
Este artículo está dedicado a estudiar la estructura de archivos del disco duro de una grabadora de video de ocho canales con el propósito de extraer en masa los archivos de video. Al final del artículo se encuentra la implementación del programa correspondiente en C.
La grabadora de video (DVR abreviado) QCM-08DL se utiliza en sistemas de video vigilancia y permite la grabación de video y audio de ocho canales. Este modelo, en mi opinión, es uno de los más baratos y al mismo tiempo confiable en operación. El formato de compresión de video es el popular formato H264. Para audio, el formato de compresión es ADPCM. El video y el audio se graban en un disco duro SATA (HDD) estándar instalado dentro del DVR. Usando el DVR en sí, es posible ver grabaciones buscándolas por fecha y hora. Además, es posible extraer datos a un archivo en un medio externo. En primer lugar, a una unidad USB que se conecta a la interfaz USB del DVR. En segundo lugar, a la computadora a través de la interfaz WEB del DVR. El nombre del archivo resultante es largo e incluye la fecha de grabación, la hora de inicio y finalización, el canal de grabación y otra información adicional. La extensión del archivo es ".264". Un examen del contenido de dicho archivo me dejó claro que el contenedor de medios en el que se empaquetan las transmisiones de audio y video está lejos de ser estándar. Dicho archivo se puede abrir con el reproductor que viene con el DVR. El jugador está muy incómodo. Pero también, puede usar el programa repacker en el contenedor AVI, que también está incluido. Este programa vuelve a empaquetar el flujo de video, dejándolo en el formato H264. Y el flujo de sonido se convierte de ADMCM a PCM, aumentando su tamaño 4 veces. El resultado es un archivo .avi que puede reproducir cualquier reproductor estándar. Noto de inmediato que este programa de reempaquetado es muy inconveniente. Le permite realizar operaciones en un solo archivo. Para volver a empaquetar un conjunto de archivos, debe abrirlos a su vez.
Se establecieron las siguientes tareas.
- Obtenga acceso a todos los archivos .264 del disco duro del DVR conectando el disco duro a la computadora.
- Para estudiar el algoritmo por el cual funciona el programa de repacker 264-avi estándar y crear el mismo programa que realizaría las mismas operaciones, pero no en uno, sino en un grupo completo de archivos, con un solo clic.
La primera tarea, a primera vista, puede parecer muy simple: solo necesita conectar el HDD a la computadora y abrir las particiones en Explorer. Sin embargo, hay dificultades. Este artículo está dedicado a la primera tarea.
Ya sabía de antemano que la carcasa del software del microcontrolador DVR se basa en un sistema operativo similar a Linux. Por lo tanto, la partición del disco duro probablemente también sea similar a Linux. Por lo tanto, necesita una computadora Linux. En mi caso, la capacidad del HDD es de 1TB, una computadora con OS Xubuntu. Después de conectar el HDD a la computadora, pude ver solo una partición por varios gigabytes. Claramente, esto no es lo que necesitas. Dentro de la sección hay muchas carpetas con el formato de nombre "AAAA-MM-DD" correspondientes a las fechas de los registros. Dentro de cada carpeta hay muchos archivos correspondientes a las entradas. Archivos del mismo nombre que los obtenidos al extraer del DVR. Sin embargo, su tamaño es muchas veces menor y la extensión no es .264, sino .nvr. Se debe suponer que estos mismos archivos nvr son claves para los 264 archivos correspondientes (o sus secuencias de medios), cuyo contenido se encuentra en el espacio principal del HDD. Copié los datos de la carpeta de archivos a un medio separado para una mayor investigación.
Utilicé muchas herramientas de software para la investigación: un editor de disco (también es un editor de archivos binarios) DiskExplorer (utilicé WinHex más tarde), MS Excel para cálculos auxiliares y resultados de fijación, entorno de programación Dev-C ++ para escribir programas de consola auxiliar y final, etc. En este artículo intentaré hablar sobre este procedimiento.
Primero, mire el primer sector del HDD (un sector (1 LBA) toma 512 Bytes). Este sector, como regla, contiene una estructura MBR. Incluye un gestor de arranque y una tabla básica de secciones de contenido. La estructura de este sector, así como la estructura de la descripción de la sección, se proporciona a continuación (tomado de Wikipedia).

