Nikolai Ryzhikov propuso su versión de la respuesta a la pregunta de por qué es tan difícil desarrollar una interfaz de usuario. En el ejemplo de su proyecto, demostrará que la aplicación en el frontend de algunas ideas del backend afecta tanto la reducción de la complejidad del desarrollo como la capacidad de prueba del frontend.
El material fue preparado sobre la base de un informe de Nikolai Ryzhikov en la
conferencia de primavera
HolyJS 2018 Piter .
Actualmente, Nikolai Ryzhikov está trabajando en el sector de TI de Salud para crear sistemas de información médica. Miembro de la comunidad de programadores funcionales de San Petersburgo FPROG. Miembro activo de la comunidad Online Clojure, miembro del estándar de intercambio de información médica HL7 FHIR. Ha estado programando durante 15 años.
- Siempre me atormentaba la pregunta: ¿por qué la interfaz gráfica siempre era difícil de hacer? ¿Por qué esto siempre ha planteado muchas preguntas?
Hoy trataré de especular si es posible desarrollar efectivamente una interfaz de usuario. ¿Podemos reducir la complejidad de su desarrollo?
¿Qué es la eficiencia?
Definamos qué es la eficiencia. Desde el punto de vista del desarrollo de una interfaz de usuario, eficiencia significa:
- velocidad de desarrollo
- cantidad de errores
- cantidad de dinero gastado ...
Hay una muy buena definición:
La eficiencia está haciendo más con menos
Después de esta determinación, puede poner lo que quiera: dedicar menos tiempo y menos esfuerzo. Por ejemplo, "si escribe menos código, permita menos errores" y logre el mismo objetivo. En general, gastamos mucho esfuerzo en vano. Y la eficiencia es un objetivo bastante alto: deshacerse de estas pérdidas y hacer solo lo que se necesita.
¿Qué es la complejidad?
En mi opinión, la complejidad es el principal problema en el desarrollo.
Fred Brooks escribió un artículo en 1986 llamado Sin bala de plata. En él, reflexiona sobre el software. En hardware, el progreso es a pasos agigantados, y con el software todo es mucho peor. La pregunta principal de Fred Brooks: ¿puede haber una tecnología que nos acelere de inmediato en un orden de magnitud? Y él mismo da una respuesta pesimista, afirmando que en el software no es posible lograr esto, explicando su posición. Recomiendo leer este artículo.
Un amigo mío dijo que la programación de la interfaz de usuario es un "problema sucio". No puede sentarse una vez y encontrar la opción correcta para que el problema se resuelva para siempre. Además, en los últimos 10 años, la complejidad del desarrollo solo ha aumentado.
Hace 12 años ...
Comenzamos a desarrollar un sistema de información médica hace 12 años. Primero con flash. Luego miramos lo que Gmail comenzó a hacer. Nos gustó y queríamos cambiar a JavaScript con HTML.
De hecho, entonces estábamos muy adelantados. Tomamos un dojo y, de hecho, teníamos todo igual que ahora. Había componentes que eran bastante buenos en los widgets de dojo, había un sistema de compilación modular y requería que el compilador de Google Clojure se construyera y minimizara (RequireJS y CommonJS ni siquiera olían entonces).
Todo salió bien. Miramos a Gmail, nos sentimos inspirados, pensamos que todo estaba bien. Al principio, solo escribimos un lector de tarjetas de paciente. Luego cambiaron gradualmente a la automatización de otros flujos de trabajo en el hospital. Y todo se volvió complicado. El equipo parece ser profesional, pero cada característica comenzó a crujir. Esta sensación apareció hace 12 años, y todavía no me deja.
Carriles camino + jQuery
Hicimos la certificación del sistema y fue necesario escribir un portal para pacientes. Este es un sistema en el que el paciente puede ir y ver sus datos médicos.
Nuestro backend fue escrito en Ruby on Rails. Aunque la comunidad de Ruby on Rails no es muy grande, ha tenido un gran impacto en la industria. De su pequeña comunidad apasionada, han venido todos sus gerentes de paquetes, GitHub, Git, maquillajes automáticos, etc.
La esencia del desafío que enfrentamos fue que tuvimos que implementar el portal del paciente en dos semanas. Y decidimos probar el camino de Rails: hacer todo en el servidor. Una web tan clásica 2.0. Y lo hicieron, realmente lo hicieron en dos semanas.
Estábamos por delante de todo el planeta: hicimos SPA, teníamos una API REST, pero por alguna razón no fue efectiva. Algunas características ya podían formar unidades, porque solo ellas podían acomodar toda esta complejidad de componentes, la relación del backend con la interfaz. Y cuando tomamos el camino de Rails, un poco desactualizado por nuestros estándares, las características de repente comenzaron a ser fascinantes. El desarrollador promedio comenzó a implementar la función en unos días. E incluso comenzamos a escribir pruebas simples.
Sobre esta base, todavía tengo una lesión: había preguntas. Cuando cambiamos de Java a Rails en el back-end, la eficiencia del desarrollo aumentó aproximadamente 10 veces. Pero cuando obtuvimos puntajes en el SPA, la eficiencia del desarrollo también aumentó significativamente. ¿Cómo es eso?
¿Por qué fue efectiva la Web 2.0?
Comencemos con otra pregunta: ¿por qué hacemos una aplicación de página única, por qué creemos en ella?
