Los valores de los parámetros de perfil se modifican y no corresponden a los reales.Un conjunto de
indicadores de
riesgo (condiciones) puede parecer un poco extraño. Pero esto no es "gran hechicería": simplemente con la ayuda de las tecnologías de aprendizaje automático y la información limitada que tenemos, describimos algunos patrones ocultos del comportamiento humano que conducen a la interrupción.
Lo mismo está en el control fiscal: los infractores pueden distinguir de la masa total de contribuyentes ciertos rangos de montos de ciertas transacciones, plazos para presentar declaraciones, el número de empleados en el personal de la empresa, el número de cuentas y otro conjunto de 30 parámetros diferentes que describen colectivamente empresarios sin escrúpulos que subestiman el IVA.
Una persona no podrá comparar todas estas características, se las arreglará con tres o cinco, que son más fáciles de entender. Y el programa puede. Tan detallado como sea necesario. Al construir un modelo, el algoritmo itera automáticamente sobre una masa de datos y encuentra lo que los delincuentes tienen en común, incluso si es un amor por los lazos rojos en una red amarilla.
Esto es similar a la descripción del criminal en sus características individuales: la forma de la nariz, las orejas, la curvatura de las cejas, los colores de las camisas y la longitud del pie. No conocemos su rostro, altura y peso, pero tenemos miles de sus características, incluida la longitud de los pelos en la falange del dedo meñique izquierdo. Cada uno de estos parámetros individualmente no revela intenciones criminales: no necesita esposar a una persona solo por el radio de curvatura de sus aurículas. Pero el conjunto completo de estas características juntas forma un retrato bastante preciso del intruso:
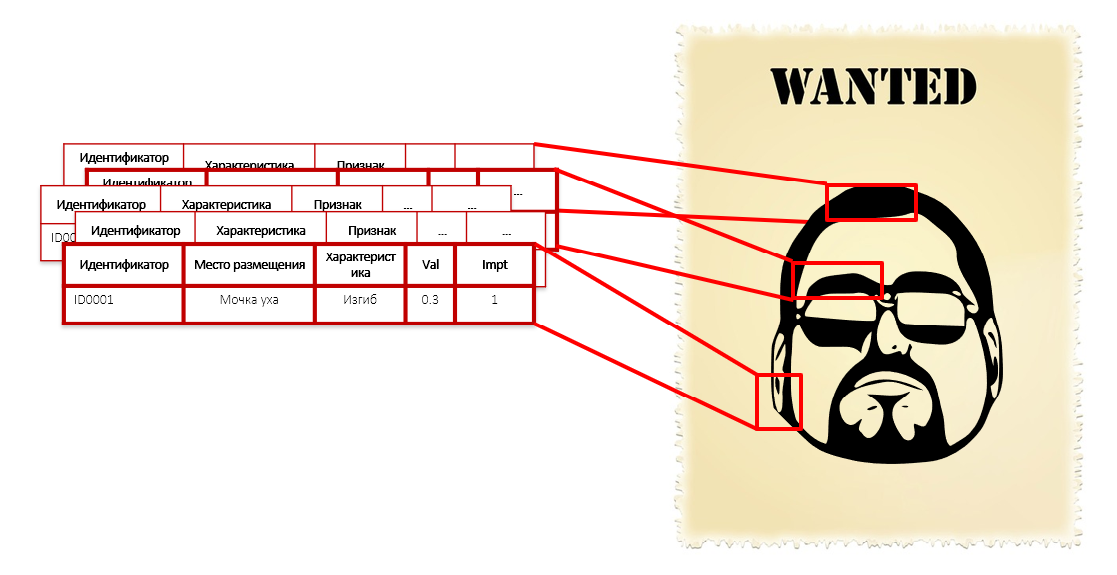
Cuando pasamos de aplicar reglas expertas a perfiles estadísticos basados en un análisis de patrones ocultos, nos deshacemos de las comprobaciones deliberadamente ineficaces. El enorme campo de control continuo se reduce a un punto de impacto en los objetos que caen bajo el
patrón revelado
de comportamiento injusto .