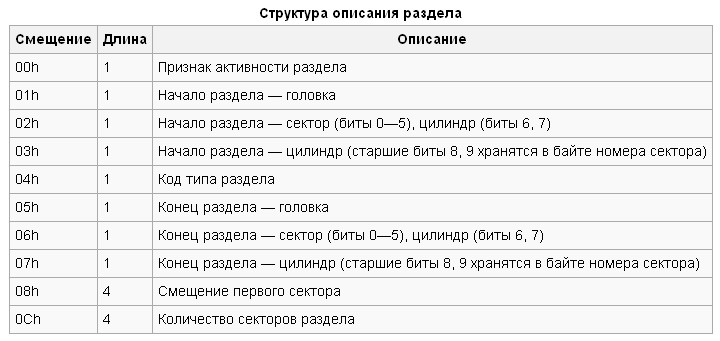
En el caso del HDD investigado, tenemos lo siguiente. Mirando la figura a continuación y siguiendo las tablas anteriores, vemos que falta el gestor de arranque. Pero estamos más interesados en la tabla de particiones. Se resalta en un marco rojo. Los dos últimos bytes (relleno azul): firma MBR. Puede ver en la tabla de particiones que el disco está dividido en dos secciones. El código para el tipo de la primera sección (relleno amarillo) es 0x0B. Esta es una partición FAT32. El código para el tipo del segundo (relleno naranja) es 0x83. Esta es una de las particiones de Linux (en el sentido de EXT). Los bytes del código del tipo de partición están encerrados en un círculo azul.
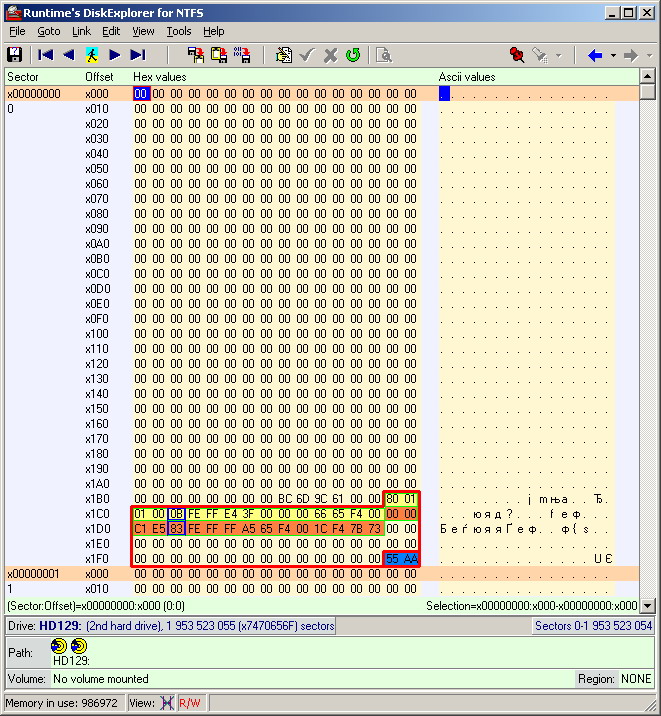
A continuación se ofrece un descifrado completo del sector MBR con una tabla de secciones y sus parámetros.
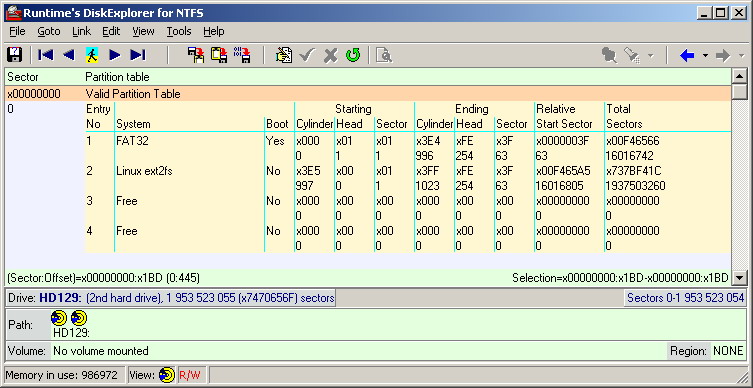
Prestando atención al tamaño de las particiones (contando el número de sectores en gigabytes), es fácil adivinar que en la computadora con el sistema operativo Xubuntu fue la primera partición que ocupó una pequeña parte del espacio en disco. Por cierto, en Windows XP solo se mostró la primera partición, pero no se abrió desde el explorador. ¿Y por qué, entonces, la segunda partición de Linux no apareció en el sistema operativo Xubuntu?