Simplemente nos dicen: tenemos que hacer esto, y lo hacemos. Y muy raramente lo cuestionan. ¿Es correcta la arquitectura REST API y SPA? ¿Es realmente adecuado para el caso donde lo usamos? No pensamos
Por otro lado, hay ejemplos conversos sobresalientes. Todos usan GitHub. ¿Sabes que GitHub no es una aplicación de página única? GitHub es una aplicación "rail" normal que se representa en el servidor y donde hay pocos widgets. ¿Alguien ha experimentado harina de esto? Creo que hay tres personas. El resto ni se dio cuenta. Esto no afectó al usuario de ninguna manera, pero al mismo tiempo, por alguna razón, tenemos que pagar 10 veces más por el desarrollo de otras aplicaciones (tanto fuerza, complejidad, etc.). Otro ejemplo es Basecamp. Twitter fue una vez solo una aplicación Rails.
De hecho, hay tantas aplicaciones Rails. Esto fue parcialmente determinado por el genio DHH (David Heinemeier Hansson, creador de Ruby on Rails). Fue capaz de crear una herramienta centrada en los negocios, que le permite hacer de inmediato lo que necesita, sin distraerse por problemas técnicos.
Cuando usamos el modo Rails, por supuesto, había mucha magia negra. A medida que nos desarrollamos gradualmente, cambiamos de Ruby a Clojure, prácticamente manteniendo la misma eficiencia, pero haciendo que todo sea un orden de magnitud más simple. Y fue maravilloso.
Han pasado 12 años
Con el tiempo, nuevas tendencias comenzaron a aparecer en la interfaz.
Ignoramos por completo a Backbone, porque la aplicación de dojo que escribimos antes era aún más sofisticada que la que ofrece Backbone.
Luego vino Angular. Fue un "rayo de luz" bastante interesante: desde el punto de vista de la eficiencia, Angular es muy bueno. Tomas al desarrollador promedio, y él remacha la función. Pero desde el punto de vista de la simplicidad, Angular trae muchos problemas: es opaco, complejo, hay vigilancia, optimización, etc.
React apareció, lo que trajo un poco de simplicidad (al menos la sencillez del renderizado, que, debido al DOM virtual, nos permite cada vez como simplemente volver a dibujar, simplemente entender y simplemente escribir). Pero en términos de eficiencia, para ser honesto, React nos hizo retroceder significativamente.
Lo peor es que nada ha cambiado en 12 años. Todavía estamos haciendo lo mismo que entonces. Es hora de pensar: algo está mal aquí.
Fred Brooks dice que hay dos problemas con el desarrollo de software. Por supuesto, él ve el problema principal en la complejidad, pero lo divide en dos grupos:
- Complejidad significativa que proviene de la tarea misma. Simplemente no se puede tirar, porque es parte de la tarea.
- La complejidad aleatoria es la que traemos al tratar de resolver este problema.
La pregunta es, ¿cuál es el equilibrio entre ellos? Esto es precisamente lo que estamos discutiendo ahora.
¿Por qué es tan doloroso hacer la interfaz de usuario?
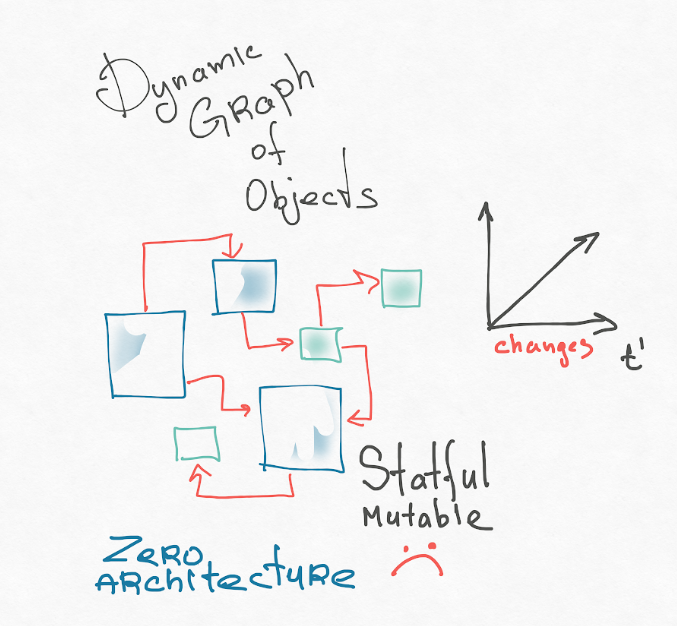
Me parece que la primera razón es nuestro modelo de aplicación mental. Los componentes de reacción son un enfoque puramente OOP. Nuestro sistema es un gráfico dinámico de objetos mutables interconectados. Los tipos completos de Turing generan constantemente nodos de este gráfico, algunos nodos desaparecen. ¿Alguna vez has tratado de imaginar tu aplicación en tu cabeza? Esto da miedo! Usualmente presento una aplicación OOP como esta:

Recomiendo leer las tesis de Roy Fielding (autor de la arquitectura REST). Su disertación se titula "Estilos arquitectónicos y el diseño de software basado en red". Al principio hay una muy buena introducción, donde habla sobre cómo llegar a la arquitectura en general e introduce los conceptos: divide el sistema en componentes y las relaciones entre estos componentes. Tiene una arquitectura "cero", donde todos los componentes pueden asociarse potencialmente con todos. Este es el caos arquitectónico. Esta es nuestra representación de objeto de la interfaz de usuario.
Roy Fielding recomienda buscar e imponer un conjunto de restricciones, porque es un conjunto de restricciones que define su arquitectura.
Probablemente lo más importante es que las restricciones son amigos del arquitecto. Busque estas limitaciones reales y diseñe un sistema a partir de ellas. Porque la libertad es malvada. Libertad significa que tiene un millón de opciones entre las que puede elegir, y ningún criterio por el cual puede determinar si la elección fue correcta. Busque restricciones y construya sobre ellas.
