Como parte del soporte de productos, atendemos constantemente las solicitudes de los usuarios. Este es un proceso estándar. Y como cualquier proceso, debe ser evaluado y mejorado periódicamente de manera crítica.
Conocemos algunos problemas sistemáticos que sería bueno resolver y, si es posible, sin atraer recursos adicionales:
- Errores en el envío de aplicaciones: obtenemos algo "extraño", otros equipos a veces obtienen algo "nuestro".
- Es difícil evaluar la "complejidad" de la aplicación. Si la aplicación es compleja, se puede pasar a un analista fuerte, y con una simple, el principiante se las arreglará.
La solución a cualquiera de estos problemas afectará positivamente la velocidad de procesamiento de las aplicaciones.
La aplicación del aprendizaje automático, tal como se aplica al análisis del contenido de la aplicación, parece una oportunidad real para mejorar el proceso de envío.
En nuestro caso, el problema puede formularse mediante los siguientes problemas de clasificación:
- Asegúrese de que la solicitud esté asignada correctamente a:
- unidad de configuración (uno de los 5 dentro de la aplicación u "otros")
- categorías de servicio (incidente, solicitud de información, solicitud de servicio)
- Estime el tiempo esperado para cerrar la solicitud (como un indicador de alto nivel de "complejidad").
Qué y cómo trabajaremos
Para crear el algoritmo, usaremos el "conjunto estándar": Python con la biblioteca scikit-learn.
Para una aplicación real, se implementarán 2 escenarios:
Entrenamiento:
- obtener datos de "entrenamiento" del rastreador de aplicaciones
- ejecutar un algoritmo para entrenar un modelo, guardar un modelo
Uso:
- recibir datos del rastreador de aplicaciones para clasificación
- carga de modelos, clasificación de aplicaciones, guardar resultados
- Actualización de aplicaciones en el rastreador basado en la clasificación
Todo lo relacionado con la tubería (interacción con el rastreador) se puede implementar en cualquier cosa. En este caso, se escribieron scripts de PowerShell, aunque era posible continuar en Python.
El algoritmo de aprendizaje automático recibirá datos de clasificación / entrenamiento en forma de archivo .csv. Los resultados procesados también se enviarán a un archivo .csv.
Datos de entrada
Para que el algoritmo sea lo más independiente posible de la opinión de los equipos de servicio, tomaremos en cuenta solo los datos recibidos del creador de la aplicación como parámetros de entrada del modelo:
- Breve descripción / título (texto)
- Una descripción detallada del problema, si existe (texto). Este es el primer mensaje en el flujo de comunicación de la aplicación.
- Nombre del cliente (empleado, categoría)
- Nombres de otros empleados incluidos en la lista de observación a pedido (lista de empleados)
- Hora de presentación de la solicitud (fecha / hora).
Conjunto de datos de entrenamiento
Para entrenar los algoritmos, se utilizaron datos sobre llamadas cerradas en los últimos 3 años: ~ 3.500 registros.
Además, para enseñar al clasificador el reconocimiento de "otras" unidades de configuración, se agregaron al conjunto de capacitación las aplicaciones cerradas procesadas por otros departamentos para otras unidades de configuración. Total de registros adicionales: alrededor de 17,000.
Para todas esas solicitudes adicionales, la unidad de configuración se establecerá en "otro"
Pretratamiento
Texto
El preprocesamiento de texto es extremadamente simple:
- Traducimos todo a minúsculas
- Deje solo números y letras: reemplace el resto con espacios
Lista de notificaciones (lista de observación)
La lista está disponible para su análisis en forma de una cadena en la que los nombres se presentan en forma de Apellido, Nombre y están separados por un punto y coma. Para el análisis, lo convertiremos en una lista de cadenas.
Al combinar las listas obtenemos un conjunto de nombres únicos basados en todas las aplicaciones del conjunto de entrenamiento. Esta lista general formará un vector de nombres.
