 Procesador tensor de tercera generaciónGoogle Tensor Processor
Procesador tensor de tercera generaciónGoogle Tensor Processor es un circuito integrado de propósito especial (
ASIC ) desarrollado desde cero por Google para realizar tareas de aprendizaje automático. Trabaja en varios productos importantes de Google, incluidos Translate, Photos, Search Assistant y Gmail. Cloud TPU ofrece los beneficios de escalabilidad y facilidad de uso a todos los desarrolladores y científicos de datos que lanzan modelos de aprendizaje automático de vanguardia en Google Cloud. En Google Next '18, anunciamos que Cloud TPU v2 ahora está disponible para todos los usuarios, incluidas
las cuentas de prueba gratuitas , y Cloud TPU v3 está disponible para pruebas alfa.

Pero mucha gente pregunta: ¿cuál es la diferencia entre CPU, GPU y TPU? Creamos un
sitio de demostración donde se encuentran la presentación y la animación que responden a esta pregunta. En esta publicación, me gustaría hacer hincapié en ciertas características del contenido de este sitio.
¿Cómo funcionan las redes neuronales?
Antes de comenzar a comparar la CPU, la GPU y la TPU, veamos qué tipo de cálculos se requieren para el aprendizaje automático, y específicamente, para las redes neuronales.
Imagine, por ejemplo, que usamos una red neuronal de una sola capa para reconocer números escritos a mano, como se muestra en el siguiente diagrama:
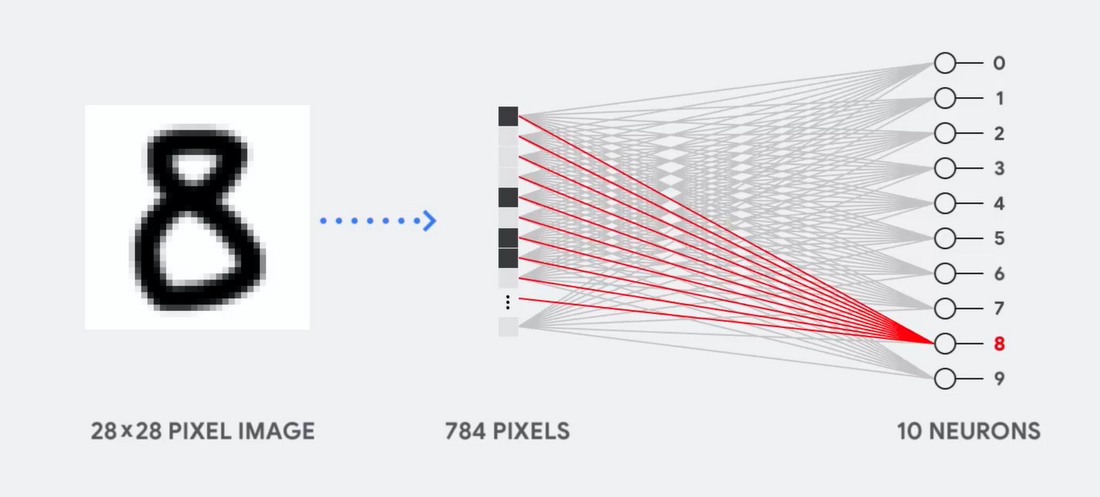
Si la imagen es una cuadrícula de 28x28 píxeles en escala de grises, se puede convertir en un vector de 784 valores (medidas). Una neurona que reconoce el número 8 toma estos valores y los multiplica con los valores de los parámetros (líneas rojas en el diagrama).
El parámetro funciona como un filtro, extrayendo características de los datos que indican la similitud de la imagen y la forma 8:

Esta es la explicación más simple de la clasificación de datos por redes neuronales. Multiplicación de datos con los parámetros correspondientes a ellos (coloración de puntos) y su suma (suma de puntos a la derecha). El resultado más alto indica la mejor coincidencia entre los datos ingresados y el parámetro correspondiente, que, lo más probable, será la respuesta correcta.
En pocas palabras, las redes neuronales necesitan hacer una gran cantidad de multiplicaciones y adiciones de datos y parámetros. A menudo los organizamos en forma de
multiplicación matricial , que puedes encontrar en álgebra en la escuela. Por lo tanto, el problema es realizar una gran cantidad de multiplicaciones de matrices lo más rápido posible, gastando la menor energía posible.
¿Cómo funciona una CPU?