Recuerde las manzanas del ejemplo de aduanas anterior. Al enviar el historial de los controles a la entrada del modelo estadístico, obtenemos un perfil de riesgo que tiene en cuenta las características de comportamiento de los importadores-infractores, independientemente del precio al que declaran los productos:
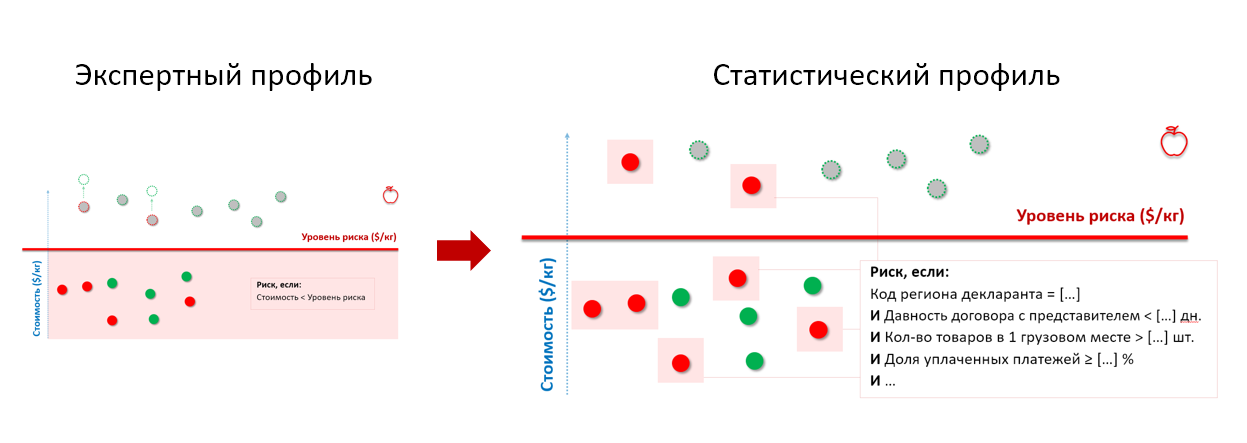 * el conjunto de parámetros del perfil de riesgo ha cambiado y no corresponde al real
* el conjunto de parámetros del perfil de riesgo ha cambiado y no corresponde al realAsí es como se construye el perfil de riesgo estadístico utilizando los algoritmos de la clase "árbol de decisión": cada nivel separa cada vez más el conjunto de entidades probadas en "bueno" y "malo" y muestra qué característica de separación resultó ser la más significativa (en la captura de pantalla de SAS Visual Statistics):
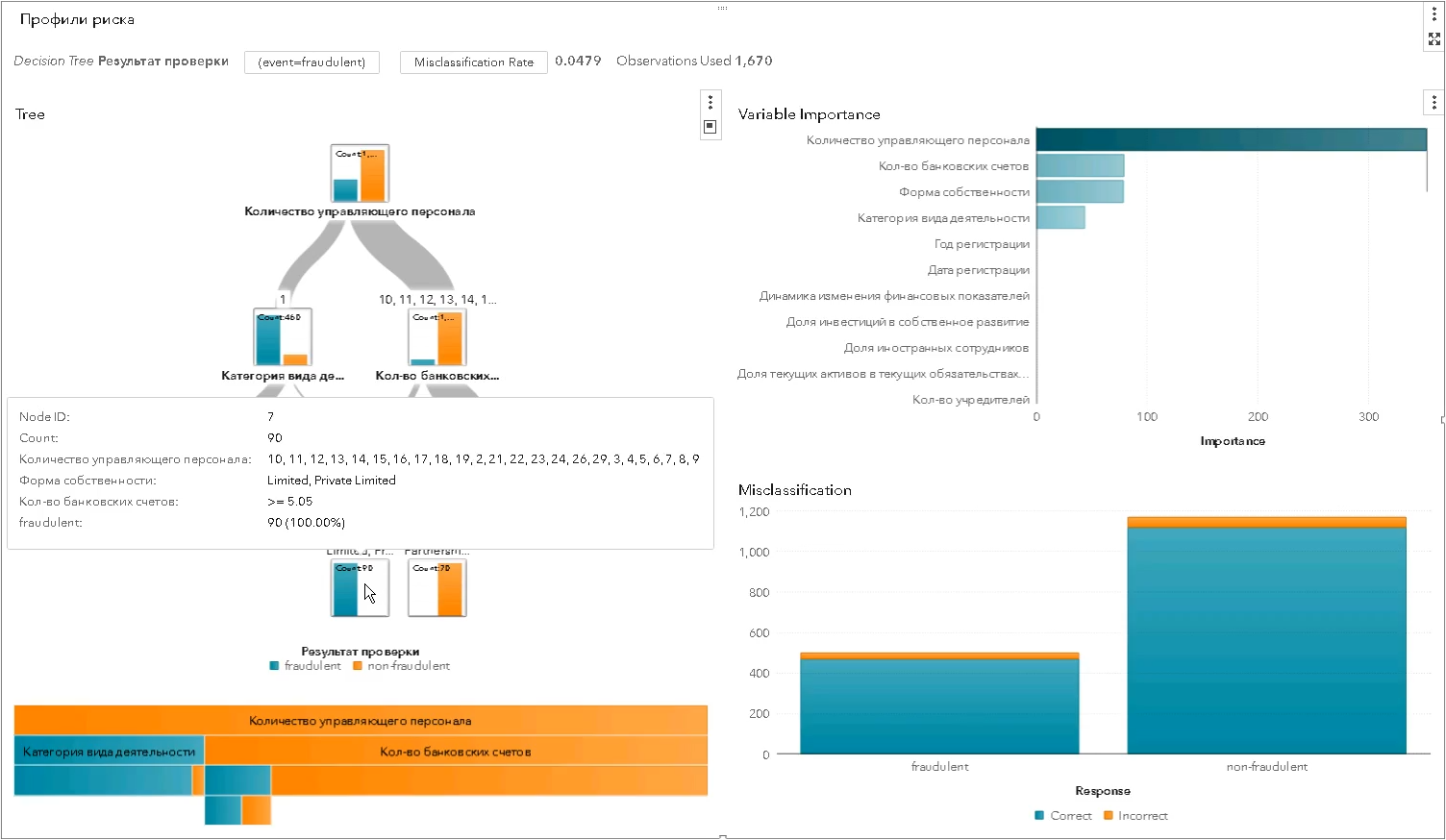
Los perfiles estadísticos son mejores que los expertos: más precisamente, más selectivos, imparciales. Ayudan a aumentar la efectividad de las inspecciones al reducir el número de "entrenamientos" inactivos:
La desventaja de los perfiles estadísticos es que están guiados por la experiencia pasada en la identificación de violaciones. A esquemas bien conocidos.