Habiendo estudiado previamente la estructura y organización del sistema de archivos Linux usando EXT2 como ejemplo, comencé a estudiar la segunda sección.
Como puede ver en la tabla de secciones, la segunda sección comienza con el sector 16016805. El manual del sistema de archivos EXT2 indica la presencia del llamado superbloque, que se encuentra a 1024 bytes desde el principio de la sección (es decir, dos sectores desde el principio). Sin embargo, el sector 16016805 + 2 = 16016807 estaba vacío. Pero el primer sector 16016805 en su estructura se parecía a un superbloque. Pero su contenido no se correspondía completamente con la descripción del contenido del superbloque del manual. El superbloque es el bloque principal, que contiene una especie de tabla de varias constantes y parámetros para el funcionamiento del sistema de archivos: direcciones de posiciones y tamaños de otros bloques necesarios, en particular, encabezados de registros de archivos y directorios. La investigación adicional en esta sección me llevó a una sola conclusión: el DVR usa su propio sistema de archivos único.
En el futuro, decidí mirar el primer sector de la primera sección (sector 63) y desplazarme hacia abajo. Se encontró en el contenido del sector 65 (dos sectores a continuación) que es completamente similar al contenido del superbloque FS EXT2, que se describe en el manual. Investigaciones posteriores llevaron a la conclusión de que la primera partición del HDD DVR es la partición EXT2, que se mostró en el sistema operativo Xubuntu, independientemente de la marca 0x08 (no EXT) en la tabla de contenido. Por lo tanto, la primera partición del disco duro del DVR es la partición EXT2, en la que se graban los archivos nvr, que son las claves para las grabaciones de video requeridas.
Escribiré brevemente sobre la estructura de los archivos .264, que también examiné anteriormente. Esta información será necesaria en el futuro para estudiar la segunda sección del HDD. Como en cualquier contenedor de medios, en "264" hay un encabezado con información de servicio y etiquetas de medios, así como secuencias de audio y video que siguen en pequeños bloques uno tras otro. Con un desplazamiento de 0x84 bytes desde el comienzo del archivo, se registra la palabra clave "MDVR96NT_2_R". Antes de esta palabra hay bytes relacionados con la fecha y hora de grabación. Pero esta información está contenida en el nombre del archivo, por lo tanto, no merece especial atención aquí. Después de eso viene una gran cantidad de bytes de ceros. La información principal con transmisiones de audio y video se origina en un desplazamiento de 65.536 bytes. Los bloques de transmisión de video comienzan con un encabezado de 8 bytes "01dcH264" (también encontrado "00dcH264"). Los siguientes 4 bytes describen el tamaño del bloque actual de la transmisión de video en bytes. Después de 4 bytes de ceros (00 00 00 00), comienza el bloque de transmisión de video. Los bloques de transmisión de audio tienen el título "03wb" (aunque, según mis observaciones, el primer carácter del encabezado en algunos casos no era necesariamente "0"). Después: 12 bytes de información que aún no he descubierto. Y comenzando con el byte 17, una secuencia de audio de una longitud fija de 160 bytes. No hay etiquetas al final del archivo.
