Bueno para todos! Bueno, ha llegado el momento de
nuestro próximo
curso Devops . Probablemente, este es uno de los cursos más estables y de referencia, pero al mismo tiempo el más diverso en términos de estudiantes, ya que ningún grupo se ha parecido nunca al otro: en uno los desarrolladores son casi completamente, luego en los siguientes ingenieros, luego administradores, y así sucesivamente. Y esto también significa que ha llegado el momento de obtener materiales interesantes y útiles, así como reuniones en línea.

Este artículo contiene recomendaciones sobre el lanzamiento de un clúster de Kubernetes de calidad de producción en un centro de datos local o ubicación periférica (ubicación de borde).
¿Qué significa el grado de producción?
- Instalación segura
- La gestión de implementación se realiza mediante un proceso repetitivo y registrado;
- El trabajo es predecible y consistente;
- Es seguro llevar a cabo actualizaciones y ajustes;
- Para detectar y diagnosticar errores y falta de recursos, hay registro y monitoreo;
- El servicio tiene suficiente "alta disponibilidad" teniendo en cuenta los recursos disponibles, incluidas las restricciones de dinero, espacio físico, energía, etc.
- El proceso de recuperación está disponible, documentado y probado para su uso en caso de falla.
En resumen, el grado de producción significa anticipar errores y preparar la recuperación con un mínimo de problemas y demoras.

Este artículo trata sobre la implementación en el sitio de Kubernetes en un hipervisor o una plataforma básica, dada la cantidad limitada de recursos de soporte en comparación con el aumento de las principales nubes públicas. Sin embargo, algunas de estas recomendaciones pueden ser útiles para la nube pública si el presupuesto limita los recursos seleccionados.
La implementación de un Minikube de metal desnudo de un solo metal puede ser un proceso simple y económico, pero no es de grado de producción. Por el contrario, no podrá alcanzar el nivel de Google con Borg en una tienda, sucursal o ubicación periférica fuera de línea, aunque es poco probable que lo necesite.
Este artículo describe consejos para lograr una implementación de Kubernetes a nivel de producción, incluso en situaciones de recursos limitados.
Componentes importantes en el clúster de KubernetesAntes de profundizar en los detalles, es importante comprender la arquitectura general de Kubernetes.
El clúster de Kubernetes es un sistema altamente distribuido basado en el plano de control y la arquitectura de los nodos de trabajo agrupados, como se muestra a continuación:
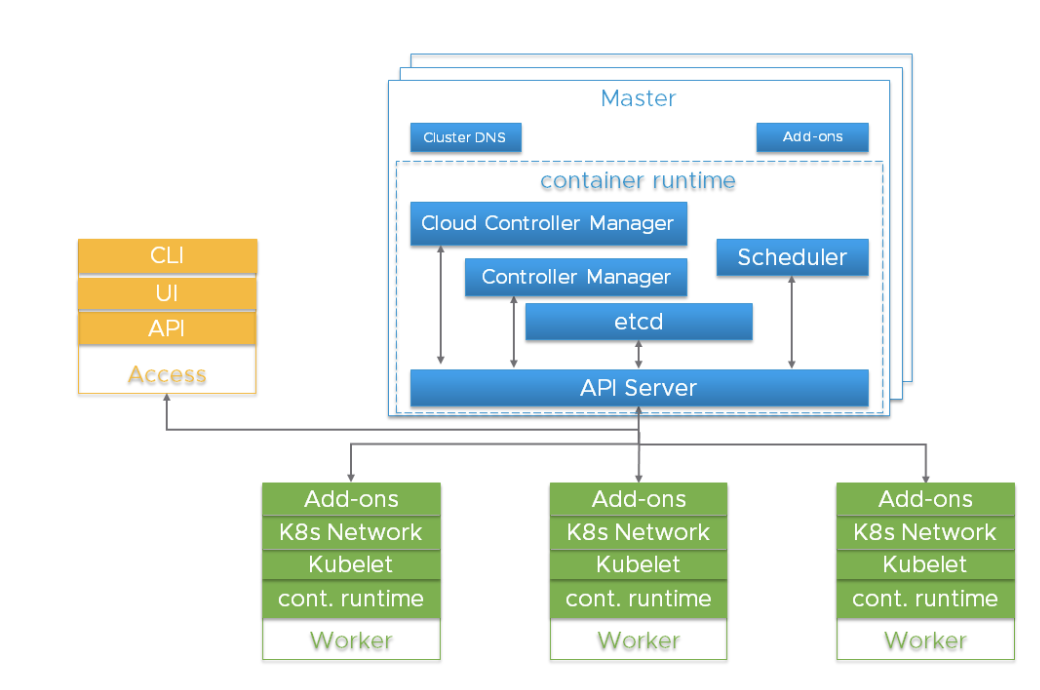
Por lo general, los componentes del Servidor API, Controller Manager y Scheduler están ubicados en varias instancias de nodos de nivel de control (llamados Master). Los nodos maestros también suelen incluir etcd, sin embargo, hay scripts grandes y muy accesibles que requieren ejecutar etcd en hosts independientes. Los componentes se pueden ejecutar como contenedores y, opcionalmente, bajo la supervisión de Kubernetes, es decir, funcionan como hogares estáticos.