Si en la historia del control aduanero ha habido casos de subestimación al importar productos, el algoritmo encontrará signos de infractores y formará un perfil de riesgo estadístico. Si estamos buscando una nueva violación que aún no ha llegado a la atención de la agencia estatal, y no conocemos sus características, entonces tenemos que actuar "por tacto", por prueba y error.
Búsqueda desconocida
Puedes sentir lo desconocido de varias maneras.
El primero es
el muestreo aleatorio . Tomamos un objeto arbitrario (dentro de nuestros poderes), un producto, empresa, edificio o ciudadano, y lo consideramos cuidadosamente. El enfoque es bastante imparcial, pero no demasiado efectivo: un tema respetable también puede caer en "debriefing". La fuerza de la agencia estatal y el dinero del presupuesto se gastará en vano.
El segundo es la
identificación de anomalías . En este caso, se toma un objeto para verificación, cuyos parámetros se distinguen del resto. Cuando analizamos eventos anormales, y no solo "empujamos" aleatoriamente un grupo de objetos, la probabilidad de encontrar una violación es mayor.
Por ejemplo, cuando se realiza una supervisión ambiental, resulta que la planta consume inesperadamente mucha electricidad:
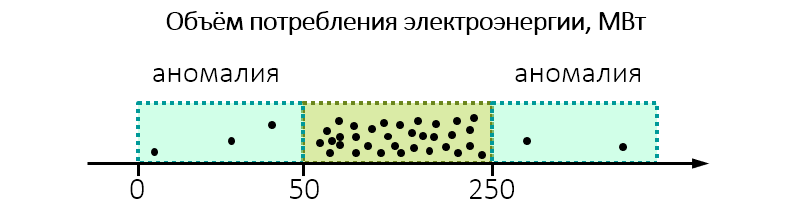
Quizás valga la pena echarle un vistazo más de cerca y comprobar si la planta no se descarga al agua o al aire más de lo permitido.
