
La migración de sistemas de TI no es una tarea fácil. Pero la dificultad particular es la situación en la que no solo necesita cambiar de hierro viejo a nuevo, sino también pasar a un nuevo sistema operativo en el equipo existente y sin migrar datos productivos. Uno de esos movimientos duró aproximadamente un año, la mayoría de los cuales requirió preparación.
El cliente tiene dos sitios en diferentes ciudades, y cada uno tiene dos sistemas de almacenamiento de datos conectados. La información de un sistema de almacenamiento que utiliza las herramientas de replicación incorporadas se envía al segundo. La administración se realiza utilizando un sistema de respaldo externo. En una ciudad, se instalan dos sistemas NetApp 3250, en la otra: el NetApp 6220 principal y el NetApp 3250 de respaldo. El cliente planea expandir este complejo en el futuro, agregar discos y actualizar los controladores.
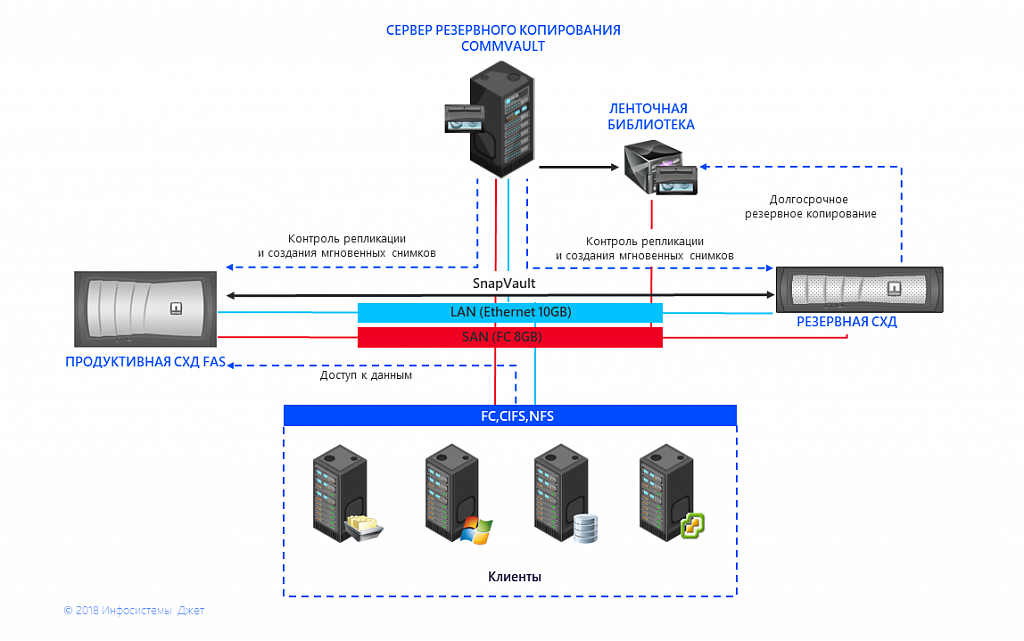 Fig. 1 Esquema de interacción de sistemas de almacenamiento e IBS
Fig. 1 Esquema de interacción de sistemas de almacenamiento e IBSY el principal problema está relacionado con esto: el fin del soporte. Para el sistema operativo Data ONTAP 8.2 7-Mode instalado en el sistema de almacenamiento, no ha habido actualizaciones importantes durante un par de años, y el lanzamiento de correcciones de errores críticos se detendrá en 2021. Las unidades y controladores más nuevos no son compatibles con el sistema operativo heredado.
La solución es la transición al sistema de clúster ONTAP 9.1 como último soporte para estos controladores de almacenamiento. Sus principales ventajas son:
- Escalado horizontal mediante la combinación en un solo clúster tolerante a fallas, que creará un único sistema basado en almacenamiento productivo y SRK.
- Equilibrio de carga entre controladores, discos, así como mover datos dentro del sistema de almacenamiento sin interrumpir el servicio y detener el acceso a las aplicaciones.
- Mantenimiento de hardware y software de sistemas de almacenamiento de datos sin interrupción de su trabajo e interrupción del servicio.
- La capacidad de crear configuraciones de clúster heterogéneas, incluidos controladores y discos de varios tipos, incluidos sistemas de almacenamiento de terceros, sujetos al uso de licencias para la virtualización de su capacidad de disco.
- Posibilidad de utilizar SSD como capa de caché para agregados.
