Al comienzo de mi carrera, trabajé para una empresa que lanzó un sistema de gestión de contenido. Este CMS ayudó a los departamentos de marketing a administrar sus sitios por su cuenta, en lugar de depender de los desarrolladores para cada cambio. El sistema ha ayudado a los clientes a reducir los costos operativos y, para mí, a aprender cómo crear aplicaciones web.
Aunque el producto en sí tenía un propósito muy general, los clientes generalmente lo usaban para tareas específicas. Estas tareas exprimieron al máximo el CMS, y los desarrolladores tuvieron que buscar una solución a los problemas. Después de diez años de trabajar en un entorno así, aprendí una gran cantidad de formas en que una aplicación web en producción puede romperse. Algunos de ellos serán discutidos en este artículo.
Una de las lecciones aprendidas a lo largo de los años es que los ingenieros individuales generalmente se sumergen profundamente en el área que les interesa y estudian el resto superficialmente. El esquema funciona normalmente en un equipo de ingenieros con buena comunicación, donde el conocimiento se superpone y llena vacíos individuales para cada uno de ellos. Pero en equipos con poca experiencia o para ingenieros individuales, ocurre una falla.
Si comenzó a trabajar en un entorno de este tipo y luego comenzó a crear e implementar una aplicación web desde cero, descubrirá rápidamente qué es "conocimiento superficial peligroso".
Existen varias soluciones en la industria para resolver este problema: aplicaciones web administradas (Beanstalk, AppEngine, etc.), administración de contenedores (Kubernetes, ECS, etc.) y muchas otras. Funcionan bien fuera de la caja y pueden resolver el problema perfectamente. Pero esta es una complejidad innecesaria cuando se inicia una aplicación web, y generalmente tales soluciones "simplemente funcionan".
Desafortunadamente, no siempre "solo funcionan". Si hay algún matiz, entonces quiero saber un poco más sobre esta siniestra caja negra.
En el artículo, tomamos un sistema poco confiable y lo modificamos a un nivel razonable de confiabilidad. En cada paso, se utiliza un problema real, cuya solución nos lleva a la siguiente etapa. Creo que es más eficiente no analizar todas las partes del diseño final, sino utilizar un enfoque tan gradual. Él demuestra mejor cuándo y en qué orden tomar ciertas decisiones. Al final, construiremos desde cero la estructura básica del servicio de alojamiento para aplicaciones web administradas, y espero que expliquemos en detalle las razones de la existencia de cada una de sus partes.
Inicio
Imagine que su presupuesto para alojamiento es de $ 500 por año, por lo que decidió alquilar un servidor t2.medium en Amazon AWS. Al momento de escribir, esto es alrededor de $ 400 por año.
Usted sabe de antemano que tendrá un sistema de autorización y que necesitará almacenar información sobre los usuarios, por lo que necesita una base de datos. Debido al presupuesto limitado, lo colocaremos en nuestro único servidor. Al final, obtenemos la siguiente infraestructura:
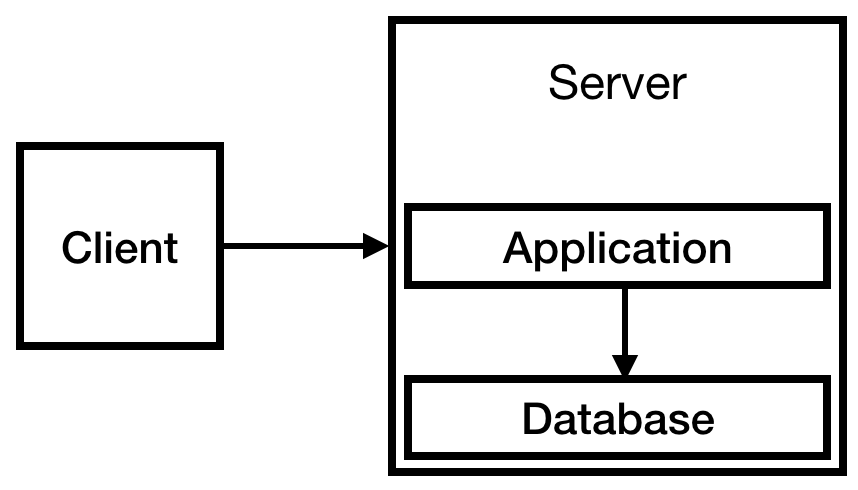 Fig. 1
Fig. 1Esto es suficiente por ahora. De hecho, dicho sistema puede funcionar durante bastante tiempo. El servicio es pequeño, menos de 10 visitas por día. Quizás una pequeña instancia fue suficiente, pero somos optimistas sobre el crecimiento de la empresa, por lo que tomamos prudentemente t2.medium.