¿Cómo aborda la CPU esta tarea? La CPU es un procesador de uso general basado en la
arquitectura von Neumann . Esto significa que la CPU funciona con software y memoria de la siguiente manera:
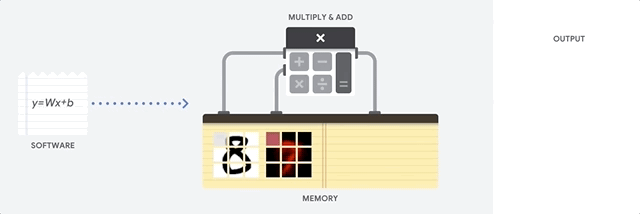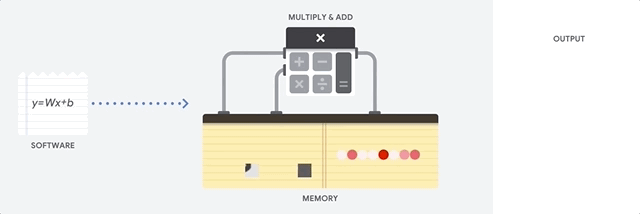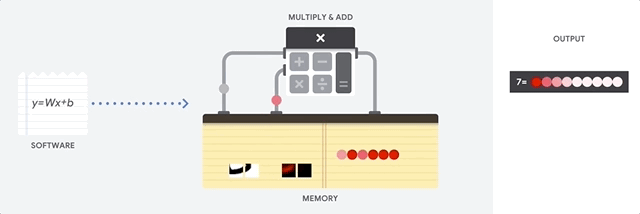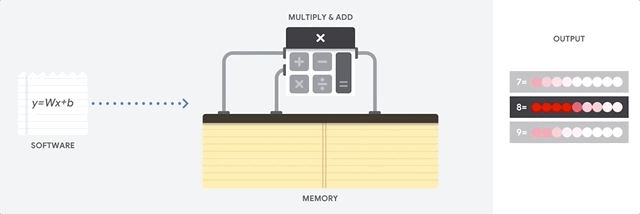
La principal ventaja de la CPU es la flexibilidad. Gracias a la arquitectura von Neumann, puede descargar software completamente diferente para millones de propósitos diferentes. La CPU se puede usar para procesamiento de texto, control de motores de cohetes, transacciones bancarias, clasificación de imágenes utilizando una red neuronal.
Pero como la CPU es tan flexible, el equipo no siempre sabe de antemano cuál será la próxima operación hasta que lea las siguientes instrucciones del software. La CPU necesita almacenar los resultados de cada cálculo en la memoria ubicada dentro de la CPU (los llamados registros o
caché L1 ). El acceso a esta memoria se convierte en una desventaja de la arquitectura de la CPU, conocida como el cuello de botella de la arquitectura von Neumann. Y aunque una gran cantidad de cálculos para redes neuronales hace que los pasos futuros sean predecibles, cada
dispositivo de lógica aritmética de la CPU (ALU, un componente que almacena y controla multiplicadores y sumadores) realiza operaciones secuencialmente, accediendo a la memoria cada vez, lo que limita el rendimiento general y consume una cantidad significativa de energía .
Cómo funciona la GPU
Para aumentar el rendimiento en comparación con la CPU, la GPU utiliza una estrategia simple: ¿por qué no integrar miles de ALU en el procesador? La GPU moderna contiene alrededor de 2500 - 5000 ALU en el procesador, lo que hace posible realizar miles de multiplicaciones y adiciones a la vez.

Dicha arquitectura funciona bien con aplicaciones que requieren paralelización masiva, como, por ejemplo, la multiplicación de matrices en una red neuronal. Con una carga de entrenamiento típica de aprendizaje profundo (GO), el rendimiento en este caso aumenta en un orden de magnitud en comparación con la CPU. Por lo tanto, hoy la GPU es la arquitectura de procesador más popular para GO.
Pero la GPU sigue siendo un procesador de uso general que debe admitir un millón de aplicaciones y software diferentes. Y esto nos lleva de vuelta al problema fundamental del cuello de botella de la arquitectura von Neumann. Para cada cálculo en miles de ALU, GPU, es necesario recurrir a registros o memoria compartida para leer y guardar resultados de cálculo intermedios. Debido a que la GPU realiza más cómputo paralelo en miles de sus ALU, también gasta proporcionalmente más energía en el acceso a la memoria y ocupa un área grande.
¿Cómo funciona TPU?
Cuando desarrollamos TPU en Google, creamos una arquitectura diseñada para una tarea específica. En lugar de desarrollar un procesador de uso general, desarrollamos un procesador matricial especializado para trabajar con redes neuronales. TPU no podrá trabajar con un procesador de texto, controlar motores de cohetes o realizar transacciones bancarias, pero puede procesar una gran cantidad de multiplicaciones y adiciones para redes neuronales a una velocidad increíble, mientras consume mucha menos energía y se adapta a un volumen físico más pequeño.
Lo principal que le permite hacer esto es la eliminación radical del cuello de botella de la arquitectura von Neumann. Dado que la tarea principal de TPU es el procesamiento matricial, los desarrolladores de circuitos estaban familiarizados con todos los pasos de cálculo necesarios. Por lo tanto, pudieron colocar miles de multiplicadores y sumadores, y conectarlos físicamente, formando una gran matriz física. Esto se llama
arquitectura de matriz canalizada . En el caso de Cloud TPU v2, se utilizan dos matrices de canalización de 128 x 128, lo que en total da 32.768 ALU para valores de punto flotante de 16 bits en un procesador.