- Operación optimizada de los mecanismos de compactación de datos (compresión y deduplicación).
Hay 3 opciones para migrar del modo 7 al modo de clúster:
- Migración con replicación de datos utilizando la herramienta de transición de 7 modos de Netapp (7MTT) y la transición basada en copia (CBT). Para esto, se requiere un segundo sistema de almacenamiento con un espacio en disco más pequeño y una replicación por fases basada en SnapMirror. Para cada servicio, la conmutación se coordina y se realiza en un momento dado.
En uno de nuestros clientes, ya hicimos este procedimiento en el clúster de metro. Debido a la gran cantidad de volúmenes, LUN (> 400) y la larga coordinación de detalles, tiempos de inactividad, etc. la migración tomó alrededor de 3 meses, excluyendo la capacitación. - Migre sin mover datos con la herramienta de transición de 7 modos de Netapp (7MTT) y la transición sin copia (CFT). Para hacer esto, necesita un segundo sistema de almacenamiento con un número mínimo de discos, que después de la preparación preliminar cambiará el subsistema de disco productivo. Para todos los servicios, se acuerda un gran tiempo de inactividad.
- Migración con copia de datos utilizando herramientas de host. Esta es la ruta de migración tradicional entre los sistemas de almacenamiento de cualquier fabricante.
Dado que los sistemas de almacenamiento existentes todavía estaban bajo el soporte del proveedor, y el rendimiento de los controladores en el futuro cercano era suficiente, el presupuesto para la compra de nuevos controladores no fue asignado. En este sentido, se decidió migrar los controladores al modo de clúster utilizando 7MTT CFT. Uno de los requisitos clave era la ausencia de interrupciones notables en la operación de los sistemas de almacenamiento: la mayoría de los sistemas deberían funcionar sin problemas durante la semana. Por lo tanto, el trabajo principal sobre migración en un sistema de almacenamiento productivo estaba programado para el fin de semana.
La fase de preparación comenzó con la recopilación de información del sistema de almacenamiento y la realización de controles preliminares. El software especializado NetApp 7MTT genera una lista de alertas que pueden interferir con la migración o no completarla. Por ejemplo, para uno de los sistemas, esta lista constaba de más de 200 elementos. Era necesario actualizar todos los sistemas a las últimas versiones compatibles del sistema operativo, actualizar el firmware de los controladores, los estantes de disco y los discos mismos. Además, el nuevo sistema operativo tiene una lógica de operación diferente, que requiere direcciones IP adicionales y conexiones entre sistemas de almacenamiento.
El factor de detención se descubrió con bastante rapidez: el cliente utilizó tecnología que no se basaba en la replicación de todo el volumen, sino en la replicación de qtree (una subsección a la que se aplican restricciones de acceso, volumen, etc.) Y es imposible migrar tales relaciones de SnapVault al nuevo sistema operativo . Como resultado, antes de comenzar a trabajar, sería necesario eliminar por completo todas las copias de replicación. Para garantizar que el cliente después del traslado no se quedara sin copias de seguridad, se inició una copia de seguridad basada en la replicación de todo el volumen antes de la migración. Con SnapMirror, se crearon nuevas copias de seguridad junto a las antiguas y se acumuló un registro de cambios en el transcurso de cuatro semanas. Y si en uno de los sitios había suficiente espacio para esto, en el segundo espacio era limitado, era necesario hacer copias gradualmente de uno de los volúmenes. Después de cuatro semanas, se eliminaron las viejas relaciones y se crearon otras nuevas. Un proceso por etapas bastante largo, que tomó alrededor de 1.5 meses en el caso de un sitio y más de 3 en el segundo. Además, quiero señalar que el procedimiento para detener la relación Snapvault se acompaña de la eliminación del qtree de destino y su velocidad de ejecución depende en gran medida del número de archivos y, en menor medida, de su tamaño. Por ejemplo, qtree con 4 millones de archivos y un tamaño de 500 GB se eliminó en 24 horas.
En el proceso, surgieron varias dificultades. La burocratización de los procesos de hacer cambios en los sistemas del cliente aumentó los términos de coordinación del trabajo. Afortunadamente, logramos acordar resolver problemas técnicos directamente, discutiendo en un nivel superior solo asuntos importantes, "ideológicos", como acordar un plan de trabajo y elegir fechas específicas para la migración.