El valor del negocio está en la base de datos, por lo que es muy importante. Debe asegurarse de que si el servidor falla, no perderá datos. Probablemente debería asegurarse de que el contenido de la base de datos no esté almacenado en un disco temporal. Después de todo, si se elimina la instancia, perderá sus datos. Este es un pensamiento muy aterrador.
También debe asegurarse de tener copias de seguridad en el almacenamiento externo. S3 parece un buen lugar para ellos y relativamente económico, así que configurémoslo también. Y definitivamente debe verificar que la copia de seguridad esté funcionando, restaurando periódicamente la copia de seguridad.
Ahora el sistema se ve así:
 Fig. 2
Fig. 2Ha aumentado la confiabilidad de la base de datos, y es hora de prepararse para el "efecto habrae" ejecutando una prueba de carga en el servidor. Todo va bien hasta que aparecen 500 errores, y luego un flujo de error 404, por lo que está investigando lo que sucedió.
Resulta que no tiene idea de lo que sucedió porque escribió registros en la consola y no dirigió la salida a un archivo. También ve que el proceso no funciona, por lo que puede suponer que es por eso que aparecen los errores 404. Se produce una oleada de alivio al haber ejecutado correctamente la prueba de carga local y no ha causado el efecto Habra real como carga de prueba.
Soluciona el problema con el reinicio automático creando el servicio
systemd , inicia el servidor web, que simultáneamente resuelve el problema del registro. Luego ejecute otra prueba de carga para verificar.
Y nuevamente vemos los errores 500 (afortunadamente, sin 404). Revisas los registros. Se detecta que el grupo de conexiones de la base de datos está lleno porque se ha establecido un pequeño límite de 10 conexiones. Actualice la restricción, reinicie la base de datos y vuelva a ejecutar la prueba de carga. Todo va bien, así que decides hablar sobre tu sitio en Habré.
Día de lanzamiento
Madre de dios Su servicio se convierte instantáneamente en un éxito. Llegaste a la página principal y obtuviste 5000 visitas en los primeros 30 minutos, y ves los comentarios. ¿Qué escriben allí?
Tengo un error 404, así que tuve que abrir una versión en caché de la página. Aquí está el enlace, si alguien lo necesita: ...
...
Nada se abre Además, tengo Javascript deshabilitado. ¿Por qué la gente piensa que quiero cargar sus 2 MB de Javascript ...
...
La descarga de la página de inicio lleva 4 segundos. Traceroute de Australia muestra que el servidor está ubicado en algún lugar de Texas. Además, ¿por qué la primera página carga 2 megabytes de Javascript?
En una carrera loca, configura Nginx como un servidor proxy inverso para su aplicación y configura una página estática 404 allí. También cambia el procedimiento de implementación para enviar archivos estáticos a S3: esto es necesario para que CloudFront CDN funcione para reducir el tiempo de carga en Australia.