Las instancias redundantes de estos componentes se utilizan para alta disponibilidad. La importancia y el nivel requerido de redundancia pueden variar.
| Componente | Roles | Consecuencias de la pérdida. | Instancias recomendadas |
|---|
| etcd | Mantiene el estado de todos los objetos de Kubernetes. | Pérdida catastrófica de almacenamiento. Pérdida de la mayoría = Kubernetes pierde el nivel de control, el Servidor API depende de etcd, las llamadas API de solo lectura que no necesitan un quórum, como las cargas de trabajo ya creadas, pueden continuar funcionando. | número impar, 3+ |
| Servidor API | Proporciona API para uso externo e interno. | No se puede detener, iniciar, actualizar nuevos pods. Scheduler y Controller Manager dependen del servidor API. Las cargas continúan si no dependen de llamadas API (operadores, controladores personalizados, CRD, etc.) | 2+ |
| Kube-Scheduler | Coloca vainas en nodos | Las vainas no se pueden colocar, priorizar o mover entre ellas. | 2+ |
| gestor-controlador-kube | Controla muchos controladores | Los principales circuitos de control responsables del estado dejan de funcionar. La integración en el árbol del proveedor de la nube se rompe. | 2+ |
| administrador-controlador-nube (CCM) | Integración de proveedor de nube fuera del árbol | Se rompe la integración del proveedor de la nube | 1 |
| Adiciones (por ejemplo, DNS) | Diferente | Diferente | Depende del complemento (por ejemplo, 2+ para DNS) |
Los riesgos de estos componentes incluyen fallas de hardware, errores de software, malas actualizaciones, errores humanos, interrupciones de la red y sobrecarga del sistema que resultan en el agotamiento de los recursos. La redundancia puede reducir el impacto de estos peligros. Además, gracias a las características de la plataforma de hipervisor (planificación de recursos, alta disponibilidad), puede multiplicar los resultados utilizando el sistema operativo Linux, Kubernetes y el tiempo de ejecución del contenedor.
El servidor API utiliza varias instancias de equilibrador de carga para lograr escalabilidad y disponibilidad. Un equilibrador de carga es un componente esencial para la alta disponibilidad. Varios registros A del servidor API de DNS pueden servir como alternativa en ausencia de un equilibrador.
Kube-Scheduler y Kube-controller-manager están involucrados en el proceso de selección de un líder en lugar de utilizar un equilibrador de carga. Dado que
cloud-controller-manager se usa para ciertos tipos de infraestructura de alojamiento, cuya implementación puede variar, no los discutiremos, solo indicamos que son un componente del nivel de administración.