Veamos cómo una matriz canalizada realiza cálculos para una red neuronal. Primero, el TPU carga los parámetros de la memoria en una matriz de multiplicadores y sumadores.

El TPU luego carga los datos de la memoria. Al completar cada multiplicación, el resultado se transmite a los siguientes factores, mientras se realizan las sumas. Por lo tanto, la salida será la suma de todas las multiplicaciones de los datos y parámetros. A lo largo del proceso de computación volumétrica y transferencia de datos, el acceso a la memoria es completamente innecesario.
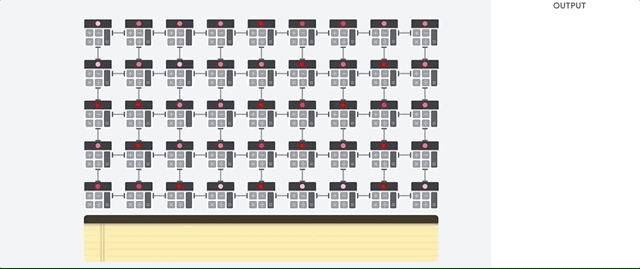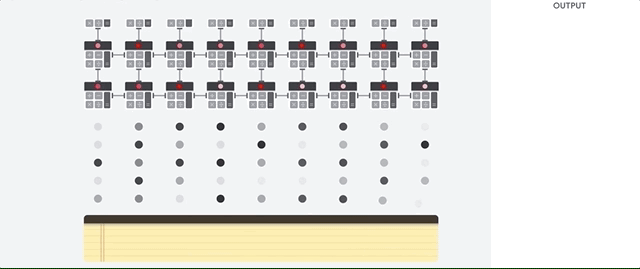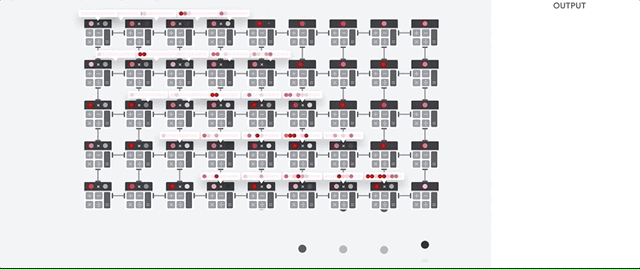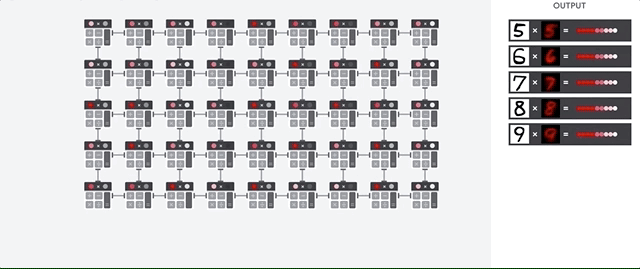
Por lo tanto, TPU demuestra un mayor rendimiento al calcular redes neuronales, consume mucha menos energía y ocupa menos espacio.
Ventaja: 5 veces menos costo
¿Cuáles son los beneficios de la arquitectura TPU? Costo Aquí está el costo de Cloud TPU v2 para agosto de 2018, en el momento de escribir esto:
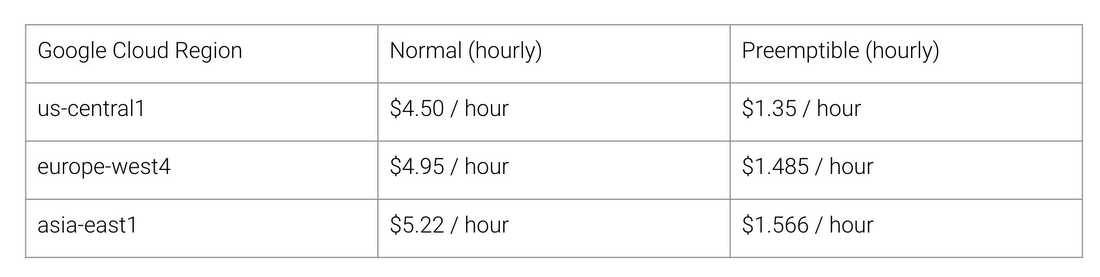
Costo de trabajo normal y de TPU para diferentes regiones de Google Cloud
La Universidad de Stanford está distribuyendo un conjunto de pruebas
DAWNBench que miden el rendimiento de los sistemas de aprendizaje profundo. Allí puede ver varias combinaciones de tareas, modelos y plataformas informáticas, así como los resultados de las pruebas correspondientes.
Al final de la competencia, en abril de 2018, el costo mínimo de capacitación en procesadores con arquitectura distinta de TPU era de $ 72.40 (para la capacitación de ResNet-50 con 93% de precisión en ImageNet en
instancias puntuales ). Con Cloud TPU v2, esta capacitación se puede realizar por $ 12.87. Esto es menos de 1/5 del costo. Tal es el poder de la arquitectura diseñada específicamente para redes neuronales.