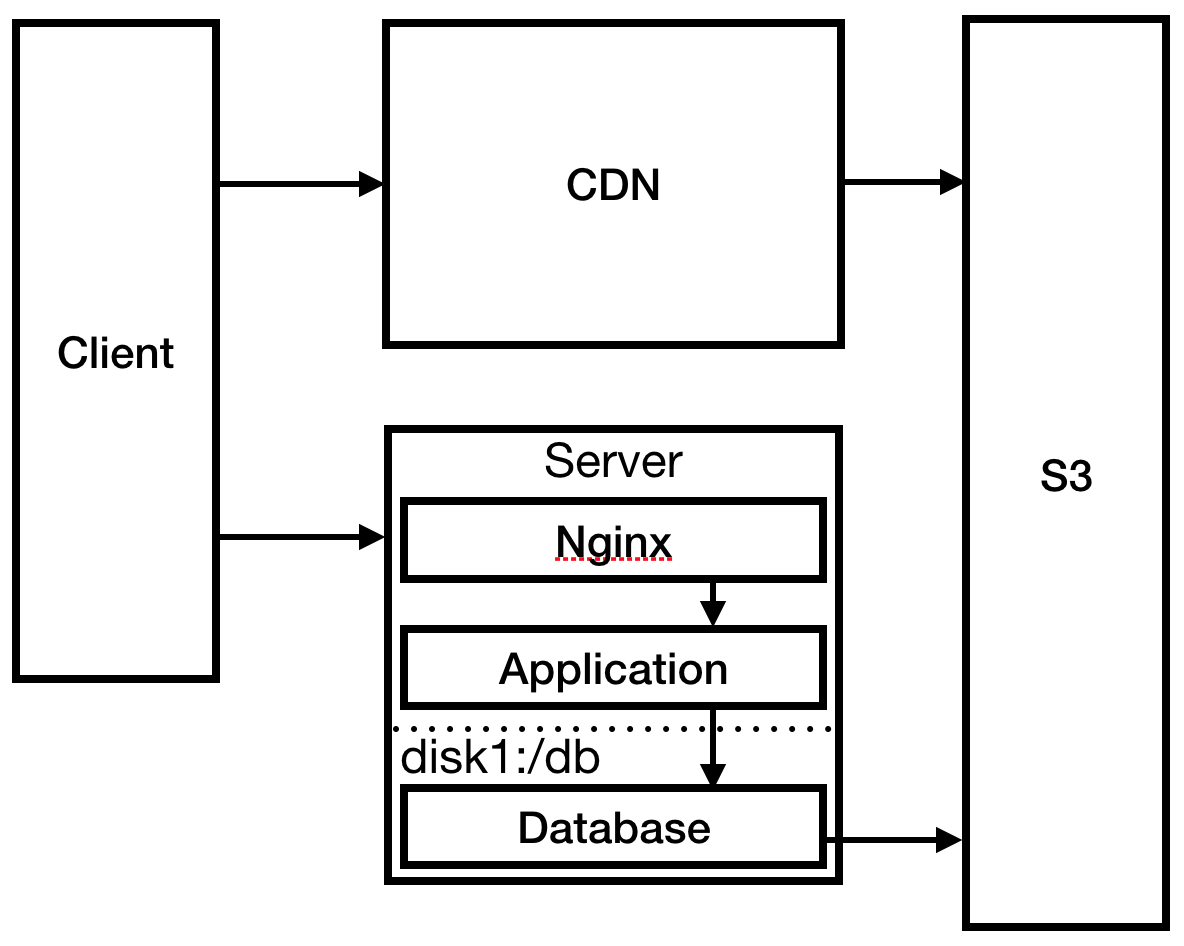 Fig. 3
Fig. 3Ha resuelto el problema más acuciante, vaya al servidor y verifique los registros. Su conexión SSH está inusualmente retrasada. Después de estudiar un poco, verá que los archivos de registro han utilizado completamente el espacio en disco, lo que provocó el bloqueo del proceso y evitó que se reiniciara. Cree un disco mucho más grande y monte los registros allí. Configure
logrotate para que los archivos de registro ya no crezcan a esos tamaños.
Problemas de rendimiento
Pasan los meses El público está creciendo. El sitio comienza a disminuir. Notó en CloudWatch que esto solo ocurre entre las 00:00 y las 12:00 UTC. Debido a los mismos tiempos de retraso de inicio y finalización, se da cuenta de que esto se debe a una tarea programada en el servidor. Verifique crontab y tenga en cuenta que un trabajo está programado para la medianoche: copia de seguridad. Por supuesto, la copia de seguridad tarda doce horas y conduce a una sobrecarga de la base de datos, lo que provoca una desaceleración significativa en el sitio.
Ya leyó sobre esto antes y decidió ejecutar copias de seguridad en una base de datos esclava. Entonces recuerde: no tiene una base de datos subordinada, por lo que debe crearla. No tiene mucho sentido ejecutar la base de datos esclava en el mismo servidor, por lo que decide expandirse. Cree dos nuevos servidores: uno para la base de datos maestra y otro para la base de datos esclava. Cambie la copia de seguridad para que funcione con una base de datos subordinada.
 Fig. 4 4
Fig. 4 4Crecimiento del equipo
Por un tiempo, todo va bien. Pasan los meses Estás contratando desarrolladores. Uno de los recién llegados introduce un error que derriba el servidor de producción. El desarrollador culpa al entorno de desarrollo, que es diferente de la producción. Hay algo de verdad en sus palabras. Como eres una persona racional con un buen carácter, percibes este evento como una lección.