Las vainas que se ejecutan en Kubernetes son administradas por el agente kubelet. Cada instancia del trabajador ejecuta un agente de kubelet y un entorno de inicio de contenedor compatible con
CRI . Kubernetes está diseñado para monitorear y recuperarse de fallas de nodo de trabajo. Pero para funciones de carga críticas, gestión de recursos de hipervisor y aislamiento de carga, se puede utilizar para mejorar la accesibilidad y aumentar la previsibilidad de su trabajo.
etcdetcd es un almacenamiento persistente para todos los objetos de Kubernetes. La disponibilidad y la capacidad de recuperación del clúster etcd deben ser una prioridad máxima al implementar Kubernetes de grado de producción.
El clúster etcd que consta de cinco nodos es la mejor opción si puede permitirlo. Por qué Porque puede dar servicio a uno y, al mismo tiempo, soportar fallas. Un grupo de tres nodos es lo mínimo que podemos recomendar para un servicio de calidad de producción, incluso si solo hay un hipervisor de host disponible. Tampoco se recomiendan más de siete nodos, con la excepción de
instalaciones muy grandes que cubren varias zonas de acceso.
Las recomendaciones mínimas para alojar un nodo de clúster etcd son 2 GB de RAM y un disco duro SSD de 8 GB. Por lo general, 8 GB de RAM y 20 GB de espacio en el disco duro son suficientes. El rendimiento del disco afecta el tiempo de recuperación de un nodo después de una falla.
Echa un
vistazo para más detalles.
En casos especiales, piense en varios grupos de etcdPara los grupos de Kubernetes muy grandes, considere usar un grupo de etcd separado para los eventos de Kubernetes, de modo que demasiados eventos no afecten al servicio de API de Kubernetes. Cuando se usa la red Flannel, la configuración se guarda en etcd, y los requisitos de versión pueden diferir de Kubernetes. Esto puede complicar la copia de seguridad de etcd, por lo que recomendamos usar un clúster de etcd separado específicamente para franela.
Implementación de host únicoLa lista de riesgos de accesibilidad incluye hardware, software y el factor humano. Si está limitado a un solo host, el uso de almacenamiento redundante, memoria de corrección de errores y una fuente de alimentación dual puede mejorar la protección contra fallas de hardware. La ejecución de un hipervisor en un host físico le permite usar componentes de software redundantes y agrega beneficios operativos asociados con la implementación, actualización y monitoreo del uso de recursos. Incluso en situaciones estresantes, el comportamiento sigue siendo repetible y predecible. Por ejemplo, incluso si solo puede permitir el lanzamiento de singletones desde los servicios maestros, deben protegerse contra la sobrecarga y el agotamiento de los recursos, compitiendo con la carga de trabajo de su aplicación. Un hipervisor puede ser más eficiente y más fácil de usar que la priorización en el planificador de Linux, cgroups, banderas de Kubernetes, etc.
Puede implementar tres máquinas virtuales etcd si los recursos del host lo permiten. Cada VM debe ser compatible con un dispositivo de almacenamiento físico separado o usar partes separadas del almacenamiento utilizando redundancia (Mirroring, RAID, etc.).
Las instancias dobles redundantes de la API del servidor, el planificador y el administrador del controlador son la próxima actualización si su único host tiene suficientes recursos para esto.