Duración del procesamiento de la solicitud
Para nuestros propósitos (gestión de prioridad, planificación de lanzamiento), es suficiente atribuir la aplicación a una clase determinada por la duración del servicio. También le permite transferir la tarea de regresión a clasificación con un pequeño número de clases.
Texto
- Combina el "título" y la "descripción del problema".
- Pase a TfidfVectoriser para formar un vector de palabra
Nombre del solicitante
Como se espera que la persona que creó la aplicación sea un atributo importante para una clasificación adicional, la traduciremos a una de codificación individual usando DictionaryVectorisor
Nombres de personas incluidas en la lista de notificaciones.
La lista de personas incluidas en las aplicaciones de la lista de observación se convertirá en un vector en base a todos los nombres preparados anteriormente: si la persona estaba en la lista, el componente correspondiente se establecerá en 1, de lo contrario, en 0. Una aplicación puede tener varias personas en la lista de observación, respectivamente, varios componentes tendrá un solo valor.
Fecha de creación
La fecha de creación se presentará como un conjunto de atributos numéricos: año, mes, día del mes, día de la semana.
Esto se realiza bajo el supuesto de que:
- La velocidad de procesamiento de la aplicación varía con el tiempo.
- La velocidad de procesamiento tiene un factor estacional
- El día de la semana (especialmente las aplicaciones de fin de semana) puede ayudar a identificar la unidad de configuración y la categoría de servicio.
Modelo de entrenamiento
Algoritmo de clasificación
Para las tres tareas de clasificación, se utilizó la regresión logística. Admite la clasificación multiclase (en el modelo One-vs-All), aprende con bastante rapidez.
Para capacitar modelos que definan la categoría de servicio y la duración de las aplicaciones de procesamiento, utilizaremos solo aplicaciones que obviamente pertenecen a nuestras unidades de configuración.
Resultados de aprendizaje
Definición de unidades de configuración
El modelo demuestra altos indicadores de integridad y precisión al asignar aplicaciones a unidades de configuración. Además, el modelo define bien los eventos cuando las aplicaciones se refieren a unidades de configuración ajenas.
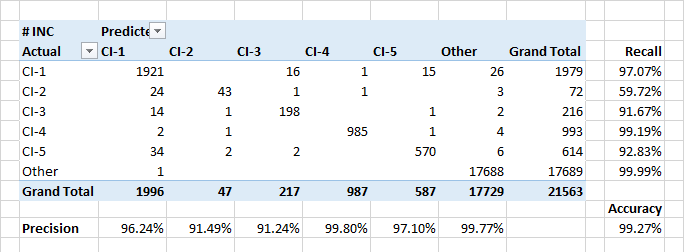
La completitud relativamente baja para la clase CI-2 se debe en parte a errores de clasificación reales en los datos. Además, los CI-2 presentan aplicaciones "técnicas" ejecutadas para otros CI. Entonces, en términos de descripción y los usuarios involucrados, tales aplicaciones pueden ser similares a las aplicaciones de otras clases.
¿Los atributos más significativos para clasificar aplicaciones como CI-? se esperaba que los nombres de los clientes de las aplicaciones y las personas se incluyeran en la hoja de alerta. Pero había algunas palabras clave que estaban en los primeros 30 ke en importancia. La fecha de creación de la aplicación no importa.
Definición de categoría de aplicación
La calidad de la clasificación por categorías resultó ser algo inferior.
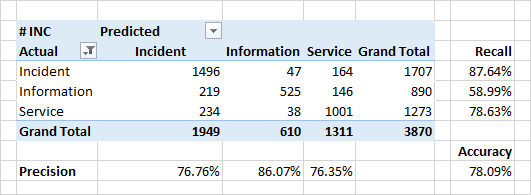
Una razón muy seria para la falta de coincidencia de las categorías y categorías predichas en los datos de origen son los errores reales en los datos de origen. Por varias razones organizativas, la clasificación puede ser incorrecta. Por ejemplo, en lugar de un "incidente" (un defecto en el sistema, un comportamiento inesperado del sistema), la aplicación puede marcarse como "información" ("esto no es un error, es una característica") o "servicio" ("sí, está roto, pero simplemente lo reiniciamos, y todo estará bien ").