Hay un excelente artículo llamado OUT OF THE TAR PIT ("Más fácil que un pozo de alquitrán"), en el que los chicos después de Brooks decidieron analizar qué contribuye exactamente a la complejidad de la aplicación. Llegaron a la decepcionante conclusión de que un sistema mutable, extendido por el estado, es la principal fuente de complejidad. Aquí es posible explicar de manera puramente combinatoria: si tiene dos celdas, y en cada una de ellas una bola puede mentir (o no mentir), ¿cuántos estados son posibles? - cuatro.
Si tres celdas - 2
3 , si 100 celdas - 2
100 . Si presenta su aplicación y comprende cuánto estado está borroso, se dará cuenta de que hay un número infinito de estados posibles de su sistema. Si al mismo tiempo no está limitado por nada, es demasiado difícil. Y el cerebro humano es débil, esto ya ha sido probado por varios estudios. Somos capaces de mantener hasta tres elementos en nuestras cabezas al mismo tiempo. Algunos dicen siete, pero incluso para esto el cerebro usa un truco. Por lo tanto, la complejidad es realmente un problema para nosotros.
Recomiendo leer este artículo, donde los chicos llegan a la conclusión de que hay que hacer algo con este estado mutable. Por ejemplo, hay bases de datos relacionales, puede eliminar todo el estado mutable allí. Y el resto se hace en un estilo puramente funcional. Y simplemente se les ocurrió la idea de tal programación funcional-relacional.
Entonces, el problema proviene del hecho de que:
- En primer lugar, no tenemos un buen modelo de interfaz de usuario fijo. Los enfoques de componentes nos llevan al infierno existente. No imponemos ninguna restricción, difundimos el estado mutable, como resultado, la complejidad del sistema en algún momento simplemente nos aplasta;
- en segundo lugar, si estamos escribiendo una aplicación clásica de interfaz de usuario, ya es un sistema distribuido. Y la primera regla de los sistemas distribuidos es no crear sistemas distribuidos (Primera ley del diseño de objetos distribuidos: no distribuya sus objetos, por Martin Fowler), ya que aumenta inmediatamente la complejidad en un orden de magnitud. Cualquiera que haya escrito alguna integración comprende que tan pronto como ingrese a la interacción entre sistemas, todas las estimaciones del proyecto pueden multiplicarse por 10. Pero simplemente nos olvidamos de eso y pasamos a sistemas distribuidos. Esta fue probablemente la consideración principal cuando cambiamos a Rails, devolviendo todo el control al servidor.
Todo esto es demasiado duro para un cerebro humano pobre. Pensemos en lo que podemos hacer con estos dos problemas: la falta de restricciones en la arquitectura (el gráfico de objetos mutables) y la transición a sistemas distribuidos que son tan complejos que los académicos todavía están desconcertando cómo hacerlo correctamente (al mismo tiempo, nosotros condenarnos a estos tormentos en las aplicaciones comerciales más simples)?
¿Cómo evolucionó el backend?
Si escribimos el backend en el mismo estilo que estamos creando la interfaz de usuario ahora, habrá el mismo "desastre sangriento". Pasaremos tanto tiempo en ello. Así que realmente una vez intenté hacerlo. Luego, gradualmente comenzaron a imponer restricciones.
La primera gran invención de backend es la base de datos.
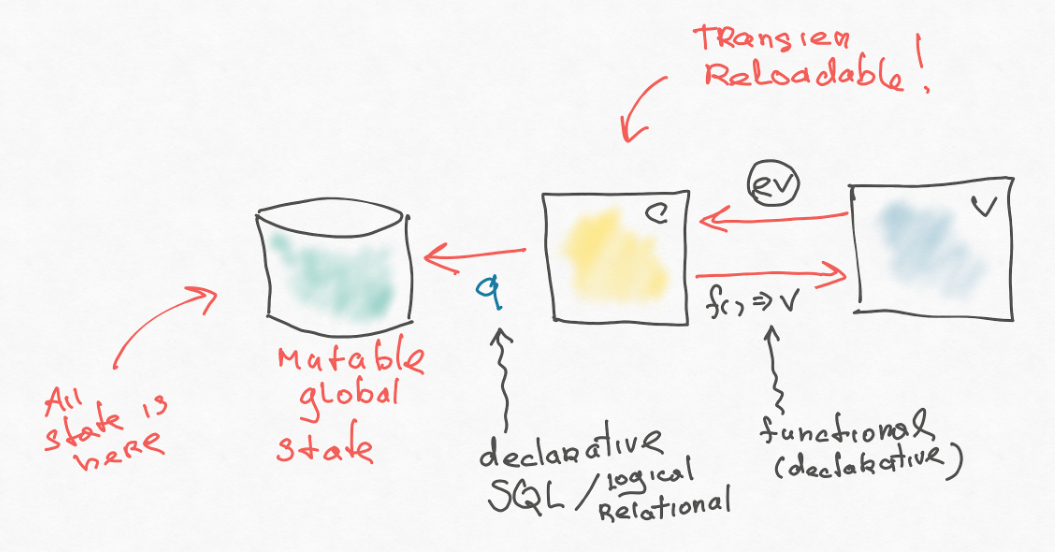
Al principio, en el programa, todo el estado colgaba inexplicablemente donde, y era difícil de manejar. Con el tiempo, los desarrolladores crearon una base de datos y eliminaron todo el estado allí.