Las dificultades fueron causadas por el uso de almacenamiento temporal. Bajo la guía de 7MTT, configuramos ambos sistemas de almacenamiento de acuerdo con los requisitos y las comprobaciones previas. Luego apagaron el viejo almacenamiento y conectaron los estantes del disco al nuevo. Revisé todo de nuevo. Desde el punto de vista del software de NetApp, el proceso de migración se completa y todos se dispersan
detrás del champán . Pero el siguiente paso fue devolver todo a los antiguos controladores de clientes. El hecho es que tal transición, de nuevos controladores a viejos, no es oficialmente compatible. Después de volver a cambiar, el sistema operativo comenzó a generar errores y a quejarse de problemas con el clúster. Después de la investigación, pude descubrir que el problema es que el clúster cambió repentinamente al modo conmutado y no quería volver al modo sin interruptor. Tardó mucho tiempo en solucionar el error. Los problemas con el lanzamiento del clúster se resolvieron al no conectar los cables que conducen a la red de combate al inicio, la red dentro del clúster se levantó en un cable y luego se agregó el segundo. Por cierto, debe recordarse que en los controladores más antiguos y las versiones anteriores del sistema operativo, la red dentro del clúster solo se puede generar en ciertos puertos de un rango limitado de adaptadores, por ejemplo, en el FAS3250 es e1a y e2a (el cliente tuvo que comprar tarjetas Ethernet de 10 GB).
Dedicaron más tiempo al trabajo en el segundo sitio, con la esperanza de evitar al menos algunos de los problemas, pero esto no ayudó: el sistema operativo se comportó de manera impredecible. El gráfico fue cambiado dos veces. En el primer caso, cuando trabajábamos con el FAS3250, no era posible migrar los sistemas de combate que funcionaban las 24 horas, los 7 días de la semana, debido a un error en la configuración recientemente modificada de la infraestructura de red del cliente (aunque al probar la migración una semana antes de que comenzara el trabajo, todo voló). vMotion copió máquinas virtuales a una velocidad de menos de 1 Mbps en un sistema de almacenamiento remoto.
Durante la migración, el cliente cambió parcialmente la arquitectura. Los volúmenes que se distribuyeron a su infraestructura VMware vSphere se emitieron previamente a través de NFS Ethernet. El cliente los rehizo y se mudaron a Fibre Channel. Durante el proceso de migración, resultó que el LUN cambió completamente su ID y, en consecuencia, VMware vio nuevos LUN dirigidos a él con datos antiguos y se negó a conectarlos permanentemente. Como resultado, gracias a la ayuda de los especialistas de VMware, fue posible conectar estos LUN a través de la consola de forma continua, lo que indica que se trata de una instantánea de los antiguos almacenes de datos. Luego tuve que reiniciar los hosts VMware. Como resultado, lograron ver máquinas virtuales y elevar la infraestructura virtual. Y si el cliente continuara usando NFS, entonces tal problema no habría surgido: la dirección IP y el nombre DNS se mantuvieron igual que antes.
El plan de trabajo directamente en los días de migración:
Viernes: trabajo con sistemas de almacenamiento e IBS
- Detuvieron todas las relaciones entre SnapVault y SnapMirror, cambiaron el almacenamiento temporal y comprobaron que los sistemas estaban listos para la migración. Comenzamos los procedimientos para migrar el almacenamiento a 7MTT utilizando el método de Transición sin copia. Regimientos de disco de combate reconectados al controlador temporal.
- Migrado a 7MTT, migró el volumen raíz de los controladores de reemplazo a los estantes de disco del sistema de almacenamiento del SRK. Instalamos nuevos adaptadores Ethernet, lanzamos el sistema de almacenamiento SRK, borramos la configuración y descargamos la imagen del sistema operativo a través de la red desde el servidor HTTP. Instalamos nuevas versiones del firmware y el sistema operativo (en esta etapa hubo problemas inexplicables con la descarga de la imagen a través de la red. Al final, se descargó directamente desde la computadora portátil).
- Reemplazamos los controladores en el clúster con los antiguos y conectamos los estantes del disco de batalla al sistema de almacenamiento mediante la actualización mediante el procedimiento de almacenamiento en movimiento. Restauramos el clúster, reconfiguramos las interfaces de red (tuve que resolver los problemas asociados con el funcionamiento incorrecto del clúster) e instalamos las claves de licencia.
Sábado: trabajar con el almacén principal.
- Conectamos los estantes de disco temporales al almacenamiento temporal y lo configuramos nuevamente.
- Importantes máquinas virtuales migraron al almacenamiento a un centro de datos remoto utilizando VMware vMotion.