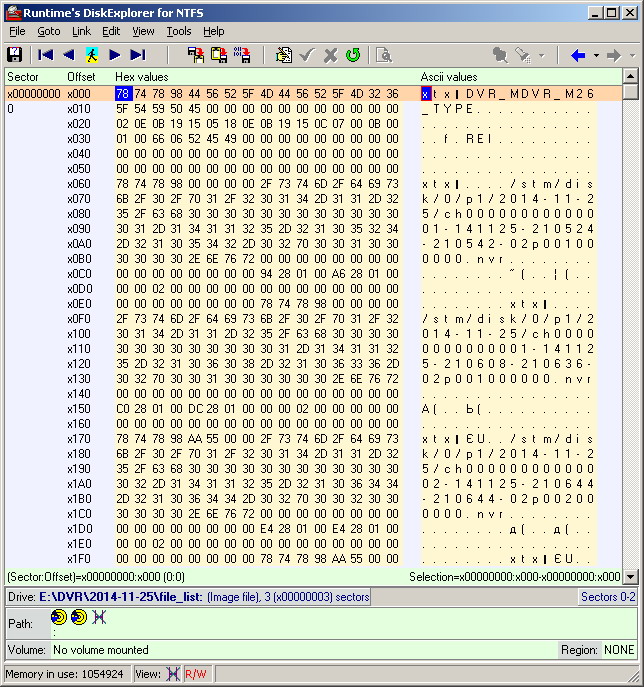
Procedemos a estudiar la estructura de los archivos y directorios ubicados en la primera partición del HDD. Como se mencionó anteriormente, el contenido de la sección se copió a un medio separado a través de un explorador regular en el sistema operativo Xununtu. En cada directorio (directorio), además de los archivos nvr, hay un archivo binario llamado "file_list". A juzgar por el nombre, contiene información sobre la lista de archivos en el directorio actual. Abra este archivo en el editor binario (vea la figura a continuación). Investigué la estructura de este archivo, y básicamente no hay nada interesante aquí. El archivo no tiene ninguna información sobre la ubicación de las transmisiones multimedia deseadas. Sin embargo, escribiré brevemente sobre esta estructura. Los primeros 32 bytes son un encabezado con algunas constantes. Los siguientes 16 bytes están relacionados con la fecha y hora y el número de archivos en el directorio actual. Esto es seguido por 48 bytes de constantes. Siguiente: 8 bytes de constantes, que indican el comienzo del registro del archivo. A continuación, 96 bytes que indican la ruta completa al archivo nvr, incluido su nombre. Siguiente: 24 bytes relacionados con el tiempo (el número de segundos transcurridos desde el comienzo del día, el comienzo y el final del video) y otros atributos del video. Y así sucesivamente, por analogía, para todos los archivos nvr en el directorio actual. Su número es igual al número de videos para el día actual, indicado por el nombre del directorio actual. ¿Para qué es este archivo? Aparentemente, para acelerar la búsqueda de video dentro de la interfaz DVR.
Pasemos a estudiar la estructura de los propios archivos nvr. La apariencia de uno de esos archivos en un editor binario (más precisamente, en un hexadecimal) se muestra en la figura a continuación. Sin entrar en detalles de la descripción de la estructura de contenido (parte de la cual seguía siendo un misterio para mí), destaqué los parámetros más básicos, que son la clave que se encuentra. Estos son valores de 32 bits (4 bytes), ubicados cada 32 bytes, comenzando desde el byte en el desplazamiento 40. En la figura están resaltados en rojo. En el futuro, me convencí de que esto es suficiente para la clave de los videos. Les recuerdo que 4 bytes del valor de este parámetro clave se encuentran de menor a mayor, ¡pero no al revés! Esta notación se debe a la arquitectura del procesador de la PC. El ejemplo en la figura muestra el primer archivo nvr del primer directorio. Corresponde a la primera grabación de video realizada por el DVR. Obviamente, los valores de los parámetros, que llamé clave, en el ejemplo anterior forman una secuencia de enteros, comenzando desde cero y yendo en orden ascendente. Al examinar otros archivos nvr y observar exactamente estos bytes especificados en ellos, también se vieron enteros, ascendentes. Pero esta secuencia, naturalmente, ya no comenzó desde cero, y en algunos casos se observaron lagunas en uno o dos números en algunos lugares. Por ejemplo (números de la excavadora): 435, 436, 438, 439, 442, ... (o en hexadecimal: B3010000, B4010000, B6010000, B7010000, BA010000, ...).
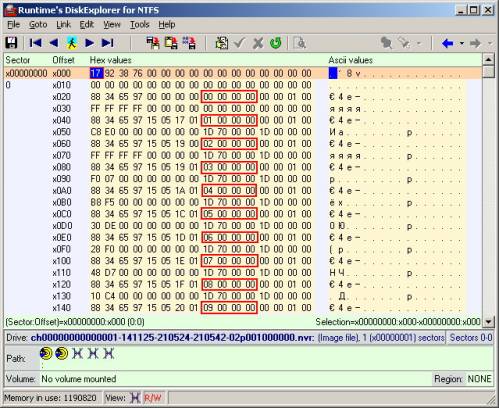
Tal secuencia con omisiones ocurrió en los archivos nvr correspondientes a los videos que el DVR grabó simultáneamente desde dos o más canales. Es decir, por ejemplo, si la secuencia "435, 436, 438, 439, 442, ..." se refiere al video de un canal, entonces los valores faltantes (437, 440, 441) se relacionarán con el video de otro canal, que se realizó en el mismo punto en el tiempo Yo mismo estaba convencido de esto al ver y comparar los archivos nvr correspondientes, en función de su nombre. No hay duda de que los números anteriores forman los números de algunas partes relacionadas con los videos. Solo queda desentrañar la relación entre estos números y las coordenadas del espacio en disco en el que se encuentran los datos.