Opciones de implementación de host único, desde la menos adecuada para la producción hasta la mayoría| Tipo | Caracteristicas | Resultado |
|---|
| Equipo mínimo | Singleton, etcd y componentes maestros. | Laboratorio casero, en absoluto grado de producción. Punto único de falla múltiple (SPOF). La recuperación es lenta, y cuando se pierde el almacenamiento, está completamente ausente. |
| Mejora de redundancia de almacenamiento | etcd singleton y componentes maestros, el almacenamiento de etcd es redundante. | Como mínimo, puede recuperarse de una falla del dispositivo de almacenamiento. |
| Redundancia de nivel gestionado | No hay hipervisor, varias instancias de componentes de nivel administrado en pods estáticos. | Ha aparecido protección contra errores de software, pero el sistema operativo y el entorno de lanzamiento del contenedor siguen siendo el mismo punto de falla con actualizaciones devastadoras. |
| Agregar un hipervisor | Ejecutando tres instancias redundantes de nivel administrado en la VM. | Existe protección contra errores de software y errores humanos y una ventaja operativa en instalación, gestión de recursos, monitoreo y seguridad. Las actualizaciones del sistema operativo y los entornos de lanzamiento de contenedores son menos perjudiciales. El hipervisor es el único punto único de falla. |
Implementación de doble hostCon dos hosts, los problemas de almacenamiento de etcd son similares a la opción de host único: necesita redundancia. Es preferible ejecutar tres instancias encd. Puede parecer poco intuitivo, pero es mejor concentrar todos los nodos etcd en un host. No aumentará la confiabilidad al dividirlos entre 2 + 1 entre dos hosts: la pérdida de un nodo con la mayoría de las instancias de cifrado provocará un error, independientemente de si es una mayoría de 2 o 3. Si los hosts no son iguales, coloque todo el clúster etcd en el más confiable.
Se recomienda que ejecute servidores API redundantes, kube-Schedulers y Kube-controller-managers. Deben compartirse entre los hosts para minimizar los riesgos de fallas en el entorno de lanzamiento del contenedor, el sistema operativo y el hardware.
El lanzamiento de una capa de hipervisor en hosts físicos le permitirá trabajar con componentes de programa redundantes, proporcionando administración de recursos. También tiene la ventaja operativa del mantenimiento programado.
Opciones de implementación para dos hosts, desde el menos adecuado para la producción hasta el más| Tipo | Caracteristicas | Resultado |
|---|
| Equipo mínimo | Dos hosts, sin almacenamiento redundante. Singleton, etcd y componentes maestros en el mismo host. | etcd: un único punto de falla, no tiene sentido ejecutar dos en otros servicios maestros. Compartir entre dos hosts aumenta el riesgo de fallas en la capa administrada. El beneficio potencial de aislar recursos ejecutando una capa administrada en un host y cargas de trabajo de aplicaciones en otro. Si se pierde el almacenamiento, no hay recuperación. |
| Mejora de redundancia de almacenamiento | Singleton, etcd y componentes maestros en el mismo host, almacenamiento de etcd redundante. | Como mínimo, puede recuperarse de una falla del dispositivo de almacenamiento. |
| Redundancia de nivel gestionado | No hay hipervisor, varias instancias de componentes de nivel administrado en pods estáticos. etcd clúster en un host, otros componentes de nivel administrado están separados. | Una falla de hardware, la actualización del firmware, el sistema operativo y el entorno de inicio del contenedor en un host sin etcd son menos dañinos. |
| Agregar un hipervisor a ambos hosts | Tres componentes redundantes de nivel administrado se ejecutan en máquinas virtuales, clúster etcd en un host, y los componentes de nivel administrado están separados. Las cargas de trabajo de la aplicación pueden residir en ambos nodos de VM. | Aplicación mejorada de aislamiento de carga. Las actualizaciones del sistema operativo y el entorno de lanzamiento de contenedores son menos perjudiciales. El mantenimiento programado de hardware / firmware se vuelve no destructivo si el hipervisor admite la migración de VM. |
Implementación en tres (o más) hostsTransición a un servicio de producción sin concesiones. Recomendamos dividir etcd entre los tres hosts. Una falla de hardware reducirá la cantidad de posibles cargas de trabajo de la aplicación, pero no dará como resultado una interrupción completa del servicio.
Los grupos muy grandes requerirán más instancias.