La primera diferencia interesante entre la base de datos es que los datos no tienen algunos objetos con su propio comportamiento, esto es pura información. Hay tablas u otras estructuras de datos (por ejemplo, JSON). No tienen comportamiento, y esto también es muy importante. Porque el comportamiento es una interpretación de la información, y puede haber muchas interpretaciones. Y los hechos básicos: siguen siendo básicos.
Otro punto importante es que sobre esta base de datos tenemos un lenguaje de consulta como SQL. Desde el punto de vista de las limitaciones, en la mayoría de los casos, SQL no es un lenguaje completo de Turing, es más simple. Por otro lado, es declarativo, más expresivo, porque en SQL se dice "qué", no "cómo". Por ejemplo, cuando combina dos etiquetas en SQL, SQL decide cómo realizar esta operación de manera eficiente. Cuando buscas algo, él recoge un índice para ti. Nunca declaras explícitamente esto. Si intenta combinar algo en JavaScript, tendrá que escribir un montón de código para esto.
Aquí, nuevamente, es importante que hayamos impuesto restricciones y ahora vamos a esta base a través de un lenguaje más simple y expresivo. Complejidad redistribuida.
Después de que el backend ingresó a la base, la aplicación se convirtió en apátrida. Esto conduce a efectos interesantes: ahora, por ejemplo, es posible que no tengamos miedo de actualizar la aplicación (el estado no se bloquea en la capa de la aplicación en la memoria, que desaparecerá si la aplicación se reinicia). Para una capa de aplicación, sin estado es una buena característica y una restricción excelente. Póntelo si puedes. Además, una nueva aplicación se puede incorporar a la base anterior, porque los hechos y su interpretación no son cosas relacionadas.
Desde este punto de vista, los objetos y las clases son terribles porque pegan el comportamiento y la información. La información es más rica; vive más tiempo. Las bases de datos y los hechos sobreviven al código escrito en Delphi, Perl o JavaScript.
Cuando el backend llegó a tal arquitectura, todo se volvió mucho más simple. La era dorada de la Web 2.0 ha llegado. Fue posible obtener algo de la base de datos, someter los datos a plantillas (función pura) y devolver el HTML-ku, que se envía al navegador.
Aprendimos a escribir aplicaciones bastante complejas en el backend. Y la mayoría de las aplicaciones están escritas en este estilo. Pero tan pronto como el backend da un paso al costado, hacia la incertidumbre, los problemas comienzan nuevamente.
La gente comenzó a pensar en ello y se le ocurrió la idea de tirar la OLP y los rituales.
¿Qué hacen realmente nuestros sistemas? Toman información de algún lugar, del usuario, de otro sistema y similares, la colocan en la base de datos, la transforman, de alguna manera la verifican. Desde la base lo sacan con consultas astutas (analíticas o sintéticas) y lo devuelven. Eso es todo Y esto es importante de entender. Desde este punto de vista, las simulaciones son un concepto muy incorrecto y malo.
Me parece que, en general, toda la POO realmente nació de la IU. Las personas intentaron simular y simular una interfaz de usuario. Vieron cierto objeto gráfico en el monitor y pensaron: sería bueno estimularlo en nuestro tiempo de ejecución, junto con sus propiedades, etc. Toda esta historia está muy estrechamente entrelazada con la OOP. Pero la simulación es la forma más sencilla e ingenua de resolver la tarea. Se hacen cosas interesantes cuando te haces a un lado. Desde este punto de vista, es más importante separar la información del comportamiento, deshacerse de estos objetos extraños, y todo será mucho más fácil: su servidor web recibe una cadena HTTP, devuelve una cadena de respuesta HTTP. Si agrega una base a la ecuación, obtiene una función generalmente pura: el servidor acepta la base y solicita, devuelve una nueva base y respuesta (datos ingresados - datos restantes).
En el camino de esta simplificación, los funcionarios tiraron otro ⅔ del equipaje que se había acumulado en el backend. No era necesario, solo era un ritual. Todavía no somos un desarrollador de juegos: no necesitamos que el paciente y el médico vivan de alguna manera en tiempo de ejecución, se muevan y sigan sus coordenadas. Nuestro modelo de información es otra cosa. No pretendemos ser medicina, ventas o cualquier otra cosa. Estamos creando algo nuevo en el cruce. Por ejemplo, Uber no simula el comportamiento de operadores y máquinas: introduce un nuevo modelo de información. En nuestro campo, también estamos creando algo nuevo, para que pueda sentir la libertad.
No es necesario intentar simular completamente: crear.
Clojure = JS--
Es hora de decirte exactamente cómo puedes tirar todo. Y aquí quiero mencionar Clojure Script. De hecho, si conoce JavaScript, conoce Clojure. En Clojure, no agregamos funciones a JavaScript, sino que las eliminamos.
- Eliminamos la sintaxis: en Clojure (en Lisp) no hay sintaxis. En un lenguaje ordinario, escribimos un código, que luego se analiza y se obtiene un AST, que se compila y ejecuta. En Lisp, escribimos inmediatamente un AST que se puede ejecutar, interpretar o compilar.
- Tiramos la mutabilidad. No hay objetos o matrices mutables en Clojure. Cada operación genera como si una nueva copia. Además, esta copia es muy barata. Eso está tan hábilmente hecho para ser barato. Y esto nos permite trabajar, como en matemáticas, con valores. No estamos cambiando nada, estamos creando algo nuevo. Seguro, fácil
- Lanzamos clases, juegos con prototipos, etc. Esto simplemente no está ahí.