Además, fue para averiguar exactamente qué datos se dividen en los segmentos numerados anteriormente. La primera suposición: los datos son flujos de audio y video, que en el contenedor 264 están representados por bloques cortos y, como se ha dicho, los bloques del flujo de video tienen diferentes tamaños. Al mismo tiempo, el DVR recoge estas transmisiones y las empaqueta en un contenedor 264 en la etapa de extracción de grabaciones de video a medios externos.El segundo supuesto es que la DVR empaqueta transmisiones de audio y video en un contenedor 264 al principio y durante la captura de video. Y al mismo tiempo, los datos del archivo .264 ya generados se escriben en el HDD, lo que habría resultado como resultado de su extracción a un medio externo. Al explorar el espacio HDD en algún lugar en el medio de la segunda sección, junto con los bytes de las transmisiones de audio y video y sus encabezados del mismo tipo que en el contenedor 264, también encontré los encabezados del contenedor en sí: MDVR96NT_2_R. Después de este encabezado, también había muchos bytes de ceros. En general, el estudio mostró que hay una segunda opción de las dos anteriores. Por lo tanto, para obtener el archivo .264 deseado, lo más probable es que solo necesite conectar todos los segmentos cuyos números están contenidos en el archivo nvr correspondiente.
Comencemos la búsqueda de la relación entre el número de segmento y las coordenadas en el HDD.
El comienzo de los datos del contenedor 264 correspondiente a la primera grabación de video (donde la numeración de los segmentos comienza desde cero) con las herramientas de búsqueda que encontré en el sector 16046629 (29824 sectores desde el comienzo de la sección). Podemos hacer una suposición sobre el llamado parámetro sesgo inicial, que participará en la fórmula que describe la dependencia deseada.
Tomemos dos archivos nvr correspondientes a videos de diferentes canales que el DVR capturó al mismo tiempo. Para hacer esto, eche un vistazo a los nombres de los archivos. Por ejemplo, los videos señalados por los archivos "ch00000000000001-150330-160937-161035-02p101000000.nvr" y "ch00000000000004-150330-160000-163000-00p004000000.nvr" se grabaron simultáneamente. El primer registro es la grabación del primer canal de 16:09:37 a 16:10:35 hora. El segundo registro es un registro del cuarto canal de 16:00:00 a 16:30:00 hora. Ambas entradas se realizaron el 30 de marzo de 2015. En la línea de tiempo, obviamente, el intervalo de tiempo del primer registro es un subconjunto del intervalo de tiempo del segundo registro. También tengo en cuenta el hecho de que en un intervalo de tiempo más corto (en la intersección de dos intervalos) el DVR no realizó la captura de video de ninguno de los otros 6 canales. Explore el contenido de estos archivos nvr. Nos aseguraremos de que los números faltantes (números de segmento) en el segundo archivo largo estén necesariamente presentes en el primer archivo corto, completa y completamente. Usando el DVR de la manera habitual, debe extraer al menos uno de los archivos .264 referenciados por los archivos nvr investigados de antemano. Supongamos que se extrajo "ch00000000000001-150330-160937-161035-02p101000000.264". Ábralo en el editor binario. Como ya se mencionó, al comienzo de este archivo, antes de la palabra clave "MDVR96NT_2_R" hay bytes únicos que corresponden a la fecha y hora de la grabación de video contenida en este archivo. Cancelamos todos estos bytes, comenzando desde cero y terminando con el encabezado (cuanto más corta sea la cadena de bytes exclusiva de esta grabación de video, mejor). Además, escriba el desplazamiento de esta cadena de bytes desde el principio del archivo. Cabe señalar que al comienzo del archivo .264 extraído hay 4 bytes adicionales de ceros. Esto se hizo notable al comparar los primeros 512 bytes del archivo .264 y el sector de espacio en disco desde el cual comienza el contenido de uno de los archivos .264 (un archivo de casi cualquier sistema de archivos siempre comienza al comienzo del sector, además, un clúster). Es decir, la información en el archivo .264 se desplaza por adelantado 4 bytes a la derecha. El tamaño (en bytes) de cualquier archivo .264 es un múltiplo de 512 solo después de restar primero el número 4 del tamaño. Comencemos la búsqueda del sector desde el que comienza el archivo .264 investigado. En el editor de discos, inicie la función de búsqueda. En el campo del valor deseado, ingrese una cadena única de bytes eliminada de antemano. Para acelerar la búsqueda, ingrese el valor de desplazamiento en el campo "buscar por desplazamiento", restando previamente 4. Inicie la búsqueda. Unas horas después, la búsqueda fue exitosa. Anotamos el número del sector en el que se encuentra el título único. Que este sea el valor de s. Observamos el contenido del archivo nvr para este video. Cancelamos el número del primer segmento (4 bytes en el desplazamiento 40). Deje que este sea el valor de b. En total, si bien conocemos el número de sector del disco (16046629) para el número de segmento cero (en la primera grabación de video) y el número del sector encontrado de los discos s para el número de segmento b que se acaba de escribir. Puede calcular el tamaño de segmento estimado: (s-16046629) / (b-0). Después de calcular, obtuve el valor 128. ¡Por lo tanto, el tamaño del segmento es igual a 128 sectores de disco (LBA), o 128 * 512 = 65536 bytes!