O los productos en la aduana tienen una proporción inusual del peso de los productos y el embalaje:
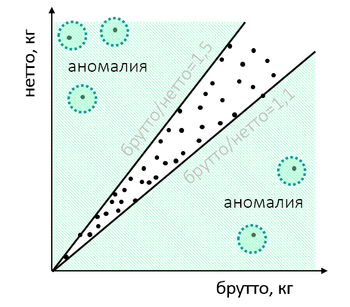
Después de verificar, puede resultar que el importador "jugó" con peso para cubrir algunas violaciones: subestimó el costo y por lo tanto quiso ajustar uno de los valores de prueba o emitir algunos bienes bajo la apariencia de otros. Las características de peso "natural", si cava bien, difieren de las ficticias.
Sin embargo, estos son los ejemplos más simples que una persona puede ver. En realidad, la búsqueda de anomalías se produce en un espacio multidimensional de atributos, puede haber cientos de ellos. El algoritmo hace lo que el humano no puede hacer: encuentra objetos que difieren significativamente de los demás al mismo tiempo en una gran cantidad de signos, y determina los llamados valores atípicos multidimensionales (en la captura de pantalla de SAS Visual Statistics):
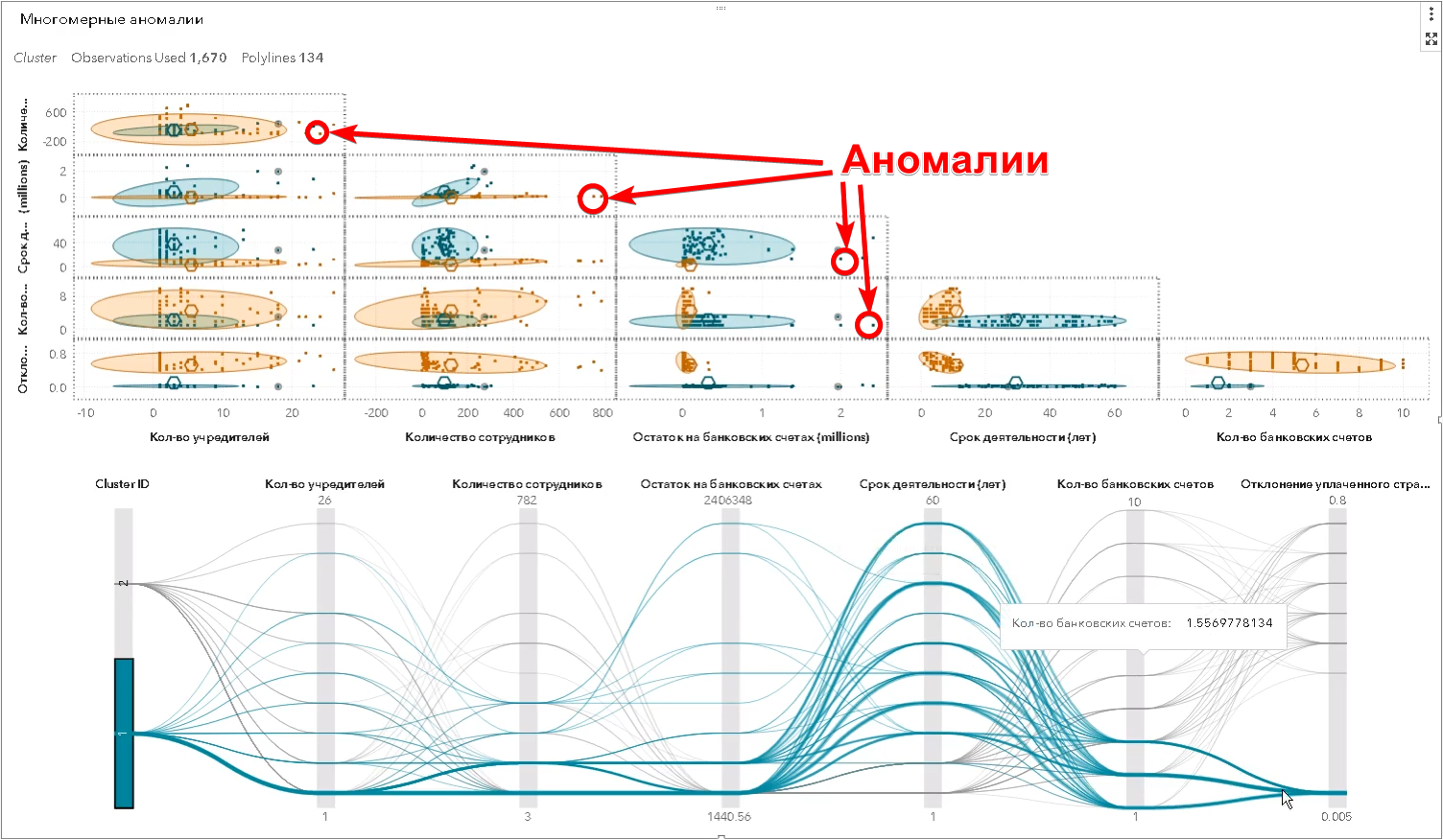