Como resultado, todavía tenemos funciones y estructuras de datos sobre las cuales operamos, así como primitivas. Aquí está todo el Clojure. Y en él puedes hacer lo mismo que haces en otros idiomas, donde hay muchas herramientas adicionales que nadie sabe cómo usar.
Ejemplos
¿Cómo llegamos a Lisp a través de AST? Aquí hay una expresión clásica:
(1 + 2) - 3
Si intentamos escribir su AST, por ejemplo, en forma de matriz, donde el encabezado es el tipo de nodo y lo que sigue es un parámetro, obtendremos algo similar (estamos tratando de escribir esto en Java Script):
['minus', ['plus', 1, 2], 3]
Ahora descarte las comillas adicionales, podemos reemplazar el menos con
- , y el más con
+ . Deseche las comas que son espacios en blanco en Lisp. Obtendremos el mismo AST:
(- (+ 1 2) 3)
Y en Lisp, todos escribimos así. Podemos verificar: esta es una función matemática pura (mi emacs está conectado al navegador; dejo caer el script allí, evalúa el comando allí y lo envía de vuelta a emacs; ve el valor después del símbolo
=> ):
(- (+ 1 2) 3) => 0
También podemos declarar una función:
(defn xplus [ab] (+ ab)) ((fn [xy] (* xy)) 1 2) => 2
O una función anónima. Quizás esto parezca un poco aterrador:
(type xplus)
Su tipo es una función de JavaScript:
(type xplus) => #object[Function]
Podemos llamarlo pasándole el parámetro:
(xplus 1 2)
Es decir, todo lo que hacemos es escribir AST, que luego se compila en JS o bytecode, o se interpreta.
(defn mymin [ab] (if (a > b) ba))
Clojure es un lenguaje alojado. Por lo tanto, toma primitivas del tiempo de ejecución principal, es decir, en el caso de Clojure Script, tendremos tipos de JavaScript:
(type 1) => #object[Number]
(type "string") => #object[String]
Entonces regexp están escritos:
(type #"^Cl.*$") => #object[RegExp]
Las funciones que tenemos son funciones:
(type (fn [x] x)) => #object[Function]
Luego necesitamos algún tipo de tipos compuestos.
(def user {:name "niquola" :address {:city "SPb"} :profiles [{:type "github" :link "https://….."} {:type "twitter" :link "https://….."}] :age 37} (type user)
Esto se puede leer como si estuviera creando un objeto en JavaScript:
(def user {name: "niquola" …
En Clojure, esto se llama hashmap. Este es un contenedor en el que se encuentran los valores. Si se utilizan corchetes, esto se llama vector, esta es su matriz:
(def user {:name "niquola" :address {:city "SPb"} :profiles [{:type "github" :link "https://….."} {:type "twitter" :link "https://….."}] :age 37} => #'intro/user (type user)
Registramos cualquier información con hashmaps y vectores.
Los nombres de dos puntos extraños (
:name ) son los llamados caracteres: cadenas constantes que se crean para usarse como claves en hashmaps. En diferentes idiomas se les llama de manera diferente: símbolos, algo más. Pero esto puede tomarse simplemente como una cadena constante. Son bastante efectivos: puede escribir nombres largos y no gastar muchos recursos en ellos, porque están conectados (es decir, no se repiten).
Clojure proporciona cientos de funciones para manejar estas estructuras de datos genéricas y primitivas. Podemos agregar, agregar nuevas claves. Además, siempre tenemos una semántica de copia, es decir, cada vez que recibimos una nueva copia. Primero debes acostumbrarte, porque ya no podrás guardar algo, como antes, en algún lugar de la variable, y luego cambiar este valor. Su cálculo siempre debe ser sencillo: todos los argumentos deben pasarse explícitamente a la función.
Esto lleva a algo importante. En lenguajes funcionales, una función es un componente ideal porque recibe todo explícitamente en la entrada. No hay enlaces ocultos divergentes en el sistema. Puede tomar una función de un lugar, transferirla a otro y usarla allí.
En Clojure, tenemos excelentes operaciones de igualdad en valor incluso para tipos compuestos complejos:
(= {:a 1} {:a 1}) => true
Y esta operación es barata debido al hecho de que las astutas estructuras inmutables se pueden comparar simplemente por referencia. Por lo tanto, incluso un hashmap con millones de claves podemos comparar en una sola operación.
Por cierto, los chicos de React simplemente copiaron la implementación de Clojure e hicieron JS inmutable.