Realicé otro experimento interesante adicional para finalmente disipar todas las dudas. Se describe a continuación.
Desde el comienzo del sector s, seleccionamos un área en el disco con un tamaño comparable al tamaño de un archivo .264 que comienza con este sector. Si mis suposiciones son correctas, los segmentos de otro archivo .264, que fue capturado en el HDD simultáneamente con el primero, caerán en el área seleccionada. Guarde esta área en un archivo (cree una imagen). Corte la imagen resultante en archivos de 65.536 bytes (tamaño de segmento). Esto se puede hacer usando la función "dividir archivo" en Total Commander. Que sean piezas M1, M2, M3, .... Del mismo modo, cortamos el archivo .264 estudiado (que se extrajo de una manera fácil de usar del DVR), pero primero eliminamos 4 bytes de ceros primero. Que sean piezas K1, K2, K3, .... Usando la función "Comparar por contenido" en Total Commander, comparamos a su vez las piezas de la imagen y las piezas del archivo .264. (M1 con K1, M2 con K2, etc.), guiado por los números de segmento del archivo nvr correspondiente. El resultado es el siguiente.
Supongamos (números de la excavadora), la cadena de números en nvr es la siguiente: 435, 436, 438, 439, 442, ... En esta situación, M1 = K1, M2 = K2, M4 = K3, M5 = K4, M8 = K5, ... Es decir, las piezas en las que se dividieron el archivo de imagen y el archivo .264 son iguales, teniendo en cuenta el avance correspondiente en el número de piezas del archivo de imagen, según las omisiones en la secuencia. Aqui esta!En total, obtuvimos la dependencia estimada: S = 16046629 + 128 * d, donde d es el número de segmento en el archivo nvr, y S es el número de sector en el HDD, comenzando desde el comienzo del disco desde el cual comienzan los contenidos del segmento. Tamaño del segmento - 128 sectores. La fórmula anterior no tiene en cuenta la existencia de la segunda sección. La dependencia se encuentra solo para un ejemplo específico de HDD a 1TB. Quizás si coloca una capacidad diferente en el HDD DVR, las constantes tendrán un aspecto diferente.Para verificar la validez de la fórmula, calculamos la posición del primer segmento de algún otro archivo arbitrario .264, guiados por el archivo nvr correspondiente. Prestando atención a la fecha y hora en el nombre del archivo, compárelos con los primeros bytes en el encabezado .264 ubicado en el sector calculado. Los bytes que codifican individualmente el número, mes, año, horas, minutos, segundos, corresponden a datos temporales en el nombre del archivo. Por lo tanto, "golpear el clavo"! Calculamos en el archivo nvr correspondiente al archivo .264 extraído de antemano, el número de segmentos cs. En general, su número es cs = sf / 32-1, donde sf es el tamaño del archivo nvr. Si el archivo .264 consta de segmentos cs, entonces su tamaño debe ser igual a cs * 65536 + 4 (el número de segmentos multiplicado por el tamaño del segmento en bytes, más 4 de los mismos bytes de ceros). ¡Y realmente lo es!Aún así, intenta explorar la segunda sección. Como se señaló anteriormente, algo similar a un superbloque se encuentra directamente en el primer sector de la sección (16016805). Y su copia exacta fue descubierta por siete sectores a continuación (16016812). Obviamente, la información básica distinta de cero se encuentra en el primer sector del superbloque. Su aparición en el editor de discos se muestra en la figura a continuación.