Además, más allá de los límites de la percepción humana, existe una variedad de relaciones legales entre diferentes compañías que se visualizan usando un gráfico (en la captura de pantalla de SAS Social Network Analysis):
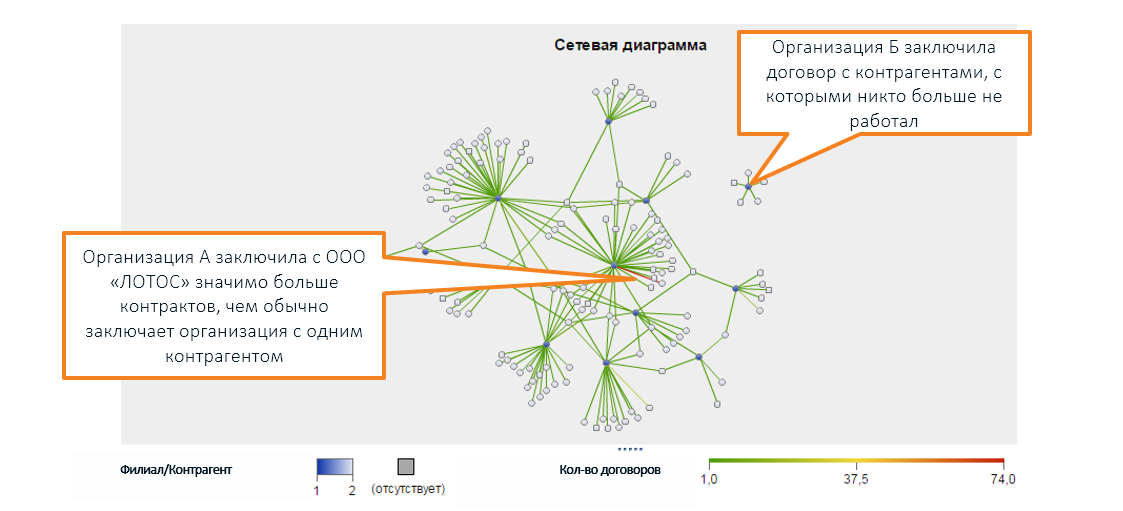 * se inventan nombres de organizaciones, las coincidencias con empresas reales son aleatorias
* se inventan nombres de organizaciones, las coincidencias con empresas reales son aleatoriasLas características inusuales no necesariamente indican un problema. La verificación puede no mostrar nada: sí, los indicadores son extraños, pero no hay violación.
Una anomalía no es un riesgo, es simplemente "algo inusual". Los perfiles de anomalías son necesarios para proporcionar nuevas "materias primas" para construir perfiles expertos o estadísticos, ya que el resultado de la verificación de anomalías se incluye en el historial de observaciones de los objetos bajo control.