Clojure también tiene un montón de operaciones, por ejemplo, obtener algo de una ruta anidada en hashmap:
(get-in user [:address :city])
Ponga algo a lo largo de la ruta anidada en hashmap:
(assoc-in user [:address :city] "LA") => {:name "niquola", :address {:city "LA"}, :profiles [{:type "github", :link "https://….."} {:type "twitter", :link "https://….."}], :age 37}
Actualiza algún valor:
(update-in user [:profiles 0 :link] (fn [old] (str old "+++++")))
Seleccione solo una clave específica:
(select-keys user [:name :address])
Lo mismo con el vector:
(def clojurists [{:name "Rich"} {:name "Micael"}]) (first clojurists) (second clojurists) => {:name "Michael"}
Hay cientos de operaciones de la biblioteca base que le permiten operar en estas estructuras de datos. Hay una interoperabilidad con el host. Necesitas acostumbrarte un poco:
(js/alert "Hello!") => nil </csource> "". location window: <source lang="clojure"> (.-location js/window)
Hay cada azúcar para ir a lo largo de las cadenas:
(.. js/window -location -href) => "http://localhost:3000/#/billing/dashboard"
(.. js/window -location -host) => "localhost:3000"
Puedo tomar la fecha JS y devolverle el año:
(let [d (js/Date.)] (.getFullYear d)) => 2018
Rich Hickey, el creador de Clojure, nos ha limitado severamente. Realmente no tenemos nada más, por lo que hacemos todo a través de estructuras de datos genéricas. Por ejemplo, cuando escribimos SQL, generalmente lo escribimos con una estructura de datos. Si observa detenidamente, verá que esto es solo un hashmap en el que algo está incrustado. Luego hay alguna función que traduce todo esto en una cadena SQL:
{select [:*] :from [:users] :where [:= :id "user-1"]} => {:select [:*], :from [:users], :where [:= :id "user-1"]}
También escribimos rutas con una estructura de datos y estructuras de datos tipográficas:
{"users" {:get {:handler :users-list}} :get {:handler :welcome-page}}
[:div.row [:div {:on-click #(.log js/console "Hello")} "User "]]
DB en la interfaz de usuario
Entonces, discutimos Clojure. Pero mencioné anteriormente que un gran logro en el backend fue la base de datos. Si observa lo que está sucediendo en la interfaz ahora, veremos que los chicos usan el mismo patrón: ingresan a la base de datos en la interfaz de usuario (en una aplicación de una sola página).
Las bases de datos se introducen en elm-architecture, en el marco de Ccripure con secuencia de comandos, e incluso en alguna forma limitada en flux y redux (se deben configurar complementos adicionales aquí para lanzar solicitudes). La arquitectura, el nuevo marco y el flujo de Elm se lanzaron aproximadamente al mismo tiempo y se tomaron prestados el uno del otro. Escribimos en remarcar. A continuación, hablaré un poco sobre cómo funciona.

El evento (es un poco como redux) sale de la vista-chi, que es capturada por cierto controlador. El controlador que llamamos controlador de eventos. El controlador de eventos emite un efecto, que también es alguien interpretado por la estructura de datos.
Un tipo de efecto es actualizar la base de datos. Es decir, toma el valor de la base de datos actual y devuelve uno nuevo. También tenemos una suscripción, un análogo de solicitudes en el backend. Es decir, estas son algunas consultas reactivas que podemos lanzar a esta base de datos. Estas solicitudes reactivas, posteriormente nos agrupamos en la vista. En el caso de reaccionar, parecemos volver a dibujar completamente, y si el resultado de esta solicitud ha cambiado, esto es conveniente.
React está presente con nosotros solo en algún lugar al final, y en general la arquitectura no está relacionada de ninguna manera con él. Se parece a esto:

Aquí se agrega lo que falta, por ejemplo, en redux-s.
Primero, separamos los efectos. La aplicación frontend no es independiente. Tiene un cierto backend, una especie de "fuente de verdad". La aplicación debe escribir constantemente algo allí y leer algo desde allí. Peor aún, si tiene varios backends a los que debería ir. En la implementación más simple, esto se podría hacer directamente en el creador de acciones, en su controlador, pero esto es malo. Por lo tanto, los chicos de re-frame introducen un nivel adicional de indirección: una cierta estructura de datos sale del controlador, que dice lo que hay que hacer. Y esta publicación tiene su propio controlador que hace el trabajo sucio. Esta es una introducción muy importante, que discutiremos más adelante.
También es importante (a veces se olvidan): algunos datos básicos deben estar en la base. Todo lo demás se puede eliminar de la base de datos, y las consultas generalmente hacen esto, transforman los datos, no agregan nueva información, sino que estructuran correctamente la existente. Necesitamos esta consulta. En redux, en mi opinión, esto ahora proporciona reselect, y en re-frame lo tenemos listo para usar (incorporado).
Echa un vistazo a nuestro diagrama de arquitectura. Reproducimos un pequeño backend (en el estilo de la Web 2.0) con una base, controlador, vista. Lo único agregado es la reactividad. Esto es muy similar a MVC, excepto que todo está en un solo lugar. Una vez que los primeros MVC para cada widget crearon su propio modelo, pero aquí todo se pliega en una base. En principio, puede sincronizar con el backend desde el controlador a través del efecto, puede crear un aspecto más genérico para que la base de datos funcione como un proxy para el backend. Incluso hay algún tipo de algoritmo genérico: escribe en su base de datos local y se sincroniza con la principal.
Ahora, en la mayoría de los casos, la base es solo un tipo de objeto en el que escribimos algo en redux. Pero, en principio, uno puede imaginar que más adelante se convertirá en una base de datos completa con un rico lenguaje de consulta. Quizás con algún tipo de sincronización genérica. Por ejemplo, hay datomic, una base de datos lógica de triple tienda que se ejecuta directamente en el navegador. Lo recoges y pones todo tu estado allí. Datomic tiene un lenguaje de consulta bastante rico, comparable en potencia a SQL, e incluso gana en algún lugar. Otro ejemplo es Google escribió lovefield. Todo se moverá a alguna parte allí.
A continuación explicaré por qué necesitamos una suscripción reactiva.
Ahora tenemos la primera percepción ingenua: conseguimos al usuario desde el backend, lo ponemos en la base de datos y luego tenemos que dibujarlo. En el momento del renderizado, sucede mucha lógica cierta, pero mezclamos esto con el renderizado, con la vista. Si inmediatamente comenzamos a representar a este usuario, obtenemos una gran pieza difícil que hace algo con el DOM virtual y algo más. Y se mezcla con el modelo lógico de nuestra visión.