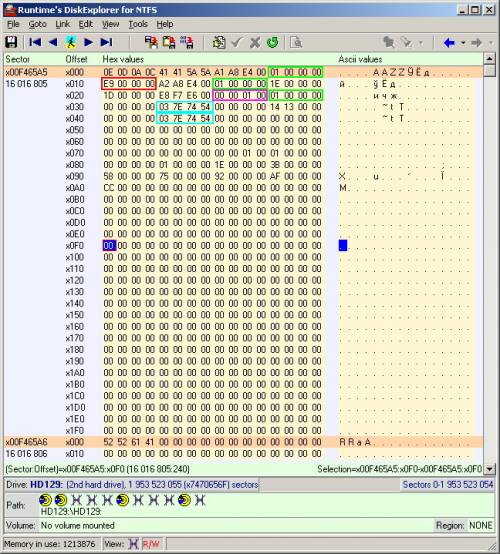 Logré descifrar una parte de los parámetros de 4 bytes. La fecha y hora de montaje de la partición se resaltan en azul. La fecha y la hora se presentan en una notación especial "Tiempo Unix" (el número de segundos transcurridos desde la medianoche del 1 de enero de 1970). En el ejemplo anterior, "03 7E 74 54" (valor decimal 1416920579) corresponde a "Mar, 25 de noviembre de 2014 13:02:59 GMT". Para traducir los valores, utilicé una calculadora en línea especial. El valor 65536 está encerrado en un círculo en el marco púrpura. Es posible que el intérprete del sistema de archivos dentro del programa DVR se refiera a esta posición del superbloque cuando se lee el tamaño del bloque (en el contexto anterior, llamé segmentos de bloques). Los valores 1 se resaltan en el cuadro verde, uno de ellos probablemente indica la posición del comienzo de la llamada. mapa de bits (en el número de bloques desde el comienzo de la sección). De hechode antemano, se encontró el comienzo de la información, algo similar a un mapa de bits en el sector 16016933 (16016805 + 128 * 1). El valor 233 se resalta en el cuadro rojo. Esta es precisamente la posición del comienzo de estas grabaciones de video .264 desde el comienzo de la sección: 16016805 + 128 * 233 = 16046629.Es decir, la segunda sección se puede llamar una sección truncada y ligeramente modificada de EXT2. Tiene un superbloque, una copia, un mapa de bits. Pero no hay los llamados. nodos de información correspondientes a registros de archivos. La sección contiene datos de archivos .264 (transmisiones de audio y video), pero los nodos de información (digamos así) para estos datos se encuentran en archivos nvr en la primera sección. Tal vez hay una redacción más competente? Pero esto no es tan importante para mí.Escribamos un programa simple para la extracción masiva de archivos .264. Debo decir de inmediato que no tengo mucha experiencia en programación en Windows. El programa escanea todos los archivos nvr copiados por adelantado a la sección de 1TB del nuevo HDD. Al analizarlos, el programa crea un archivo .264 con el mismo nombre en el mismo directorio, utilizando el acceso a los sectores del HDD original. Anteriormente, se creó una carpeta con el nombre "DVR" en una sección vacía del nuevo HDD, en la que se colocan las carpetas por fechas, que se copian de la "forma habitual" en Linux. Fue posible incluir en este programa un algoritmo para trabajar con la primera partición de Linux para acceder a los archivos nvr para no tener que copiarlos previamente. Y podría agregar otras características convenientes. Sí, era posible, pero en ese momento quería hacer todo lo más rápido posible.No utilicé la recursividad para escanear directorios, dado que el formato de los directorios es fijo y tiene dos niveles de archivo adjunto. En consecuencia, apliqué dos ciclos: ejecutar a través de las carpetas hasta que finalicen, y ejecutar a través de los archivos en cada carpeta con la misma condición. Para leer archivos, utilicé la función fopen. Para trabajar con sectores de HDD, utilicé la funcionalidad de WinAPI similar a trabajar con archivos. Pasemos al código del programa.Las bibliotecas necesitan tal.