Enfoque híbrido
Los mejores resultados en las actividades de control y supervisión de los organismos estatales (y no solo en él) se pueden lograr combinando los tres métodos de identificación de riesgos: reglas de expertos, perfiles estadísticos de riesgos basados en tecnologías de aprendizaje automático y perfiles de anomalías. Al mismo tiempo, es mejor reducir la cobertura de los objetos con reglas expertas, dejándolas solo para influencias administrativas específicas (por ejemplo, sanciones impuestas: bloqueamos productos de estos países):
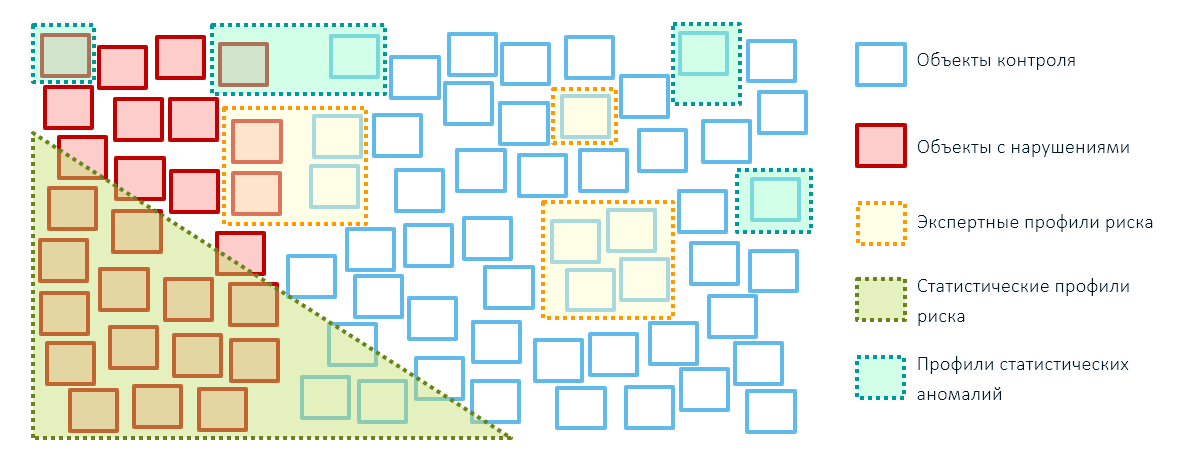
No puede prescindir de las reglas de expertos en la etapa inicial de construcción de un sistema de gestión de riesgos, ya que se necesita una base precedente para crear modelos analíticos. Para crearlo, será necesario realizar verificaciones basadas en perfiles de riesgo expertos y solo luego pasar a modelos matemáticos.
En SAS creemos que el futuro de la actividad de control y supervisión del estado se basa en un enfoque híbrido que combinará la experiencia de los organismos estatales y el conocimiento experto de sus empleados con tecnologías modernas de aprendizaje automático. En este caso, reducimos los resultados de los tres módulos en una evaluación de riesgos integrada:
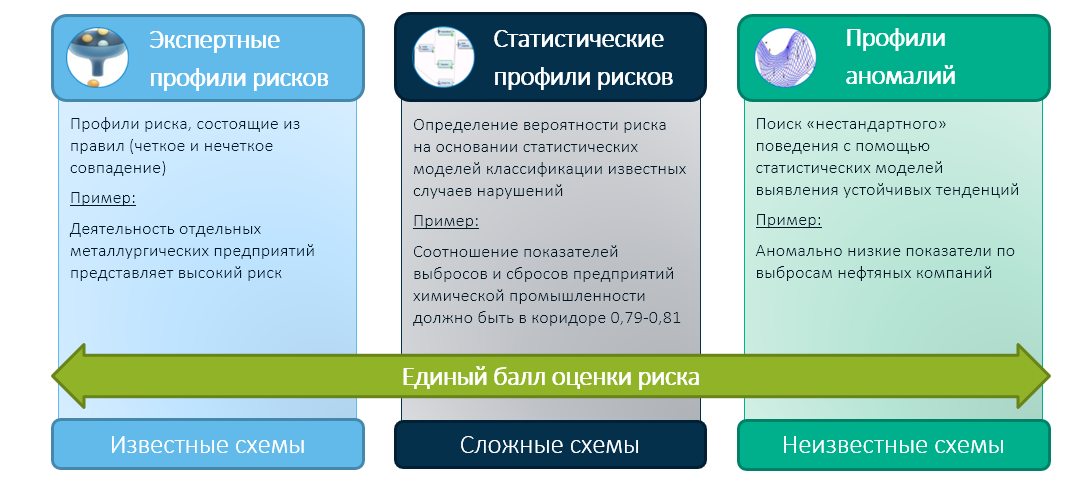
Y ya una evaluación integrada (por ejemplo, basada en una matriz de decisión experta) determina la elección del organismo de control: a quién verificar y en quién confiar.
En el próximo artículo, analizaremos métodos para minimizar las amenazas identificadas y pensaremos por qué la retroalimentación y la reevaluación dinámica del riesgo son tan importantes.