El lanzamiento de una capa de hipervisor proporciona beneficios operativos y un aislamiento mejorado de las cargas de trabajo de la aplicación. Esto está más allá del alcance del artículo, pero a nivel de tres o más hosts, pueden estar disponibles funciones mejoradas (almacenamiento compartido redundante en clúster, administración de recursos con un equilibrador de carga dinámico, monitoreo de estado automatizado con migración en vivo y conmutación por error).
Opciones de implementación para tres (o más) hosts desde el menos adecuado para la producción hasta el más| Tipo | Caracteristicas | Resultado |
|---|
| Mínimo | Tres anfitriones Instancia, etcd en cada nodo. Componentes maestros en cada nodo. | La pérdida de un nodo reduce el rendimiento, pero no conduce a una caída en Kubernetes. La posibilidad de recuperación permanece. |
| Agregar un hipervisor a los hosts | En máquinas virtuales en tres hosts, etc., se está ejecutando un servidor API, programadores y un administrador de controladores. Las cargas de trabajo se ejecutan en la VM en cada host. | Protección adicional contra errores del sistema operativo / contenedor / entorno de lanzamiento de software y errores humanos. Beneficios operacionales de instalación, actualización, gestión de recursos, monitoreo y seguridad. |
Configurar KubernetesLos nodos maestro y trabajador deben estar protegidos contra sobrecarga y agotamiento de recursos. Las funciones de hipervisor se pueden usar para aislar componentes críticos y reservar recursos. También hay ajustes de configuración de Kubernetes que pueden ralentizar cosas como la velocidad de las llamadas API. Algunos kits de instalación y distribuciones comerciales se encargan de esto, pero si está implementando Kubernetes usted mismo, la configuración predeterminada puede no ser adecuada, especialmente para recursos pequeños o para un clúster que es demasiado grande.
El consumo de recursos de nivel administrado se correlaciona con el número de hogares y la tasa de salida de hogares. Los clústeres muy grandes y muy pequeños se beneficiarán de la solicitud de kube-apiserver modificada y la
configuración de desaceleración de memoria.
El nodo asignable debe configurarse en los
nodos de trabajo en función de la densidad de carga admitida razonable para cada nodo. Se pueden crear espacios de nombres para dividir un grupo de nodos de trabajo en varios grupos virtuales con
cuotas para CPU y memoria.
SeguridadCada clúster de Kubernetes tiene una entidad emisora de certificados (CA) raíz. Se deben generar e instalar los certificados Controller Manager, API Server, Scheduler, kubelet client, kube-proxy y administrador. Si usa una herramienta de instalación o distribución, es posible que no tenga que lidiar con eso usted mismo. El proceso manual se describe
aquí . Debe estar preparado para reinstalar certificados si expande o reemplaza los nodos.
Dado que Kubernetes está totalmente administrado por la API, es imprescindible controlar y limitar la lista de quienes tienen acceso al clúster. Las opciones de cifrado y autenticación se analizan en esta documentación.
Las cargas de trabajo de la aplicación Kubernetes se basan en imágenes de contenedor. Necesita que la fuente y el contenido de estas imágenes sean confiables. Casi siempre, esto significa que alojará la imagen del contenedor en el repositorio local. El uso de imágenes de Internet público puede causar problemas de confiabilidad y seguridad. Debe seleccionar un repositorio que tenga soporte para firmar la imagen, escanear la seguridad, controlar el acceso para enviar y descargar imágenes, y registrar la actividad.
Los procesos deben configurarse para admitir el uso de host, hipervisor, OS6, Kubernetes y otras actualizaciones de firmware de dependencia. La supervisión de la versión es necesaria para respaldar la auditoría.