La identificación de tales inconsistencias es una de las tareas del clasificador.
Los atributos importantes para la clasificación en el caso de las categorías son palabras del contenido de las aplicaciones. Para incidentes, estas son las palabras "error", "corregir", "cuándo". También hay palabras que denotan algunos módulos del sistema: estos son los módulos con los que los usuarios trabajan directamente y observan la aparición de errores directos o indirectos.
Curiosamente, para las aplicaciones que se definen como "servicio", las palabras principales también definen algunos módulos del sistema. Una ocasión para pensar, revisar y finalmente repararlos.
Determinar el tiempo de procesamiento de la solicitud.
Lo más débil fue predecir la duración del procesamiento de las solicitudes.
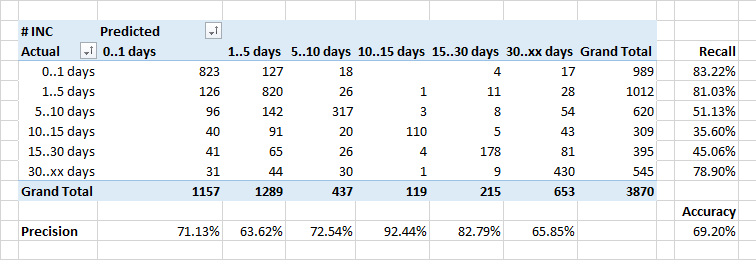
En general, la dependencia del número de aplicaciones que están cerradas durante un tiempo determinado debería ser idealmente inversa al exponente. Pero teniendo en cuenta el hecho de que algunos incidentes requieren correcciones en el sistema, y esto se hace como parte de los lanzamientos regulares, la duración de la ejecución de algunas aplicaciones aumenta artificialmente.
Por lo tanto, tal vez el clasificador clasifique algunas aplicaciones "largas" como "más rápidas": no conoce el momento de las versiones planificadas y cree que la aplicación debe cerrarse más rápido.
Esta es también una buena razón para pensar ...
Implementación del modelo como clase.
El modelo se implementa como una clase que encapsula todas las clases estándar de aprendizaje de scikit utilizadas: escala, vectorización, clasificador y configuraciones significativas.
La preparación, la capacitación y el uso posterior del modelo se implementan como métodos de clase, basados en objetos auxiliares.
La implementación de objetos le permite generar convenientemente versiones derivadas del modelo que usan otras clases de clasificadores y / o predicen los valores de otros atributos del conjunto de datos original. Todo esto se hace anulando los métodos virtuales.
Sin embargo, todos los procedimientos de preparación de datos pueden seguir siendo comunes a todas las opciones.
Además, la implementación del modelo en forma de un objeto permitió resolver naturalmente el problema del almacenamiento intermedio del modelo entrenado entre las sesiones de uso, a través de la serialización / deserialización.
Para serializar el modelo, se utilizó el mecanismo estándar de Python, pickle / unpickle.
Dado que le permite serializar varios objetos en el mismo archivo, esto ayudará a guardar consistentemente la recuperación de varios modelos incluidos en el flujo de procesamiento general.
Conclusión
Los modelos resultantes, aun siendo relativamente simples, dan resultados muy interesantes:
- identificó "omisiones" sistemáticas en la clasificación por categoría
- quedó claro qué partes del sistema están asociadas con problemas (aparentemente, no sin razón)
- Los tiempos de procesamiento de la solicitud dependen claramente de factores externos que deben mejorarse por separado.
Todavía tenemos que reconstruir los procesos internos basados en los "consejos" recibidos. Pero incluso este pequeño experimento hizo posible evaluar el poder de los métodos de aprendizaje automático. Y también, provocó un interés adicional del equipo en el análisis de su propio proceso y su mejora.