Logré descifrar una parte de los parámetros de 4 bytes. La fecha y hora de montaje de la partición se resaltan en azul. La fecha y la hora se presentan en una notación especial "Tiempo Unix" (el número de segundos transcurridos desde la medianoche del 1 de enero de 1970). En el ejemplo anterior, "03 7E 74 54" (valor decimal 1416920579) corresponde a "Mar, 25 de noviembre de 2014 13:02:59 GMT". Para traducir los valores, utilicé una calculadora en línea especial. El valor 65536 está encerrado en un círculo en el marco púrpura. Es posible que el intérprete del sistema de archivos dentro del programa DVR se refiera a esta posición del superbloque cuando se lee el tamaño del bloque (en el contexto anterior, llamé segmentos de bloques). Los valores 1 se resaltan en el cuadro verde, uno de ellos probablemente indica la posición del comienzo de la llamada. mapa de bits (en el número de bloques desde el comienzo de la sección). De hechode antemano, se encontró el comienzo de la información, algo similar a un mapa de bits en el sector 16016933 (16016805 + 128 * 1). El valor 233 se resalta en el cuadro rojo. Esta es precisamente la posición del comienzo de estas grabaciones de video .264 desde el comienzo de la sección: 16016805 + 128 * 233 = 16046629.Es decir, la segunda sección se puede llamar una sección truncada y ligeramente modificada de EXT2. Tiene un superbloque, una copia, un mapa de bits. Pero no hay los llamados. nodos de información correspondientes a registros de archivos. La sección contiene datos de archivos .264 (transmisiones de audio y video), pero los nodos de información (digamos así) para estos datos se encuentran en archivos nvr en la primera sección. Tal vez hay una redacción más competente? Pero esto no es tan importante para mí.Escribamos un programa simple para la extracción masiva de archivos .264. Debo decir de inmediato que no tengo mucha experiencia en programación en Windows. El programa escanea todos los archivos nvr copiados por adelantado a la sección de 1TB del nuevo HDD. Al analizarlos, el programa crea un archivo .264 con el mismo nombre en el mismo directorio, utilizando el acceso a los sectores del HDD original. Anteriormente, se creó una carpeta con el nombre "DVR" en una sección vacía del nuevo HDD, en la que se colocan las carpetas por fechas, que se copian de la "forma habitual" en Linux. Fue posible incluir en este programa un algoritmo para trabajar con la primera partición de Linux para acceder a los archivos nvr para no tener que copiarlos previamente. Y podría agregar otras características convenientes. Sí, era posible, pero en ese momento quería hacer todo lo más rápido posible.No utilicé la recursividad para escanear directorios, dado que el formato de los directorios es fijo y tiene dos niveles de archivo adjunto. En consecuencia, apliqué dos ciclos: ejecutar a través de las carpetas hasta que finalicen, y ejecutar a través de los archivos en cada carpeta con la misma condición. Para leer archivos, utilicé la función fopen. Para trabajar con sectores de HDD, utilicé la funcionalidad de WinAPI similar a trabajar con archivos. Pasemos al código del programa.Las bibliotecas necesitan tal.#include <windows.h> #include <stdio.h> #include <string.h>
Y copié completamente estas funciones de algún foro.
HANDLE openDevice(int device) { HANDLE handle = INVALID_HANDLE_VALUE; if (device <0 || device >99) return INVALID_HANDLE_VALUE; char _devicename[20]; sprintf(_devicename, "\\\\.\\PhysicalDrive%d", device);
La función de copia contiene una fórmula de dependencia lineal, que apareció en la teoría anterior.
void copy(HANDLE device, HANDLE file, unsigned long int s){ LONG HPos; LONG LPos; __int64 sector; sector = 16046629+128*s; HPos = (sector*512)>>32; LPos = (sector*512); SetFilePointer (device, LPos, &HPos, FILE_BEGIN); DWORD dwBytesRead; DWORD dwBytesWritten; unsigned char buf[65536]; ReadFile(device, buf, 65536, &dwBytesRead, NULL); WriteFile(file, buf, dwBytesRead, &dwBytesWritten, NULL); }
La función principal también es bastante simple.
int main(){ HANDLE hdd = openDevice(1);
En una computadora vieja con un procesador Pentium 4 y un controlador PCI SATA, el programa transfirió con éxito hasta el final un HDD completo con varios miles de archivos .264 en un promedio de 7 horas. En una computadora nueva, tres veces más rápido. Como ya señalé, el programa no es universal, todas las constantes y variables se ajustan a mi caso específico de HDD a 1TB. Sin embargo, puede trabajar un poco más y hacerlo universal, dibuje una interfaz gráfica.
En la segunda parte del artículo escribiré cómo "hacerlo usted mismo" para volver a embalar desde el contenedor "264" al contenedor estándar "avi".