Es hora de crear entornos adicionales: puesta en escena, control de calidad y producción. Afortunadamente, desde el primer día automatizaste la creación de infraestructura, para que todo funcione sin problemas y de manera simple. También ha establecido buenas prácticas de entrega continua desde el primer día, por lo que puede ensamblar fácilmente un transportador desde nuevas sucursales.
El departamento de marketing está presionando para la versión 2.0. No entiendes lo que significa 2.0, pero estás de acuerdo. Es hora de prepararse para el próximo aumento del tráfico. Ya está cerca del pico en el servidor actual, por lo que ha llegado el momento de equilibrar la carga. Amazon ELB lo hace fácil. Alrededor de este tiempo, observará que los diagramas en capas de este artículo deben mostrar capas de arriba a abajo y no de izquierda a derecha.
 Fig. 5 5
Fig. 5 5Seguro de que va a hacer frente a la carga, vuelve a mencionar su sitio en Habré. Oh milagro, puede soportar el tráfico. Gran exito!
Todo parecía ir bien hasta que fuiste a revisar los registros. Tardó una hora en probar 12 servidores (cuatro servidores en cada entorno). Una verdadera molestia. Afortunadamente, hay suficiente dinero para comprar una pila ELK (ElasticSearch, LogStash, Kibana). Lo implementa y dirige los servidores desde todos los entornos.
 Fig. 6 6
Fig. 6 6Ahora, puede volver a los registros, mirarlos y notar algo extraño. Están llenos de tales entradas:
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
No estás usando PHP o WordPress, por lo que esto es bastante extraño. Observa entradas sospechosas similares en los registros de los servidores de bases de datos y se pregunta cómo se conectaron a Internet. Es hora de implementar subredes públicas y privadas.
 Fig. 7 7
Fig. 7 7Verifique los registros nuevamente. Los intentos de pirateo se mantuvieron, pero ahora están limitados al puerto 80 en el equilibrador de carga, lo cual es un poco reconfortante, porque los servidores de aplicaciones, los servidores de bases de datos y la pila ELK ya no están en acceso abierto.
A pesar de los registros centralizados, está cansado de buscar tiempos de inactividad, verificando los registros manualmente. A través de Amazon CloudWatch, configura alertas de correo electrónico cuando la unidad, la CPU y la red alcanzan el 80% de utilización. Genial
Operación suave
Es broma! No hay tal cosa como una operación sin problemas en el software. Algo definitivamente se romperá. Afortunadamente, ahora tiene muchas herramientas para manejar la situación.
Creamos una aplicación web escalable con copias de seguridad, reversiones (utilizando implementaciones azules / verdes entre la producción y la etapa intermedia), registros centralizados, monitoreo y notificación. La ampliación adicional, por regla general, depende de las necesidades específicas de la aplicación.
Hay muchas opciones de alojamiento en el mercado que asumen la mayoría de las tareas mencionadas. En lugar de desarrollarlo por su cuenta, puede confiar en Beanstalk, AppEngine, GKE, ECS, etc. La mayoría de estos servicios configuran automáticamente permisos razonables, subsistemas de equilibrio de carga, subredes, etc. Esto elimina una parte importante de la molestia al ejecutar una aplicación web de forma rápida y rápida. backend confiable que funciona por mucho tiempo.
A pesar de esto, me resulta útil comprender qué funcionalidad proporciona cada una de estas plataformas y por qué la proporcionan. Esto facilita la elección de una plataforma en función de sus propias necesidades. Al alojar la aplicación en dicha plataforma, ya sabrá cómo funcionan estos módulos. Cuando algo sale mal, es útil conocer las herramientas para resolver el problema.
Conclusión
Este artículo omite muchos detalles. No describe cómo automatizar la creación de infraestructura, cómo preparar y configurar servidores. No cubre la creación de entornos de desarrollo, la configuración de tuberías de entrega continua y la implementación y retroceso. No abordamos la seguridad de la red, el intercambio de claves y el principio de privilegios mínimos. No hablaron sobre la importancia de la infraestructura inmutable, los servidores sin estado y las migraciones. Cada tema requiere un artículo separado.
El propósito de esta publicación es una descripción general de cómo debería ser una aplicación web razonable en producción. Los artículos futuros se pueden vincular aquí y ampliar el tema.
Eso es todo por ahora.
Gracias por leer y buena codificación!
Nota: no tome literalmente la secuencia de este artículo ilustrativo. Por separado, todos estos eventos realmente me sucedieron, pero en diferentes momentos, en entornos completamente diferentes y en diferentes tareas.