Recomendaciones:
- Fortalecer la configuración de seguridad predeterminada para componentes de nivel administrado (por ejemplo, bloqueo de nodos de trabajo );
- Use la política de seguridad del hogar ;
- Piense en la integración de NetworkPolicy disponible para su solución de red, incluido el seguimiento, la supervisión y la resolución de problemas;
- Use RBAC para tomar decisiones de autorización;
- Piense en la seguridad física, especialmente cuando se implementa en ubicaciones periféricas o remotas que podrían pasarse por alto. Agregue cifrado de almacenamiento para limitar las consecuencias del robo del dispositivo y protección contra la conexión de dispositivos maliciosos, como llaves USB;
- Proteja las credenciales de texto del proveedor de la nube (claves de acceso, tokens, contraseñas, etc.).
Los objetos
secretos de Kubernetes son adecuados para almacenar pequeñas cantidades de datos confidenciales. Se almacenan en etcd. Se pueden usar de forma segura para almacenar credenciales de la API de Kubernetes, pero hay momentos en que una carga de trabajo o la expansión del clúster en sí requiere una solución más completa. El proyecto HashiCorp Vault es una solución popular si necesita más de lo que los objetos secretos integrados pueden proporcionar.
Recuperación ante desastres y respaldo
La implementación de redundancia mediante el uso de múltiples hosts y máquinas virtuales ayuda a reducir la cantidad de ciertos tipos de fallas. Pero escenarios como un desastre natural, una mala actualización, un ataque de piratas informáticos, errores de software o un error humano aún pueden provocar bloqueos.
Una parte crítica de una implementación de producción es la expectativa de una recuperación futura.
También vale la pena señalar que parte de su inversión en diseño, documentación y automatización del proceso de recuperación puede reutilizarse si necesita implementaciones replicadas a gran escala en varios sitios.
Entre los elementos de recuperación ante desastres, cabe destacar las copias de seguridad (y posiblemente las réplicas), los reemplazos, el proceso planificado, las personas que realizarán este proceso y la capacitación regular.
Los ejercicios y principios de prueba frecuentes de
Chaos Engineering se pueden usar para evaluar su preparación.
Debido a los requisitos de disponibilidad, es posible que deba almacenar copias locales del sistema operativo, los componentes de Kubernetes y las imágenes del contenedor para permitir la recuperación, incluso si Internet falla. La capacidad de implementar hosts y nodos de reemplazo en una situación de "aislamiento físico" mejora la seguridad y aumenta la velocidad de implementación.
Todos los objetos de Kubernetes se almacenan en etcd. La copia de seguridad periódica de datos de clúster etcd es un elemento importante en la restauración de clústeres de Kubernetes durante situaciones de emergencia, por ejemplo, cuando se pierden todos los nodos maestros.
etcd
etcd . Kubernetes . , Kubernetes.
, Kubernetes etcd , - . , .
etcd. , , , , /. , . :
- : CA, API Server, Apiserver-kubelet-client, ServiceAccount, “Front proxy”, Front proxy;
- DNS;
- IP/;
- ;
- kubeconfig;
- LDAP ;
- .
Anti-affinity . , . , Kubernetes , . , , - .
, .
stateful-, — Kubernetes (, SQL ). , , Kubernetes,
roadmap feature request , , , Container Storage Interface (CSI). , - , , . , Kubernetes , , , Kubernetes .
stateful- (, Cassandra) , , . - Kubernetes ( -) .
( ) , , . , , .
, (,
Ansible ,
BOSH ,
Chef ,
Juju ,
kubeadm ,
Puppet .). , .
, , , , , , . , Git, .
, , — . 2 , — . — , .

— . - , Airbus A320 — . , . , .
, . , , , . Kubernetes , - , , (, FedEx, Amazon).
production-grade Kubernetes . . , , , , . , (, Kubernetes
self-hosting, no hogares estáticos). Quizás deberían discutirse en los siguientes artículos, si hay suficiente interés. Además, debido a la alta velocidad de la mejora de Kubernetes, si su motor de búsqueda encontró este artículo después de 2019, algunos de sus materiales podrían estar muy desactualizados.El fin
Como siempre, estamos esperando sus preguntas y comentarios aquí, y puede ir a la jornada de puertas abiertas de Alexander Titov .