Un concepto muy importante que debe entenderse: debido a la complejidad de la interfaz de usuario, también debe modelarse. Es necesario separar cómo se dibuja (como parece) de su modelo lógico. Entonces el modelo lógico será más estable. No puede cargarlo con la dependencia de un marco específico: Angular, React o VueJS. Un modelo es el ciudadano de primera clase habitual en su tiempo de ejecución. Idealmente, si son solo algunos datos y un conjunto de funciones por encima de ellos.

Es decir, a partir del modelo de back-end (objeto), podemos obtener un modelo de vista en el que, sin utilizar ninguna representación todavía, podemos recrear el modelo lógico. Si hay algún tipo de menú o algo similar, todo esto se puede hacer en el modelo de vista.
Por qué
¿Por qué estamos todos haciendo esto?
He visto buenas pruebas de IU solo donde hay un equipo de 10 evaluadores.
Por lo general, no hay pruebas de IU. Por lo tanto, estamos tratando de sacar esta lógica de los componentes en el modelo de vista. La falta de pruebas es una muy mala señal, lo que indica que algo está mal allí, de alguna manera todo está mal estructurado.
¿Por qué es difícil probar la IU? ¿Por qué los chicos del backend aprendieron cómo probar su código, proporcionaron una cobertura enorme y realmente ayuda a vivir con el código del backend? ¿Por qué está mal la IU? Lo más probable es que estamos haciendo algo mal. Y todo lo que describí anteriormente en realidad nos movió en la dirección de la capacidad de prueba.
¿Cómo hacemos pruebas?
Si observa de cerca, la parte de nuestra arquitectura, que contiene el controlador, la suscripción y la base de datos, ni siquiera está relacionada con JS. Es decir, este es algún tipo de modelo que opera simplemente en estructuras de datos: los agregamos en alguna parte, de alguna manera transformamos, sacamos la consulta. A través de los efectos, estamos desconectados de la interacción con el mundo exterior. Y esta pieza es totalmente portátil. Se puede escribir en el llamado cljc: este es un subconjunto común entre Clojure Script y Clojure, que se comporta de la misma manera allí y allá. Podemos cortar esta pieza de la interfaz y ponerla en la JVM, donde vive el backend. Luego podemos escribir otro efecto en la JVM, que llega directamente al punto final: tira del enrutador sin ninguna conversión de cadena http, análisis, etc.
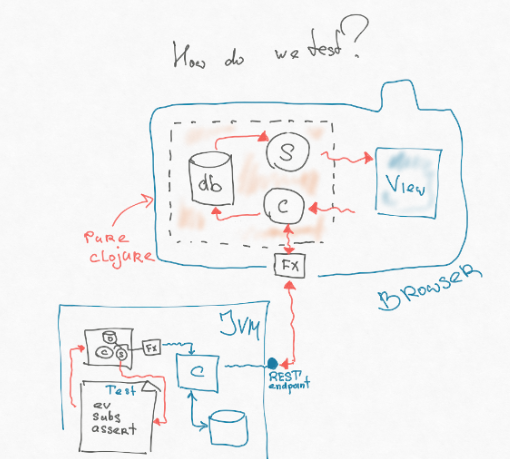
Como resultado, podemos escribir una prueba muy simple: la misma prueba integral funcional que los chicos escriben en el back-end. Lanzamos un evento determinado, arroja un efecto que golpea directamente el punto final en el backend. Nos devuelve algo, lo coloca en la base de datos, calcula la suscripción y en la suscripción se encuentra una vista lógica (ponemos allí la lógica de la interfaz de usuario al máximo). Afirmamos esta opinión.
Por lo tanto, podemos probar el 80% del código en el back-end, mientras que todas las herramientas de desarrollo de back-end están disponibles para nosotros. Usando accesorios o algunas fábricas, podemos recrear una situación específica en la base de datos.
Por ejemplo, tenemos un nuevo paciente o algo no se paga, etc. Podemos pasar por un montón de posibles combinaciones.
Por lo tanto, podemos lidiar con el segundo problema: con un sistema distribuido. Debido a que el contrato entre los sistemas es precisamente el principal problema, porque estos son dos tiempos de ejecución diferentes, dos sistemas diferentes: el backend cambió algo y algo se rompió en nuestra interfaz (no puede estar seguro de que esto no suceda).
Demostración
Así es como se ve en la práctica. Este es un asistente de backend que limpió la base y escribió un pequeño mundo en ella:
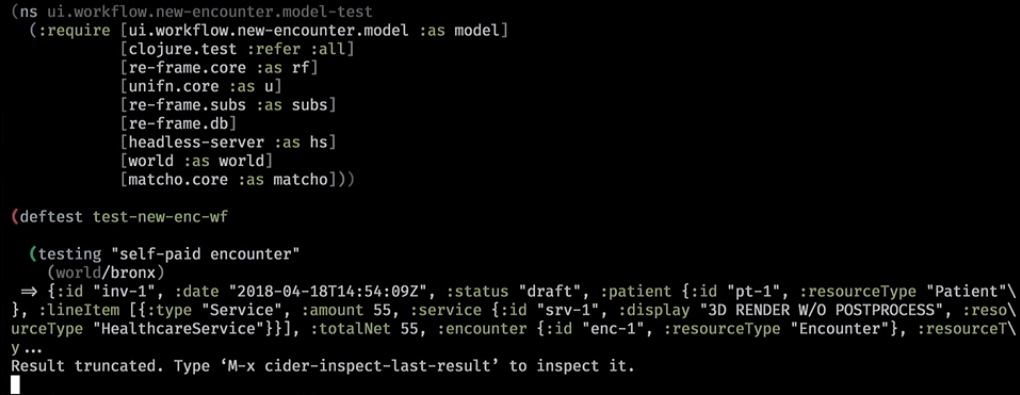
A continuación lanzamos la suscripción:

Por lo general, la URL define completamente la página y se produce algún evento: ahora está en tal o cual página con un conjunto de parámetros. Aquí entramos en un nuevo flujo de trabajo y nuestra suscripción regresó:

Detrás de la escena, fue a la base, tomó algo, lo puso en nuestra base de UI. La suscripción funcionó y se dedujo de él el modelo de vista lógica.