- Los principales sistemas de almacenamiento se migraron a 7MTT utilizando el método CFT. Apagaron el almacenamiento de combate principal, conectaron sus estantes de disco al controlador y convirtieron los metadatos del sistema operativo a 7MTT. El volumen raíz de los controladores de intercambio migró a los estantes de disco del sistema de almacenamiento SRK.
- Instalamos nuevos adaptadores Ethernet y lanzamos el almacenamiento de batalla en una configuración sin disco, borramos la configuración y luego lo descargamos a través de la red desde el servidor HTTP. Se instalaron nuevas versiones de firmware y sistema operativo. Reemplazamos los controladores en el clúster, conectamos los estantes del disco de combate al sistema de almacenamiento mediante la actualización mediante el procedimiento de almacenamiento en movimiento.
- Se restableció el clúster, se reconfiguraron las interfaces de red (el trabajo con el clúster funcionaba incorrectamente debido a las interfaces de red de combate conectadas). Claves de licencia instaladas.
- Restauramos las conexiones de almacenamiento a los servidores VMware, cambiamos la zonificación en la red SAN, configuramos la asignación de LUN, movimos los volúmenes a un SVM separado para trabajar con acceso FC. LUN conectado a ESXi. Debido al hecho de que la ID de LUN ha cambiado, los almacenes de datos no aparecieron en modo automático, tuve que reiniciar constantemente los servidores ESXi y conectar los LUN con comandos a través de esxcli.
- Se reconfiguraron las interfaces de batalla, se cambió el nombre de los servidores CIFS y se recuperó el acceso a las bolas CIFS y las exportaciones NFS.
Domingo: Resolución de problemas y configuración del software IBS
- Las máquinas virtuales migraron desde el sistema de almacenamiento al sistema de almacenamiento de combate.
- Resolvimos el problema con el acceso a la carpeta en modo de grabación desde el host de Linux. Implementamos la última versión del software de monitoreo Netapp onCommand Unified Manager 7.3 y conectamos ambos sistemas de almacenamiento.
- Analizamos los datos sobre la carga actual en las unidades usando el software Unified Manager, usando el SSD conectamos la capa de almacenamiento en caché a las unidades de disco existentes (Flash / Pool de almacenamiento).
- Apagaron el sistema de almacenamiento alternativo, crearon enlaces de clúster (emparejamiento de clúster, emparejamiento SVM) para que se pudiera utilizar la replicación. Creamos nuevas relaciones SnapMirror entre el almacenamiento principal y el almacenamiento SRK en función de los volúmenes existentes (que se utilizaron en las relaciones del modo SnapMirror 7) con la resincronización de los datos modificados, y luego convertimos las relaciones SnapMirror en relaciones SnapVault (SnapMirror XDP).
- Conectamos ambos sistemas de almacenamiento al software Commvault SRC en modo de replicación abierta de NetApp utilizando el soporte técnico de Commvault, no funcionó de manera diferente, aunque hicimos todo de acuerdo con las instrucciones. Configurado el envío de registros de Autosupport desde el almacenamiento de combate y los sistemas de almacenamiento del SRK.
Lunes: molienda
- Verificación del funcionamiento de los principales sistemas productivos de almacenamiento y almacenamiento del sistema de almacenamiento. Solución de posibles problemas y mal funcionamiento.
- Desconexión y desmontaje de equipos temporales.
La migración en sí misma solo tomó dos días. La mudanza fue exitosa, todos los datos del cliente están sanos y salvos. El sistema de gestión de copias de seguridad y la integración con el software SRK existente también se conservaron. Si anteriormente utilizó el paquete Commvault con OnCommand Unified Manager, luego de cambiar al Modo de clúster, se decidió abandonarlo en favor de Netapp Open Replication para conectar Commvault directamente a los controladores de almacenamiento.
Las principales recomendaciones que puedo dar en función de los resultados de esta migración: cambiar del modo 7 al modo de clúster junto con la sustitución de los controladores. Si todavía planea pasar a los segundos controladores, como en el caso descrito anteriormente, entonces necesita planificar el tiempo suficiente para resolver varios problemas que necesariamente surgirán al volver a los controladores antiguos. El uso de la migración sin mover datos con 7MTT CFT es un procedimiento completamente seguro, si los profesionales confían en él.
Guías útiles utilizadas durante esta migración:
Dmitry Kostryukov, ingeniero de diseño líder de sistemas de almacenamiento
Centro de diseño de complejos informáticos "Jet Infosystems"