Lo inicializamos. Y aquí está nuestro modelo lógico:

Incluso sin mirar la interfaz de usuario, podemos adivinar lo que se dibujará de acuerdo con este modelo: vendrá alguna advertencia, alguna información sobre el paciente, encuentros y un conjunto de enlaces (este es un widget de flujo de trabajo que dirige la recepción en ciertos pasos cuando llega el paciente).
Aquí llegamos a un mundo más complejo. Hicieron algunos pagos y también probaron después de la inicialización:
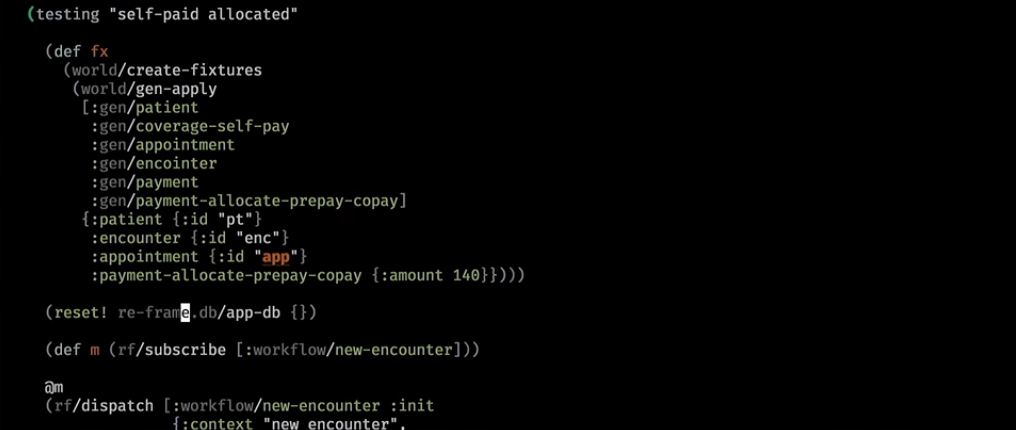
Si ya ha pagado la visita, verá esto en la interfaz de usuario:

Ejecutar pruebas, establecer en CI. La sincronización entre el backend y el frontend estará garantizada por pruebas, y no honestamente.
De vuelta al backend?
Presentamos las pruebas hace seis meses y realmente nos gustó. El problema de la lógica borrosa persiste. Cuanto más inteligente se comporta una aplicación comercial, más información necesita para algunos pasos. Si intenta ejecutar algún tipo de flujo de trabajo desde el mundo real allí, habrá dependencias de todo: para cada interfaz de usuario, necesita obtener algo de diferentes partes de la base de datos en el back-end. Si escribimos sistemas de contabilidad, esto no se puede evitar. Como resultado, como dije, toda la lógica está manchada.
Con la ayuda de tales pruebas, podemos crear la ilusión al menos en tiempo de desarrollo, en el momento del desarrollo, de que nosotros, como en los viejos tiempos de la web 2.0, estamos sentados en el servidor en un tiempo de ejecución y todo es cómodo.
Otra idea loca surgió (aún no se ha implementado). ¿Por qué no bajar esta parte al backend? ¿Por qué no alejarse completamente de la aplicación distribuida ahora? ¿Deje que esta suscripción y nuestro modelo de vista se generen en el backend? Allí la base está disponible, todo es sincrónico. Todo es simple y claro.
La primera ventaja que veo en esto es que tendremos control en un solo lugar. Simplemente simplificamos todo de inmediato en comparación con nuestra aplicación distribuida. Las pruebas se vuelven simples, las validaciones dobles desaparecen. El mundo de moda de los sistemas interactivos multiusuario se abre (si dos usuarios van a la misma forma, les informamos al respecto; pueden editarla al mismo tiempo).
Aparece una característica interesante: al ir al backend y al prospecto de la sesión, podemos entender quién está actualmente en el sistema y qué está haciendo. Esto es un poco como el desarrollo del juego, donde los servidores funcionan así. Allí el mundo vive en el servidor, y el front-end solo se renderiza. Como resultado, podemos obtener un cierto cliente ligero.
Por otro lado, esto crea un desafío. Tendremos que tener un servidor con estado en el que vivan estas sesiones. Si tenemos varios servidores de aplicaciones, será necesario equilibrar adecuadamente la carga o replicar la sesión. Sin embargo, existe la sospecha de que este problema es menor que la cantidad de ventajas que obtenemos.
Por lo tanto, vuelvo al eslogan principal: hay muchos tipos de aplicaciones que se pueden escribir sin distribuir, para eliminar la complejidad de ellas. Y puede obtener un aumento múltiple en la eficiencia si revisa una vez más los postulados básicos en los que confiamos en el desarrollo.
Si le gustó el informe, preste atención: del 24 al 25 de noviembre, se celebrará un nuevo HolyJS en Moscú, y también habrá muchas cosas interesantes allí. La información ya conocida sobre el programa está en el sitio , y los boletos se pueden comprar allí.